
前回は、ロボットシステムを分解していくと、「制御」と「計画」といった要素で階層的に構成されることを学びました。「制御」は、制御対象の制御値を与えられた目標値に近づけることです。そして、制御の基本である倒立振子システムの制御処理に FPGA を用いることで、マイクロ秒程度の周期で超高速な制御を計算できることを示しました。
今回は、ロボットシステムの「計画」をするための処理に FPGA を用いることを考えます。「計画」のためのセンサ情報の取得において、特に期待が高まっているのは、ロボットビジョンやコンピュータビジョンと呼ばれる、カメラによる画像認識です。この記事では、ロボットの計画における画像認識の役割と時間制約、局所特徴による画像認識、FPGA を用いた画像認識の処理回路の高位合成による開発、について説明します。
ロボットシステムにおける画像認識と時間制約
「計画」とはロボットの近い未来の行動の目標値を決めることです。そのためには、現在・過去の情報を統合・判断して、未来を予測して目標値を設定する処理が必要です。具体的には、現在のロボットの周辺 (外界) の状況をセンサで取得したり、これまでの自分自身の状況を記憶・蓄積しておいて参照したり、更には (他のロボットや人間が蓄積した) 過去の知識を参考にすることもあるでしょう。
下の図は、センサと画像の入力に基づいてモータ駆動を行う、ロボットシステムを示したモデルの例です。モデルというのは模型の事で、中身 (詳細) には立ち入らずに、システムの一つの側面を示すものです。ここでは「処理」・「データ」・「操作」・「データフロー (データの流れ)」・「時間制約」だけに着目したモデルとしました。
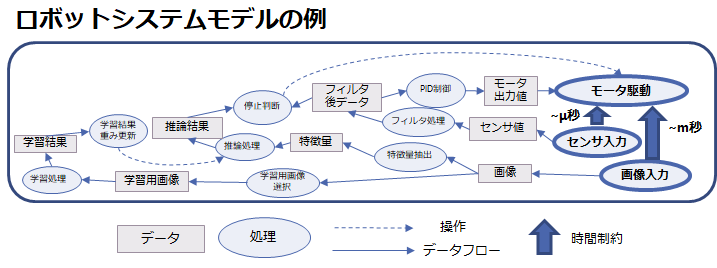
図の右側にセンサ入力と画像入力があり、上に向かう太い矢印をたどるとモータ駆動があります。例えば位置センサの入力に応じてロボットアームを動かすとしましょう。目標の位置に向かってロボットアームを動かす際の「制御」を考えると、位置センサ入力からモータを駆動するまでの遅延時間は、(物理的な大きさに依りますが) マイクロ秒程度から数ミリ秒以内にする必要があります。この時間制約の中で、位置センサから入力されたセンサの値に応じて、ノイズ除去のためのフィルタ処理・PID 制御処理を経てモータ出力値を決める、というデータフローを経ることがこのモデルとして示されているわけです。
一方、ロボットアームの位置の目標値を定める「計画」を画像認識で行いたいという要求もあります。余談になりますが、以前「Amazon Picking Challenge」という名称のロボットコンテストがありました(*1)。棚に商品が雑然と置かれている状況から、指定されたものをロボットアームでつかみ取り、別の箱に入れます。もちろん指定されたものは画像認識で判別する必要があります。Amazon の倉庫がロボットで自動化されているのはご存知と思いますが、更に人手によるピッキング作業もロボットが出来るかも、という挑戦 (Challenge) のコンテストです。日本のチーム(*2) も出場していて大変面白いので是非ご覧ください。関連して、2015年の Preferred Network 社によるバラ積みロボット(*3) も大変面白い事例です。無造作に箱の中に入れられた部品を画像認識によってロボットアームを用いて一つ取り出す、というもので、CNN (Convolutional Neural Network) を用いて実装されました。以上余談でした。
