
自作回路を PYNQ から使うための設計・開発法に関するコースの第4回です。今回は、「AXI でプロセッサとつながる IP コアを作る (5)」で紹介したステンシル計算コプロセッサを再び取り上げ、IP コアがフル機能の AXI をもつ場合の設計のポイントを確認します。前述の記事でも、ハードウェア実装とソフトウェア実装 (C 言語による) とを比較してみましたが、Python ではどうでしょうか。
本コースで使用したハードウェア記述 (一部ソフトウェアも含む) は、GitHub リポジトリ上で公開しています。今回のハードウェア (PL) 部分のソースコードは以前に公開したものと同じです。今回新たに Python のスクリプト例も掲載しました。
PYNQ と仮想記憶
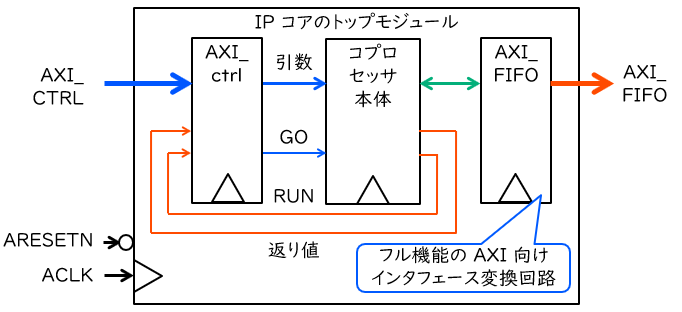
「AXI でプロセッサとつながる IP コアを作る (4)」で説明した典型的なコプロセッサ IP コアの構成図を、ここで再掲します。AXI-Lite のインタフェース回路は、プロセッサから引数や動作開始の命令を書き込んだり,返り値を読み出したりするために使用します。対して、フル機能の AXI は、PS のメモリへのアクセスを自発的に行うためのものです。
当然ながら、PS のメモリにアクセスするためには、必要なデータがどこにあり、どこに書き込まれなければならないかを知っている必要があります。つまり、必要なデータや書き込み先へのポインタが必要です。「AXI でプロセッサとつながる IP コアを作る (5)」では OS のない (スタンドアロン) 環境でソフトウェアを動作させていたため、単にアプリケーションが知っているポインタの値を IP コアに渡せば、それで問題ありませんでした。
しかし、今回使用している PYNQ プラットフォームでは、メモリは仮想記憶という仕組みによって OS の管理下に置かれています。PYNQ 上では OS (具体的には、Ubuntu ベースの PYNQ Linux) が動作しています。ここではメモリはシステム上での共有資産ですので、各アプリケーションが好き勝手に全てのメモリにアクセスできてしまっては困るわけです。
仮想記憶の概念を表したものが下図です。仮想記憶のもとでは、メモリは一定サイズのブロック (ページという) 単位で管理されています。OS は各アプリケーションにとってのメモリアドレス (論理アドレス) とハードウェアにとってのメモリアドレス (物理アドレス) の対応表を持っており、プロセッサはその一部を TLB とよばれる一種のキャッシュに保存しています。プロセッサがメモリにアクセスする際には、この情報をもとに自動的にメモリアドレスを変換してから、ハードウェアのメモリにアクセスします。アプリケーションはそれぞれ個別の論理アドレス空間をもっていて、OS の力を借りない限り、他のアプリケーションの論理アドレス空間にアクセスすることはできません。これにより、メモリの保護や効率的な利用を達成しているわけです。
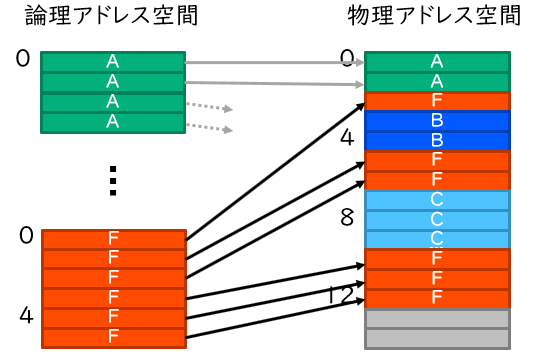
さて、PL が PS のメモリにアクセスするために必要なのは、この物理アドレスの方です。しかし、論理アドレスから物理アドレスへの変換は OS が管理していますので、アプリケーションが自身で確保したメモリ領域に対する物理アドレスを、アプリケーションは知ることができません。つまり、OS やライブラリの力を借りて、特別なメモリ領域を確保する必要があるわけです。
……そろそろ種明かしをしましょう。実は、第3回で紹介した PYNQ の allocate メソッドこそ、物理アドレスに紐付けられたメモリ領域を確保するためのメソッドです。このメソッドによって作成された領域は、一見 NumPy の ndarray クラスのインスタンスであるかのように見えますが、実際にはこれを継承した PYNQ の PynqBuffer クラスのインスタンスです。このクラスには device_address という変数があり、この変数がその領域の先頭の物理アドレスを表します。PYNQ において PL が自発的に PS にアクセスしたければ、このアドレスを教えてあげればよいのです。
オーバーレイの作成
今回は、「AXI でプロセッサとつながる IP コアを作る (5)」で定義したステンシル計算を再び題材にします。ここで改めて計算の定義を確認しておきましょう。
