目次
2. アーキテクチャの検討
2-1. FPGA 優位のデザインパターンと典型問題
■ 高性能アーキテクチャの鉄則
■ タスク “内” の並列性と課題
■ タスク “間” の並列性と課題
■ HLS-C で表現できないケース
2-2. 実装品質の限界まで求められるケースも
2-3. そもそもハードウェア化すべきなのか?
Coffee Break. 最終形は 「ML+X」 over 「AIE+PL」 かも?
高位合成と C ベース設計 ~ 2章 アーキテクチャの検討
Xilinx の黒田です。さて、前回の1章 (「HLS の誤解を解く」) から半月ほど間が空きましたので、本章の本論に入る前に1章のリキャップと (あるいは1章を読まずに本章から初めて読まれる方にとっては1章を読む手間が省けるように…、ていうかすません、いつでもいいので1章も是非読んで下さい!) あと、今後話を進めていく上での前置きをいくつかしておきたいと思います。
1章のおさらい
CPU や GPU で実際に動いているものは汎用プロセッサ (マルチコア、メニーコア) というすでに出来上がっているアーキテクチャ/方式のハードウェアがあって、その上で動くアプリケーションにしても、その高性能化にしても、プロセッサを動かす指示を与えるための “プログラミング” で実現されます。
その指示の内容を考えるのは人間ですが、プロセッサが直接理解できる指示の羅列だと大変なので、コンパイラの力を借りて人間が理解できるレベルまで可読性を上げた指示の表現方法がいわゆるプログラミング言語で、CPU に対する C/C++ もその一つです。
一方 FPGA はハードウェア (論理回路) の素材を提供するだけであって、その上で何かを動かそうにもハードウェアのアーキテクチャからして誰か (人間) が考案して “設計” してあげないと、そもそも何も始められない訳です。
当たり前の話じゃないかとあきれている方がいらっしゃるかも知れません。著者としては割とマジメに話をしているつもりです。あるいは、1章で言葉遣いの在り方についてもいろいろ考えながら24,000文字以上も費やして語ったはずなのに、まだ気が済んでいないのかも知れません。。 (^^;
1章では、設計生産性の観点からそのような FPGA に対して設計者が1チップをフルスクラッチで開発するのではなく、ホスト (CPU) 上で動作する SW アプリの一部である計算アルゴリズムを FPGA にオフロードするための仕組みとして、Xilinx が用意しているプラットフォームがまずあって、そのアルゴを担うアクセラレータ/カーネルをそのプラットフォームに自動で繋いでくれるツール (Vitis) までお膳立てされていることで、「設計者が新規で開発するハードウェアとしてはカーネルだけで良い」という状況を前提として話をしました。
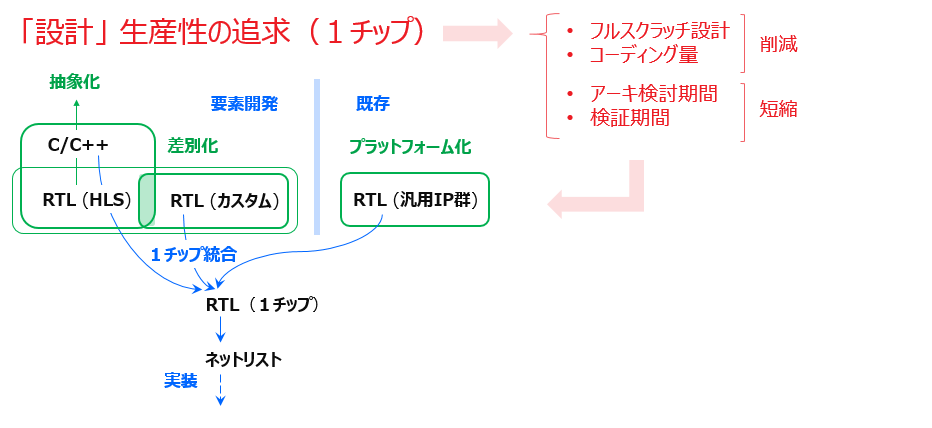
そのカーネル開発も、もう一つのツールである HLS を使えば、アプリからパーティショニングされただけの計算アルゴの C/C++ コードであっても HLS が受け入れられる内容でありさえすえば、カーネルのハードウェア (RTL) を自動生成できることで結局、アプリのオフロードのための1チップ HW/SW 開発の全てを C ベースで済ませられることになります。それ自体すごい事 (デバイスベンダー製の垂直統合 EDA (1章の Coffee Break も参照) にしか実現できない事) です。
でも問題はそのカーネルの中身で、C/C++ といってもやっぱりちゃんと設計しないとダメだし、RTL 設計だとしても HLS を利用して設計生産性も問題にしないといけません、といった感じで話を進め、アクセラレータ/カーネル開発についてこれから見ていきたい範囲と論点を絞り込んでいった訳です。
これまでの話から、アクセラレータ/カーネルの C ベース設計に対する “心構え” の部分 (本連載の中心には常にこの話が在ります) を、ここであらためて繰り返します:
- 世のため人のためになる高性能アクセラレータのアーキテクチャは、人間にしか考案できない
- HLS-C (1章) はそのアーキを記述するための HDL であり、プログラミング言語ではない
- HLS-C だけで記述が済めば理想だが、それが出来ない内容なら RTL で記述すればいい
- それでも HLS か RTL の二択とせず、HLS を道具として全体の設計生産性 UP も図るべき
3) と 4) について具体的には、主に3章 (最終章) で論じます。
本章では、1) と2) の構えで、計算アルゴリズムのアクセラレーション (Compute Acceleration) を実現する「高性能カーネルのアーキテクチャ」とは何か?を、FPGA に即して具体的に見ていきます。
今後のための前置き
ここでいくつか前置きをさせてください。この連載一回目の「はじめに」の冒頭で、開発するアクセラレータについて “対象がエンベデッドか?/サーバーか?にかかわらず” と言いましたが、製品向けの1チップ HW/SW 開発まで考えたときに、対象のホストがエンベデッド (組込み) になるか、サーバーになるかで、”開発全体” の様相としては大きく異なってきます。
Vitis がサポートするのはサーバー向けの Alveo カード上の FPGA だけではなくて、エンベデッド向けの Zynq SoC (Zynq、ZynqMP) 上の FPGA の両方です。つまり、Vitis がカーネルを繋げられるプラットフォームをそれぞれについて Xilinx が用意しています。
特に Zynq SoC については、組込み製品 (あるいは試作) の用途や事情によってプラットフォームに求められる要件がハード (IO 他) とソフト (OS 他) 共に多種多様になってくるため、そこでは、Zynq 上の ARM から計算アルゴを同じ Zynq 上の FPGA にオフロードするために Xilinx が用意しているプラットフォームだけではカバーし切れません。その使い道を組込み開発全体のどこに位置付けてどのように活用するべきかという話があるかと思います。
前者は Vitis の恩恵は受けるも、Vitis 対応のためのカスタマイズが面倒そう。後者だと、従来的な開発手法で、Vitis すらそもそも使いません。それはもう案件毎で与えられた状況か、歴史的な経緯次第だと思います。ちなみに、同じ理由で Alveo 上の FPGA をフルスクラッチで開発したいケースもあると思います (そのために、Alveo 向けのボードファイル等の設計データ一と緒に Vivado フローが用意されています)。
あるいは、同じエンベデッド向けでも、組込み製品の中でホストのプロセッサあるいは SoC は別 (つまり Xilinx 以外) にあって、Xilinx といっても Non-Zynq の FPGA デバイスにオフロードしたいという形態、つまり Vitis プラットフォームがそもそも存在しない状況/案件も、当然あるはずです。
いずれにしても、どんな形態の製品/システムであれ、ホスト CPU 上で動作する SW アプリとしての計算アルゴがあって、それを FPGA にオフロードするほうがシステム全体として高性能化が図れるのならば、遅かれ早かれ、少なくともアクセラレータ/カーネルの開発は共通して必要になってきます。
それをどのタイミングでどのように開発するのか?具体的には3章で展開しますが、簡単に言えば、最終製品としての実装先はどこであれ、少なくともアクセラレータだけは、Alveo を挿したサーバー上で高位合成 (HLS、Vitis) を使い、あるいは最終的には人手の RTL 設計かも知れないですが、これまでに述べたような設計生産性の高い環境の下で、別立てで先行して開発しましょう、という提言です。これを、”アクセラレータの先行要素開発” と呼びたいと思います。
手元の Alveo ではなくクラウドの F1 を利用する、という手もあります。どちらを利用するかはプロジェクトの状況 and/or お財布次第、かと思います。
Xilinx からの第1期ブログ連載に、Amazon EC2 F1 インスタンス (Alveo U200相当のアクセラレータ カードが挿入されている EC2) を開発環境として利用するための分かり易い解説とチュートリアルがありますので、必要になったときには是非こちらを参考にしてください (以下)。

さらには、FPGA をターゲットとする高性能アクセラレータの開発といっても、その競合が組込み SoC (ARM) なのか、サーバー (Xeon、他) あるいは GPU なのかによって、求められる性能や複雑度のレベルにも大きな違いがあります。恐らく想像がつくように、エッジ側よりもサーバー側の世界で居場所を見つけるほうがより大変です。
また、サーバー (特にデータセンター向け) の世界では、従来から FPGA を採用する企業 (例えば、組込み製品メーカー) が関わってきたビジネスとは、その活動のパラダイムが全く異なっていますので、新規参入を考える場合には、技術だけでなくプロジェクトの進め方や組織 (ビジネスと技術) の在り方に対しても変革を迫られることになるのではないかと、筆者は考えています。技術だけでなく組織やビジネスの話まで持ち出す理由は、何を進めるにもお互いが不可分な関係/状況にあるためです。
具体的には本章の後半で展開します。その話の読者モデルとしてはどちらかというと「企業」の方を想定していますが、もう一人の読者モデルである「学生」の方にも就活を考える上で参考になればと思っています (執筆の背景として、前回ブログの「はじめに」も参照ください)。
そういった諸々の状況を考慮して、開発環境としても、問題意識の背景としても、エンベデッドよりは Alveo 挿しのサーバーを本流に据えて優先する形で、話を進めていきたいと思います。
以降は、特に断りが無ければ、暗にサーバー向けの状況を想定した上での話と致します。
以上、本論へのあまりにも長過ぎる “前フリ” でした。
2-1. FPGA 優位のデザインパターンと典型問題
FPGA をターゲットとして、計算アルゴリズムのアクセラレーションを実現する高性能カーネルのアーキテクチャを検討する上で、必ず守らないといけない (守らないと FPGA の良さを引き出せない) 鉄則があります。
