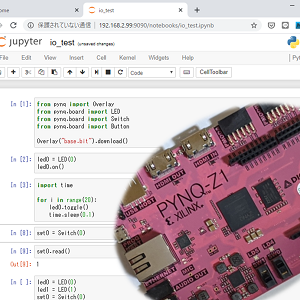
みなさんこんにちは。このコースでは、Python で FPGA を手軽に利用できる PYNQ とその活用方法を紹介していきます。ゴールは、Jupyter Notebook の環境を使って Python から手軽に FPGA を利用できるようになることです。前回は、自分で設計したロジックを PYNQ 上で利用する開発手順を紹介しました。
最終回となる今回は、PYNQ を使って本格的なアプリケーションを実装するために必須の PS (プロセッサ) と PL (プログラマブルロジック) でのデータ共有の方法を紹介します。
PS と PL でデータ共有
PYNQ で実用的なアプリケーションを実行しようと思うと PS と PL でのデータ共有が不可欠です。PS と PL のデータ共有方法は、
- (a) PS から PL のデータを読み書きする方法
- (b) PL から PS に接続したメモリのデータを読み書きする方法
の二つがあります。実際のアプリケーションではこれらを組み合わせて利用することもあります。
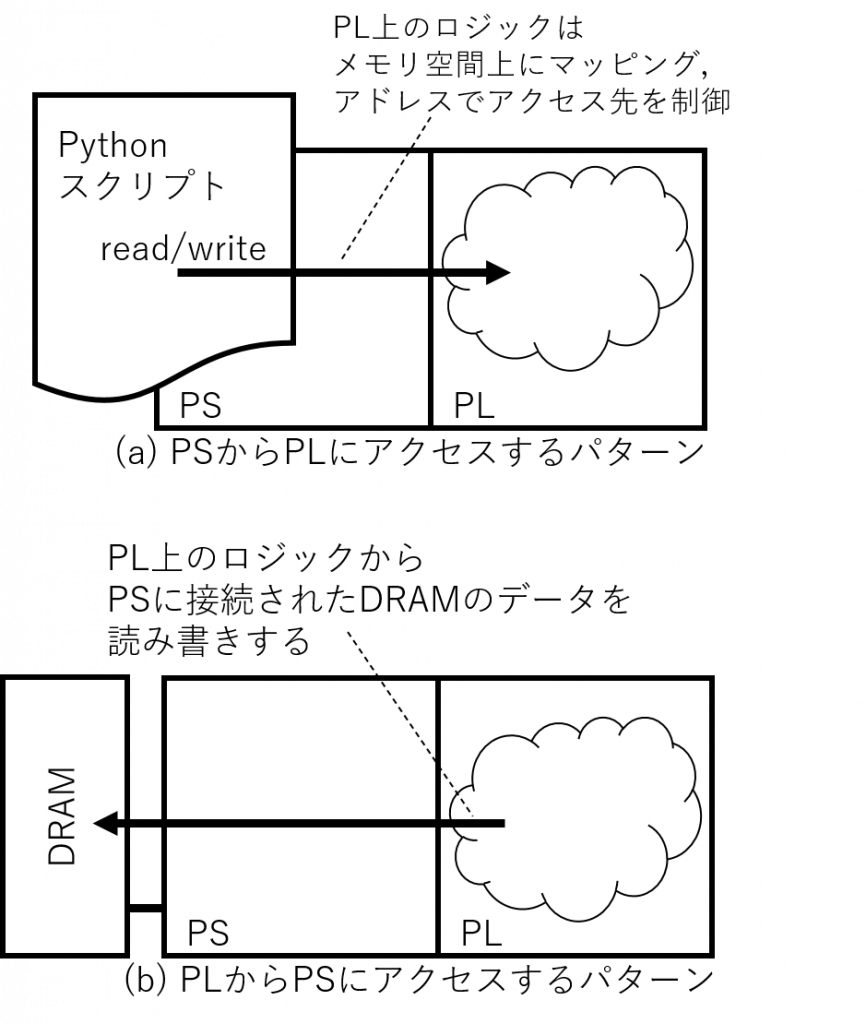
PS から PL のデータを読み書きする
これは前回の記事で紹介した方法です。PL 上のロジックを PS の GP ポートに接続し、読み書きしたい領域をメモリ上にマッピングすることで PS 上のソフトウェアから読み書きできるようにします。
前回は AXI GPIO モジュールに PS から値をセットすることで LED を制御するシンプルな例を紹介しました。GPIO の代わりに BRAM を配置することで、数十 KB 程度のデータを共有できます。なお、BRAM について知りたい方は、FPGA をもっと活用するために IP コアを使ってみよう (4)をご覧ください。
PL 上の BRAM を PS と PL で共有してみる
PS と PL でそれぞれアクセス可能な BRAM を PL の上に配置したサンプルプロジェクトを作って動作を確認してみましょう。開発の流れは、
- ハードウェア側: Vivado でプロジェクトを作り IPI を使ってロジックデザインを設計、合成してビットストリームと hwh ファイルを得る
- ソフトウェア側: Jupyter Notebook でビットストリームなどをアップロード、Python プログラムで動かしてみる
の二段階です。
ハードウェア側の準備
Vivado を起動してプロジェクトを作成します。プロジェクト名は pynq_overlay_bram としました。PYNQ-Z1 のボードファイル (ここで公開されている) を使うと楽に設定できます。
