
みなさん、こんにちは。広島市立大学の窪田です。1回目のブログでは、「HPC アプリを…」というタイトルにもかかわらず、Vitis の template しか扱いませんでしたが、今回は、HPC アプリとして連立一次方程式の求解法である CG 法を取り上げ FPGA 向けに移植する手順を説明します。通常の CPU で動作する逐次版と FPGA へ移植したバージョンを github から取得できるようにしています。C/C++ 言語のプログラムを最小限の変更で Xilinx の FPGA 向けに移植する際の参考になればと思います。
CG 法のアルゴリズムと逐次プログラム
共役勾配法 (Conjugate Gradient Method; CG 法) は、大規模な対称疎行列を係数行列とする連立一次方程式の解法として広く用いられています。数値計算の教科書[1]などにアルゴリズムが説明されていますし、多くのライブラリも利用可能です。CG 法を含む線形代数プログラムを C++ 言語で実装したライブラリとしては Eigen などが有名で、今回の CG 法のプログラムの作成でも参考にさせてもらいました。
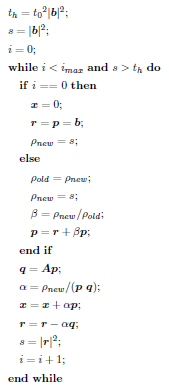
CG法のアルゴリズムは上のようになります。係数行列 A と右辺ベクトル b が与えられ、反復法で解ベクトル x が得られます。与えられた許容相対誤差 t0 をもとに解が収束したと判定されるか、反復回数が imax を超えるか、どちらかの条件が満たされるまで処理が繰り返されます。ここで、1回目以外の反復での主な処理は以下のようになっています。
- ベクトルの内積 (dot) 2回
- 疎行列とベクトルの積 (Sparse Matrix Vector Multiply; SpMV) 1回
- axpy 型計算3回
- 除算2回
これら dot, SpMV, axpy などの処理や CG 法全体を関数としてまとめ、C++ 言語で実装したプログラムが、前述したように github から取得できます。solver/cg/seq/cg_float_app/src ディレクトリにあるファイルが通常の CPU 上で実行可能な CG 法実装例です。FPGA への移植例も solver/cg/ocl_base ディレクトリにありますが、こちらは後で説明します。
なお、axpy 型というのは定数 a とベクトル x の乗算結果とベクトル y の加算 (plus) 型の処理で ax+y つまり axpy ということです。BLAS などのライブラリで用いられる用語ですので、ご存知の方もいらっしゃるかもしれません。
さて、ここでちょっと逐次のプログラムを実行してみましょう。
$ cd solver/cg/seq/cg_float_app/src
$ make
c++ -O3 -o solver main.cpp -lm
$ ./solver
res:16 = 7.04937e-05
error = 0.000135595
0: 1.00011
1: 1.00024
2: 1.00025
3: 1.00015
4: 1.00014
5: 1.0001
6: 1.00011
7: 1.00005
8: 1.00006
9: 1.00003
10: 1.00005
11: 1.00003
12: 1.00003
13: 1.00002
14: 1.00002
15: 1.00001
Time: 2.74879e-06
$ここで、サンプルとして用意した係数行列は 16×16 のもので、Matrix Market という行列のリポジトリのファイル形式で sym_sparse.mtx というファイルに格納されています。解ベクトルの値がすべて 1 になるように右辺ベクトルの値を初期化して CG 法を呼び出しています。ちなみに反復終了の閾値が t0 = 10-4 と比較的大きいので、解は10進数で4桁程度の精度になっています。参考までに、この CG 法のプログラムに指定可能なオプションは以下のようにしています。
- -i 反復回数の上限 (デフォルトで行列のサイズ N の2倍)
- -r 反復終了の閾値 (デフォルトで t0 = 10-4)
- -m 係数行列ファイル名 (デフォルトで sym_sparse.mtx)
この CG 法のプログラムは C++ 言語で記述され、コンパイルして通常の CPU 上で実行可能ですが、このプログラムを修正して Vitis で FPGA 向けに回路を高位合成 (High Level Synthesis; HLS) することを前提にしている点があります。少しこれらの点を説明しておきます。
