はじめに
BRAM アプリケーションとして FIFO を扱っていますが、第2回では同期型 (書き込み側のクロックと読み出し側のクロックが同一の場合) を扱いました。今回は非同期型 (書き込み側のクロックと読み出し側のクロックが独立な場合) を扱います。
どうしたら非同期型の FIFO ができるか
まず、前回の基本構成を図3-1に示します。
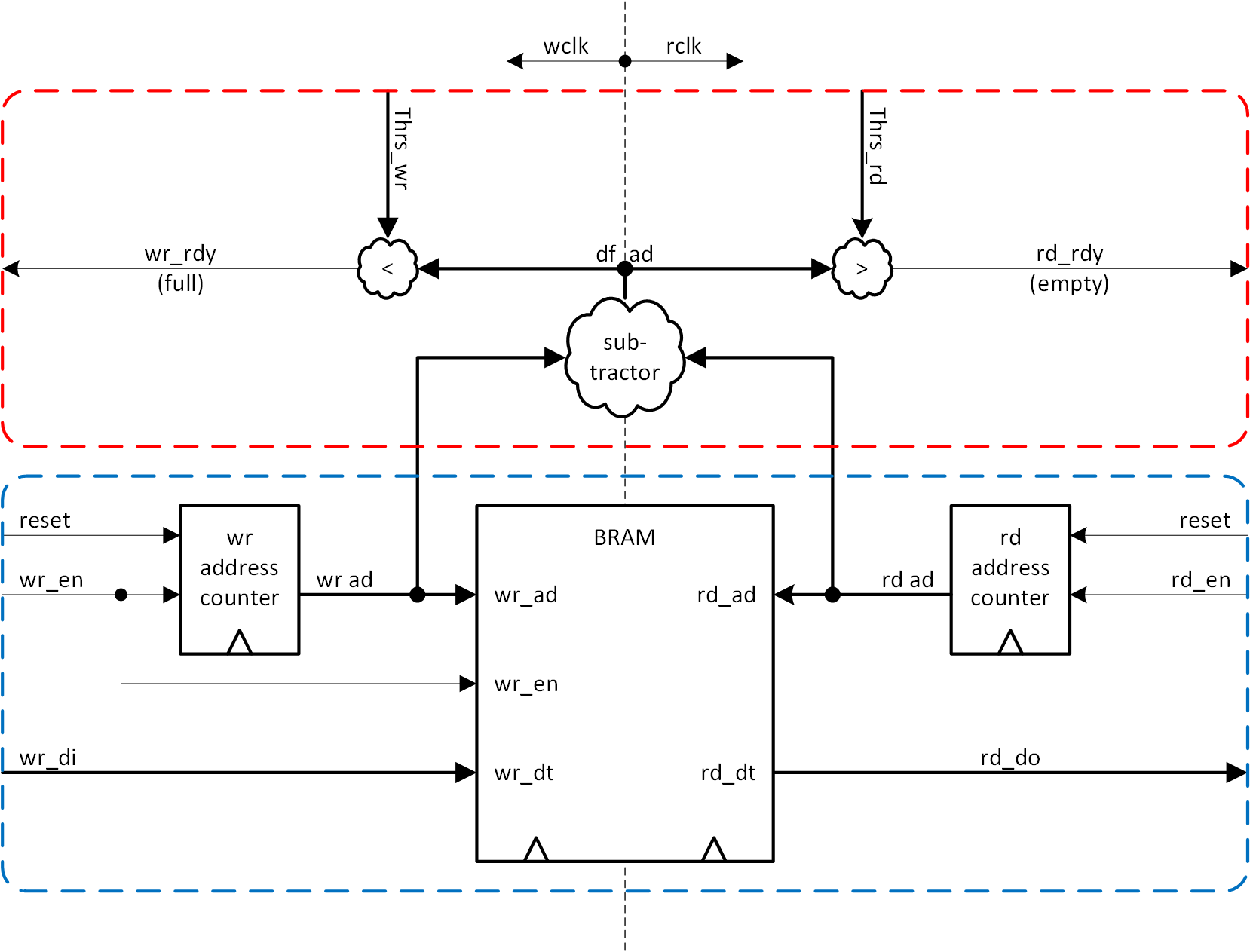
書き込みアドレスカウンタ、読み出しアドレスカウンタは独立したクロックで動作し、互いに干渉しないので、駆動するクロックをそれぞれ書き込み用、読み出し用のものにすり替えれば、機能的には問題ありません。そのうえで、メモリアレーに対し、書き込み側ポートに書き込み用クロック、読み出しポートに読み出し用クロックを供給すれば、メモリアレーへの書き込み、読み出しはできてしまいます。メモリアレーを挟んで、書き込みと読み出しの機能は独立しているからです。だからこそ、非同期クロック間のデータ授受ができるといえます。クロックをすり替えるだけで済んでしまう部分を、図3-1の青い破線内に示します。
しかし、書き込み許可情報 (wr_rdy) 、読み出し許可情報 (rd_rdy) の生成は、そうはいきません。いずれも書き込みアドレスと読み出しアドレスの差分で生成されるわけですが、それぞれが非同期クロックで生成されたものですので、直接差分演算を行うことができないからです。前回、非同期クロック系間のデータ授受はなかなか厄介で、FIFO を使って解決することをお話ししましたが、アドレスを一種のデータとみなせば、ここでも同じことが起きるわけです。問題の個所を図3-1の赤い破線内に示します。
例えば、wr_rdy は書き込み側の制御で使用するために生成するわけですから、書き込み側クロックに同期したステータスとして渡したいはずです。ですので、そのステータスを生成する差分演算では、書き込みアドレス、読み出しアドレス共に、書き込み側クロックに同期している必要がありますが、読み出しアドレスは読み出しクロックに同期して生成されています。従って、読み出しアドレスが静的な状態にあればまだしも、動的な状態にあれば、書き込み用クロック立ち上がりエッジでは、不確定な状態が発生することになります。rd_rdy についても同様の事情が発生します。
といって、アドレスの非同期クロック系間の授受に FIFO 使おうというのでは、FIFO 内で FIFO を使うことになり、そこでまた同じ問題が発生するわけですから、無限に FIFO を階層化することになってしまい、現実的ではないことはおわかりでしょう。
非同期クロック型 FIFO のブロック図を、図3-2に示します。今回は、非同期クロック系間のアドレス交換 ( 書き込みアドレスを読み出しクロック系へ、読み出しアドレスを書き込みクロック系へ ) が焦点になります。その部分を図3-2の赤い破線内に示します。アドレス交換が終わった状態で、それぞれのクロック系でクロック差分を演算しますので、差分演算が2系統になります。
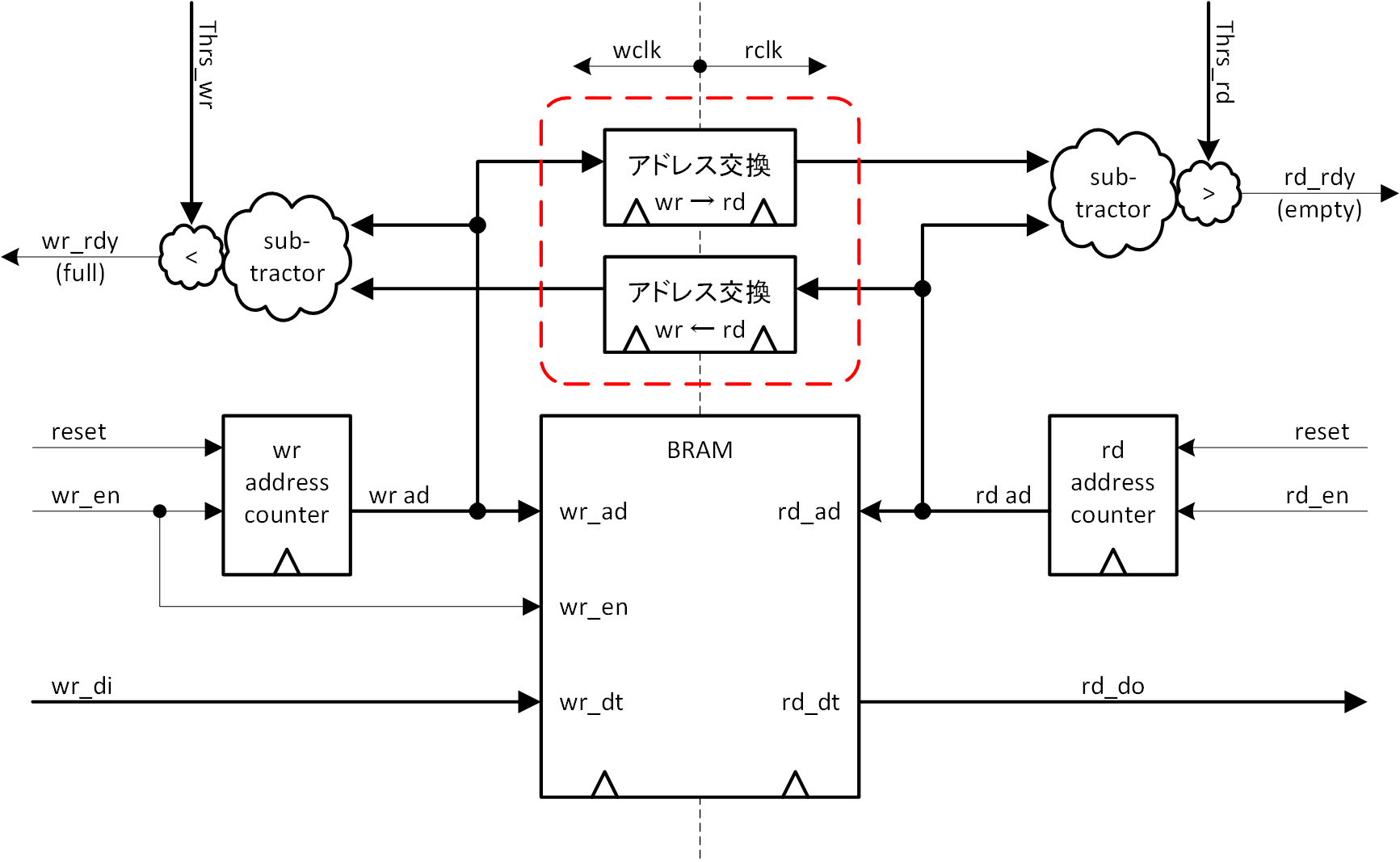
どうやってアドレス交換をするか
最初に、条件を整理
どうやってアドレス交換をするかを考えるわけですが、その前に、条件を整理しましょう。書き込み許可 (wr_rdy) 、読み出し許可 (rd_rdy) を、以下の通り定義します。
アドレス差分 = 書き込みアドレス - 読み出しアドレス 定義式1
wr_rdy = アドレス差分 < 書き込み側閾値 定義式2
rd_rdy = アドレス差分 > 読み出し側閾値 定義式3
その上で、FIFO の制御が成立する条件を以下の通りとします。
基本条件1:!wr_rdy の時は書き込まない
基本条件2:!rd_rdy の時は読み出さない
基本条件1 & 基本条件2 が、FIFO の制御成立の絶対条件となります。
書き込み側クロックと読み出し側クロックが非同期の場合を考えますが、全く無条件では設計が立ち行きませんし、説明も面倒ですので、本稿では以下の条件とします。
書き込み側クロック周波数: f_wclk
読み出し側クロック周波数: f_rclk
として、