IPI を起動してデザインを設計します。PS と、BRAM、BRAM をPS の GP ポートに接続する IP (AXI BRAM)、PL 上のロジックを制御するための GPIO (AXI GPIO)のインスタンスを生成します。

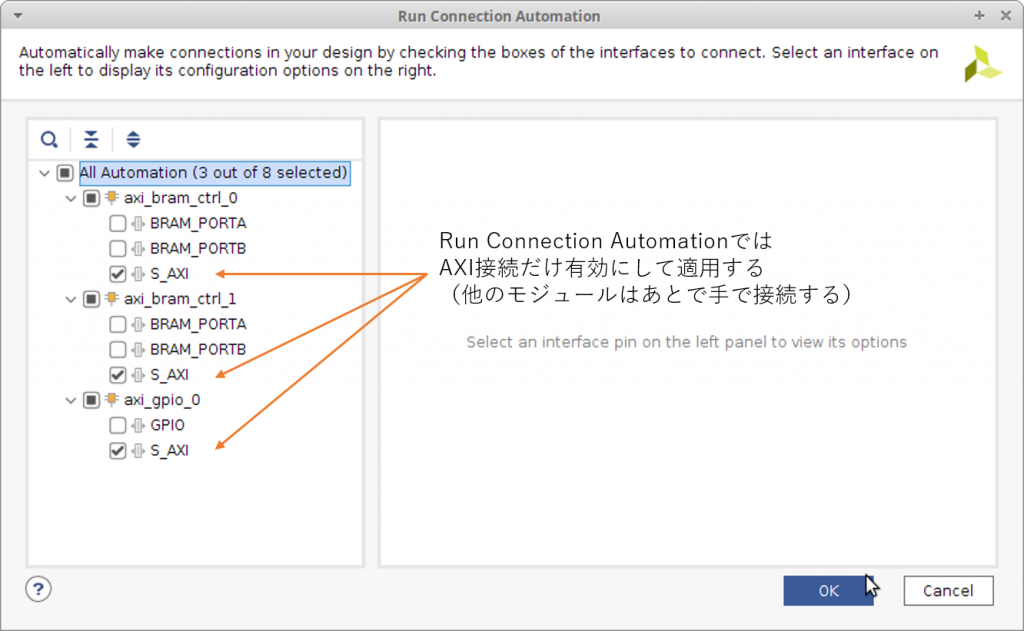
Run Block Automation で PS の設定をおこない、Run Connection Automation で AXI 関連の接続をします。AXI BRAM と AXI GPIO の接続はあとで自分で設定したいので、ここでは AXI の接続だけ自動接続に任せます。
AXI BRAM で利用するポートの数を1ポート、BRAM のモードを True Dual Port に変更します。
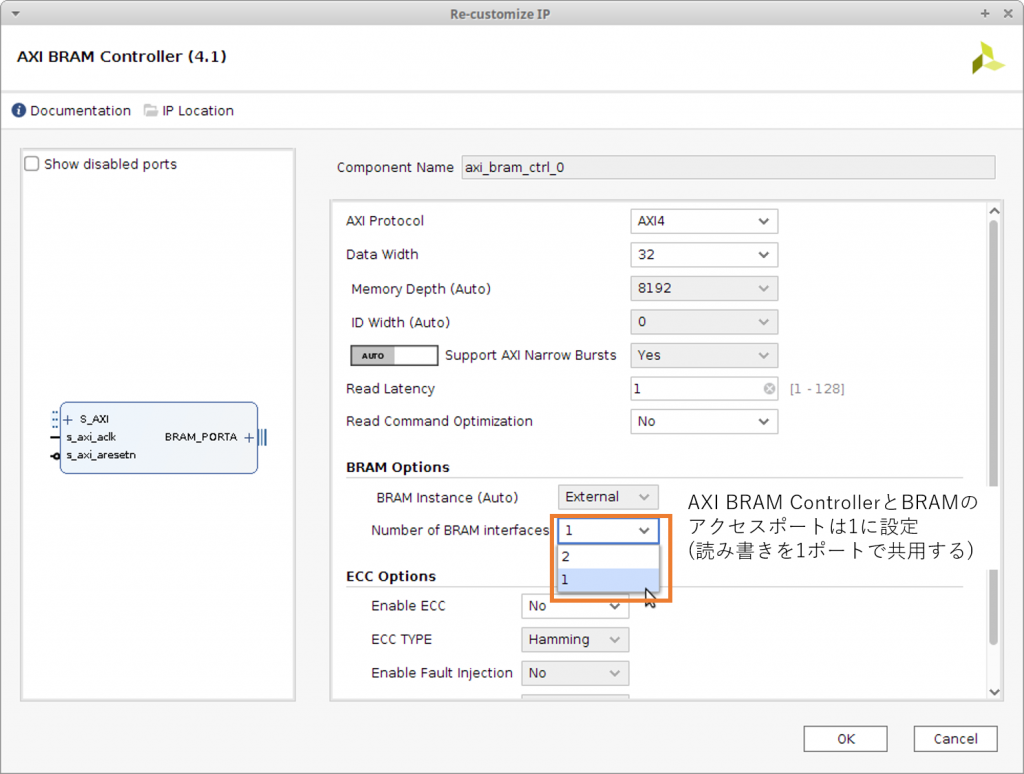
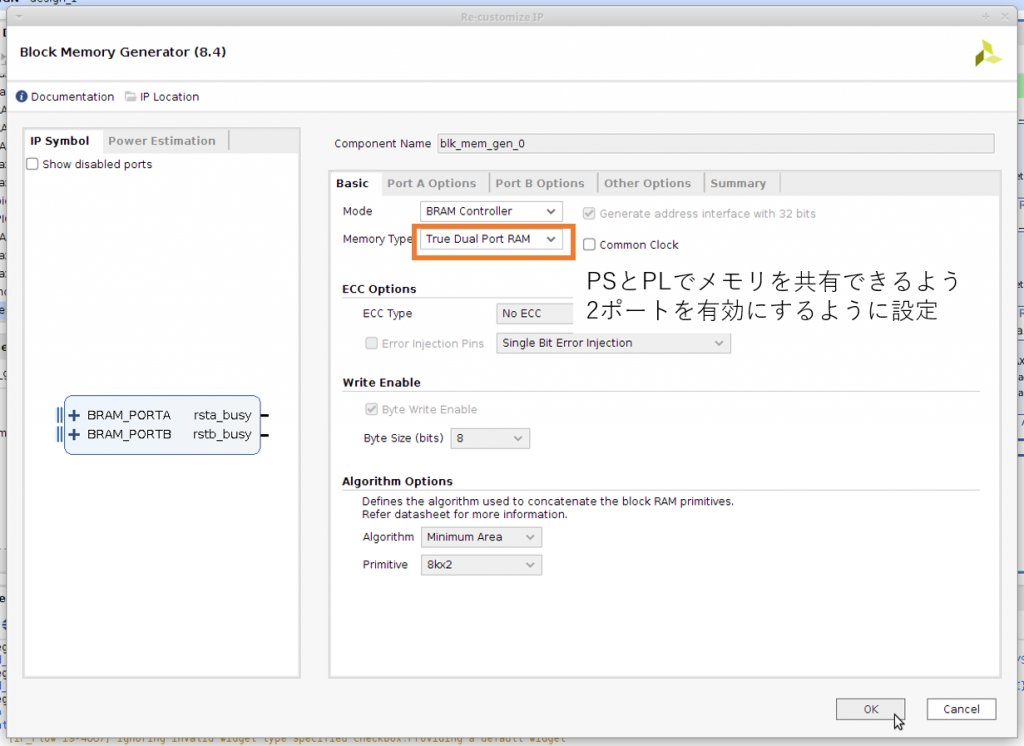
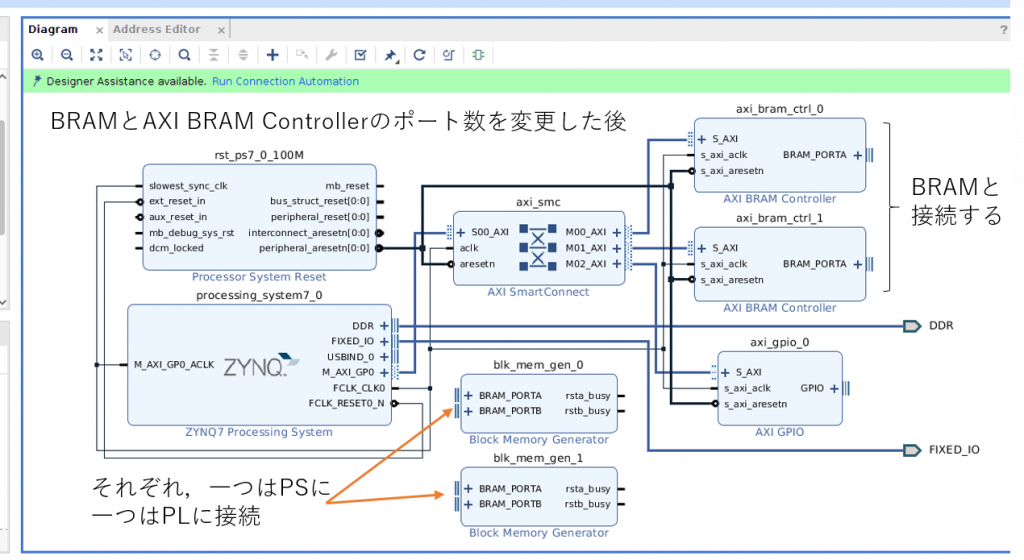
一通りの作業が終わると下のようなデザインができあがります。
動作確認用のサンプルロジックとして片方の BRAM からもう一方の BRAM にデータをコピーするモジュール (bram_copy.v) を用意しました。このモジュールをプロジェクトに登録して IPI 上のインスンタンスとしてデザインに組み込みます。
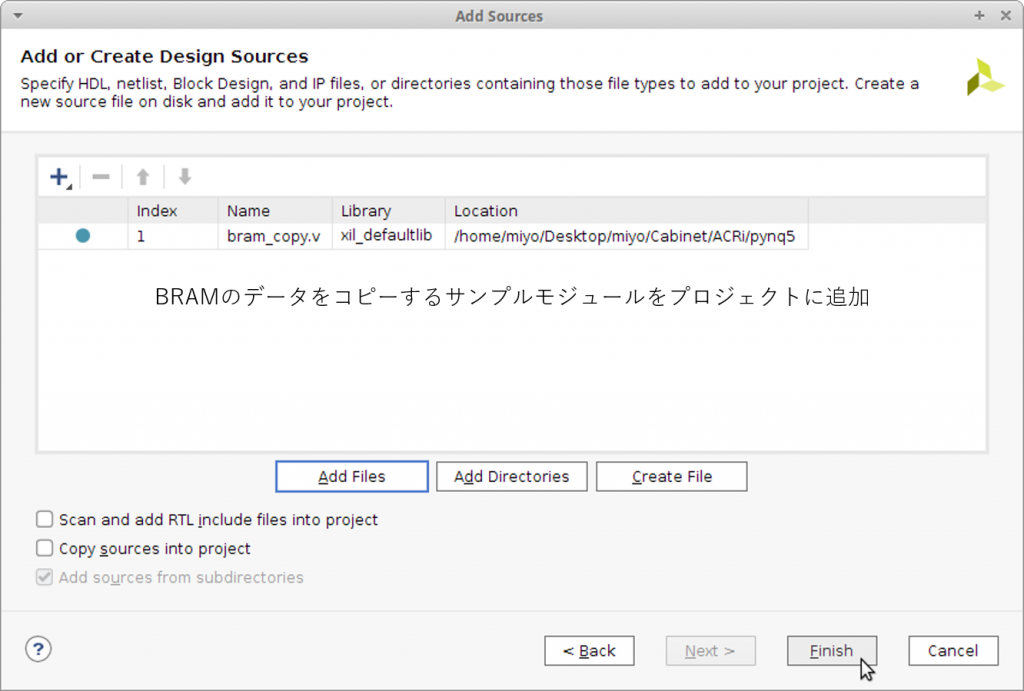
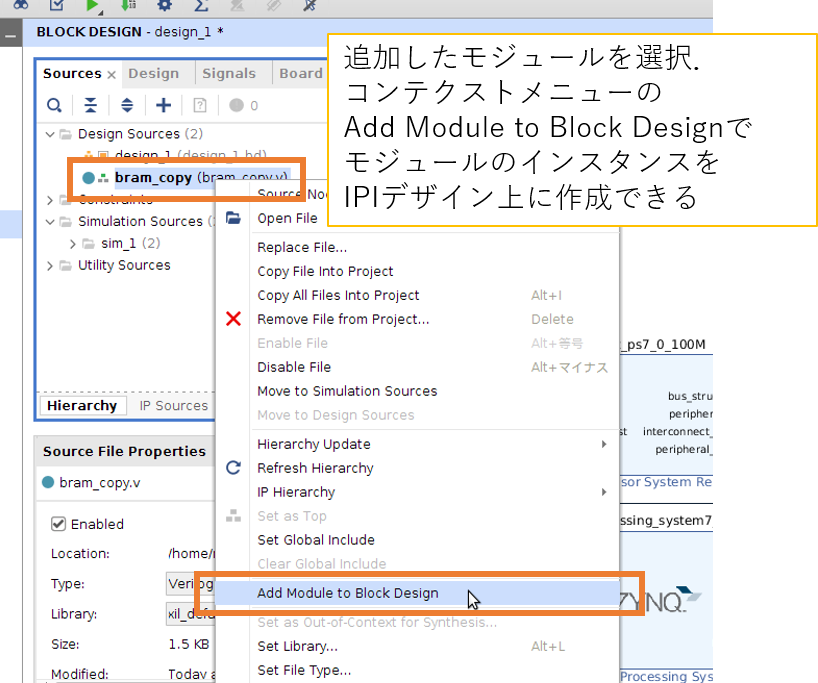
最終的なデザインは次のようにできあがりました。
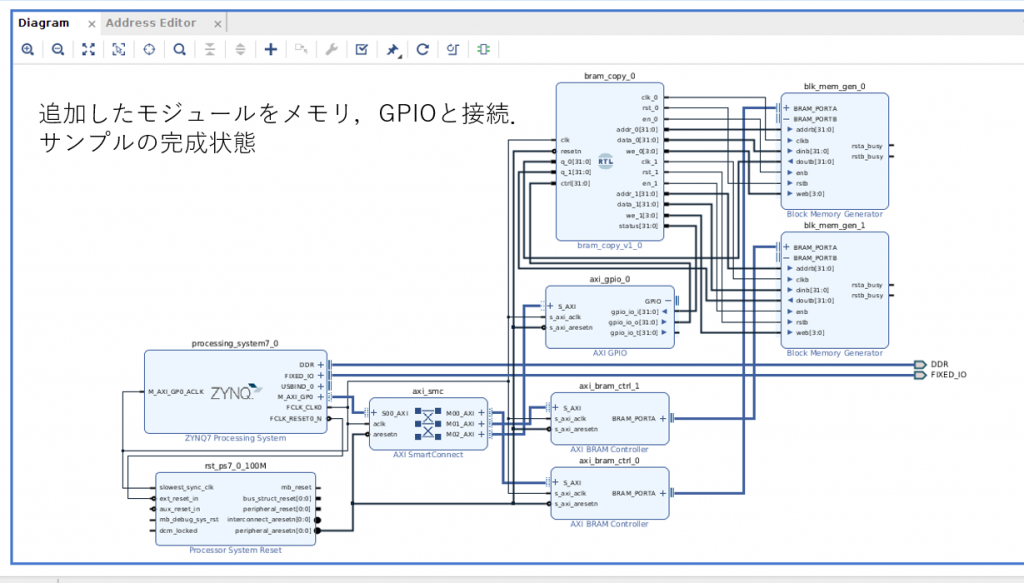
Create HDL Wrapper で作成したブロックデザインのラッパーモジュールを生成、トップモジュールに指定して Generate Bitstream で合成すると最終的に、PYNQ での動作に必要な
- pynq_overlay_bram.runs/impl_1/design_1_wrapper.bit
- pynq_overlay_bram.srcs/sources_1/bd/design_1/hw_handoff/design_1.hwh
の二つのファイルが得られます。
Jupyter Notebook で動作確認
Jupyter Notebook を使って PYNQ にアクセスします。新しく作業フォルダを作って、作成した design_1_wrapper.bit と design_1.hwh をアップロードしましょう。アップロードが終わったら、design_1_wrapper.bit の名前を design_1.bit に変更します。
