本連載は今回から、BRAM を用いたアプリケーションの一つとして、FIFO を扱うことにします。
はじめに
FIFO は First In First Out の略で、最初に書き込まれたデータが最初に読み出せる→データが書き込んだ順に読み出せる記憶機能、と考えることができます。何らかのデータを扱うアプリケーションにおいては、非常に便利な構成要素で、その記憶素子として BRAM を使うととても便利です。FIFO の記憶容量として RAMB36 が大きすぎてもったいない場合もありますが、筆者の経験からは RAMB36 が程よい大きさである場合が多く、大変重宝しています。
ベーシックな FIFO は非常に単純な構成を持つのですが、ある程度の設計経験者でも IP として生成した既製品を使用するケースが散見されます。もちろん機能的にそれで足りる場合は問題ないと思いますが、設計者にとって本当に欲しい機能を満たしてくれない場合もあるのではないかと思います。例えば、IP が提供する基本機能には問題ないが、I/O のタイミングに不都合があり、それをカバーするために別の回路要素を付加する、という回りくどい設計に陥っているケースを見たことがあります。FIFO そのものを要求する機能に合致させてしまえば、少なくともこうした回りくどさは排除できます。
本連載では、第2回と第3回を通して、FIFO の便利な使い方、基本的な構成法から初めて、応用的な構成法までを解説したいと思います。なお、第2回である今回では副題に「同期型」と記しましたが、書き込み側と読み出し側で同一クロックを使用した場合、と解釈してください。
FIFO が使われるアプリケーション
筆者が FIFO を使用する主だったアプリケーションは、以下の2点が圧倒的に多いです。もちろん他にも多くのケースがあると思いますが、以下の2点は、筆者が多く扱ってきたアプリケーションが信号処理系であったことに起因するかもしれません。
- データ処理系間の処理シーケンス緩衝
- データ処理系間のクロック乗り換え
2つのアプリケーションについて解説しておきましょう。FIFO を使用した経験がない方には、今後の設計に参考になるとうれしいです。
データ処理系間の処理シーケンス緩衝
データ処理系間の処理シーケンス緩衝は、2つの処理系が動作するシーケンスに対し、自由度を与えてくれるクッションのようなものです。2つの処理系が単純なパイプラインとして構成できるのであれば、FIFO は必要ありません。しかし、それぞれの都合で独自のデータ処理シーケンスを持つ場合、FIFO を間に挟むことで、2つの処理系の独立性が高くなり、接続に柔軟性が生まれ、設計、検証が簡易化されます。
例えば2つの処理系が、SDRAM のような1ポートメモリへの wr/rd を処理シーケンスに含んでいたとします。その場合、 wr と rd は同時に行えない、リフレッシュ中は wr も rd も行えないなど、処理シーケンスに制限が加わってきます。これが2つの処理系に適用されると、前段がデータを渡したい時間帯と後段がデータを受け取りたい時間帯を一致させることは、なかなか困難なことになります。ここで FIFO を処理系間に挟むと、前段はデータを渡したい時に FIFO に書き込み、後段はデータを受け取りたい時に FIFO から読み出す、といった互いに自由なシーケンスが実現できると同時に、メモリアドレスを意識する必要がありません。書き込み側は FIFO がいっぱいの時に書かないこと、読み出し側は FIFO が空の時に読まないこと、の2つのルールを守ればデータの授受は成立します。
データ処理系間のクロック乗り換え
データ処理系間のクロック乗り換えについては、2つの処理系が異なるクロックで動作している場合、必ず何らかの方法でクロック乗り換えをしてデータを授受する仕組みが必要になります。その際に使われる仕組みとして FIFO は最適です。
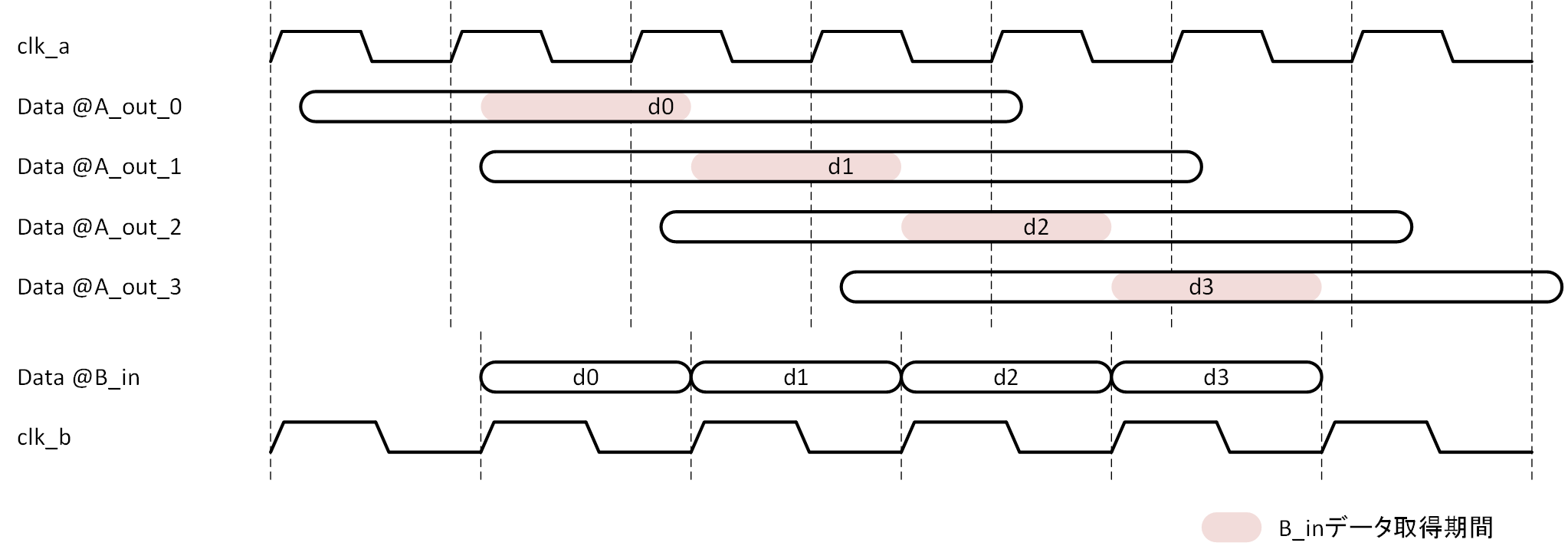
