
はじめに
連載の最終回となる今回は、ハードウェアを設計しない方にも理解しておいていただきたい、FPGA アクセラレータの性能に関する基本的な考え方を説明します。また、これを踏まえて前回の記事で動作させた Deflate アクセラレータの性能向上を図ってみます。
アクセラレータの鉄則
前回の記事では、Vitis ライブラリの Deflate アクセラレータを AWS F1 上で動かし、CPU と比べておよそ3.6倍の高速化を確認しました。確かに速くはなったのですが、FPGA を利用することのコスト増や手間を考えると少し物足りなく感じるかもしれません。FPGA を導入するからには、ひと声10倍くらいは速くなってほしいところです。
あらかじめ設計されたアクセラレータを利用することで、ハードウェア設計をしなくても FPGA を利用できることを見てきましたが、FPGA の性能を十分に発揮させる方法を知らないと、期待する性能が得られないことがあります。アプリケーションレベルでアクセラレータの性能を追求するには、その性能についての考え方や解析方法を理解しておくことが必要です。
アクセラレータの性能はおおよそ次の式で決まります。これが考え方の基本となります。
演算性能 = 演算器数 × 動作周波数 × 稼働率
この式は、「たくさんの演算器を速く長い時間動かすと多くの演算ができる」ことを意味します。当たり前のことですが、これがアクセラレータの性能を引き出す上で守るべき鉄則です。FPGA アクセラレータにおいて各項がどのような意味を持つのか見ていきます。
演算器数
FPGA にどれだけたくさんの演算器を詰め込めているか、別の言い方をすると、FPGA で使用できるハードウェアリソース (FF、LUT、メモリ、DSP) を十分に活かせているかが性能を左右します。
演算器をたくさん使用するように設計済みのカーネルを変更することは難しいかもしれません。Vitis ではカーネルのインスタンス数を簡単に変更できます。FPGA のリソース量とカーネルのリソース量を把握して、適切なリソース使用率となるようにインスタンス数を設定します。
動作周波数
CPU と同じように、動作周波数が速ければより短い時間で計算が完了します。ただし動作周波数はカーネルの設計に大きく依存するため、設計済みのものを速くすることは簡単ではありません。
Vitis では目標の動作周波数を指定して FPGA バイナリを生成することができますが、回路を論理合成および配置配線した結果から動作可能な周波数が見積もられ、実際にはこの見積もった周波数で FPGA が動作します。
高位合成を利用した設計の場合、基本的には指定した周波数を満たせるような回路が生成されますが、演算の中にフィードバックループがあると、そこがネックとなり動作周波数が頭打ちとなります。むやみに高い周波数を指定すると、データを毎サイクル入出力できない (II=1 を満たせない) 回路ができてしまい、逆に性能が下がってしまうことがあります。
