
自作回路を PYNQ から使うための設計・開発法に関するコースの第3回です。ここからは、PS と多量のデータのやりとりを必要とする回路を含んだ設計例の説明に入ります。今回は、AXI-Stream で回路からデータを PS に流し込み、そのデータをファイルに保存する、という例を取り上げます。今回の例は、「PYNQ を使って Python で手軽に FPGA を活用 (5)」の後半で紹介されている、AXI-Stream で来たデータを加工して AXI-Stream で返す、といった回路にも応用できます。
本コースで使用したハードウェア記述は、GitHub リポジトリ上で公開しています。今回の関連するファイルは、単体でも活用できるよう、別リポジトリに分けています。
真性乱数生成回路のための汎用データ送信コア
AXI DMA IP コア
冒頭ではぼかして書いていましたが、今回の設計例は以前「FPGA と予測不可能性と乱数」のコースで紹介させていただいた真性乱数生成回路 (TRNG) にかかわるものになります。……とはいっても、別に上記のコースでお話したような知識が必要なわけではありませんし、TRNG 自体それなりにニッチな研究ですので、この例が直接的に役に立つ人が限られているのは、承知の上です。
ただ、今回問題にするのは TRNG そのものをどう作るかでなく、得られたデータをどう集めるかです。TRNG を入出力のレベルで抽象化してしまえば、これは「不定期に1ビットのデータが出力される回路」です。今回は、そのデータを収集して、PS に流し込んで、ファイルに保存する、という部分をどう作るかに注目します。この部分は、IoT で考えられる、例えばセンサ等から得た情報を PL で下処理してから PS に送る、などの使い方とも共通点があるのではと思います。
さて、「AXI でプロセッサとつながる IP コアを作る (1)」でも紹介した通り、PS-PL 間での多量のデータの受け渡しにはフル機能の AXI や AXI-Stream を使います。同コースの第3回では、ビデオアプリケーションでの AXI-Stream の例を取り上げ、AXI VDMA という IP コアを自作回路と併用することで PS のメモリ上にテストパターンを送信しました。
対して、一般のデータ送受信で AXI-Stream を利用する場合には、AXI DMA IP コアを使用します。このコアに送受信先のアドレスとデータサイズを渡すと、PS のメモリからデータを読み出して AXI-Stream で送ったり、AXI-Stream で受け取ったデータを PS のメモリに書き込んだりできます。
下図に、AXI DMA IP コアをシンプル DMA モード、送受信各1チャネルで設定した時のブロック図を示します。

S_AXI_LITE は制御用の AXI-Lite、M_AXI_MM2S と M_AXI_S2MM は PS と接続するためのフル機能の AXI のインタフェースです。これらの PS との接続は、基本的に Run Connection Automation 一発でうまくやってくれます。残りの2つが AXI-Stream で、S_AXIS_S2MM は PL → PS へのデータ送信用、S_AXIS_MM2S は PS → PL へのデータ受信用に使います。
AXI DMA IP コアを使うときの AXI-Stream の信号の扱いで注意すべきは、PL → PS へのデータ送信では、データの末尾を示す TLAST 信号が必須であることです (参考: Xilinx のアンサーレコード)。指定したデータサイズと同量のデータの送信が終わったら、最後のデータに付随する TLAST は必ず ‘1′ にしなければなりません。そうでないと、AXI DMA 側でエラーが発生します。逆に、指定したデータサイズと同量のデータを送り終わる前に TLAST を ‘1′ にすることは許容されます (その時点で転送は終了します) 。PS の側から見れば、AXI DMA にはデータサイズとして、AXI-Stream で送られうる最大のサイズを指定する必要がある、とも言えます。
