愛知工業大学の藤枝です。2020年第2クォーター (20Q2) で担当したコース「IP の世界からこんにちは」で、AXI (Advanced Extensible Interface) の詳しいことはまた別の機会に……という話をしたのですが、案外早くその機会がやってきました。
このコースでは、AXI を使ってプロセッサと連携する高性能な計算回路や応用システムを設計するための基礎技術として、AXI の詳細とインタフェース変換回路の例、それらを使った計算回路の設計例について説明します。
特にこうした回路は、ハードウェアの Arm プロセッサを搭載した Zynq シリーズで大きな効果を発揮します。細々とした面倒な処理はプロセッサ上のソフトウェアに任せてしまって、本当に特化させたい部分に FPGA のハードウェア資源を使いましょう、ということです。そのため、このコースは Zynq-7000 を搭載した PYNQ-Z1、あるいはそれとほぼ同型の Arty Z7-20 を対象のボードとします。この記事の掲載時点 (2020年10月) では ACRi ルームでこれらのボードを使うことはできませんが、現在 PYNQ-Z1 ボードも ACRi ルームで使えるように準備中です。ご期待ください。
このコースで扱う内容は、これまで私が担当したコースと比べると少し高く (FPGA での設計にある程度慣れてきた人向け) なります。基本的なディジタル回路設計や IP コアの作成方法については、「シリアル通信で Hello, FPGA」および「IP の世界からこんにちは」を参照してください。
第1回では、Zynq の概要と内部接続について紹介した後、AXI の3種類のインタフェースについてそれぞれ説明します。
Zynq の構造と内部接続
Zynq の概要と基本構造
Zynq は、Xilinx 社が提供している FPGA と Arm プロセッサとをワンチップに搭載したシステムオンチップ (SoC) のブランドです。同様のチップはもう1つの FPGA 主要ベンダーである Intel (旧 Altera) からも提供されており、彼らはそうしたチップを FPGA SoC と呼んでいます。
Arm プロセッサは組込み用途ではメジャーなプロセッサですから、ちょっとしたアプリケーションだけではなく、OS として Linux を動作させることも可能です。これを利用して、Zynq 上に ubuntu と Python の実行環境 (Jupyter Notebook) を用意し、Python から FPGA を操作できるようにしたシステムが、「PYNQ を使って Python で手軽に FPGA を活用」のコースで紹介されていた PYNQ になります。
Zynq の基本的な内部構造を下図に示します。Zynq では、プロセッサ部分を Processing System (PS)、FPGA 部分を Programmable Logic (PL) とそれぞれよんでいます。
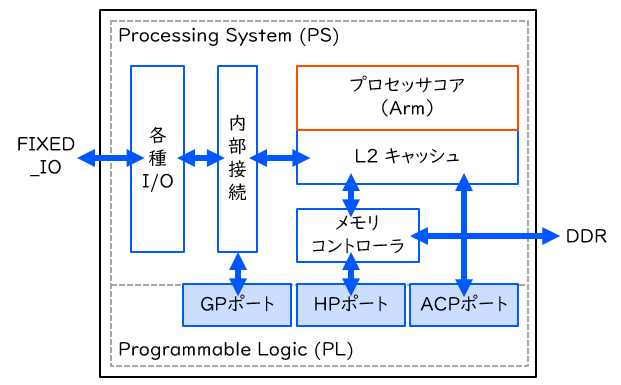
PS 側にはプロセッサコアと L2 キャッシュ、メモリコントローラ、各種の I/O コントローラが搭載されています。Zynq-7000 では、ローエンドの Z-7007S を除いて、プロセッサコアは Cortex-A9 のデュアルコアになっています (Z-7007S はシングルコア)。I/O コントローラには、シリアル通信 (UART)、SD カード、USB、Ethernet などのコントローラが含まれます。つまり、別途 PL 側にシリアル通信の回路を用意しなくても、PS 側で用意されたシリアルポートにアクセスできるようになっています。
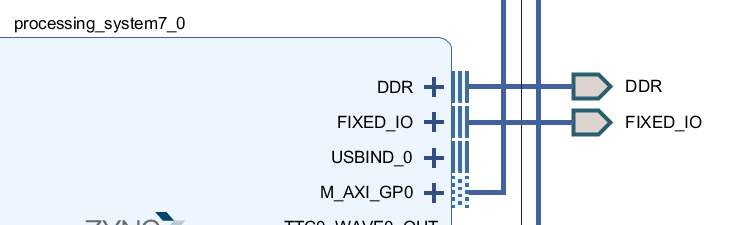