その鉄則に従うと、「演算器 → サブモジュール → カーネル TOP (階層デザイン) → HW/SW ラインタイム」の各粒度/レベルにおけるデザインパターンの要件と、要件を満たすために取り組むべき典型問題が (自然と) 見えてきます。
本節では、そのデザインパターンの説明と併せて、要素アーキテクチャに対応する HLS-C の記述スタイルも (できるだけ) 一緒に示すようにします。論理合成にしても高位合成についても、参考書が最も紙面を費やすのは、合成ツールにエントリーする記述スタイルと、合成後に生成されるアーキあるいは回路との関係性の提示/説明です。また、HLS-C では表現できない (C-Sim (1章を参照) では検証できない) 類のデザインパターンやシチュエーションについても少し触れます。
本節で提示されるデザインパターンは、要素アーキ毎の “一般解” としてのそれです。競争力を持った “売り物” としてのカーネルのアーキは、それらのアーキ要素を様々な粒度で (複雑に) 組合せて出来上がる特殊解あるいは最適解です (個人的には、FPGA って元々そういうものだったような気がします) 。
特定のアプリ/業界の、特定の案件において、特定の経緯で与えられたレファレンス アルゴリズムのアクセラレータ開発に取り組んだとして、そこに FPGA の選択が優位となる “特殊解/最適解” が存在するかどうか、その見極めに至るプロセスには、組織としていろいろな方面のスキル (後述) が求められると思っています。
高性能アーキテクチャの鉄則
カーネルの性能というときには、SW アプリからアルゴを切り出してアクセラレータを開発する訳ですから、実際に開発するのがハードウェアであっても、ホストプログラムのレベルまで視点を引き上げて HW/SW ランタイムとして評価しないと意味がありません。その性能をホストプログラムの視点で分析すると、以下のスライドに示すように大きく3つの要因に分解できます。
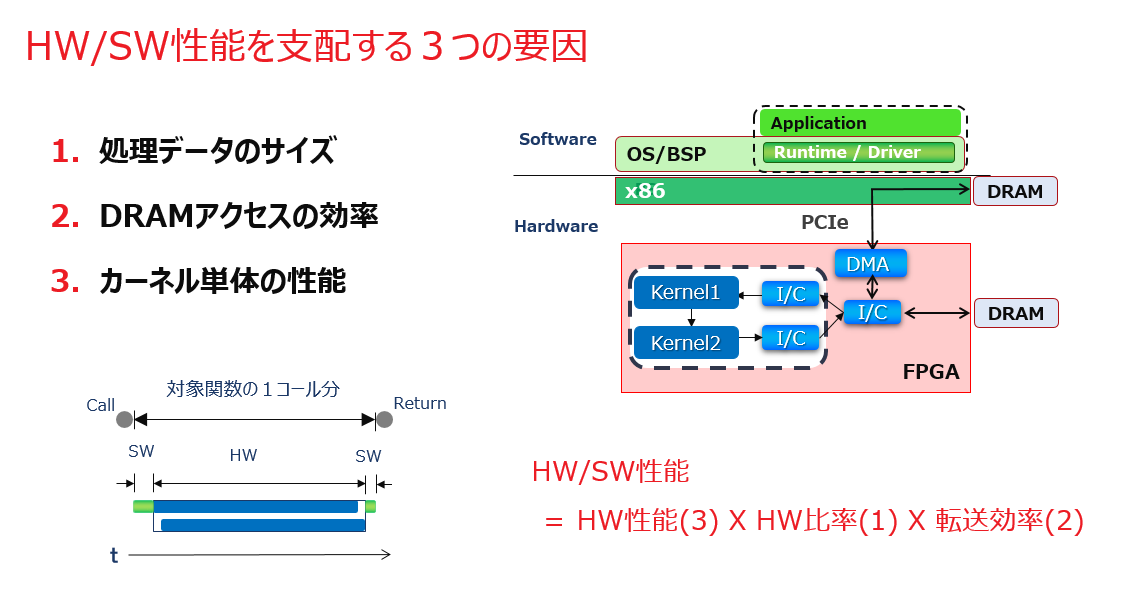
カーネルのハードウェアは、ホストプログラムから見ると、カーネルを制御するための関数 (ランタイム API) の中に隠蔽される形で利用され、その性能はカーネル関数のコール~リターン時間で計測されます。
全体の性能としては、カーネルが処理するデータをホストから手元 (Alveo カード上の DRAM あるいは FPGA ダイ上の HBM) に転送する時間も考慮する必要がありますが、上の図はそれが済んだ後にカーネルをコールしている状況を示しています。
カーネルからデータへのアクセスの仕方には、Xilinx の提供する Vitis プラットフォームとしては、ホスト側の DRAM に直接アクセスするか (QDMA)、ホスト側から Alveo 側の DRAM あるいは HBM にコピーした上でアクセスするか (XDMA)、という2つの方法があります。
前者ではコピー転送が要らなくなるのでレイテンシ的に有利ですが、後者よりも多くの回路リソースが必要になるトレードオフと、PCIe も越えて物理的に遠く離れてしまうために全データの一括転送以外の頻繁なアクセスを避けたい状況への配慮も必要です。
後者の場合には、そのままだとデータ転送のオーバーヘッドが加算されるインパクトがありますが、データ転送とカーネル実行を Runtime プログラム (スレッド) 側でパイプライン化してあげれば、そのマイナス面をスループット上は隠蔽できます。その辺りの様子については、Xilinx からの第1期ブログ連載に分かり易い図解がありますので (以下) 、そちらも参考にしてください 。
性能要因の1) は、カーネルが一回の実行でアクセス/処理するデータのサイズのことを言っていますが、大きいほど良いです。
カーネルが関数としてホストプログラムからコールされて実行される時間には、スライド中の図でも示すようにホストプログラムがハードウェアを起動するまでの準備と終了の認識を行う処理のオーバーヘッドが含まれますが、ハードウェア処理の期間を大きくするほどオーバーヘッド期間の相対的な圧縮が図れます。そのために、カーネル関数に渡すポインタのデータサイズを出来るだけ大きく取れるシチュエーションをアプリケーション側で担保されるか?、という話になります。
動画像処理のようなアプリだと、サイズの大きいフレームデータを相手にすることが最初から分かっているので通常は問題になりません。
性能要因の2) は文字通りの内容を言っていますが、カーネルから DRAM へのアクセスが (本当はヤだけどどうしても) 必要になるようであれば、最大バンド幅を目指しましょう、という話になります。その際はランダムアクセスが少ないほど良い。というか、FPGA 向けにはあって欲しくないです。
DRAM へのアクセスパタンがランダムだと、各データをアトミックにポツポツと転送することになるので効率が悪くなります。アクセスパタンがシーケンシャルだと連番のデータ列を一括してバーストで隙間なく転送できるので、理想は全てのアクセスが後者で済むことです。
Alveo カードとしてのバンド幅あるいはスループットのそもそもの上限はもちろん、DRAM の前に PCIe/DMA です。
ちなみに、この連載では触れませんが、カーネルのアクセス先として PCIe や DRAM だけでなく、Alveo 上の超高速 IO という話もあります。今は Alveo カード一枚の話をしていますが、高速 IO で繋がる複数の Alveo カードを対象に世界を拡げていけます (例えば、科学技術計算などの HPC 分野が考えられるでしょうか)。その話はまた別の機会に (別の人に www) 譲りたいと思います。
性能要因の3) はホスト視点での要因分析という切り口でカーネル全体を見ています (その内訳の鉄則については後述します) が、上述のホストプログラム由来のオーバーヘッドや DRAM アクセス効率の要因を除いて、ハードウェア単体としての最大性能の理論値のことを意味しています。
1章の1-2節で触れた HLS の話でいうと、高位合成後の生成回路 (RTL) に対する確認項目4つの中の1) に挙げた、目標性能としてのクロックサイクル数に相当します。
このように HW/SW ランタイムとしてのカーネルの性能をそれら3つの要因に分解して捉えると、スライド中の掛け算で示すように、ハードウェアの設計から HW/SW ランタイムの実装を経て Alveo 上で実行して採取したカーネル関数コールのプロファイルを、正確に分析できるようになります。この理解が得られると、ツールを使って設計を積み上げていくときに、きちんと足元を踏み固めながら進めている感が得られます。
どういう事かと言えば、まず、HLS カーネル (1章 1-1節) であれば HLS のレポートあるいはシミュレーション (Co-Sim) の結果で、カーネルのハードウェアがフル稼働の想定での最大性能が理論的に分かります (HW 性能(3))。
次に、実機動作のプロファイルによって、ホスト視点でのカーネルのアクティブ期間が見えることから、それに対するホストプログラムのオーバーヘッド期間が分かるので、その割合がファクターとして掛かってきます (HW 比率(1))。
最後に、
“[カーネルの実際のアクティブ期間] ー [理論値としての期間 (HW 性能(3)) ]”
を求めれば、カーネルの一回の実行で DRAM アクセスに絡んで実際にどのくらい待ちを食らったか (これを “ストール” と呼びます) が分かるので、その割合がファクターとして掛かります (転送効率(2))。
ちなみにストールの要因には二つあって、カーネル自身のアクセス効率と、別のマスターによるアクセスで DRAM の帯域が混んでしまっている状況の可能性です。
以上はカーネルに対して外側から決まってくる要件あるいは制約ですが、そこに FPGA というハードウェアの素材を持ち込んで、高性能を狙うカーネルはどのようなアーキテクチャで構成されるべきなのか?を考えていくと、次のような鉄則というか、まるでどこかの老舗に代々伝わる家訓のようなガイダンスが、おのずと導き出されてきます。
- カーネル1回の実行でアクセス/処理するデータのサイズを十分に大きく取れ
- カーネル外部の DRAM へのアクセスパタンはシーケンシャルに変え、バースト転送を実現せよ
- 2) の為に、入出力に直結する本流のデータパスはパイプライン (“土管” と呼ぶ) を目指せ
- 本流のデータパスに沿った演算処理は、土管が実現出来るほど十分な並列化を心掛けよ
- 元の外部ポインタへの (局所的) ランダム&冗長アクセスは、FPGA にキャッシュして行え
- カーネル内のアルゴリズムが複雑な場合には、タスク分割した上で階層設計を検討せよ
鉄則1) については、性能要因1) で述べた通りで、アクセラレータ化の大前提として SW アプリ側で担保しておいて欲しい状況になります。
大きなデータサイズのポインタが、HW アクセラレータを含むカーネル関数に直接渡せる形で、ホストプログラム側で準備されているか (でなければ、出来るか)?、という話です。それが複雑なデータ構造の中に埋もれてたりしてそのままでは直接は取り出せない状況にあったりすると、面倒な話になります。多分、HW アクセラレータ化の可能性を事前に考慮して SW アプリ/アルゴを開発することのほうが稀かも (そして今後は FPGA を含むヘテロデバイスの時代に向けては改めてもらいたい前提になっていくかも) 知れません。
その上で、鉄則の2) 3) は性能要因2) から導かれる内容で、DRAM へのアクセスをバーストで行えるようカーネル内のアーキを検討すべし、になりますがそれは、鉄則の4) 5) 6) にとっては “十分条件” という関係になります。
つまり、2) 3) が実現するように、具体的には 4) 5) 6) を検討しましょう、という意味です。
ということで、これからカーネル内部のアーキテクチャの話に入っていきますが、その前に “タスク” の概念を導入します。
学術的な定義はあるかも知れませんが、ここでは「以降の話を進め易くするための便宜上の定義」であることを断っておきます。