- 配列は N x N の2次元配列
- 配列の各要素は 32 bit の符号なし整数
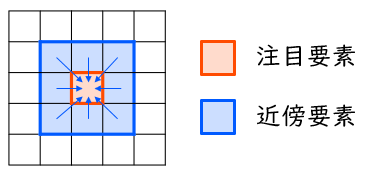
- ⾃要素の新しい値は、⾃要素とその近傍8要素の値の平均値 (下図参照。端数は切捨て) とする
- 外周要素は0で固定とする
- (4, 4) 要素は
0x0fffffffで固定とする - 配列のいくつかの要素には、初期値として決まった値が書き込まれているとする
先の記事では、このステンシル計算を効率よくハードウェア実装するための演算パイプラインを設計し、SystemVerilog で記述し、シミュレーションで動作検証した後で IP コアへとパッケージし、これを含むシステムを構築しました。
今回は、PL 部の設計は PYNQ を使わない場合と全く一緒です。つまり、IP コアの構築、いやそれどころか、Vivado を使う作業は全て先の記事と同様に行います。もし過去に作業したプロジェクトが残っているようでしたら、そのプロジェクト内の .bit ファイルと .hwh ファイルを取り出し、適当にリネーム (以下では stencil.bit と stencil.hwh とします) して、PYNQ のオーバーレイとして必要なファイルを抽出してください。
そうでない場合には、おおむね以下の手順で .bit ファイルを生成してから、同様の作業を行ってください。
- ステンシル計算コプロセッサの IP コア一式のディレクトリを GitHub リポジトリからダウンロードする。
- PYNQ-Z1 向けにプロジェクトを作成し、IP Repository に stencil ディレクトリを登録する。
- ブロック図を新規作成し、PS と IP コアとを追加し、Run Block Automation と Run Connection Automation をそれぞれ行う。
- ブロック図からファイルを Generate し、HDL Wrapper を作成し、Generate Bitstream を行う。
PYNQ 上でのコプロセッサの評価
ここからは PYNQ 上での作業です。「AXI でプロセッサとつながる IP コアを作る (5)」で Vitis と C 言語を使って行ったのと同じように、今度は Python によるソフトウェアを記述して、性能を比較してみましょう。オーバーレイに必要なファイルは、今までと同じ要領で、あらかじめ PYNQ にアップロードしているものとします。
ソフトウェア実装(ナイーブ)
まずは、先の記事で紹介した C 言語による実装を参考に、コードを Python に移植してみます。この場合、ステンシル計算のプログラムは、例えば以下のように記述できます。ただし、初期化 init_buf と結果表示 printresult の各関数は別途定義されているものとします。
import numpy as np
def stencil_soft(src, dst, coproc):
for y in range(1, N - 1):
for x in range(1, N - 1):
dst[y, x] = (src[y-1, x-1] + src[y-1, x] + src[y-1, x+1] +
src[y , x-1] + src[y , x] + src[y , x+1] +
src[y+1, x-1] + src[y+1, x] + src[y+1, x+1]) // 9
dst[4, 4] = 0x0fffffff
buf1 = np.ndarray((N, N), dtype=np.uint32)
buf2 = np.ndarray((N, N), dtype=np.uint32)
init_buf(buf1) # バッファを指定された値で初期化
init_buf(buf2)
for i in range(ITER):
stencil_soft(buf1, buf2, None)
buf1, buf2 = buf2, buf1
printresult(buf1) # 結果を表示
C 言語と Python とではだいぶ記法が異なりますが、stencil_soft の部分はおおむね同様のプログラムになっていることが見て取れるかと思います。C 言語の場合は引数を入れ替えながら1ループにつき2回のステンシル計算を実行していましたが、Python の場合は単に17行目のように記述するだけで変数やポインタの入れ替えが可能ですので、それを使って1ループにつき1回のステンシル計算を行う記述としています。