メモリコントローラと各種 I/O の入出力ポートは Vivado ではそれぞれ DDR と FIXED_IO という名前でまとめられています。実際、IP インテグレータ上で PS の IP コア (ZYNQ7 Processing System) を追加し、Run Block Automation を実行して初期設定を済ませると、DDR と FIXED_IO の2つのポートの存在が確認できます。この時の画面の例を下図に示します。
PS-PL 間の内部接続
先の図に示した通り、Zynq で PS-PL 間の通信を行うために、3種類の内部接続ポートが用意されています。それぞれ、GP (General Purpose) ポート、HP (High Performance) ポート、ACP (Accelerator Coherency) ポートとよびます。
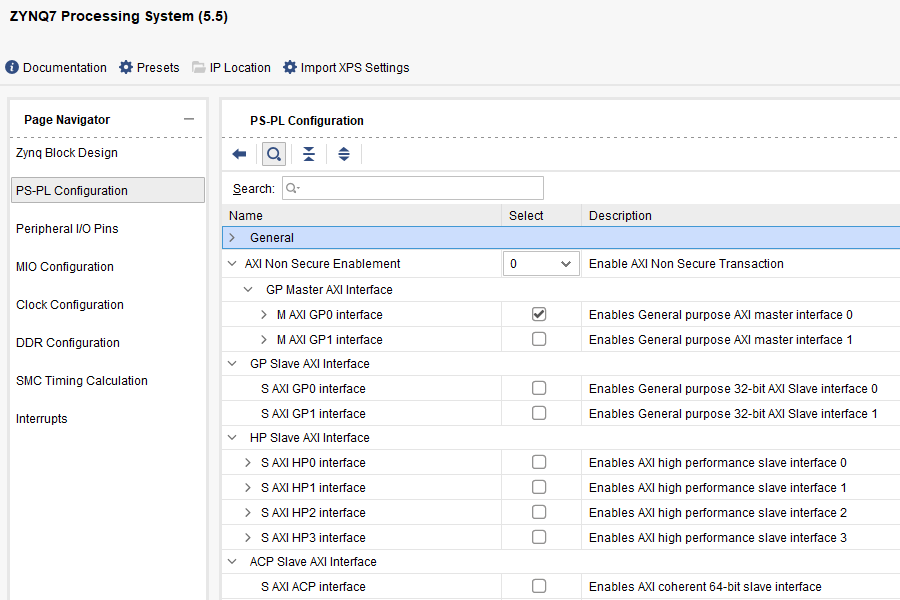
IP インテグレータで PS の IP コアを追加・初期設定した段階では、このうち GP ポートのマネージャ (PS 側がリクエストを発行する) が1つだけ有効になっています。もし他のポートも有効にしたければ、Run Block Automation が済んだ後、PS の IP コアをダブルクリックしてカスタマイズ画面を開き、PS-PL Configuration の項目から設定します。設定画面の例を下図に示します。追加したいポートのチェックボックスにチェックを入れると、そのポートが追加されます。
【2022-09-07追記】現在の AXI, AXI-Lite の最新仕様では、リクエストを発行する側をマネージャ (Manager, 上司)、受け取る側をサボーディネイト (Subordinate, 部下) とよぶようになっていますが、Vivado では従前のマスター (Master)、スレーブ (Slave) の用語を使用しています。これらの用語は、必要に応じて適宜読み替えてください。
GP ポートは、各種の I/O コントローラと同じように、PS の内部に接続されます。基本的には、メモリマップド I/O を用いた PS との制御や少量のデータ (引数や返り値など) のやりとりに使われることが多いです。PL 側の回路は典型的には PS 側からのリクエストを受けて動くように設計されるので、GP ポートのうち1つはデフォルトで有効になっているのです。
HP ポートは、PS 側のメモリコントローラを通じて主記憶 (DRAM) と接続され、PL から DRAM に高速アクセスする場合に用います。高速な計算回路を設計する場合や、PL が大容量の記憶領域を必要とする場合には、このポートを活用することになります。
ACP ポートは HP ポートに似ていますが、PS の L2 キャッシュコントローラに接続されます。HP ポートとは異なり、ACP ポートを通じたメモリへの読み書きは、L2 キャッシュとの一貫性 (コヒーレンシ) が維持されます。そのかわり、通信帯域は HP ポートと比べると一段低くなります。PS と PL との間で密な連携が必要な場合に使うことになるでしょう。
これらを踏まえると、典型的な PL 側の計算回路は AXI のマネージャ (リクエストを発行する側) とサボーディネイト (受ける側) のポートを1つずつ持つものになります。計算回路の IP コアのブロック図の例を下図に示します。

サボーディネイトのポートは GP ポートに接続され、PS 側からの制御の受けつけに使います。回路が必要とするデータは、HP ポートに接続されたマネージャのポートを使い、回路が自発的に (PS とは関係なく) 読み書きの要求を送って処理します。
AXI の3種類のインタフェース
Vivado では、AXI のインタフェースのうち AXI4-Lite、AXI4、AXI4-Stream の3種類がサポートされています。AXI4 の “4” は仕様のバージョンを表しますが、このコースでは以後省略します。