リソース使用率が高かったり、配線が混雑する設計では、配置配線をしてみると動作可能な周波数が大きく下がってしまうことがあります。性能を上げるために演算器を増やすとリソース使用率が上がって配置配線が難しくなり周波数が下がってしまうジレンマがあります。
稼働率
演算器がたくさんあっても動いていなければ意味がありません。演算器の稼働率は、アプリケーションレベルで考慮すべき重要なポイントです。
もちろん、アクセラレータ自体が十分なタスク並列性を備え、アクセラレータ内の様々な演算器を同時に動作させることも重要ですが、これはアクセラレータの設計に依存するため容易には変えられません。
アプリケーションレベルでは、アクセラレータへデータを滞りなく供給し、演算器が常に動いている状況を作ることが重要です。これをどのように実現するかは後ほど説明します。
時間あたりに供給すべきデータが多い場合、データ転送のために DRAM 帯域や PCIe 帯域が逼迫し、性能が頭打ちとなることがあります。アクセラレータを設計する際は、データ転送をいかに少なくするかも重要なポイントとなります。
Deflate アクセラレータの性能改善
アクセラレータの鉄則を踏まえ、Deflate アクセラレータについて振り返ってみます。
プロファイラによる計測
前回、Deflate アクセラレータの理論性能は動作周波数と並列数から 2GB/s と見積もりました。ところが実際に動作させてみるとその半分の性能しか得られませんでした。見積もりよりこれほど性能が低いということは、カーネルの稼働率が低いのかもしれません。
「推測するな、計測せよ」の格言に従い、確認していきましょう。Vitis は OpenCL ラインタイムのレベルでプロファイルを取る機能を備えています。データ転送、カーネル実行等の動作のタイミングを詳しく解析でき、ホストプログラムやアクセラレータが期待通りに動作しているか確認するのに便利です。
プロファイラを利用するには、カレントディレクトリに次の内容の xrt.ini ファイルを作成します。
[Debug] profile=true timeline_trace=true
このようにしてホストプログラムを実行すると、プロファイル結果がファイルに出力されます。次のようにしてプロファイル結果を開きます。
$ vitis_analyzer xclbin.run_summary
タイムラインを見てみます。
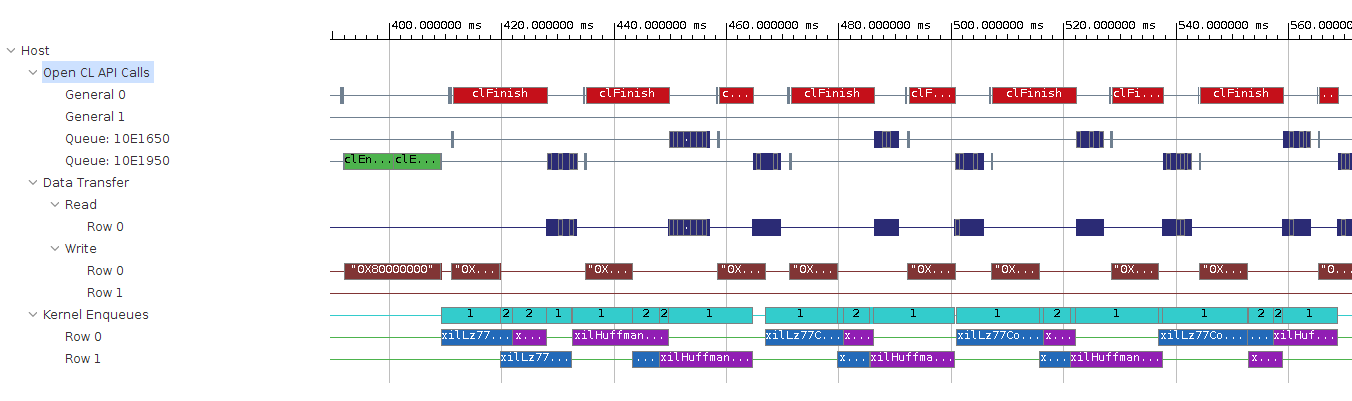
「Kernel Enqueues」はカーネルにタスクがキューイングされてから完了するまでの時間を示しています。これを見ると LZ77 カーネル、Huffman カーネルの両方とも、タスクがなく休んでいる時間があることが分かります。