クロック周波数条件: f_rclk < f_wclk < f_rclk*2
とします。例えば、f_wclk が f_rclk の1.5倍とかです。FIFO を適用するアプリケーションによって条件は変わると思いますので、その都度、条件に合わせた変更が必要になることを意識してください。
前回ではデータの静的期間を利用して、書き込み側クロックから読み出し側クロックへの乗り換えを行う仕組みを説明しました。基本的考え方としては同様で、アドレスの静的期間を狙ってアドレスの交換を行うことを考えます。
ところが、wr_rdy である限りできるだけ書き込みたい、rd_rdy である限りできるだけ読み出したいというのは、アプリケーションの都合として十分あり得ることで、その場合にはアドレスがインクリメントしている状態が続くことになり、静的期間を期待するのは難しくなります。アドレスの静的期間がないのではアドレス交換は望めないのですが、ここでは「アドレス交換はできるときにやることにして、アドレスカウンタがインクリメントするたびにアドレスを交換する必要はない」という方針で考えます。ずいぶん荒っぽい考え方に聞こえますが、できないことを期待しても仕方ありませんし、機能的には案外問題となりません。
何らかの方法 (具体的には後で説明します) でアドレスの静的期間を作るために、アドレス交換を間引くことになるわけですが、それがどう作用するかを考えてみましょう。例えば、wr_rdy を生成するために書き込み側で定義式1に従ってアドレス差分を演算する際、読み出しアドレスは非同期のクロック系から持って来なければなりませんが、ここで全てのアドレス交換をせずに間引いて持ってきたとします。情報としては常に最新のものが得られなくなりますので、読み出しアドレスの値としてはインクリメントが遅れ、小さくなる傾向にあるといえます。その場合、定義式1によりアドレス差分は大きくなることになりますので、定義式2に当てはめると、wr_rdy になりにくい方向に作用することがわかります。従って、より厳しい閾値を用いたかのような作用となりますが、FIFO の制御としてはより破綻しにくいことになりますので、問題を起こすことはないわけです (FIFOの深さの効率的利用に若干の障害にはなりますが) 。rd_rdy についても同様で、rd_rdy になりにくい傾向とはなりますが、問題を起こすことはありません。
アドレス交換法1
アドレスの変化を間引くことで静的期間を作り、アドレス交換をする、という方法の1例を紹介しましょう。もちろん、アドレスの変化を間引くために書き込みや読み出しを連続的にさせない (wr、rd 後の一定期間は wr_rdy、rd_rdy をデアサートするなど) のでは、間違いなく性能が劣化することになるので、そうした方法は採用しません。
この例では、アドレスの変化を間引くために、アドレスの下位桁を参照しない方法を採用します。例えば、アドレスの下位2桁を参照しないとすれば、下位2桁が0~3に変化する間に上位桁は変化しませんので、少なくとも4クロックサイクル間は上位桁が静的状態にあるといえます。下位桁を参照しない方法は、下位桁を0にマスクする、あるいは上位桁のみを参照する、いずれでもかまいません。こうしてできたアドレスの静的期間に、アドレス交換先のクロック系にアドレスを渡します。
その構成とシーケンスを図3-3に示します。
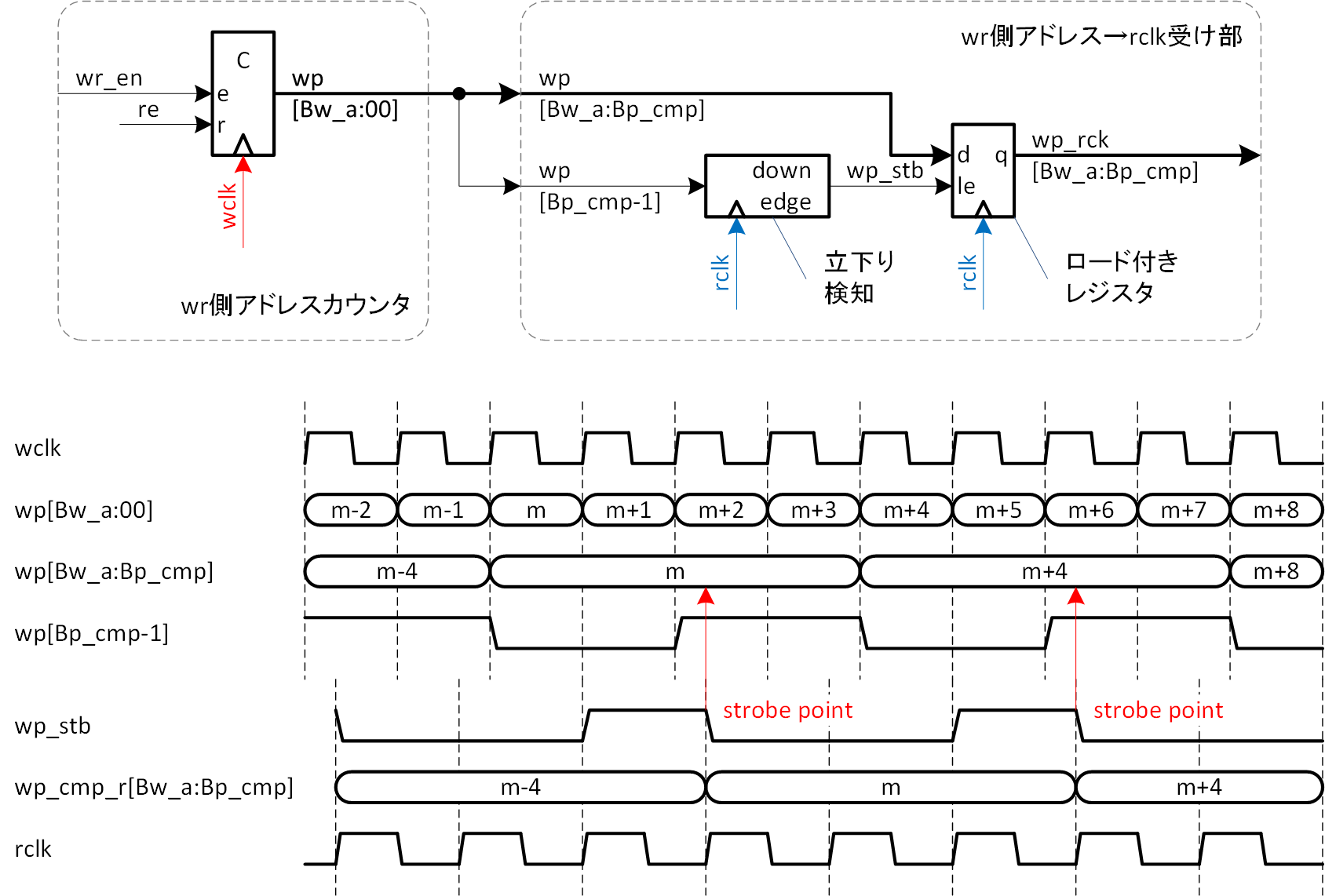
アドレスの交換部分として書き込みアドレスを読み出しクロック系に渡す部分のみ示しています。アドレス幅は Bw_a、参照するアドレス上位桁の LSB を Bp_cmp としています。下位2桁を参照しないとすれば、Bp_cmp = 2 になります。書き込みアドレスの生成は、前回同様1ビット拡張して生成し、wp[Bw_a:0] になります。これを読み出しクロック ( rclk ) 系に渡しますが、渡す桁は wp[Bw_a:Bp_cmp] で、渡すタイミングは wp[Bp_cmp-1] から生成します。Bp_cmp = 2 ですので、書き込みが連続している場合でも、wp[Bw_a:Bp_cmp] は最低4クロック期間は変化しません。同時に、wp[Bp_cmp-1] は4クロックに1回、wp[Bw_a:Bp_cmp] の変化点で立ち下がることになり、L/H の期間は2クロックずつです。これを rclk に渡しますが、クロック周波数条件より、L/H の期間を rclk で確実にとらえられるものとします。そのためにL/H の期間は2クロックずつとしているわけです。