元のレファレンスの計算アルゴがどのような C/C++ の記述スタイルで書かれているのか、事前には予想が付きませんが、アクセラレータ化の事など微塵も意識していない事だけは確かです。
計算アルゴの内容が複雑だったとして、その記述スタイルはスパゲッティ or べた書きかも知れませんし、あるいは SW アプリ開発側の都合 (ソフトウェアのコーディング生産性の観点) で緻密に練られた階層構成を持たせているかも知れません。
ソフトウェアプログラムとしての C/C++ コードの階層構成と、ハードウェア記述としての HLS-C コードのそれとは、背景あるいは目的が全く異なります。後者はハードウェア モジュールを表現するための記述スタイルです。
なので (あえて極端な言い方をしますが)、間違っても「前者を起点に捏ねくり回して後者まで持っていこう」なんていう発想をしないことが、HLS-C によるアクセラレータ設計の心構えとして致命的に大事になってきます。RTL 設計だと意識しなくても最初から別物ですが、HLS-C の場合は別物であることを特に意識する (今まで用いていた言葉の表面的な理解だけに引きずられないように気を付ける) 必要があります。
タスクの概念は、そのように素性の分からないソフトウェアのレファレンスコードを、高性能アーキテクチャの観点で解釈し直すために用いる解析の道具になります。
上述の鉄則の2) 3) の通り、カーネルが処理するデータの大元は DRAM から来ますので、そのバンド幅を使い切れないハードウェアに意味なんて無いです。なので、DRAM から入力するデータ列がカーネル内で様々な処理を受けながら左から右に抜けていくものであろうと、あるいはローカルのメモリ (レジスタ、BRAM/URAM) にキャッシュするためのデータ転送であろうと何であれ、入出力に直結するデータパスのスループットは DRAM アクセスの最大バンド幅に何としてもマッチさせなくてはなりません。
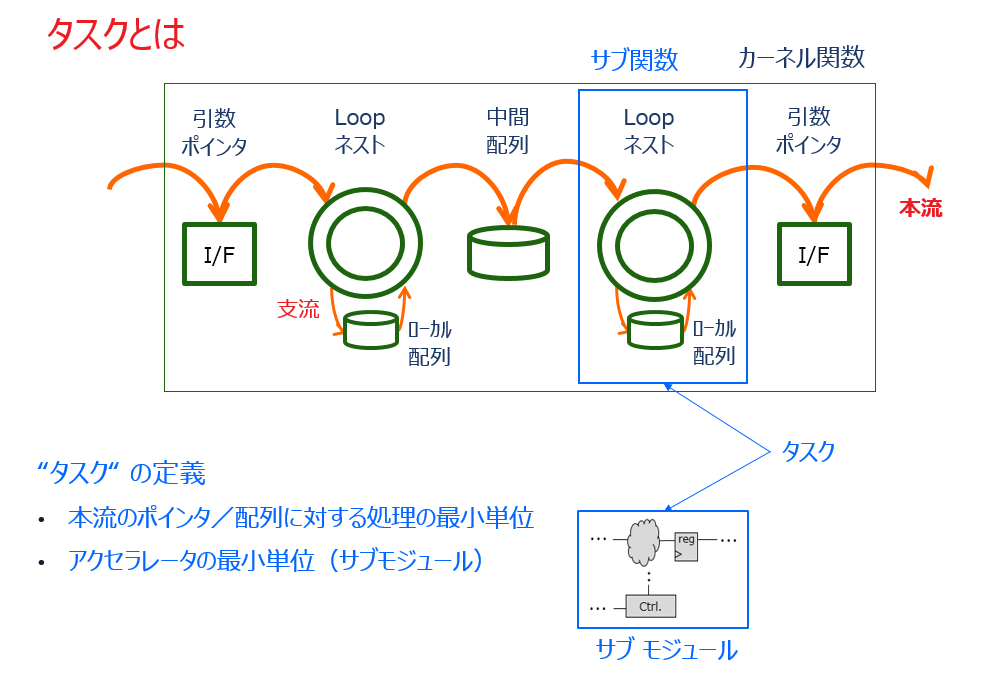
カーネル内のそのようなデータパスを “本流” と呼び、本流を流れるデータ列に対して何らかの処理を行う最小の単位を “タスク” と呼ぶことにします。タスクは、上のスライドで示すように、
・ C/C++ 記述の観点では、ポインタ/中間配列に対する処理の最小単位である “サブ関数”
・ ハードウェアの観点では、本流を入出力するアクセラレータの最小単位としての “サブモジュール”
の二つを結び付けて付けてくれる概念的な道具になってくれます。
C/C++ のレファレンスのコードをタスクの切り口で分析すると、本流データを格納するポインタ/中間配列を介したサブ関数の集まり (グラフ) として、捉え直すことが出来ます。この作業を “タスク分割” と呼ぶこととします。
それをハードウェアとして見ると、”チャネル” を介したサブモジュールのグラフで構成される階層デザインに対応します。チャネルの具体的な実装 (の決まり方) については後述します。
レファレンスの C/C++ コードに対するタスク分割という作業は、同時に、カーネルのトップレベルの構成を検討することにもなる、という訳です。
ちなみに、このタスク分割という作業を、机上だけの鉛筆舐め舐めだけで済ませるのか、あるいはそれを、レファレンスから HDL へ橋渡しをするための中間 C/C++ モデルという成果物として残し、以降の設計に継承していくのか、それは人なのか状況によってか進め方に差が出るところかも知れません。
HLS-C で進めるならもちろんですが、人手の RTL 設計の場合であっても (特に規模が大きい階層デザインでは) アーキ検討用に中間 C/C++ モデルを用意し、それをその後のハードウェア設計のための直接的な機能レファレンスとしても利用する、というケースはあるようです。
タスク概念の導入のために周り道をしましたが、これから鉄則の4) 5) 6) に沿ってカーネル内部のアーキテクチャを考えていきます。
上述のタスクの理解を踏まえると、鉄則の4) 5) はタスク内部の、6) はタスク間の、アーキテクチャの話になります。
タスク “内” の並列性と課題
上に挙げた「タスクとは」のスライドに示すように、タスク内のアーキテクチャとはつまり、アクセラレータ単体のそれになります。単なるスカラー演算器とは違い、一回の実行でサイズの大きなデータ (フレーム) を処理する回路の粒度になり、フレームの始め (start) と終り (done) を認識し、データの流れを制御するステートマシン (FSM) を有します。開始時にパラメータを受ける場合には、実行中に参照できるようにレジスタを持ちます。
そのようなアクセラレータの中で、DRAM アクセスと入出力を経由して直結する本流データパスを “土管” にすることが目指すアーキテクチャの大目標であり、鉄則4) が示す通りです。
鉄則4) 本流のデータパスに沿った演算処理は、土管が実現出来るほど十分な並列化を心掛けよ
そういえば、”土管” の定義をしていませんでした。土管とは、1章の1-2節 (「C ベース高位合成 (HLS) の基本」) の中で説明したパイプラン演算器のマイクロアーキテクチャを含み、クロックサイクル毎に次々とデータ列を流し込める状況にあるデータパスのこと、とします。
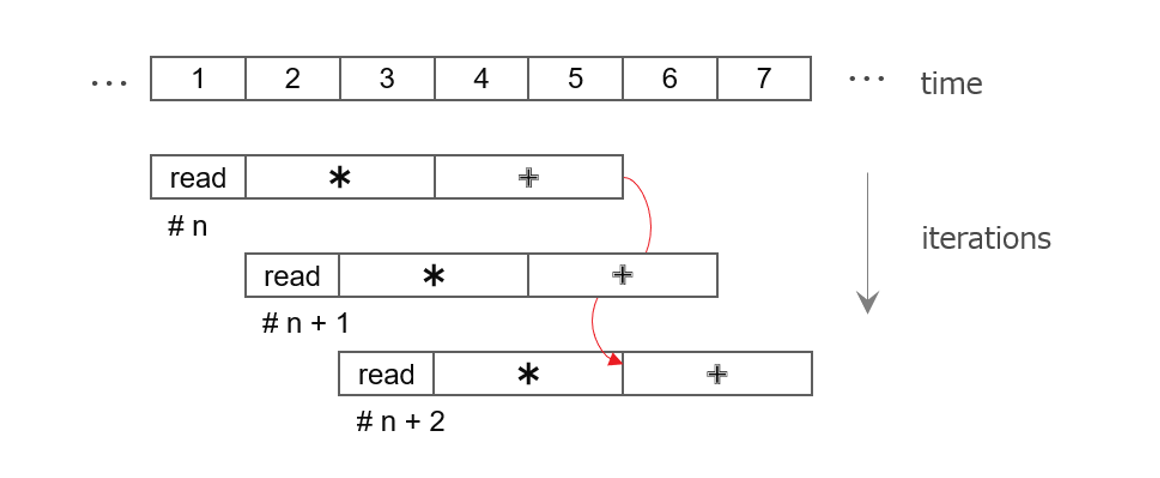
HLS-C 記述の観点では、ループネストの中に出入りする本流のデータ列に対する毎回の演算処理 (“イタレーション”、と呼びましょう) が、内容的には次のようにパイプラインで進んでいくイメージです。
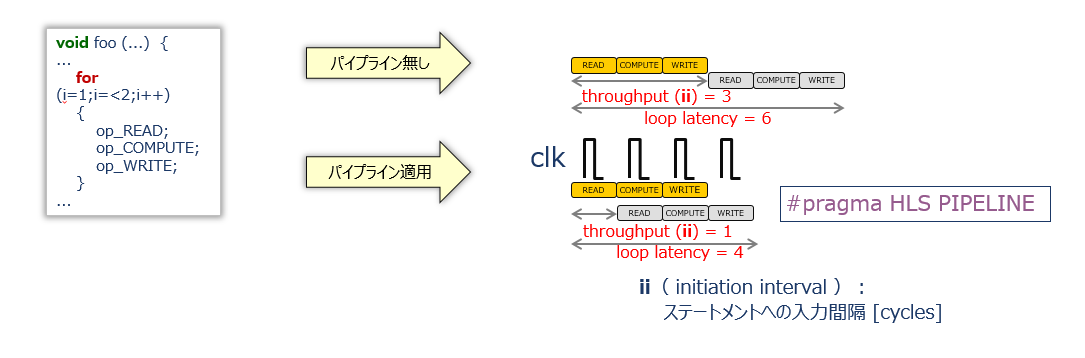
毎回のイタレーションをクロックサイクル毎に起動できる状況という風な解釈ができます。イタレーションが毎サイクル起動できる状況を、ii=1 (Initiation Interval が1という意味で、”アイアイ イコール イチ”) と呼びます。
頭の中で、HLS-C の解釈と、実際のアーキテクチャを対応付けられるようになると完璧です。
HLC-C 上で本流を土管にするためには、ループネストの中で本流データに対する処理のイタレーションのあるスコープの直下に、次のプラグマ文を挿入します。
#pragma HLS PIPELINE上のスライドの例の HLS-C の例では、ループネストの中でサブ関数の配列/ポインタの引数からデータを読んで、何か処理をして、結果をまた引数に返す、という一連の処理を各1サイクルずつで行えているイメージです。
仮に、その本流のイタレーションにおける処理の内容が単発の演算ではなく、そこからデータパスが支流に分岐して、その先の子ループでデータをバッファリングしながら複数の演算が入れ子になって行われる処理が存在する場合はどうしましょう?
アーキテクチャとしては本流を土管 (ii=1) にしなければならない訳ですから、本流から分かれる支流の処理は、全体が一つのパイプライン演算器になるよう回路リソースを使って並列化 (複製) を目指します。そのためには、その支流のループネスト上に次のプラグマを挿入します。
#pragma HLS UNROLL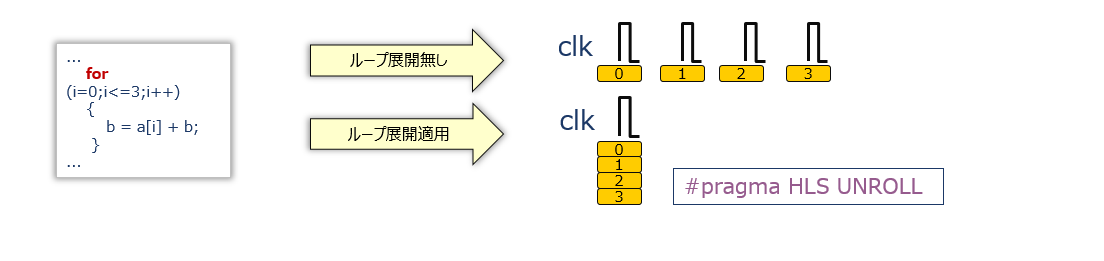
PIPELINE と UNROLL のプラグマはそれらの違いも含め、けっこう適当に理解されがちなのですが、大事なのでここで強調すると、基本的な目的はそれぞれ以下の通りです。
- PIPELINE は、本流データパスを土管にするため
- UNROLL は、本流を土管にするために支流を並列化してパイプライン演算器にするため
実は、PIPELINE 対象のループの中に入れ子のループがある場合には、その入れ子ループに対して明示的に UNROLL を指定しなくても、暗黙的に並列化されます。なぜなら、そうしないと土管が実現しないからです。
支流のループでローカルの配列にバッファリングしながら処理を行っているような場合は、ループ (演算処理) の並列化だけでなく、そこでアクセスされるローカルの配列も、演算の並列化に合わせて分解することで、演算とメモリアクセスの並列度をマッチングさせないと、パイプライン演算器が実現できず、本流を土管に出来なくなります。
筆者の拙い文章力だと段々と説明し辛い内容になってきましたが、読者の皆さんが付いてきて下さっていればと願っています。
HLS-C 記述でサブ関数 (アクセラレータ) 内でローカルに定義した配列は、対応する回路としては、レジスタ (FF) か BRAM になります。特にマイクロアーキの指定 (プラグマ文) がなければ、32以上のサイズの配列からは BRAM が推定されます。
BRAM は RAM であり、Read/Write のポートは多くても Dual までです。支流のループ (演算処理) を回路として並列化しても、それらの演算がアクセスするはずのメモリも物理的に分割をしてポート数を十分増やさなければ、本流上でパイプライン演算器、つまり、土管は実現できないことになります。
ローカルの配列から回路として何を推定し、どう分割するかは、その配列に対してプラグマを当てることで、そのマイクロアーキを確定させます。以下のスライドがその様子を示しています。
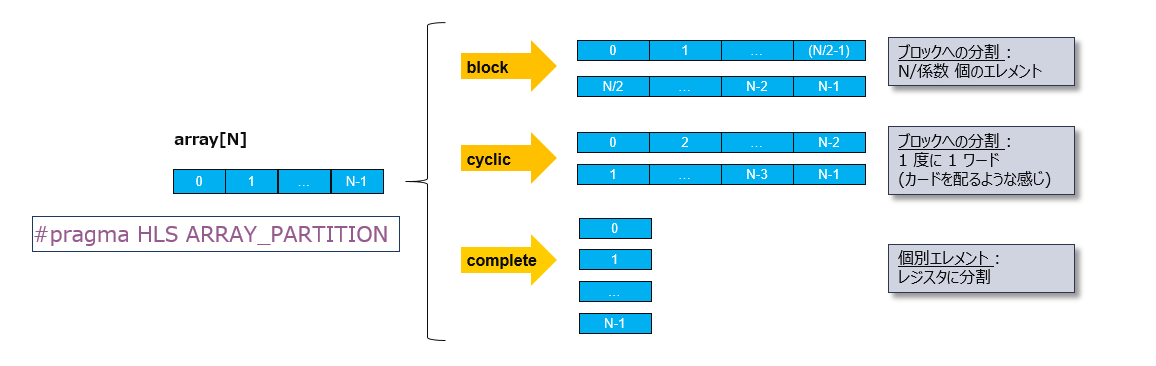
FPGA で構成できるアクセラレータの常識としては、並列化したい支流の処理の回数 (ループサイズ) はあまり大き過ぎない範囲にあるとすれば、並列アクセスしたい配列は回路としてはレジスタを推定するよう指定して、全ての要素を本流の1サイクルで並列参照できるようにします。
ここまでが、タスク内で実現したいアーキの目標 (本流を土管にする) に向けた基本の話です。
本流データパスのループに PIPELINE を当てるだけで済むなら簡単でいいですが、それで済まないアルゴリズムもいろいろあって、最悪は回路化に適さないという場合もあります。
土管の実現を阻む問題になるのは、本流のデータ列に対する処理のイタレーションの間に依存性が存在する場合です。
次のような浮動小数点の積のアキュムレータのループ処理に本流からデータ列を流し込むとして、そのループに PIPELINE を適用することで土管 (ii=1) を実現できるでしょうか?
