
みなさんこんにちは。この記事は、ACRi ブログの Deep Learning コースの第5回目です。
前回の記事までで、畳み込み層、全結合層、プーリング層、活性化関数 ReLU の全ての C 実装が完成しました。今回の記事では、これらの層を結合して推論関数全体を作っていきます。
モデルの実装
第2回で作成した推論モデルの図を以下に再掲します。

最初に 1x28x28 の画像を入力し、その後 Conv2d -> ReLU -> MaxPool2d というパスを2回通して特徴を抽出し、最後に Linear -> ReLU -> Linear により 10次のベクトル値へと変換するという処理でした。
C で書く場合は、次のように単純に層による処理を連続で行っていくだけです。
14 static void inference(const float* x,
15 const float* weight0, const float* bias0,
16 const float* weight1, const float* bias1,
17 const float* weight2, const float* bias2,
18 const float* weight3, const float* bias3,
19 float* y) {
20 #pragma HLS inline
21
22 static const int kWidths[] = {28, 14, 7};
23 static const int kHeights[] = {28, 14, 7};
24 static const int kChannels[] = {1, 4, 8, 32, 10};
25
26 float x1[kWidths[0] * kHeights[0] * kChannels[1]];
27 float x2[kWidths[0] * kHeights[0] * kChannels[1]];
28 float x3[kWidths[1] * kHeights[1] * kChannels[1]];
29 float x4[kWidths[1] * kHeights[1] * kChannels[2]];
30 float x5[kWidths[1] * kHeights[1] * kChannels[2]];
31 float x6[kWidths[2] * kHeights[2] * kChannels[2]];
32 float x7[kChannels[3]];
33 float x8[kChannels[3]];
34
35 // 1st layer
36 conv2d(x, weight0, bias0, kWidths[0], kHeights[0], kChannels[0], kChannels[1], 3, x1);
37 relu(x1, kWidths[0] * kHeights[0] * kChannels[1], x2);
38 maxpool2d(x2, kWidths[0], kHeights[0], kChannels[1], 2, x3);
39
40 // 2nd layer
41 conv2d(x3, weight1, bias1, kWidths[1], kHeights[1], kChannels[1], kChannels[2], 3, x4);
42 relu(x4, kWidths[1] * kHeights[1] * kChannels[2], x5);
43 maxpool2d(x5, kWidths[1], kHeights[1], kChannels[2], 2, x6);
44
45 // 3rd layer
46 linear(x6, weight2, bias2, kWidths[2] * kHeights[2] * kChannels[2], kChannels[3], x7);
47 relu(x7, kChannels[3], x8);
48
49 // 4th layer
50 linear(x8, weight3, bias3, kChannels[3], kChannels[4], y);
51 }各レイヤー間の特徴データのインターフェースには、関数内部のバッファ (x1-x8) が使用されます。
HLS ではこのバッファをどこで定義するかが大事で、今回のように関数内に置けば FPGA 内の RAM (またはレジスタ) を使うように指定できます。それに対し、このバッファを関数の引数に与える形にすれば、そのデータを外部の DRAM に繋ぐようなこともできます。この辺りは用途に応じた設計が必要ですが、今回は内部 SRAM で十分足りる量なので関数内部に定義しています。
今まで通りインターフェース仕様を書くと下のようになります。
- 入力
x: 入力画像。shape=(1, 28, 28)weight0: 1つ目の畳み込み層の重み。shape=(4, 1, 3, 3)bias0: 1つ目の畳み込み層のバイアス。shape=(4)weight1: 2つ目の畳み込み層の重み。shape=(8, 4, 3, 3)bias1: 2つ目の畳み込み層のバイアス。shape=(8)weight2: 1つ目の全結合層の重み。shape=(32, 8 * 7 * 7)bias2: 1つ目の全結合層のバイアス。shape=(32)weight3: 2つ目の全結合層の重み。shape=(10, 32)bias3: 2つ目の全結合層のバイアス。shape=(10)