rclk で wp[Bp_cmp-1] の立下りパルスを生成し、これを書き込みアドレスの rclk によるストローブ信号 (wp_stb) とすると、wp_stb はwp[Bw_a:Bp_cmp] が変化しない期間に生成されます。wp_stb により wp[Bw_a:Bp_cmp] を rclk でレジスタに取り込めば、書き込みアドレスの読み出しクロック系への受け渡しは完了です。これを wp_rck[Bw_a:Bp_cmp] としました。wp_rck[Bw_a:Bp_cmp] の下位に Bp_cmp 分0を詰めれば、wp_rck[Bw_a:0] として読み出しアドレスとの差分演算が可能になります。
図3-4には、この例による FIFO の全体をブロック図で示します。
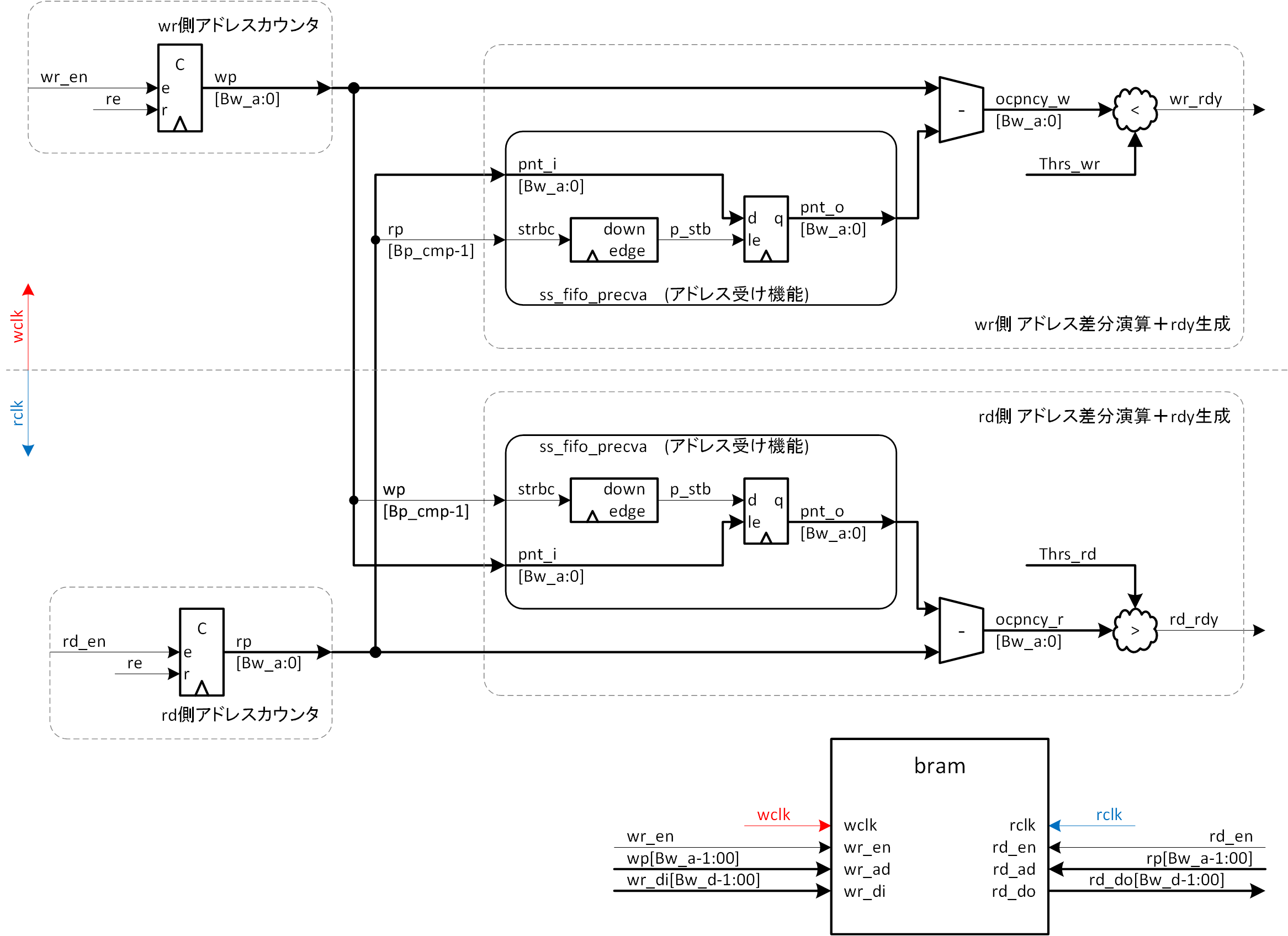
図3-4では、アドレス差分演算 +rdy 生成部を対称形にしてあります。しかし、クロック周波数条件によれば、読み出しアドレスを書き込みクロック系に渡す際には、Bp_cmp = 1 でもアドレス交換が成立する可能性があります。rp[Bp_cmp-1] (= rp[0]) が wclk にとって、L/H 期間をとらえるのに十分な期間を持っているならば、Bp_cmp = 2 である必要はないわけです。このあたりは、書き込みクロックと読み出しクロックの比によって決まりますので、状況に応じて選択してください。記述例は、list3-1 (ss_fifo_asynca.v) の通りです。
module ss_fifo_asynca (
rd_rdy , // o fifo read ready
rd_en , // i read enable in
rd_do , // o read data out
rclk , // i read clock
wr_rdy , // o fifo write ready
wr_di , // i write data in
wr_en , // i write enable in
wclk , // i write clock
rst ); // i sync reset ( h active )
parameter Bw_d = 8 ;
parameter Bw_a = 10 ;
parameter Bp_cmp = 2 ; // compare bit point for ready
parameter Bw_ac = Bw_a - Bp_cmp ;
parameter Depth = ( 1 << Bw_a ) ;
parameter Thrs_w = Depth/4*3 ; // for write ready
parameter Thrs_r = (2**Bp_cmp) ; // for read ready
output wr_rdy ; // o fifo write ready
input [Bw_d-1:00] wr_di ; // i write data in
input wr_en ; // i write enable in
input wclk ; // i write clock
input rst ; // i sync reset ( h active )
output rd_rdy ; // o fifo read ready
input rd_en ; // i read enable in
output [Bw_d-1:00] rd_do ; // o read data out
input rclk ; // i read clock
// wires & regs
reg [Bw_a:00] wp ;
reg [Bw_a:00] rp ;
wire [Bw_a:Bp_cmp] rp_h = rp[Bw_a:Bp_cmp] ;
wire rp_stb = rp[Bp_cmp-1] ;