新しく Python スクリプトを生成して以下のスクリプトを入力し、実行します。
from pynq import Overlay
from pynq import MMIO
base = Overlay("./design_1.bit")
bram0 = MMIO(base_addr = base.ip_dict['axi_bram_ctrl_0']['phys_addr'], length = 8*1024)
bram1 = MMIO(base_addr = base.ip_dict['axi_bram_ctrl_1']['phys_addr'], length = 8*1024)
ctrl = MMIO(base_addr = base.ip_dict['axi_gpio_0']['phys_addr'], length = 0x1000)
for i in range(128):
print(bram0.read(4*i)) # 初期値(0)が表示されるはず
for i in range(128):
bram0.write(4*i, i)
for i in range(128):
print(bram0.read(4*i)) # 書き込んだ値が表示されるはず
for i in range(128):
print(bram1.read(4*i)) # この時点ではbram1は初期値(0)が表示されるはず
ctrl.write(4, 0) # AXI GPIO経由でCTRLに書き込む準備
ctrl.write(0, 1) # AXI GPIO経由でCTRLに書き込む
ctrl.write(4, 0xFFFFFFFF) # AXI GPIO経由でステータスを読み込む準備
while ctrl.read(0) < 128:
pass
for i in range(128):
print(bram1.read(4*i)) # PLでbram0→bram1とコピーできた無事、ソフトウェアから PL 上の BRAM にデータを書き込み、PL 上のロジック (BRAM から BRAM にデータをコピーするロジック) でデータを利用できることを確認できます。
PS → PLの性能の目安を知っておこう
PS から PL 上のメモリへのアクセスは read あるいは write メソッドで実行されます。目安として転送速度を測定しておきましょう。ここでは、以下のような簡単なスクリプトで実験してみました。
import time
LOOP = 1024
SIZE = 2048
sum = 0
t0 = time.time()
for l in range(LOOP):
for i in range(SIZE):
sum = bram0.read(4*i) # bramから読んだ値を足し込む
