
こんにちは! 前回は FPGA を活用して AI を実現するとどのようなメリットがあるか、いくつかの応用事例を交えて概観しました。
今回は FPGA がそうしたメリットを実現できるしくみについて解説します。そして後半には今までの課題とそれを解消するべく登場した開発環境について触れたいと思います。
FPGA はなぜ低遅延、高スループット、低消費電力を実現できるのか
前回のブログで FPGA を活用して AI を実現するメリットを5つ挙げました。そのうち特に遅延時間とスループットの両立、および消費電力の低減を実現するしくみについていくつかの観点から解説します。
処理の並列度を大幅にかつ柔軟に向上できる
データセンターで近年よく利用されている FPGA には DSP (デジタル・シグナル・プロセッサ) コアが約12,300個搭載されています。この DSP コア は SIMD (Single Instruction Multiple Data) 演算をサポートしており、乗算、積和演算、バレルシフト、複素数演算、三角関数演算などを効率よく実行できる構造になっています。ディープラーニングの推論で最近よく使われるようになった8ビットデータの場合、1クロック毎に4つの命令を実行することが可能です。
豊富な機能を持った演算ユニットがたくさん搭載されていることで並列度を高められることはスループットの向上と遅延時間の短縮に効果的です。しかし FPGA の良いところはそれだけではありません。それに加えてユーザが自分の実現したい機能に合わせて DSP 同士や DSP とユーザの実現したい演算回路などを自由に接続できる点にあります。この点は、固定された演算回路とそれらに接続されているハードウェアで予め決められた命令セットを実行する CPU や GPU などのプロセッサとの比較における大きなメリットのひとつです。
例えば GPU は同じ命令を並列実行することはとても得意な構造になっていますが、まったく別々の多数の処理を同時に並列実行することはあまり得意ではありません。そのため、高いスループットを実現するためにはデータや命令をまとめてそろえることで並列度を高める必要があります。データや命令をそろえるための待ち時間などが生じるため、高いスループットと短い遅延時間の両立が難しくなります。この点については (2) と合わせて次に見てみましょう。
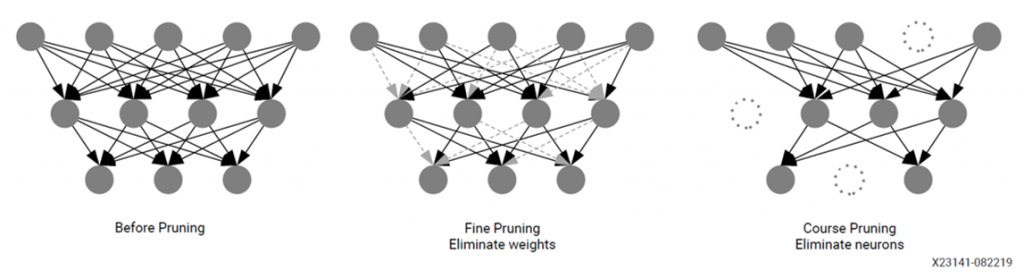
