FPGA を用いて AI のアクセラレーションのような高度な処理を行うことが当たり前の時代になりました。しかし、FPGA を利用する全てのエンジニアがそうしたアプリケーションに携わっているわけではなく、初心者、初級者レベルのエンジニアが多数おられるということも事実ではないかと思います。
この記事では、現場レベルで使えるちょっとした工夫や考え方のヒントを紹介し、初級者のレベルアップや、現場の方々の手助けにつながればと考えています。
はじめに
題材としては、FPGA の基本要素として非常に重要な「ブロック RAM」 (以下 BRAM) を扱います。BRAM は程々に大きな容量を持つ SRAM で、デバイスの規模に合わせてある程度の個数が搭載されていますので、大変重宝する要素です。少し経験のあるエンジニアであれば、既に何らかの恩恵を受けているのではないかと思います。
第2回目からは、FIFO を例に BRAM の使い方をお話ししたいと考えていますが、第1回の今回は、BRAM の基本的な構成や機能について説明し、2回目以降につなげることにしたいと思います。
なお、一つ注意点があります。記事の中で説明する BRAM は、Xilinx の UltraScale シリーズに搭載されているものを前提としています。UltraScale シリーズにおける BRAM の詳細については、 UG573 を参照してください。 BRAM の基本的な部分は大きく変わっていないのですが、それでも時代を反映してか、デバイスによって若干の違いがあるのも事実です。普遍的な事実のみではないので、実際に応用する際は考慮してください。
BRAM の基本構造
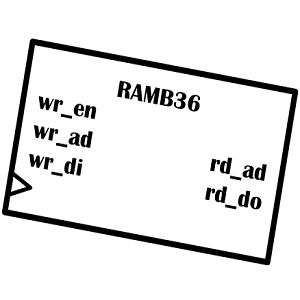
BRAM は 36kbit の SRAM に付帯的な機能を加え、RAMB36 を1単位としてとして与えられます。UG573 の図1-1を見てください。 36kbit のメモリアレーを、2系統の独立したポート (A ポート/B ポート) から共有できる構造になっていて、各ポートから書き込みと読み出しが可能です。これを TDP (True Dual Port) モードと呼びます。 UG573 の図1-1に示されています。A ポート/B ポートで異なるクロックを使用できることに着目してください。RAMB36 を書き込みポート×1、読み出しポート×1として使用することも可能で、この構成を SDP (Simple Dual Port) モードと呼びます。 UG573 の図1-6に示されています。
TDP モードと SDP モードでは、メモリアレーとして使えるデータ幅に異なる制限が加わるので、注意しましょう。36kbit のメモリアレーを、2つの 18kbit メモリアレーとして使用することもできます。
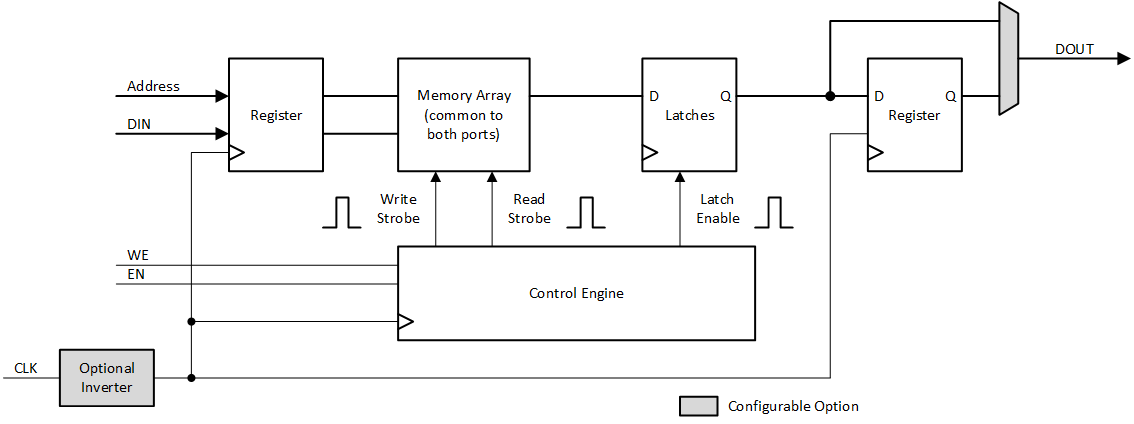
図1-1に UG573 図1-5を写し取りました。1系統分の書き込みと読み出し機能が示されています。 RAMB36 には、数多くの機能が盛り込まれていて、その詳細は UG573 で確認をお願いするわけですが、図1-1で説明したいのは出力段の構成です。図1-1には、出力段にラッチとレジスタが示され、それをマルチプレクサで選択して出力する構成が示されています。ラッチ出力を使用する場合をラッチモード、レジスタ出力を使用する場合 (オプション) をレジスタモードと呼びます。
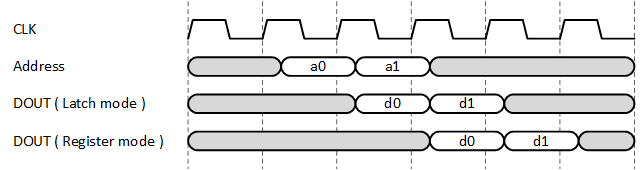
