こんにちは。この「Synthesijer と高位合成ツールの作り方」のシリーズでは、全5回を通じて Synthesijer をベースに FPGA 向けの簡単な高位合成処理系を作る方法を紹介していきます。例は Java ですが、お気に入りの言語向けの処理系を開発する足がかりとして利用できるように紹介できればと思ってます。
前回は、Synthesijer における内部情報の変形処理として並列化とチェイニングの様子を紹介しました。最終回となる今回は、高位合成による高速化の効果を楽しめるパイプライン化を紹介します。また、おまけとして、高位合成処理系を作ってみたいという人向けのツールを簡単に紹介します。
パイプライン化とは?
パイプライン化は、繰り返して実行される処理を細かい単位に分割して、それぞれをオーバラップすることで全体の処理時間を短かくする最適化手法です。次の図のように、繰り返して実行される (S) が A → B → C という同一処理時間の3つの処理に分割できる場合、S をそのまま繰り返すのではなく、A、B、C の実行をオーバラップさせることで、実行時間を短縮できます。繰り返し回数が多ければ実行時間は約 1/3 になります。
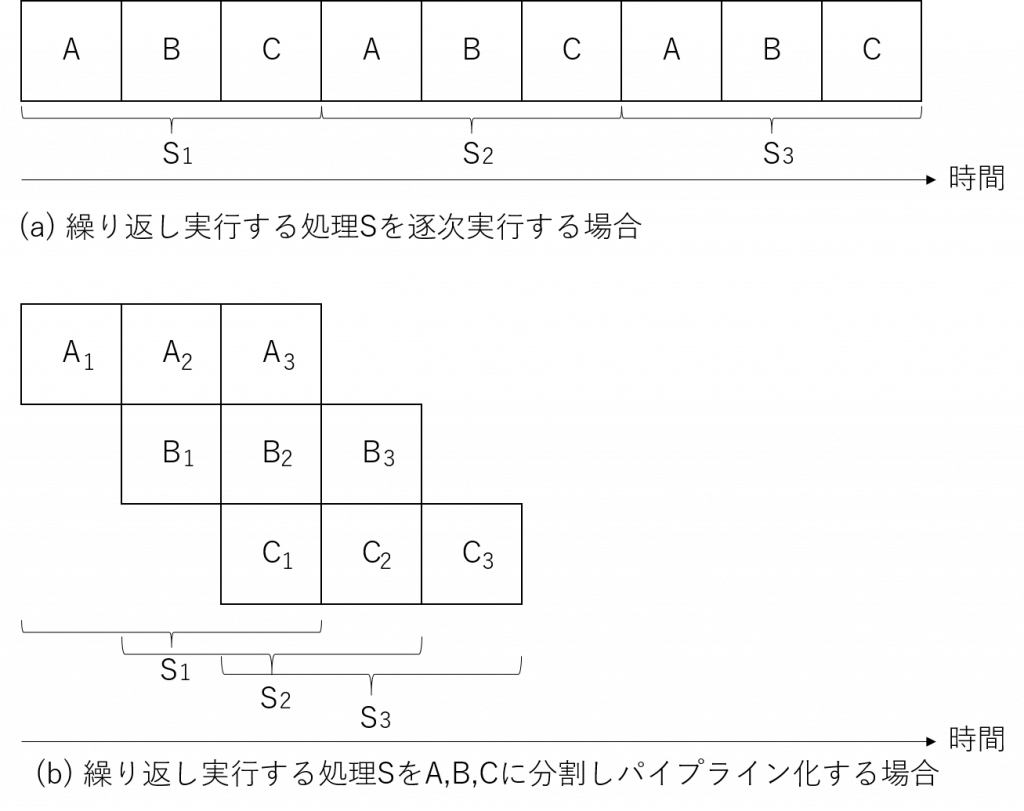
パイプライン化はハードウェア・ロジック設計特有のテクニックというわけではなく、ソフトウェアプログラミングにおいても重要な最適化の一つです。しかし、ハードウェア・ロジック設計では、既存のプロセッサの演算器の制約にあわせたパイプライン化ではなく、処理したいアプリケーションが必要とする演算器を自由に並べてパイプライン化できる可能性があり、うまく利用できれば大きな効果が得られます。
ループを対象にパイプライン化
逐次処理用のプログラミング言語をベースにした高位合成処理系の場合、一般に、パイプライン化の対象である「同じ処理が何度も繰り返される箇所」としてループに着目します。ループ構文を持たない言語からハードウェア・ロジックを生成する場合では、ループに変換可能な末尾再帰が対象になるでしょう。
処理系は、ループ内の処理を細かい処理に分割して、パイプライン化、すなわち複数回のループをオーバラップして実行できるように並べなおします。パイプライン化で大きな効果を得るためには、なるべく大きなループを細かな処理に分割することと、分割した処理を毎クロック動作させることが肝要です。そのため、与えられたループをプログラムの意味を壊さない範囲で並べかえたり、多重ループを一重ループに変換するような前処理を行なう場合があります。
一般に、処理をパイプライン化するとオーバラップ実行のために演算器やレジスタが余計に必要になります。つまり、パイプライン化による高速化とハードウェアリソースの使用量はトレードオフの関係にあります。そのため、多くの処理系では、ループをパイプライン化するかどうかユーザが指定できるようになっています。
Synthesijer のパイプライン化
Synthesijer では、実験的にパイプライン化の実装をすすめています。ここでは Synthesijer に実装中のパイプライン化の様子を紹介します。
サンプルプログラムは次の通りです。Java では C/C++ のように #pragma が使えないので、パイプライン化したいループのインデックス変数に @Pipeline というアノテーションをつけて目印にしています。
import synthesijer.rt.*;