wire [Bw_a:Bp_cmp] wp_cmp_w = wp[Bw_a:Bp_cmp] ;
wire [Bw_a:Bp_cmp] rp_cmp_w ;
wire [Bw_a:00] ocpncy_w ;
wire [Bw_a:Bp_cmp] wp_h = wp[Bw_a:Bp_cmp] ;
wire wp_stb = wp[Bp_cmp-1] ;
wire [Bw_a:Bp_cmp] wp_cmp_r ;
wire [Bw_a:Bp_cmp] rp_cmp_r = rp[Bw_a:Bp_cmp] ;
wire [Bw_a:00] ocpncy_r ;
reg [Bw_d-1:00] m_ary [0:Depth-1] ; // memory array
reg [Bw_d-1:00] rdo_r ;
// write pointer
always @( posedge wclk ) begin
if ( rst ) wp <= {(Bw_a+1){1'b0}} ;
else if ( wr_en ) wp <= wp + 1'b1 ;
end
// read pointer receive
ss_fifo_precva
#(.Bw_a (Bw_ac ))
urw (
.pnt_o (rp_cmp_w), // o pointer out
.pnt_i (rp_h ), // i pointer in
.strbc (rp_stb ), // i term count in
.clk (wclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer
always @( posedge rclk ) begin
if ( rst ) rp <= {(Bw_a+1){1'b0}} ;
else if ( rd_en ) rp <= rp + 1'b1 ;
end
// write pointer receive
ss_fifo_precva
#(.Bw_a (Bw_ac ))
urr (
.pnt_o (wp_cmp_r), // o pointer out
.pnt_i (wp_h ), // i pointer in
.strbc (wp_stb ), // i term count in
.clk (rclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// occupancy
assign ocpncy_w = wp - {rp_cmp_w,{Bp_cmp{1'b0}}} ;
assign ocpncy_r = {wp_cmp_r,{Bp_cmp{1'b0}}} - rp ;
assign wr_rdy = ~ocpncy_w[Bw_a] & ( ocpncy_w[Bw_a-1:00] <= Thrs_w ) ;
assign rd_rdy = ~ocpncy_r[Bw_a] & ( ocpncy_r[Bw_a-1:00] >= Thrs_r ) ;
// data buffer register
always @( posedge wclk ) begin
if ( wr_en ) m_ary [wp[Bw_a-1:00]] <= wr_di ;
end
always @( posedge rclk ) begin
rdo_r <= m_ary [rp[Bw_a-1:00]] ;
end
assign rd_do = rdo_r ;
endmoduleまた、図3-4では、アドレス受け機能部を、 ss_fifo_precva という名前でモジュール化してあります。同一機能を複数回使用するということと、後々の流用や、機能のすり替えを容易にするためです。記述例を、list3-2 (ss_fifo_precva.v) に示します。
module ss_fifo_precva (
pnt_o , // o pointer out
pnt_i , // i pointer in
strbc , // i strobe count in
clk , // i clock
rst ); // i sync reset ( h active )
parameter Bw_a = 10 ;