今回の例では PL → PS へのデータ送信だけを扱いますので、このうち M_AXI_MM2S と S_AXIS_MM2S のインタフェースは無効化して使うことになります。
データ送信コアの設計
今回作成するデータ送信コアの内部構造の概要を、下図に示します。TRNG ではしばしば、パラメータを変更しながら回路を動作させてみて、パラメータの良し悪しをチェックしながら適切なパラメータを見つける、という手順が必要な場合があります。ここでは、最低限必要な制御情報に加え、こうした手順に必要なパラメータや統計情報も、AXI-Lite のインタフェース回路を介して送受信することとします。
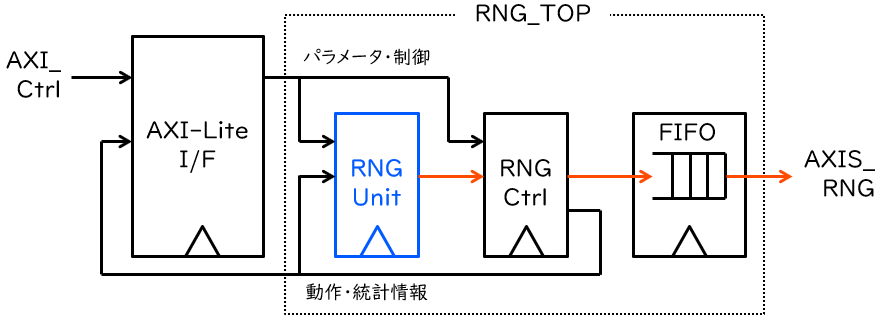
図中の RNG Unit が、TRNG の本体ユニットです。パラメータと、回路が動作すべきかどうかを入力とし、データを有効ビットとともに出力します。TRNG の中には、内部にカウンタを持っていて、その値が偶数か奇数かによって出力を定めているものもあります。このカウンタの値をそのまま出力できるよう、出力データのビット幅は16ビットに定めています。
最初に述べた通り、今回は TRNG そのものの作り方は問題としませんので、RNG Unit の中身は上記の入出力 (外見) に適合するものであれば、何でも構いません。今回はあらかじめ設計しておいたものを使うことにします。
RNG Ctrl はコントローラ回路です。基本的には、RNG Unit からの1ビット (データの最下位ビット) のシリアル出力を、32ビット単位のパラレル出力に変換する、シリアル-パラレル変換器として動作します。過去31回分のデータをシフトレジスタで記憶して、現在のデータと合わせ、32ビットごとに FIFO へと出力します。また、これまでに送信したバイト数を記憶し、あらかじめ指定したバイト数に達したら、DMA 転送を終了する、あるいは乱数の生成を終了します。FIFO に格納されたデータは、受信側 (AXI DMA) の準備ができたタイミングで出力されます。これに加え、オプションでユーザ定義の統計量を計算する回路を搭載できるようになっていますが、詳細はここでは割愛します。
データ送信コアの SystemVerilog 記述
つづいて、実際の SystemVerilog の記述のうち、特に解説が必要そうな部分を紹介していきます。まずは、第2回でもテンプレートからの変更によって作成した、AXI-Lite のインタフェース回路です。やはり今回も、入出力の定義と読み出し・書き込みデータの定義の部分を変更します。
RNG_GO <= 1'b0;
RNG_STOP <= 1'b0;
if (reg_we && d_awaddr == 2'd0) begin
if (AXI_CTRL_WSTRB[0]) begin
RNG_GO <= AXI_CTRL_WDATA[0];
RNG_STOP <= ~ AXI_CTRL_WDATA[0];
end
書き込みデータは、アドレスが 0, 4, 8, 12 (バイト) の場合に、動作制御、生成する合計のバイト数、DMA転送1回あたりのバイト数、パラメータを、それぞれ書き込むように記述されています。
動作制御では、最下位ビットに ‘1′ を書き込んだ場合には乱数の生成を開始し、‘0′ を書き込んだ場合には中止する、という動作をさせることにします。対応する SystemVerilog 記述では、0バイト目に書き込んだ瞬間 (次のクロックサイクル) にだけ開始 (RNG_GO)、または中止 (RNG_STOP) の信号が ‘1′ となるロジックが記述されています。
// -- 読み出しデータ
always_comb begin
if (d_araddr == 2'd0) begin
n_rdata = {30'b0, RNG_OVER, RNG_RUN};
end else if (d_araddr == 2'd1) begin
n_rdata = RNG_SENT_BYTES;
end else if (d_araddr == 2'd2) begin
n_rdata = RNG_SUM_DATA;
end else begin // d_araddr == 2'd3