sparse_defs.hpp ファイルに、係数行列のサイズ、非零要素数などが書かれています。係数行列を変更する場合は、それに合わせてこのファイルを修正し、コンパイルし直す必要があります。配列の要素数がプログラム実行時に変更可能なように記述することもできますが、Vitis が対応できなかったり、望ましい回路が合成されなかったりするため、要素数は実行時は固定にしています。
また、関数に配列を渡すときには、その要素数を指定しています。たとえば、ベクトルの内積を求める関数 dot は以下のように要素数 N を明記して宣言しています。
template <typename T> T dot(T a[N], T b[N]);C/C++ 言語では、このように要素数を指定して引数の配列を宣言しても、その要素数はコンパイル時には無視されます (1次元配列の場合。多次元の場合は、一番左の配列の要素数が無視されます)。しかし Vitis ではこの要素数を利用しますので、あえてこのように指定しています。
もう一つ付け加えますが、この CG 法のプログラムでは、C++ 言語の template 機能を使って、ほとんどの関数で浮動小数点数の型をパラメータ化して、同一のソースコードで単精度 (float) または倍精度 (double) どちらにも対応可能にしています。template 機能などの C++ 言語独自の機能は、Vitis をはじめとする Xilinx の CAD でも利用可能で、Xilinx から提供されるサンプルやライブラリ、マニュアルの記述でも多数の C++ のコードが提供されています (と私は感じています)。 そのため、コードを簡潔に記述する手段として template などの機能は積極的に使っています。なお github から取得できるようにしている CG 法のプログラムでは、単精度で計算するようになっています。main.cpp 内の float を double に変更すれば、倍精度でも計算できるようにしています。
だんだん FPGA の話題から脱線しそうになってきましたので、サンプルの CG 法のプログラムの説明はこれくらいにして、そろそろ FPGA への移植の話題に移りましょう。
CG 法の FPGA への移植
CG 法に限らず、プログラムを FPGA に移植する場合、どの部分を FPGA 上で処理して、それ以外の部分を CPU などで処理するのかという判断が必要になります。今回は、CG 法全体を処理する solve という関数を FPGA 上で処理することにして、FPGA 上で関数 solve からさらに dot, spmv, axpy などの関数の処理が行われるようにします。
これ以降の説明で、関数 solve とそこから呼び出される 関数 dot, spmv, axpy からなる FPGA 上での処理全体をカーネルまたはカーネル処理、カーネル以外の処理をホストプログラムと呼ぶことにします。Alveo U50 の場合は、ホストプログラムは Intel x86 CPU を搭載したホスト PC で実行されることになります。ホスト PC の CPU やメモリと、その上で実行されるホストプログラム全体を指して、単にホストと呼ぶこともあります。また、ホストプログラムから呼び出されるカーネルの関数をカーネルトップ関数と呼ぶことにします。
ホストプログラムの変数は、カーネルトップ関数の引数を介してカーネルでアクセスすることができます。この場合、ホスト PC のメインメモリ上の領域と、FPGA から直接アクセスできるメモリ領域との間でデータ転送が行われます。このデータ転送のことを、誤解のない限り「ホストとカーネル間のデータ転送」などと表現することがあります。
前回のブログの最後の方で少し説明しましたが、Vitis の GUI を使う場合、プロジェクト内でホストプログラムのソースプログラムを置くディレクトリと、カーネルのソースプログラムを置くディレクトリが異なっています。そのため、github 上の Vitis 用に移植したサンプルプログラムもホストプログラムとカーネルとでソースプログラムを分けています。
ホストプログラム用ソース solver/cg/ocl_base/cg_float_app/src
カーネル用ソース solver/cg/ocl_base/cg_float_app_kernels/src
続いて、カーネルとホストプログラムに分けて、CG 法の逐次プログラムを Vitis 用に修正する手順を説明していきますが、その際、上記の修正後のソースプログラムも適宜ご参照下さい。