t1 = time.time()
print("Read:", (t1-t0), "sec")
print("Throughput:", float((LOOP*SIZE)*4) / float(t1-t0), "Bps")
print(sum)
t0 = time.time()
for l in range(LOOP):
for i in range(SIZE):
bram0.write(4*i, i) # bramに値を書き込む
t1 = time.time()
print("Write:", (t1-t0), "sec")
print("Throughput:", float((LOOP*SIZE)*4) / float(t1-t0), "Bps")実行してみると、PL の BRAM からの読み込みと BRAM への書き込みのスループットは、それぞれ 200KBps と 150KBps 程度でした。なお、Python のリストの読み書き速度は約 2.5MBps でしたので 1/10 から 1/15 程度の速度であると言えそうです。
PL から PS に接続されたメモリを読み書きする
この方法では、PS に接続された DRAM のデータを PL が読み書きすることで、PS と PL がデータを共有します。PL 上のロジックが、HP ポートあるいは ACP ポートを介して主体的にデータを読み書きします。
主なメリットは次の3つです。
- DRAM を利用するので大きなサイズのデータの共有がしやすい
- HP ポートあるいは ACP ポートの転送速度は GP ポートの転送速度より速い
- データ転送にソフトウェアを介在する必要がない
主なデメリットも3つあります。
- PL 上のロジックとしてデータを読み書きする仕組みを実装する必要がある
- PS 上の Linux がメモリを使っているので好きなアドレスを読み書きしていいわけではない
- プロセッサのキャッシュの仕組みを知る必要がある (ACP を使う場合)
設計が多少複雑にはなりますが、実用的なアプリケーションの実装では速さは重要です。たとえば、PYNQ のサンプルの中では、HDMI で入出力する画像をハンドリングするようなアプリケーションでは PL から PS に接続された DRAM へのアクセスが利用されています。
デメリットの1つ目については、AXI DMA という Xilinx の提供する IP コアを利用することで、(a) メモリを連続的に読み出してロジックに供給する、(b) ロジックの出力をメモリに連続的に書き出す、という機構を簡単に実現できます。デメリット2つ目については、PYNQ の DMA ライブラリを使うことで見通しよくプログラムを書けるので、慣れてしまえば問題になりません。デメリットの3つ目については、プロセッサのキャッシュの仕組み及びキャッシュを考慮したプログラミングの知識が必要です。たいていの場合は HP で事足りますので、まずは考えないことにしましょう。
