
みなさんこんにちは。この記事は、ACRi ブログの Deep Learning コースの第2回目です。
前回の記事では、Deep Learning とは何か、FPGA で Deep Learning するメリットについて話しました。このコースのこれ以降の記事では、FPGA をターゲットとした Deep Learning 用デザインの開発を始めていきます。特にこの記事では、まずは Python 上で学習コードを動作させ、FPGA 上で動かすためのネットワークモデルを作成します。
これ以降の記事では実際のソースコードを元に説明を行っていきます。本記事で使用するソースコードは本記事末尾に添付します。FPGA 上のデザインを含めた全コードは、後日まとめて提供予定です。
使用するデータセット・ツール
MNIST database
このコースでターゲットとする問題は、一般的に画像分類 (Image Classification) と呼ばれるタスクです。このタスクでは、入力画像に対して、それを表すラベルを出力します。ここでのラベルとは、例えば写っている物体の一般名称などが挙げられます。
MNIST database は、0から9までの手書き数字のデータセットであり、各手書き数字に対して正解ラベル (0~9) が定義されています。入力は 28×28 のグレースケール画像であり、出力も高々10クラスのため、画像分類タスクの中では非常に初歩的なタスクとなります。MNIST 以外のメジャーな画像分類データセットには、CIFAR10や ImageNet等があり、この順で、より難しい問題となっていく傾向があります。
MNIST は非常に簡単なデータセットのため、多くのディープラーニングのチュートリアルで使用されます。このコースは深層学習を FPGA で実装することが主目的のため、MNIST をターゲットとした学習モデルを作成していきます。

PyTorch
PyTorch は Facebook 社製のオープンソースのディープラーニングフレームワークであり、Google 社製の TensorFlow と並んで最も頻繁に使用されるフレームワークの一つです。本記事では、PyTorch 上で学習を行いネットワークモデルを作成していきます。
PyTorch の導入は公式サイトの手順を参考にします。筆者が使用した Ubuntu 16.04 LTS にインストールされている Python 3.5 では最新の PyTorch に対応していないため、以下のコマンドで古いバージョンのものをインストールしました。
$ pip install torch==1.4.0 torchvision==0.5.0本記事では PyTorch の使い方は主題としないため、特に学習部分などのコードの説明は省略します。興味がある方は、英語になりますが以下の公式チュートリアルを試してみることをお勧めします。
畳み込みニューラルネットワーク
畳み込みニューラルネットワーク (Convolutional Neural Network: CNN) とは、画像系のタスクでうまく動作するように作成されたニューラルネットワークです。この記事で作成するネットワークモデルは畳み込みニューラルネットワークであり、以下の3つの層と活性化関数の組み合わせでネットワークが構成されます。
- 全結合層
- 畳み込み層
- プーリング層
- 活性化関数
一つ一つの層の処理・役割について以下で概説します。
全結合層
全結合層は、入力ベクトルに対して内部パラメータの行列をかけてベクトルを出力する処理です。畳み込みなどの前置きをつけずにただニューラルネットワークというと、この全結合層を表すことが多いです。
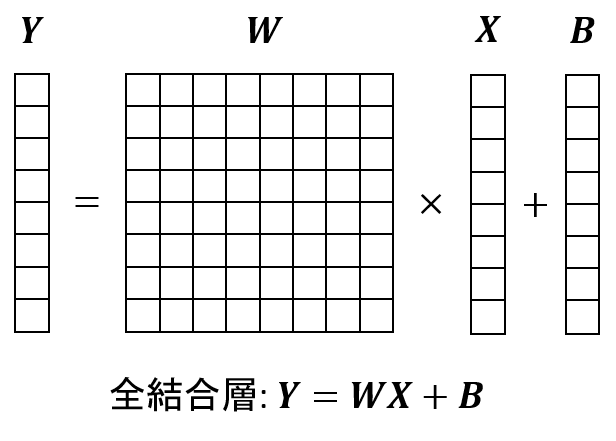
全結合層の入力がベクトルであるため、画像で注目すべき周辺ピクセルとの関係といったものが取れません。畳み込みニューラルネットワークでは、全結合層は主に畳み込み層・プーリング層によって作られた圧縮した画像情報 (特徴) をラベルデータ (0~9) のどれかに変換する場合などで使われます。
畳み込み層
畳み込み層は画像に対して畳み込み処理を行う層です。画像処理の知識のある人なら、フィルタ処理と言っても良いかもしれません。
畳み込み層では、入力画像のピクセルに対してその周辺ピクセルのピクセル値を取得し、その各ピクセル値に対して内部パラメータである配列 (カーネル) をかけ、その総和を出力画像のピクセル値とします。これを図で表すと下図のようになります。
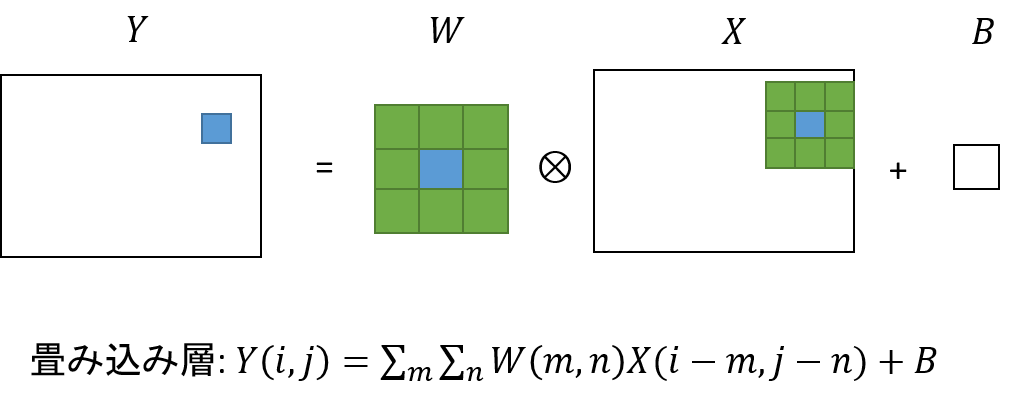
このように画像を対象とするため、畳み込みニューラルネットワークの多くの層はこの畳み込み層で構成されます。
プーリング層