n_rdata = RNG_STATS;
end
end
一方、読み出しデータは、アドレスが 0, 4, 8, 12 (バイト) の場合に、動作状況、転送したバイト数、RNG Unit から出力されたデータ値の総和、ユーザ定義の統計情報が、それぞれ読み出されるように記述されています。動作状況は、最下位ビット (1の位) が TRNG が動作中かどうかを示し、その1つ上位 (2の位) で FIFO があふれたかどうかを示します。
end else if (RUN & DATA_RE) begin
n_sum = SUM_DATA + DATA_IN;
n_count = count + 1'b1;
n_data_reg = DATA_OUT[30:0];
if (n_count == 5'd0) begin
if (FIFO_FULL) begin
n_over = 1'b1;
end else begin
n_sent = SENT_BYTES + 3'd4;
n_sent_dma = sent_dma + 3'd4;
n_run = (n_sent < SEND_BYTES || SEND_BYTES == 0);
if (sent_dma + 3'd4 >= DMA_BYTES) begin
n_sent_dma = 0;
dma_last = 1'b1;
end
end
end
end
コントローラ回路のメインのロジックの記述です。基本的には、カウンタとシフトレジスタを組み合わせた記述になっています。5ビットのカウンタが一巡するたび (つまり 25 = 32 回ごと) に、そのときのパラレル出力を FIFO へと送るとともに、送信したバイト数に4を加算しています。もしこの値が、生成する合計のバイト数や、DMA転送1回あたりのバイト数に達した場合には、乱数の生成を終了したり、TLAST を ‘1′ に設定したりします。ただし、FIFO が満杯になっていた場合には、バイト数の加算は行わず、FIFO があふれたことを示すフラグを立てます。
これらの記述は、リポジトリの core/src ディレクトリにまとめられています。ユーザ回路 (core/src/user) はデフォルトでは何も出力しないものになっていますので、サンプルのうち1つで置き換えます。ここでは sample/TC-TERO ディレクトリの中のすべてのファイルを、core/src/user にコピーします (rng_unit.sv は上書きします)。
ブロック図の作成と論理合成
ここからは Vivado の出番です。まずは、PYNQ-Z1 向けの Vivado プロジェクトを作成し、第2回と同じ要領で、IP パッケージャを使ってデータ送信コアをパッケージします。IP コアが作成できたら、Create Block Design でブロック図を新規作成し、ZYNQ7 Processing System を追加し、Run Block Automation を⾏います。
今回は PS の HP ポートを使用しますので、ここで PS をダブルクリックして、設定画面を開きます。PS-PL Configuration から、HP Slave AXI Interface → S AXI HP0 Interface にチェックを入れます。このときの様子を下図に示します。
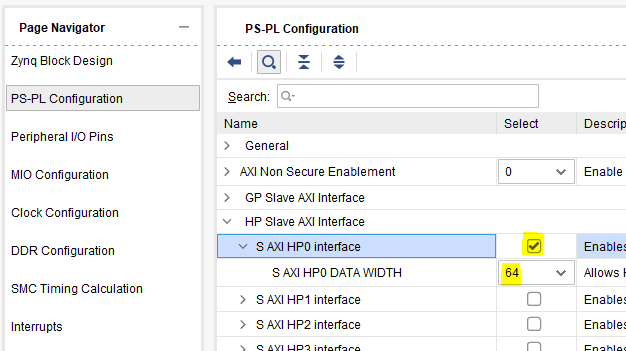
なお、その下に HP ポートのビット幅を設定できる項目 (S AXI HP0 DATA WIDTH) が存在しますが、64のままにしておいてください。PYNQ の場合、HP ポートのビット幅は OS の起動時に設定されているため、ここで32ビットを設定してしまうと、送受信したはずのデータが欠落してしまう不具合の原因となります。
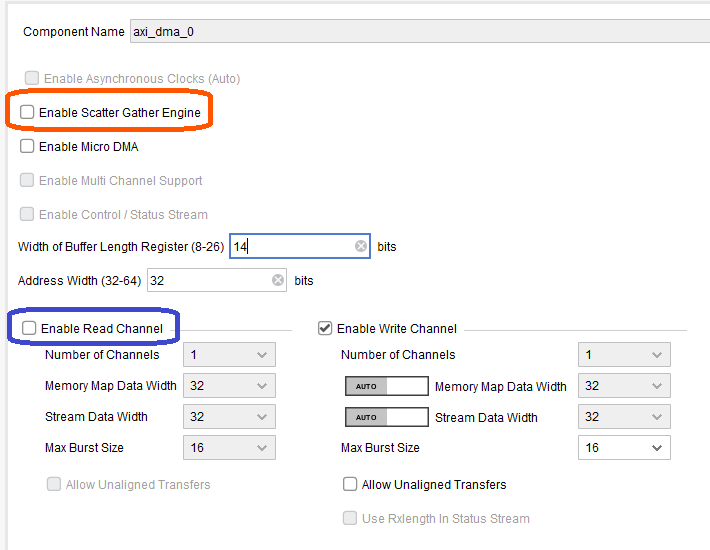
次に、AXI DMA IP コアを配置します。ダブルクリックして設定画面を開くと、下図に示すダイアログが表示されます。PYNQ の AXI DMA IP コア向けドライバはシンプル DMA にのみ対応しますので、Enable Scatter Gather Engine のチェックは外しておきます。また、今回は PS → PL へのデータの受信 (読み出し) は必要ありませんので、Enable Read Channel のチェックも外します。
