
前回の記事では、私たちが国際会議 FCCM 2017 (論文 [1]) で提案した、2つのソートされた系列を1つの系列にマージするマージロジック回路の新しいアーキテクチャを紹介しました。
この記事では、これを用いて構築したハードウェア・マージソータ (Hardware Merge Sorter, HMS) の評価について解説します。
比較対象
性能を評価するためには適切な比較相手を見つける必要があります。ここでの比較対象は、国際会議 FCCM 2016 (論文 [2]) で Song らによって提案された PMT という当時の最速の FPGA ベースのハードウェア・マージソータです。
下図は PMT の E レコードのマージロジック回路(各クロックサイクルに E 個のレコードを出力できるマージロジック回路) を示しています。この例では E=4 です。この比較対象のマージロジック回路についても、その構成を少しだけ説明しましょう。
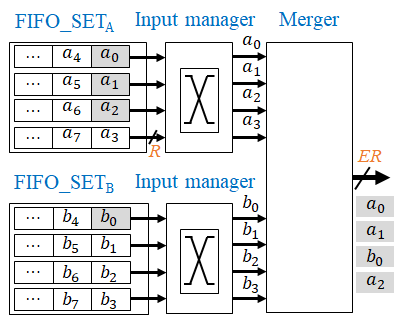
ここで2つの入力系列は a0, a1, a2, a3, a4, a5, … (a0 ≤ a1 ≤ a2 ≤ a3 ≤ a4 ≤ a5 ≤ …) と b0, b1, b2, b3, b4, b5, … (b0 ≤ b1 ≤ b2 ≤ b3 ≤ b4 ≤ b5 ≤ …) です。これらは FIFO_SETA と FIFO_SETB という2つの FIFO バッファセットに格納されます。
各セットは E 個の FIFO バッファを持ちます。 FIFO_SETA の最上部の FIFO バッファに a0, aE, a2E, …、次の FIFO バッファに a1, aE+1, a2E+1, … のようにレコードを格納します。FIFO_SETB も同様です。
マージャ (Merger) はソートされた2つの E 個のレコードの系列をソートして、最小の E 個のレコードを出力します。図1の例では、a0 ≤ a1 ≤ b0 ≤ a2 ≤ b1 ≤ b2 ≤ a3 ≤ b3 としています。そのため、灰色でハイライトされている E 個のレコード (a0, a1, b0, a2) が出力されます。
その後に、FIFO_SETA と FIFO_SETB 内の FIFO バッファの先頭レコードは (a4, a5, a6, a3) と (b4, b1, b2, b3) となります。(a4, a5, a6, a3) も (b4, b1, b2, b3) もソートされていないので、マージャに入力される前に入力マネージャ (input manager) で並べ替えられます。この処理は E x E のクロスバスイッチで実現されます。
出力レコードが決定されるまで、どの FIFO バッファからレコードを読み出すか分からないため、上記のマージロジック回路の処理を単純にパイプライン化してクリティカルパスのゲート段数を削減することは困難です。クリティカルパスのゲート段数は、1サイクルあたりの出力レコード数 (E) の増加とともに増加します。一方、私たちが提案したマージロジック回路は、 E を増やしてもクリティカルパスは1個のコンパレータと1個の2入力マルチプレクサの一定で変わりません。
