
みなさんこんにちは。この記事は、ACRi ブログの Deep Learning コースの第3回目です。
前回の記事では、MNIST データセットに対するネットワークモデルの作成・学習を行いました。この記事からは FPGA 上で推論処理を動かすために、まずは C++ で推論処理コードを記載していきます。
C++ 実装の初回のこの記事では、畳み込み層をターゲットに C++ 実装を始めます。具体的な内容は、(1) 畳み込み層の実装、(2) 動作確認 (C 検証、C/RTL 協調検証) です。
畳み込み層の実装
前回の記事で、畳み込み層は画像に対するフィルタ処理であると説明しましたが、入出力チャネルの扱いや、フィルタ処理時の画像の端処理などについては説明しませんでした。この記事では実装レベルの理解を目標とするので、これらの点を詳細に説明します。
入出力チャネルの扱い
画像処理においては、RGB 入力画像に対してノイズ除去などのフィルタリングをかけ、結果の RGB 画像を取得する処理を行うような処理が頻出します。この場合、畳み込み処理は各チャネル (R/G/B) に対して独立に行われることが多く、入力の G/B チャネルの値は出力の R チャネルの結果に影響しません。
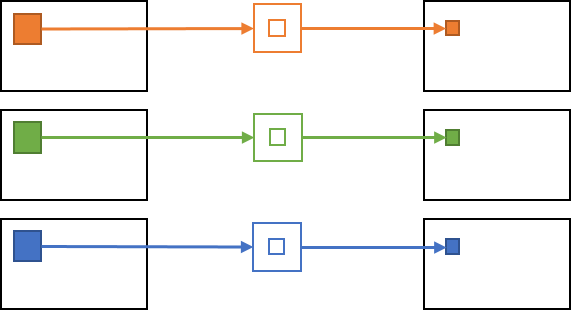
一方で、畳み込み層で行われる畳み込み処理では各出力チャネルに対して全ての入力チャネルの値が影響します。このため、出力画像の各画素 (出力チャネル, Y 座標, X 座標) に対して、全ての入力チャネル・周辺画素の領域が計算に参加することになり、非常に膨大な計算が行われます。
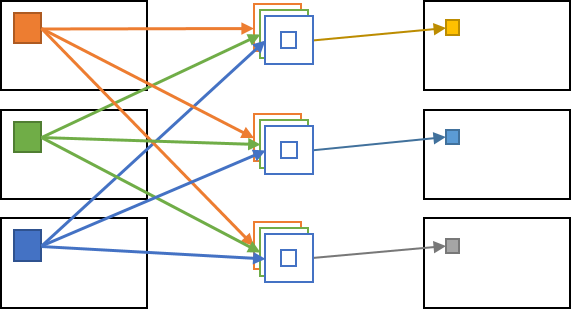
余談ですが、前述した各チャネルに対して独立な畳み込みが行われるような畳み込み層は Depthwise Convolution という名前で呼ばれます。
これは MobileNet 等の演算量を軽量化したネットワークモデルで多く使われます。
画像の端処理
画像に対して畳み込み処理を行う際に多くの場合で問題となるのが画像端の扱いです。
畳み込み処理ではある画素に対する計算でその周辺画素を使うため、画像端のピクセルのような周辺画素が存在しないピクセルにおいて、周辺画素が取得できなくなってしまいます。
畳み込みニューラルネットワークでは、主に以下の2つの方法で端画素に対する対応を行います。
- パディングなし: 出力画像を入力画像より畳み込み領域分だけ縮小した画像とする
- ゼロパディング: 予め入力画像を畳み込み領域分だけ拡大しその領域をゼロ埋めし、元の入力画像に対して畳み込み処理を行う
パディングなしの畳み込みを図示すると下のようになります。この場合だと出力画像は入力画像よりもフィルタサイズ分だけ小さい領域 (橙色部) になります。仮にカーネルサイズが3 (中心ピクセル+/-1) だとすると、画像の外側の1ピクセルが畳み込みできない領域となるため、出力画像サイズは幅、高さ共に-2となります。

次に、ゼロパディングを図示すると下図のようになります。この例だと、予め入力画像の外側に値0の領域を追加し (灰色部)、画面外アクセスが発生しないように畳み込みを行います。カーネルサイズが3の場合は、画面の外側に+1ピクセル分の値ゼロの領域が付与されるため、パディングありの入力画像サイズは幅、高さ共に+2となります。
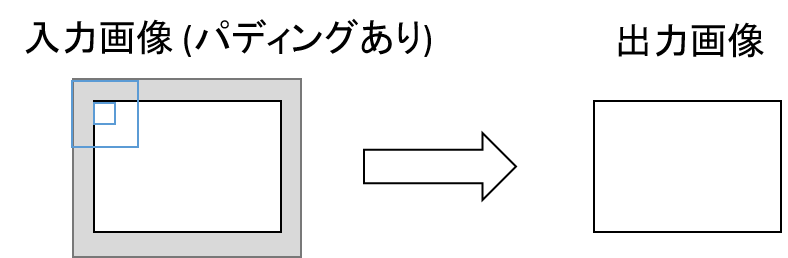