さらに、先ほどパッケージしたデータ送信コア (ここではパッケージの際に回路名を TRNG_IP に変更したとします) を回路図に追加して、Run Connection Automation を実行します。この段階で AXI-Stream 以外の接続が自動で設定されます。最後に、データ送信コアの AXIS_RNG を、AXI DMA の S_AXIS_S2MM に接続したら、ブロック図は完成です。完成したブロック図を下図に示します。
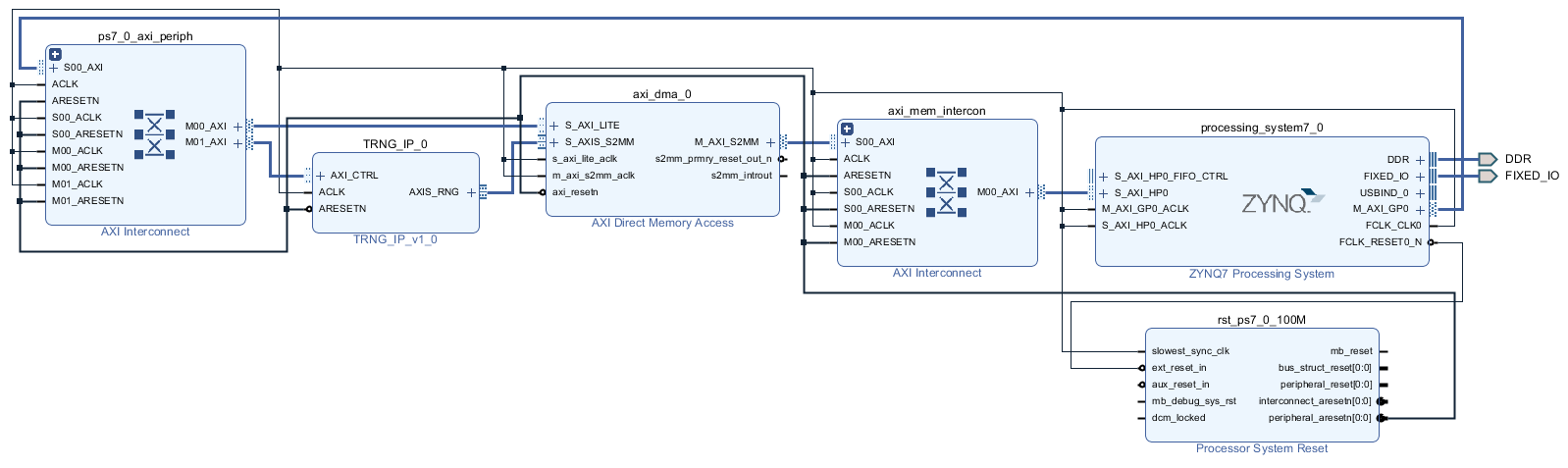
では、Validate Design 以降の手順をいつも通り進めましょう。今回は、外部に出ている入出力がありませんので、制約ファイル (XDC) は不要です。生成されたビットストリーム (.bit) とハードウェア情報ファイル (.hwh) は、今回は trng_ip.bit, trng_ip.hwh と名前を変更して、アップロードしておきます。
Python による動作確認
つづいて PYNQ 上での作業です。今回も、専用のドライバクラスを作成し、データ送信コアへのアクセスを抽象化することにしましょう。例えば、乱数の生成を開始したいときには、送信したいバイト数を引数として、start メソッドを呼び出します。中身は以下のように定義されています。
def start (self, total, dma_size = 4096):
self.write(self.ADDR_SEND_BYTES, total)
self.write(self.ADDR_DMA_BYTES, dma_size)
self.write(self.ADDR_GO, 1)
self.send_bytes = total
送信したいバイト数、DMA 1回あたりのバイト数をデータ送信コアに書き込んでから、動作制御のレジスタに1を書き込み、回路の動作開始を指示しています。
今回サンプルとして使用した TC-TERO には、パラメータを切り替えることで回路の挙動が変わり、TRNG の内部カウンタの値の分布が変化するという特徴があります。実際に、いくつかのパラメータに対して、得られたカウンタの値の平均値や、得られた乱数 (カウンタ値の最下位ビットを並べたもの) の最初の32ビットを表示してみます。この場合、例えば以下のようなスクリプトを用意します (GitHub 上のソースコード) 。
from pynq import Overlay
from pynq import allocate
import numpy as np
pl = Overlay("trng_ip.bit")
rng = pl.TRNG_IP_0
dma = pl.axi_dma_0
buffer = allocate(shape=(1024,), dtype=np.uint32)
for i in range(16):
rng.parameter = i
rng.start(4096)
dma.recvchannel.transfer(buffer)
rng.wait()
dma.recvchannel.wait()
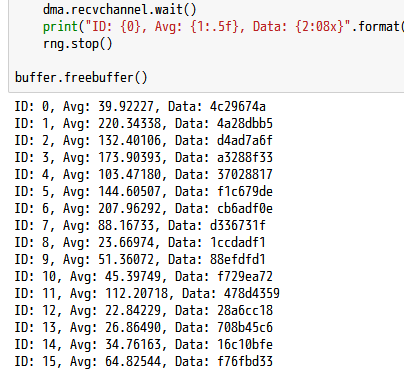
print("ID: {0}, Avg: {1:.5f}, Data: {2:08x}".format(i, rng.sum_data/32768, buffer[0]))
rng.stop()
buffer.freebuffer()
下準備として、PYNQ の allocate メソッドを使い、送信されたデータの格納先となるメモリ領域を確保します (8行)。ここでは、32ビット整数1024要素分 (つまり 4,096 バイト) の領域を確保しています。その後、0~15の各パラメータについて、4,096 バイト分の乱数生成を行う (12行) とともに、確保した領域に対する DMA 転送を指示します (13行)。各コアの動作が終了したことを確認 (14~15行) してから、その結果を表示します (16行)。全ての転送が終わったら、確保したメモリ領域は忘れずに解放しておきます (19行)。