ホストコードを読むと、カーネル実行をキューイングする度に前の計算が完了するのを待つようになっていました。これが原因でカーネルの稼働率が落ちてしまっています。
データ転送の隠蔽
FPGA で計算を行うには、ホストメモリと FPGA メモリとの間でデータ転送が必要ですが、その方法を工夫をしないとカーネルの稼働率が下がります。例えば、単純にデータ転送とカーネル実行を逐次的に行うと次のようなタイミングチャートになります。
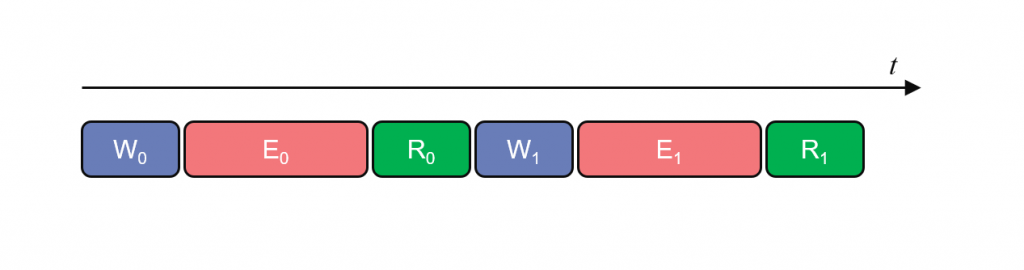
図中の W (Write) はホストから FPGA へのデータ転送、E (Execute) はカーネル実行、R (Read) は FPGA からホストへのデータ転送を表します。
このように WER を逐次的に行ってしまうとカーネルが動いていない時間が生じ、稼働率が低くなります。データ転送に比べてカーネル実行の時間が非常に長ければ、待ち時間が相対的に小さくなり問題とならない場合もありますが、通常は待ち時間が生じないようにする工夫が必要です。
カーネルがデータ転送の間に休まないようにするには、カーネル実行の裏でデータ転送を行うようにします。
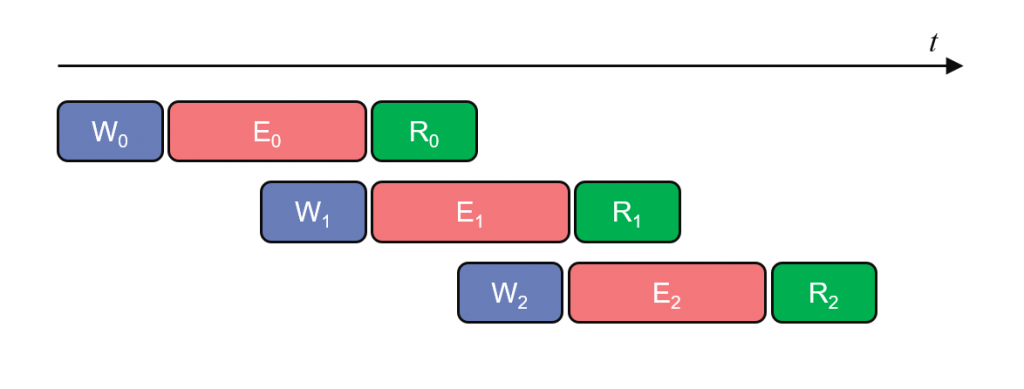
こうすると、カーネルがタスクを完了したときには、すでに次のデータが供給されていて、すぐに次のタスクを実行できます。この状況を作ることができれば、データ転送はカーネル実行の影に隠蔽され、アクセラレータの性能に影響しなくなります。
ホストコードの修正
Deflate アクセラレータの場合、圧縮処理はブロックごとに独立して行えるのですが、出力データのサイズがカーネル実行ごとに変わるため、出力データを CPU メモリの連続した領域にコピーする際にはブロックを順番に同期的に処理していく必要があります。この部分をうまく実装しないと、カーネルへのデータ供給が滞る原因となります。
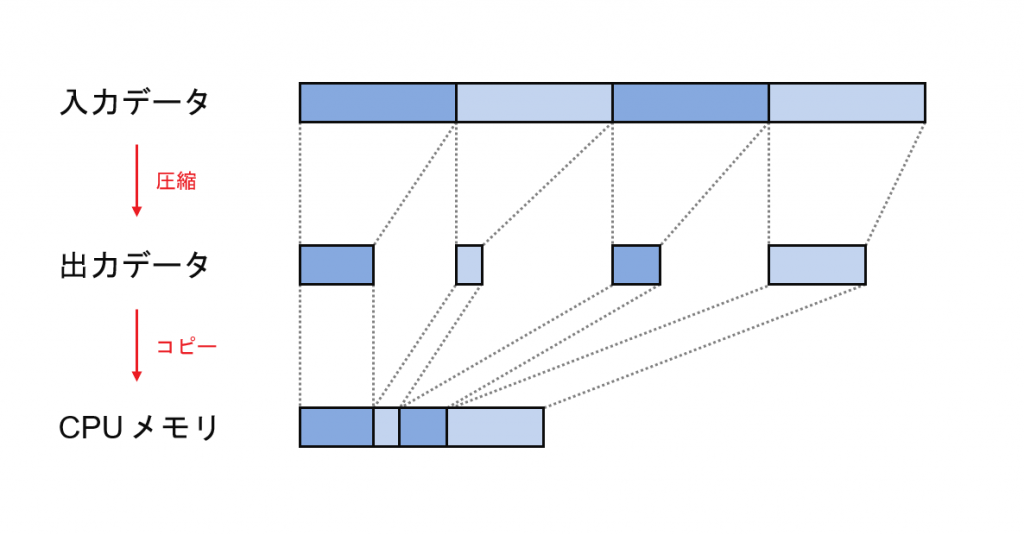
元のホストプログラムの実装では、CPU・FPGA 間のデータ転送と CPU でのメモリコピーを最小限に抑えるため、出力データサイズを確認した上で、必要な分だけ、出力先のメモリ領域にコピーするようしています。今回はこの設計方針は変更せず、より効率的な実装を考えてみました。次が実装にあたって工夫したポイントです。
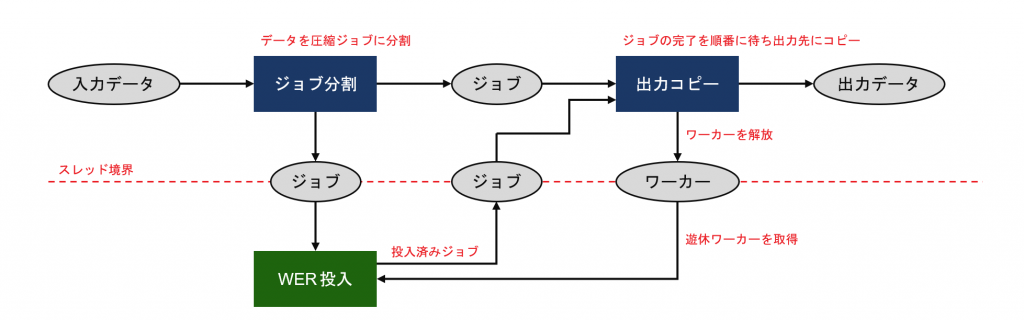
- 圧縮ジョブごとの WER を管理するワーカーを作成した
- WER をコマンドキューに投入する処理を別のスレッドに分割した
- 圧縮ジョブが投入された順に処理されるよう、コマンドに依存関係を与えた
データの流れを図で表すと次のようになります。マルチスレッドを使わないよりシンプルな実装も考えられますが、今回は実際のアプリケーションに組み込んだときにも性能を出せるよう考慮して設計しています。