input [Bw_a:00] pnt_i ; // i pointer in
input strbc ; // i strobe count in
input clk ; // i clock
input rst ; // i sync reset ( h active )
output [Bw_a:00] pnt_o ; // o pointer out
// wires & regs
reg [02:01] strbcr ; // i term count shift reg
wire p_stb = ( strbcr==2'b10 ) ;
reg [Bw_a:00] pnt_o ; // o pointer out
// termc shift reg
always @( posedge clk ) begin
strbcr <= {strbcr[01],strbc} ;
end
// pnt_i strobe
always @( posedge clk ) begin
if ( rst ) pnt_o <= {(Bw_a+1){1'b0}} ;
else if ( p_stb ) pnt_o <= pnt_i ;
end
endmoduleこの設計例は、頻繁にかつ定期的に書き込みも読み出しも発生する場合に効果的です。Bp_cmp = 2 の例で言えば、wr_stb は書き込みアドレスの4回に1回だけのインクリメントに発生しますので、少なくともデータの書き込み、読み出しが4の倍数単位のデータ数で行われるならば、問題はありません。しかし、4の倍数に対し端数を持つデータ数で書き込みが終わってしまった場合には、端数データがあることは読み出し側に伝達されないまま終わってしまいますので、使用する範囲には制限があります。
アドレス交換法2
先の方法でのアドレス交換は、最後に記述した通り、端数データが発生し、そこで止まってしまう条件下では、欠点がありました。これを解決する方法を考えてみましょう。
まず、根本的にアドレスが連続的にインクリメントを続けている場合、アドレスの静的期間を非同期クロック側に伝達するのは、かなり困難な状況といえます。ですから、前例ではアドレスを間引いて、無理やりその期間を作ったわけです。とりあえず、端数データが FIFO にある、要するに1データでも FIFO にあれば、その状態を非同期クロック側に伝達することを目指しますが、アドレスが連続的にインクリメントを続けている状況は勘弁してもらうことにします。要するに、アドレスの静的期間を意図的に作り出すのではなく、アドレスの静的期間が発生したら、そこでアドレス交換を行うわけです。少なくとも、端数データが発生しそこで止まってしまう状況はその場合と考えることができますし、その状況に対応できれば、FIFO 内のデータ残量による制限は受けません。
アドレスの交換方法例を図3-5に示します。
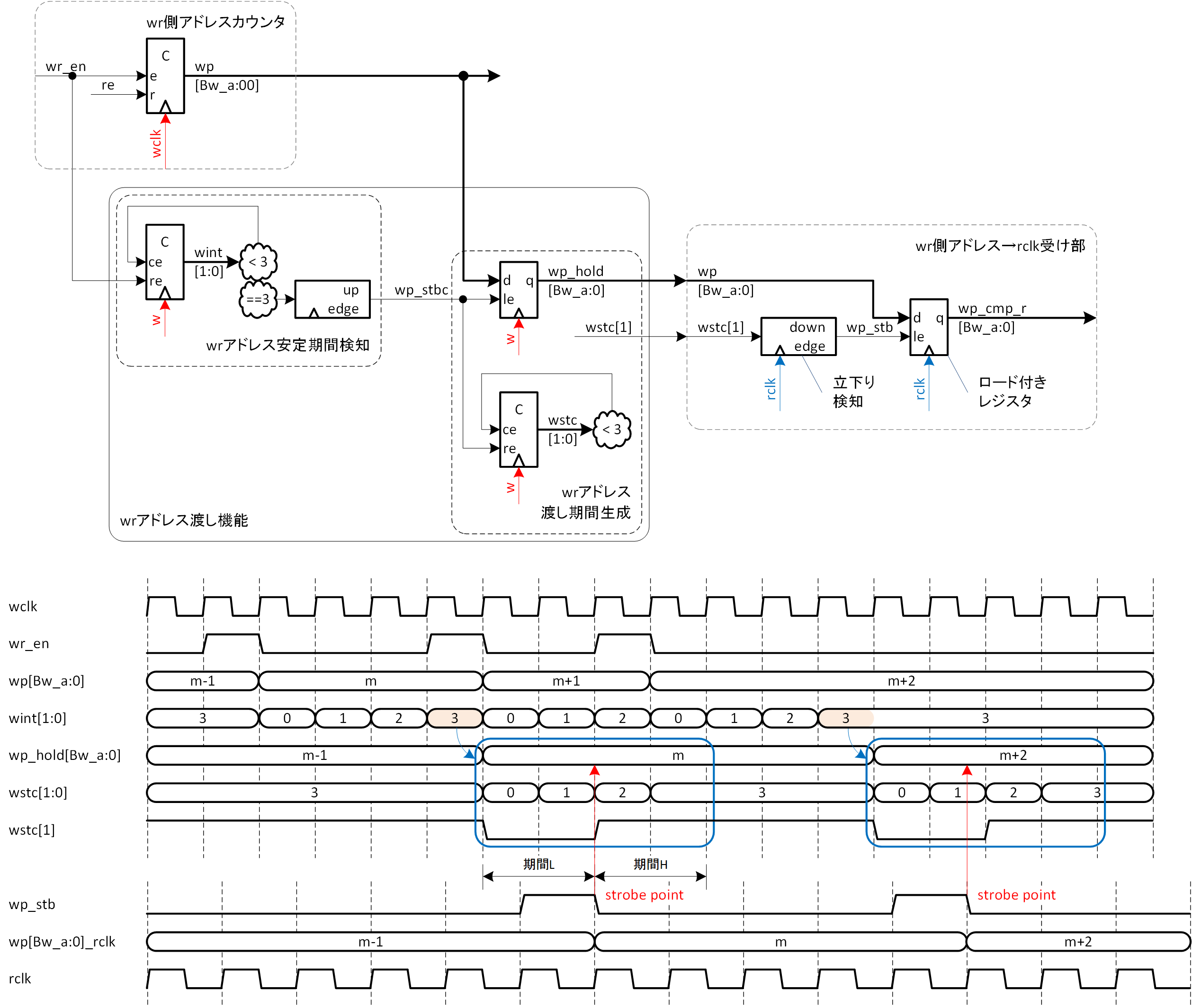
まずは、アドレスの静的期間が発生したことを検知します。wint[1:0] はカウンタで、wr_en で0にリセット、3未満の期間はインクリメントを続け、3で止まります。wr_en が3サイクル以下のインターバルで発生する場合は wint[1:0] は3に到達しませんが、2から3に遷移したことで wr_en のインターバルが4以上であった (アドレスが4クロック以上静的であった) ことがわかります。wint[1:0] が2から3に遷移した時に、wp を wp_hold レジスタに取り込み、wstc[1:0] をリセットします。wstc[1:0] もカウンタで、0にリセット後、3未満でインクリメントし、3で止まります。wint[1:0] の2から3への遷移で起動するシーケンスを、図3-5では青枠で囲って示しています。
wstc[1] に着目すると、青枠シーケンス起動後、2クロックの L 期間を経て2クロック以上の H 期間に入ります。ここからは、先のアドレス交換間引き法1の場合と同様に wp_stb を生成することができますので、やはり同様に wp_stb により wp[Bw_a:0] を rclk でレジスタに取り込めば、書き込みアドレスの読み出しクロック系への受け渡しは完了です。この場合は、wp の全桁を交換することができます。
