
本コースでは、複数の FPGA を用いた計算機システムの構成と、私達が研究開発が行っているカスタム・コンピューティング・システムについて紹介していきます。
第2回では、いろいろな FPGA 接続ネットワークについて紹介していきます。
20年前から研究されている FPGA 直結ネットワーク
以前より、複数の FPGA を直結する研究開発は行われています。
2000年代には、 FPGA のチップを独自のバスで直結する研究が盛んに行われていました。例えば、英 Imperial College London の CUBE や 米 California 大学 Barclay 校の BEE2, 米 North Carolina 大 Charlotte 校の RCC project, Edinburgh 大の Maxwell, 慶応大/JAXA の FLOPS-2D などがあります。
研究目的は、単体の FPGA には収まりきらない、より大規模な数値シミュレーションなどの計算を行うためでした。FPGA 同士は独自のバスで直結され、レイテンシの面で有利だったようです。しかし、独自バスの設計や検証、その上で実際の計算を行うまでの全体の生産性が低いという問題がありました。
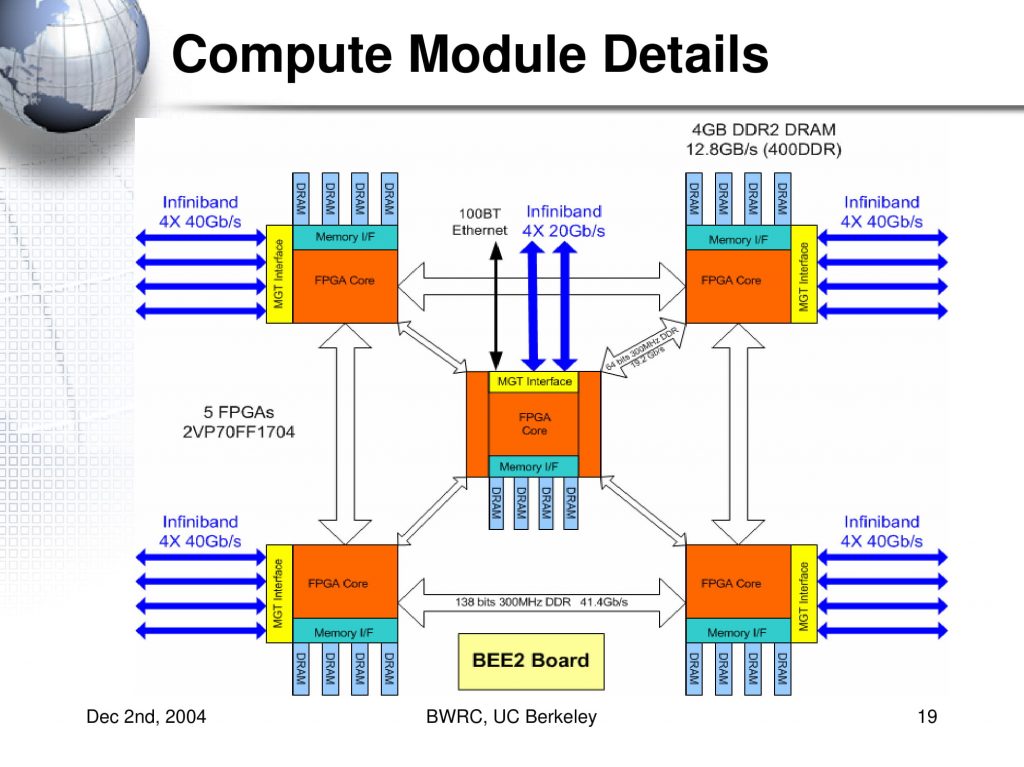
出典:From BEE to BEE2 Development of Supercomputer-in-a-Box, 2004
産業界でも、ASIC のシミュレーションの高速化を目的として、複数の FPGA を直結したシステムが開発されていると聞きます。
この目的に近いものとして、東京工業大学の ScalableCore System が挙げられます。
ScalableCore System は Xilinx 社の Spartan-6 を128枚直結したシステムで、メニーコア CPU の HW シミュレータとして研究されていました。
近年の FPGA 直結システム
2010年代後半からは、高性能計算を目的として数十枚の FPGA を直結する研究開発が行われています。
今回は以下の4つのシステムの FPGA 直結ネットワークについて見ていきたいと思います。
- 日 筑波大学のスーパーコンピューター Cygnus
- 独 Paderborn 大学の Noctua
- 米 Boston 大学を中心とした Novo-G #
- 米 Microsoft 社の Project Catapult
それぞれ、接続したい FPGA 枚数やトポロジ、レイテンシに加えて、利便性など、どこをポイントにするかによって、プロトコルやネットワークの構成が変わってきます。
大きく分けて、以下の3つの方式に分けられます。
- 直結網 + スイッチ:Noctua, Novo-G #
- 直結網 + ルーター:Cygnus, Novo-G #
- 間接網 ( Etheret プロトコル ) + パケットスイッチ:Noctua, Project Catapult, Novo-G #