ソースコードは GitHub に置きました。動かしてみる場合はこちらからクローンしてください。
$ git clone https://github.com/anjn/vlib-deflate-benchmark.git $ cd vlib-deflate-benchmark $ git submodule update --init
プラットフォーム、FPGA バイナリのパス (前回の記事で作ったもの) を環境変数に設定してスクリプトを実行します。
$ source ~/aws-fpga/vitis_setup.sh
$ source ~/aws-fpga/vitis_runtime_setup.sh
$ export PLATFORM=$AWS_PLATFORM
$ export XCLBIN=compress_decompress_200516_1.awsxclbin
$ ./run.sh silesia/all_x10
Found Platform
Platform Name: Xilinx
INFO: Reading compress_decompress_200516_1.awsxclbin
Loading: 'compress_decompress_200516_1.awsxclbin'
Load FPGA : 228.961 ms
Open : silesia/all_x10
Input size : 2119385800 bytes
Allocate memory : 1835.802 ms
Read from file : 767.195 ms
Compress : 1594.649 ms
Throughput : 1329.1 MB/s
Output size : 774490839
Compression ratio : 2.736
Write to file : 5066.541 ms
Unload FPGA : 113.057 ms元のホストプログラムでは 1000MB/s くらいだったスループットが 1330MB/s まで改善しました。タイムラインも見てみましょう。
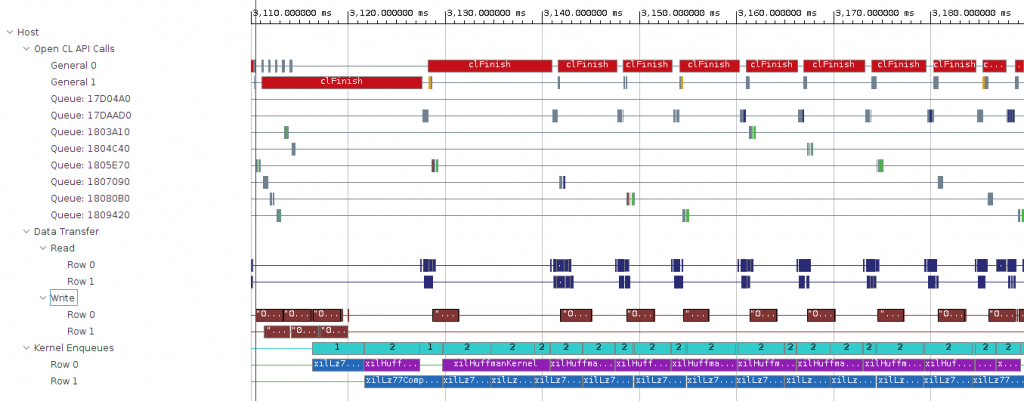
タイムライン上にカーネル実行が詰まっていて、効率的に動作しています。
アクセラレータを追加
前回の記事の手順に沿うと、LZ77 カーネルと Huffman カーネルがひとつずつ実装された FPGA バイナリが生成されます。また今回は動作させていない Decompress カーネルも実装されています。FPGA のリソース使用状況を視覚的に分かりやすく見てみると次のようになります。
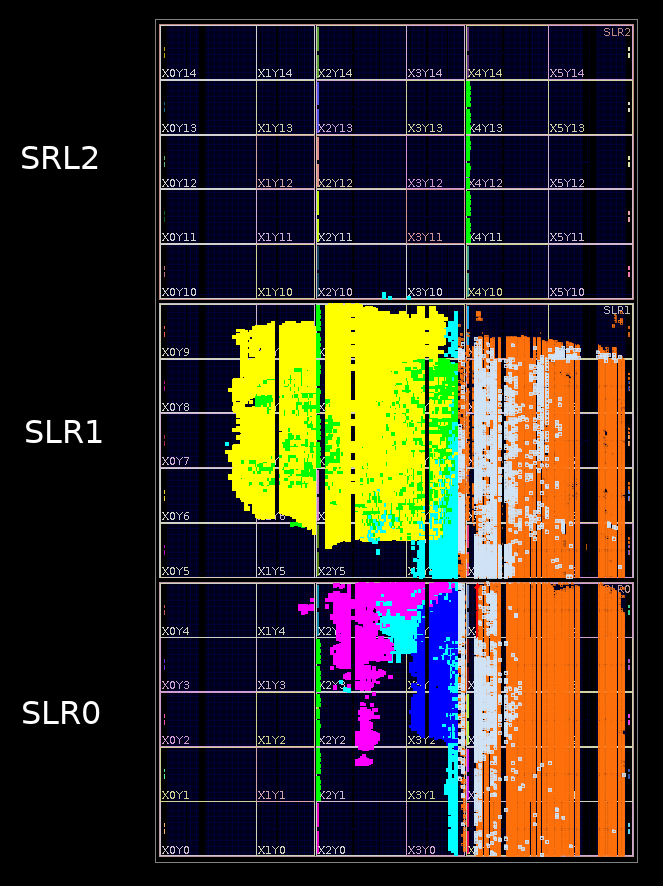