さて、「カメラの入力画像を認識して、危険な状態であれば停止判断をしてモータを止める」ことは現在は人間が行うことが多いですが、画像認識処理によって行うことが出来れば不幸な事故を減らせるわけです。ロボットシステムにおいて、画像入力からモータ停止までの遅延時間は、もちろん短ければ短いほど良く、数ミリ秒から数秒以内であって欲しいでしょう。先ほどの図のシステムモデルには、この時間制約において、画像からの特徴量抽出・推論・停止判断、というデータフローを経てモータ停止操作が行われることを示しました。
推論は過去の事例の学習結果によって行うわけですが、それもシステムの中に組み込んで示すと、学習用画像の選択・学習処理・学習結果による (推論のための) 重みデータ更新、といった要素が必要になります。学習に対する遅延時間の要求はそれほど厳しくはないと思いますが、人間が失敗から学んで新たなルールを作るという時間感覚を参考にするならば、数分から数時間以内には学習結果を反映した推論を行ってもらいたいものです。
さて気付いたと思います。制御処理に対しては時間制約を厳密に考えることが出来ましたが、目標値を決めるための計画の処理や、さらにその計画の方針を決める処理に関しては次第に要求があいまいになり、結果として時間制約は緩くなります。もちろん、本当は短時間の方が望ましいのですが、現実の情報処理システムであるコンピュータとソフトウェアの性能を考慮すると、このくらいの時間制約が妥当かな、と人々が考えている (常識) ということです。
FPGA を用いた処理で、ロボットにおける画像認識や、様々な計画に関する処理が大幅に高速化できたら、どうなるでしょうか?もしかしたら、ロボットの世界の常識が変わるかもしれない、そんな可能性があるのだと思います。
局所特徴による画像認識と FPGA
画像認識というと2012年以降の AI (いわゆる人工知能) ブームにおける DL (Deep Lerning、深層学習) や DNN (Deep Neural Network、深層ニューラルネットワーク) による画像認識を思い浮かべる人は多いと思います。FPGA を用いて DNN を高速化する手法や開発環境は数多く提供されています。一方、DNN 以前にも人間の目に相当する処理をコンピュータに行わせたいという人類の夢に対して、画像認識のアルゴリズムは着々と進歩を続けてきた歴史があります。そして、DNN じゃなくても出来ること、DNN では無いほうが良いことも沢山あるのです。
DNN 以前の画像認識で重要な技術は、画像局所特徴点・特徴量という考え方です。画像の中に、特徴的な点 (特徴点) を見つけて、その特徴的な点の周辺画素の状況から特徴量 (ベクトル) を計算して、特徴点を表現する、というものです。例えば、「画像中の (x,y)=(150, 200) が特徴点で、その特徴量ベクトルは (5, 3, 10, 4)」という表現です。
下の図は、局所特徴の一つである「FAST 特徴点」の検出を OpenCV を用いて行った結果です。赤い点が特徴点で、あらかじめ設定した閾値によって検出される特徴点の数が変化することが分かります。画像中の特徴点の検出は、一定のルールによる周辺画素との演算によって行われます。基本的には「エッジ」「コーナー (曲がり角)」が特徴点になります。閾値を適切に設定することで、注目すべき特徴点を絞り込むことが出来ます。

(左上:入力画像、右上:閾値20、左下:閾値40、右下:閾値60)
次のステップは、検出した特徴点の特徴量の計算です。特徴点の周りの画素値から計算を行うことで、エッジの方向・コーナーの方向を数値化できます。例えば「右下に向かって暗くなるエッジ」「上向き凸のコーナー」みたいな分類を定量的に行う事ができます。数値は一つだけにする必要も無く、複数の数値を用いたベクトル表現にすることももちろん可能です。
特徴点や特徴量は、画像中の物体の方向や大きさが変わっても比較可能 (変化しないよう) な設計をすることが可能です。SIFT 特徴量は Scale-Invariant Feature Transform の略で、回転・大きさに対して不変な特徴量として1999年に提唱されたものです。その後、2012年の DL ショックごろまで、局所特徴関連の技術は急激に進歩しました。詳しくは下記の参考資料のスライド(*4) を一読することをお勧めします。