アドレス交換シーケンスは、wint ==3 によって4クロックの静的期間があったことがわかってから開始するので、そのシーケンス期間は静的であったアドレスを保存しておく必要があり、そのために wp_hold レジスタが使用されます。逆に、wint ==3 によってアドレスロードシーケンスが起動されるので、保存されたアドレスは4クロックの静的期間が保証されます。図3-5を見れば、wstc が0から3に至るまでの4クロック間は、wp_hold が変化しないのがわかります。
図3-6には、この例による FIFO の全体をブロック図で示します。BRAM 周辺はこれまでと同じですので省略し、アドレスの交換部分のみ示しています。図3-6では、アドレス渡し機能部を、 ss_fifo_psenda という名前でモジュール化してあります。理由は先の例と同じです。アドレスのストローブ信号の生成からアドレス差分演算、rdy 信号の生成機能は、先のアドレス交換法1と全く同じで、アドレス受け部は ss_fifo_precva を流用しています。
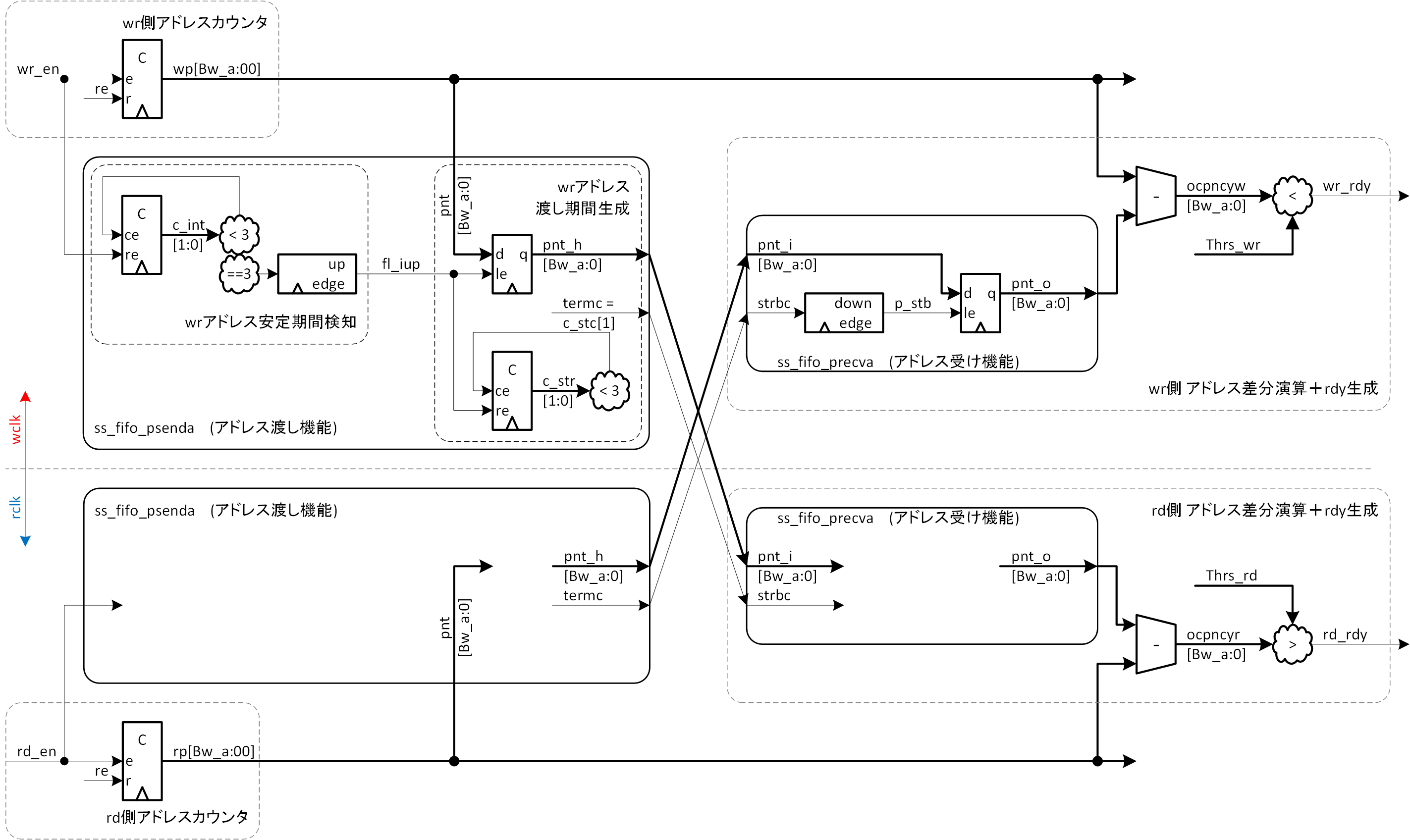
ss_fifo_psenda の記述例を、list3-3 (ss_fifo_psenda.v) に、FIFO 階層の記述例を、list3-4 (ss_fifo_asyncb.v) に示します。
module ss_fifo_psenda (
pnt_h , // o pointer hold out
termc , // o term count out
pnt , // i pointer in
enb , // i enable in
clk , // i clock
rst ); // i sync reset ( h active )
parameter Bw_a = 10 ;
input [Bw_a:00] pnt ; // i pointer in
input enb ; // i enable in
input clk ; // i clock
input rst ; // i sync reset ( h active )
output [Bw_a:00] pnt_h ; // o pointer hold out
output termc ; // o term count out
// wires & regs
reg [01:00] c_int ; // interval count
wire ce_int = ( c_int < 2'h3 ) ;
wire fl_int = ( c_int >= 2'h3 ) ; // interval count full
reg fl_intr; // interval count full reg
wire fl_iup = ( {fl_intr,fl_int}==2'b01 ) ; // interval count full up edge
reg [01:00] c_str ; // strobe count
wire re_str = fl_iup ;
wire ce_str = ( c_str < 2'h3 ) ;
reg [Bw_a:00] pnt_h ; // o pointer hold out
assign termc = c_str[01] ;
// interval count
always @( posedge clk ) begin
if ( rst ) c_int <= 2'h3 ;
else if ( enb ) c_int <= 2'h0 ;
else if ( ce_int ) c_int <= c_int + 1'b1 ;
end
// interval count full reg
always @( posedge clk ) begin
fl_intr <= fl_int ;
end
// strobe count
always @( posedge clk ) begin
if ( rst ) c_str <= 2'h3 ;
else if ( re_str ) c_str <= 2'h0 ;