FPGA リソースが使用されている部分に色が着いています。黄色が LZ77 カーネルと Huffman カーネル、紫色が Decompress カーネル、オレンジ色がプラットフォームです。
面積の半分以上が未使用で、アクセラレータを追加する余地があります。この FPGA は3つの SLR (Super Logic Region) で構成されているので、空き領域を見て、SLR0 に1組、SLR2 に2組を追加して合わせて4組の LZ77 / Huffman カーネルを実装するように変更してみます。
カーネルのインスタンス数と SLR への配置を指示するには、Vitis に渡すコンフィグファイル (opts.ini) の中で次のようにします。ここでは DRAM 帯域がネックにならないように、DRAM への接続も分散するようにしています。
[connectivity] # カーネルのインスタンス数を指定 nk=xilLz77Compress:4 nk=xilHuffmanKernel:4 # 各インスタンスのSLR配置を指定 slr=xilLz77Compress_1:SLR0 slr=xilLz77Compress_2:SLR1 slr=xilLz77Compress_3:SLR2 slr=xilLz77Compress_4:SLR2 slr=xilHuffmanKernel_1:SLR0 slr=xilHuffmanKernel_2:SLR1 slr=xilHuffmanKernel_3:SLR2 slr=xilHuffmanKernel_4:SLR2 # 各インスタンスのAXIマスターのDRAM接続を指定 sp=xilLz77Compress_1.m_axi_gmem0:DDR[0] sp=xilLz77Compress_1.m_axi_gmem1:DDR[0] sp=xilLz77Compress_2.m_axi_gmem0:DDR[1] sp=xilLz77Compress_2.m_axi_gmem1:DDR[1] sp=xilLz77Compress_3.m_axi_gmem0:DDR[2] sp=xilLz77Compress_3.m_axi_gmem1:DDR[2] sp=xilLz77Compress_4.m_axi_gmem0:DDR[3] sp=xilLz77Compress_4.m_axi_gmem1:DDR[3] sp=xilHuffmanKernel_1.m_axi_gmem0:DDR[0] sp=xilHuffmanKernel_1.m_axi_gmem1:DDR[0] sp=xilHuffmanKernel_2.m_axi_gmem0:DDR[1] sp=xilHuffmanKernel_2.m_axi_gmem1:DDR[1] sp=xilHuffmanKernel_3.m_axi_gmem0:DDR[2] sp=xilHuffmanKernel_3.m_axi_gmem1:DDR[2] sp=xilHuffmanKernel_4.m_axi_gmem0:DDR[3] sp=xilHuffmanKernel_4.m_axi_gmem1:DDR[3]