ここで述べるスイッチとは、電気的に転送経路を変更するもので、送信元から送信先へ直接データを送る方式です。ルーターとは、いくつかの FPGA を中継して、送信元から送信先の FPGA へデータを送る方式です。パケットスイッチは、パケットの情報から行き先を決定する方式です。
それでは、それぞれのシステムの直結ネットワークについて見ていきましょう。
日 筑波大学, 計算科学研究センター スーパーコンピューター, Cygnus (Albireo ノード)
筑波大学 計算科学研究センターのスーパーコンピューター Cygnus の Albireo ノード は、CPU と GPU に加え、FPGA を搭載したヘテロジニアス構成のシステムです。スーパーコンピュータでも使われ始めた FPGA (3) – ACRi Blogでは、ネットワーク構成について解説があります。
ここでは、小林らの論文から独自のネットワーク方式、Communication Integrated Reconfigurable CompUting System (CIRCUS) について詳細を見ていきます。
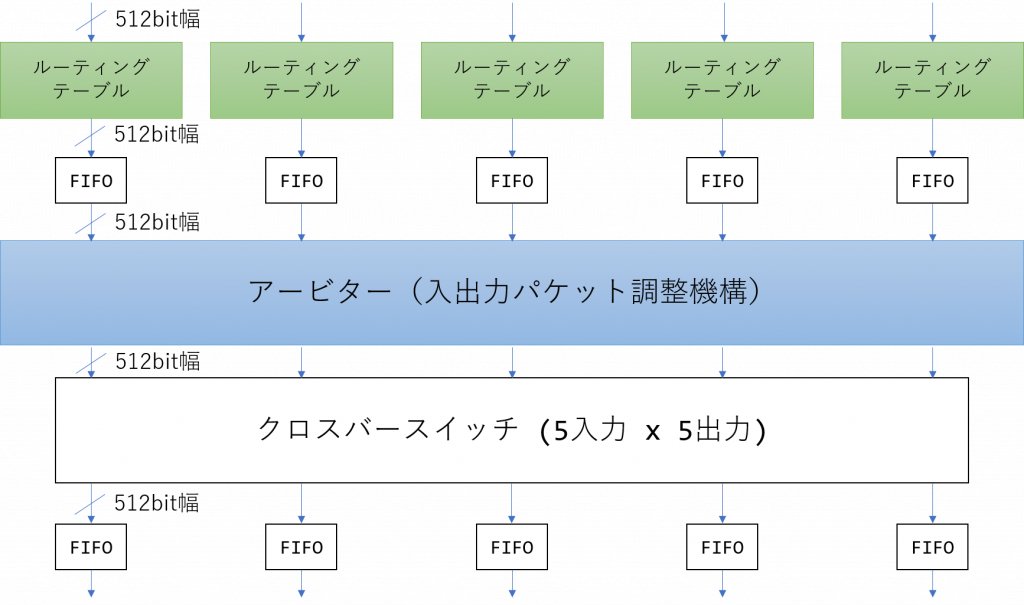
出典:論文を元に著者作成
CIRCUS は、最大で 64 台の FPGA を結合することができ、Mesh や Torus といったトポロジが構成可能です。通信のデータリンク層に Intel 社の直結通信プロトコル SerialLite III (SL3) を用い、外部のスイッチは用いていません。また、SL3 プロトコルに加え、上の図に示す様な独自のルーター機構を開発することで、間接的に他の FPGA への通信を実現しています。
実効バンド幅は 98.3Gbps (0.384 [GHz] × 256 [bit]) であり、隣接通信 (a ping-pong 通信) は 0.5 [us] と非常に低いレイテンシを実現しています。また、1つの FPGA を通過するのに約 250 [ns] が必要と述べられています。
独 Paderborn 大学, Paderborn Center for Parallel Computing (PC²), Noctua
独 Paderborn 大学 Paderborn Center for Parallel Computing (PC²) のスーパーコンピューター Noctua は、CPU と FPGA を搭載したヘテロジニアス構成のシステムです。各 FPGA は、4つの 40Gbps QSFP ポートを持ち、それぞれが光ファイバによって直結されています。
論文などでネットワーク構成が公開されていないのですが、以下の全光スイッチが使用されており、非常に面白いネットワーク構成となっています。
Noctua に利用されている光スイッチは、米 CALIENT Technologies 社の S320 – Optical Circuit Switch が利用されています。S320 は、入力ポートから入って来た光信号を、ミラーに当てて屈折させ、目的の出力先のポートに返します。ミラーは MEMS 技術により物理的に角度を変えて、反射させる方向を変更することで、任意のスイッチングを実現しています。