カーネルトップ関数の変更
Vitis では、カーネル処理を記述する C/C++ 言語の関数にはいくつかの制約があります。UG1399 (v2020.2) Vitis HLS User Guide p.117 には、配列変数の要素数は固定であること、システムコール (入出力関数などが含まれます) を呼び出せないことなどが説明されています。
また、Vitis ではカーネルトップ関数は OpenCL の API を使って呼び出されるため、関数自身やその引数にも制約があります。
- カーネルトップ関数は C 言語の関数でなければなりません。
- 引数としてポインタは使用できません。
- 引数として配列変数を使用できますが、配列の先頭アドレスがポインタとして渡されるのではなく、配列全体のホストとカーネル間のデータ転送として実現されます。
今回の扱っている CG 法のプログラムでは、solver/cg/ocl_base/cg_float_app_kernels/src ディレクトリのファイル cg.hpp に CG 法の関数 solve が、ファイル sparse_lib.hpp に関数 dot, spmv, axpy が記述されています。関数 solve は C++ の template で記述されており、そのプロトタイプ宣言は以下のようになっています。
template <typename T>
void solve
(int colptr[N+1],
int col[NV],
T val[NV],
T b[N],
T x[N],
int max_iter,
int & iter,
T tol_error,
T & ret_error,
T p[N],
T q[N],
T r[N]
);なるべくこの関数 solve に修正を加えない方針をとってみます。そこで、ほぼ solve を呼び出すだけの C 言語の関数 kernel_func をソースファイル kernel.cpp 内に用意することにします。
関数の引数については、スカラ変数 (単純な int 型や float 型など) と配列変数に分けて、以下のように扱うことにします。
- 配列変数の引数は修正しません。ホストからカーネルおよびその逆も、すべての要素の値が転送されます。
- スカラ変数の引数の値をホストからカーネルへ渡す場合は、修正しません。修正しなくても、スカラ変数の値は転送されます。
- スカラ変数の引数の値をカーネルからホストへ渡す場合、ポインタが使えないため、1要素のみの配列に修正します。
ちょっとわかりにくいですが、CG 法の例では以下のように修正します。カーネルトップ関数として用意する kernel_func の引数は以下のようにします。
extern "C" {
static float p[N];
static float q[N];
static float r[N];
void kernel_func
(int colptr[N+1],
int col[NV],
float val[NV],
float b[N],
float x[N],
int max_iter,
int iter[1],
float tol_error,
float ret_error[1]
)
{
/* 関数内部は後述 */
}
}この関数は C 言語の関数でなくてはならないため、extern “C” {…} で囲む必要があります。また、元の solve 関数の配列変数の引数 colptr, col, val, b, x は変更はありません。ホストからカーネルへ値が転送される max_iter, tol_error といったスカラ変数も変更はありません。しかし、カーネルからホストへ値を転送するスカラ変数の iter, ret_error は、1要素のみの配列変数に変更しています。
配列変数 p, q, r はそのまま引数としてホストとカーネルの間でデータを転送することにしても良かったのですが、これらは CG 法の中で作業領域として使用されるため、そもそも、ホストでは記憶領域を確保する必要はありません。そのため、カーネル内の静的変数として記憶領域を確保することにしました。
スカラ変数 iter, ret_error を1要素の配列変数に変更しましたので、関数 kernel_func から 関数 solve を呼ぶ処理は以下のようにしました。
void kernel_func(/* 引数省略 */)
{
int tmp_iter;
float tmp_error;
solve<float>