さて、このプログラムを PYNQ-Z1 上で動かしてみようと思いますが……初めに言っておきます。残念ながら、とても遅いです。 上記のプログラムに計算時間を測定するコードを追記して、手元の PYNQ-Z1 で実行した結果を、下図に示します。配列サイズ N は 512 (1辺あたり)、繰り返し回数 ITER は100とします。
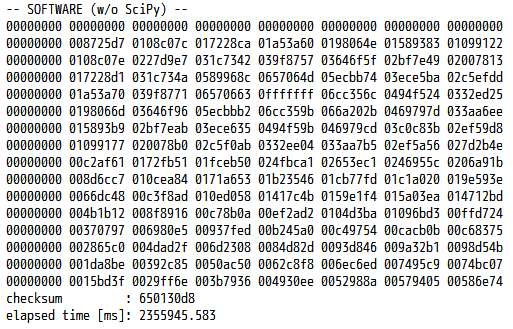
チェックサムは 650130d8 で C 言語版と一致していますので、計算自体は正しく行えています。しかし実行時間を見てみると、およそ 2,355,946 ミリ秒……つまり、40分近く (!)かかっています。C 言語での実装と比べても600倍以上低速です。NumPy の配列要素を直接操作するのには相応のオーバーヘッドがかかりますので、単に C 言語のプログラムの通りに記述したのでは、性能的にまったく使い物にならないプログラムが出来上がってしまうのです。
ソフトウェア実装(SciPy使用)
流石にこれをハードウェア実装と比べるのは、不公平に過ぎるというものです。ということで、Python を使うからには先人たちの力、ライブラリの力を借りましょう。Python で科学技術計算を行うための定番ライブラリに SciPy があり、PYNQ にも最初からインストールされています。
今回扱っているステンシル計算は、2次元の畳み込み (Convolution) 演算の一種といえます。画像処理でよく用いられるニューラルネットワークに CNN (Convolutional Neural Network) がありますが、この C も「畳み込みの」という意味です。数学的には畳み込み演算は積分で表されますが、今の文脈では注目要素とその近傍要素との間で重み付きの和を求める計算のことを言います。畳み込む配列 (行列) が 3 x 3 の全要素が1である配列の場合、注目要素とその近傍要素との値を合計した値が、演算結果における注目要素の値として得られます。
SciPy で2次元配列に対して畳み込み演算を行うメソッドは、convolve2d です。これを使って、今回扱っているステンシル計算を実現するプログラムを記述すると、例えば以下に示すプログラムとなります (メインルーチンは先ほどと同様なので省略) 。
import numpy as np
from scipy.signal import convolve2d
WEIGHT = np.ones((3, 3), dtype=np.uint32)
def stencil_scipy(src, dst, coproc):
dst[1:-1, 1:-1] = convolve2d(src[1:-1, 1:-1], WEIGHT, mode="same") // 9
dst[4, 4] = 0x0fffffff
あらかじめ、3 x 3 の、全要素が1である配列 (np.ones) を定数配列 WEIGHT として定義しておきます。そして、入力配列 src の外周要素を除く全ての要素について、WEIGHT との畳み込み演算を行い、演算結果の各要素を9で割り、その結果を出力配列 dst に上書きしています。
それでは、このプログラムにも同様に時間測定のコードを挿入し、PYNQ-Z1 上で動かしてみます。手元の PYNQ-Z1 で実行した結果は、下図に示す通りです。
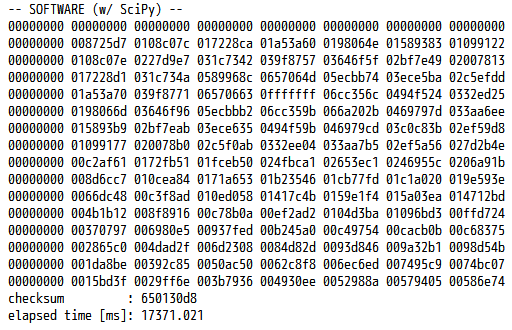
チェックサムは先ほどと一致しており,実行時間もおおよそ 17.37 秒へと大幅に短縮されました。それでも C 言語による実装よりもやや (5倍弱) 遅いですが、ハードウェア実装との公平な比較相手としては、許容範囲でしょう。
ハードウェア実装(コプロセッサ使用)
それでは本題です。PYNQ 上でステンシル計算コプロセッサを起動するプログラムを用意して、ステンシル計算をハードウェア処理させてみましょう。今回は、C 言語版との対応を取りやすくするため、専用のドライバクラスは作成せず、コプロセッサのメモリマップされたレジスタを直接読み書きすることにします。
ステンシル計算コプロセッサを用いたステンシル計算のプログラムは、例えば以下のように記述できます。ADDR_ から始まる定数は事前に定義されているものとします。
def stencil_hard(src, dst, coproc):
