カウンタ回路を FPGA で動作させて挙動を確認しよう(入門編)
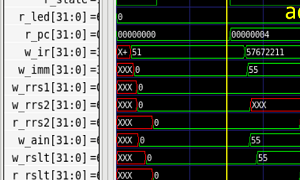
この記事では、ACRi ルームのコンピュータと FPGA を利用して、Verilog HDL で記述される簡単なカウンタ回路を動作させて、その挙動を確認する方法を説明します。 Verilog HDL で記述したハードウェアの内容や、論理合成、配置・配線といった処理の詳細は後回しにします。Vivado を活用して、FPGA を動かすこと、動かした FPGA の動作を確認することを目標にします。 FPGA の設計・開発に慣れていないみなさんを対象とする初級の内容です。ACRi ルームの...