(colptr, col, val, b, x,
max_iter, tmp_iter,
tol_error, tmp_error,
p, q, r);
iter[0] = tmp_iter;
ret_error[0] = tmp_error;
return;
}カーネルでもう一つ修正があります。関数 solve の最後の方で相対誤差を求めている箇所があります。
ret_error = std::sqrt(rho_new / rhsNorm2);除算や平方根の計算が行われていますが、ループの中の処理ではなく関数の最後に1回しか実行されない処理であるにもかかわらず、処理時間も長く合成される回路の規模が大きいことが予想されます。そのため、rho_new の値をホストプログラムへ返し、ホストプログラム中で除算と平方根の計算によって相対誤差を求めるようにしました。
カーネルの変更は以上のようになります。関数 kernel_func のために用意した solver/cg/ocl_base/cg_float_app_kernel/src/kernel.cpp などをご確認下さい。
ホストプログラムの変更
カーネルでは、カーネルトップ関数 kernel_func 内で関数 solve を呼ぶように修正しました。これに対応して、ホストプログラムでも関数 kernel_func を呼び出すことになります。 ただし、kernel_func の呼び出しは OpenCL の API を使うことになり、かなりの行の追加と修正が必要になります。以下、これらの追加修正を説明していきます。主に修正したのは main 関数で、ファイル solver/cg/ocl_base/cg_float_app/src/main.cpp で確認できます。
なお、OpenCL の API については、Xilinx のマニュアル UG1393 や OpenCL 1.2 API、XilinxのOpenCL extension, XRT などで詳しく説明されています。
OpenCL の API を使って、Context, CommandQueue, Kernel などのオブジェクトを順に生成していきます。第1回のブログで扱った Vector Addition の template の記述とあまり違いがありませんので、主要な部分の記述のみ以下に示します。cl::Kernel クラスのオブジェクト krnl を生成する際に、カーネルトップ関数名 kernel_func を指定することに注意して下さい。
cl::Context context(device);
cl::CommandQueue q(context, device, CL_QUEUE_PROFILING_ENABLE);
cl::Kernel krnl(program, "kernel_func");ここまでは、Vector Addition の template の記述とあまり違いはありませんが、これ以降は、context, q, krnl などのオブジェクトのメンバ関数を呼び出して、カーネルトップ関数の引数のデータをホストとカーネルの間で転送したり、カーネルを実行したりする記述になりますので、大幅な修正が必要になってきます。
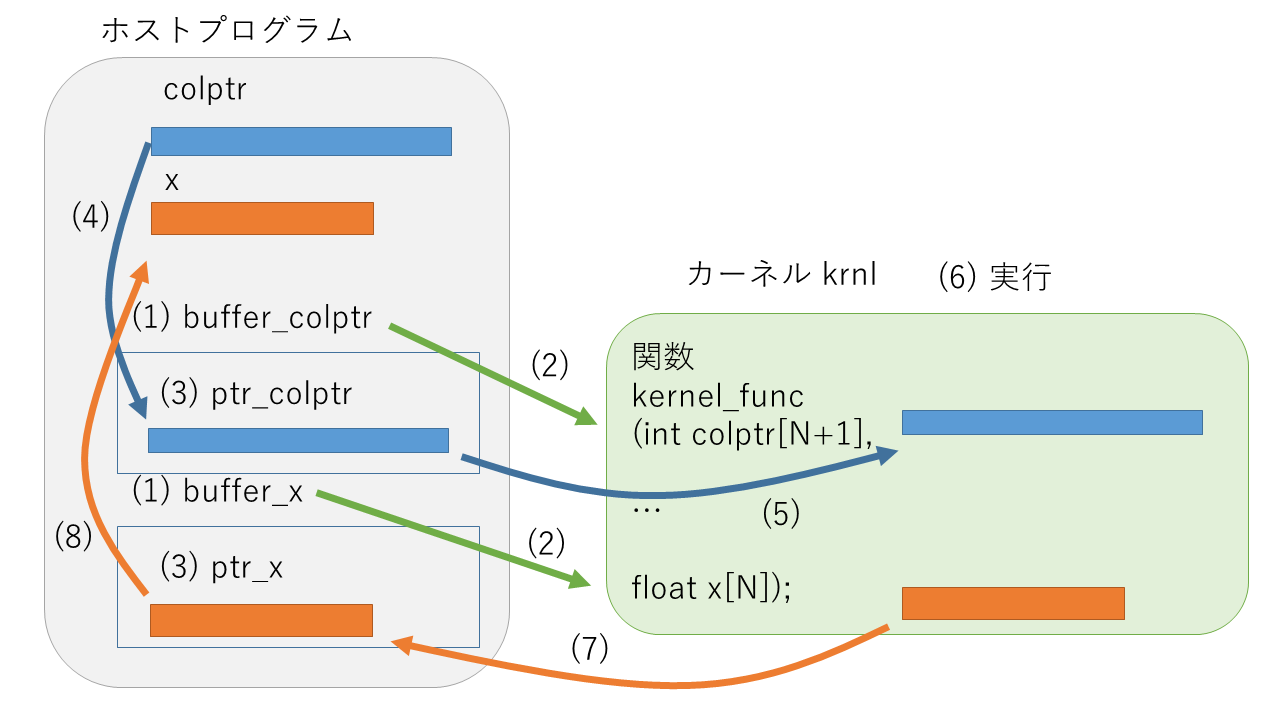
上の図では、カーネルトップ関数 kernel_func の引数のうち、colptr と x を例に挙げて、ホストとカーネルの間での転送を示してしています。これらの処理の記述例を順番に見ていきましょう。
size_t colptr_size_in_bytes = sizeof(int) * (N+1);
size_t vector_size_in_bytes = sizeof(float) * (N);
cl::Buffer buffer_colptr(context, CL_MEM_READ_ONLY, colptr_size_in_bytes);
cl::Buffer buffer_x(context, CL_MEM_WRITE_ONLY, vector_size_in_bytes);(1) ホストプログラムで、cl::Buffer クラスのオブジェクトとして colptr や x に対応するバッファをそれぞれ buffer_colptr, buffer_x という変数名で生成しています。カーネルから見て、データを読み込む (CL_MEM_READ_ONLY) のか、書き込む (CL_MEM_WRITE_ONLY) のかを指定します。このとき、バッファのサイズをバイトで指定する必要があるのですが、この後でもサイズを指定する処理が現れますので、colptr_size_in_bytes や vector_size_in_bytes などの変数を用意して指定しています。