クロック同期回路を前提とし、2つの異なるクロック処理系間でデータを授受するモデルを考えてみましょう。その様子を図2-1に示します。データ送り側を A 、データ受け側を B とし、それぞれは異なるクロック clk_a 、clk_b の立ち上がりに同期して動作しているとします。A 系で生成されたデータは clk_a の立ち上がりに同期して確定し、これを B 系のデータ受け側は clk_b の立ち上がりで受け取ることが目的になります。1ビットのデータをストローブなしで A 系から B 系へ渡すだけでも、A 系出力の変化点に clk_b が立ち上がる場合には、メタステーブルが発生し問題となります。それでも、メタステーブルは長時間続く現象ではありませんから、入力レジスタを2段にするなどして回避可能です。
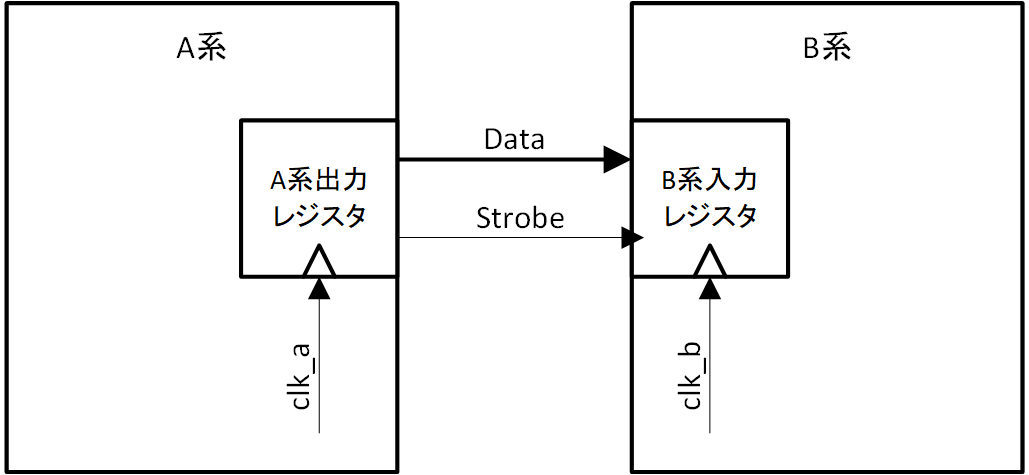
図2-1 A 系- B 系間のデータ授受モデル
しかし、多ビットデータの場合は状況が変わります (図2-1であれば、データ自体が1ビットでも、ストローブを合わせると2ビットと考えられます) 。A 系の出力レジスタが clk_a の立ち上がりに同期して確定しますが、clk_to_q (図2-2) の遅延に加えて B 系への配線遅延が加わるうえ、データが多ビットであればその遅延量はビットごとに異なります。つまり、B 系から見たデータとして、不確定な期間が発生するということです。その様子を図2-2に示します。
A_out は A 系の出力端における値、B_in は B 系の入力端における値を表し、データのビット幅を2ビットとして値が0から3に遷移した場合を示しています。実際には、値の遷移時間も発生しますし、clk_to_q もビット毎にばらつきますが、それらは無視し、かなり単純化して示しています。
B_in では配線遅延が加わったうえでデータが到達しますので、ビット毎に到着時刻が異なります。図2-2では、データが0から1時的に2に遷移し、最終的に3に遷移する様子を示しています。従って、clk_b の立ち上がり点が時刻1、2、3であった場合は、B_in におけるデータはそれぞれ0、2、3に見えてしまうということです。0と3は実際に発生した値ですので伝達されても問題ないとしても、2は実際にはない値ですので、この不確定期間に clk_b でデータを取り込んでしまうと、誤った値を B 系で受け取ったことになってしまいます。
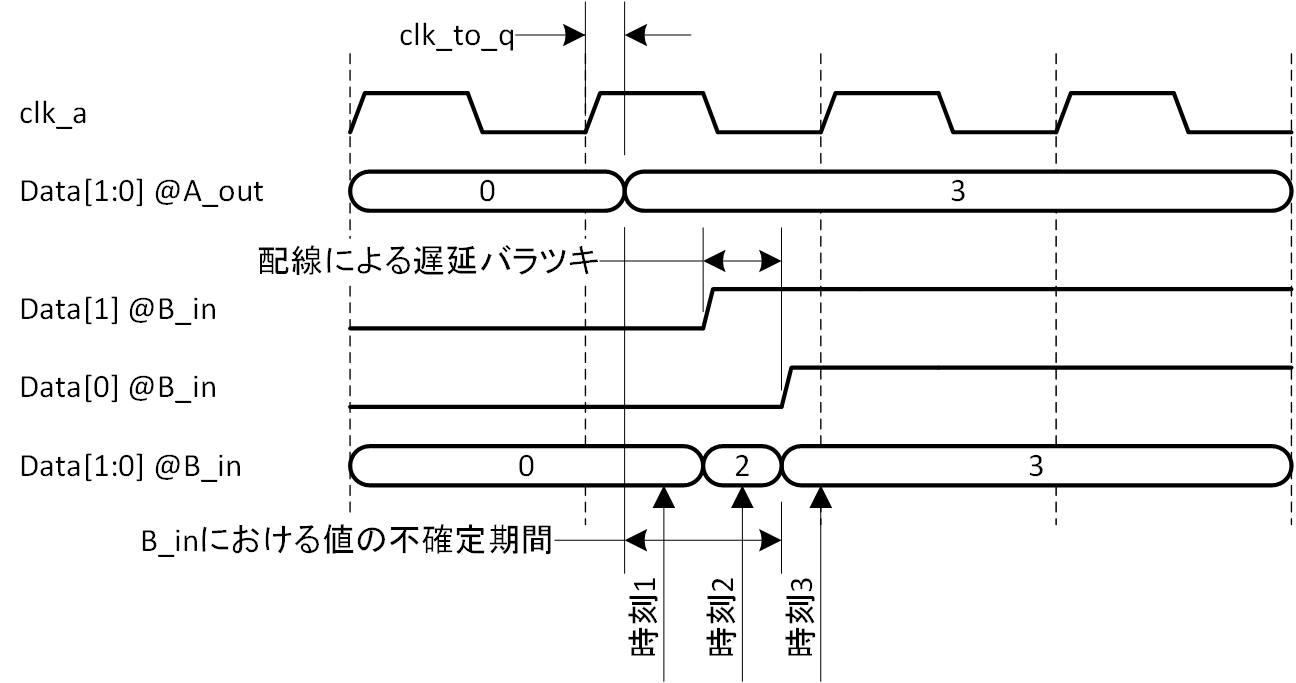
図2-2 データのストローブ点による値の不確定期間
問題は、A 系レジスタ出力の不確定期間に B 系が値を取り込むことにありますから、A 系出力レジスタの値が確定 (変化) した後、静的な状態となってから B 系でデータを受け取れば、そうした問題は発生しないことになります。つまり、意図的に A 系出力レジスタの値が静的な期間を作り、その期間 (strobe) を B 系に知らせてやれば、A 系- B 系間のデータの授受は可能になるわけです。図2-2でいえば、0から3への遷移が確実に終わった期間 (時刻3以降) にデータを受け取るということです。
ここで別の問題が発生します。B 系でデータを受け取れるように、A 系出力レジスタの値が静的な期間を十分長く取ろうとすると、どうしてもデータ授受の効率が落ちてしまうのです。なぜならば B 系でデータを受け取ったかを確認しなければ、A 系は次の値を出力レジスタに書き込むことができないからです。A 系出力レジスタの値確定→ B 系入力レジスタで値取得→ B 系での取得を A 系へ伝達、というステップを非同期クロック間で行うので、1データの授受に手間がかかるのは想像に難くないでしょう。図2-3にその例を示します。少なくとも A 系出力は clk_a の毎サイクルで値を更新することができません。クロックサイクルをできる限り有効に使いたいですから、これは大きなデメリットになります。
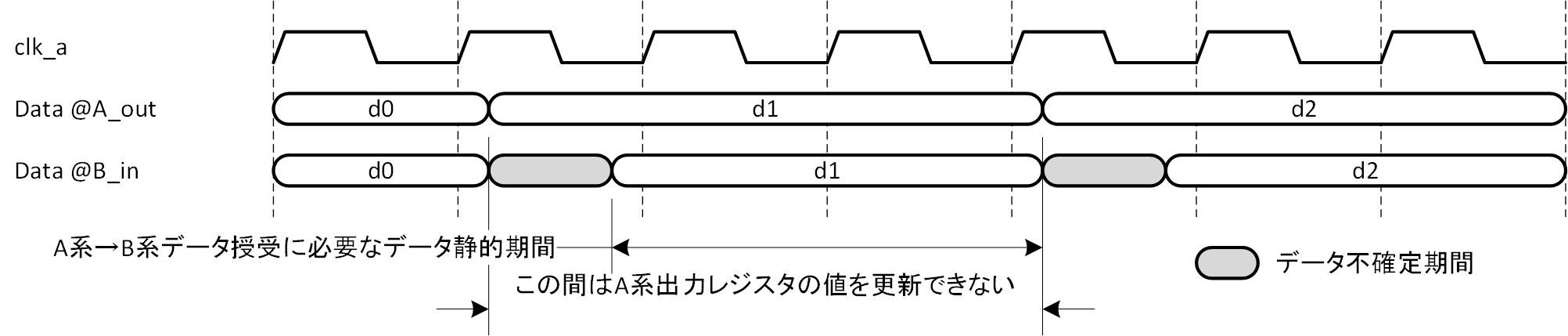
図2-3 A 系出力レジスタ値の静的期間を長くした場合のデータ授受効率低下
ここで A 系出力レジスタを複数用意して並列化し、新しい出力データを複数のレジスタに順次保存すれば、動的な状態にあるレジスタは限定され、静的期間にあるレジスタを複数得ることができます。静的期間にあるレジスタをのみ参照するように制御すれば、誤った値を授受することなく、先のデメリットは解消されます。その様子を図2-4に示します。A 系出力レジスタを0~3の4並列とし、B 系入力では4並列からマルチプレクスして1データを選択している様子です。A 系としては clk_a で毎サイクルデータを出力していることになりますので、図2-3にあった不都合は解消されています。
