21Q2.02A
21Q2.02ATVM を使ってディープラーニングを手軽に FPGA で高速化 (3)
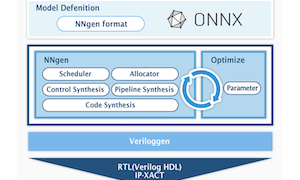
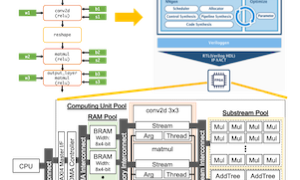
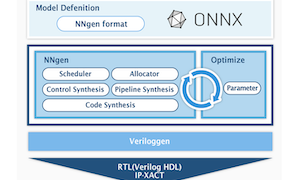
みなさんこんにちは。この記事は「TVM を使ってディープラーニングを手軽に FPGA で高速化」の第3回目です。前回に引き続き、今回は Xilinx Kria KV260 ボードでの TVM Vitis-AI Integration を動作させます。 Kria KV260 Xilinx Kria KV260 は Vision AI スターターキットとして販売される FPGA ボードであり、Xilinx が提供するビルド済みのAIアクセラレーションアプリを利用することができます。KV...