一例として、ディープラーニングでは認識精度を維持したまま演算量を削減し、消費電力や演算に必要なリソースを削減するプルーニング (枝刈り) という前処理が利用されることがあります。プルーニングにはノードをまるごと削減する粗粒度プルーニング (Course Pruning) とノードは残したまま重みエッジを削減する細粒度プルーニング (Fine Pruning) が提案されています。このうち細粒度プルーニングを行うと命令やデータをそろえることが難しいため、GPU などのプロセッサでは実現することが不得手な手法となります。
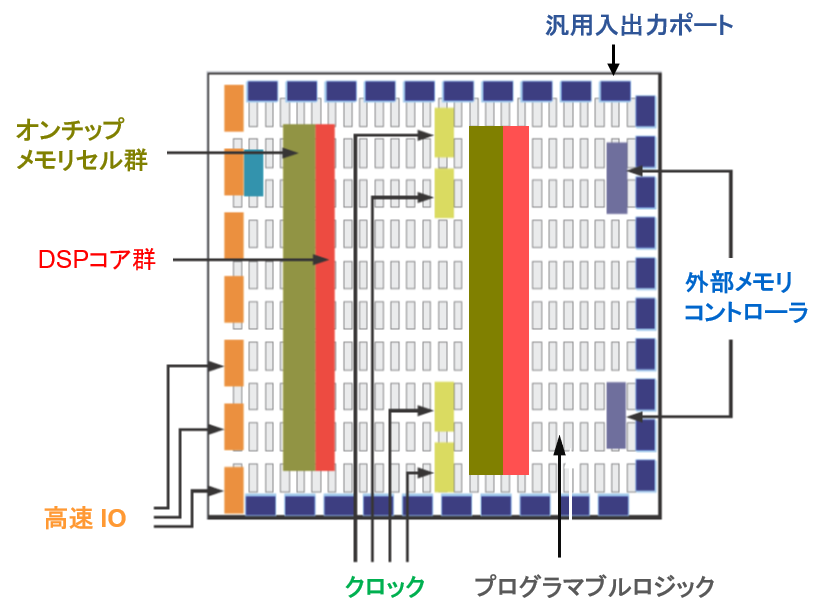
メモリの構成および容量
FPGA のメモリ構造が CPU、GPU と比較して優れている点は以下の3つに分類できます。
1) 処理能力の向上
2) 遅延時間を安定的に短縮
3) 消費電力の削減
プロセッサでは、命令を高速に実行するために、データ (オペランド) を演算命令を実行する前にレジスタにロードして準備しておくロード・ストア型アーキテクチャが一般的です。また、レジスタのデータ幅は固定となっています。このようなアーキテクチャは優れた面もありますが、例えば大きなデータからある特定のシーケンスパターンのデータを検索するマッチング判定といった処理の場合、データをレジスタのビット幅に細かく分断してレジスタにロード、シフト、比較といった処理を数多く繰り返す必要が生じるため、処理能力が大きく低下します。
FPGA はビット幅が可変なメモリ・セルを数多く搭載しています。それらのメモリセルを自由につなぎ合わせることでさらに幅広いビット幅を持ったメモリを自由に作ることができます。比較のデータパターンをたくさん準備しておけば、データを何度もオンチップのメモリに読み込むことなく、一度にいくつものデータパターンと比較することができ、処理時間を劇的に短縮することが可能になります。
プロセッサは一次キャッシュ、二次キャッシュを搭載することでオンチップのメモリ容量を節約しながらなるべく性能を引き出す構造を採用しています。これは優れた考え方ですが、実行に必要な命令やデータがキャッシュに存在しない場合にはミスによるペナルティが生じ、待ち時間となってしまいます。さらに割込み処理などによる不定期な遅延時間が加わり、全体の処理時間にばらつきやジッタが大きく生じる結果となります。
オンチップのメモリ容量が大きいことのもう一つのメリットは、外部メモリへのアクセスを無くす、もしくは低減できることです。これにより、システムのコストやサイズを削減できるだけでなく、外部メモリのアクセスによる消費電力や遅延時間を削減できます。