この機能は FIFO そのものです。先に書き込んだデータ→動的期間を過ぎて静的期間にあるデータ、と置換すればよいわけです。複数レジスタとデータをマルチプレクスする機能をメモリに置き換えれば、典型的な FIFO になります。
なお、データ処理系間のクロック乗り換え (書き込み側と読み出し側のクロックが異なる場合) については第3回で扱いますので、具体的な実現法についてはしばらくお待ちください。今回は、異なるクロック処理系間でデータを授受するのはとても面倒なことだ、とだけ理解してください。
以上を踏まえて、FIFO の基本構成を考えてみましょう。
FIFO の基本構成 (同期型)
繰り返しになりますが、今回は FIFO 構成の考え方を単純にするため、書き込み側と読み出し側のクロックを同じもの (同期型) とします。
FIFO の基本構成は実に簡単で、データを保持する記憶素子 (メモリ)、書き込みアドレス生成用カウンタ、読み出しアドレス生成用カウンタ、の3つがあれば構成できます。
記憶素子としては、先の説明にあるように複数のレジスタでも可能ですが、メモリを用いるのが一般的です。メモリとしては、FPGA 内に求めるならば、 Distributed RAM、BRAM 、URAM などが候補になると思いますが、本連載においては BRAM とします。巨大な容量の FIFO が必要であれば、FPGA の外にメモリ (SRAM、DRAM など) を配置して FIFO を構成することも可能です。
アドレス生成用カウンタとしては、インクリメント型のバイナリカウンタを使うことが一般的です。メモリは2のべき乗のアドレスを持つことが一般的ですから、2のべき乗の状態を生成できるカウンタが求められますし、First In First Out となるためには書き込み用、読み出し用をインクリメント型としてそろえておくことが必要です。デクリメント型でも構いませんが、わざわざそうする理由はないと思います。バイナリカウンタは FPGA と相性がよく高速に構成できます。カウンタをインクリメントさせるには、書き込みイネーブル (wr_en) 、読み出しイネーブル (rd_en) が制御要素として必要になります。
書き込み側の機能
書き込み側の機能を単独で考えます。書き込み側のアドレス生成用にインクリメント型のバイナリカウンタが用意されていて、アドレスが n を指しているとすれば、ここで wr_en をアサートすることでアドレス n にデータを書き込むことができます。同時に wr_en で書き込み側アドレスカウンタをインクリメントすれば、アドレスは n+1 となり、次にアドレス n+1 に書き込む準備が完了します。
このシーケンスを図2-5に示します。wr_ad は書き込みアドレス、wr_dt は書き込みデータ、mem[n] はアドレス n のメモリセルの内容を示しています。
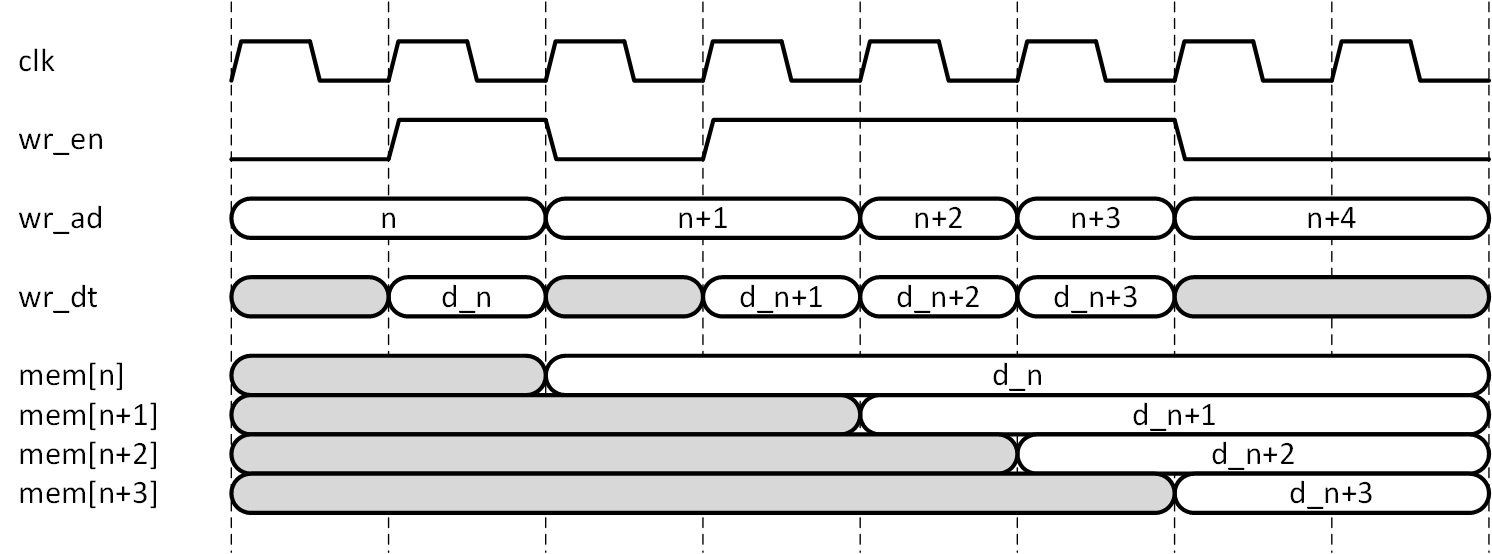
図2-5 FIFO の書き込み側機能
読み出し側機能
読み出し側の機能も、アドレスカウンタの動作は同様で、rd_en によってアドレスカウンタが自動的にインクリメントし、与えられたアドレスに従ってメモリの内容が読み出されます。
このシーケンスを図2-6に示します。図では読み出しレイテンシを1とし、rd_ad は読み出しアドレス、rd_dt は読み出しデータを表しています。
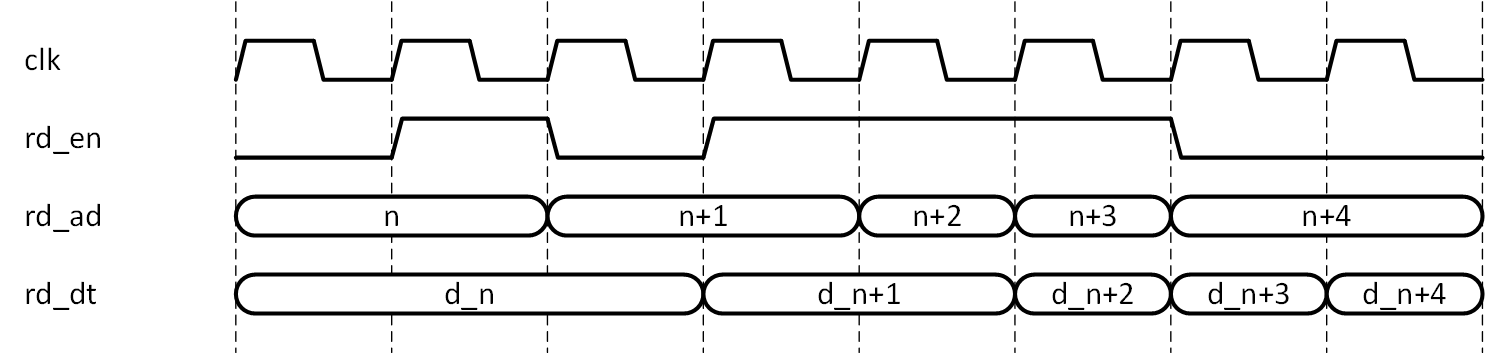
図2-6 FIFO の読み出し側機能
ここで重要なのは、書き込み側と読み出し側でメモリの内容は共有されますが、それ以外は完全に独立であるということです。だからこそ、書き込み側と読み出し側のクロックが異なっていても、機能が成立するわけです。
さらに必要な機能
3つの要素で基本的に FIFO は構成できますが、実はそれだけではとても不便です。「データが書き込んだ順に読み出せる記憶機能」を実現する仕組みが必要なのです。一般的に、FIFO に書き込んだデータが全て必要なものであれば、全て読み出して使いたいですし、使い終わった古いデータを再度使ってしまうことは避けなければなりません (記憶素子がメモリであれば、読み終わってもデータはメモリ上に残っているので、使用済みデータでも再度読めてしまう)。言い換えれば、