乱数はパラメータごとに 4,096 バイト = 32,768 ビット生成していますので、カウンタの値の平均値を求める場合は、合計を 32,768 で割ります。
このスクリプトを実行すると、例えば下図に示す結果が得られます。Zynq のチップを構成するトランジスタには個体差がありますので、使用するボードが異なれば、得られる結果も大きく異なります。
あるいは、1つのパラメータに対してしばらく乱数の生成を続け、その結果をファイルに保存するのであれば、例えば以下に示すスクリプトを用意します (GitHub 上のソースコード) 。
from pynq import Overlay
from pynq import allocate
import numpy as np
NUM_BLOCKS = 16
pl = Overlay("trng_ip.bit")
rng = pl.TRNG_IP_0
dma = pl.axi_dma_0
buffer_r = allocate(shape=(1024,), dtype=np.uint32)
buffer_w = allocate(shape=(1024,), dtype=np.uint32)
file = open("random_data.dat", "wb")
rng.parameter = 1
rng.start(NUM_BLOCKS * 4096)
for i in range(NUM_BLOCKS):
dma.recvchannel.transfer(buffer_r)
if i != 0:
buffer_w.tofile(file)
dma.recvchannel.wait()
buffer_r, buffer_w = buffer_w, buffer_r
rng.stop()
buffer_w.tofile(file)
file.close()
buffer_r.freebuffer()
buffer_w.freebuffer()
ここでは、ダブルバッファリングを用いています。バッファを2つ allocate して、片方はデータ送信コアからのデータの受け取りに、もう片方は受け取ったデータのファイルへの書き込みに、それぞれ使用します (10~11行)。また、ループの末尾でこれらを入れ替えています (22行)。ループの最初の1回に限りファイルへの書き込みは行わないこと (19~20行)、ループが終了したあとにもう1度ファイルへの書き込みが必要なこと (35行) に、注意が必要です。
一度ファイルに書き込んでしまえば、あとは PYNQ 上でそのまま分析するもよし、WinSCP などでホスト PC に吸い出すもよしです。データの収集後の取り回しが楽な点も、PYNQ を使う1つのメリットとなりうるでしょう。
まとめ
今回は、AXI-Stream で PS との送受信を行う場合の例を示しました。AXI-Stream は扱いが簡便なので、利用の機会は多いのではないでしょうか。今回のポイントは以下のとおりです。
- AXI-Stream で PS との送受信を行う場合は、AXI DMA IP コアと併用するのが便利
- PL → PS への送信信号を自分で作成する場合,TLAST 信号を DMA 転送のサイズに合わせて ‘1′ にしないといけない点に注意
送受信が両方ある場合で、受信したのと同じ量のデータを送信する場合は、単に受信した TLAST 信号をそのまま送り返せば済むかもしれません。実際、「PYNQ を使って Python で手軽に FPGA を活用 (5)」で示されたデータ値を2倍する回路はそう書かれています (23行目に注目)。
データにアクセスするパターンによっては、AXI-Stream が使いづらいケースもあるでしょう。その場合、フル機能の AXI を使って、自分から PS のメモリにアクセスしに行くことを検討することになるでしょう。この場合の設計例について、次回紹介します。
愛知⼯業⼤学 藤枝直輝