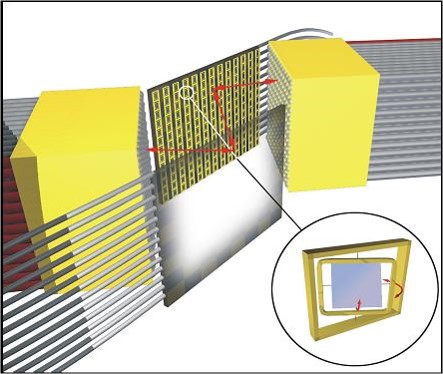
3D MEMS 技術を用いてミラーの向きを変え、入力と出力の接続関係を変更する。
出典:光回線L1スイッチソリューション「Sシリーズ」 東陽テクニカ “はかる”技術で未来を創る 情報通信
また、以下のユーザーガイド (Noctua FPGA Usage, Integration and Development – PC2 Doc) から、ルーターなどの機構はなく、物理的に存在する4つポートを別のポートと光スイッチを介して直結するようです。ユーザーは、計算ジョブの投入時にネットワークの設定を記述するようです。
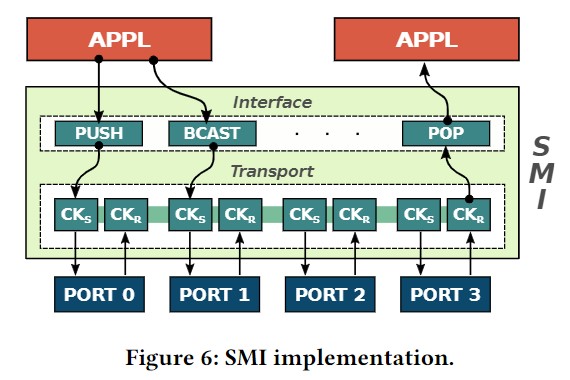
出典:Streaming Message Interface: High-Performance DistributedMemory Programming on Reconfigurable Hardware, SC19
また、T.D.Matteis らの論文 (Streaming Message Interface: High-Performance Distributed Memory Programming on Reconfigurable Hardware – SC19, 著者論文, スライド) では、 Noctua 上でデータ通信の研究を行っており、目的はどんなトポロジにも対応でき、大規模な構成も実現できること、とあります。その上で、”Streaming Message Interface” と呼ばれる、トランスポート層でのパケットスイッチングの方式を提案しています。
スイッチング経路は、アプリケーションの実行前に書き込まれ、その情報を元に実行時にパケットがスイッチされる形です。パケットスイッチングの情報が必要なため、データの理論バンド幅は 40Gbps から 35Gbps に減少してしまいます。
実効バンド幅は 31.85Gbps (35Gbps の 91%) であり、隣接通信 (a ping-pong通信) は 0.801 [us] と十分に低いレイテンシを実現しています。
米 Boston 大学, 大規模 FPGA セントリッククラスター, Novo-G#
米 Boston 大学が中心となって研究開発が行われている大規模 FPGA セントリッククラスター Novo-G# は、CPU と FPGA を搭載したヘテロジニアス構成のシステムです。
