
はじめに
この連載では、Amazon EC2 F1 インスタンスの FPGA を使ってアクセラレーションを体験してみます。これまでの記事では準備編として FPGA 開発環境や F1 インスタンスの立ち上げ方法を紹介しました。この記事ではいよいよ FPGA を動かしてみます。
Vitis ライブラリ
今回はザイリンクスがオープンソースで提供する Vitis ライブラリを利用して、FPGA によるアクセラレーションを体験します。

Vitis ライブラリは次の8つの分野を対象に、C++ で実装された再利用可能なハードウェア部品を提供します。ライセンスは Apache License 2.0 なので商用利用も可能です。
- BLAS (線形代数演算)
- ソルバー (行列分解、線形ソルバー、固有値ソルバー)
- データ圧縮
- データベース
- 信号処理
- 数理ファイナンス
- セキュリティ (暗号、ハッシュ)
- ビジョン (画像処理)
アクセラレータの開発では、対象となる計算を効率的に実行できるアーキテクチャを検討し、回路を設計、検証する必要があります。高位合成を使って C++ で効率的に設計・検証ができるとは言え、すべてをゼロから開発するのは簡単ではありません。参考となるコードや、再利用できる部品があればその分の労力を削ることができます。これはソフトウェアのオープンソースの考え方と同じですね。使えるものは有効活用していきましょう。
Vitis ライブラリの中から、比較的身近なデータ圧縮をテーマに選びます。
データ圧縮は、データを保存するドライブの容量を節約したり、ネットワークを介してデータを速く転送したりする目的で用いられます。メールで大きなファイルをやりとりするときに ZIP で圧縮して小さくしてから送ることがありますね。
圧縮でデータのサイズが小さくなるのは、データが持つ冗長性を利用して、データをよりコンパクトに表現するためです。このデータをコンパクトな表現に変換する手順を決めるのが、圧縮アルゴリズムです。ZIP では Deflate と呼ばれるアルゴリズムが使われています。Vitis ライブラリには Deflate アルゴリズムのハードウェア実装がありますので、これがどのようなものか簡単に見てみます。
Deflate のハードウェア実装
Deflate は LZ77 とハフマン符号から構成されます。Vitis ライブラリでは、LZ77 とハフマン符号に対応するそれぞれのカーネルが提供されています。
LZ77 カーネル
LZ77 は、過去に出現した文字列が再び現れたときに、その文字列を過去の出現位置と長さの符号に置き換えることでデータ全体の文字数を減らすアルゴリズムです。Vitis ライブラリの実装では次の図のような処理の流れになっています。

出現位置の検出において、過去の文字列を1文字ずつ調べていくやり方では文字を比較するためにたくさんのメモリアクセスが必要になり、1文字を処理するのに長い時間がかかってしまいます。Vitis ライブラリの実装では、4K エントリのハッシュテーブルに過去に出現した連続する3文字の位置を記憶しておき、このハッシュテーブルを引くことで高速に文字列の出現位置を求めます。現在注目している3文字がハッシュテーブルに存在すれば、文字と出現位置を次の処理に渡します。
一致長のカウントでは、32KB のメモリに過去の文字列を記憶しておき、文字と出現位置のペアが入力されたら、その出現位置以降の文字列と比較して一致長をカウントします。
LZ77 カーネルでは、ハフマン符号で必要となる、文字の出現頻度のカウントも行います。最後に、文字、出現位置、長さ、出現頻度が DRAM に書き出されます。
ハフマン符号カーネル
ハフマン符号は、データに含まれる文字の出現頻度の偏りを利用して、そのデータ全体を表現するのに必要なビット数を減らすアルゴリズムです。出現頻度の高い文字には短い (ビット数の少ない) 符号を割り当て、そうでない文字には長い符号を割り当てることで合計のビット数を減らします。Vitis ライブラリの実装では次の図のような処理の流れになっています。
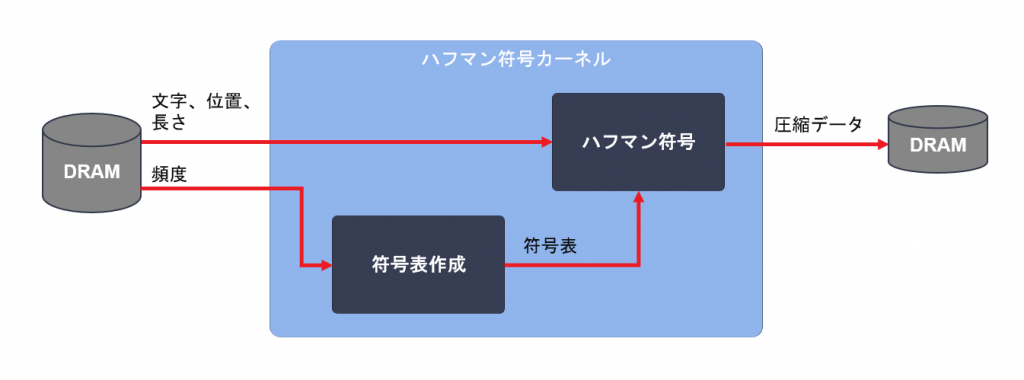
ハフマン符号カーネルでは、LZ77 カーネルでカウントした文字の出現頻度から、文字と符号の対応表 (符号表) を作成します。そしてこの符号表を使って LZ77 カーネルが出力した文字、出現位置、長さの情報を符号化していき、圧縮されたデータを DRAM へ書き出します。
並列化
Deflate ではデータをブロックに分割して、ブロックごとに独立して圧縮することができます。これによりデータの部分ごとに文字の出現頻度が変わる状況でも、ブロックで区切ることで部分ごとに適した圧縮を行うことができます。
このブロックごとに独立して圧縮できる性質を利用して、Vitis ライブラリの実装ではそれぞれのカーネルの中に8本のパイプラインを実装し、8個のブロックを並列に圧縮できるようにしています。
いずれのカーネルも主要なパイプラインは1文字を1サイクルで処理できるよう設計されています。カーネルを 250 MHz の周波数で動作させた場合、スループットの理論値は 1 byte/cycle * 250 MHz * 8 並列で 2 GB/s となります。