int narg=0;
krnl.setArg(narg++, buffer_colptr);
...
krnl.setArg(narg++, buffer_x);
krnl.setArg(narg++, max_iter);
...(2) narg 変数をインクリメントしながら krnl.setArg 関数にバッファとともに指定して、各バッファがカーネルトップ関数 kernel_func の何番目の引数に対応するのかを設定します。スカラ変数 max_iter のように実引数の値を直接ホストからカーネルへ転送する場合も同様に設定します。
int * ptr_colptr = (int *) q.enqueueMapBuffer(buffer_colptr, CL_TRUE, CL_MAP_WRITE, 0, colptr_size_in_bytes);
int * ptr_x = (int *) q.enqueueMapBuffer(buffer_x, CL_TRUE, CL_MAP_READ, 0, vector_size_in_bytes);(3) カーネルトップ関数の引数のうちバッファを利用するものは、q.enqueueMapBuffer 関数でホストからバッファに直接アクセスできるポインタを取得します。ホストから見て、カーネルへ転送するバッファは書き込み (CL_MAP_WRITE), カーネルから転送してくるバッファは読み出し (CL_MAP_READ) を q.enqueueMapBuffer 関数への引数として指定します。
cl::Buffer のコンストラクタでは、カーネルから見た読み書きを CL_MEM_READ_ONLY, CL_MEM_WRITE_ONLY と指定したのに対し、q.enqueueMapBuffer 関数では、ホストから見た読み書きを CL_MAP_READ, CL_MAP_WRITE と指定することに注意して下さい。
for (size_t i=0; i<N+1; i++) {
ptr_colptr[i] = colptr[i];
}(4) q.enqueueMapBuffer 関数でポインタを取得した後、このポインタを介して、ホストからアクセスできるメモリ領域に、ホストからカーネルへ転送するデータを書き込んでおきます。
q.enqueueMigrateMemObjects ({buffer_colptr, buffer_col, buffer_val, buffer_b}, 0 /* 0 means from host */);(5) バッファに書き込まれたデータは、ホストからカーネルへ、q.enqueueMigrateMemObjects 関数によって転送します。この関数では、ホストからカーネルへ転送するバッファをすべて指定します。直接転送するスカラ変数は、ここでは指定しませんので注意して下さい。
q.enqueueTask(krnl);(6) ここまでで、カーネルトップ関数の引数の設定と、ホストからカーネルへのデータ転送が終わり、カーネルトップ関数を呼び出す準備ができたことになりますので、q.enqueueTask 関数によってカーネルを実行します。
q.enqueueMigrateMemObjects ({buffer_x, buffer_iter, buffer_error}, CL_MIGRATE_MEM_OBJECT_HOST);(7) カーネルの処理が終了したら、q.enqueueMigrateMemObjects 関数を呼び出します。カーネル実行直前に、この関数を用いてホストからカーネルへデータを転送しましたが、今度は逆にカーネルからホストへデータを転送します。配列 x に対応するバッファ buffer_x だけでなく、カーネルからホストへ転送するデータに対応するバッファがすべて指定されています。
q.finish();続いて q.finish 関数を呼び出します。ここまで「データを転送する」「カーネルを実行する」などと説明していましたが、正確には q は待ち行列のクラス cl::CommandQueue のオブジェクトですので、enqueueMigrateMemObjects や enqueueTask などのメンバ関数が呼び出されても、これらの処理が待ち行列に追加されるだけで処理の終了は保証されません。q.finish の関数呼び出しが終了すれば、これらの処理が順番に処理されてすべて終了したことが保証されたことになります。
