
前回の記事では、宇宙物理アプリケーションになぜ FPGA を利用しようと考えるに至ったかについて紹介しました。2 回目となる今回は、宇宙物理アプリケーションの支配的な処理である ART 法 (前回の記事参照) のハードウェアアクセラレータをどのように FPGA に実装していくかをご紹介します。
FPGA-based ART accelerator
実装の概要
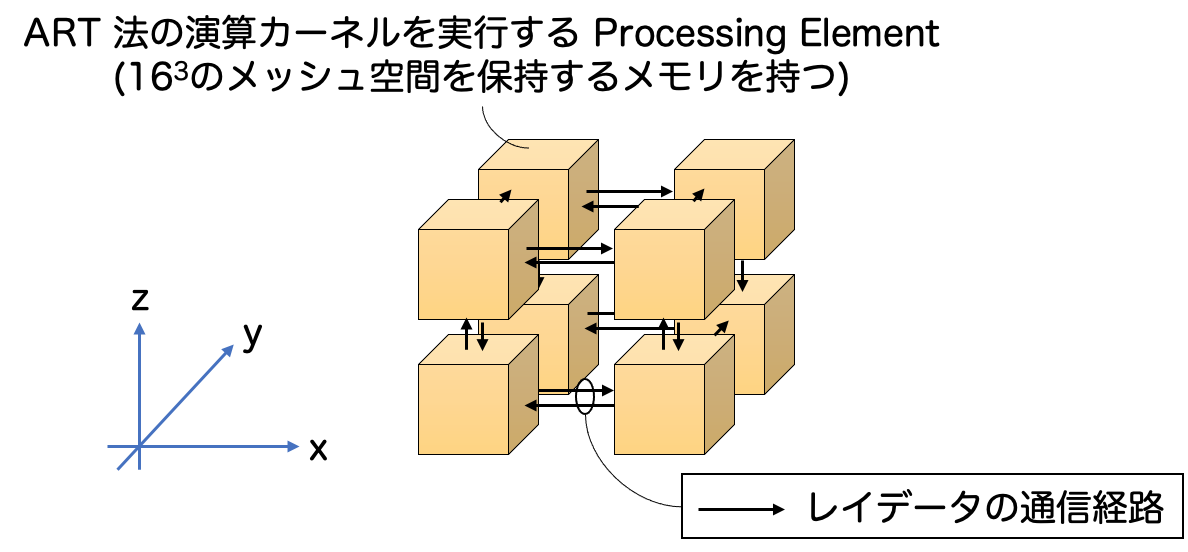
図に示すように、1 FPGA に実装される ART 法のハードウェアアクセラレータは、演算コアである Processing Elements (PE) を 3 次元状 (2 × 2 × 2) に接続することによって構成されています。すなわち、1 つの FPGA が担当する問題空間をより小さなブロックに分割し、それぞれの PE に割り当てて並列計算を実行するイメージです。
分割された問題空間は各 PE に備わっている Block RAM で実装されたワーキングメモリ (スクラッチパッドメモリのようなもの) に格納され、今回の実装では各 PE は163 のメッシュ空間を保持します (1 FPGA 内に 323 のメッシュ空間が保持されます)。そして、各 PE がレイデータを相互に通信し、レイデータを受信した PE で ART 法の演算カーネル (前回の記事参照) を実行し、レイの進行方向に位置する次の問題空間を担当する PE に演算カーネルの結果を反映したレイデータを送信することによって、 ART 法のレイトレーシングアルゴリズムが実現されます。
本研究では、ART 法のハードウェアアクセラレータを Intel FPGA SDK for OpenCL を用いて実装しています。各 PE は、OpenCL カーネルとして実装され、カーネル間の接続 (つまり、PE 間におけるレイデータの送受信のための接続) は、Intel FPGA SDK for OpenCL の独自拡張である Channel を利用することで実現されています。Intel FPGA SDK for OpenCL についてのこれらの概要は後述します。
ACRi ブログの様々な記事で述べられている様に、アプリケーションを処理する回路を全てハードウェア記述言語で実装するのは、多大なプログラミングコストを要します。そして、ハードウェア記述言語での実装は往々にして、極めて専用性が高くなる傾向にあるため、開発したコードの可搬性が損なわれ、FPGA に慣れ親しんでいないアプリケーション開発者からは利用を敬遠される恐れがあります。そのため、計算科学研究センター (以下、当センター) では、高位言語を中心とした FPGA プログラミングを前提に、実アプリケーションの演算加速にフォーカスしています。
Intel FPGA SDK for OpenCL
概要
こちらの記事でも紹介していますが、Intel FPGA SDK for OpenCL は高位合成 (High Level Synthesis, HLS) の処理系であり、次の図はそのプログラミングモデルを示しています。ホストコードは主に OpenCL API (Application Programming Interface) を用いての FPGA のコンフィグレーション、メモリ管理、カーネル実行管理などの FPGA デバイスの制御を担当し、カーネルコードは FPGA にオフロードされる演算を担当します。
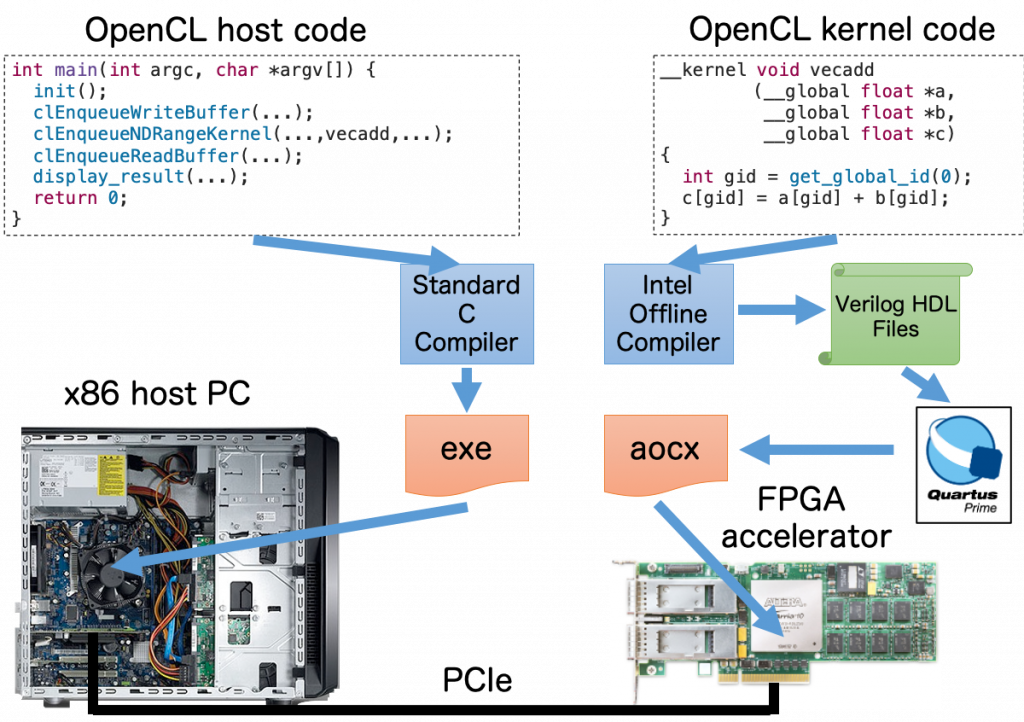
この FPGA 開発ツールチェインは All-in-One 型の総合開発環境であり、FPGA 向け OpenCL コンパイラだけでなく、ホストで動作する OpenCL ランタイムライブラリおよび FPGA PCIe ドライバを含み、このツールチェインだけでハードウェア開発に加えてホストから PCIe 経由で FPGA を制御する動作環境を構築できるものとなっています。
そのため、ユーザーはホスト PC で動作するホストコードと FPGA で動作するカーネルコードの2種類を記述するだけで、ハードウェア記述言語を知らなくても FPGA プログラミングを実現できるのが、このツールチェインを利用する最大のメリットです。