さて、このようにして計算した特徴点・特徴量を用いると「画像と画像のマッチング・類似度比較」「特徴点を用いた物体追跡」「異常画像の検出」「自己位置推定および地図作成 (SLAM: Self-Localization And Mapping)」など、ロボットのための画像認識処理が可能です。ただし、適切な認識のためには、更に機械学習による分類などを組み合わせる必要があります。
一定の数学的なルールに基づく人工的な画像局所特徴量を用いることの特長は以下の通りです。
(1)適切なルールを事前に設定することで再現性の高い物体認識が出来る
(2)ルールの調整で認識率の向上を図る、いわゆる改善がしやすい
(3)DL/DNN と比較して一般に計算量が少なく、処理の遅延時間を短くできる
一方、これらの人工的に設計された特徴量を用いると、以下の問題があります。
(4)カメラ周辺の照明条件等、外部環境により結果が大きく左右されることが多い
(5)画像の前処理 (ノイズ除去や正規化) によって認識の成功率が大きく変わる
(5)は、DL/DNN でも同様なところはありますが、ロバスト性 (頑健性、様々な条件が変わっても大丈夫であること) に関しては、DL/DNN の方が優れているというのが一般的な見解です。ただし、DL/DNN の認識率を上げるための学習のやり方にもノウハウが色々とあるようで、一筋縄ではいきません。また、DL/DNN の誤認識の原因分析と改善、すなわち何故間違ったのかを分析して改善する事が容易でないということも理解しておく必要があるように思います。ロバスト性が必要ないように、周囲の環境を一定にする改善の方が有効なことも良くあります。
これまで見てきたように、DL/DNN ベースの画像認識と局所特徴ベースの画像認識には、それぞれ一長一短があります。すなわち、FPGA を用いて超高速なコンピュータビジョン・ロボットビジョンを実現するためには、DL/DNN だけではなく、局所特徴をベースとしたアルゴリズム活用の可能性を検討すべきではないでしょうか。
FPGA による局所特徴ベース画像認識処理
さて、ここからは FPGA を用いた画像認識処理の具体的なやり方を紹介します。ACRi ブログコースで標準的に用いられている Xilinx 社の高位合成ツール Vivado HLS 2019.2 (無償版の WebEdition で大丈夫) を用いて、画像認識処理 (FAST 特徴点検出) を手元で動かしてみるための手順を紹介します。しかし残念ながら FPGA で動かすところまでは書ききれませんので、シミュレーションまでとさせてください。
OpenCV (C++言語)による FAST 特徴点検出処理の記述
現在、Xilinx の Vivado HLS では、OpenCV がサポートされています。注意すべき点は、2018.3以降のバージョンでは、従来の OpenCV は deprecated (不推奨) となっており、Xilinx xfOpenCV Library(*5) を用いることが推奨されていることです。正式には2019.1までしかサポートされていませんが、2019.2でも使えそうです。なお、使い方という意味では OpenCV とほぼ互換なのですが、FPGA で効率よく・高速に処理するための記法が必要なので、そこは学んでいく必要があります。ドキュメントは、古いものと新しいものが混在しているため注意してみる必要があります。最新版はこちら(*6)。
それでは、先ほどの FAST 特徴点検出処理を、xfOpenCV で書くとどうなるか、見てみましょう!