PS に接続されたメモリのデータを PL から読み書きしてみる
実際に、AXI DMA を使って PL から PS に接続されたメモリを動かすサンプルプロジェクトを作って動作を確認してみましょう。開発の流れは、先程と同様、
- ハードウェア側: Vivado でプロジェクトを作り IPI を使ってロジックデザインを設計、合成してビットストリームと hwh ファイルを得る
- ソフトウェア側: Jupyter Notebook でビットストリームなどをアップロード、Python プログラムで動かしてみる
というハードウェア側の準備とソフトウェア開発の二段階です。
ハードウェア側の準備
プロジェクトの作成方法は先程と同じです。PYNQ-Z1 のボードファイルを使ってプロジェクトを作成しましょう。プロジェクト名は pynq_overlay_dma としました。
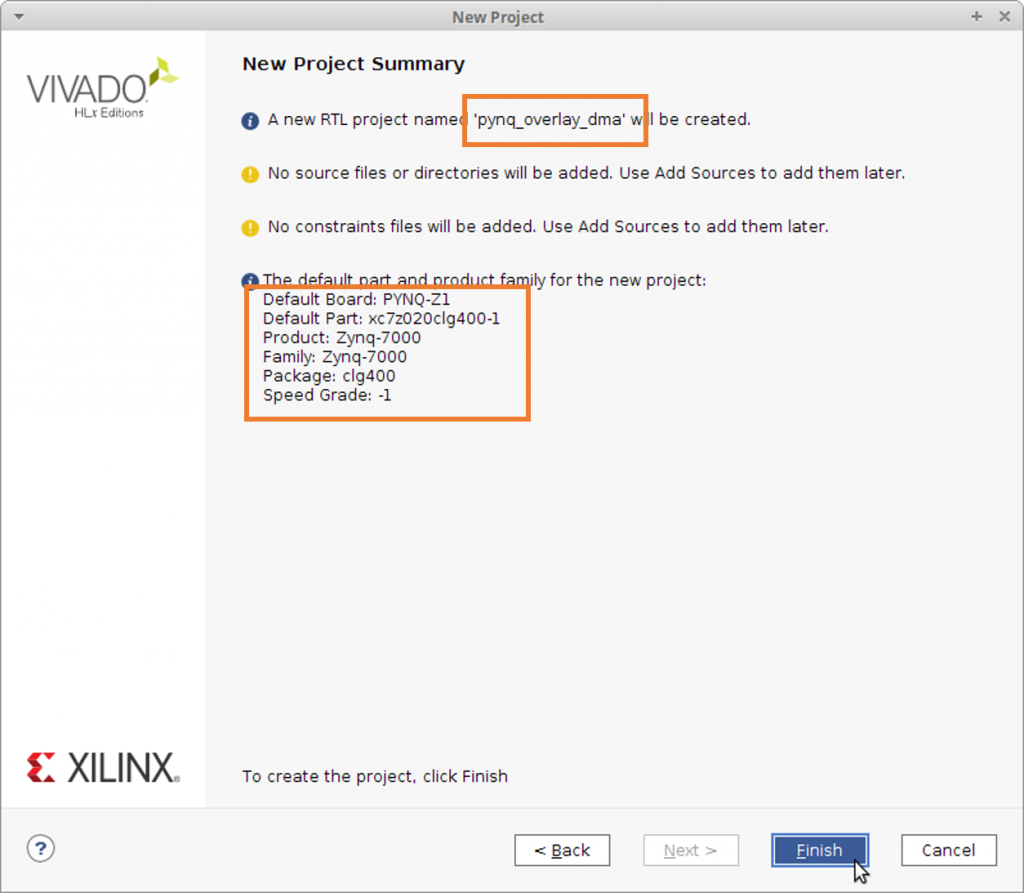
IPI を起動しデザインを設計しましょう。PS と、AXI DMA のインスタンスを生成します。AXI DMA に似た名前の IP に AXI Video DMA というものがあります。これはビデオ信号を便利に扱うためのモジュールですので間違えないようにしてください。
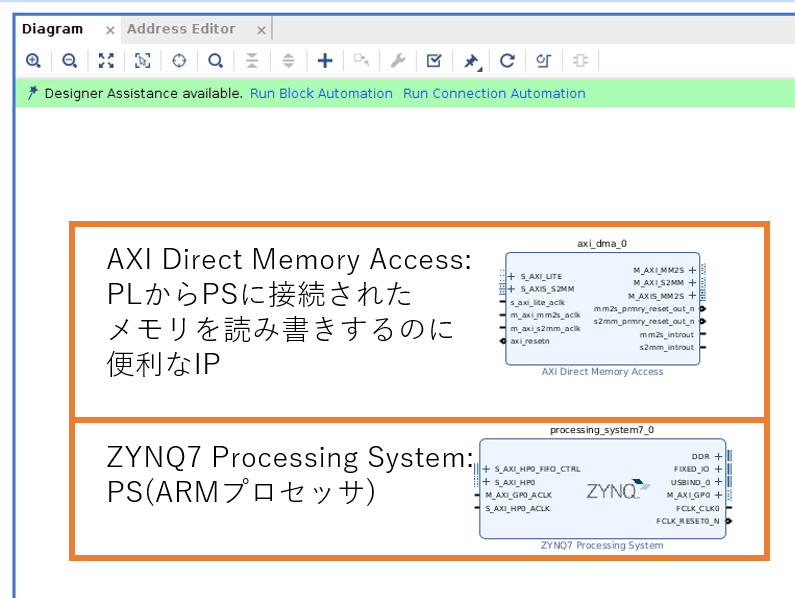
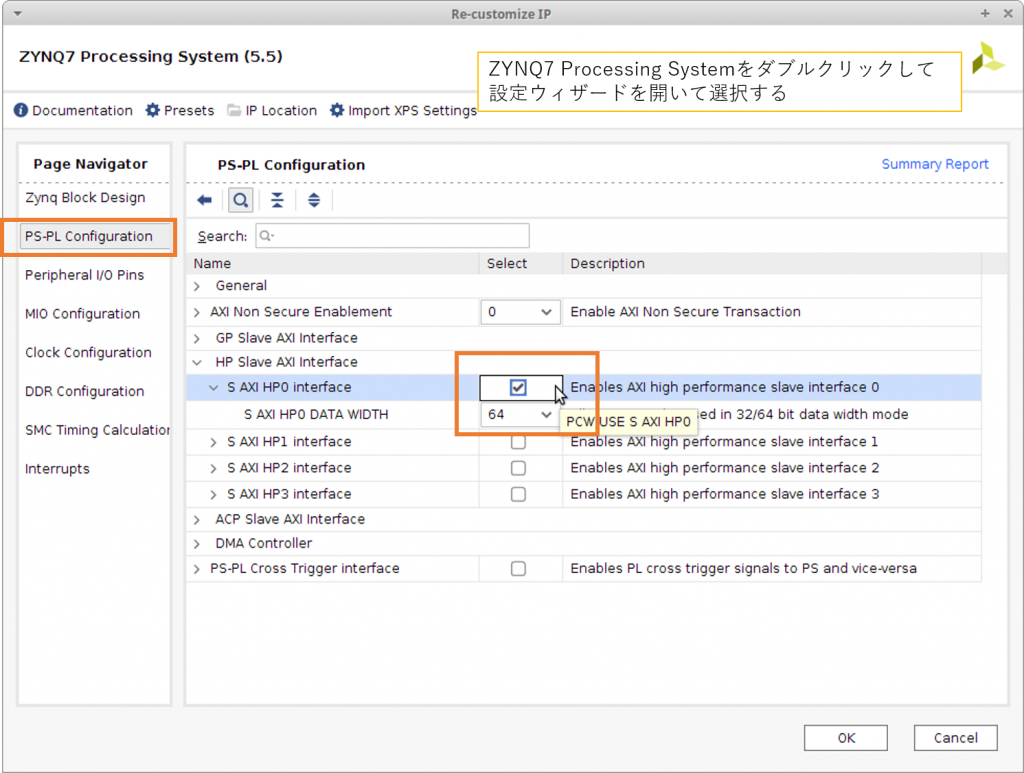
Run Block Automation で PS の設定をおこなった後で、PL から PS のメモリにアクセスするための HP ポートを有効にします。ZYNQ7 Processing System のインスタンスをダブルクリックして設定ダイアログを開き、PS-PL Configuration の HP Slave AXI Interface の下にある S AXI HP0 Interface のチェックを有効にします。データ幅は 32bit と 64bit から選択できますが、今回はデフォルトの 64bit 幅のまま使用します。
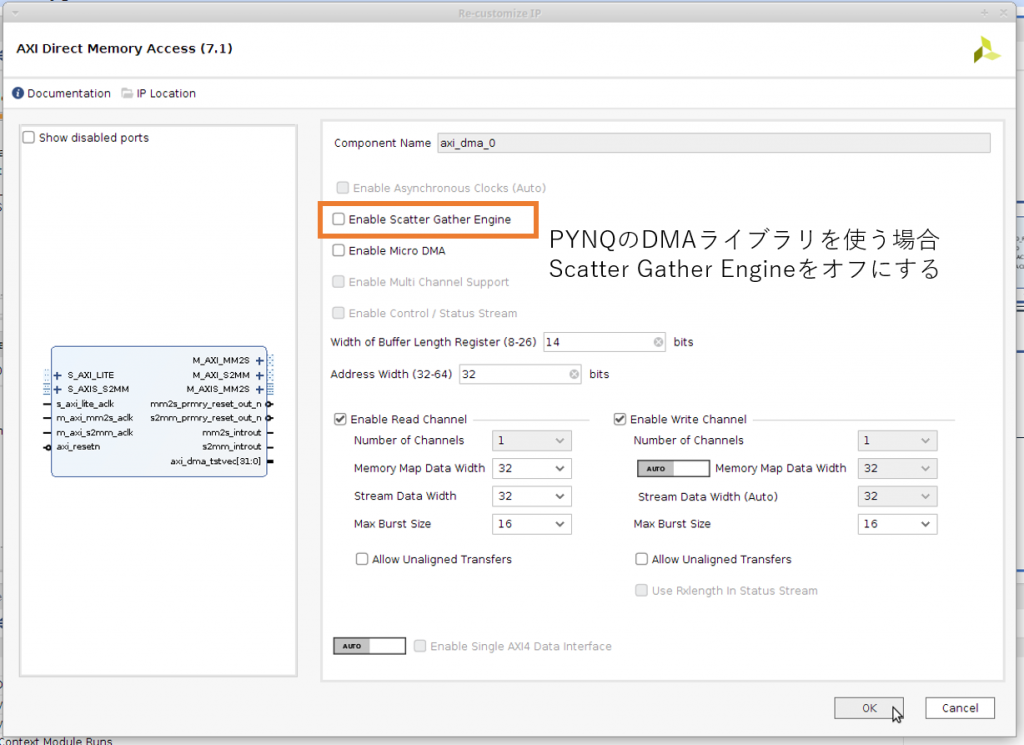
また、PYNQ の DMA ライブラリは AXI DMA のシンプルモードというモードにのみ対応しています。デフォルトで Scatter Gather DMA というモードに設定されているので解除する必要があります。
HP ポートの有効化と AXI DMA のモード変更を終えたら Run Connection Automation で AXI 関連の接続をします。ここまで設定すると下のようなデザインができあがりました。