- 出力
y: 出力ベクトル。shape=(10)
インターフェースの設定
ここまで作成した関数では、特に作成される回路のインターフェースは規定してきませんでした。Vivado HLS ではインターフェースを未指定時は単なる SRAM 用のインターフェースが生成されます。
このインターフェースでは、DRAM のようなアクセス時間が不定のインタフェースに対するアクセスに使用できないため、実機上で動作させるには不便です。このため、Xilinx の FPGA 上で IP 間のインターフェースに主に用いられる AMBA AXI4 Interface Protocol (以下、AXI) というプロトコルを使用するように Vivado HLS に指示します。
AXI について軽く説明すると、 AXI は ARM 社の提供するインターフェース規格です。
Xilinx の IP では、主に以下の3つのプロトコルを使用します。
- AXI4: 高速なメモリアクセス用のプロトコル (主な用途: DRAM, PCIe 等のアクセス)
- AXI4-Lite: AXI4 のサブセットで、低速なメモリアクセス用のプロトコル (主な用途: IP のレジスタ制御)
- AXI4-Stream: 片方向のデータのみの送信を行うプロトコル、アドレスはなし (主な用途: ストリームデータ処理)
今回は入出力データへのアクセスに AXI4 を、IP の制御に AXI4-Lite を使用します。
インターフェース定義を付与した推論関数は次のようになります。
24 void inference_top(const float x[kMaxSize],
25 const float weight0[kMaxSize], const float bias0[kMaxSize],
26 const float weight1[kMaxSize], const float bias1[kMaxSize],
27 const float weight2[kMaxSize], const float bias2[kMaxSize],
28 const float weight3[kMaxSize], const float bias3[kMaxSize],
29 float y[kMaxSize]) {
30 #pragma HLS interface m_axi port=x offset=slave bundle=gmem0
31 #pragma HLS interface m_axi port=weight0 offset=slave bundle=gmem1
32 #pragma HLS interface m_axi port=weight1 offset=slave bundle=gmem2
33 #pragma HLS interface m_axi port=weight2 offset=slave bundle=gmem3
34 #pragma HLS interface m_axi port=weight3 offset=slave bundle=gmem4
35 #pragma HLS interface m_axi port=bias0 offset=slave bundle=gmem5
36 #pragma HLS interface m_axi port=bias1 offset=slave bundle=gmem6
37 #pragma HLS interface m_axi port=bias2 offset=slave bundle=gmem7
38 #pragma HLS interface m_axi port=bias3 offset=slave bundle=gmem8
39 #pragma HLS interface m_axi port=y offset=slave bundle=gmem9
40 #pragma HLS interface s_axilite port=x bundle=control
41 #pragma HLS interface s_axilite port=weight0 bundle=control
42 #pragma HLS interface s_axilite port=weight1 bundle=control
43 #pragma HLS interface s_axilite port=weight2 bundle=control
44 #pragma HLS interface s_axilite port=weight3 bundle=control
45 #pragma HLS interface s_axilite port=bias0 bundle=control
46 #pragma HLS interface s_axilite port=bias1 bundle=control