public class Test030{
public void test(int[] a, int[] b, int[] c){
for(@Pipeline int i = 0; i < 1024; i ++){
c[i] = a[i] + b[i];
}
}
}パイプライン化しない場合、Synthesijer は次のような内部表現に変換して HDL を生成します。これは、配列 a と b からデータを読み出し、読み出した値の和を配列 c に書き出すという動作を逐一実行するハードウェア・ロジックに相当します。
(MODULE Test030
(VARIABLES
)
(BOARD VOID test
(VARIABLES
...
)
(SEQUENCER test
(SLOT 0 (METHOD_EXIT :next (1)))
(SLOT 1 (METHOD_ENTRY :next (2)))
(SLOT 2 (SET test_i_0003_1 (ASSIGN constant_00004) :next (3)))
(SLOT 3
(SET test_i_0003_2 (PHI test_i_0003_1 test_i_0003_4 :patterns ( 2 13)) :next (4))
(SET unary_expr_00007_1 (PHI unary_expr_00007_0 unary_expr_00007_2 :patterns ( 2 13)) :next (4))
(SET unary_expr_postfix_preserved_00008_1 (PHI unary_expr_postfix_preserved_00008_0 unary_expr_postfix_preserved_00008_2 :patterns ( 2 13)) :next (4))
(SET binary_expr_00006_1 (PHI binary_expr_00006_0 binary_expr_00006_2 :patterns ( 2 13)) :next (4))
(SET test_i_0003_3 (PHI test_i_0003_1 test_i_0003_4 :patterns ( 2 13)) :next (4))
(SET binary_expr_00006_2 (LT test_i_0003_3 constant_00005) :next (4))
(SET test_i_0003_4 (ADD test_i_0003_3 constant_00009) :next (19))
)
(SLOT 4
(JT binary_expr_00006_2 :next (10 0))
)
(SLOT 10
(SET array_access_00011 (ARRAY_INDEX test_b_0001 test_i_0003_3) :next (19))
(SET array_access_00010 (ARRAY_INDEX test_a_0000 test_i_0003_3) :next (19))
(SET unary_expr_postfix_preserved_00008_2 (ASSIGN test_i_0003_3) :next (19))
)
(SLOT 19
(SET array_access_00011 (ARRAY_ACCESS_WAIT test_b_0001 test_i_0003_3) :next (20))