アプリケーションを実行してみる
Deflate のハードウェア実装がおおよそ分かったところで、実際に FPGA を動かしてみましょう。次のような流れとなります。
- Vitis ライブラリを入手して FPGA バイナリを生成する
- FPGA バイナリを AFI に変換する
- ホストプログラムを実行する
- CPU と比較する
Vitis ライブラリを入手して FPGA バイナリを生成する
FPGA バイナリとは、FPGA に読み込ませるイメージ (ビットストリーム) を含んだファイルで、拡張子は xclbin です。Vitis で生成します。
前回の記事で立ち上げた F1 インスタンスで作業を進めていきますが、Vitis 向けのプラットフォームに更新がありますので aws-fpga リポジトリを最新の状態にしてください。
$ cd ~/aws-fpga $ git pull $ cd ..
コマンドラインから Vitis を使用できるように環境をセットアップします。
$ source ~/aws-fpga/vitis_setup.sh
Vitis Libraries リポジトリをクローンします。
$ git clone https://github.com/Xilinx/Vitis_Libraries
実行するアプリケーションのディレクトリに移動し、xclbin とホストプログラムをビルドします。すべてのビルドが完了するまでに2時間ほどかかります。
$ cd Vitis_Libraries/data_compression/L3/demos/zlib_app $ make TARGET=hw DEVICE=$AWS_PLATFORM all
ビルドが正常に完了すると xclbin とホストプログラムが生成されます。
build_dir.hw.xilinx_aws-vu9p-f1_shell-v04261818_201920_2/ ├── compress_decompress.xclbin (FPGA バイナリ) └── xil_zlib (ホストプログラム)
FPGA バイナリを AFI に変換する
F1 インスタンスでは xclbin を直接 FPGA に読み込ませることはできず、AFI (Amazon FPGA Image) に変換する手順が必要となります。AFI への変換は AWS 上で行われます。変換に必要なデータを S3 に置いて、AWS に変換をリクエストする流れとなります。
まず S3 にデータを置く場所を用意します。バケット名 (f1-afi-20200508 の部分) は何でも良いのですが、他のすべての AWS ユーザーと被らないようにユニークな名前を付ける必要があります。
$ aws s3 mb s3://f1-afi-20200508 --region us-west-2
次にデータを S3 にコピーして変換をリクエストするのですが、この処理はスクリプトが用意されていて自動で行うことができます。生成した xclbin とバケット名を指定してスクリプトを実行します。
$ $VITIS_DIR/tools/create_vitis_afi.sh \ -xclbin=build_dir.hw.xilinx_aws-vu9p-f1_shell-v04261818_201920_2/compress_decompress.xclbin \ -o=compress_decompress \ -s3_bucket=f1-afi-20200508 \ -s3_dcp_key=dcp \ -s3_logs_key=logs
これでリクエストは完了しました。後で FPGA を動かす際に必要となる compress_decompress.awsxclbin もカレントディレクトリに生成されています。
AFI への変換には時間がかかりますが、AFI に振られた ID を使って変換の状況を調べることができます。ID はファイルに記録されています。
$ cat 20_05_16-160703_afi_id.txt
{
"FpgaImageId": "afi-0f5f661ae51d3a92e",
"FpgaImageGlobalId": "agfi-0bb15f28b8c62d125"
}変換状況は次のコマンドで確認できます。
$ aws ec2 describe-fpga-images --fpga-image-ids afi-0f5f661ae51d3a92e
{
"FpgaImages": [
{
"UpdateTime": "2020-05-16T07:09:34.000Z",
"Name": "compress_decompress",
"Tags": [],
"DataRetentionSupport": false,
"FpgaImageGlobalId": "agfi-0bb15f28b8c62d125",
"Public": false,
"State": {
"Code": "pending"
},
"OwnerId": "693019048218",