マージツリー (Merge Tree)
提案したハードウェア・マージソータを SHMS と呼ぶことにします。SHMS は、比較対象の PMT が採用しているように、次の図のマージツリーの形で実装されます。
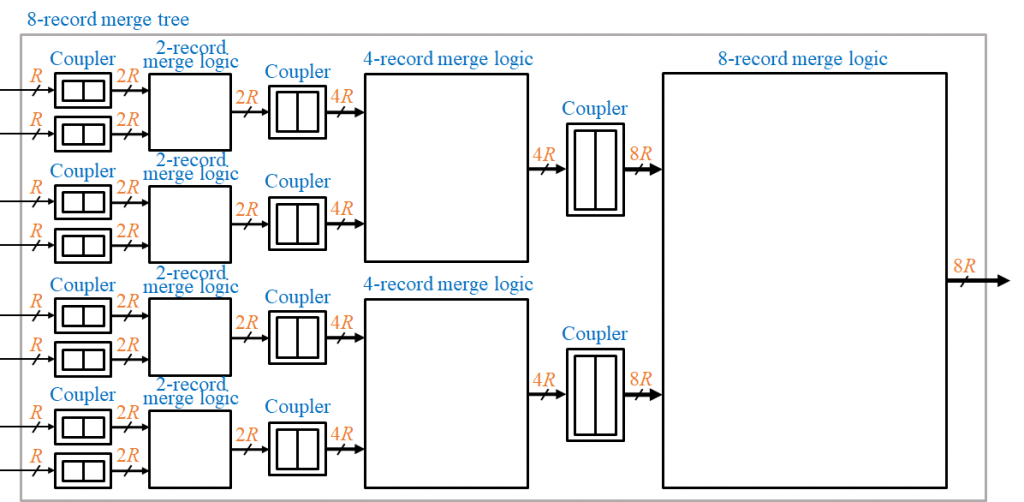
このマージツリーは異なるサイズのマージロジック回路から構成されます。各マージロジック回路の入力側に、2つのレコードセットを1つのセットにくっつけるカプラ (coupler) を置きます。
この図は、サイクルあたりに8個のレコードを出力する構成です。すなわち、左端に E=8 のマージロジックを1つ、その左に E=4 のマージロジックを2つ、その左に E=2 のマージロジックを4つ接続する構成となります。このようなツリーの構成にすることで、同時にマージする入力の系列の数を増やすわけです。
右端の根ノードのマージロジック回路が、ツリー全体の性能と構造を決定します。このマージロジック回路の1サイクルあたりに出力するレコード数を E とすると、ツリーが同時にマージできる系列数 K も E となります。図2は、E=K=8 の構成となります。一回目の記事で説明したように、ソーティング性能は E と log2K に比例します。
以下では、根ノードに E レコードのマージロジック回路を持つマージツリーを E レコードのマージツリーと呼ぶことにします。また、E レコードのマージツリーの構成を持つ SHMS と E レコードの PMT をそれぞれ SHMS(E) と PMT(E) と書くことにします。
E レコードのマージツリーの理想的なスループットは E records/cycle です。これは,毎サイクルにどの入力系列からも1個のレコードが読みだされる場合に得られる値です。しかし、実際には、入力データの偏りにより、一般に E レコードのマージツリーのスループットは E records/cycle より小さくなります。つまり、有効なレコードを出力しないサイクルが存在しています。論文 [2] で Song らは、マージツリーでソートする前に入力データセットをリシャフルすることにより、この問題を緩和できることを示しています。
評価方法
SHMS と PMT を評価では、FPGA のリソース使用量、アクティブレート、動作周波数、スループットという4つの指標を用います。
マージツリーのアクティブレート α (0 < α ≤ 1) は、有効なレコードが出力されるサイクル数を経過サイクルの総数で割った比率として定義します。名前から推測できるように、意味のあるデータが出力されたサイクルの割合です。アクティブレートが 1.0 であれば、すべてのサイクルでちゃんとレコードが出力される理想的なハードウェアになります。この α は入力データの分布とマージロジック回路の実装の両方に依存します。
次に、E レコードのマージツリーのスループット (T) は以下の式で計算できます。