xfOpenCV の配布物の example/fast (下記のリンク) に、ソースコードがあります。
https://github.com/Xilinx/xfopencv/blob/master/examples/fast/xf_fast_accel.cpp
void fast_accel(xf::Mat<XF_8UC1, HEIGHT, WIDTH, NPC1> &_src,xf::Mat<XF_8UC1, HEIGHT, WIDTH, NPC1> &_dst,uchar_t threshold)
{
xf::fast<NMS,XF_8UC1,HEIGHT,WIDTH,NPC1>(_src,_dst,threshold);
}・・・1行だけです。ただ、中身はオープンソースですので、見ることが出来ます。
下記は、FAST特徴点検出処理のソースです。
https://github.com/Xilinx/xfopencv/blob/master/include/features/xf_fast.hpp
ループ展開や配列メモリ配置など、多くの #pragma があり、FPGA を用いて高速に効率よく処理するための苦心が見られます。自分で画像処理を記述するとなると結構な苦労が必要であることが想像できますが、参考となるものがオープンソースになっていると非常に心強いです。
もう少し分かりやすい例としては、色変換処理があります。これはループ展開で並列処理になることが分かると思います。
https://github.com/Xilinx/xfopencv/blob/master/include/imgproc/xf_bgr2hsv.hpp
なお、Vivado HLS の高位合成そのものについての解説は、また別の機会にしたいと思います。
xfOpenCV のインストール
読者の皆さんの手元でも動かせるように、xfOpenCV のインストール方法を紹介します。Windows10 に、Vivado/VivadoHLS 2019.2 がインストール済みと仮定します。
1.https://github.com/Xilinx/xfopencv から ZIP ファイルを Download (右側の緑のボタン)
2.ZIPファイルを適当な場所に展開 (例:C:\xfopencv)
以上です。上記の場所 (例:C:\xfopencv) に ZIP ファイルを展開すると、include ディレクトリが C:\xfopencv\include に存在することを確認できます。
xfopencv_fast プロジェクトの作成