- 未使用のデータでメモリが埋まっている場合は、これ以上の書き込みは未使用データの上書きとなり、上書きされたデータは未使用のまま消失する。
- 使用済みのデータでメモリが埋まっている場合は、ここからさらに読み出しを行うと使用済みデータを再度読み出してしまう。
という事態を避けるために、書き込み許可情報 (wr_rdy) を書き込み側へ、読み出し許可情報 (rd_rdy) を読み出し側へ与えることが求められます。それらの情報は「メモリ上にどれだけのデータが未使用で蓄積されているか」によって生成され、未使用データの蓄積量は「書き込みアドレスと読み出しアドレスの差」で演算されます。もちろん、書き込み側、読み出し側で、そうした情報を生成する仕組みが用意できれば、FIFO 側で生成する必要はありませんが、FIFO 内で手に入るアドレスの差分を用いて情報を提供できれば、便利であることは間違いありません。
ここで、データ蓄積量 (アドレス差分) としてありうる状態数を考えます。アドレスのビット幅を Bw_a としたとき、メモリが空あるいは使用済みデータしか残っていなければデータ蓄積量は0、未使用データで埋まっていればデータ蓄積量は 2**Bw_a となりますので、取りうる状態数は (2**Bw_a)+1 になります。従って、0 ≦アドレス差分≦ 2**Bw_a が成立しなければ FIFO して正常に動作していないことになり、これが成立するよう、書き込み側、読み出し側の制御が必要です。言い換えれば「書き込みアドレスと読み出しアドレスが適切な距離を保ち、追い越したり追い越されたりしない」ことが、FIFO を正常に使用するうえで重要な条件になります。
FIFO を構成する
以上をふまえて FIFO の基本構成を、ブロック図として図2-7に示します。Xilinx では、RAMB36 を用いた FIFO36 をビルトイン FIFO として提供しています。これは UG573 に説明があり、図1-20には FIFO の概略図が掲載されています。図2-7はそれと同様の構成となっていることを確認してください。同一機能を実現しようとしているので、当たり前なのですが。ビルトイン FIFO については、後に説明を加えます。
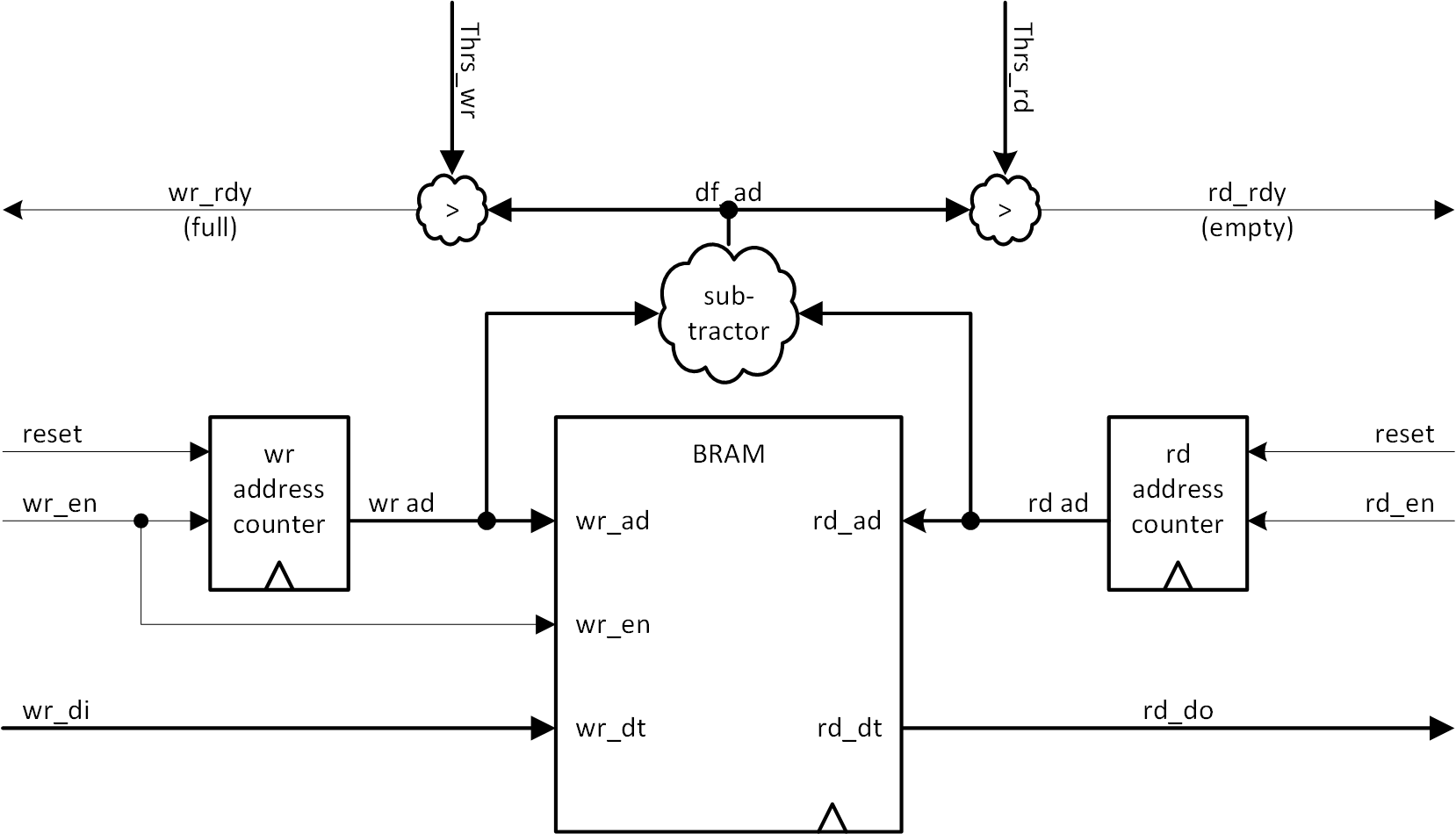
図2-7 FIFO の基本構成
list 2-1 に図2-7に基づいたサンプルコード (ss_fifo_sync.v) を示します。筆者なりの設計ですので、若干説明を加えておきましょう。記述そのものよりは、考え方を拾ってください。
module ss_fifo_sync (
wr_rdy , // buffer write ready
rd_rdy , // buffer read ready
rd_do , // read data out
wr_di , // write data in
wr_en , // write enable
rd_en , // read enable
clk , // clock
reset ); // sync reset ( h active )
parameter Bw_d = 8 ;
parameter Bw_a = 10 ;
parameter Depth = ( 1 << Bw_a ) ;
parameter Thrs_wr= Depth/4*3 ; // for write ready
parameter Thrs_rd= Depth/4*1 ; // for read ready
input [Bw_d-1:00] wr_di ; // write data in
input wr_en ; // write enable
input rd_en ; // read enable
input clk ; // clock
input reset ; // sync reset ( h active )
output wr_rdy ; // buffer write ready
output rd_rdy ; // buffer read ready