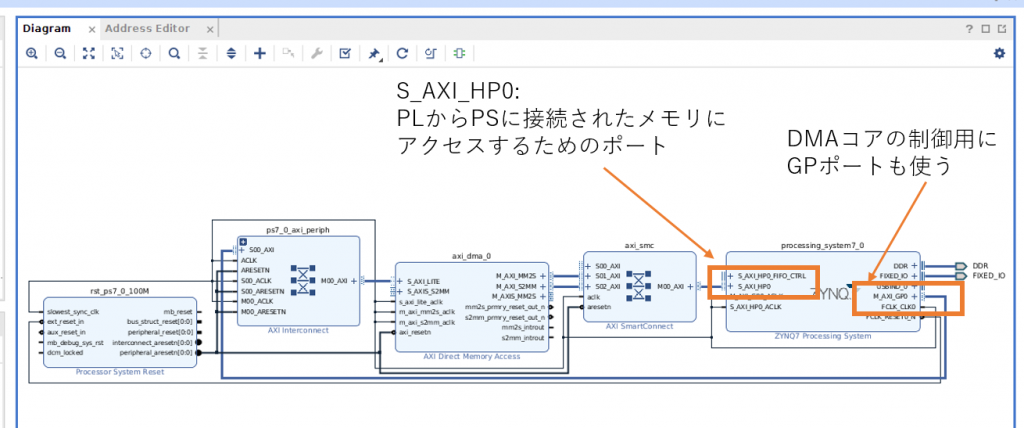
AXI DMA IP コアが大部分を吸収してくれているので、見かけ上の設計はとてもシンプルに見えますね。
動作確認用のモジュールとして連続データを受け取って、値を2倍して出力するモジュール (stream_double.v) を用意しました。このモジュールをプロジェクトに登録して IPI 上のインスンタンスとしてデザインに組み込みます。
最終的なデザインは次のようにできあがりました。
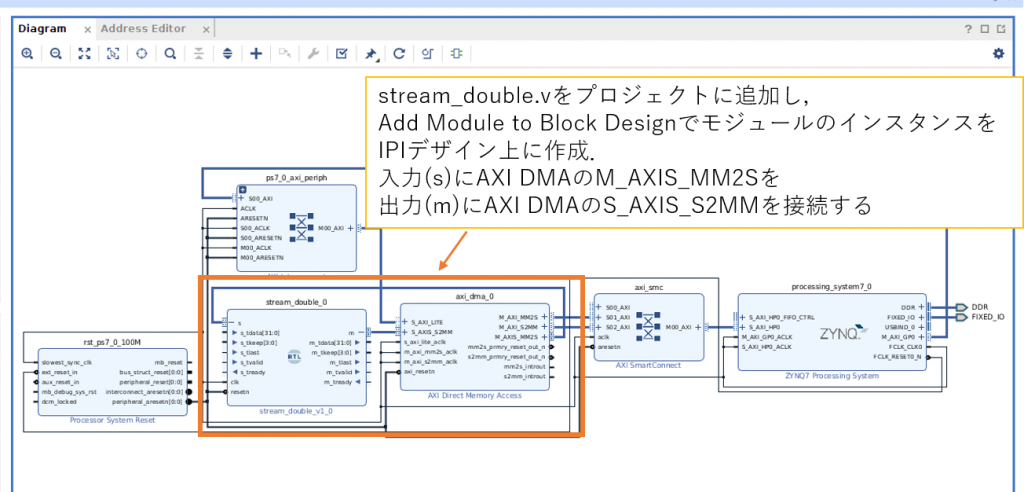
Create HDL Wrapper で作成したブロックデザインのラッパーモジュールを生成し、トップモジュールに指定して Generate Bitstream で合成すると最終的に、
- pynq_overlay_dma.runs/impl_1/design_1_wrapper.bit
- pynq_overlay_dma.srcs/sources_1/bd/design_1/hw_handoff/design_1.hwh
の二つのファイルが得られます。
ソフトウェアで動作確認
デメリットの2つ目に挙げたように、PS に接続されたメモリは PS 上で動作している Linux で管理されています。そのため PL が好き勝手なアドレスにデータを読み書きするとシステムが正しく動作しなくなります。そこで、ソフトウェアで以下のように利用可能なデータ領域をハンドリングする必要があります。
- メモリ上にPLで使っていい領域を確保する
- 確保した領域のアドレスとサイズを PS から PL に通知する
- PL は通知された情報を使ってメモリを読み書きする
PYNQ ではこの一連のフローをまとめたDMAアクセス用のクラス _DMAChannel が実装されていて sendchannel/recvchannel というインスタンス変数でアクセスできます。そのため次のような Python スクリプトで DMA の動作を確認することができます。
from pynq import Overlay
from pynq import MMIO
base = Overlay("./design_1.bit")
dma = base.axi_dma_0 # AXI DMA を操作するハンドラ
from pynq import allocate # 利用可能な領域を確保するメソッドを利用可能にする
import numpy as np
input_buffer = allocate(shape=(5,), dtype=np.uint32) # Numpy の配列からデータ受け渡し用の領域を確保