float accum_ref(float *a, float *b) {
float accum = 0;
for(int i=0; i<FRM_SIZE; i++) {
#pragma HLS PIPELINE
accum += a[i] * b[i];
}
return accum;
}以下の図は、HLS-C 記述の観点で見たイタレーションの様子を以下は示していますが、そのままでは土管を実現することはできず、2サイクル毎にしか本流データを受け付けられません。
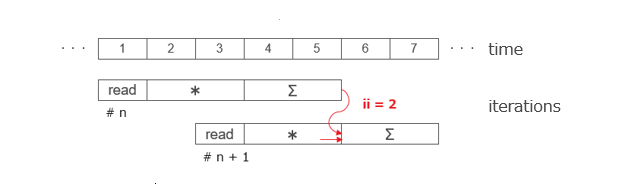
アキュムレータが同じ一つの変数を使ってイタレーション毎に足し込んでいくため、その変数を介してイタレーションの間に依存関係が存在します。ここでの問題は、イタレーションの最後の演算、つまり足し込みに2サイクル掛かっていることであり、その間次のイタレーションの足し込みのために今のアキュムレータの値を読み出せないという状況です。
この問題の対策としては、2つあります。
一つは、回路として浮動小数点はやめて、以下のように固定小数点化することです。固定小数の足し込みが1サイクルで済むので、イタレーションの最後が1サイクルとなって、ii=1の土管が実現できます。
float accum_hls(float a[FRM_SIZE], float b[FRM_SIZE])
{
float accum;
ap_fixed<24,12,AP_RND> accum_tmp = 0;
for(int i=0; i<FRM_SIZE; i++) {
#pragma HLS PIPELINE
mult_tmp = a[i] * b[i];
accum_tmp += mult_tmp;
}
accum = accum_tmp;
return accum;
}固定小数点化で土管は実現できますが、ペナルティとしては、レファレンスのアルゴが浮動小数点に対して回路が固定小数点での処理になり、精度検証が追加で必要になることです。また、どの変数をどの精度で固定小数化するか、という別の課題への取り組みが必要になります。
Vivado HLS には任意のビット精度や丸め方を指定できるデータ型を用意しています。
もう一つの対策方法としては、データ型は浮動小数点のままで、実現できる方式になります。
それは、毎サイクルの足し込みを同じ一つの変数 (レジスタ) に対して行うのではなく複数の変数、つまり配列に対して行うことで依存性を回避するというものです。
#define ORIG_II 2
float accum_hls(float a[FRM_SIZE], float b[FRM_SIZE])
{
float accum_tmp[ORIG_II];
for(int i=0; i<ORIG_II; i++) {
#pragma HLS UNROLL
accum_tmp[i] = 0.0f;
}
int j = 0;
for(int i=0; i<FRM_SIZE; i++) {
#pragma HLS PIPELINE
j = i % ORIG_II;
accum_tmp[j] += a[i] * b[i];
}
float accum = 0.0f;
for(int i=0; i<ORIG_II; i++) {
#pragma HLS UNROLL
accum += accum_tmp[i];
}
return accum;
}配列の各要素に積和をスキャンしながら格納していけるよう、一次足し込みのイタレーションから、最後に途中経過の Σ のために追加したループの UNROLL によって、以下のような回路をイメージして HLS-C で表現します。
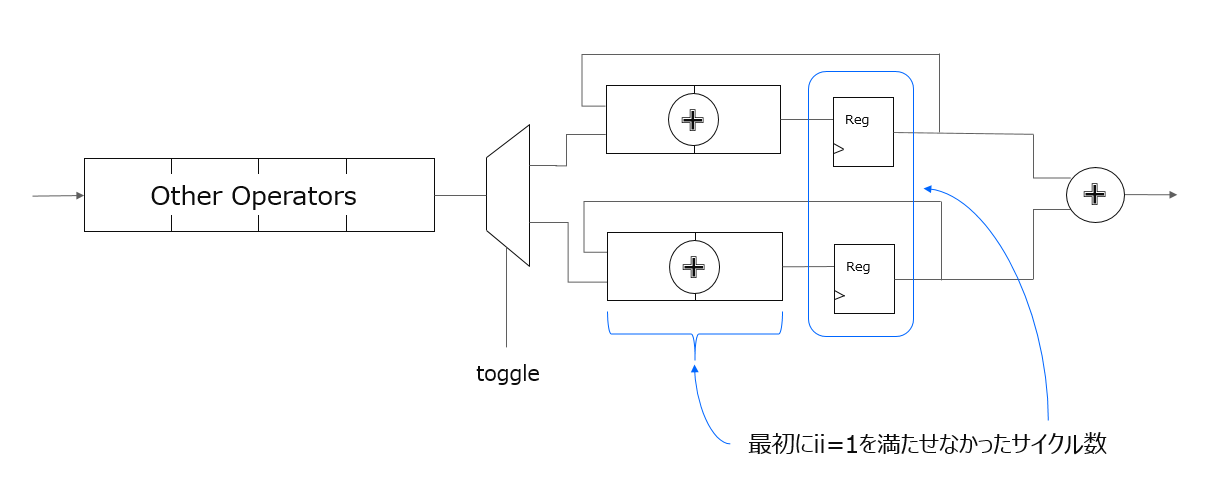
足し込みの格納先の変数を一つにしていた時に HLS がレポートした ii の数だけ、足し込みのパスを複製する形になります。
HLS-C 記述の観点で見たイタレーションの様子を以下に示します。今のイタレーションの積和に一つ飛ばした次のイタレーションの積を足し込むことで依存性を回避でき、ii=1 を実現できるようになります。
この方式のアーキを選ぶペナルティとして、以下の2点への考慮が必要です。
- 途中経過の足し込みのために余計にイタレーションが必要になりますが、それが元々のメインの積和計算のイタレーションのサイズに対して相対的に小さければ OK との判断です。
- float の積和の順番が変わってくるので、最初の方式に対して計算誤差が発生します。テストベンチの中で、レファレンスモデルによる期待値 vs. HLS-C 結果 の比較ルーチンにおいては、完全一致ではなく ε 未満かどうかの判断にしています。
本流データパスを土管にするための基本の鉄則4) を踏まえ、次の鉄則を満たすアーキを考えます。
鉄則5) 元の外部ポインタへの (局所的) ランダム&冗長アクセスは、FPGA にキャッシュして行え
これまでと状況が違うのは、一つの計算を行うために複数の入力データが必要になるとして、そのために引数ポインタに対するアクセスパターンがランダムになる場合への対応です。
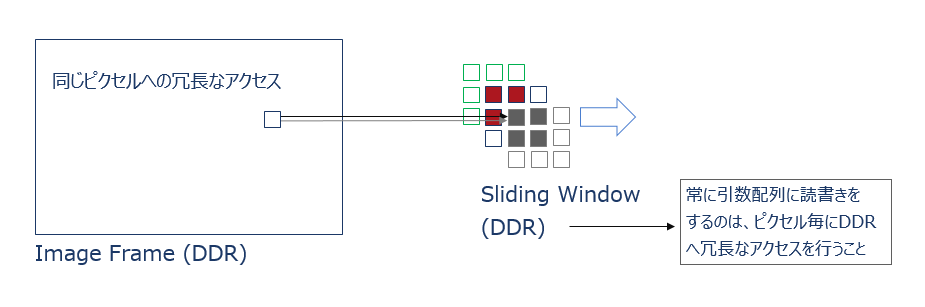
言葉だけだと分かり辛いので例を挙げると、数値計算の分野でいう2次元ステンシル計算、あるいは画像処理の分野で2次元フィルタ計算が同類ですが、ここでは後者を取り上げて見てみます。
以下は3×3の2次元フィルターを図示したもので、一回のフィルター計算には自身を含めた近傍の3×3のデータが必要ですが、その3×3のフィルター計算をフレーム全体に亘って行います。
それと対応するレファレンスのコードの例も併せて以下に示します。
最奥の二重ループで3×3のフィルタ計算を行い、最外の二重ループのインデックスを基準に計算結果を本流データとしてシーケンシャルにスライドさせながら出力しています。
入力データは3×3の計算の度に最奥の二重ループの中から入力ポインタに対して9回アクセスします。アクセスする3×3のウィンドウが出力ピクセル毎にスライドしていくので、入力ポインタに対するアクセスが局所的にランダムでかつ冗長になるのが分かります。
void gaussian_ref(unsigned char src[WIDTH*HEIGHT], unsigned char dst[WIDTH*HEIGHT]) {
const unsigned char coef[3][3] = {
1, 2, 1,
2, 4, 2,
1, 2, 1
};
for(int y=0;y<HEIGHT;y++) {
for(int x=0;x<WIDTH;x++) {
int sum = 0;
for(int yy=-1;yy<=1;yy++) {
for(int xx=-1;xx<=1;xx++) {
int tmp_x = x + xx;
int tmp_y = y + yy;
int col = (tmp_x<0)?0:((tmp_x>=WIDTH)?(WIDTH-1):tmp_x);
int row = (tmp_y<0)?0:((tmp_y>=HEIGHT)?(HEIGHT-1):tmp_y);
sum += src[row*WIDTH + col] * coef[yy+1][xx+1];
}
}
dst[y*WIDTH + x] = (unsigned char)(sum >> 4); // sum * 1/16
}
}
}このコードはあくまでアルゴリズムを理解するための機能レファレンスモデルであって、そのまま HLS-C として扱う訳にはいきません。引数ポインタを DRAM に見立てると、それに対して上述したような冗長なランダムアクセスを行う時点でアクセラレータとしてはアウトです。
アクセラレータとしては、鉄則4) 5) に従い、以下の図に示すようなアーキテクチャを持つ必要があります。
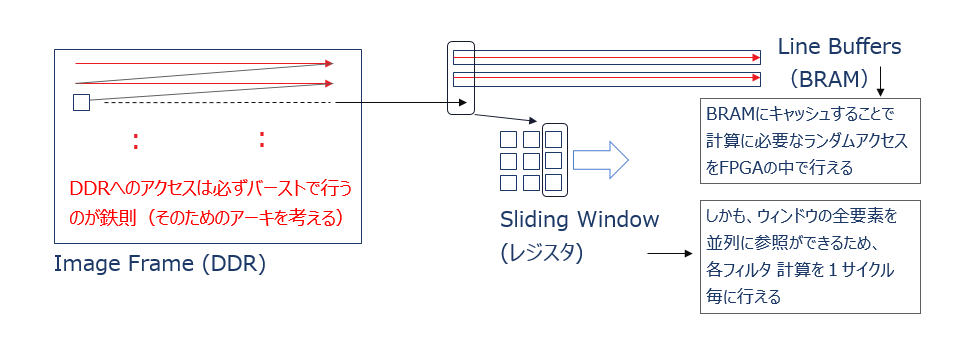
計算に必要なフレームデータに対する冗長なランダムアクセスは FPGA 内に引き込んで、BRAM やレジスタにキャッシュした上で行うようにする、という方式です。
本流データパスを土管にして DRAM アクセスと同じバンド幅を実現するには、その支流に当たる3×3フィルタ計算のルーチンは、1サイクルのスループットで結果を出力できるよう並列化し、パイプライン演算器として構成する必要があります。
その一つのフィルタ計算に必要な3×3のデータ入手のためのランダムアクセスは、ラインバッファ (主に BRAM) とウィンドウ (主にレジスタ) という回路部品を用意し、それらに対して行います。
そのアーキを記述した HLS-C のコード (抜粋) を例題として以下に掲載します。ここからはコードを参照しながら説明を進めていきます。
フィルタ係数代入やフレームの境界処理などの枝葉の部分は、すでに上に掲載しているレファレンスコードのほうで意味的な内容は参照できるので、HLS-C の例では省略し、主な動作だけをハイライトする形の抜粋になります。説明のほうも同様に枝葉は省略します。
例題の中ではラインバッファとウィンドウ部品として以下の HLS コードライブラリを利用します。以下の日本語版の UG902 に説明があるので (2章「高位合成の C ライブラリ」→「HLS ビデオライブラリ」)、必要に応じて参考にしてください。
hls::LineBuffer<2,WIDTH,unsigned char>
hls::Window<3,3,unsigned char>実は、それらはすでに Vitis ライブラリのほうに移行してしまっているのですが、内容的には同じですし、本質の説明のためだけであれば日本語の UG も残っているほうが補足としても都合が良いと思い、利用する次第です。

void gaussian_hls(hls::stream<unsigned char> &src, hls::stream<unsigned char> &dst) {
const unsigned char coef[3][3] = {
1, 2, 1,
2, 4, 2,
1, 2, 1
};
hls::LineBuffer<2,WIDTH,unsigned char> line_buffs; // 2 line buffers (BRAM)
hls::Window<3,3,unsigned char> window; // sliding 3x3 window buffer (Reg)
unsigned char col_buff[3]; // column buffer (Wire) to insert to window
unsigned char lbd_buff[3]; // column buffer (Reg) for the left boarder
unsigned char rbd_buff[3]; // column buffer (Reg) for the right boarder
for(int y=0;y<(HEIGHT+1);y++) {