A.D.George らの論文 (Novo-G#: Large-scale reconfigurable computing with direct and programmable interconnects) によれば、フリーの直結通信プロトコル Interlaken を用いて、テーブルベースのルーティング、仮想チャネルスイッチを実現しています。主たる目的は、分子動力学法のシミュレーションの高速化であり、Stratix V を利用して最大 64ノード (4 × 4 × 4 の Torus トポロジ) の構成が可能です。これを実現するために、以下のテーブルベースのルーティングを採用しています。
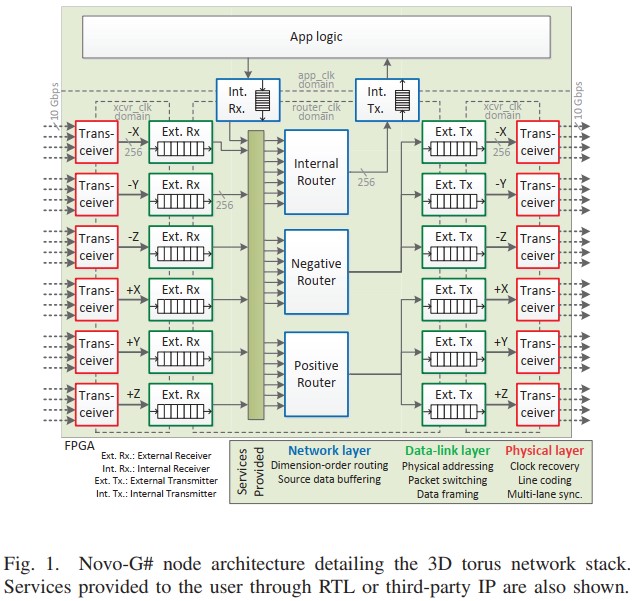
上の図は3つのルーターを実装した場合の例で、図中の青い四角 “Internal Router”, “Negative Router”, “Positive Router” の3つがそれに当たります。ルーター内のルーティング情報は、アプリケーションの実行前に書き込まれ、その情報を元に実行時にパケットがルーティングされる形です。
“App Logic” から来た入力データはパケット化され、”Int. Rx.” FIFO に格納されます。また、 “Transceiver” からのデータはストリームとして、”Ext. Rx.” FIFO へ格納されます。FIFO 内のデータは、3つのルーターのどれかに入力され、所定の出力ポートへと送信されます。
論文中では、具体例として、3次元 Torus トポロジのための次元順ルーティングが例示されています。
別の論文 (High Performance Dynamic Communication on Reconfigurable Clusters, FCCM 2018, Novo-G#: a multidimensional torus-based reconfigurable cluster for molecular dynamics) では、ワイヤのみのレイテンシを 176.8ns としています。実効バンド幅の記載はありませんが、CUBE 通信パターンをシミュレーションしたところ隣接する FPGA へのレイテンシが 0.87[us] 程度であると述べられています。
Novo-G# は全ての方式に対応しているようですが、直結網 + ルーター方式以外は、実データが不明でした。
米 Mirosoft 社, データセンター用 FPGA 搭載システム, Project Catapult, Project BrainWave
米 Microsoft 社の Project Catapult は、実際の大規模なデータセンターに FPGA を導入し、処理の高速化だけでなく商業的な点でも大きな効果を挙げたことで有名です。Catapult は FPGA を搭載したデータセンター用のサーバで、上記の3つの FPGA 搭載システムとは少し目的が異なります。
主な対象アプリケーションとしては、Bing の検索やレコメンデーションエンジンから始まり、現在は深層学習 (Project BrainWave) となっています。
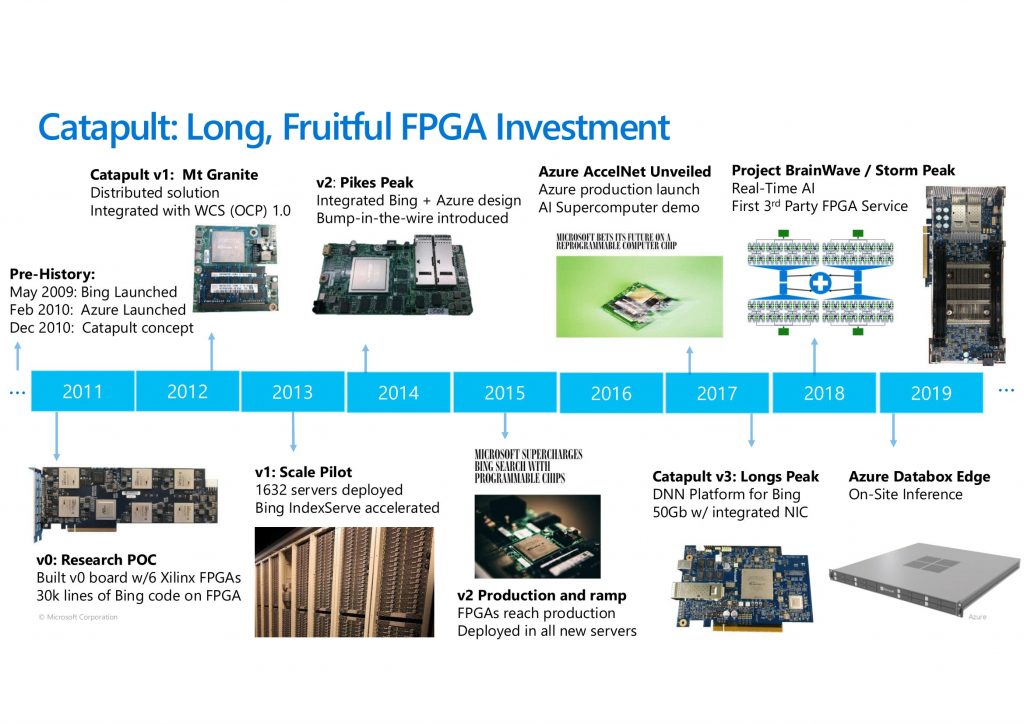
出典:Heterogeneous Computing @ Microsoft, Fast Machine Learning 2019