プーリング層は畳み込み層により得られた情報を圧縮するための層です。今回使用したパラメータでは、画像内の 2×2 のブロックに対し、その最大値を取るという処理を行い、画像サイズを半分にします。下図がその最大値による縮小処理を表したものです。
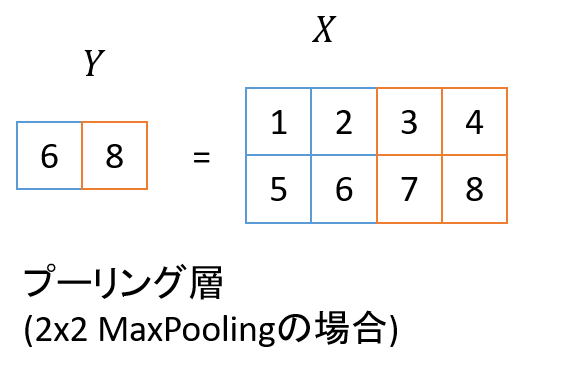
プーリング層を何度もかけることで、画像の部分ごとの情報が集約され、最終的な画像全体を表すラベル情報に近づいていきます。
活性化関数
活性化関数は非線形な関数であり、畳み込み層・全結合層の後に挿入されます。これは、二つの層が線形関数であるため、それらが合成されて実質的に一つの層と等価となってしまうことを避けるためです。活性化関数自体は様々な種類が提案されていますが、近年では ReLU が主に使用される活性化関数となります。
ReLU は Rectified Linear Unit の略称です。この関数は、0未満の入力値を0にして、0以上の値はそのまま出力する関数となります。
ネットワークモデルの作成
使用するネットワークモデルは、LeNetと呼ばれる有名なネットワークモデルを簡略化したものとします。LeNet は初期の畳み込みニューラルネットワークの一つであり、今回と同じく手書き文字認識をターゲットとしています。
本記事で使用したモデルの定義は以下となります。本家 LeNet と比較すると、畳み込み層のカーネルサイズが削減されていたり、活性化関数が ReLU になっているなどいくつか違いがあります。
class Net(nn.Module):
def __init__(self, num_output_classes=10):
super(Net, self).__init__()
# 入力は28x28 のグレースケール画像 (チャネル数=1)
# 出力が8チャネルとなるような畳み込みを行う
self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=1)
# 活性化関数はReLU
self.relu1 = nn.ReLU(inplace=True)
# 画像を28x28から14x14に縮小する
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 4ch -> 8ch, 14x14 -> 7x7
self.conv2 = nn.Conv2d(in_channels=4, out_channels=8, kernel_size=3, padding=1)
self.relu2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全結合層
# 8chの7x7画像を1つのベクトルとみなし、要素数32のベクトルまで縮小
self.fc1 = nn.Linear(8 * 7 * 7, 32)
self.relu3 = nn.ReLU(inplace=True)
# 全結合層その2
# 出力クラス数まで縮小
self.fc2 = nn.Linear(32, num_output_classes)
def forward(self, x):
# 1層目の畳み込み
# 活性化関数 (activation) はReLU
x = self.conv1(x)
x = self.relu1(x)
# 縮小
x = self.pool1(x)
# 2層目+縮小
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
# フォーマット変換 (Batch, Ch, Height, Width) -> (Batch, Ch)
x = x.view(x.shape[0], -1)
# 全結合層
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
return xこのモデルのデータフローを netron で可視化すると下のようになります。

順にデータの流れを追っていくと、最初に手書き画像 (28×28, 1ch) が入力され、最初の Conv2d 層で (28×28, 4ch) の画像に変換され、ReLU により非負値となります。
次に、Maxpool2d 層によりこの画像は (14×14, 4ch) の画像へと縮小されます。その後の Conv2d, ReLU, MaxPool2d はほぼ同様の手順となり、最終的に (7×7, 8ch) の画像となります。この画像を 7x7x8 = 392 次のベクトルとみなし、全結合層を2度適用すると最終的に10次のベクトルを出力します。この10次のベクトルのうち、最大値となる要素のインデックス (argmax) が推論した文字となります (0-9)。