Channel を用いたカーネル間通信
Intel FPGA SDK for OpenCL は、FPGA に特化した言語拡張を有しており、その中の一つにカーネル間でデータを直接やり取りできる Channel と呼ばれる仕組みがあります。Channel の実態は、FPGA 内部メモリ (Block RAM) を用いた First-In-First-Out (FIFO) バッファであり、OpenCL の組み込み関数 (read_channel_intel()、write_channel_intel()) を用いて値を読み書きできます。次のコードは、OpenCL カーネル send からベクタ型 float8 の配列データをチャネルを通じてもう片方の OpenCL カーネルである recv に転送するサンプルです。
#pragma OPENCL EXTENSION cl_intel_channels : enable
channel float8 ch0 __attribute__((depth(16)));
__kernel void send(__global float8* restrict data, int n) {
for (int i = 0; i < n; i++) {
float8 v = data[i];
write_channel_intel(ch0, v);
}
}
__kernel void recv(__global float8* restrict data, int n) {
for (int i = 0; i < n; i++) {
float8 v = read_channel_intel(ch0);
data[i] = v;
}
}チャネルを通じたデータの送受信を実行する OpenCL カーネルコードを実装するたに、まず 1 行目のコンパイラ指示文でチャネル拡張を有効にし、3 行目でカーネル間の接続性を定義するチャネルのハンドルをファイルスコープ変数 ch0 として宣言します。この宣言されたチャネル変数と送信したいデータを write_channel_intel() 関数に渡す (8 行目) ことによって、recv カーネルでは、チャネル変数 ch0 を渡した read_channel_intel() 関数を呼び出す (14 行目) ことによって、send カーネルから送信される float8 の配列データを受信することができます。
ちなみに ch0 の宣言に付加された depth 属性はチャネルに利用される FIFO バッファの最小深度を指定でき、このコードでは 16 個の float8 データをブロッキングすることなくチャネルに書き込むことができます。チャネルがフルになった場合は、read_channel_intel() 関数でデータが読み出され、FIFOバッファのデータスロットが最低 1 つ利用可能になるまで、書き込み動作を進めることはできず、書き込み側のカーネルはストールします。逆に、読み出し側はチャネルが空の場合、write_channel_intel() 関数でデータが書き込まれ、最低 1 つのデータ要素が FIFO バッファで利用可能になるまで読み出し動作を進めることはできず、読み出し側のカーネルはストールします。つまり、FIFO バッファのオーバーフローおよびアンダーフローが発生しない仕様となっています。
この Channel を利用する最大のメリットは、外部メモリにアクセスすることなく 2 つのカーネル間でデータ交換を行える仕組みであることです。一般的な OpenCL の環境において、カーネル間でデータ交換をする場合は外部メモリを利用しますが、FPGA 環境における外部メモリは DDR4 (古い FPGA ボードやミドルレンジのものだと DDR3) の採用が一般的であり、レイテンシやバンド幅の面から性能が期待できません。一方で、2 つのカーネルがチャネルで接続されると、外部メモリにアクセスすることなく FPGA 内部に低レイテンシ・高バンド幅の通信を実行するデータパスを構築できます。この仕組みによって、ユーザーは FPGA 内に複数のカーネルを実装し、それらをチャネルを通じて接続することによって、空間並列性を活用するハードウェアアクセラレータを明示的にプログラミングすることが可能になるわけです。