Catapult v1
ISCA 2014の論文 (A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA 2014, 論文) で解説が行われています。
Stratix V D5 FPGA を搭載した独自ボードで、 CPU からは PCIe Gen3 x8 のアクセラレータカードとして利用されます。このため、CPU 側のグローバルのネットワークとは切り離されています。各 FPGA は、4 つの SL3 ポートを持ち、それぞれが片方向 10 Gbps で通信が可能です。FPGA 間通信には Intel 社の SL3 プロトコルを利用し、6 x 8 の Torus トポロジが構成可能で、ルーターやスイッチは利用されていません。
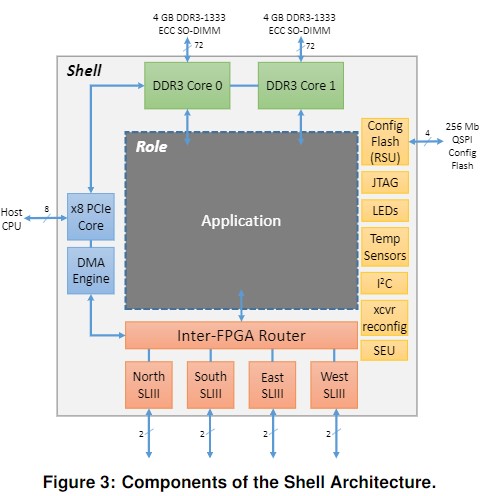
出典:A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA 2014
Doug Burger 氏の講義ビデオによれば、この方式は “An Elastic Reconfigurable Fabric” と呼ばれています。
複数の FPGA が SL3 を介して直接接続され、大きなパイプラインを形成します。ホスト CPU が PCIe で入力データを送ると、このパイプラインが自律的に処理を行い、出力データをホスト CPU に返します。
SL3 の理論バンド幅は 2Gbps で、1つの FPGA を通過するのに約 400 [ns] 必要と述べられています。実効バンド幅の記載はありませんが、隣接通信 (a ping-pong通信) は約 1 [us] と後述の論文にあります。
Catapult v2
MICRO 2016 (A cloud-scale acceleration architecture, MICRO 2016, 論文) で解説が行われています。Stratix V を搭載した FPGA カードで、コードネームはメザニンカード版が “Pikes Peak”、PCIe 版が “Story Peak” です。v2 と v1 の大きな違いは、v2 では Ethernet プロトコルを直接利用可能になったことと、 ネットワークが CPU と共有になったことです。これは、接続したい FPGA の枚数が増えたためだと考えられます。
v1 の直結方式では、48 FPGA までは非常に低いレイテンシで通信できますが、それ以上の FPGA は一旦 CPU 側のネットワークを介する必要があるからです。
v2 の Ethernet プロトコルと後述のパケットスイッチング方式を組み合わせることで、接続したい枚数が増えた場合に通信レイテンシを低く抑えることができるようです。
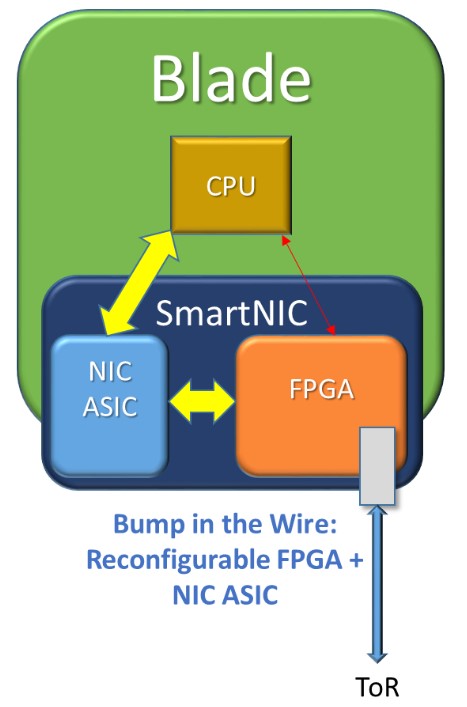