output_buffer = allocate(shape=(5,), dtype=np.uint32) # Numpy の配列からデータ受け渡し用の領域を確保
for i in range(5):
input_buffer[i] = i # 適当に値を代入
print(input_buffer) # [0 1 2 3 4] と表示される
print(output_buffer) # [0 0 0 0 0] と表示される
# PL にデータを読み込ませる指示(ソフトウェアからみると PL へのデータの送信に相当)
dma.sendchannel.transfer(input_buffer)
# PL にデータを書き込ませる指示(ソフトウェアからみると PL からのデータの受信に相当)
dma.recvchannel.transfer(output_buffer)
# PL での動作の終了を待つ
dma.sendchannel.wait()
dma.recvchannel.wait()
print(output_buffer) # [0 2 4 6 8]と表示され PL でデータが処理されたことがわかるPYNQ のソースコード (pynq/lib/dma.py) を見てみると、sendchannel/recvchannel のクラス _DMAChannel に定義された transfer メソッドで、下記のように引数 (array) に与えたデータ領域のアドレスとサイズを AXI DMA の設定レジスタに書き込んでいることがわかります。
self._mmio.write(self._offset + 0x18, array.physical_address)
self._mmio.write(self._offset + 0x28, array.nbytes)AXI DMA の使い方を詳しく知りたい方は、Xilinx の ドキュメントを参照してみてください。
PL → PS の性能の目安を知っておこう
次のような簡単なスクリプトでPLからメモリの読み書きをするときの転送性能を測定してみました。
import time
SIZE=8192 # 転送バイト数。
LOOP=1024 # 繰り返し回数
t0 = time.time()
for l in range(LOOP):
# 測定の本体
input_buffer = allocate(shape=(SIZE//4,), dtype=np.uint32) # 領域の確保
output_buffer = allocate(shape=(SIZE//4,), dtype=np.uint32)
dma.sendchannel.transfer(input_buffer) # PL に `input_buffer` からデータを読み込ませる