(SET array_access_00010 (ARRAY_ACCESS_WAIT test_a_0000 test_i_0003_3) :next (20))
)
(SLOT 20
(SET array_access_00011 (ARRAY_ACCESS0 test_b_0001 test_i_0003_3) :next (12))
(SET array_access_00010 (ARRAY_ACCESS0 test_a_0000 test_i_0003_3) :next (12))
)
(SLOT 12
(SET binary_expr_00012 (ADD array_access_00010 array_access_00011) :next (13))
)
(SLOT 13
(SET array_access_00013 (ARRAY_INDEX test_c_0002 test_i_0003_3) :next (3))
(SET array_access_00013 (ASSIGN binary_expr_00012) :next (3))
)
)
)
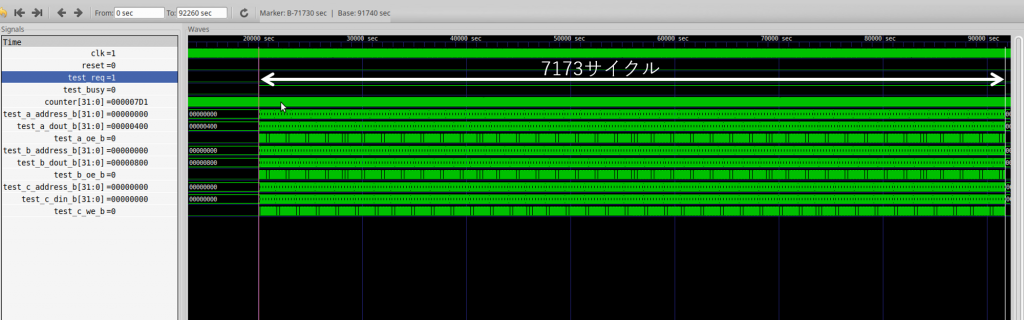
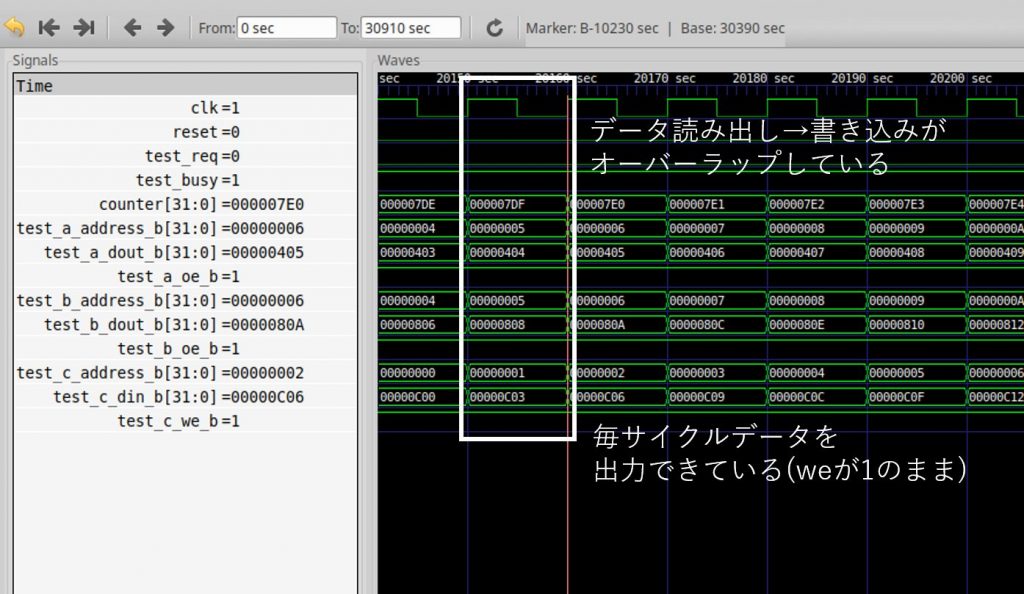
)動作の様子を確認している様子が次の通りです。ここでは,1クロック10秒でシミュレーションしているため、メソッドの実行に 7173 クロックかかっていることになります。
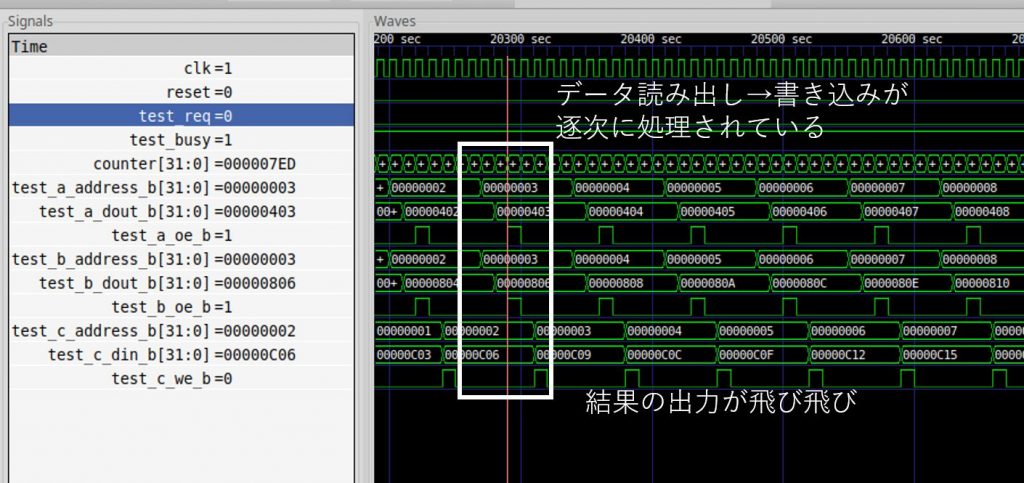
一部を拡大してみると、値の読み出しと書き込みが逐次に実行されている様子が確認できます。
パイプライン化する場合、最初は SLOT 3 の動作を開始、続いて SLOT 4 の動作に加え次の SLOT 3 の動作をオーバラップ、その次は、SLOT 3、4、10を動作させる、という風に仕込みます。最終的には、元の SLOT 13 相当のステートで、すべての動作を同時に実行します。
ここで、処理は同時には実行しますが、メモリを読む動作とメモリを書く動作のループインデックスがずれていることに注意する必要があります。インデックス計算の結果は適切に遅延を挿入して取り出す要があります。
(SLOT 13
;; 元のSLOT 13相当
(SET array_access_00013 (ARRAY_INDEX test_c_0002 test_i_0003_3_5) :next (13 0))
(SET array_access_00013 (ASSIGN binary_expr_00012) :next (13 0))
;; 元のSLOT 12相当
(SET test_i_0003_3_5 (ASSIGN test_i_0003_3_4) :next (13 0)) ;; 遅延生成
(SET binary_expr_00012 (ADD array_access_00010 array_access_00011) :next (13 0))
;; 元のSLOT 20相当
(SET test_i_0003_3_4 (ASSIGN test_i_0003_3_3) :next (13 0)) ;; 遅延生成
(SET array_access_00011 (ARRAY_ACCESS0 test_b_0001 test_i_0003_3_2) :next (13 0))