for (size_t i=0; i<N; i++) {
x[i] = ptr_x[i];
}(8) カーネルからホストへ転送されたデータはバッファに保存されていますので、(3) の q.enqueueMapBuffer 関数の呼び出しで取得したポインタを使って、ホスト内でデータをコピーします。このコピーの前に、カーネルからホストのバッファへデータが転送されていなければなりませんので、上で説明しましたように、それを保証するために、直前に q.finish 関数が呼び出されています。
以上、FPGA 上でのカーネルの実行とホストとカーネルの間のデータ転送の記述例を見てきました。
今回は説明の都合上 CPU 上で実行可能な逐次プログラムに OpenCL の API を追加する形でホストプログラムを修正しましたが、もう少し改善することが可能です。q.enqueueMapBuffer 関数で取得されたポインタを介して、ホストからアクセスできるメモリ領域を積極的に利用すれば、ホスト上での配列データのコピーは省略できます。
また、カーネルトップ関数の引数は FPGA からアクセスできるメモリ上に領域が確保され、配列変数、スカラ変数ともに通常の C 言語の引数と同様に扱うことができます。これらは FPGA 内にバッファを用意することでアクセスを高速化できるのですが、これについては次回以降に説明したいと思います。
ホストプログラムでは、ここまで説明した OpenCL 関連の処理以外に、以下のように修正を行いました。
- 配列 p, q, r の宣言を削除しました。カーネルで宣言するように変更しています。
- カーネルの関数 solve の最後に除算や平方根の計算によって残差を求めている箇所をホストプログラムへ移動しました。
- カーネルトップ関数 kernel_func の引数 iter と ret_error は1要素の配列に変更しましたので、それに対応してホストプログラムの main 関数でも配列に変更しました。
- main.cpp の先頭に OpenCL 用の define マクロと CL/cl2.hpp のインクルードを追加しました。
- Vitis ではカーネルのバイナリはデフォルトでは binary_container_1.xclbin というファイル名で生成されます。ホストプログラムでこのバイナリファイルを読み込みますが、-f オプションでファイル名を変更できるようにしました。
- ホストプログラムでもカーネルと同様のベクトルの内積演算を行いますので、dot 関数のホスト版 dot_host を追加しました。
以上、修正したホストプログラムが solver/cg/ocl_base/cg_float_app/src ディレクトリ内のファイルです。逐次版に対して、主に main.cpp 対して修正を行い、util_host.hpp も若干の修正を行いましたので、ご確認下さい。
CG 法のプログラムの FPGA 上での実行
カーネル、ホストともに修正した CG 法のプログラムを FPGA 上で実行してみます。1回目のブログと同様に、使用した FPGA は Xilinx Alveo U50 です。Vitis の GUI を起動してワークスペースやプロジェクトを作成するところまでは、1回目とほぼ同じです。Vector Addition の template を使用したところだけ、Empty Application にしておきましょう。
- Vitis, xrt の環境変数などの設定
- vitis の起動
- ワークスペースとプロジェクトの作成
- workspace: cg_float_workspace
- project: cg_float_app
以下のような Vitis の ウィンドウが起動されます。
Empty Application を選択しましたので、ソースプログラムのディレクトリは空のままです。github から取得した solver/cg/ocl_base ディレクトリのファイルを vitis のワークスペース cg_float_workspace のディレクトリへコピーします。
- ホストプログラム
- github : solver/cg/ocl_base/cg_float_app/src
- Vitis の ワークスペース : cg_float_workspace/cg_float_app/src
- コピーするファイル : main.cpp, util_host.hpp, sparse_defs.hpp, sym_sparse.mtx