まず、アドレスを RAMB36 に入力してからラッチモードで出力するまでのシーケンスを確認しましょう。アドレスは入力されてからクロックに同期してアドレスレジスタに取り込まれます。ここでレイテンシ1が発生することに留意しましょう。アドレスレジスタに取り込まれたアドレスはメモリアレーに与えられ、メモリアレーからの読み出しデータが後段のラッチにラッチイネーブルで取り込まれます。ラッチイネーブルは詳細は明らかではありませんが、アドレスレジスタ出力アドレス→メモリアレー出力データにタイミングを合わせた信号と考えられ、次のクロックエッジを待たずにラッチ出力に読み出しデータが現れる仕掛けになっているようです。ですので、アドレスレジスタ出力からラッチ出力は非同期動作になりますが、ラッチイネーブルがクロックに付随するタイミングを持っているので、ラッチは見かけ上 clk_to_q の値が大きめのレジスタに見え、レイテンシが1となります。
レジスタモードでは、ラッチの後段にレジスタが入りますので、さらに1クロックのレイテンシが加わります。ラッチの出力の遅さを相殺するために、 Xilinx ではレジスタモードでの使用を推奨しています。
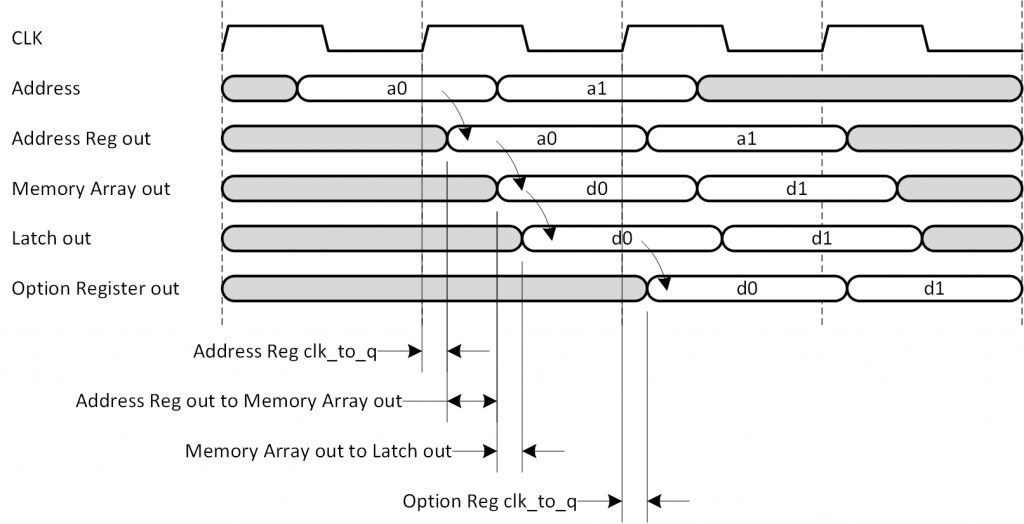
図1-2a に各モードにおける出力レイテンシの違いを示します。また、図1-2b にはアドレス入力からデータ出力への遅延シーケンスを示します。具体的な遅延量についてはデバイスごとに異なりますので、Xilinx が提供しているそれぞれの Data Sheet における Block RAM Switching Characteristic の表で確認してください。表中に without output register とあるのがラッチモード、with output register とあるのがレジスタモードの値です。
RAMB36 には、複数の RAMB36 を組み合わせてより大きな ( ワード数が多い ) メモリを構成する、カスケード機能が用意されています。また、 ECC 機能を割り当てることも可能です。さらに、書き込みデータとメモリ上のデータが、どのように読み出しデータに反映されるか ( 例えば、同一アドレスに対して書き込みと読み出しが同時に発生した場合に、読み出しデータには何が出力されるかなど ) を、書き込みモードによって選択も可能です。いずれも今回の連載では使用しませんので、説明は UG573 に委ねることにします。
BRAM の使い方
使い方といっても、要求されたアプリケーションの中でどのように BRAM を使うかは様々ですから、エンジニアがアプリケーションに応じて考えることだと思います。ここで言う使い方とは、どのような手段で必要とするメモリ機能を BRAM に割り当てるか、を指しています。
Xilinx の FPGA をターゲットデバイスとして使用する場合は、 Vivado を用いて設計を構成する要素を FPGA のリソースに割り当てる工程が必要です。これが論理合成です。 BRAM を使用する場合もその例にもれず、設計者が BRAM を使いたがっているということを確実に Vivado に伝えることが、「思い通りの結果」に早くたどり着くことにつながります。もちろん reg の配列宣言をして、あとは論理合成にお任せでも、 BRAM が推定されるかもしれませんが、確実性が下がってしまいますので、間違いなく BRAM が推定される手段を手に入れておくことは有効だと思います。
Xilinx では UltraScale で RAMB36 を使用するにあたり、 RAMB36E2 というプリミティブを提供しています。詳細については UG573 の「ブロック RAM のライブラリ プリミティブ」を参照してもらうことになりますが、すでに説明した通り数多くの機能を制御できるように作られているため、知らなくてはならない情報がたくさんあります。