(SET array_access_00010 (ARRAY_ACCESS0 test_a_0000 test_i_0003_3_2) :next (13 0))
;; 元のSLOT 19相当
(SET test_i_0003_3_3 (ASSIGN test_i_0003_3_2) :next (13 0)) ;; 遅延生成
(SET array_access_00011 (ARRAY_ACCESS_WAIT test_b_0001 test_i_0003_3_1) :next (13 0))
(SET array_access_00010 (ARRAY_ACCESS_WAIT test_a_0000 test_i_0003_3_1) :next (13 0))
;; 元のSLOT 10相当
(SET test_i_0003_3_2 (ASSIGN test_i_0003_3_1) :next (13 0)) ;; 遅延生成
(SET array_access_00011 (ARRAY_INDEX test_b_0001 test_i_0003_3_1) :next (13 0))
(SET array_access_00010 (ARRAY_INDEX test_a_0000 test_i_0003_3_1) :next (13 0))
;; 元のSLOT 4相当
(SET test_i_0003_3_1 (ASSIGN test_i_0003_3) :next (13 0)) ;; 遅延生成
(JT binary_expr_00006_2 :next (13 0))
;; 元のSLOT 3相当
(SET test_i_0003_2 (PHI test_i_0003_1 test_i_0003_4 :patterns ( 2 13)) :next (13 0))
(SET unary_expr_00007_1 (PHI unary_expr_00007_0 unary_expr_00007_2 :patterns ( 2 13)) :next (13 0))
(SET binary_expr_00006_1 (PHI binary_expr_00006_0 binary_expr_00006_2 :patterns ( 2 13)) :next (13 0))
(SET test_i_0003_3 (ADD test_i_0003_3 constant_00009) :next (13 0)) ;; 演算結果を次のステートで即利用できるよう展開
(SET binary_expr_00006_2 (LT test_i_0003_3_4 constant_00005) :next (13 0))
)シミュレーションで動作を確認してみます。一部を拡大した様子が次の通りです。連続してメモリ読み書きが実行されていること、配列 c に書き出される結果がパイプライン化の前と同じであることが分かります。
メソッド呼び出しから終了までの様子は次の通りです。
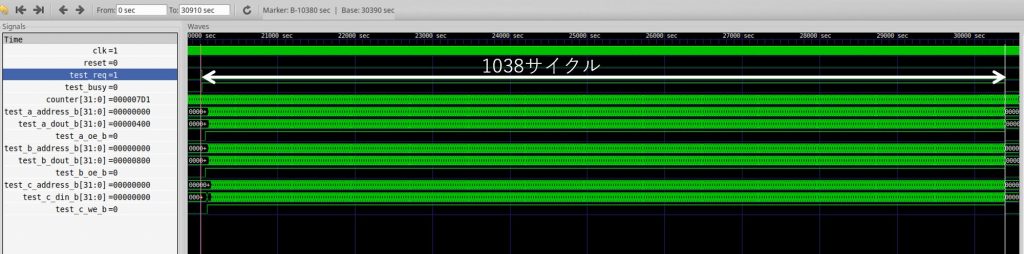
パイプライン化の前のメソッド実行時間が 7173 クロックだったのに対してパイプライン後の実行時間は 1038 クロックになりました。7 ステートを逐次に実行していたハードウェア・ロジックをパイプライン化によって同時に動作させたことで、約 7 倍の高速化が達成できたことが見て取れます。