for(int x=0;x<(WIDTH+1);x++) {
#pragma HLS PIPELINE
unsigned char tmp_0, tmp_1, pix_in;
if(x<WIDTH) {
tmp_0 = line_buffs.getval(0,x);
tmp_1 = line_buffs.getval(1,x);
}
if(y<HEIGHT && x<WIDTH) {
pix_in = src.read();
line_buffs.shift_pixels_up(x);
line_buffs.insert_bottom_row(pix_in,x);
}
if(y==1) {
col_buff[0] = tmp_1;
col_buff[1] = tmp_1;
col_buff[2] = pix_in;
}
else if(y==HEIGHT) {
col_buff[0] = tmp_0;
col_buff[1] = tmp_1;
col_buff[2] = tmp_1;
}
else {
col_buff[0] = tmp_0;
col_buff[1] = tmp_1;
col_buff[2] = pix_in;
}
if(x==0) {
lbd_buff[0] = col_buff[0];
lbd_buff[1] = col_buff[1];
lbd_buff[2] = col_buff[2];
}
if(x==WIDTH-1) {
rbd_buff[0] = col_buff[0];
rbd_buff[1] = col_buff[1];
rbd_buff[2] = col_buff[2];
}
window.shift_pixels_left();
if(x==1) {
window.insert_right_col(col_buff);
window.insert_left_col(lbd_buff);
}
else if(x==WIDTH) {
window.insert_right_col(rbd_buff);
}
else {
window.insert_right_col(col_buff);
}
if(y>=1 && x>=1) {
int sum = 0;
for(int m = 0; m < 3; m++) {
for(int n = 0; n < 3; n++) {
sum += window.getval(m,n) * coef[m][n];
}
}
unsigned char pix_out = (unsigned char)(sum >> 4); // sum * 1/16
dst.write(pix_out);
}
}
}
return;
}[1行]
この例では、カーネル引数はメモリ・アクセス想定の配列ではなく、ストリーム FIFO を実装するために hls::stream<data type> を用いています。
hls::stream<data type> や FIFOについては次節で解説します。
外部メモリ (DRAM) への直接のアクセスは前段のモジュールで行っている想定です。例えば、フィルタ処理の対象が DRAM に格納したフレーム全体ではなく一部になるようなケースでは、その部分フレームを切り出すためのメモリ・アクセスを行い、データをストリームとしてフィルタに流します。
部分フレームを切り出すための DRAMへのアクセスでは、ライン毎に改行 (ストライド・アクセス) が発生するため、その分だけメモリ・アクセス効率が落ちます。シーケンシャル・アクセスできるサイズが大きいに越したことはありません。
[9~10行]
3×3フィルタ計算のために2ライン分を先読みして格納しておくためのラインバッファと、フィルタ計算で直接参照する9個のピクセルデータを格納しておくためのウィンドウレジスタとして、先述のコード・ライブラリを利用します。
[12行]
ウィンドウレジスタに対しては、サイクル毎に旧3×3データを1ピクセル分だけ左にずらす水平シフトと、3×1カラム (一列) 分の新規データを右から挿入する処理を繰り返すことで、3×3データの更新 (スライディング) 動作を実現しますが、その3×1カラムの新規データの一時格納先として、ここで宣言した配列を用います。
3つの要素のうち上から2つにはラインバッファ2行に先読みして格納している上下2つのデータを、残りの1つには今ストリームから読んだデータを代入します。回路としてはワイヤとして束ねるだけの内容です。
[13~14行]
フレーム左右の境界に対するフィルター処理はミラーリング (フレーム外には境界と同じ内容のデータがあるという想定で処理する) としています。そのフレーム外の左右それぞれの余白に相当する3×1カラム・データを別に準備しておくための配列です。
[16~18行]
フレーム・データの入出力とフィルタ処理のシーケンスを制御する2重ループと、そのスコープに属する処理/イタレーションを回路としてパイプライン化するための PIPELINE プラグマになりますが、ここでは特に、ループ・サイズについて触れておきます。
実際のフレーム・サイズよりも行と列それぞれで1つだけループ・サイズのカウントが多く設定されています。これは、フレーム外の余白まで考慮したフィルタ処理の場合、最初の3×3フィルタ計算を行うまでに1ラインと1ピクセル分のデータをラインバッファに先読みする必要がある、別の言い方をすると、最初の3×3フィルタ計算結果を出力できるタイミングがその分だけ遅れる状況にある、という背景からです。
フレームの入出力と処理全体のシーケンスの制御を一つのループ・ネストで記述するために、入力フレームに対して1行と1ピクセル分だけ位相が遅れて始まるフィルタ後の出力フレームも併せた形の、いわば水平・垂直方向に1ピクセルずつサイズの大きな拡張フレームをイメージしています。
[20行]
それぞれ、ラインバッファ (上下2ライン) と入力から読み出す同じデータを、あちこちで繰り返し参照するために用います。
ラインバッファは BRAM で構成され、メモリ・インタフェースを持ちます。入力はストリームなので FIFO インタフェースになります。ソフトウェアの世界では、同じインデックスの配列をあちこちで繰り返し参照するような記述は普通に見られますが、HLS-C でサイズの大きな配列を参照する記述は、BRAM に対して物理的にアクセスを起こすことを意味しています。同様にストリームを参照する記述は、FIFO に対する物理的なアクセスを意味しています。
ラインバッファや入力ストリームへの直接の参照をは一度で済ませ、一時変数に格納してそれを方々で使い回す記述スタイルを採用するのはそのような背景からです。この例の一時変数は、ハードウェアとしてはワイヤになります。
ハードウェアとしてのパイプライン動作のために、ラインバッファに対する読み出しと書き込みの同時アクセスをデュアルポートの BRAM を使って実現しますが、デュアルなので、リードとライトでそれぞれ一つずつしかポートは存在しません。FIFO については、参照のための1回のアクセスで FIFO の中からデータを1つ取り出す、つまり一度読み出したデータはもう FIFO には存在しません。次に同じ FIFO にアクセスすると、その次のデータを読み出すことになります。
同じイタレーションの中で、BRAM や FIFO に対するアクセスはパイプラインを実現するために本質的に必要最低限の回数しか行わないよう、ハードウェア動作を意識して設計/記述する必要があります。
[22~25行]
入力フレーム幅のインデックス期間中は、イタレーション毎に指定したインデックスにおいてラインバッファの上下2つのデータを読み出し続けます。読み出しの記述にはライブラリで定義されているメソッドを利用します。ハードウェアとしては BRAM に対するリードになります。
[27~31行]
入力フレームを読み込むインデックス期間中は、イタレーション毎にまず、入力のストリームからフレーム・データを読み出します。読み出したデータは、ラインバッファのその時のインデックスにて下から挿入という形で新規書き込みをします。挿入の前に場所を空ける必要があるので、そのインデックスにある上下2つの参照済みデータを事前に上にシフトしておきます。それで上のラインにあるデータを廃棄することになります。それらの記述にはライブラリで定義されているメソッドを利用しています。
[33~47行]
3×3ウィンドウのデータをカラム単位で更新するための3×1データを、インデックスの状況に分けて準備します。
フレーム上下の境界以外 (else) の通常モードのインデックス期間では、ラインバッファの上下2つのデータが3×1の上2つに、ストリームからのデータが残りの1つになります。出力フレームの上端 (y==1) では、3×1の一番上は余白分であり、ミラーリングを踏まえ境界のピクセルの重複になります。出力フレームの下端 (y==WIDTH) では、3×1の上2つはラインバッファの上下2つになりますが、残りの1つは余白分であり、同様に境界のピクセルの重複になります。
[49~53行]
フレーム左端の余白について、ミラーリングを踏まえ3×1カラムのデータを用意しています。
[55~59行]
フレーム右端の余白についても同様に、3×1カラムのデータを用意しています。
[61行]
全てのインデックス期間において、イタレーション毎に3×3ウィンドウ・データを左に1ピクセルずつシフトすることで、左から古い順に3×1カラム分を廃棄します。シフトの記述にはライブラリで定義されているメソッドを利用します。
これを繰り返すことで、フィルタ計算のために参照する3×3ウィンドウを右方向にスライドする動作を表現しています。最初の3×3フィルタ計算ができるまでの間は、挿入されるデータには内容がありません (不定データ)。
[63~72行]
3×3ウィンドウ・データの左シフト後に3×1データを挿入しますが、出力フレームの左右境界ではミラーリングを踏まえたウィンドウ・データを準備するために、インデックス期間を3つに場合分けして挿入を行います。挿入の記述にはライブラリで定義されているメソッドを利用します。
出力フレームの左右境界以外 (else) の期間では、3×3ウィンドウの右端に通常の3×1カラム・データを挿入します。出力フレームの右端 (x==WIDTH) では、3×3ウィンドウ右端は余白分になるので、ミラーリングを踏まえ事前に準備しておいた3×1カラム・データを挿入します。出力フレームの左端 (x==1) では、3×3ウィンドウの右端には通常の3×1カラム・データを挿入しまが、左端は余白分になるので、ミラーリングを踏まえ事前に準備しておいた3×1カラム・データを左端に挿入します。
[74~85行]
3×3ウィンドウ・データに対するフィルタ計算とその出力動作の記述になります。
インデックス期間は出力フレームのフェーズです。つまり、16~18行目の説明で述べた理由により、最初のフィルタ計算結果の出力が始まるのがインデックス座標 (1,1) からとなります。