UG974 の第4章:デザインエレメントには、 RAMB36E2 のインスタンシエーションテンプレートが掲載されていますが、数多くの I/O ポートと属性を記述しなければならないことがわかります。これらを正しく使わなければならないので、なかなか面倒なことだと思います。確実に BRAM を思い通りに使うには、 RAMB36E2 を使いこなすことが最良であると思いますが、多くのアプリケーションでは、 RAMB36E2 のすべての機能を必要とすることはないと思われますので、 RAMB36E2 を使いこなすことができるようになったとしても、ご利益にあずかる機会は少ないと思われます。また、 RAMB36E2 に限定してしまうと、デバイスのリターゲットの際に障害になりますので、再利用の可能性が高い設計を行う場合は注意が必要です。
RAMB36 を使用するには、 IP として生成する方法もあります。これも、設計者が欲しい機能、仕様を確実に指定する方法の一つと言えます。しかし、生成の段階でターゲットデバイスを指定しなければなりませんので、リターゲットの際の障害になるのは同じです。また、IP のアップデートなども気にしなければなりません。
UG974 の第4章:デザインエレメント RAMB36E2 において、デザインの入力方法として先の2つの方法以外に「推論」が挙げられ、これが推奨されています。 RTL として機能を記述し論理合成で推定させる方法は、筆者個人としても推奨される方法と考えています。少なくともターゲットデバイスが限定されることはありませんし、メンテナンス性も良いと思います。デメリットとして考えられるのは、論理合成における推定が自分が期待したものになるかという点で、先の2つの方法より確実でないという点です。どう推定されるかを設計者が推定するのは、なかなか難しいといえます。ですので、どう記述すればどう推定されるかを知っておくことは大変重要です。
UG901 の第4章: RAM の HDL コーディング手法、 RAM の HDL コード記述のガイドラインには、BRAM 推論に関する考え方、いろいろな機能の BRAM の記述例がありますので、ぜひ読んでください。また、同節のリンクから、「ug901-vivado-synthesis-examples」という RTL サンプル集を入手することができます。この中には BRAM を推定する RTL が多く含まれています。例えば、「rams_sp_rf.v」は、SDP モード read_first の RTL です。ファイル名から機能を連想しにくい部分はあるのですが、これらを覗いたうえで論理合成してみることをお勧めします。どう記述するとどう論理合成されるかを知ったうえで、自分なりのテンプレートを作っておくと便利です。
RAM を構成するリソースとして何を割り当てるかを、 RAM_STYLE という合成属性を使用して制御することが可能です。 BRAM を使用したい場合は、
(* ram_style = “block” *) reg [data_size-1:0] myram [2**addr_size-1:0];
というように記述して、明示的に BRAM を使用するように指定します。多くの場合この合成属性をつけなくても BRAM が使用されると思いますが、合成属性をつけておくと、何らかの理由で BRAM が推定されなかった場合に Warning が発生しますので、予定通りの合成結果でなかったことがわかりやすくなります。
では、少し筆者なりの記述例を list 1-1 に示しましょう (ss_rams_sp_rf.v) 。