47 #pragma HLS interface s_axilite port=bias2 bundle=control
48 #pragma HLS interface s_axilite port=bias3 bundle=control
49 #pragma HLS interface s_axilite port=y bundle=control
50 #pragma HLS interface s_axilite port=return bundle=control
51
52 dnnk::inference(x,
53 weight0, bias0,
54 weight1, bias1,
55 weight2, bias2,
56 weight3, bias3,
57 y);
58 }dnnk::inference 関数が先に述べた推論関数で、この関数ではdnnk::inferenceをラップしています。
前回の記事と同様に、top 関数のインターフェースはポインタでなく配列としています。これはVivado HLS のシミュレーション時にシミュレータが確保するメモリバッファのサイズを規定するために必要な表記ですが、本質的にはあまり重要ではありません。
30-50 行目では、#pragma HLS interface <protocol> port=<引数名> bundle=<割り当てるインターフェース名> という構文で、関数の各引数に対してインターフェースプロトコルを指定していきます。使用するプロトコルは m_axi と s_axilite の 2つで、 m_/s_ の部分がそのリクエストの送信側か受信側か (AXI の用語で master/slave) を表し、後ろの部分が先に述べたプロトコル部分となります。
この関数では、各データポートが AXI4 の master ポートとなり、DRAM からデータを自発的に取得します (L30-39)。その際にアクセスするメモリアドレスは AXI4-Lite の slave ポートより、ホストのCPU等から設定できます (L40-49)。
最後に、処理の開始などを行うためのコントロールレジスタや、処理の完了などを確認するためのステータスレジスタ等は port=return に紐づけられ、これも AXI4-Lite の slave ポートになります (L50)。
合成・結果確認
インターフェース
この回路を IP として出力し、 Vivado の IP Integrator 上に配置すると下図のようになります。各ポートの名前は上述したinterface プラグマの bundle= の箇所に対応します。
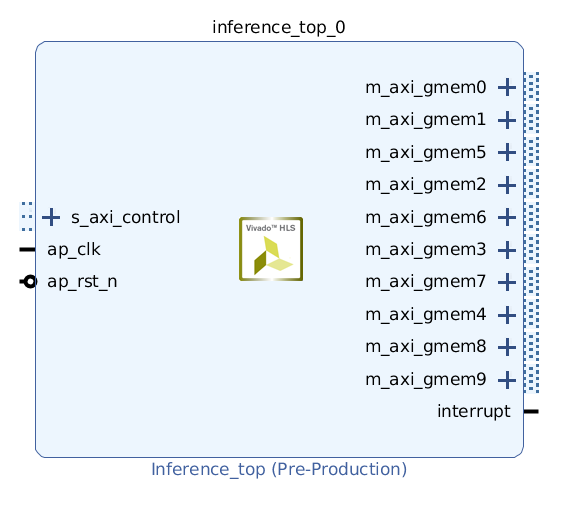
Vivado の開発に慣れている人なら分かると思いますが、ここまでできれば後は適切にポートを接続するだけで、推論処理を行える FPGA イメージを作成できます。
実行性能
合成時のパフォーマンスは以下のようになります。実行時間は最小で 1.775 ms, 最大で 7.132 ms です。
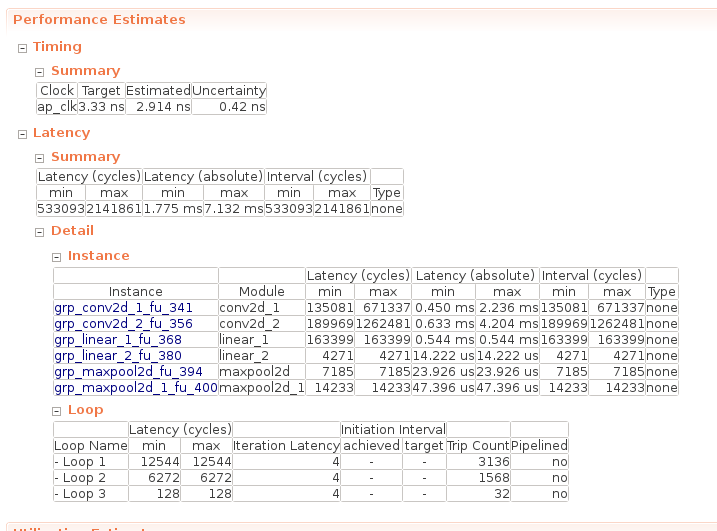
ここで、なんで入力画像サイズが固定なのに実行時間が固定じゃないのか気になりますが、これは第3回の記事で作成した畳み込み関数に以下のcontinue 処理が含まれているためです。
このゼロパディング処理は画面端でしか行われないため、実際の実行時間はほぼ最大時間の 7.132 ms 寄りの値になります。
19 for (int32_t kw = 0; kw < ksize; ++kw) {
20 int32_t ph = h + kh - ksize/2;
21 int32_t pw = w + kw - ksize/2;
22
23 // zero padding
24 if (ph < 0 || ph >= height || pw < 0 || pw >= width) {
25 continue;
26 }
27
28 int64_t pix_idx = (ich * height + ph) * width + pw;
29 int64_t weight_idx = ((och * in_channels + ich) * ksize + kh) * ksize + kw;
30
31 sum += x[pix_idx] * weight[weight_idx];
32 }ここでは可読性のために continue で打ち切っていますが、FPGA 的にはここでループを打ち切る処理よりは、既に実装されている乗加算器を用いて 0 加算した方がコストが少ないです。
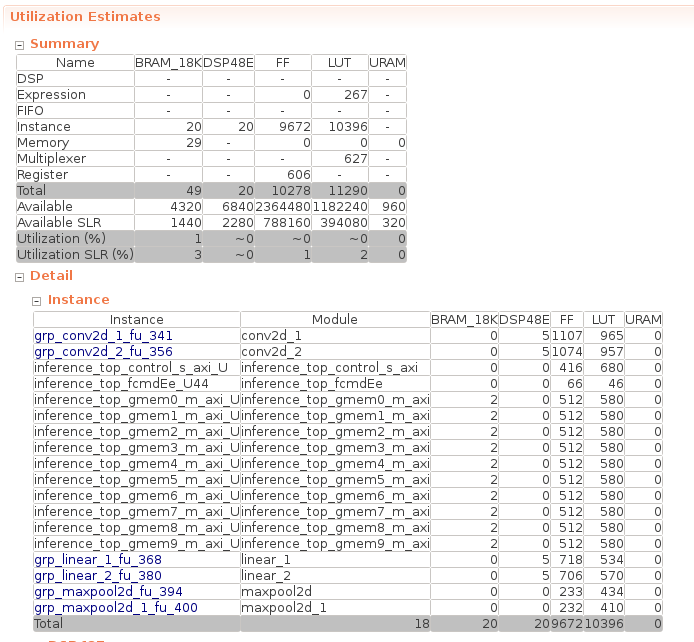
リソース使用量
Alveo U200 上でのリソース使用率は以下のようになります。並列化やパイプライン化などリソースの増える高速化を行っていないため、全体的に微々たる使用量となります。
まとめ
この記事では、第3回から作成していた推論関数の全体がようやく完成しました。次回の記事では、これを Alveo ボード上で動作させていきます。
株式会社フィックスターズ シニアエンジニア 松田裕貴