入出力フレームに対する処理全体をパイプライン化 (ii=1) するために最外の2重ループに PIPILINE プラグマを当てていました。この3×3フィルタ計算については、9回の積和が同時に行われるようハードウェアとしては9並列に (UNROLL) する必要がありますが、ループ・ネストに UNROLL プラグマを明示的に記述しなくても暗黙的に適用されます。そうしないと全体のパイプライン化が実現できないことが分かっているからです。
フィルタ計算のための3×3ウィンドウ・データの読み出しと、ストリームへの計算結果の書き込みの記述には、ライブラリで定義されているメソッドを利用します。
タスク “間” の並列性と課題
売り物になるようなカーネルであれば、処理の内容がタスク一つだけで終わりということはないと思います。ということで、最後の鉄則の話になります。
鉄則6) カーネル内のアルゴリズムが複雑な場合には、タスク分割した上で階層設計を検討せよ
レファレンスのアルゴを解析して得られた全てのタスクで土管が実現するとは限りません。土管が実現できないタスクについてはハードウェア化の対象から外すしかないと思います。
アクセラレーションを割り付ける対象としてヘテロ構成を考える場合は、FPGA には合わないと判明したタスクについては別の Compute リソースへの割り付けを検討することになると思います。
ここでは説明の簡単の為、仮に、アクセラレーション対象として切り出した手元のアルゴを構成するタスク全てについて、土管が実現することが分かったとして、次に検討すべきは、互いに依存関係にある タスク (土管) 同士を繋ぐことです。
タスク間をつなぐパスのことを “チャネル” と呼ぶことにします (以下スライド)。
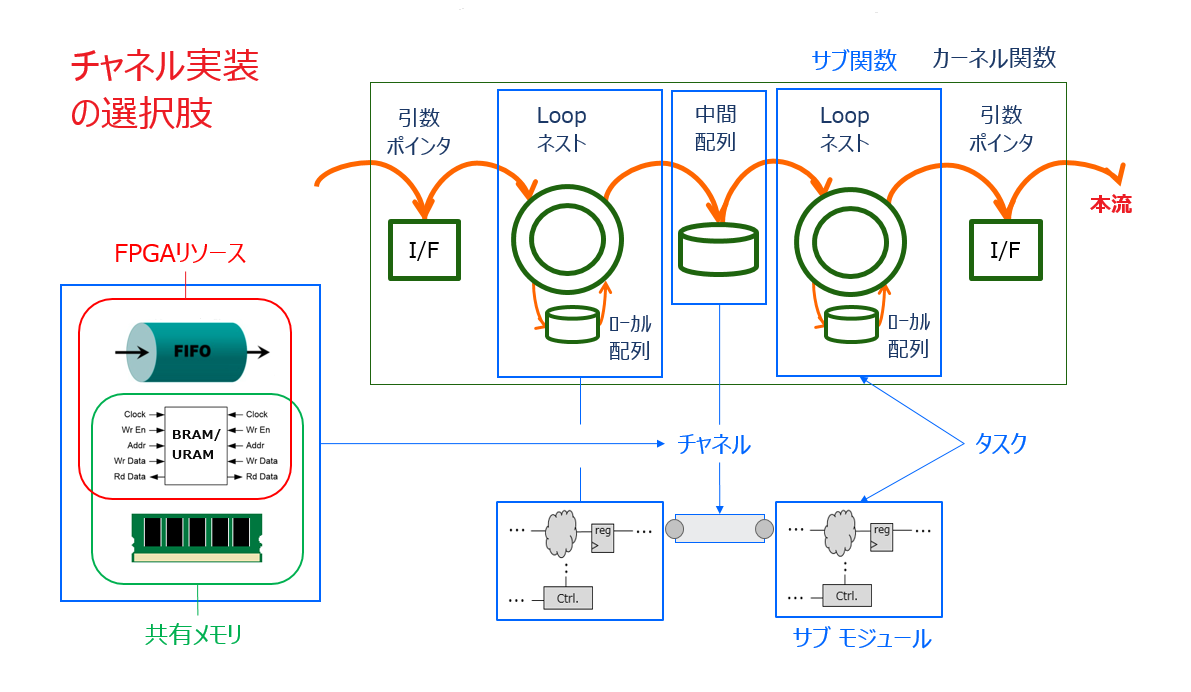
チャネルを HLS-C 以前の中間 C/C++ モデルの観点で捉えると、サブ関数の間をつなぐ中間配列になります。
回路としてみると、チャネルはサブモジュール間を渡すパスになりますが、その実装には3種類あります。
- FIFO/ストリーム
- 共有メモリ (FPGA 内部:BRAM/URAM)
- 共有メモリ (FPGA 外部:DRAM)
タスク間の並列性という観点で分類すると、1は並列、2と3は逐次になります。
チャネル1) で繋がるタスク間の並列性を “タスク並列”、その構成を “データフロー” と呼びます。
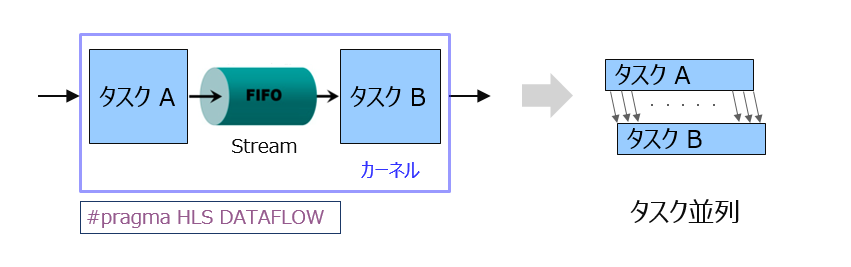
中間配列へのアクセスパタンが両タスクともシーケンシャルだった場合に実装可能なチャネルです。
回路部品としては FIFO で繋ぐことで、前段のタスク内で各イタレーションの処理が済む度に、その結果のデータが順番に次々と FIFO を通って後段のタスクに流れていきます。
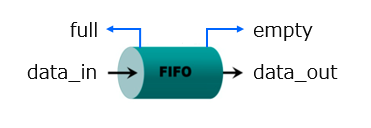
タスクは回路としてはサブモジュールであり、アクセラレータとして FSM (ステートマシン) を中に持って自律的に動作してますが、データの出し入れの判断は、FIFO のステータスを full/empty フラグを見て行っています。
前段のタスクは FIFO に空きがあるかどうかを full フラグを見て判断し、空きがあれば (NOT full であれば) full になるまで流し込みます (自分に流し込むデータがある限り)。後段のタスクは FIFO にデータがあるかどうかを empty フラグを見て判断し、空でなければ (NOT empty であれば) empty になるまで読出し続けます (自分が受け入れ可能である限り)。
チャネル2) は共有メモリですが、それが FPGA 内で実装されている場合です。
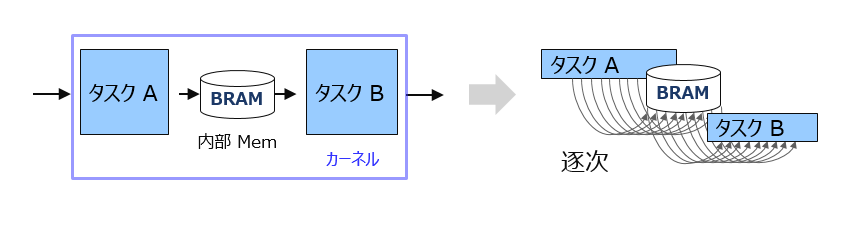
共有メモリなので、タスク間の並列性は、というか並列ではなく当然、逐次の関係になります。
タスク間のパス上にある共有メモリなので、サイズの大きなデータであることが前提だとすると、FPGA リソースとしては BRAM or URAM で実装されることになります。
FPGA 内で本流の土管として共有メモリであるのは、アクセスパタンがランダムだからだと思います。ランダムアクセスでも BRAM/URAM なので、外部 Mem (DRAM) とは違い、土管としてアクセスできます。
アクセスパタンがシーケンシャルだとただのバッファ (段数を持たせた FIFO) です。
チャネル3) は FPGA 外部の共有メモリです。
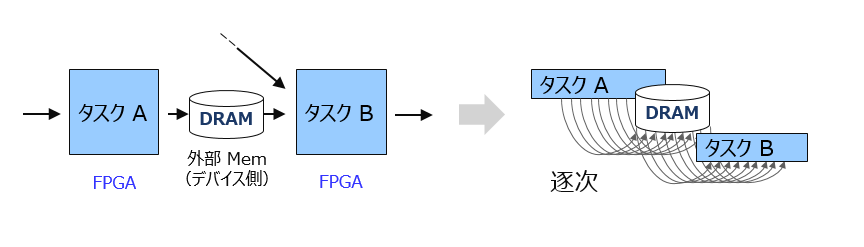
DRAM である理由は何でしょうか?カーネルを出入りするのでアクセスパタンはシーケンシャルのバースト転送は前提です。アクセスパタンがシーケンシャルなのに FIFO でない理由として考えられるのは、後段のタスクには前段のタスクだけではなく上図には現れていない別なタスクもあって、そこからのデータも後段にマージしてくるような構成になっていて、その別のタスクのプロセスが終わるのを待つまでどこかにデータをバッファリングしておきたいというシチュエーションが一つあるかと思います。ある意味、バッファ用の FIFO が外部にあるようなイメージでしょうか。
BRAM/URAM で足りるのであれば FPGA 内にバッファリングでもいいかも知れないですが、データサイズは大きい想定なのでそれだけだと勿体ないかも知れません。
ちなみに、DRAM が共有メモリの場合とした上の図の中で、タスクの割り付け先は FPGA としていますが、カーネルの階層を示していまんが、それらのタスクが同じカーネル内にある場合もあれば、別のカーネルかも知れない、という含みです。
また、この場合のタスクがカーネルのだと、ホスト側からソフトウェア/タスクパイプラインという形でスループットを上げられる可能性があるかも知れませんが、上の図では示していません。
タスク並列を実現するデータフローの記述について、少し触れておきます。ここでは主なポイントと、いくつか注意事項だけに留めます。詳しく知りたい方は UG902を参照してください。
void func_hls(int a[FRM_SIZE], int b[FRM_SIZE], \
int c[FRM_SIZE], int coef)
{
#pragma HLS DATAFLOW
hls::stream<int> a_strm;
hls::stream<int> b_strm;
hls::stream<int> c_strm;
int coef_tmp = coef;
array2stream(a, b, a_strm, b_strm);
task_core(a_strm, b_strm, c_strm, coef_tmp);
stream2array(c_strm, c);
return;
}これは、3つのタスク (サブモジュール) を含むカーネル TOP 関数の記述です。
サブモジュールを表すサブ関数をインスタンスし、それらの間を渡す FIFO として hls::stream<> を TOP 下で宣言して接続しています。
このスコープ内にプラグマ文、#pragma HLS DATAFLOW を入れることで、3つのデータフローのタスクがアクセラレータとして同時に起動するような制御が生成されます。
このプラグマを入れないと、データフロータスクであっても、回路としては逐次に起動される制御になってしまいます。
void task_core(hls::stream<int> &a_strm, hls::stream<int> &b_strm, \
hls::stream<int> &c_strm, int &coef)
{
int a_tmp, b_tmp, c_tmp;
for(int i = 0; i < FRM_SIZE; i++) {
#pragma HLS PIPELINE
a_tmp = a_strm.read();
b_tmp = b_strm.read();
c_tmp = (a_tmp + b_tmp) * coef;
c_strm.write(c_tmp);
}
return;
}このコードは上述の3つのデータフロータスクのうち、真中のものを示しています。
いくつか注意事項を挙げておきたいと思います。
・ 宣言した hls::stream<> 変数 (実体) はこのサブ関数の外にありますので、引数は参照です。
・ hls::stream<> 変数からの/への代入は回路としての FIFO へのアクセスを意味していますので、本当に必要なときのみ行います (フレームデータが FIFO の中にシーケンシャルに流れ込んでいるイメージを持ってください)。同じデータを複数の箇所でかつ何度も参照したい場合には、一度 temp 変数に代入した上でそれを使い回します。
・ 同じ stream データを分岐して出力したいときは、それぞれに別々の hls::stream<> 引数を持たせます (FIFO チャネルは p2p 接続が原則)。
・ 毎回のカーネル実行終了時には必ず FIFO の内容が空になっていること、つまり、ストリームとして入力するフレームデータはかならず FIFO から消費し切るようなデザインにしてください。もし FIFO にデータを残したまま終了すると、FIFO の full/empty を生成するための Read/Write ポインタのカウンターがリセットされないため、カーネル実行を繰り返しているうちに動作がスタックような回路になってしまいます。
注意事項の他に、データフローで起こる問題の典型例であるデッドロックについて、少し詳しく解説をします。
以下のようなグラフ構成のデータフローを含むカーネルがあったとします。処理の内容としては、FullHD の画像を1/2に縮小して分岐し、一方はフィードスルー、もう一方は何か2D フィルター処理のパスに分かれ、次の処理のために後段のタスクにマージするというものです。
最後段のタスクでは、2つの 1/2 FullHD 画像を FullHD 上の4象限のうち、図で示すような位置にそれぞれ貼り付け、残りはブランクに (白色に描画) して FullHD として出力します。
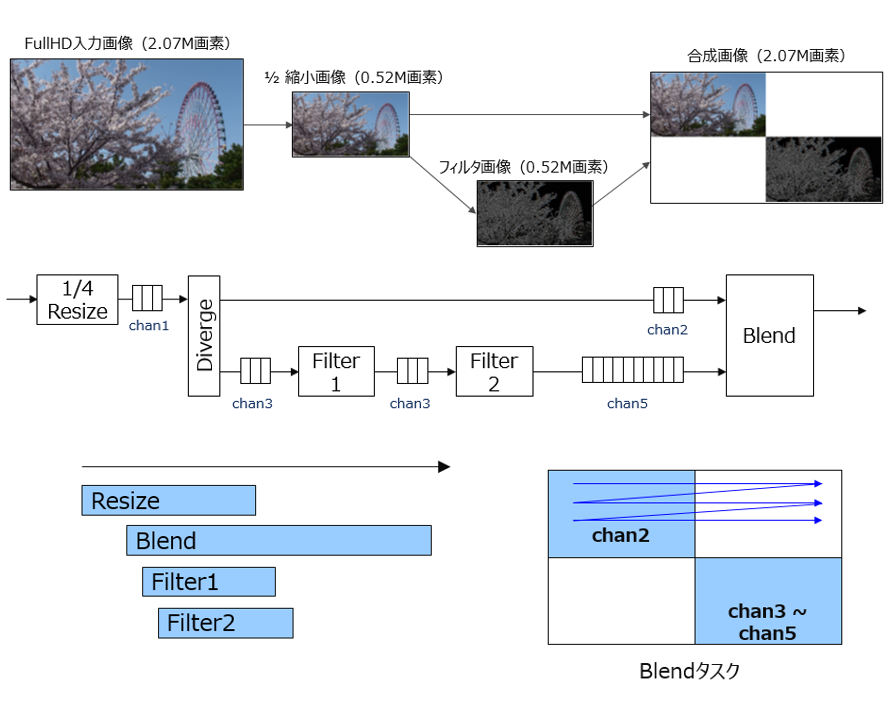
全てのタスクでデータフローを構成するので、滞りなければタイムチャートで示すようにタスク並列で動くはずですが、FIFO の段数を間違うと、全体がデッドロックして動かなくなります。どこの FIFO のことを言っているでしょうか?どこか一つの FIFO というよりは、フィルターのタスクを含むパス全体と言ったほうが正しい言い方かも知れません。
カーネルが開始 (start) すると、タスクを担う全てのサブモジュールも同時に起動します。最後段で描画をするタスク/サブモジュールは、FullHD 画像のピクセルをシーケンシャルに処理/出力しますが、図に示すような仕様であれば先に chan2、つまり1/2にリサイズ後のフィードスルー画像が到着します。もう一方のパスでは並行してフィルターの処理が進んでいますが、フィードスルー画像の描画が終わるまでは待つ必要があります。