FPGA バイナリをビルドします。
$ source ~/aws-fpga/vitis_setup.sh $ export PLATFORM=$AWS_PLATFORM $ ./build.sh
FPGA バイナリができたら awsxclbin に変換します (説明は省略します)。それでは新しく作った awsxclbin でホストプログラムを動かしてみます。4つのカーネルインスタンスを利用するように -n 4 オプションを渡します。
$ ./run.sh silesia/all_x10 -n 4
Found Platform
Platform Name: Xilinx
INFO: Reading compress_decompress_200523_1.awsxclbin
Loading: 'compress_decompress_200523_1.awsxclbin'
Load FPGA : 236.489 ms
Open : silesia/all_x10
Input size : 2119385800 bytes
Allocate memory : 1841.153 ms
Read from file : 766.124 ms
Compress : 528.504 ms
Throughput : 4010.2 MB/s
Compression ratio : 2.736
Write to file : 5063.340 ms
Unload FPGA : 205.403 msスループットが 4010MB/s まで向上しました。カーネル1組あたりでは 1000MB/s と性能が下がってしまっていますが、これはカーネルインスタンスを増やしたことで動作周波数が 250MHz から 213MHz へと下がってしまったことが大きな原因です。
CPU では 280MB/s だったので14.3倍の高速化になります。これだけ速ければ FPGA の導入にメリットを見い出せそうですね。
さいごに
ここまで読んでいただきありがとうございました。全5回の連載を通して、Amazon EC2 F1 サービスを利用した FPGA アクセラレーションを体験してきました。この連載をきっかけに FPGA に興味を持っていただき、F1 に触れてみたいと思っていただけたらうれしいです。
また、F1 をテーマに説明してきましたが、Vitis はマルチプラットフォームです。組み込み向けから、オンプレミス、他社のクラウドでも利用できます。特にオンプレミス向けには、Alveo アクセラレータカードを利用することで F1 と同じことがお手元でも実現できます。こちらもぜひチェックしてみてください!

ザイリンクス株式会社 安藤潤