module ss_rams_sp_rf (
clk , // clock
wr_en , // write enable
wr_ad , // write address
wr_di , // write data
rd_ad , // read address
rd_do ); // read data
parameter Bw_a = 11 ; // address bit width
parameter Bw_d = 72*4 ; // data bit width
// i/o
input clk ; // clock
input wr_en ; // write enable
input [Bw_a-1:0] wr_ad ; // write address
input [Bw_d-1:0] wr_di ; // write data
input [Bw_a-1:0] rd_ad ; // read address
output [Bw_d-1:0] rd_do ; // read data
// registers
(* ram_style = "block" *)
reg [Bw_d-1:0] mcel [0:2**Bw_a-1]; // memory cell
reg [Bw_d-1:0] rd_do ; // read data
// function
always @( posedge clk ) begin
if ( wr_en ) mcel[wr_ad] <= wr_di ;
end
always @( posedge clk ) begin
rd_do <= mcel[rd_ad] ;
end
endmodule
前述の「rams_sp_rf.v」とほぼ同一の機能ですが、すべての機能に効く ”en” は I/O から外し、代わりに書き込みと読み出しのアドレスを独立として、書き込みと読み出しを同時にできるようにしました。それに合わせて、書き込み、読み出しが明示されるように、 I/O 名を変更しています。(* ram_style = “block” *) を明示し、アドレスとデータのビット幅をパラメータとして与え、インスタンス化した記述から上書きできるようにして、テンプレートとしての利便性を狙っています。例えば、 Bw_a = 10、Bw_d = 72*1 であれば、2個の RAMB36 が推定されます。
なぜレジスタ出力にするのか
最初に述べたことですが、BRAM を使用する際には、出力段の構成に気を遣うことをお勧めします。Xilinx が提供している文書の中には BRAM が同期 RAM であるかのような記述も見受けられますが、ラッチモードでは出力段はラッチであることに注意します。例えば、前述の「ss_rams_sp_rf.v」はラッチモードが推定されます。ラッチモードが推定されると、以下の info が messagge に現れますので確認してみてください。レジスタモードが推定されたときには、この messagge が出ません。レジスタモードは、rd_do レジスタを2段のレジスタにすることで得られます。
[Synth 8-7053] The timing for the instance RAM_reg_bram_0 (implemented as a Block RAM) might be sub-optimal as no optional output register could be merged into the ram block. Providing additional output register may help in improving timing.