学習・推論
上記モデルを用いて MNIST の学習を行います。ここで行う手順は、以下の3つです。
- 学習・テストデータのロード
- ループを回して学習
- テスト (推論)
まずはデータの読み出しです。PyTorch では予め MNIST のローダーが定義されているので、これを使ってデータを読み出します (trainset/testset)。trainloader/testloader は、各データセット内のデータの読み出し方を定義するオブジェクトです。
import torch
import torchvision
import torchvision.transforms as transforms
# 2. データセットの読み出し法の定義
# MNIST の学習・テストデータの取得
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor())
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
# データの読み出し方法の定義
# 1stepの学習・テストごとに16枚ずつ画像を読みだす
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False)データの読み出しがこれで完了するので、次は学習を開始します。初めに、ロス関数 (誤差関数) と最適化器の定義を行います。以降の学習では、ロスの値が小さくなる方向へと学習を行っていきます。
# ロス関数、最適化器の定義
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.0001)学習ループは以下のようになります。trainloader から入力データ (inputs)、正解ラベル (labels) を読みだし、ネットワークを通して出力 (outputs) を取得し、正解ラベルとの誤差 (loss) を取得します。
その後、誤差逆伝搬 と呼ばれる手法 (loss.backward()) を行い、各層における学習方向 (勾配) を計算します。得られた勾配を用いて optimizer がモデルの最適化を行います (optimizer.step())。これが1ステップの学習の流れで、今回のコードではデータセットを10順するまで学習を繰り返します。
今回 FPGA で行うのは推論処理のため、ここで説明した学習手順は理解できなくても問題ありません。なぜこのようにして学習が進むのか興味がある方は、前回の記事でいくつか分かりやすい文献等をまとめているため、そちらをご参照ください。
# データセット内の全画像を10回使用するまでループ
for epoch in range(10):
running_loss = 0
# データセット内でループ
for i, data in enumerate(trainloader, 0):
# 入力バッチの読み込み (画像、正解ラベル)
inputs, labels = data
# 最適化器をゼロ初期化
optimizer.zero_grad()
# 入力画像をモデルに通して出力ラベルを取得
outputs = net(inputs)
# 正解との誤差の計算 + 誤差逆伝搬
loss = loss_func(outputs, labels)
loss.backward()
# 誤差を用いてモデルの最適化
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0テストコードは以下のようになります。テストも学習ループとほぼ同じ作りですが、学習用のロス計算などが省かれます。また、ここでは scikit-learn の accuracy_score, confusion_matrix 関数を使って精度及び混同行列の出力を行っています。
from sklearn.metrics import accuracy_score, confusion_matrix
# 4. テスト
ans = []
pred = []
for i, data in enumerate(testloader, 0):
inputs, labels = data
outputs = net(inputs)
ans += labels.tolist()
pred += torch.argmax(outputs, 1).tolist()
print('accuracy:', accuracy_score(ans, pred))
print('confusion matrix:')
print(confusion_matrix(ans, pred))ここまで実装すると、PyTorch 上で MNIST の学習・推論を行えます。実際に i7-6800K CPU 上で上記のコードを動かしたところ、概ね3分くらいで処理が終わりました。ログが以下になります。