- カーネルのディレクトリ
- github : solver/cg/ocl_base/cg_float_app_kernels/src
- Vitis : cg_float_workspace/cg_float_app_kernels/src
- コピーするファイル : kernel.cpp, cg.hpp sparse_lib.hpp, sparse_defs.hpp
ソースファイルをコピーしても、どの関数がカーネルトップ関数 (Vitis では Hardware Functions と呼ばれます) なのかを Vitis が自動的に検出してくれるわけではありません。そのため、以下のように Hardware Functions を指定します。
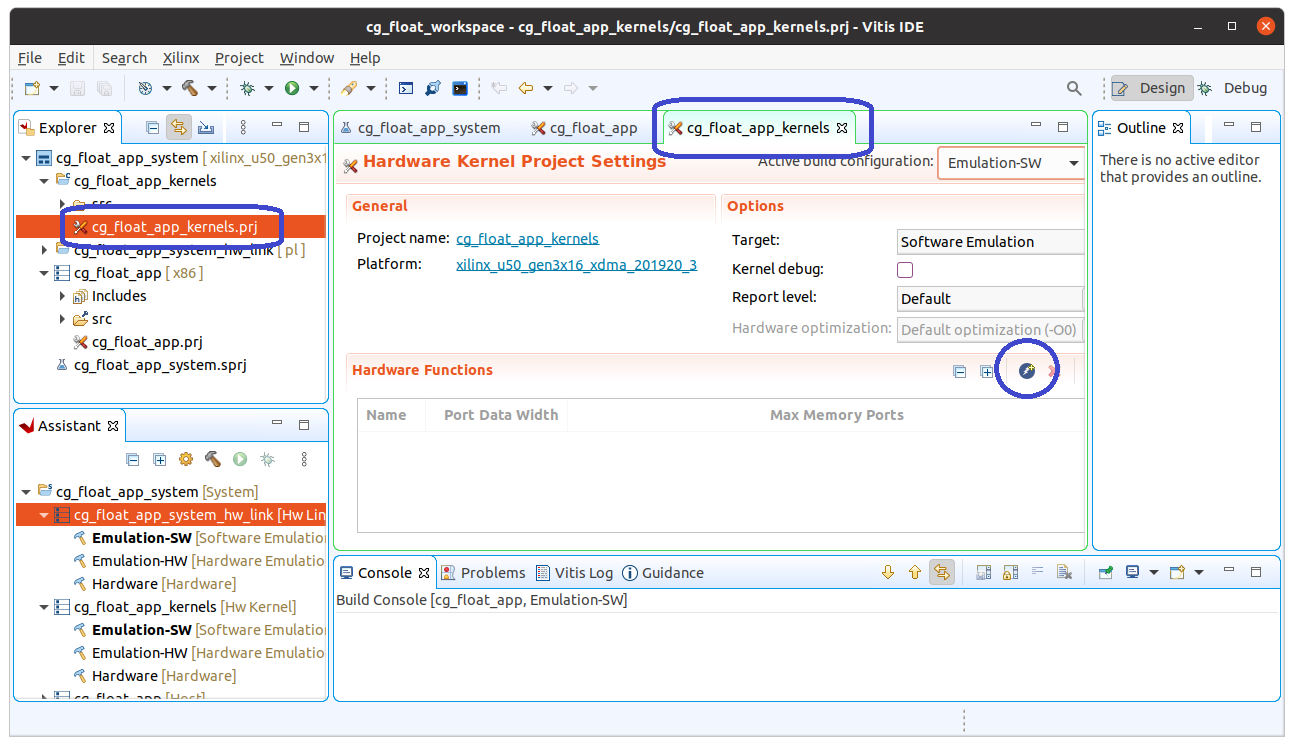
Vitis のウィンドウの左上の Explorer タブで階層から cg_float_app_system -> cg_float_app_kernels -> cg_float_app_kernels.prj とたどって、cg_float_app_kernels.prj をダブルクリックして下さい。ウィンドウの中央に cg_float_app_kernels のタブが現れます。このタブの下半分が Hardware Functions を指定する領域です。右の方の青いアイコンをクリックして下さい。
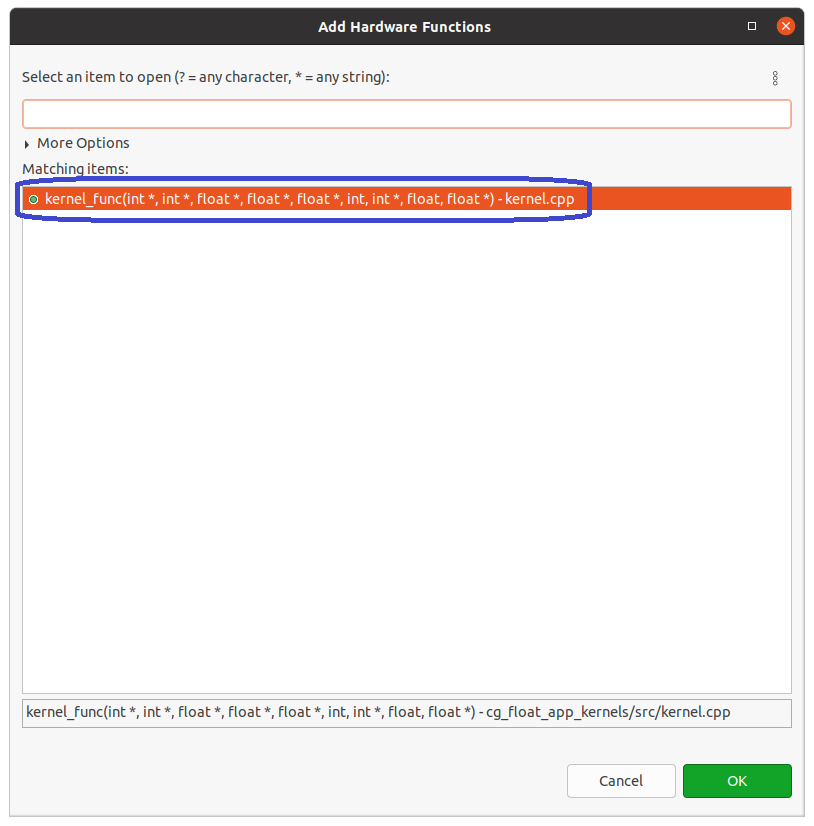
Add Hardware Functions という新たなウィンドウが現れます。Hardware Function として指定したい関数名 kernel_func で検索すると、Matching items に kernel_func のエントリが現れます。これを指定して、OK ボタンをクリックすると、下のウィンドウ画面のように Hardware Functions として kernel_func が選択されていることが確認できます。
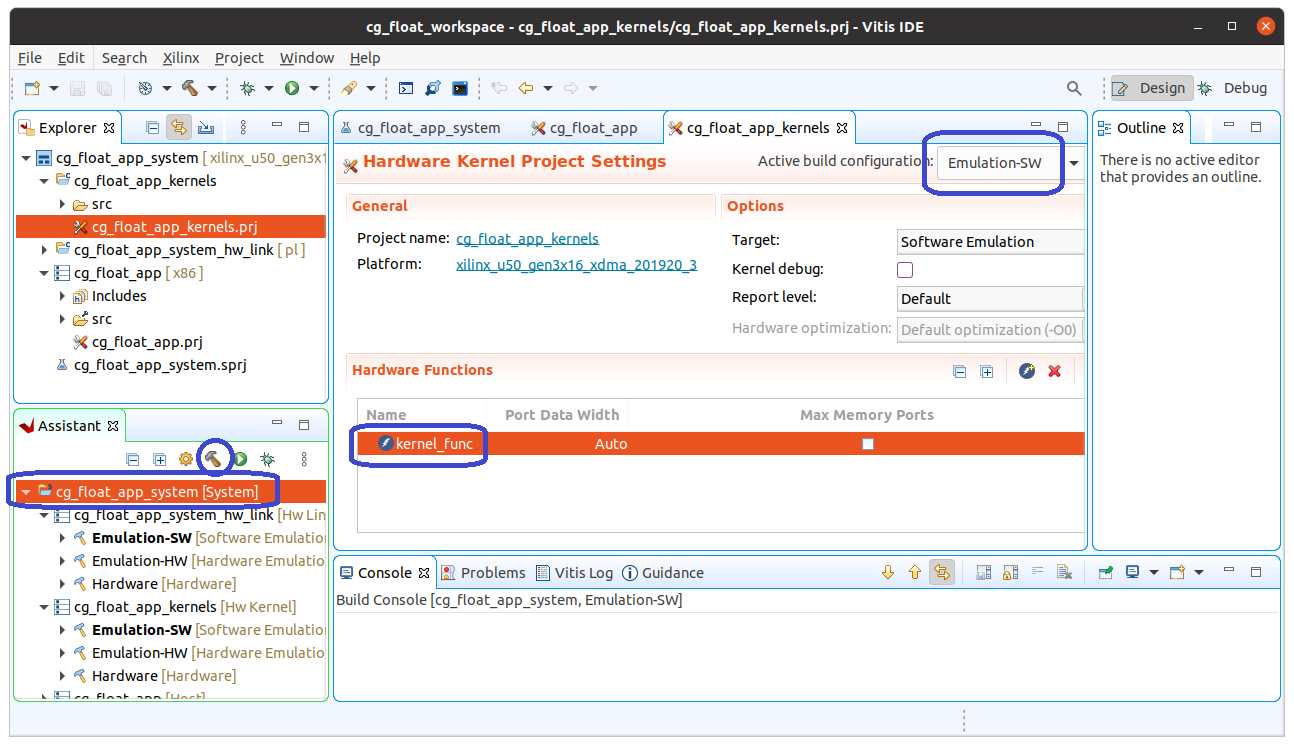
では、準備ができましたので、回路の合成、FPGA 上での実行へと進みましょう。今回はいきなり Hardware を合成 (build) するのではなく、Emulation-SW を build して FPGA 向けに移植したプログラムが正しく動作するかどうかをテストしてから、Hardware でも build して FPGA 上で実行することにします。
前回、Hardware の build を説明しましたが、Emulation-SW の build も大きな違いはありません。
上に示した Vitis のウィンドウの中央には、cg_float_app_kernels タブが表示されていると思います。このタブの右上の方の Active build configuration がデフォルトでは Emulation-SW になっていると思います。違っていたら Emulation-SW を選択しましょう。次に、ウィンドウの左下の Assistant タブで、1番上の階層の cg_float_app_system を選択し、トンカチアイコンをクリックすると build が始まります。 build は1分もかからずに終了するはずです。
終了しましたら、端末上でテストしてみましょう。端末では、Vitis や XRT の環境変数が設定されているものとします。
さきほど build の前に cg_float_workspace/cg_float_app/src にホストプログラムのソースファイルをコピーしましたが、cg_float_app ディレクトリには src のほかに Emulation-SW というディレクトリが作成されているはずです。Emulation-SW の build の結果、このディレクトリにホストプログラムとカーネルが生成されています。端末で以下のように Emulation-SW ディレクトリに移動し、環境変数 XCL_EMULATION_MODE を sw_emu に設定し、src ディレクトリにある係数行列のファイル sym_sparse.mtx をコピーしてから、build されたホストプログラム cg_float_app を実行します。
$ cd Emulation-SW
$ export XCL_EMULATION_MODE=sw_emu
$ cp ../src/sym_sparse.mtx .