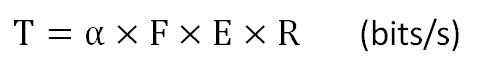
ここで、F と R はそれぞれ回路の動作周波数と各レコードのビット幅です。今回の評価では、R=64 とします。このスループットは単位時間 (秒) あたりに処理できるデータ量なので、高いほど高性能になる指標です。
論文 [2] のように、ターゲットの FPGA デバイスはザイリンクス社の Virtex-7 XC7VX485T です。研究開発でも用いられる大規模な FPGA を搭載しています。実装には Verilog ハードウェア記述言語を用いました。FPGA 合成および配置配線は Vivado で自動的に処理させています。
評価結果
FPGA のリソース使用量
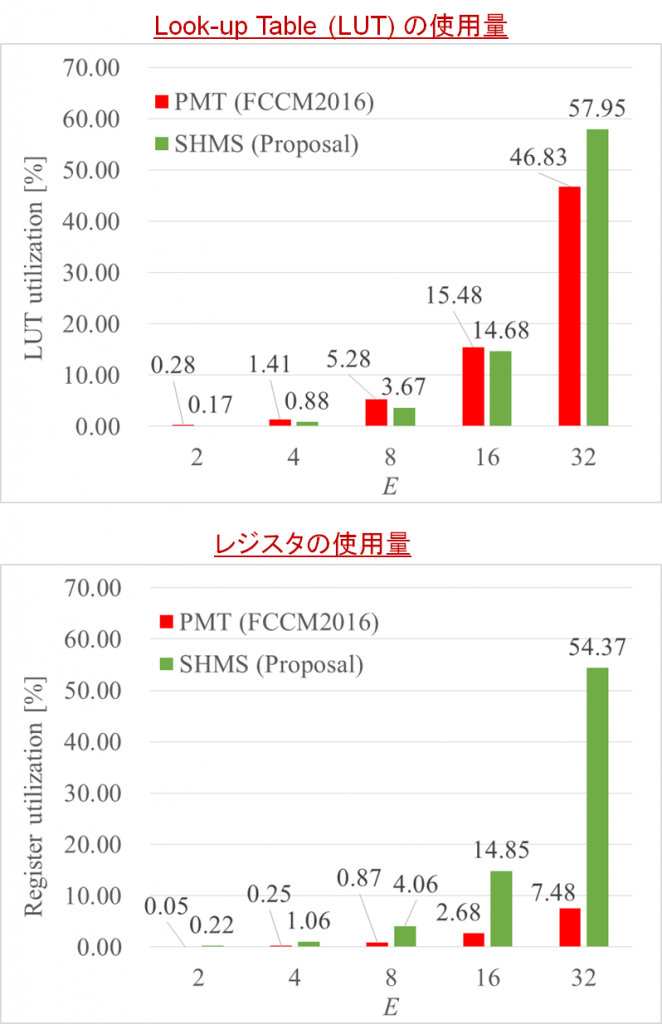
上図に LUT の使用量のグラフとレジスタの使用量のグラフを示します。ここからわかるように、SHMS は PMT に比べて多くの FPGA リソース (特にレジスタ) を使用します。SHMS(32) は PMT(32) より1.24倍の Look-up Table (LUT) と7.26倍のレジスタを消費しています。これは、SHMS が深いパイプラインの構成を持つためです。多くのパイプライン段数は、以下に示すようにソーティング性能を高速化しますが、特にレジスタの使用量の増加につながります。
提案手法の LUT の使用量は対象とする FPGA の58%です。一方、PMT と比較して、提案手法のレジスタ数がかなり増加していますが、それでも FPGA の約55%のレジスタしか用いていません。これは LUT の利用率よりもまだ低い値です。この値を見ると、PMT で有効に使えていなかったレジスタを提案手法では活用できている、と捉えることもできます。
アクティブレート
SHMS と PMT のアクティブレートの評価は Verilog シミュレーションにより求めました。評価ではランダムに生成された入力データ系列を用いています。測定結果を次に示します。
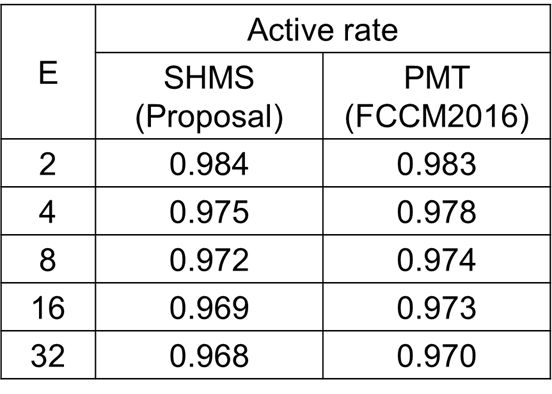
上表からわかるように、SHMS は PMT と同等の高いアクティブレートを達成しています。E=32 という大規模な構成であっても、0.967 という高い値を維持します。すなわち、スループットに対するアクティブレートの影響はほとんどありません。
動作周波数
SHMS と PMT の動作周波数の結果を次に示します。SHMS と PMT の5つの構成 (E = 2, 4, 8, 16, 32) の動作周波数を示しています。
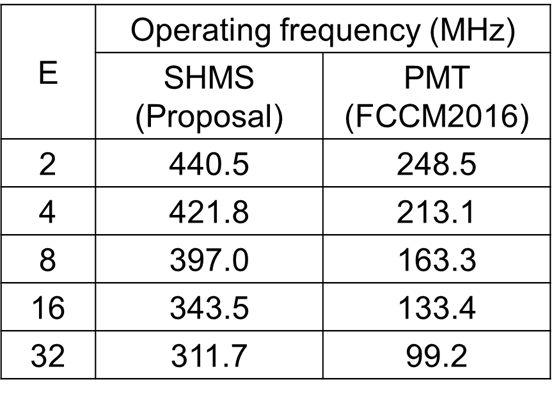
SHMS は PMT よりはるかに高い動作周波数を達成します。SHMS(32) の動作周波数は PMT(32) の動作周波数より3.14倍も高いです。これは、E を増やしても SHMS のクリティカルパスは1個のコンパレータと1個の2入力マルチプレクサの一定で変わらないからです。一方、PMT では、E を増やすと、クリティカルパスのゲート段数が増加するため動作周波数が E=2 の248MHz から E=32 の 99MHz へと大幅に低下します。