特徴的なのは、下の図のように、CPU がネットワークにアクセスするには、”Bump in the Wire” 方式と呼ばれる、必ず FPGA を介さないといけない形になっています。この方式を取ることで、 以下の 3 種類の役割が持たせられるとしています。
- 単体サーバのアクセラレータ
- ネットワークやストレージのアクセラレータ
- 複数サーバのアクセラレータ
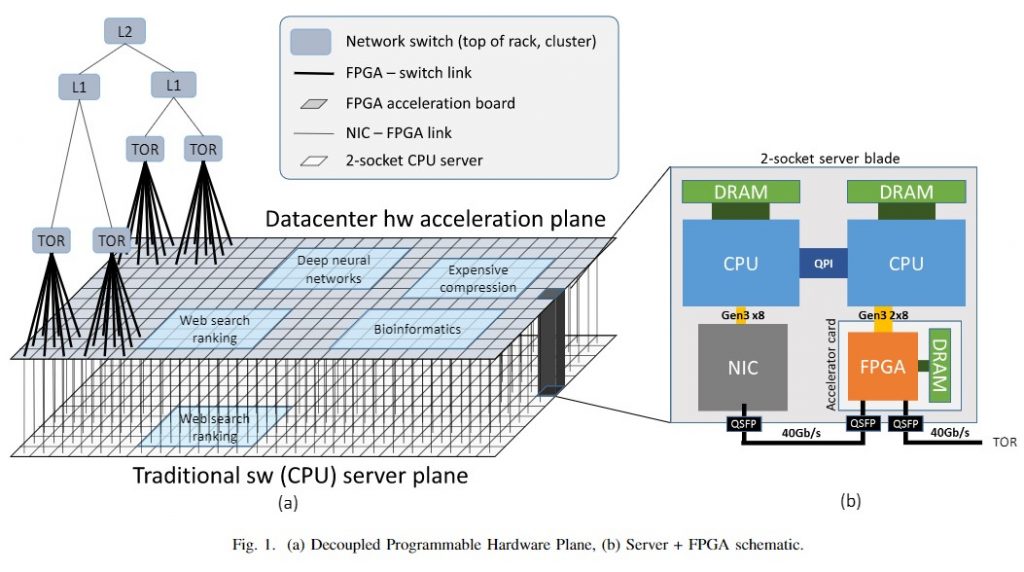
出典:A cloud-scale acceleration architecture, MICRO 2016
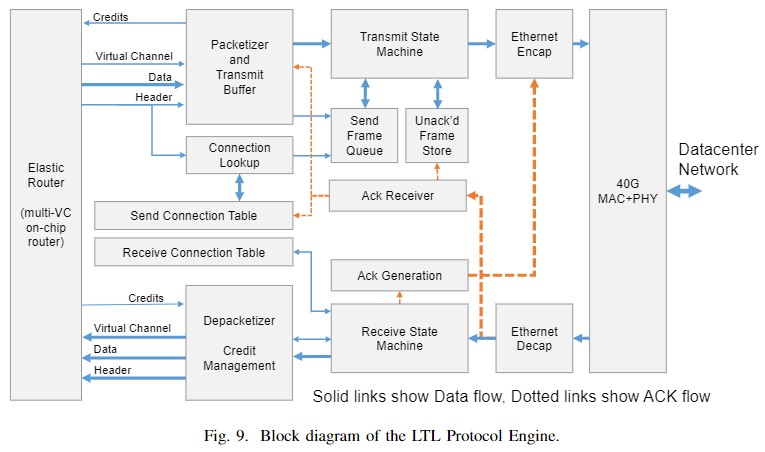
出典:A cloud-scale acceleration architecture, MICRO 2016
新たに FPGA 間の通信に利用される独自プロトコル “Lightweight Transport Layer (LTL)” が導入されています。LTL は、UDP パケットに行き先の FPGA の情報を組み込む、パケットスイッチング形式です。優れている点は、ACK/NACK ベースのパケット再送機能を持つことです。
送信されるパケットはバッファリングされ、受信先から ACK が戻ってくるのを待ちます。もし、パケットのリオーダリングが発生した場合、NACK が返され、そのパケットは即座に再送されます。これに加え、優先度付きのフローコントロールや DC-QCN 方式の輻輳制御にも対応していると述べられています。
実効バンド幅の記載はありませんが、同じスイッチに接続された FPGA 同士での隣接通信 (a ping-pong通信) は約 2.88 [us] と後述の論文にあります。これは、v1 の Torus のワーストケースの値である約 7 [us] よりも良い値であり、10万台以上の FPGA を接続しても 23.5 [μs] 以下で通信が可能です。
Catapult v3, 2017
Catapult v3 は USENIX の論文 (Azure accelerated networking: SmartNICs in the public cloud, 著者論文) にソフトウェア層の解説があるのですが、ハードウェアとしての情報はうまく見つけられませんでした。
大きな変更は、CPU との接続方式が Cataput v2 よりスマートになっており、SR-IOV などの高度な仮想化に対応している点です。Catapult v3 は Arria 10 を搭載した FPGA カードで、コードネームはメザニンカード版が “Dragontail Peak”、PCIe 版が “Longs Peak” です。Arria 10に加えて、50Gbps 通信に対応したNICである、米 Mellanox 社の ConnectX-3 Pro を搭載しています。ConnectX-3 Pro を搭載することで、上記の論文にある様な、Smart NIC としての機能を提供しているようです。