「ss_rams_sp_rf.v」の出力段を書き換えて、
wire [Bw_d-1:0] rd_do ; // read data
assign rd_do = mcel[rd_ad] ;と記述すると、論理合成はできますが BRAM は推定されず、 Distributed RAM (LUT をメモリとして構成された RAM) が推定されます。この時、
(* ram_style = “block” *)
を記述しておくと、
[Synth 8-6849] Infeasible attribute ram_style = “block” set for RAM “memory_array_name”,trying to implement using LUTRAM
との Warning が出て、 BRAM が推定されなかったことがわかります (LUTRAM はDistributed RAM のこと) 。
本題の「なぜレジスタ出力にするのか」ですが、タイミング制約を満たしやすくすることに他なりません。レジスタモードであればレジスタ出力とすることで、少なくともアドレスレジスタ出力~ラッチ出力にかかる遅延が清算され、出力フリップフロップの clock_to_q に転化されますので、レイテンシは1増えますがタイミング的に有利になります。
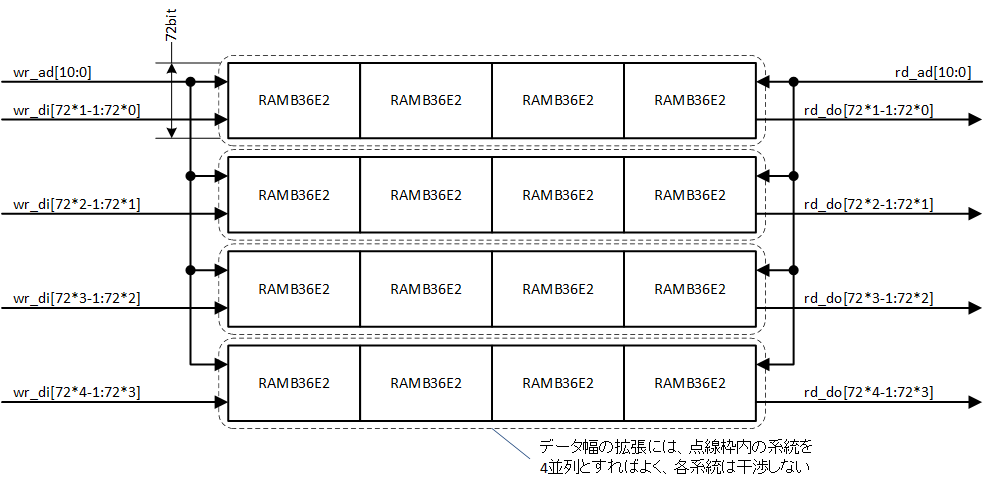
レジスタモードで追加されるオプションレジスタには、次のような恩恵もあります。前述の「ss_rams_sp_rf.v」で、Bw_a = 11、Bw_d = 72*4 とすると、1個の RAMB36E2 を基準とすれば、データ幅で4倍、メモリの深さで4倍になり、16個の RAMB36E2 になります。ここでデータ幅を4倍に拡張するには、1個の RAMB36E2 を72ビット幅として (ss_rams_sp_rf.v は SDP モードを想定していますので、データ幅の最大値は72ビットになります)、4個の RAMB36E2 を並列化すればよいだけで、4個は互いに干渉しないことがわかります。この様子を図1-3に示します。