パイプライン化の難しさ
高位合成では、パイプライン化によってプログラムから高速なデータ処理が可能なハードウェア・ロジックを生成できます。ただし、以下のような場合には、プログラムをうまくパイプライン化できません。
- パイプライン化したいループ間の依存がある場合
- 同時にアクセスできるリソースに限りがあるアクセスが競合する場合
一つ目のループ間の依存は、たとえば、簡単にはループの 1 回目で生成した結果をループの2回目で利用しなければならいないような場合です。必要なデータがなければ、1 回目のループが完了するまで 2 回目のループをスタートすることができません。
二つ目のリソース競合は、たとえば、ループ内で同一のメモリから複数回のデータを読み書きしなければならないような場合です。メモリのポートはレジスタや演算器のように簡単に配置することはできません。たいていの場合は 2 ポートが利用でき、それ以上のポート数が必要な場合には複数のメモリを組み合わせて対応する必要があり、そのコストは小さくありません。ループ間でうまくアクセスをずらすことができればパイプライン化できますが、いつでも可能というわけではありません。
実際に人間が記述したプログラムには様々な依存があり、そのままパイプライン化できるようなパタンばかりではありません。それを紐といてパイプライン化するのが処理系の品質です。逆に、既存の高位合成処理系を利用する場合には、時には、高位合成処理系の負担にならないようなプログラムを記述する必要があることにも注意が必要です。
まとめ
この 5 回の連載では、高位合成処理系を俯瞰からはじめ、その後、一つの事例として Java を VHDL/Verilog HDL に変換する Synthesijer の内部の様子を紹介してきました。
高位合成処理系の実装方式を咀嚼してまとめたかったのですが、残念ながら Synthesijer 内部での変換事例の紹介に終始してしまいました。それでも、高位合成処理系の開発というのが、プログラムを表現したデータ構造の変形にすぎない、簡単に作れば簡単な、いろいろ考え出すとチャレンジングで面白いタスクだということが紹介できたのであれば、筆者としては幸いです。
大規模な FPGA が手軽に利用できるようになってきたことで「アプリケーションをハードウェア・ロジックとして実装するならば究極に高速化や低消費電力化、省リソース化したものでなければならない」ということばかりではなく「ほどよい性能で開発コストを削減」というケースも多少は増えてきたように思います。ソフトウェア・プログラミングで実装したいアプリケーションに応じて言語を自由に選べるように、ハードウェア・ロジックの設計でも「設計しやすさ」の観点で多数の選択肢が生まれる将来を願っています。
Synthesijer については、(1) 先行研究にある各種最適化手法を実装できていない、(2) Java ベースの利点をまだまだ全然活用できていない、という大きな余地が残っています。まだまだ開発を楽しめそうです。
[おまけ] 高位合成ツールの作成に便利なツール
これから高位合成ツール作ってみようかなと思った人向けに、知っておくと便利なツールを簡単に紹介します。それぞれの詳細については公式サイトや多数ある解説記事を参照してください。
グラフ描画ツール (Graphiviz)