coproc.write(ADDR_SIZE, N)
coproc.write(ADDR_SRC, src.device_address)
coproc.write(ADDR_DST, dst.device_address)
coproc.write(ADDR_GO, 1)
while coproc.read(ADDR_DONE) == 1:
pass
coproc.write(ADDR_GO, 0)
while coproc.read(ADDR_DONE) == 0:
pass
pl = Overlay("stencil.bit")
coproc = pl.stencil_top_0
hbuf1 = allocate(shape=(N, N), dtype=np.uint32)
hbuf2 = allocate(shape=(N, N), dtype=np.uint32)
init_buf(hbuf1) # バッファを指定された値で初期化
init_buf(hbuf2)
for i in range(ITER):
stencil_hard(buf1, buf2, coproc)
buf1, buf2 = buf2, buf1
printresult(buf1) # 結果を表示
hbuf1.freebuffer()
hbuf2.freebuffer()
stencil_hard 関数はおおむね C 言語版に沿った記述になっていますので、「AXI でプロセッサとつながる IP コアを作る (5)」と照らし合わせながら確認してみてください。C 言語版と大きく異なる点は2つです。1つは、配列へのポインタを渡していた部分 (上記コードの3~4行目) で、device_address を使用している点です。もう1つは、中身のない while 文 (ビジーループ) を記述する際に、何もしないことを表す Python の文である pass を使用していることです (7, 10行目)。Python はインデントを重視する言語です。Python の文法上、コロンで終わる行の後には、インデントを1段増やした上で何かしら書かないといけません。ここでは、何もすることがないことを pass 文で明示する必要があるのです。
メインプログラムの変更点も2つあります。1つは PL にステンシル計算コプロセッサのオーバーレイを書き込んでおくこと (12行目) であり、もう1つは NumPy の ndarray ではなく PYNQ の allocate を使って、配列のためのメモリ領域を確保すること (14~15行目) です。確保した領域は、プログラムの末尾で freebuffer メソッドを呼び出して、間違いなく解放しておきましょう (22~23行目)。
それでは今度も時間測定のコードを挿入して動かしてみます。手元の PYNQ-Z1 では、下図に示す結果が得られました。
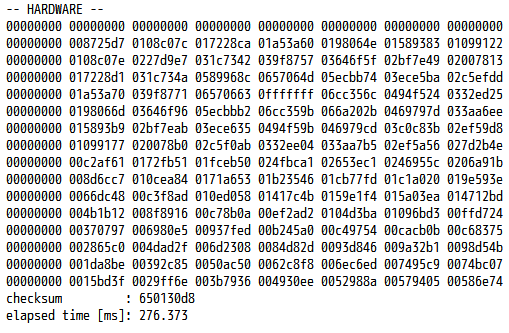
チェックサムはやはり一致しており、実行時間は約 276.4 ミリ秒となりました。先ほどの SciPy を用いたソフトウェア実装と比べると、62.84倍高速です。
また、C 言語でハードウェア実装のためのプログラムを書いた場合 (約 264.9 ミリ秒) と比べると、実行時間の増加は 4.3 % に抑えられていることも確認できました。この分は Python を使うことや、キャッシュの無効化にかかるオーバーヘッドと考えられます。ただ、計算の大部分はハードウェア処理に移されており、それにかかる時間は Vitis で C 言語を使っても PYNQ で Python を使っても変わらないのです。プログラムの記述のしやすさというメリットを考えれば、この実行時間の増加は許容できると言える場合が多いのではないでしょうか。
まとめ
今回は、IP コアがフル機能の AXI により PS のメモリに直接アクセスする場合の例を扱いました。今回のポイントを以下にまとめます。
- PYNQ において IP コアから直接アクセスされるメモリ領域 (バッファ) は、PYNQ の
allocateメソッドを使って確保する - バッファの物理メモリアドレスは、確保したバッファの
device_address変数を読み出すことで取得できる。
最終回では、IP コアを Vivado (Vitis) HLS を使った高位合成で作成する場合の設計例について紹介します。
愛知⼯業⼤学 藤枝直輝