このプログラミングをソフトウェア的に解釈すると UNIX における daemon が複数起動し、それらがソケットを通じて通信を行うことで処理を実行するものに近いかもしれません。事実、Intel FPGA SDK for OpenCL では autorun というカーネル関数に対する属性の拡張がサポートされており、この属性を付与すると FPGA コンフィグレーション後に、そのカーネルが UNIX daemon のように自動起動します (ホストから明示的に制御できなくなるので、autorun を付加したカーネルへのデータ転送はチャネルを介するものに制限されます)。ただし、UNIX におけるソケット通信はその都度通信オーバヘッドが発生しますが、Channel を用いた FPGA のカーネル間接続は、実際にはクロック単位で同時並列動作するハードウェア (パイプライン) として実装されるため、ハードウェアリソース (回路) を消費しますが、実行時のオーバヘッドはソケットよりも遥かに少ないというのが大きな違いとなります。
PE の中身
ART 法の演算コアである PE の中身を見ていきましょう。以下に (x, y, z) = (0, 0, 0) に位置する PE の擬似コードを示します。
#pragma OPENCL EXTENSION cl_intel_channels : enable
channel rt_ch[6][NPE_X][NPE_Y][NPE_Z];
// PE が保持するメッシュ空間
#define PE_MESH_SIZE (16 * 16 * 16)
// 1 つの面に 1 入力 / 1 入力 あるので、12 本のチャネルが必要
#define PE_INPUT_X_POS rt_ch[1][1][0][0]
#define PE_INPUT_X_NEG rt_ch[0][1][0][0]
#define PE_INPUT_Y_POS rt_ch[3][0][1][0]
#define PE_INPUT_Y_NEG rt_ch[2][0][1][0]
#define PE_INPUT_Z_POS rt_ch[5][0][0][1]
#define PE_INPUT_Z_NEG rt_ch[4][0][0][1]
#define PE_OUTPUT_X_POS rt_ch[0][0][0][0]
#define PE_OUTPUT_X_NEG rt_ch[1][0][0][0]
#define PE_OUTPUT_Y_POS rt_ch[2][0][0][0]
#define PE_OUTPUT_Y_NEG rt_ch[3][0][0][0]
#define PE_OUTPUT_Z_POS rt_ch[4][0][0][0]
#define PE_OUTPUT_Z_NEG rt_ch[5][0][0][0]
__kernel void PE_x0_y0_z0(...) {
// メッシュ空間のデータ (光学的厚みと source function) を格納する配列に Block RAM を利用する
__local struct radiation_mesh rmesh[PE_MESH_SIZE];
// メッシュにおける光学的厚み、メッシュの source function を格納
set_radiation_mesh(rmesh);
// 768 x N^2 の全てのレイに対してレイトレーシングを実行 (N = 16)
bool exit = false;
while (!exit) {
bool x_neg;
bool x_pos;
bool y_neg;
bool y_pos;
bool z_neg;
bool z_pos;
// レイの入力判定
INPUT_COND(x_neg);
INPUT_COND(x_pos);
INPUT_COND(y_neg);
INPUT_COND(y_pos);
INPUT_COND(z_neg);
INPUT_COND(z_pos);
// 隣接 PE から入力がある場合、レイデータを受信する
if (x_neg) ray = read_channel_intel(PE_INPUT_X_NEG);