else if ( ce_str ) c_str <= c_str + 1'b1 ;
end
// pointer hold
always @( posedge clk ) begin
if ( rst ) pnt_h <= {(Bw_a+1){1'b0}} ;
else if ( re_str ) pnt_h <= pnt ;
end
endmodule
module ss_fifo_asyncb (
rd_rdy , // o fifo read ready
rd_en , // i read enable in
rd_do , // o read data out
rclk , // i read clock
wr_rdy , // o fifo write ready
wr_di , // i write data in
wr_en , // i write enable in
wclk , // i write clock
rst ); // i sync reset ( h active )
parameter Bw_d = 8 ;
parameter Bw_a = 10 ;
parameter Depth = 2**Bw_a ; // fifo depth
parameter Thrs_w = Depth/4*3 ; // for write ready
parameter Thrs_r = 1 ; // for read ready
output wr_rdy ; // o fifo write ready
input [Bw_d-1:00] wr_di ; // i write data in
input wr_en ; // i write enable in
input wclk ; // i write clock
input rst ; // i sync reset ( h active )
output rd_rdy ; // o fifo read ready
input rd_en ; // i read enable in
output [Bw_d-1:00] rd_do ; // o read data out
input rclk ; // i read clock
// wires & regs
reg [Bw_a:00] wp ; // wr pointer
reg [Bw_a:00] rp ; // rd pointer
wire [Bw_a:00] wp_h ; // wr pointer
wire [Bw_a:00] rp_h ; // rd pointer
wire wtrmc ; // wr term count
wire rtrmc ; // rd term count
wire [Bw_a:00] rp_wck ; // rd pointer wclk
wire [Bw_a:00] wp_rck ; // wr pointer rclk
wire [Bw_a:00] ocpncyw; // pointer difference for wr
wire [Bw_a:00] ocpncyr; // pointer difference for rd
reg [Bw_d-1:00] m_ary [0:Depth-1] ; // memory array
reg [Bw_d-1:00] rdo_r ;
assign rd_do = rdo_r ;
// write pointer
always @( posedge wclk ) begin
if ( rst ) wp <= {(Bw_a+1){1'b0}} ;
else if ( wr_en ) wp <= wp + 1'b1 ;
end
// write pointer send
ss_fifo_psenda
#(.Bw_a (Bw_a ))
usw (
.pnt_h (wp_h ), // o pointer hold out
.termc (wtrmc ), // o term count out
.pnt (wp ), // i pointer in
.enb (wr_en ), // i enable in
.clk (wclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer receive