例として下図のフローの処理の実行を考えてみましょう。図は説明のために概念をシンプルに表現しています。
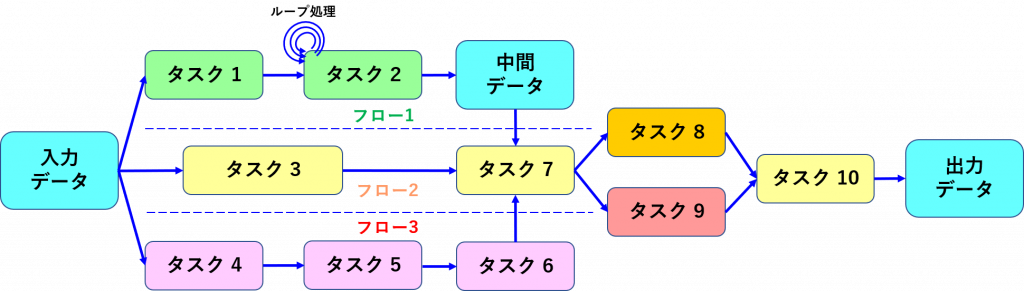
並列処理を行わずシングルタスクで実行する場合には、データの取り込みからタスク 1、タスク 2、… 、タスク 10 の順番にシーケンシャルに実行することになります。各タスク内の並列実行可能な処理を並列に同時実行することで、全体の処理時間を短縮できますが、異なる処理を並列に実行することができない場合、上段のフロー 1、中段のフロー 2、下段のフロー 3は処理内容が異なるため、シーケンシャルに実行しなければなりません。
このようなケースで FPGA は処理内容が異なるフロー 1、フロー 2、フロー 3を並列に同時実行して処理時間を短縮することが可能です。タスク 8、タスク 9についても同様です。さらに、オンチップのメモリ容量が十分でない場合、タスク 2 は中間データを外部メモリにいったん保存し、タスク 7 はデータが保存されているデータを外部メモリからロードする必要があります。外部メモリへのストア、ロードのアクセスは全体の処理時間や消費電力を増加させる要因となります。オンチップメモリの容量が大きい FPGA を使用して中間データのすべて、または多くをオンチップメモリに格納することで処理時間や消費電力を削減する効果があります。
ここでタスク 2 にあるループ処理はループ内を並列化することでループ回数を削減して処理時間を短縮できる可能性があります。以下はループの処理時間を例えば10倍高速にする簡単な例です。ループ内の並列処理数を増やすほど処理時間を短縮できますが、並列化のために回路規模が増えるので並列数をどれくらいにするかは全体を見て判断する必要があります。
この例ではタスク 3 とタスク 6 を完了してタスク 7 を開始するまでに中間データが準備できれば十分で、それよりあまり早く完了する必要はなさそうです。なお、このようにループ内の処理を並列化して高速化する手法は一般に「ループ展開」とか「ループアンロール」と言いますのでついでに覚えておきましょう。

異なるビット幅に柔軟に対応できる
DSP を16ビット、8ビット、4ビットの演算に効率よく使用することもできますし、プログラマブルロジックを使用することで 2 ビット演算でも 1 ビット演算でも容易に実現できます。