今回のモデルでは、全ての畳み込み層でゼロパディングを採用しています。
C コード
ここまでの説明を元に畳み込み処理を C で実装すると、下記のコードのようになります。
10 void conv2d(const float* x, const float* weight, const float* bias, int32_t width, int32_t height,
11 int32_t in_channels, int32_t out_channels, int32_t ksize, float* y) {
12 for (int32_t och = 0; och < out_channels; ++och) {
13 for (int32_t h = 0; h < height; ++h) {
14 for (int32_t w = 0; w < width; ++w) {
15 float sum = 0.f;
16
17 for (int32_t ich = 0; ich < in_channels; ++ich) {
18 for (int32_t kh = 0; kh < ksize; ++kh) {
19 for (int32_t kw = 0; kw < ksize; ++kw) {
20 int32_t ph = h + kh - ksize/2;
21 int32_t pw = w + kw - ksize/2;
22
23 // zero padding
24 if (ph < 0 || ph >= height || pw < 0 || pw >= width) {
25 continue;
26 }
27
28 int64_t pix_idx = (ich * height + ph) * width + pw;
29 int64_t weight_idx = ((och * in_channels + ich) * ksize + kh) * ksize + kw;
30
31 sum += x[pix_idx] * weight[weight_idx];
32 }
33 }
34 }
35
36 // add bias
37 sum += bias[och];
38
39 y[(och * height + h) * width + w] = sum;
40 }
41 }
42 }
43 }この関数のインターフェースは以下のようになります。
- 入力
x: 入力画像。shape=(in_channels, height, width)weight: 重み係数。shape=(out_channels, in_channels, ksize, ksize)bias: バイアス値。shape=(out_channels)
- 出力
y: 出力画像。shape=(out_channels, height, width)
- パラメータ:
width: 入力/出力画像の幅height: 入力/出力画像の高さin_channels: 入力画像のチャネル数out_channels: 出力画像のチャネル数ksize: カーネルサイズ
各入力/出力のメモリレイアウトはshape=(...) という形で示していますが、例えば x の場合はfloat x[in_channels][height][width]; のような3次元配列で定義されていると思えば良いです。