ss_fifo_precva
#(.Bw_a (Bw_a ))
urw (
.pnt_o (rp_wck ), // o pointer out
.pnt_i (rp_h ), // i pointer in
.strbc (rtrmc ), // i term count in
.clk (wclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer
always @( posedge rclk ) begin
if ( rst ) rp <= {(Bw_a+1){1'b0}} ;
else if ( rd_en ) rp <= rp + 1'b1 ;
end
// read pointer send
ss_fifo_psenda
#(.Bw_a (Bw_a ))
usr (
.pnt_h (rp_h ), // o pointer hold out
.termc (rtrmc ), // o term count out
.pnt (rp ), // i pointer in
.enb (rd_en ), // i enable in
.clk (rclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// write pointer receive
ss_fifo_precva
#(.Bw_a (Bw_a ))
urr (
.pnt_o (wp_rck ), // o pointer out
.pnt_i (wp_h ), // i pointer in
.strbc (wtrmc ), // i term count in
.clk (rclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// occupancy
assign ocpncyw = wp - rp_wck ;
assign ocpncyr = wp_rck - rp ;
assign wr_rdy = ~ocpncyw[Bw_a] & ( ocpncyw[Bw_a-1:00] <= Thrs_w ) ;
assign rd_rdy = ~ocpncyr[Bw_a] & ( ocpncyr[Bw_a-1:00] >= Thrs_r ) ;
// memory array wr
always @( posedge wclk ) begin
if ( wr_en ) m_ary [wp[Bw_a-1:00]] <= wr_di ;
end
// memory array rd
always @( posedge rclk ) begin
rdo_r <= m_ary [rp[Bw_a-1:00]] ;
end
endmoduleこの設計例では、FIFO 内のデータ蓄積量が不確定で端数が出やすいときに効果的ですが、アドレスの静的期間が必ず発生するという条件が必要です。ここではクロック周波数条件により読み出しクロックが遅いことを条件に説明していますので、例えば書き込みが行われたらすぐに読み出すという動作が続けられた場合には、読み出しアドレスに静的期間が訪れないという可能性があり、その場合読み出しアドレスが書き込みクロック系に渡されないことになります。間違いなく FIFO の制御は、早晩破綻を迎えます。
ここまで、2つの設計例を示しましたが、アドレス交換法1、2、何れも一長一短で、オールマイティーではありません。困りました。
次の指針
2つの設計例で、特定の条件下では有効に機能するが、万能ではない結果となってしまいました。この続きは次回に持ち越しますが、2つの設計例のハイブリッド化を考えてみたいと思います。また、Xilinx のビルトイン FIFO では、非同期型がどのように対処されているかについても解説を予定しています。
なお、設計例はいずれも、どちらかといえば考え方を示したものですので、あらゆるケースでの動作を保証するものではありません。くれぐれもご注意ください。
エンジニア 鈴木昌治
参考文献
UG573 (v1.11) 2020年8月18日「 UltraScale アーキテクチャ メモリリソース ユーザー ガイド」