output [Bw_d-1:00] rd_do ; // read data out
// wires & regs
reg [Bw_a:00] wr_ad ; // wr address
reg [Bw_a:00] rd_ad ; // rd address
wire [Bw_a:00] df_ad ; // address difference
reg [Bw_d-1:00] m_ary [0:Depth-1] ; // memory array
reg [Bw_d-1:00] rd_do ; // data output reg
// write pointer
always @( posedge clk ) begin
if ( reset ) wr_ad <= {(Bw_a+1){1'b0}} ;
else if ( wr_en ) wr_ad <= wr_ad + 1'b1 ;
end
// read pointer
always @( posedge clk ) begin
if ( reset ) rd_ad <= {(Bw_a+1){1'h0}} ;
else if ( rd_en ) rd_ad <= rd_ad + 1'b1 ;
end
// occupancy
assign df_ad = wr_ad - rd_ad ;
assign wr_rdy = ~df_ad[Bw_a] & ( df_ad[Bw_a-1:00] <= Thrs_wr ) ;
assign rd_rdy = ~df_ad[Bw_a] & ( df_ad[Bw_a-1:00] >= Thrs_rd ) ;
// memory wr
always @( posedge clk ) begin
if ( wr_en ) m_ary[wr_ad[Bw_a-1:00]] <= wr_di ;
end
// memory rd
always @( posedge clk ) begin
rd_do <= m_ary[rd_ad[Bw_a-1:00]] ;
end
endmoduleアドレスカウンタのビット幅は、実際に必要とするアドレス幅を Bw_a とすれば、上位側に1ビット拡張し、Bw_a+1 としています。既に説明しましたが、アドレス差分として取りうる状態数は (2**Bw_a)+1 ですから、アドレス差分は Bw_a+1 ビットが必要であることは自明です。そのためにアドレスカウンタを1ビット拡張していますが、メモリ量そのものが増えたわけではありませんから注意しましょう。アドレスとして使用するのは、アドレスカウンタの下位 Bw_a ビット分です。
先に示した条件式、0 ≦アドレス差分≦ 2**Bw_a 、を保持するために用意されているのが、wr_rdy (=not full)、rd_rdy (=not empty) の2つのステータスです。full は未使用のデータでメモリが埋まっている状態を示しますので、これ以上書き込みを行ってはいけないことになります。従って not full であるときに限って書き込みを行うよう、書き込み側が制御します。empty は使用済みのデータでメモリが埋まっている状態を示しますので、これ以上読み出しを行ってはいけません。従って not empty の時に限って読み出しを行うよう、読み出し側が制御します。こうして先の条件を保持することが可能になります。
図2-7では、full と empty を判断する閾値を Thrs_wr と Thrs_rd として示しています。これらの閾値は、例えば Thrs_rd であれば、必ずしも0 ( 完全に empty) である必要はありません。0より大きな値を適用することで「およそ empty 」という状態を得ることもできます。複数のコンパレータに異なる閾値を適用して、制御に変化を持たせることも可能ですし、アドレス差分 (df_ad) を引数として、何らかの関数により連続的に制御を変化させる、なども面白いと思います。もちろん Thrs_wr についても同じことが言えます。