[n, m] loss: X という行が n 回目の epoch (データセットを使用する回数)、データセット内の m 個目のデータを学習した時点でのロス (誤差) を表します。学習が進むにつれロスがほぼ0に近づいていることが分かります。今回の非常に小さなネットワークモデルでも無事に学習ができています。
テスト精度 (accuracy) は最終的に 97.26% と十分高い精度を示しています。その次の行列は混同行列 (confusion_matrix) であり、 i 行 j 列の値が正解が i で推論結果が j であることを表します。今回のデータでは精度が十分なこともあり、特筆すべき偏りもなさそうな結果となりました。今回は一度で十分な精度が出ていますが、本来の開発では思った通りの精度が出なくて、ここでモデルや学習方法の見直しを行ったりします。
[1, 1000] loss: 1.765
[1, 2000] loss: 0.655
[1, 3000] loss: 0.475
...
[10, 1000] loss: 0.106
[10, 2000] loss: 0.101
[10, 3000] loss: 0.104
accuracy: 0.9726
confusion matrix:
[[ 973 0 1 0 0 2 0 2 2 0]
[ 0 1128 2 1 0 0 2 0 2 0]
[ 3 3 997 8 0 1 2 7 10 1]
[ 1 0 6 968 0 12 0 5 10 8]
[ 1 0 3 0 960 0 1 2 2 13]
[ 3 1 0 5 0 870 2 0 7 4]
[ 10 2 1 1 7 8 927 0 2 0]
[ 1 3 9 0 1 0 0 1006 1 7]
[ 5 1 1 12 4 3 3 8 927 10]
[ 5 6 0 3 10 1 0 10 4 970]]最後に、以下のコードでモデルの保存を行います。前者は PyTorch から再度評価をするためのモデルファイルで、後者は PyTorch の C++ API (libtorch) 上でネットワークモデルを読み出すために使用します。
# 5. モデルの保存
# PyTorchから普通に読み出すためのモデルファイル
torch.save(net.state_dict(), 'model.pt')
# libtorch (C++ API) から読み出すためのTorch Script Module を保存
example = torch.rand(1, 1, 28, 28)
traced_script_module = torch.jit.trace(net, example)
traced_script_module.save('traced_model.pt')まとめ
本記事では、MNIST データセットを学習用のターゲットとして、ネットワークモデルの作成及び学習・推論を行いました。
LeNet をベースとした軽量なネットワークモデルを使用し、MNIST データセットに対して十分な精度が達成できました。次回以降の記事では、このモデルを FPGA 上で動かすことを目標とし、高位合成まで見据えた C++ 実装を開始していきます。
本記事で使用したソースコード全体
この記事公開時点ではソースコードリポジトリはまだ公開されていないため、学習用コード全体を以下に記載します。
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from sklearn.metrics import accuracy_score, confusion_matrix
# 1. ネットワークモデルの定義
class Net(nn.Module):
def __init__(self, num_output_classes=10):
super(Net, self).__init__()
# 入力は28x28 のグレースケール画像 (チャネル数=1)
# 出力が8チャネルとなるような畳み込みを行う
self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=1)
# 活性化関数はReLU
self.relu1 = nn.ReLU(inplace=True)
# 画像を28x28から14x14に縮小する
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 4ch -> 8ch, 14x14 -> 7x7
self.conv2 = nn.Conv2d(in_channels=4, out_channels=8, kernel_size=3, padding=1)