細かい手順を書くと大変なので、詳しくは資料 (*6) のザイリンクス OpenCV ユーザーガイドをご覧ください。p.46 からの第4章、HLS の使用、HLS スタンドアロンモード、GUI モードを見ると動かすことが出来ると思います。
まずは空のプロジェクトを作成して、C:\xfopencv\examples\fast ディレクトリから、ソースファイル (*.h, *.cpp) を、コピーしてください。
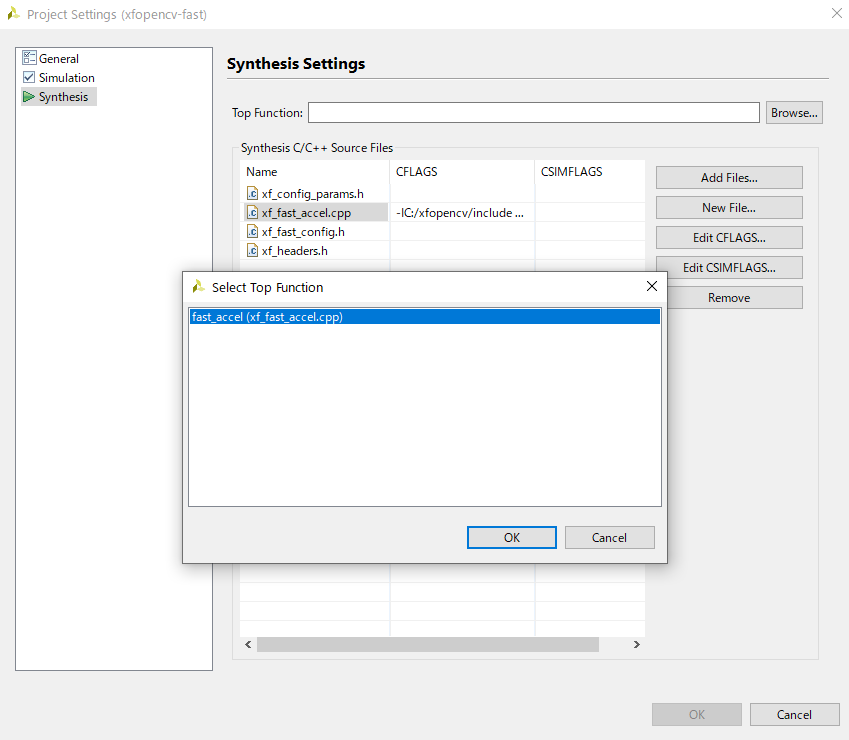
次に、ソースファイルを全てプロジェクト (source) に追加します。xf_fast_tb.cpp についてはテストベンチ (Test Bench) に追加しましょう。
次のポイントは、プロジェクト設定で、各 CPP ファイルのコンパイルフラグに下記を追加することです。なお、Synthesize 対象の Top Function を設定しないと、OK ボタンを押させてもらえませんので注意です。
(例:C:\xfopencv に ZIP ファイルを展開した場合。)
合成対象のファイル: "-IC:\xfopencv\include -D__SDSVHLS__"
テストベンチのファイル: "-IC:\xfopencv\include -D__SDSVHLS__ -std=c++0x"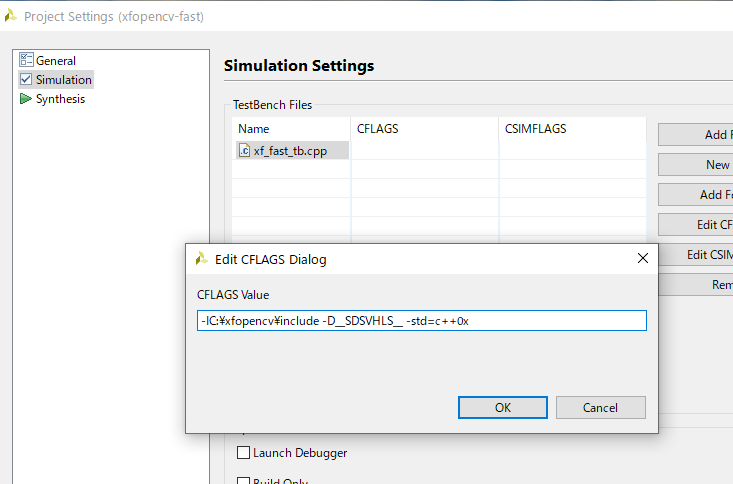
これで、コンパイルが出来るようになったはずです。
ソフトウェアによるシミュレーション
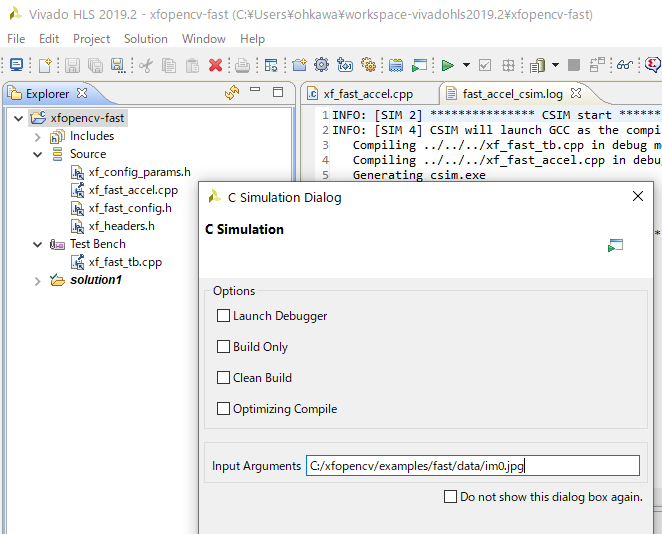
では、シミュレーションしてみましょう。メニューの Project→Run C Simulation で、C シミュレーションの開始を指示すると、下記のダイアログが出ますので、コマンドライン引数として、画像ファイルを指定します。ここでは、c:/xfopencv/examples/fast/data/im0.jpg としました。Windows の場合、¥マークではなく、スラッシュ / で入力することに注意です。
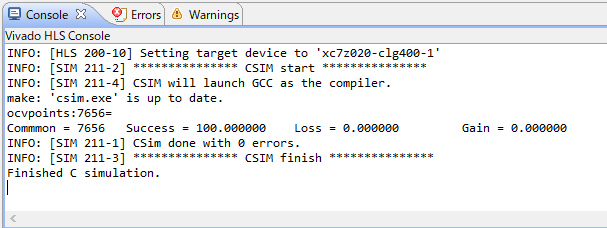
シミュレーションが無事終了すると、画面下のコンソールに以下のメッセージが出るはずです。
結果は、プロジェクトのディレクトリ (<project_dir>/solution1/csim/build) に出ているはずです。
・output_ocv.png :通常の OpenCV の出力結果を入力画像に表示したもの
・hls_out.jpg :HLS (高位合成つまりxfOpenCV) のC言語シミュレーション結果
・output_hls.png :HLS の出力結果を入力画像に表示したもの
です。是非試してみてください!