list 2-1では、 full と empty 出力にレジスタを介していません。これは full と emptyにより制御側が即反応できるように、レイテンシが発生しないよう考慮したものです。当然 full と empty には組み合わせ回路による遅延が発生しますので、クロック周波数が高い場合にはタイミング制約に不利に働きますので、注意しましょう。あえてレジスタを介した出力とすることも可能ですが、その場合はレイテンシの発生により制御が変わることを考える必要があります。例えば、「完全に full 」がレイテンシ1で書き込み側に伝達された場合には、書き込みを止めるタイミングが1クロック遅れますので、その間にもう1データ書き込んでしまい制御が破綻する、といったことがないように設計に配慮が必要ということです。「およそ full 」で回避できますね。
ちょっと工夫してみましょう
例えば、以下のような「およそ full 」の使い方はどうでしょうか。図2-8を見てください。
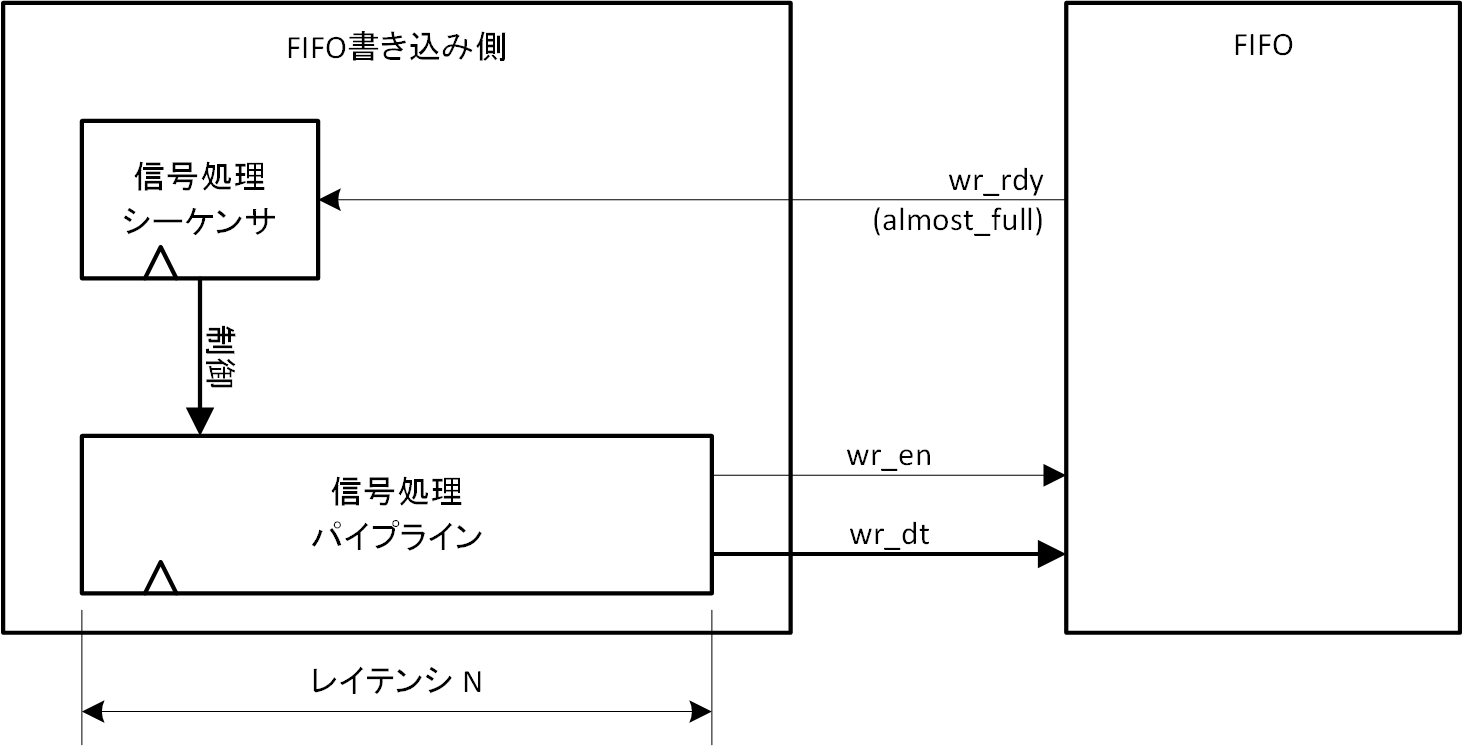
図2-8 およそ full の使い方例
FIFO 書き込み側には信号処理パイプラインと、これを制御するシーケンサがあるとします。FIFO は自身のデータ蓄積量から wr_rdy を生成し、シーケンサに与えて FIFO のオーバーフローを防ぐように制御する構成です。もし wr_rdy が「完全に full 」を条件とするものであるとすると、シーケンサが止まったとしても、パイプライン上にあるデータは垂れ流しで FIFO にやってきますので、FIFO のオーバーフローを止めることはできません。もちろん、wr_rdy でパイプラインレジスタをすべて止めてしまえば問題はないのですが、その場合 wr_rdy のファンアウトが大きくなってしまい、タイミング制約に不利に働きます。この時に Thrs_wr を「完全に full 」からレイテンシ N 分だけ少ない値とし「およそ full 」とすれば、パイプライン上にあるデータが垂れ流しで FIFO にやってきても、オーバーフローを起こさずに制御可能になります。
「およそ empty 」の使い方として、次のような応用もできると思います (empty と呼べるか疑問は残りますが ) 。図2-9にその例を示します。
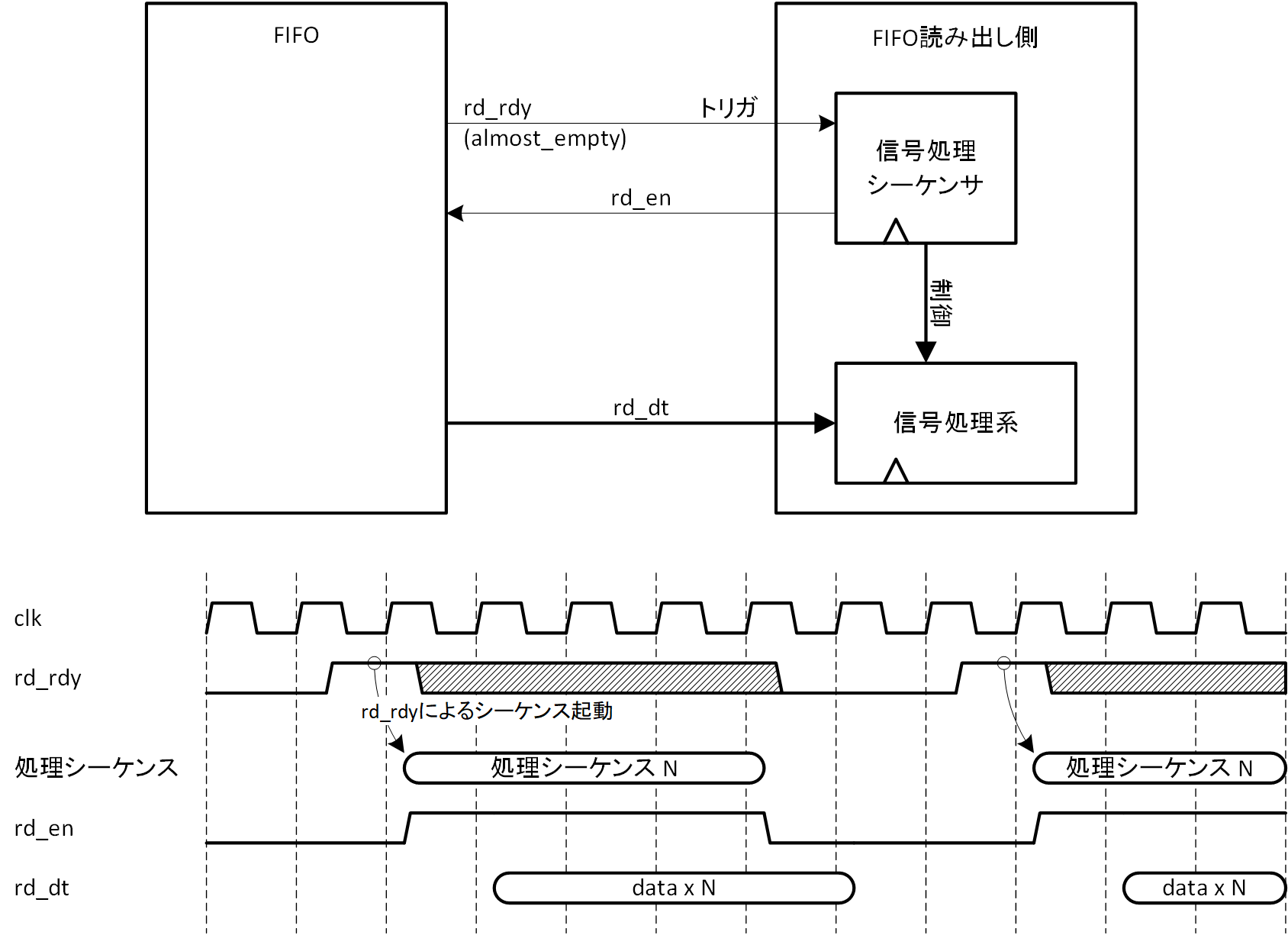
図2-9 およそ empty の使い方例
FIFO 読み出し側が一定量のデータ (図中ではデータ数を N としている) について連続的に処理するシーケンスを持っているとします。そのような場合には、Thrs_rd をそのデータ数 N に合わせ「およそ empty 」の判断を行い、rd_rdy をシーケンスの起動トリガとして使うというものです。
rd_rdy がアサートされたということは、FIFO 中に N 個のデータがあることは間違いないわけですから、迷いなく N データを読み出して構わないわけで、処理シーケンス中は rd_rdy を参照する必要がありません。逆に「完全に empty」を参照する読み出しシーケンスを前提としてしまうと、常に rd_rdy を参照することになりますので、いざ「完全に empty」となった場合にはデータの間欠動作を保証するシーケンサが必要になります。元が複雑なシーケンスの場合には、より複雑化することになり案外面倒です。「およそ empty」方式とすれば、rd_rdy を参照してシーケンスを起動する、を繰り返すだけで済みますので、考え方としては単純です。rd_rdy にレジスタが介してあっても、N データが読み出せるという事実に変わりがありませんので、問題なく制御が可能です。
full と empty を判断する閾値を Thrs_wr と Thrs_rd を操作し「およそfull」、「およそ empty」とすることで、制御の幅が広がる例を示しました。ここまでの説明では、Thrs_wr と Thrs_rd は parameter で与えられるような固定値で考えていますが、これらを変数として扱えば、閾値を動的に変化させることも可能になり、面白い制御が期待できそうなのは既に述べたとおりです。
Xilinx が提供する IP
既に触れましたが、Xilinx は BRAM を FIFO として使用できるよう、ビルトイン FIFO を提供しています。プリミティブとしては FIFO36 という名前で、UltraScale であれば FIFO36E2 になります。以下ではビルトイン FIFO を FIFO36 と呼称することにします。