高位合成処理系を実装する上では、正しく動作するハードウェア・ロジック、さらには小さくて高速なハードウェア・ロジックを組み立てるために制御フローやデータフローを解析することが必須です。コンピュータで処理する場合には好きなツリー構造で保持すればよいのですが、実装方針の検討やデバッグの際には可視化できると便利です。
制御フローやデータフローグラフを描くのに便利なツールが Graphviz です。ノードとエッジでグラフを表現できる DOT 記述から SVG や PNG などの形式で画像ファイルを生成できます。この連載中で例に示したグラフも Graphviz を利用して描画しました。
単純に有向グラフを書くだけなら
digraph {
test_1;
test_2;
test_1 -> test_2;
}というファイル (test.dot) を用意して、
$ dot -Tpng -o test.png test.dotとコマンドを実行するだけで、次のような PNG ファイルを生成できます。
グラフ全体、ノード、エッジをいろいろと装飾することもできます。綺麗なグラフを書くことで見通しが良くなりデバッグや最適化もはかどるかもしれません。一方で「綺麗なグラフを書いて満足してしまう」ことから Graphviz は危険だという言語処理系実装者の声を聞いたこともあります。凝りすぎには注意しましょう.
シミュレータと波形ビューワ
高位合成処理系で生成した VHDL や Verilog HDL を毎回 FPGA 向けに合成して動作を確認するのは手間がかかりますし、観測できる信号に限りがあるためデバッグがはかどりません。デバッグにはシミュレータを使うのが簡単です。Xilinx の Vivado や Intel の Quartus を利用するのもよいのですが、VHDL なら GHDL、Verilog なら Icarus Verilog を使うのが手軽です。C++ で手軽にテストベンチを記述して Verilog/SystemVerilog コードをシミュレーションできる Verilator も便利です。
GHDL、Icarus Verilog、Verilator 自体は結果を確認する GUI を持ってはいません。シミュレーション結果は波形ファイルに出力して確認します。波形の表示には Windows 含む多くの環境で利用できる GTKWave がよく使われています。
言語パーザ
高位合成処理系を作りたいという場合、たいては人が読み易い入力言語からハードウェアを作りたいと思うのではないでしょうか。入力言語を処理系で扱いやすい表現に変換する方法は高位合成処理系に特化したものではなく、一般的なコンパイラ作成のノウハウが利用できます。コンパイラ作成の入門書の中にはパーザを実装する例題があるものもありますので参考にするとよいでしょう。
また、既存の言語を入力とした処理系を作りたい場合、ゼロからその言語のパーザを実装するのも楽しいかもしれしれませんが、言語のコンパイラに対するフック機能や、言語が持つパーザを利用すると便利です。Synthesijer は Java のプラグインとして実装してフロントエンド実装の手間を省略しています。C や C++ を対象にしたいのであれば gcc のプラグインを利用するか LLVM を利用するのもよいでしょう。自分自身のパーザを持つ言語には、Scheme や Go 、Python などがあります。好きな言語を入力として受けとる処理系を好きな言語そのもので手軽に開発しはじめられるという嬉しさがあります。
わさらぼ・みよしたけふみ