クリティカルパスが一定なのに、どうして SHMS でも E を増やした時に動作周波数が低下するのでしょうか? それは、FPGA に実装する回路の動作周波数が、その回路の規模、配線による遅延、ファンアウトなどの影響を受けるからです。
補足です。実は、回路の最大の動作周波数を求める作業は簡単ではありません。Vivado で論理合成 (と配置配線) をすれば自動的に出てくるものではありません。
例えば、100MHz の動作周波数の制約で論理構成すると、100MHz で動作するかどうかはわかりますが、150MHz で動作するかはわかりません。 100MHz (10nsec) の制約を満たして、余裕 (slack) が 5nsec あると Vivado が教えてくれる場合には 200MHz で動くことが予測できます。ですが、それでもやはり 200MHz の制約で試してみる必要があります。このため、回路の最高の動作周波数を求めるためには、さまざまな動作周波数の制約で論理合成して、それらの中で制約を満たした最も高い周波数を求める必要があります。簡単ではありません。
スループット
SHMS と PMT のスループットの結果を次に示します。5つの構成 (E = 2, 4, 8, 16, 32) のスループットを示しています。
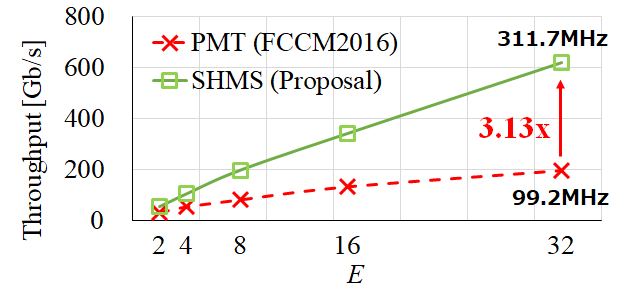
先に示したように SHMS は高い周波数で動作するため、PMT よりもはるかに高いスループットを達成します。SHMS(32) のスループットは 617.9 Gb/s であり、PMT(32) と比べて3.13倍の高速化を達成しました。
ソーティング時間はスループットに逆比例するので、SHMS(32) は PMT(32) より3.13倍速いことになります。
まとめ
今回は、私たちが論文 [1] で提案したハードウェア・マージソータ SHMS の評価を述べました。SHMS は当時の最速の FPGA ベースのハードウェア・マージソータである PMT と比較して、3倍を超える高い性能を達成しました。
次回は、残された研究課題と今後の展望について解説します。
東工大 Thiem Van Chu
参考文献
- Susumu Mashimo, Thiem Van Chu, and Kenji Kise, “High-Performance Hardware Merge Sorter,” The 25th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), May 2017.
- Wei Song, Dirk Koch, Mikel Lujan, and Jim Garside, “Parallel Hardware Merge Sorter,” The 24th IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), May 2016.