もしフィルターのパス上にいる FIFO の段数がそれぞれ1段 (hls::stream<>のデフォルト想定) だったすると、早々に chan5の FIFO が full になり Filter2モジュールに対して「待った」を掛けます。すると、その「待った」情報が前段に伝搬していって、それでまずフィルターのパスがストールします。すると、経路が分岐する根元のタスク/モジュールにも待ったが掛かります。分岐して出力するデータの生成元は一つなので、そこに待ったが掛かることで、最終的に全体がデッドロックしてスタックしてします、という顛末です。
このデッドロック問題は、これが HLS カーネルであれば、Vivado HLS の Co-Sim を実行することで捕獲され、問題箇所も特定してくれます。
C-Sim では分かりません。ソフトウェアとしては hls::stream<> のサイズ (FIFO 段数) は無限の想定だからです。
HLS-C で表現できないケース
HLS-C で表現できない場合と、1章の1-3~1-4節でコメントしたように (HLS-C で記述出来ない訳ではないが)「C-Sim で検証できないような内容」という意味も含み、該当するケースとして大きくは3つかと思います。
- 計算アルゴリズムとは関係のない機能をカーネル内に含めたい
- 後段モジュールから前段モジュールに向かってフィードバックパスがある
- FIFO チャネルに対するノンブロッキング読み/書き
1) は明らかです。
2) は例えば、後段モジュールの処理結果のデータの内容に依存して前段モジュールの処理が変わるような内容の場合です。
3) は FIFO が empty や full であってもストールせずに処理を実行できるというものですが、外部状況に依存して動作が変わる制御回路のような内容になり、hls:stream<> のメソッドとして表現手段が存在はしますが、C-Sim で検証できる内容ではなくなるのでメリットを感じないという意味で挙げました。
カーネル機能の全てを HLS-C で記述できない場合は、HLS-C で記述出来る部分だけを部品として流用する形で、全体としては RTL カーネルとして設計するやり方が現実的な気がします。
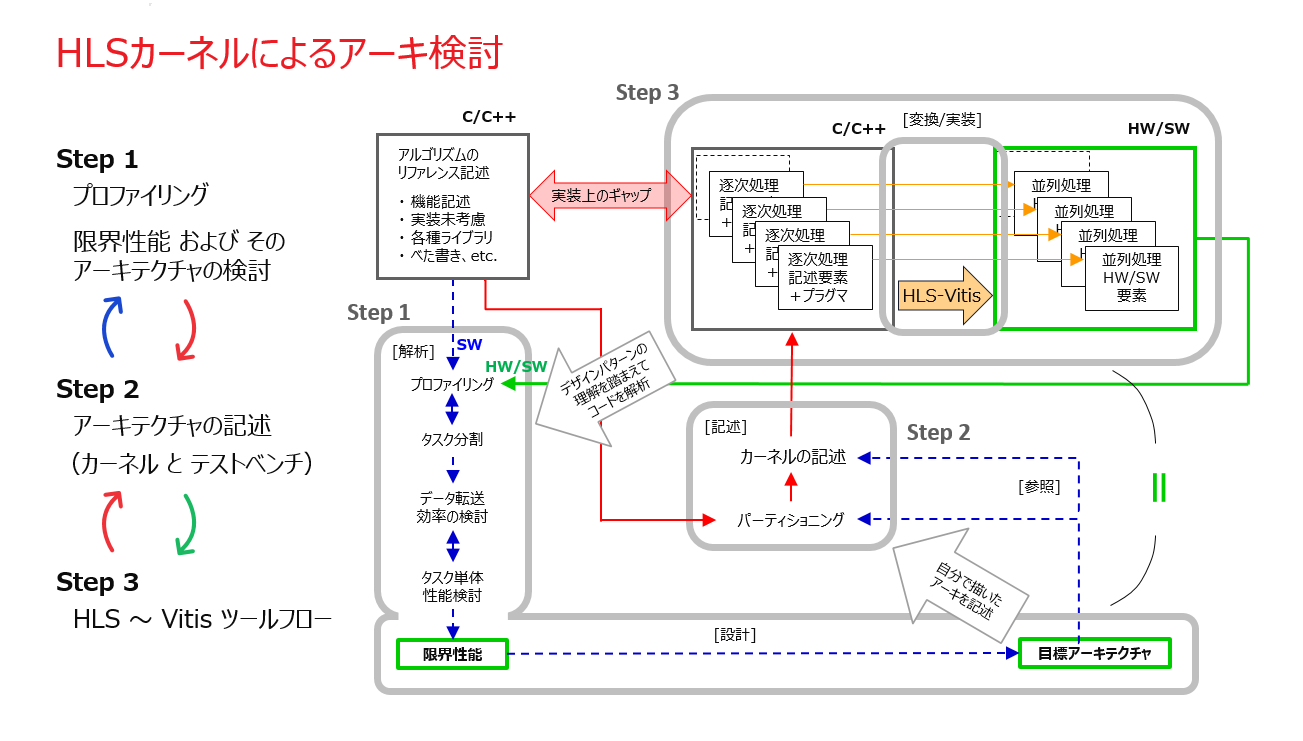
少なくともアクセラレータのデータパス系の中で HLS-C で表現できない/したくない部分に対する取扱いについては、1章の1-4節「HLS か? RTL か?という二択の話ではない」の後半で “HLS の使いこなし方 ” の問題意識として少し触れた内容に関わりますが、「アーキ検討 ⇔ アーキ記述/検証」の往還を早めるために HLS を利用する中で (上図)、HLS-C 記述が適さない部分は何かの目的を持たせた仮置きのモデルで代替しておいて、最終版に向けた情報収集の手段とする等、開発者の方々が置かれた状況に応じていろいろと対処の仕方がありそうに思います。
2-2. 実装の限界まで求められるケースも
本章では高性能化のための “アーキテクチャ” をメインテーマにこれまで話を進めてきましたが、実装品質改善の要請から、設計済みのカーネルに対する再構成が (それに伴うホストプログラム側の修正も含め) 必要になるケースもあります。
Vitis ツール (中に Vivado を含む) でインプリ (合成~配置・配線) まで実行して達成した Fmax (クロックの最大動作周波数) が “期待より低い” といった状況がその一つです。期待といっても、もちろんその内容が妥当である前提です。
例えば、Alveo の U250 を製品向けに (なかなか無さそうですが) 選んだとすると、そこに搭載されている FPGA (Alveo シリーズの中で最大のロジックリソース) のダイは1枚ではなく、以下の図に示すように同じダイが4枚の構成になります。その1枚のダイのことを SLR (Super Logic Region)、そして全体を SSI (Stacked Silicon Interconnect) デバイスと呼びます。
簡単に言えば、歩留まりを下げずに集積度を上げたいという背景から生まれたデバイス形態の一つです。
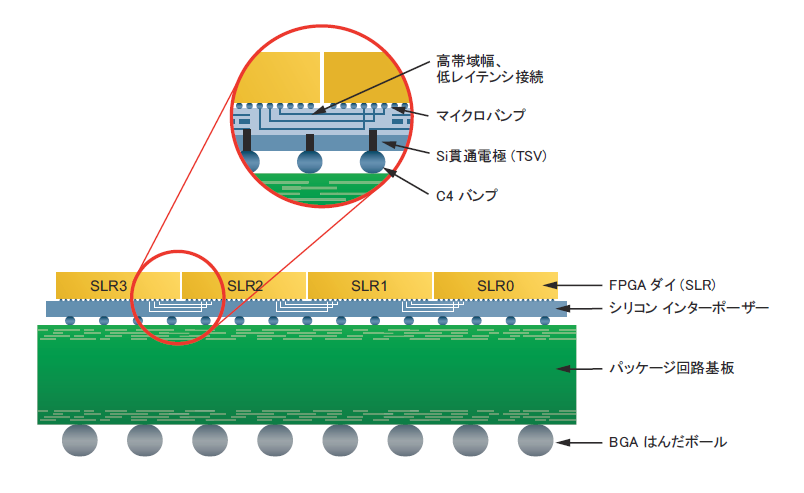
2つの SLR の間は上の拡大図で見られるような接続で渡します。図では “低レイテンシ接続” とありますが具体的には 2ns の遅延が掛かります。つまり、どんなに実装の配慮を施したデザインであっても複数の SLR に跨ぐと Fmax の上限は 500MHz ということになります。
SSI デバイスについて何の配慮もなく構成した規模の大きいデザインを実装しようとすると、1つの SLR からはみ出て複数の SLR を跨いでベチャっと実装されることになり、そのままだと500MHz よりは随分低い周波数で終わってしまうかも知れません。500MHz は SLR 跨ぎのデバイス仕様上のベストケースであって、それぞれの SLR の出口でちゃんと FF (レジスタ) を介して渡すケアがなされていないと出せない周波数です。
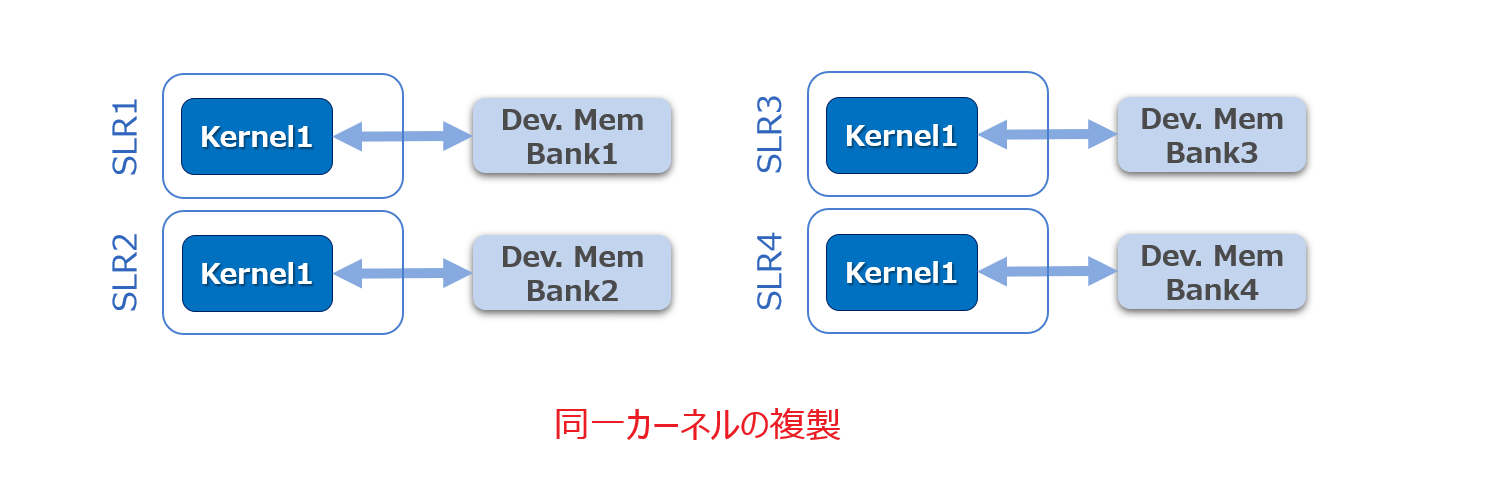
仮に、上述の U250 をターゲットに、1カーネルのアクセラレータとしてデータフロー (タスク並列) アーキテクチャを持つ規模の大きいデザインを設計したとします。500MHz は無理でも、期待する性能実現のために 400MHz は欲しいと期待していたところ現状 150MHz だとして、周波数が思いのほか低い原因が前の段落で述べたような状況だったとすると、その対策として、データフローを構成するサブモジュールをカーネルに昇格させて複数のカーネルに分割し、それぞれを適切な SLR にマニュアルで配置を決める (Vitis の v++ -link コマンドのオプションでコンフィグファイルを介して指定可能) というやり方が考えられます。この話はもちろん、それぞれあるいは複数のカーネルが1つの SLR に収まることが前提です。

そのように配慮したマルチカーネルの実装では、SLR の間をストリームの “土管” だけが渡ることになりますが、SLR の間を渡すリソースにも限りがありますので、分割したカーネルのそれぞれの DRAM へのパスが別の一方の SLR へ無駄に跨いでいくことが無いよう DRAM への接続を分散する (これも同様に Vitis から任意に指定可能) といったケアも必要になるかも知れません。
さらに、カーネルが分割されて複数になると、ホストプログラムから見える (制御が必要になる) カーネルも複数になります。マルチカーネルでデータフロー (タスク並列) 動作を実現するために、ホストからそれらを (スレッドとして) 同時に起動できるようランタイムプログラムの修正も必要になります。
あるいは、カーネル一つの規模は小さくでも、(CPU や GPU に対して) 少しでもスループットを上げるために、同じカーネルのコピーを出来るだけデバイスに詰め込みたい (Density を上げるとも言います) といったケースでは、先ほど触れたカーネルの SLR 配置の配慮のほかに、リソース使用率の限界と目標のクロック周波数との兼ね合いによって (トレードオフの内容が妥当である限りにおいて) Vivado を使った実装検討が通常以上に必要になることもあるかと思います。
Xilinx の第1期ブログ連載からの引用を繰り返していますが、カーネル設計済みの Vitis ライブラリを使った実装例の分かり易い説明や、上述したカーネルの SLR 配置や DDR との接続の指定やツール実行手順を示すチュートリアルまで含んでいます。
本連載はアクセラレータ/カーネル設計にフォーカスしていますが、以下の記事ではカーネル設計後の実装フローや実機上での確認の様子について、具体的な理解が得られる内容になっています。是非二つを併せてご覧になり、ここまでに得られた理解を元に HW/SW アクセラレーション開発の全体像をイメージしてみてください (ツール/設計フローの “心構え” については3章で詳しく触れる予定です)。
2-3. そもそもハードウェア化すべきなのか?
本論に入る前に前置きさせていただいたように本章では、アクセラレーションの対象としては “サーバー上の SW アプリ/計算アルゴ” にフォーカスした上で、その高性能アーキについて、実装品質への考慮も含め、話をしてきました。
サーバー側のそのような分野で FPGA が競合するのは、ハードウェア開発済みの汎用プロセッサ アーキテクチャであり、そこにソフトウェアで機能を実装するような、(部分的には) Xeon といった CPU や、(全面的には) Tesla といった GPU になります。エンベデッド向けの CPU とは訳が違います。
また、特にデータセンターの世界では、FPGA をその製品 (説明の為、エンベデッド/組込み向けとしましょう) に採用してきた “メーカー” による従来のビジネスとは、対象デバイスの種別だけでなく、それが適用から運用されるまでの舞台セットというか、販促活動のパラダイムも全く異ってきます。
メーカーであれば以下のスライド (筆者の自作ですが、原稿〆切に追われて日本語に変更する時間がありませんでした…) で示すように、企業として、製品であるシステムをエンドカスタマーに届けるために必要なコーポレート機能 (経営企画/R&D/マーケティング/事業部/資材、etc.) が、基本は全てその中に揃っています。
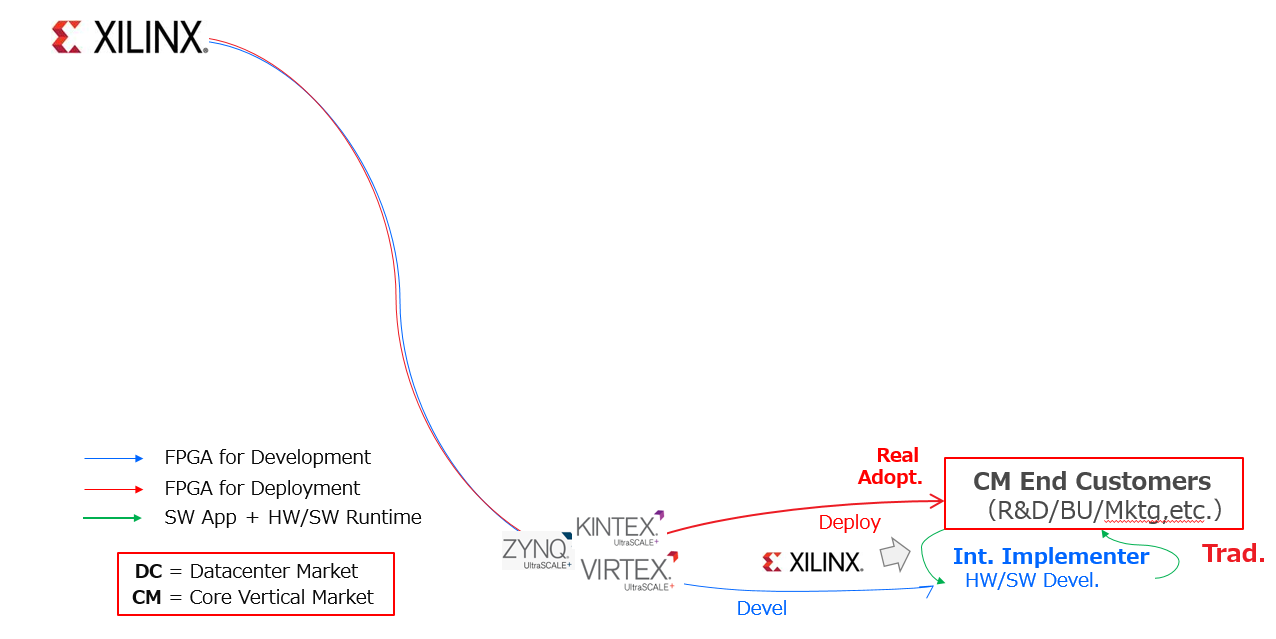
それがデータセンターの世界になると、同様に以下にスライドで示して上下を対比してみると、システムを構成する主体としてメーカーという階層は無くなり、各コーポレート機能がそれぞれ独立した企業体として World Wide に散らばっている状況になる訳です。これを、エコシステムと呼んでいます。
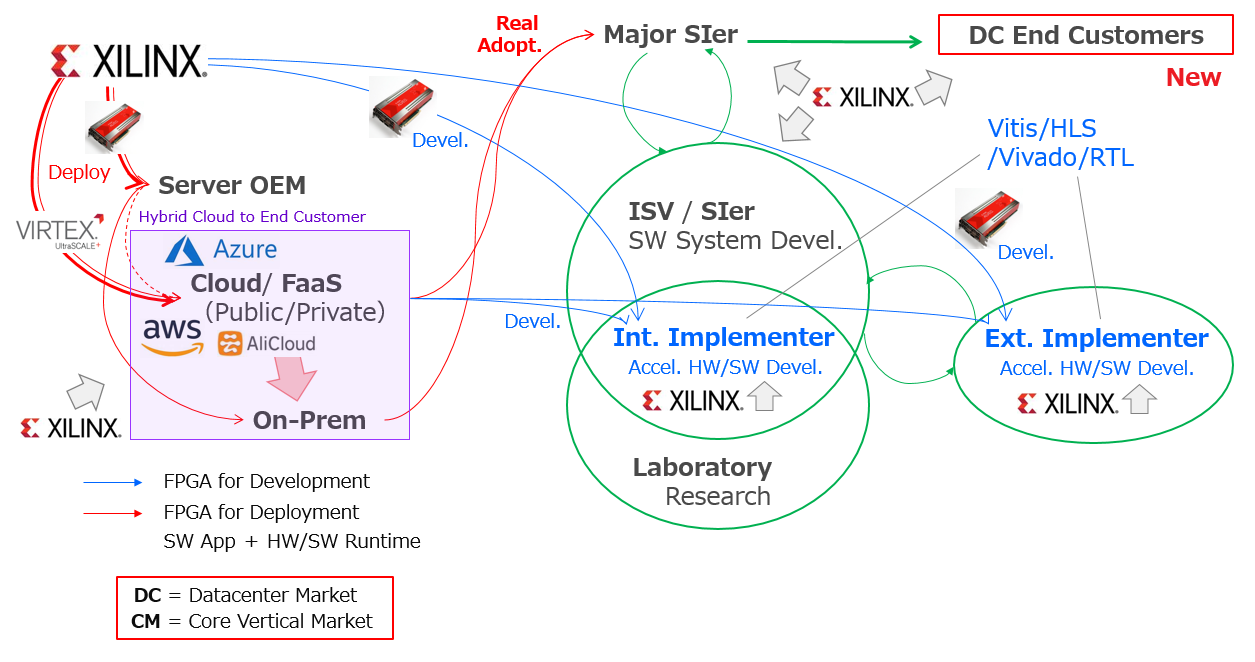
オンプレにせよクラウドにせよ、右端にはサーバー上で SW アプリケーションサービスを運営して収益を上げるデータセンターのエンドカスタマーがいて、左端にはサーバー OEM や、CPU/GPU/FPGA といったデバイスベンダー、真中には左端から “モノ” を集め、ソフトウェアは ISV (Independent Software Vendor) から購入するか自分で開発するかしてシステムを組み上げる (大手) SIer がいて、その SIer が右端のエンドカスタマーの経営陣に対して案件毎にそのシステム構成が妥当である理由を、コスパを説明する言葉を使って説得した上で、試作を含め長い開発期間を経てシステムを納品し、場合によっては MSP (Managed Service Provider) として運用も引き受けるかも知れません。そんなパラダイムです。
そのような新しいパラダイムにおいて、我らが FPGA をエンドカスタマーに採用していただくためには何が必要でしょうか?