一方、メモリの深さを4倍に拡張するには、4個に増設した RAMB36E2 出力をマルチプレクスする必要があります。その様子を図1-4に示しますが、上側には図1-3における4並列の1並列分を示し、下側に実現イメージを示しています。4個の BRAM が独立でなく、互いに接続が発生することがわかります (あくまで原理図ですが)。
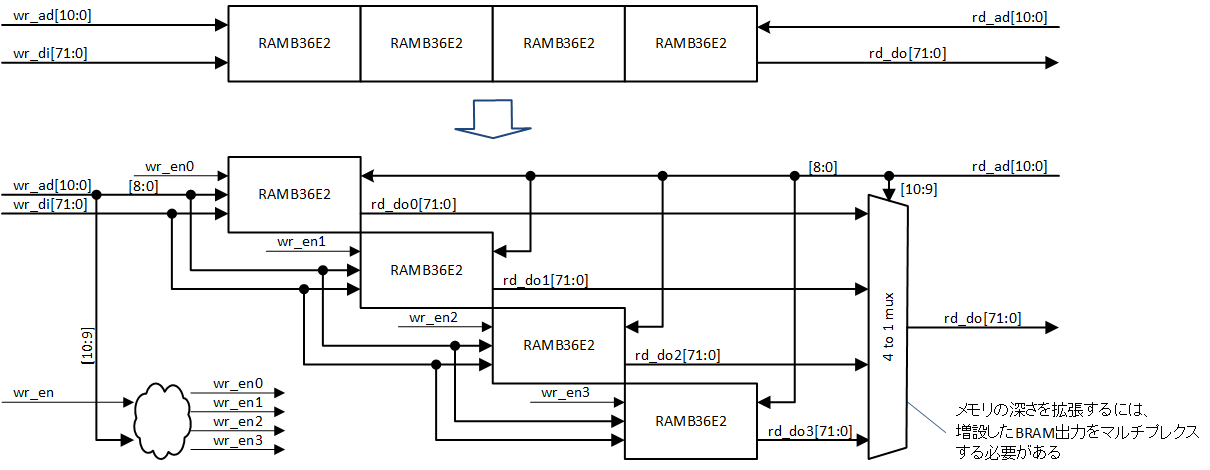
ところが、この原理通りに構成した場合には、以下の2つの不都合が発生します。
1. この例では出力に4 to 1 mux が必要になりましたが、8倍に深さを拡張するには 8 to 1 mux が必要となるのは想像に難くないと思います。拡張の度合いによってマルチプレクサの構成が変わってしまうわけですので、BRAM 内の標準回路としてマルチプレクサを用意するのは困難になります。
2. マルチプレクサという組み合わせ回路が出力段となるのは、レジスタ出力でタイミング制約的に有利になろうという目論見に反しますので、レジスタをマルチプレクサの後段に追加することになります。しかし、マルチプレクサが BRAM の外にあるということは、追加したレジスタも BRAM の外にあるわけですので、複数の BRAM とそれ以外の構成要素が必要となり、配置と配線による遅延が発生しますので、高速動作において安定したタイミング収束が難しくなります。
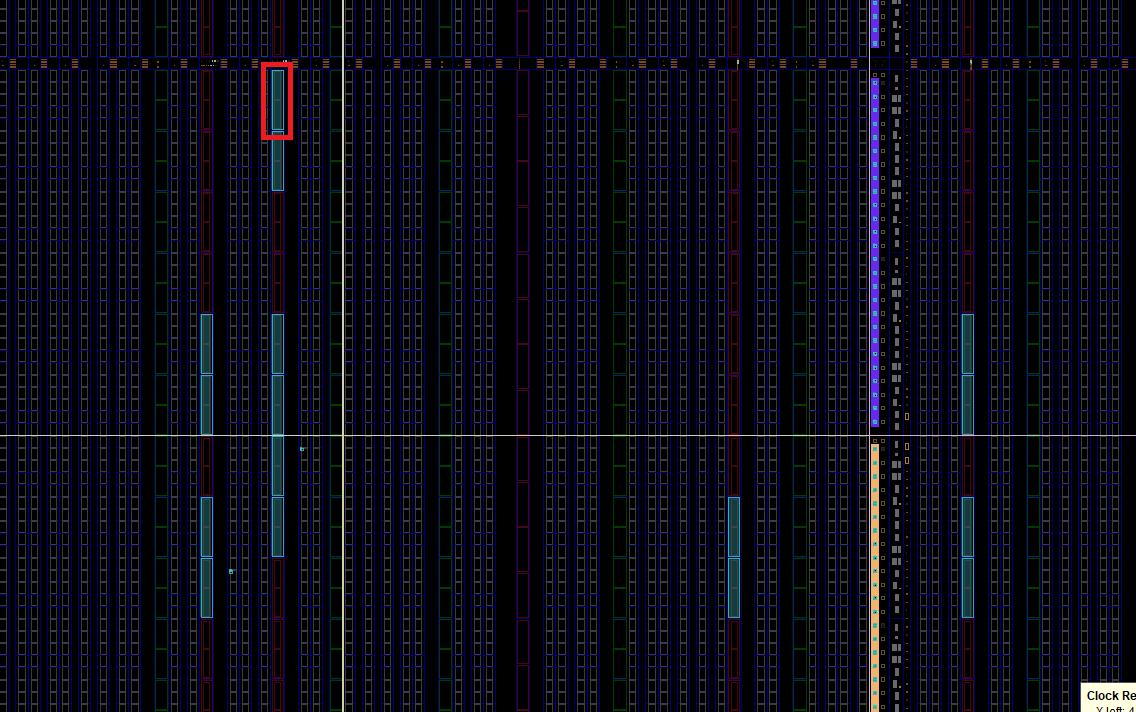
Bw_a = 11、Bw_d = 72*4 として論理合成、配置配線した場合の RAMB36E2 の配置のサンプルを、図1-5に示します。赤枠で示したのが RAMB36E2 1個分です。配置制約をつけていませんので Vivado 任せによる結果ですが、このように飛び散ることは想定しておく必要があります。