dma.recvchannel.transfer(output_buffer) # PL に `output_buffer` にデータを書き込ませる
dma.sendchannel.wait()
dma.recvchannel.wait()
t1 = time.time()
print("Elapsed time:", t1-t0)
print("Throughput:", (SIZE*LOOP) / 1024 / 1024 / (t1-t0), "MBps")
print(input_buffer)
print(output_buffer)結果は 4.5MBps 程度でした。
まとめ
今回は、実用的なアプリケーションを作るために必須の PS と PL でのデータ共有について二つの方法と使い方を紹介しました。データ共有ができれば、ソフトウェア処理の好きな部分を PL にオフロードしたり、PL の入出力を利用して集めたデータを PS で活用するといった使い方が簡単にできます。利用した IP コアの詳細についての説明はだいぶ省略しました。詳しく知りたい人は参考資料にあげた URL にアクセスしてみてください。
5回に渡って Python で FPGA を手軽に利用できる PYNQ とその活用方法を紹介してきました。ちょっとしたロジックを作って使ってみたいな、という場合や、FPGA 向けの ロジックをソフトウェアプログラマにも簡単に使って欲しいな、という場合のプラットフォームとして是非 PYNQ を使ってみてください。
参考資料
- PYNQのWebページ http://www.pynq.io/
- GitHubで公開されているPYNQのソースコード https://github.com/xilinx/pynq
- PYNQのドキュメント https://pynq.readthedocs.io/en/latest/index.html
- PYNQ Workshop(スライド多数) https://github.com/Xilinx/PYNQ_Workshop
- AXI DMA Controller https://japan.xilinx.com/products/intellectual-property/axi_dma.html
- AXI BRAM Controller https://japan.xilinx.com/products/intellectual-property/axi_bram_if_ctlr.html
- AXI General Purpose IO https://japan.xilinx.com/products/intellectual-property/axi_gpio.html
わさらぼ・みよしたけふみ