高位合成を試してみる
上記のC言語シミュレーションがうまくいったら、高位合成も試してみましょう。右向きの三角アイコン、もしくは、メニューから Solution→Run C Synthesis→Active Solution と選択すると、高位合成が始まります。
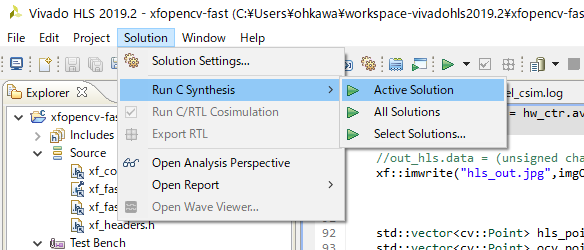
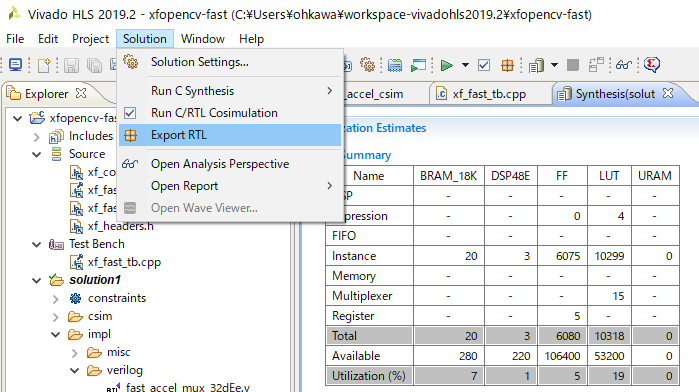
上手くいくと、下記の Synthesis Report が出てくるはずです。処理時間は、100MHz (10ns) クロックで、83.619ms の処理時間ということが分かります。下の方に行くと、使用ハードウェア量も書かれています。
合成結果の Verilog ファイルは、プロジェクトの中の solution/impl/verilog ディレクトリの中にありますので、見てみてください。
IP の生成
メニューから Solution→Export RTL をすると、Vivado で使用可能な IP を生成することが出来ます。生成が完了したら Vivado HLS を終了して、Vivado で IP を指定してつなぐ、という事になります。と、一言で書きましたが、なかなかこれが奥が深いので、その方法はまたの機会にいたしましょう。
まとめ
今回は、ロボットの計画における画像認識の役割、特に時間制約について説明したうえで、局所特徴による画像認識の紹介、そして、FPGA 処理での FAST 特徴点検出の高位合成 (Xilinx の Vivado HLS 2019.2) について紹介しました。
カメラの接続による画像データの入力と画像出力などを統合して FPGA で動かすところまでは、もう少し (まだまだ) 手順が必要で、そこがなかなか難しいのですが、画像認識の FPGA 処理の設計・開発についての入り口までは到達できたのではないかと思います。次回以降は、どのように FPGA を用いた画像認識・計画や制御の処理をロボットシステムに統合していくか、について説明していきます。お楽しみに
東海大学情報通信学部組込みソフトウェア工学科
大川猛
参考資料
*1 2015年-2017年に開催。今は名称が変わってAmazon Robotics Challengeとなっています。
*2 中部大学藤吉先生 Machine Perception and Robotics Group (MPRG) http://mprg.jp/research/amazon_picking_challenge_j
*3 PFNブログ https://tech.preferred.jp/ja/blog/robot_binpick_deep_learning/
*4 MIRU2013のチュートリアル「画像局所特徴量SIFTとそれ以降のアプローチ」, 第16回画像の認識・理解シンポジウム MIRU2013 https://www.slideshare.net/hironobufujiyoshi/miru2013sift
*5 https://github.com/Xilinx/xfopencv
*6 ザイリンクス OpenCVユーザーガイド https://japan.xilinx.com/support/documentation/sw_manuals_j/xilinx2019_1/ug1233-xilinx-opencv-user-guide.pdf