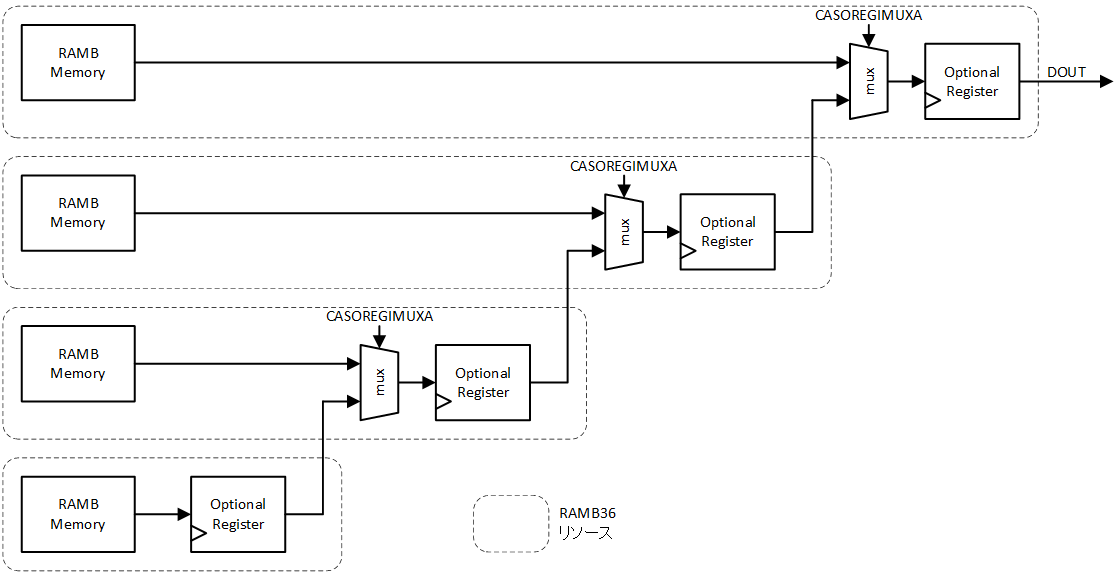
これらの不都合を解消するために用意されているのがデータ出力カスケード機能で、パイプラインモードのデータ出力カスケードで、オプションの出力レジスタが回路の高速化に寄与することになります。図1-6に、UG573 の図1-10をより単純化して示します。
これらの構成要素が RAMB36E2 内で調達できるので、配線遅延要素が少なくなり、タイミング収束に効果的です。少なくとも RAMB36E2 内での配線は決められた経路の配線ですので、遅延量も決まっていると同時に少なくできています。図1-6にはデータの接続しか示していませんが、各部の制御信号もパイプライン化されて接続されますので、機能が満たされると同時に安定したタイミング収束が可能です。
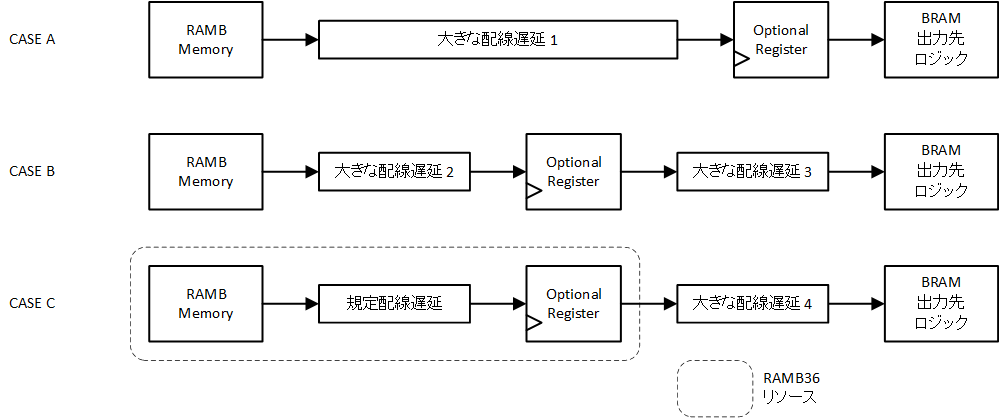
なお、オプション出力レジスタによるパイプライン化によって、タイミング収束で恩恵を受けられるのは範囲が限定されますので、注意してください。図1-7における CASE A のように BRAM の出力先ロジックの手前において、そこまでの大きな配線遅延1を清算する、CASE B のように BRAM の出力先ロジックの中継として、大きな配線遅延2を清算する、などには使えません。オプション出力レジスタは RAMB36E2 内のリソースで、配置できる場所に自由度はありませんので、CASE C のように規定配線遅延を清算するのみです。
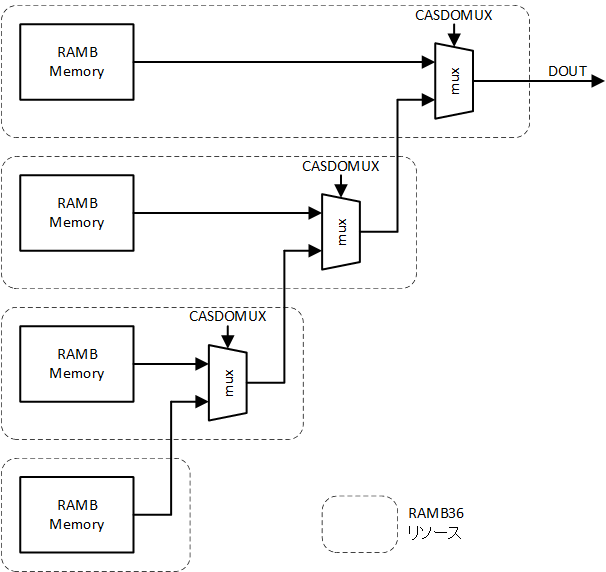