"FpgaImageId": "afi-0f5f661ae51d3a92e",
"CreateTime": "2020-05-16T07:09:34.000Z",
"Description": "compress_decompress"
}
]
}State の Code が available になれば変換完了です。私が試したときには40分ほどかかりました。
ホストプログラムを実行する
実行する前に、圧縮の対象となるデータを用意します。ここでは圧縮アルゴリズムのベンチマークに用いられる Silesia Corpus を利用します。Silesia Corpus には様々なタイプのデータが含まれていますが、すべて連結した上で、さらにサイズを大きくするために10個分を連結して約 2GB のデータを作成しました。
$ wget http://sun.aei.polsl.pl/~sdeor/corpus/silesia.zip $ mkdir silesia $ cd silesia $ unzip ../silesia.zip $ cat * > all $ cat all all all all all all all all all all > all_x10 $ cd ..
それでは実行してみましょう。ランタイムをセットアップします。
$ source ~/aws-fpga/vitis_runtime_setup.sh
awsxclbin と圧縮対象のデータをホストプログラムに渡して実行します。
$ time ./build_dir.hw.xilinx_aws-vu9p-f1_shell-v04261818_201920_2/xil_zlib \
-sx compress_decompress.awsxclbin -c silesia/all_x10
Found Platform
Platform Name: Xilinx
INFO: Reading compress_decompress.awsxclbin
Loading: 'compress_decompress.awsxclbin'
OpenCL Setup = 2781.86
Compress Host Buffer Allocation Time = 11.05
E2E(Mbps) :1005.770
ZLIB_CR :2.74
File Size(GB) :2.119
File Name :silesia/all_x10
Output Location: silesia/all_x10.zlib
real 0m11.977s
user 0m0.548s
sys 0m3.558sFPGA に回路が読み込まれ、無事に実行が完了しました。ログによるとスループットは 1005MB/s、圧縮率は2.74となりました (ログには Mbps と表示されますが実際には MB/s です)。
プログラム全体の実行時間は12秒となっていますが、調べたところおおよそ次の内訳となっていました。
| 処理内容 | 時間 |
|---|---|
| FPGA セットアップ | 3 秒 |
| ファイル読み込み | 2 秒 |
| FPGA 実行 | 2 秒 |
| ファイル書き込み | 5 秒 |
| 計 | 12 秒 |
このプログラムでは FPGA 実行以外の処理に多くの時間がかかってしまい、FPGA の性能を十分に活かせていないようです。FPGA セットアップの時間については、大半が FPGA に回路を読み込ませる時間ですが、2 回目以降の実行では省略されますので気にしなくて良いかと思います。ファイル読み書きについては、FPGA 実行と並列に行うように変更した上で、書き込みに時間がかかっているため、より高速なディスクを使った方が良さそうです。
CPU と比較する
CPU でのスループットも確認しておきます。できるだけ公平な比較となるよう、同じ Deflate アルゴリズムを利用する gzip のマルチスレッド実装である pigz で測定します。また、FPGA と同等の圧縮率となるように -1 オプションを渡しています。
$ sudo yum install -y pigz $ time pigz -1 -c silesia/all_x10 > /dev/null real 0m7.659s user 0m57.058s sys 0m0.350s
pigz ではファイル読み書きと圧縮処理が並列で実行されるため、time コマンドで測定した約7.6秒を圧縮処理にかかった時間とみなすことにします。FPGA の場合と同じ式で計算するとスループットは約 280MB/s となりました。
FPGA を利用することで Deflate による圧縮処理を約3.6倍に高速化できることが分かりました。これに加え、FPGA に処理をオフロードして空いた CPU 時間は他の仕事に使えそうです。また実はこのハードウェア実装は FPGA リソースを十分に使っていないため、カーネルの数を増やしてさらに性能を上げたり、他の処理をオフロードすることもできそうです。
まとめ
今回は Deflate のハードウェア実装の概要を紹介し、Amazon EC2 F1 インスタンスで FPGA を動かしてみました。
ザイリンクス株式会社 安藤潤