上記のように、畳み込み層の処理は6段のループとなります。最初の3段のループで出力画像上の位置を決定し、その後の3段ループでその位置に対する畳み込み演算を行っていきます。
ゼロパディングは、24-26行目で行われます。実際にゼロパディングした入力画像を作るのは効率が悪いため、画像外にアクセスする場合に積和に参加しないことでゼロパディングを実現しています。
31行が畳み込み処理内の積和演算部で、この積和演算は out_channels * height * width * in_channels * ksize * ksize 回行われます。この畳み込み処理の演算回数は非常に膨大であり、多くの場合で畳み込みニューラルネットワークの実行時間においては畳み込み層が支配的となります。このことが、CPU よりも多くの演算器を持つ GPU や FPGA がニューラルネットワークの処理に適している理由となります。
37行目がバイアス処理部です。バイアス処理が何なのかここまであまり触れてきませんでしたが、ここで書いているように単純に出力値に対してオフセットを与える処理となります。このバイアス処理は入力チャネル/カーネルサイズ (Y,X) のループ外となるため、処理回数としては非常に微々たるものです。
動作確認
前節で作成したconv2d 関数の動作確認として、PyTorch の C++ 用 API (libtorch) 上で行った畳み込み計算と十分に近い結果が得られるかどうか比較を行っていきます。
各テストは以下の2ステップで行っていきます。
- C 検証
- C/RTL 協調検証
1の C 検証は通常のソフトウェア開発と同様に gcc 等の一般的なコンパイラでソースコードをコンパイルし、結果を確認するだけです。
2の C/RTL 協調検証は、Xilinx の提供する高位合成ツールである Vivado HLS を用いた検証となります。この検証では、初めに Vivado HLS により C ソースコードが Verilog HDL 等の RTL に変換されます。その後、得られた RTL に対して Vivado 上で論理シミュレーションが行われます。
この論理シミュレーション上では作成した回路に対して C 検証と同じようなデータ系列を入力し、出力される結果が正しいかどうかの確認が行われます。
本節以降の内容は、作成済みのソースコードを動かす形式で説明していきます。
ソースコードは後日公開します。
動作環境
動作環境は Linux マシンを対象とします。Windows/Mac の OS はサポート外です。またプリインストールされている gcc のバージョンの都合上、ディストリビューションは Ubuntu 18.04 を対象とします。動作環境を個人で用意するのが難しい人は、後日公開予定の ACRi Room の FPGA 検証環境 (無料) をご検討ください。
ツール群としては以下のものが必要となります。
- Vivado >= 2019.2 (2019.2を推奨)
- cmake >= 3.11
cmake は apt 等のパッケージマネージャでインストールできるものよりも高いバージョンが必要なため面倒ですが、https://github.com/Kitware/CMake/releases よりビルド済みのバイナリ (cmake-\-Linux-x86_64.tar.gz) がダウンロードできます。
C 検証
テストコードは <dnn-kernel>/tests/ref/conv2d.cc を使用します。この記事では特に内容は触れませんが、テスト内容としては至って普通のランダムテストとなります。