$ ./cg_float_app
Loading: 'binary_container_1.xclbin'
res:16 = 7.04937e-05
error = 0.000135595
0: 1.00011
1: 1.00024
2: 1.00025
3: 1.00015
4: 1.00014
5: 1.0001
6: 1.00011
7: 1.00005
8: 1.00006
9: 1.00003
10: 1.00005
11: 1.00003
12: 1.00003
13: 1.00002
14: 1.00002
15: 1.00001
Time: 0.0081342
$正しく build できていれば、ソフトウェアエミュレーションによって上のような結果が得られます。逐次版の実行結果と比べてみるとわかりますが、全く同じ結果が得られていることが確認できます。
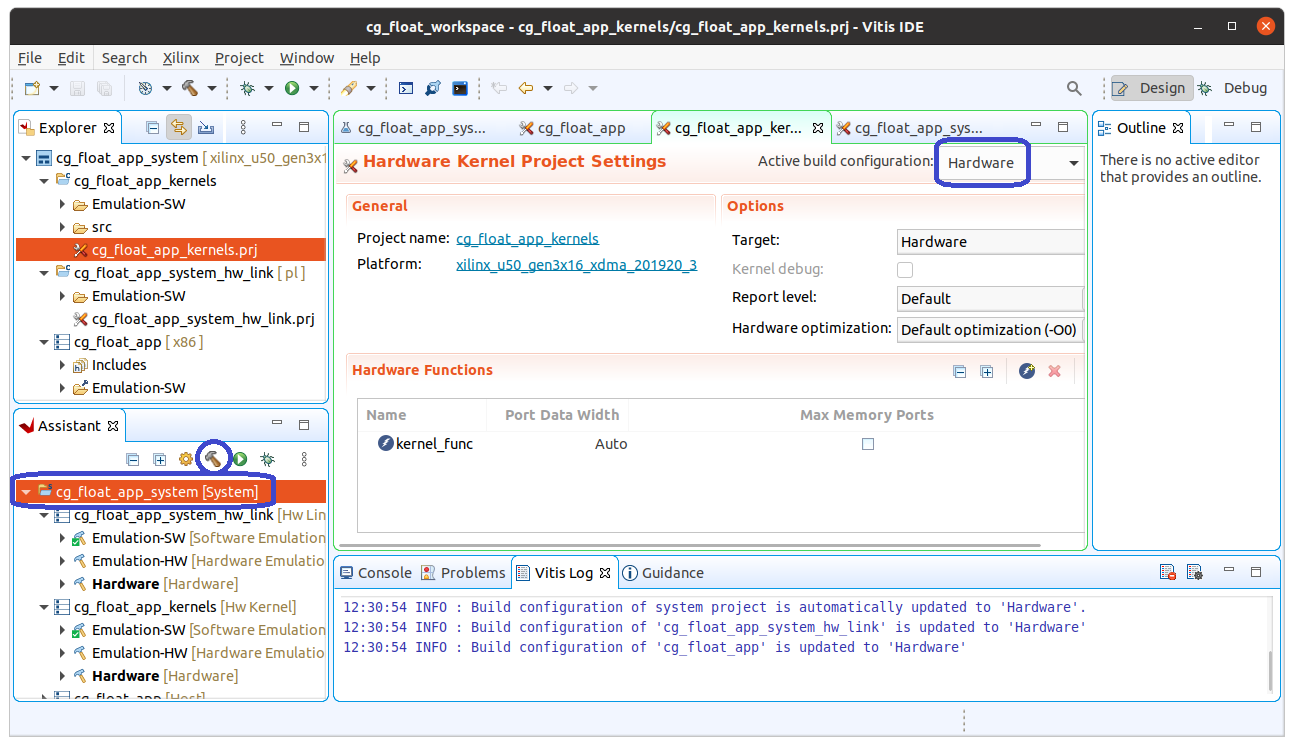
Emulation-SW のテストが終了したら、Vitis のウィンドウで Active build configuration を Hardware に変更して build します。1回目でも説明しましたように、Hardware の build は数分から数時間かかりますのでご注意下さい。
Hardware の合成が終了しましたら、端末で実行してみます。cg_float_app ディレクトリの下、src や Emulation-SW の隣に Hardware というディレクトリが作成されています。Emulation-SW をテストしたのと同じ端末の場合、環境変数 XCL_EMULATION_MODE を削除してから実行しましょう。
$ cd Hardware
$ export -n XCL_EMULATION_MODE
$ cp ../src/sym_sparse.mtx .
$ ./cg_float_app
Loading: 'binary_container_1.xclbin'
res:16 = 9.8571e-05
error = 0.000257615
0: 1.00015
1: 1.00034
2: 1.00036
3: 1.00021
4: 1.00011
5: 1.00014
6: 1.00016
7: 1.00007
8: 1.00009
9: 1.00005
10: 1.00008
11: 1.00005
12: 1.00004
13: 1.00002
14: 1.00003
15: 1.00001
Time: 0.0406779
$正しく build できていれば、FPGA 上で CG 法が実行されて上のような結果になるはずです。Vitis 2020.2 では、Emulation-SW と Hardware とで演算結果がやや異なるようですが、10進数で4桁の精度の解が得られていることが確認できます。
まとめ
HPC アプリである CG 法のプログラムを FPGA 向けに移植して Alveo U50 で実行してみました。ホストプログラムから OpenCL の API で FPGA 上で実行されるカーネルを呼び出す処理がやや煩雑ですが、カーネル内は C/C++ の関数を大きく変更する必要がないことが確認できたかと思います。
CG 法の SpMV では複雑な処理も行われているのですが、FPGA 上でも問題なく動作することが確認できました。最初は恐る恐るというか、本当に正しく動作するのか半信半疑で合成してみたのですが、実行速度はともかく、正しい結果が得られることに驚き、HLS の威力を実感したことを思い出します。
今回は問題サイズも小さく、カーネルの実行速度にも着目していませんでしたが、次回以降は問題サイズを大きくするとともに、カーネルも高速化していきます。
参考文献
[1] 寒川、藤野、長嶋、高橋 : HPC プログラミング 第4章、オーム社、2009.
広島市立大学 窪田昌史