具体的な仕様は Arm 社により公開されています。AXI および AXI-Lite の仕様書の文書番号は IHI0022HC、AXI-Stream の文書番号は IHI0051B です。これらが Vivado や Xilinx 社の IP コアでどのように使われているかは、同社のドキュメントの文書番号 UG1037 に記載されています。
AXI-Lite
AXI-Lite については、「IP の世界からこんにちは (4)」でも簡単に紹介しました。以下に、AXI-Lite で必要な入出力信号をチャネルごとにグループ分けした図を再掲します。
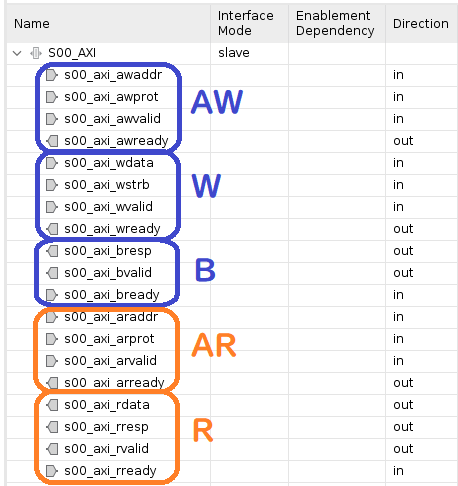
AXI-Lite を含め、AXI のクロックとリセットを除いた信号名は、チャネル名 + 信号の種類で名前付けされています。AXI-Lite では5種類のチャネルが存在します。書き込みのアドレス・データ・成否をそれぞれやりとりするのが AW・W・B チャネルであり、読み出しのアドレス・データ (成否を含む) をそれぞれやりとりするのが AR・R チャネルです。
AXI-Lite の各チャネルで必須となっている信号は以下のとおりです。
| 信号の種類 | チャネル | 概要 |
|---|---|---|
| valid | 全て | アドレスやデータ、結果を用意する側が、その準備ができたときに ‘1’ に設定します。 |
| ready | 全て | アドレスやデータ、結果を受け取る側が、その準備ができたときに ‘1’ に設定します。 |
| addr | AW, AR | 読み書きのアドレスを指定します。Address の略です。 |
| prot | AW, AR | メモリ保護のためのアクセス権限を指定します。Protection の略です。Xilinx は単に “000” とすることを推奨しています。 |
| data | W, R | 読み書きするデータを指定します。 |
| strb | W | 書き込みを有効にするかどうかをバイトごとに指定します。Strobe の略です。ワード全体に書き込む場合は、全てのビットを ‘1’ に指定します。 |
| resp | B, R | 読み書きの成否を指定します。成功したときは “00”、リクエストの受け側における何らかの要因で失敗したときは “10” に設定します。 |
AXI-Lite の信号波形の例を下図に示します。
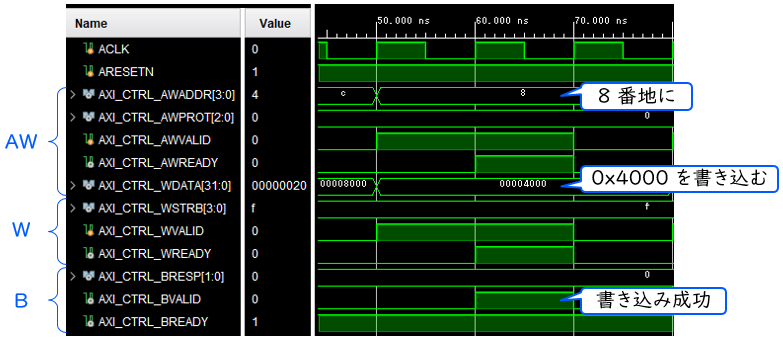
ここでは、アドレス 0x8 にデータ 0x4000 を書き込む場合を示しています。書き込みのリクエストが発生すると、AWVALID と WVALID の信号が ‘1’ になります。受け側はそれを確認して AWREADY, WREADY, BVALID を ‘1’ にして、書き込みを受けつけ、そして成功したことを通知しています。
AXI-Lite には、アドレスの転送とデータの転送とが必ず1対1で対応するという特徴があります。そのため制御が比較的簡単であり、制御や少量のデータのやりとりに向いています。
(フル機能の) AXI
フル機能の AXI もまた、AW・W・B・AR・R の5種類のチャネルを持ちます。フル機能の AXI では、AXI-Lite にはない様々な信号が追加されますが、特に重要なのは転送長を示す len (Length の略) です。len は8ビットで、実際の転送長 – 1 を指定することとなっています。これにより、1回のアドレスの転送あたり最大256ワード (len に 0xff = 255 を指定した場合) のデータ転送が可能になります。ただし、ページ境界 (4 KiB) をまたいだ転送はできません。
フル機能の AXI の信号波形の例を下図に示します。