self.relu2 = nn.ReLU(inplace=True)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全結合層
# 8chの7x7画像を1つのベクトルとみなし、要素数32のベクトルまで縮小
self.fc1 = nn.Linear(8 * 7 * 7, 32)
self.relu3 = nn.ReLU(inplace=True)
# 全結合層その2
# 出力クラス数まで縮小
self.fc2 = nn.Linear(32, num_output_classes)
def forward(self, x):
# 1層目の畳み込み
# 活性化関数 (activation) はReLU
x = self.conv1(x)
x = self.relu1(x)
# 縮小
x = self.pool1(x)
# 2層目+縮小
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
# フォーマット変換 (Batch, Ch, Height, Width) -> (Batch, Ch)
x = x.view(x.shape[0], -1)
# 全結合層
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
return x
net = Net()
# 2. データセットの読み出し法の定義
# MNIST の学習・テストデータの取得
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor())
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
# データの読み出し方法の定義
# 1stepの学習・テストごとに16枚ずつ画像を読みだす
trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=16, shuffle=False)
# ロス関数、最適化器の定義
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.0001)
# 3. 学習
# データセット内の全画像を10回使用するまでループ
for epoch in range(10):
running_loss = 0
# データセット内でループ
for i, data in enumerate(trainloader, 0):
# 入力バッチの読み込み (画像、正解ラベル)
inputs, labels = data
# 最適化器をゼロ初期化
optimizer.zero_grad()
# 入力画像をモデルに通して出力ラベルを取得
outputs = net(inputs)
# 正解との誤差の計算 + 誤差逆伝搬
loss = loss_func(outputs, labels)
loss.backward()
# 誤差を用いてモデルの最適化
optimizer.step()
running_loss += loss.item()
if i % 1000 == 999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
running_loss = 0.0
# 4. テスト
ans = []
pred = []
for i, data in enumerate(testloader, 0):
inputs, labels = data
outputs = net(inputs)
ans += labels.tolist()
pred += torch.argmax(outputs, 1).tolist()
print('accuracy:', accuracy_score(ans, pred))
print('confusion matrix:')
print(confusion_matrix(ans, pred))
# 5. モデルの保存
# PyTorchから普通に読み出すためのモデルファイル
torch.save(net.state_dict(), 'model.pt')
# libtorch (C++ API) から読み出すためのTorch Script Module を保存
example = torch.rand(1, 1, 28, 28)
traced_script_module = torch.jit.trace(net, example)
traced_script_module.save('traced_model.pt')株式会社フィックスターズ シニアエンジニア 松田裕貴