オプション出力レジスタを使用せず、カスケードが必要な1個の BRAM に収まらない深さのメモリが必要な場合には、図1-8に示す標準データ出力カスケードモードが割り当てられます (使用されるマルチプレクサが異なることに注意)。複数のマルチプレクサがカスケード接続され、RAMB36E2 間に配線が発生しますので、必然的に遅延量は大きくなります。クロック周波数が低い場合には問題とならないかもしれませんが、そうでない場合は注意しましょう。
以上のようなカスケードの処理については、Vivado が論理合成時に自動的に解決してくれます。その様子は、Vivado の Message タブで Synthesis の info として確認できます。また、オプション出力レジスタを使用しなかった場合には、使用したほうがタイミングを改善できる旨の info も得ることができます。
なお、ここまでで説明したかったのは、カスケードに関する情報ではなく、オプションの出力レジスタが何に対して有効に機能するか、についてです。 BRAM のカスケード機能については、 UG573 を参照することをお勧めします。
おわりに
第1回として BRAM について、第2回以降で使用する機能を中心に説明をしました。既にご存じの方にとっては、知っていることばかりで退屈であったかと思いますが、初級者の方々に最低限の土台を提供する場としたかったので、お許しください。
第2回以降では、 BRAM の有効な活用例として FIFO を取り上げます。第2回においては FIFO の基本構造、RTL としての記述法、Xilinx が与えてくれるプリミティブとそこからの脱却法、について説明したいと思います。手前味噌ですが、今回よりは面白くなると思います。
エンジニア 鈴木昌治
参考文献
UG573 ( v1.11 ) 2020年8月18日「 UltraScale アーキテクチャ メモリリソース ユーザー ガイド」
UG974 ( v2019.1 ) 2019年5月22日「 UltraScale アーキテクチャ ライブラリ ガイド」
UG901 ( v2018.2 ) 2018年6月6日「 Vivado Design Suite ユーザー ガイド 合成」