このことは革新の速度が速いディープラーニングの最新のアーキテクチャを効率よく実現するためにはとても有利です。また、すでに触れたとおり、ビット幅を可変に構成できるオンチップメモリをレジスタの様に使用すれば、幅の広いデータを効率よく処理することも可能です。
周辺機能の一体化
周辺機能を一体化してデバイス内に取り込むことができる点も FPGA の特徴です。周辺機能を取り込むことによってデバイス間のデータ転送で生じる遅延時間や消費電力を削減することができます。製品の小型化にも有効です。
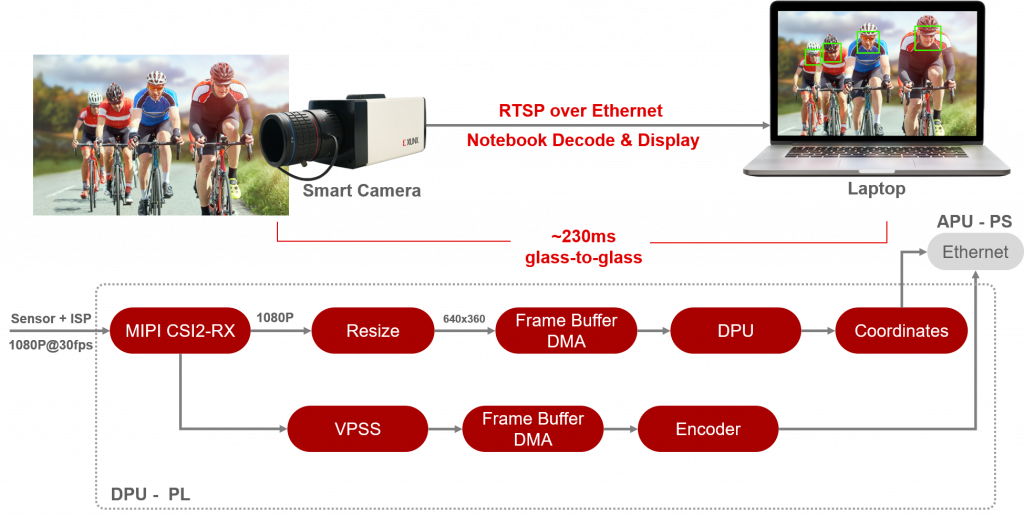
以下は周辺機能を取り込んだ組込み製品とデータセンターの事例です。さまざまな機能を一つのデバイスで実現したスマートカメラはスマートシティのインフラの一部として、車載向けには ADAS 機能として社会に貢献している事例が数多くあります。ネットワーク処理、演算、アクションなどを一体して遅延時間を削減、かつ安定させることで、金融の世界でも FPGA は有効に活用されています。

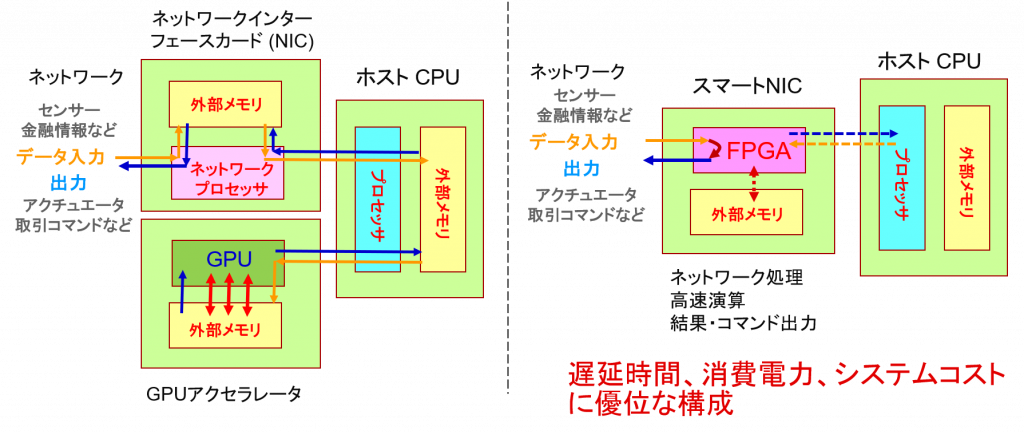
標準的機能のハードマクロ化
FPGA が商用で利用され始めたころは搭載できるロジックも小規模でしたが、それでもいろいろなロジックを一つのプログラマブルデバイスに集積できることで活躍していました。半導体技術が大きく進歩を遂げるとともに、より多くの機能を搭載したいという要求にこたえて進化を続けてきました。
各ユーザがプログラマブル領域を使用して実現している共通の機能は、だんだんとシリコンにハードマクロとしてあらかじめ搭載して製品化するようになりました。例えば PCIe コントローラ、メモリコントローラ、イーサネット MAC など多くのユーザが利用する機能はプログラマブルロジックを使用せずハードマクロで予めシリコン上に準備することによって消費電力を低減する効果があります。
また、設計者はより多くの時間やプログラマブルロジック部のリソースをユーザ固有の機能を実現するために利用できるようになりました。この点については、最終回で今後の展望として少し詳しく見てみたいと思います。
ここまで説明した FPGA のもたらすメリットとその理由を読んで、このように思われた方もいらっしゃるのではないかと思います。「そんなに良いものならもっと多くの製品やサービスを FPGA を使って構築したほうが良いソリューションができるのではないか?」 そう、その通りなんです!一社でも、ひとりでも多くのかたに FPGA がもたらすメリットを享受いただくことが、このブログの大事なミッションと考えています。
FPGA を使って開発したい !