出典:Heterogeneous Computing @ Microsoft, Fast Machine Learning 2019
また、この頃から、対象のアプリケーションに深層学習が入り、後継のプロジェクトとして、Project BrainWave が始まったようです。
Catapult v2 と v3 に搭載されている Stratix V と Arria10 FPGA での学習用アーキテクチャなどの提案が、ISCA 2018 (A Configurable Cloud-Scale DNN Processor for Real-Time AI, ISCA2018, 著者論文, スライド) で公開されています。この論文では、Float16 形式の行列積演算器とそれに対応した命令セットが提案され、性能評価が行われています。こちらの記事にも同様の解説があります。
Project BrainWave
Project BrainWave は Catapult に代わる Microsoft 社のプロジェクトです。プロジェクト自体は、深層学習のアルゴリズムの開発なども含まれるものに統合されたと思われます。
ほとんど公開情報がないため不明な部分が多いですが、Heterogeneous Computing @ Microsoft”, Fast Machine Learning, Sep 11, 2019 には、”First 3rdParty FPGA Service” とあり、他社のボードを採用しているようです。写真からすると、Intel 社の Stratix 10 ボードではないかと思います。
2020年 6月に Intel 社から「AI 向け FPGA」Stratix 10 NX FPGA がアナウンス (Intel® Stratix® 10 NX FPGA, Intel has just announced its first AI-optimized FPGA – the Intel® Stratix® 10 NX FPGA – to address the rapid increase in AI model complexity – Programmable Logic) され、Microsoft 社も歓迎のコメントをするなど非常に緊密な関係のようです。また、コードネームは “Storm Peak” の1種類だけのようです。
Project BrainWave に利用されている FPGA やその直結ネットワークも今後、論文などで発表が行われるでしょう。
まとめ
今回は、2010年代後半の大規模な FPGA 直結ネットワークについて、4つの具体例を詳しくみていきました。接続したい FPGA の枚数やトポロジ、レイテンシに加えて、利便性などから、3つの方式に分けられることも示しました。
次回は、FPGA のネットワーク部分だけではなく、FPGA を搭載したヘテロジニアスシステムとして分類などを行っていきます。
理化学研究所 計算科学研究センター (R-CCS) プロセッサ研究チーム
特別研究員 宮島敬明
チームリーダー 佐野健太郎