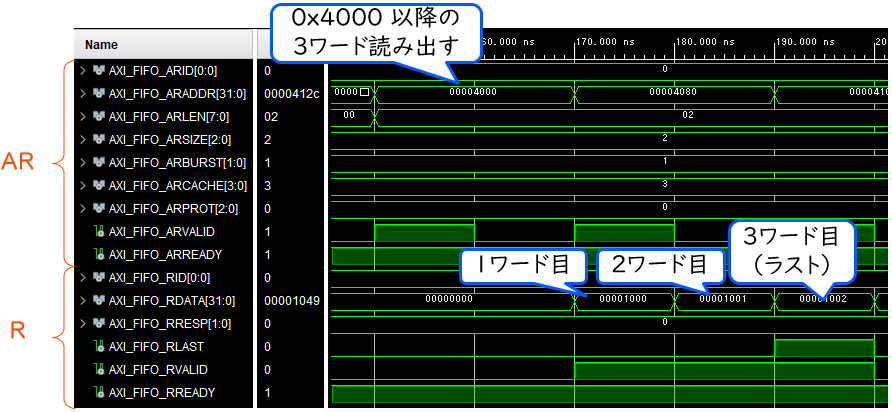
ここでは、アドレス 0x4000 以降の3ワードを読み出す場合を示しています。読み出しリクエストが受理された (ARVALID と ARREADY がともに ‘1’) あと、データの準備ができたところで RVALID が ‘1’ になっています。また、最後のデータを転送するときは、それが最後のデータであることを示す RLAST も同時に ‘1’ になっています。
なお、受け側が対応していれば、データの転送途中でも、次のリクエストを AW, AR チャネルから発行することができます。実際、上記の波形では、アドレス 0x4080 以降、 0x4100 以降への読み出しリクエストが、それぞれ先行して発行されています。もし受け側が対応していなければ、読み出しが完了するまで ARREADY は ‘1’ にはならず、次のリクエストは受理されません。
フル機能の AXI は、こうした機能を備えていることから、大量のデータ転送に向いています。ただし、全ての機能を扱おうとすると、制御はかなり複雑です。実際に使うときには、必要な機能を絞り込むほか、あらかじめインタフェース変換回路などを作っておいて、扱いが面倒な信号はそちらで生成するといった工夫が必要でしょう。
AXI-Stream
フル機能の AXI と同様に大量のデータ転送向けであり、なおかつ制御が簡単なインタフェースが、AXI-Stream です。AXI-Stream はトランスミッタ (データの送信側) とレシーバ (受信側) との間のデータ列の送受信に用いるもので、T というただ1つのチャネルをもちます。
【2022-09-07追記】AXI におけるマネージャ/サボーディネイトに対応する用語は、AXI-Stream の最新仕様ではトランスミッタ/レシーバになっています。過去には AXI と同様にマスター/スレーブが使用されていました。
T チャネルにおいて唯一必須である信号は TVALID です。TREADY も TSTRB も、それどころか TDATA すら (!) 必須ではなく、省略した場合の扱いが仕様で定められています。とはいえ、それではまともに IP コア同士を接続することはできませんから、相手側の IP コアの仕様、例えば信号やデータの解釈をよく確認した上で、適切に自身の IP コアを設計する必要があります。
また、AXI や AXI-Lite にあったチャネルがないということは、PS 側 (DRAM) とは直接接続できず、接続には変換のための IP コアが別に必要であるという意味でもあります。ただ、典型的なパターンであれば、既存の DMA (Direct Memory Access) IP コアなどを使い、読み書き対象のアドレスやデータの順序を適切に指定することで、その労力の削減が可能です。
以上の特徴から、AXI-Stream は同種の IP コア間でデータの送受信を行う場合や、 既存の DMA IP コアと組み合わせて DRAM を読み書きする場合など、データの送信順序がある程度固定できるときに活用されます。
まとめ
今回は、Zynq の概要と内部接続、および AXI のインタフェースの種類について説明しました。今回の要点は以下のとおりです。
- Zynq PL 上の典型的な計算回路では、GP ポートを通じて制御を受けつけ、HP ポートを通じて自発的に DRAM にアクセスする。
- 制御や少量のデータのやりとりには、AXI-Lite を利用する。
- 大量のデータのやりとりには、フル機能の AXI を利用する。ただし、データの送信順序がある程度固定できる場合は、AXI-Stream も利用できる場合がある。
次回は、今回紹介した AXI のインタフェースのうち AXI-Lite について、私が仕様をもとに書いたインタフェース回路の HDL 記述を使いながら、説明していきます。
愛知⼯業⼤学 藤枝直輝