コードのビルドは以下の手順で行えます。-DVIVADO_HLS_ROOT の値はインストールした Vivado のパスに適宜書き換えてください。
$ mkdir <dnn-kernel>/build
$ cd <dnn-kernel>/build
$ cmake .. -DVIVADO_HLS_ROOT=/tools/Xilinx/Vivado/2019.2
$ cmake --build .テストは次のコマンドで行います。エラーがなく終了すれば成功です。
$ ctest -V -R "conv2d_ref"C/RTL 協調検証
次のコマンドを実行すると、Vivado HLS による C/RTL 協調検証が始まります。
所要時間は5分程度です。
$ ctest -V -R "conv2d_hls_cosim"C/RTL 協調検証を行うと、Vivado HLS のプロジェクトファイルが自動で作成されるため、それを用いて高位合成の結果や RTL のシミュレーション波形などが確認できます。
これを確認するには、次のコマンドで Vivado HLS を立ち上げます。
$ vivado_hls &Vivado HLS が開いたら、以下の図のように “Open Project” をクリックし、<dnn-kernel>/build/tests/hls/conv2d/conv2d_hls_cosim までディレクトリを移動し OK をクリックします。
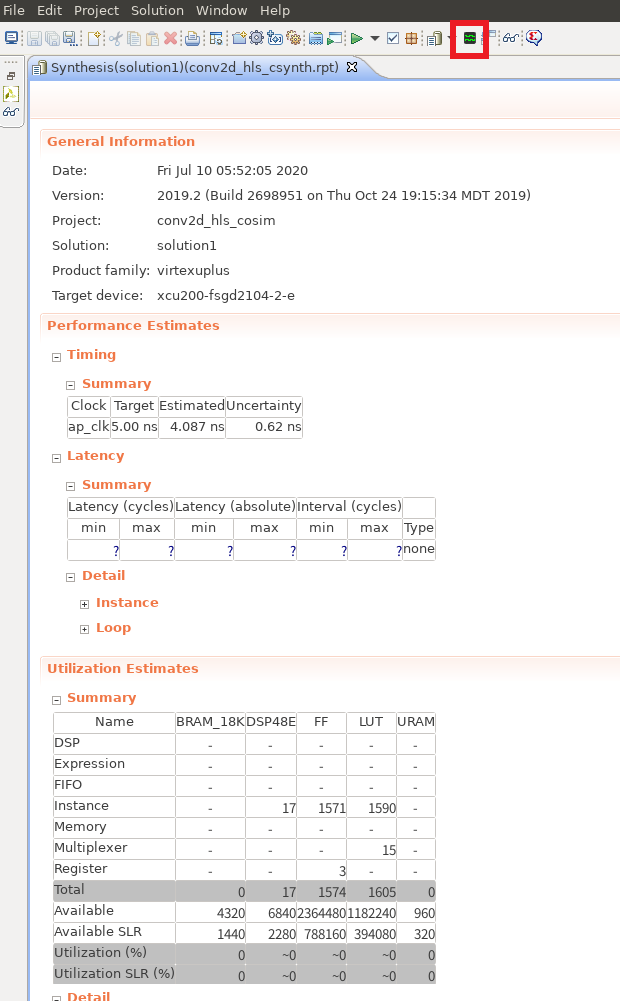
すると、以下の画面のように HLS の合成レポートが表示されます。
このレポートからは、Performance Estimates の欄から作成した回路の性能の推定値が見れたり、Utilization Estimates からターゲットデバイス (今回は Alveo U200) に実装時のリソース使用量の想定値などが見れたりします。
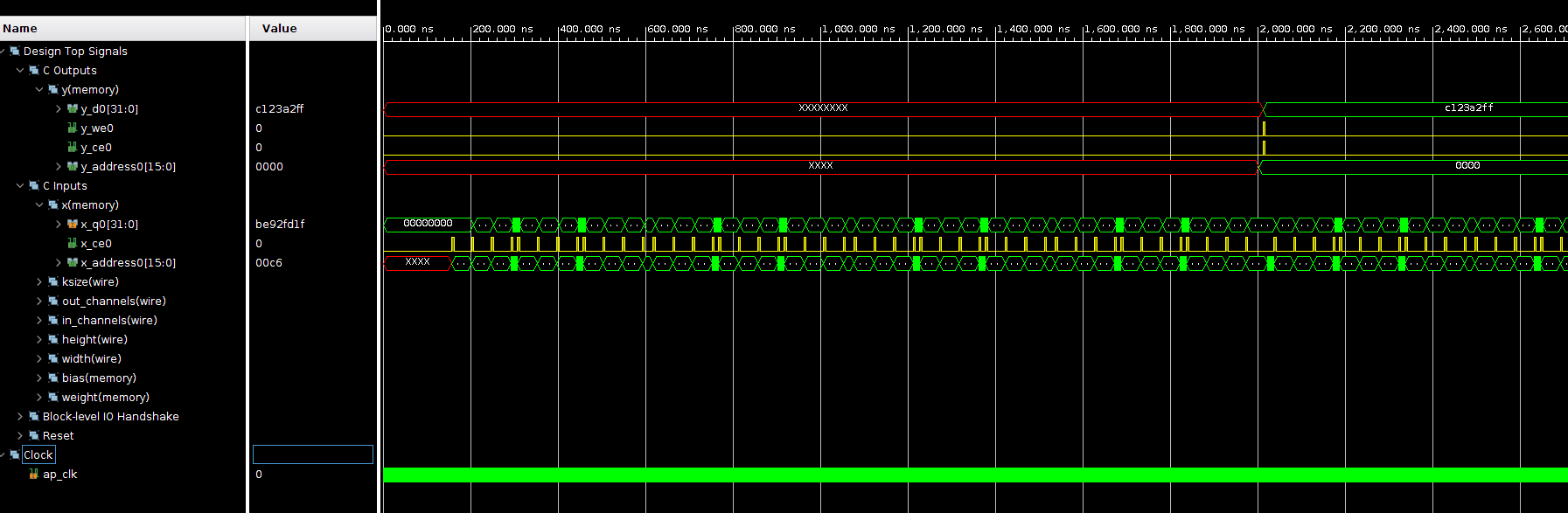
上部の赤枠で囲んでいる箇所をクリックすると、シミュレーションの波形が見れます。
波形は以下のようになり、なんとなく x の値が読めてそうなことや、大体 2,000.000 ns 秒あたりで y の1つめの値が出力できていることが読み取れます。
このように、特に HW を意識せずとも Vivado HLS により畳み込み層の計算を行う論理回路が作成できました。
ただし、この回路はチューニングを全く行っていないため CPU の方が圧倒的に速いようなデザインとなっています。実際の開発ではここで FPGA 向けに効率化された回路が作れるよう Vivado HLS に最適化指示を与えていくのですが、このコースではひとまず実機で動かすことを最優先としたいため、この時点では特にチューニングは行いません。
まとめ
この記事では畳み込み層を C++ で実装し、その動作確認をしました。また、この C++ 実装に対して Vivado HLS で高位合成をかけ、C/RTL 協調検証においても問題なく動作していることを確認しました。
次回の記事では残りの2層 (プーリング層・全結合層) と ReLU も同様に C++ で実装していきます。その後としては実装した層を結合して MNIST 用のモデルを作成・検証し、問題なければ実機での動作確認をしていく予定となります。
株式会社フィックスターズ シニアエンジニア 松田裕貴