FIFO36 の良いところは何といっても、RAMB36 に FIFO として必要なメモリ機能以外の要素 (アドレスカウンタ、full,empty 生成部など) を専用回路として持っている、ということに尽きると思います。CLB を用いてそうした FIFO 特有の部分を別途生成しなくて済みますので、回路リソースの節約になることもさることながら、そうした部分との配線も RAMB36 内に持てますので配置の影響を受けることがなく、配線遅延を規定値かつ小さな値にすることができます。タイミング制約の収束に十分配慮されているわけです。また、RAMB36 のカスケード機能がそのまま使えますので、FIFO 容量の拡張も容易に対応できますし、オプションの出力レジスタを使用すればタイミング制約に有効であることも変わりません。うまく使えば、至れり尽くせりということです。
FIFO として FIFO36 使おうとするならば、正しい理解を得るために必ず UG573 のビルトイン FIFO の記述を読んでください。まずは I/O ポートと属性を把握するのがよいでしょう。属性は静的に制御できるパラメータで、I/O ポートは動的に入出力可能な信号になります。RAMB36 と同様、かなりいろいろな使い方ができるように工夫されていますが、FIFO としての機能に特化したためか、個人的には RAMB36 よりシンプルなように感じます。属性が少ないので、少し気が楽です。
FIFO36 理解のポイント
ここでは、筆者なりのポイントをいくつか説明しましょう。
理解する上でのポイントは、数多くある I/O や属性を機能別に把握することだと思います。機能分類 (主たる FIFO 機能ではなく、付帯的機能とでもいうべき) として、筆者は以下の5つを意識することをお勧めします。
- 同期型と非同期型の選択
- 標準モードと FWFT (First-Word Fall-Through) モードの選択
- full と empty フラグ
- カスケード接続
- レジスタモードの選択
同期型と非同期型は、本連載では書き込み側と読み出し側のクロックが共通か独立か、を指しています。これは FIFO を使用するアプリケーションに応じて選択される機能ですので、筆者が決めるものではないのですが、今回は話を同期型に限定していますので、まずは同期型を選択しましょう。FIFO がとても理解しやすくなります。非同期型については第3回で扱います。FIFO36E2 では、CLOCK_DOMAINS という属性で COMMON/INDEPENDENT を選択することで制御できます。このあたりは RAMB36E2 と同じです。
標準モードと FWFT モードについては、まず標準モードでの動作を理解すればよいと考えます。FWFT モードとは、空の FIFO に最初のデータを書き込んだ際、rd_en がアサートされなくてもそのデータが出力に現れるという機能で、メモリを介さずデータが筒抜けになる機能です。それに対し標準モードは、全てのデータは一度メモリを介し、rd_en のアサートで出力に現れる、というわかりやすい機能です。FWFT モードはやや特殊な機能ですので、必要になったら考えましょう。なお、RAMB36 に似たような制御として、Write-First/Read-First という属性がありましたが、FIFO36 にはありませんので、それとの干渉は考える必要はありません。
full と empty フラグとして、FULL、EMPTY、PROGFULL、PROGEMPTY の4つが用意されています。PROGFULL、PROGEMPTY は既に説明した「およそ full 」「およそ empty 」と同義ですので、説明の必要はないでしょう。その閾値は属性で与えられます。ポイントは各フラグのアサート/デアサートのタイミング (レイテンシ) に癖があるということです。とはいっても、都合の良し悪しを除外すれば、そういうものだと理解するだけですので、難しいものではないでしょう。
表2-1に同期型の場合のレイテンシを示します。非同期型は第3回で説明を加えます。
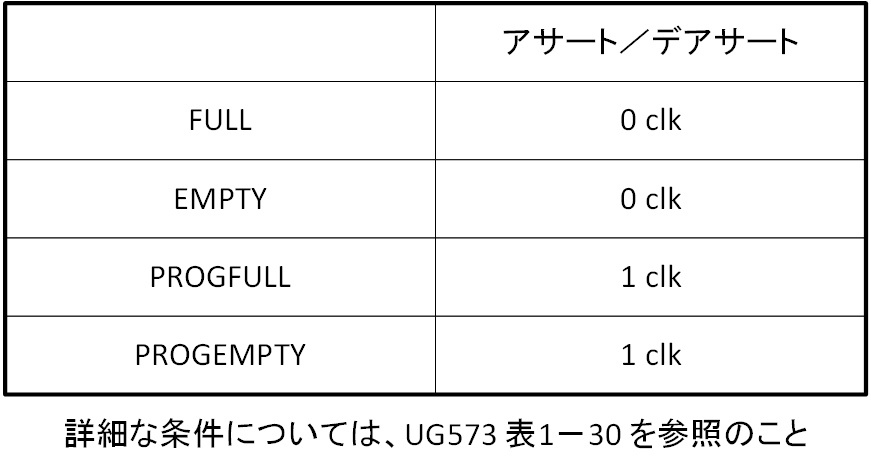