そんなのベンダーが自分で考えろよ、って声が速攻で聞こえました。その辺はわきまえているつもりではおります。(^^;
未だデータセンター向けにその HW/SW アクセラレータが開発されたことのない SW アプリ/計算アルゴがあったとして、その開発を直接担当するのは、上のスライドの中で SIer や ISV に寄り添っているように見える専業インプリメンターです。そのビジネスモデルとしては、そのインプリメンターにしか考案できないアーキテクチャを有するカーネルを含む HW/SW ランタイムを IP として買い取ってもらうか、課金にするか、のどちらかになると思います。
あるいは、ISV 自身がカーネル開発部門を内に抱えているであれば、そのソフトウェアの付加価値というビジネスになるかと思います。
それで、そのようなビジネスを展開できるほどの、本連載で言及する全てのスキル (というより、それを可能にする “組織力” かも知れないです) を備えた企業が日本に潜在的にどのくらいいそうなのか、自分には正直よく分かりません。
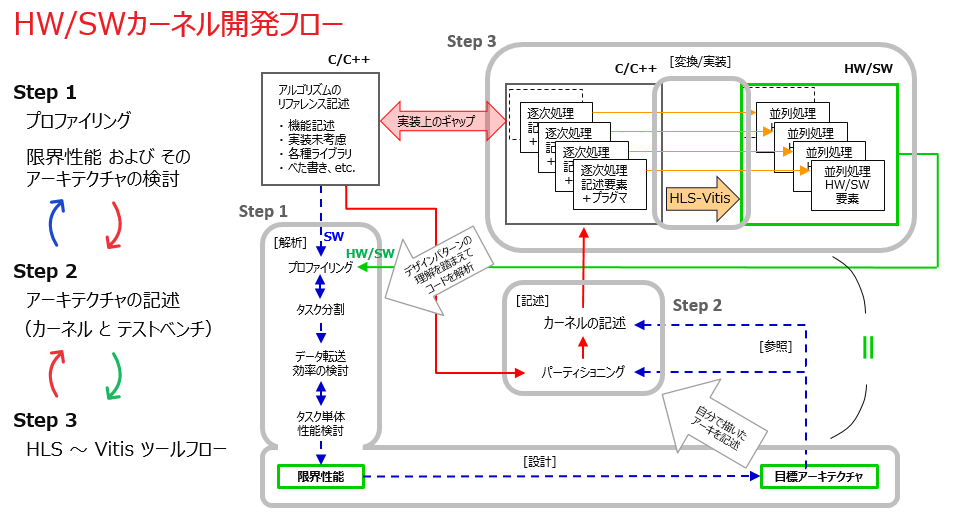
組織の能力として要求されるのは具体的にはどういう内容でしょうか。
- 専門とするアプリケーション分野に誰よりも深く精通している
- ハードウェア開発が必要な FPGA はもちろん、汎用プロセッサ (マルチコア、メニーコア) も含め、それぞれのアーキと実装手法、高性能化の対象としての向き不向きもよく分かっている上で、3択だけでなくそれらを組み合わせたヘテロとしての最適解も開発し、SIer を介してエンドカスタマーにとってのコスパの観点で提案までできる
- ソフトウェアのレファレンスコードを受けて最適なアーキを検討を進めるために、場合によっては元のソフトウェアに修正を迫る必要がある場合でも、HW/SW アクセラレーションの観点でそのソフトウェア開発元の ISV や SIer と (上下関係ではなく同じ目線で) 協業して進めていけるだけのリレーションを確立できる
2) については、どのような計算アルゴに対して、どのような Computing リソースを使い、HW/SW アーキテクチャの最適解 (特殊解) を見極められるか?そして、様々な選択肢を吟味して見極めた結果として、SIer を介す形でエンドカスタマーに対し、FPGA でハードウェア化する意味が有る/無いと、純粋に技術面だけでなく経済面の観点も踏まえ、根拠をもって主張できるほどのスキルを持てるような組織としてマネジメントできているか?という話だと思っています。
3) についても同様に、エコシステムのパラダイムをよく理解して SIer や ISV にアプローチできた上で、従来のような上から下に仕様が下りていくような進め方ではなく、最適解の見極めのために最初のレファレンスコードの解析段階から、SIer や ISV と一緒になって「SW ⇔ HW/SW ⇔ HW」の間を往還しながら進んでいけるような関係性が、アクセラレータ開発の前提として大事になってくると推察していますが、そのようなコミュニケーションが成立する状況を実現できるだけの組織としてマネジメントできているか?という話だと思っています。
おそらく、そのような組織は、従来のような「システム開発部 vs. SW/FW 技術部 vs. HW 技術部 vs. 営業部 vs. マーケ部、etc.」といった (サイロ間で排斥し合いがちな) 縦割りではなく、それらが混然一体となったチームとして機能しているものではないかと。特に、将来は FPGA を含む ACAP のような1チップヘテロデバイスまで対象にするようになるとなおさら、デバイスがヘテロで、エコシステムもヘテロなら、それに対応して組織構成もヘテロとして最適化を図っていかないと不自然じゃないかなと、(勝手に) 想像している次第です。
Coffee Break. 最終形は「ML+X」 over 「AIE + PL」かも?
ふぅ~ぅ。やっと2章の Coffee Break まで辿り着きました。ちなみに、筆者がここに至るまでの今回の Coffee の量ですが、1章ときのそれの比じゃない (200杯くらい?) ですね (感覚です)。考え込む時間が長かったです。ここでこんな冗談言っちゃって良いのかな悪いかな、とか (違うか)。そんな疲れてるんだったら Coffee Break どころかいっそ Stop しちゃったら? どっかからそんな声が聞こえますが (寝不足でとうとう幻覚か…)。でもそれだと何か締まらない気がして、まぁ1章の Coffee Break (「デバイスベンダーの垂直統合 EDA ツール」) のときみたいに人生を語りながらその頃の思いにふけるみたいなことも今回は無いですし、やらせていただきます。
さて、内容ですが、目次でタイトルを見ただけでは何の話かイメージ出来なかったかと思います。一行に収まる表現をと思ってあれこれ考えた結果があぁだっただけで、意味深なつもりではありませんでした。
全部が頭文字か略称の代名詞で、それぞれ以下のような内容です。
ML:Machine Learning. Xilinx の DPU コアを用いてアクセラレーションされる推論モデル.
X:ML 以外でアクセラレーションされる対象である “何か (X) ” (計算アルゴリズム) .
AIE:ACAP デバイス上の AI Engine.
PL:ACAP デバイス上の Programmable Logic、つまり FPGA のことですね.
ACAP という呼び名でパブリックに紹介されているのは、以下の要素で構成される “新しい種類の1チップデバイス” になります (ざっくり過ぎて怒られそうです)。
ACAP = Scalar Engines (ARM:マルチコア)
+ Intelligent Engines (DSP + AI Engines:メニーコア)
+ Adaptable Engines (つまり FPGA:カスタムハードウェア)
ちなみに、Zynq SoC が登場したときには、1チップ上の ARM を PS (Processing Engine)、FPGA を PL (Programmable Engine) と呼びました。何をどういう文脈でどう呼ぶか (呼ばせたいのか)、今は特にヘテロデバイスの普及前の過渡期でもありますし、諸々のネーミングがしっくりと落ち着くまではオーディエンスも混乱しそうですね (他人事のような言い方ですみません)。
今まではヘテロデバイスという言葉はあっても、CPU vs. GPU、GPU vs. FPGA というように、デバイスベンダーもそれぞれ専業で違うためか、たとえシステムとしては一体となって運用されていたにしても、どちらかというと “融合” というよりは “競合” という図式で捉えられてきた感がありますが、ACAP は1チップで、こういうのが本当の意味でのテロデバイスだよなぁ、と筆者はブツブツ言っております。これが将来普及して他社も追ってリリースすれば、デバイスはデバイス、ベンダーはベンダーという、ちゃんとした競合関係になっていくのかなと (余計なことばかり) 思ったりもします。
タイトルの意味の話に戻りますが、簡単に表現すると、ACAP デバイスに対して
ML の推論は AIE に、その前後処理の “何か” (X) は PL に、割り付ける
という意味で、そういう ACAP の実装形態が ML を含む計算アルゴリズムのアクセラレーションの本命になっていきそうかも、という今後のトレンドについて言っています。以下はその内容の話になります。
Xilinx ではこれまで、ML 推論モデルをプログラムで割り付けられるような専用エンジン/プロセッサとして、FPGA ベースの DPU (Deep Learning Processing Unit) というアーキテクチャ/ハードウェアを独自開発&買収で持っています。DPU が用意されているので、ユーザーは推論モデル毎にアクセラレータをカスタム開発する必要が無く、”プログラムだけで” 済みます。
Xilinx からの第2期ブログ連載に FPGA ベースの DPU と、DPU に対して ML 推論モデルを割り付けるための DK (Design Kit) である Vitis AI 開発環境について簡潔に紹介している記事がありますので (以下)、参考にしてください。

この FPGA ベースの DPU と Vitis AI ですが、これまでずっとサーバー向けのアクセラレーションをしてきましたのでこの話をしますと、実は AWS F1インスタンス向けにはサポートされません (パブリックに公表はされてはいないと思いますが、事実です)。本章の2-3節 (「そもそもハードウェア化すべきなのか?」) と関連した話かと思いますが、理由は「FPGA ベースの DPU 単体の “汎用品” ソリューションにすると、F1の従量課金だと GPU インスタンスに対してコスパで魅力的では無さそう」と考えたから だと思います。
クラウド向けの Compute アクセラレーションの分野でエンドカスタマーが採用を決めるのは、”性能” ではなく、”従量課金額でノーマライズされた性能”、というかコスパです。高額な従量課金というペナルティを解消して大幅なコスパの逆転を実現するためには、2-2節で述べたような FPGA 実装の Density を上げる努力が (アーキ、実装の両面で) 必要になってきます。
F1インスタンスの現時点の従量課金の価格は GPU インスタンスと比べて高額です。クラウドのインスタンスで従量課金なので時間単価になりますが、価格の内訳までは (自分には) 分かりません。
F1は AWS でリリースされた Xilinx デバイスの一番最初のインスタンスでもありますし、採用と価格の関係は鶏と卵の関係という、今は本格的な普及前のまだ過渡期ということなのかなと (勝手に) 想像している次第です。
これが、同じデータセンターでもコスト (TCO:Total Cost of Ownership) の形態が異なるオンプレとか、データセンターではなく産業向けで Alveo を直接仕入れて製品に使うメーカーのケースだと、また全然状況が (良い意味で) 違います。ちなみに前者は、よほどのサービスボリュームが見込まれる場合の話ですね。
じゃぁクラウド向けに FPGA 実装の DPU 単品だとダメならその前後に何か “X” を付けて、という話になります。「ML + X」というのは、アプリケーション毎 ML とその分野に固有の計算アルゴリズムを合せたものに対してアクセラレーションが必要な典型的なユースケースに対する複合ソリューションを提供していこうという、Xilinx が考える方向を示しています。
ちなみに、組込み向けだと FPGA ベースの DPU 単品でも十分コスパに見合います。消費電力等の他のメトリックスもあって有利な状況です。
そしてその複合ソリューションの割り付け先として、今後は1チップ FPGA というよりは、ACAP のほうを優先して進んでいくようです。その場合、DPU コアは ACAP 上の FPGA ではなく、AIE に実装した専用エンジンになります。
FPGA が1チップだったり ACAP の一部だったり、確かに言葉遣いが難しいですね (^^;
先ほど触れた第2期ブログ連載の中に、AIE (AI Engine) の分かり易い概要説明があります。以下の記事も参考にしてください。
今お客様が ACAP を渡されて、AIE を含む ACAP 1チップ全部スクラッチで開発してくださいと言われても、最初はかなりハードル高くて困っちゃいそうですが、Xilinx が AIE に割り付けた DPU を用意してくれているというのであればまずはそれを使って、PL (FPGA) には自分の機能をカスタムで加えて統合も出来そうだな、という話になると思います。それは AIE というか、初の1チップヘテロデバイスである ACAP の門出にとっても、幸せな事だと思います。
ということで、ML の実装は DPU の AIE だとして、ML 以外の何か “X” は PL つまり FPGA に実装するという、タイトルが示すテーマにやっと繋がりました。アプリケーション毎に AIE と PL のセットのソリューションを Xilinx は Xilinx で取り揃えていく方向だとは思いますが、同時に、専業のインプリメンターが独自のアクセラレータを PL 上の “X” として、AIE 上の DPU と1チップ統合/開発する話もいろいろと出てくると思います。
ちなみに、本章の2-1節の中で「タスク間の並列性」について話をしましたが、AIE 上の DPU と PL 上のアクセラレータ “X” は、DRAM を介さず同じ1チップ ACAP デバイス上で FIFO/ストリームを介して繋がって、データフロー (タスク並列) を構成します。FPGA を含むヘテロデバイスらしい実装として性能的にも申し分のない内容になろうかと思いますが、あと問題は価格でしょうか… (最後はいつもその話)。
第3章へ続く
3章の前に、設計事例を紹介する記事を一回挟みます。
(ちなみに執筆するのは自分の今の上司です 😊)
ザイリンクス株式会社 黒田成一