else if (x_pos) ray = read_channel_intel(PE_INPUT_X_POS);
else if (y_neg) ray = read_channel_intel(PE_INPUT_Y_NEG);
else if (y_pos) ray = read_channel_intel(PE_INPUT_Y_POS);
else if (z_neg) ray = read_channel_intel(PE_INPUT_Z_NEG);
else if (z_pos) ray = read_channel_intel(PE_INPUT_Z_POS);
// ART 法の演算カーネルを実行 (輻射強度の計算)
calc_intensity(&ray, rmesh);
bool x_neg_out;
bool x_pos_out;
bool y_neg_out;
bool y_pos_out;
bool z_neg_out;
bool z_pos_out;
// レイの出力判定
OUTPUT_COND(x_neg_out);
OUTPUT_COND(x_pos_out);
OUTPUT_COND(y_neg_out);
OUTPUT_COND(y_pos_out);
OUTPUT_COND(z_neg_out);
OUTPUT_COND(z_pos_out);
// レイの次の計算領域が隣接 PE の保持するメッシュ空間である場合、レイデータを送信する
if (x_neg_out) write_channel_intel(PE_OUTPUT_X_NEG, ray);
else if (x_pos_out) write_channel_intel(PE_OUTPUT_X_POS, ray);
else if (y_neg_out) write_channel_intel(PE_OUTPUT_Y_NEG, ray);
else if (y_pos_out) write_channel_intel(PE_OUTPUT_Y_POS, ray);
else if (z_neg_out) write_channel_intel(PE_OUTPUT_Z_NEG, ray);
else if (z_pos_out) write_channel_intel(PE_OUTPUT_Z_POS, ray);
// レイトレーシングの終了判定
CHECK_TERMINATION(exit);
}
}PE の計算はレイ入力、輻射強度の計算、レイ出力の 3 つのパートから構成され、これらは FPGA 内でパイプライン動作するハードウェアとして実装されます。また、PE の計算は演算に必要な全てのデータを FPGA の Block RAM に格納してから行われますので、メモリアクセスによる性能低下を回避しています。
そして、隣接 PE とのレイデータの送受信は全て Channel を介して行われますので、全ての PE はクロック単位で同時並列的にパイプライン動作します。すなわち、1 FPGA に実装される ART 法アクセラレータは、時間並列性 (パイプライン並列) および空間並列性を活用したハードウェアであるため、ART 法の実効性能を最大化することが可能になるということです。
この構造は複数 FPGA を用いた並列計算を行う際に極めて重要となります。当センターでは、PE 間のチャネル接続をこれまでに開発した FPGA 間通信技術を用いて異なる FPGA 間に拡張することで、並列計算を実現するアプローチを採用しています。つまり、複数の FPGA を組み合わせることで巨大な PE クラスタを構築している、と言い換えることもできます。次回は、これの実現の根幹を成す FPGA 間通信技術について紹介していきたいと思います。
まとめ
2 回目となる今回は、Intel FPGA SDK for OpenCL の機能を活用した、宇宙物理アプリケーションの支配的な処理である ART 法のハードウェアアクセラレータの FPGA 実装を紹介させて頂きました。次回は、マルチ FPGA での並列コンピューティングを実現するための FPGA 間通信について紹介していきます。どうぞお楽しみに。
筑波大学 計算科学研究センター 小林諒平