カスケード接続については、それに関与する I/O ポートと属性は独立したもので、I/O の接続方法も直列カスケード接続/並列カスケード接続の2者択一があるだけで、決まりきった接続となります。直列カスケード接続/並列カスケード接続は、いずれも FIFO の深さを拡張する際に使用する機能で、UG573 を参照してもらえれば、それほど難解なものではないと思います。まずは、カスケードなしで FIFO36 を理解し、必要に応じて機能を追加してはどうでしょうか。
出力段の構成については RAMB36 と全く同じですので、あえて言及するほどのものではありませんが、REGISTER_MODE という属性により制御できるようになっています。UNREGISTERED/REGISTERED でラッチモード/レジスタモードが選択できますので、 RAMB36 よりわかりやすいかと思います。
というわけで、一気に全体像を把握せず、上記5機能くらいに分けて使ってみると、わかりやすいと思います。すべての I/O と属性を RTL にインスタンス化してしまうと煩雑になるので、筆者は FIFO36E2 にラッパーを被せ、自分に必要な機能のみを制御できるように工夫しています。
RTL で FIFO を記述する
本連載の力の入れどころは、「ジェネリック表現を用いて RTL で FIFO を記述しよう」にあります。ここでいうジェネリック表現とは、論理合成可能な RTL 表現のことで、IP やプリミティブに頼らない記述法を指します。
FIFO36E2 についてわずかながらですが説明をしましたので、これを例にとって説明しましょう。list2-1との比較をすれば、一つの違いは full、empty の生成部ではないかと思います。list2-1における full、empty は、特定の閾値との比較で生成されていますので、FIFO36E2 の PROGFULL、PROGEMPTY にあたりますが、同期型であってもレイテンシが1あるというのは、場合によって不都合となる可能性があります。筆者としてはレイテンシ0のほうがありがたい場合が多いので、list2-1の形を多用する傾向にあります。ここはあくまで状況次第です。
また、図2-9で説明した読み出しシーケンスの起動トリガとして「およそ empty」を使用する際に、読み出しシーケンスのデータ数を可変にして、複数の異なるシーケンスを起動できると便利な場合があります。そのような場合に、閾値 Thrs_rd を動的に変化できれば簡単に実現できるわけですが、FIFO36E2 では閾値は属性扱いで静的なパラメータですので、その機能を望むことはできません。
以上、FIFO36E2 で実現できない2つのケースを示しましたが、設計者自身の手で記述されたジェネリック表現のRTLであれば、自由自在です。その場合、そのRTLに想定された論理合成がなされたか否かは設計者の自己責任ですから、検証は入念に行います。
ただ1点の大きな欠点は、ジェネリック表現で FIFO を記述した場合、メモリ以外の機能は RAMB36 の外部にある CLB のロジックリソースを使用して構成される可能性が高い、という点です。ですので、ロジックリソースを余分に必要とすると同時に、配線遅延は配置の影響を受けるうえに、遅延は増大する傾向にあるのは間違いありません。FIFOに必要なメモリ以外のロジックは大きなものではありませんので、ロジックリソース増分はたいしたことないとしても、遅延の増大はタイミング制約との相談になります。
勘違いされないように付け加えますが、本連載は IP やプリミティブを使用した設計を排除しようとしているわけではありません。IP やプリミティブで用が足り、デバイスのリターゲットもないなら、筆者としても迷いなくそれを選択します。ただ、用が足りなかった場合に、別の手段として選択できる力をつけておきましょう、ということを伝えたいと思います。
おわりに
今回は同期型の FIFO を事例とし、FIFO の構成に関する基本的な部分を押さえました。次の第3回では、非同期型に進みたいと思います。この記事で説明したクロック乗り換えに使用する FIFO の出番で、FIFO アプリケーションの醍醐味です。やや複雑な FIFO にならざるを得ませんが、設計者が手腕をふるえる範囲ともなります。お楽しみに。
エンジニア 鈴木昌治