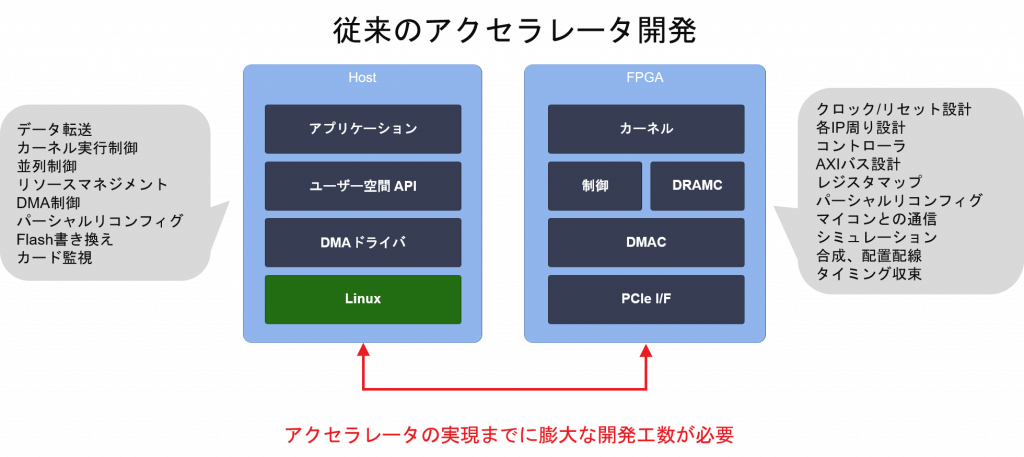
FPGA のメリットを理解しても、なかなか踏み出すことができない。できなかった要因はいくつかあると思います。
そこでこのような障壁を解消するために長年にわたる経験とノウハウを生かして構築された開発環境として Vitis (“バイティス”と読みます) そして Vitis-AI が登場しました。
今までの課題と Vitis によるアプローチを表にしてみました。このような課題への解決策を提供する Vitis について次回詳しく解説したいと思います。

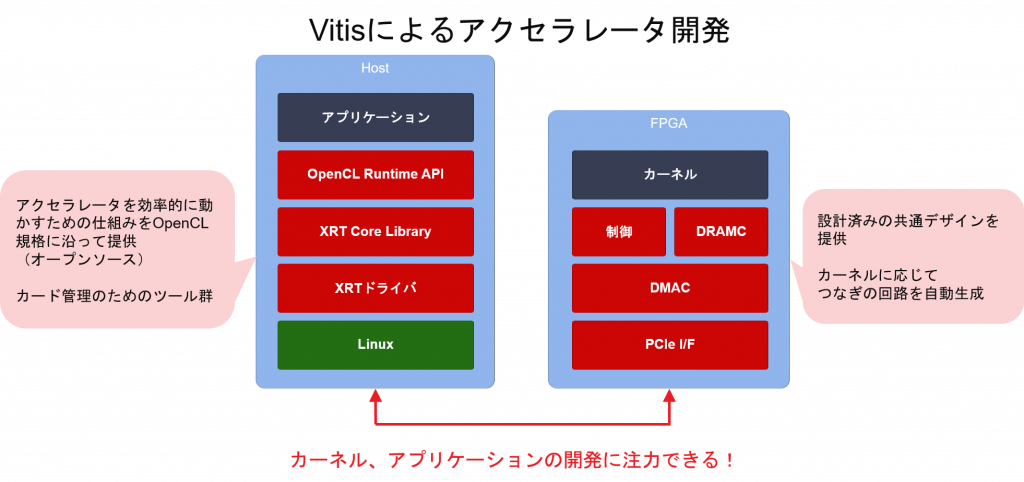
まとめ
今回は FPGA を活用することで低遅延、高スループット、低消費電力を実現できるしくみについて解説しました。そしてそのようなメリットをより多くのかたに享受いただくための開発環境として Vitis が登場したことをお話ししました。
第3回目となる次回は Vitis を無料で試しいただく手順を含め、解説します。第4回には Vitis-AI を無料で試していただく手順を含めて詳しい解説を予定しています。
ザイリンクス株式会社
堀江義弘