
このコースでは、スーパーコンピュータ (以下、ブログの文字数節約のために一般的に使われている略称「スパコン」を使います) にも FPGA が何故使われ始めたのか、FPGA をスパコンに使うことによって何ができるようになるのか、どのような技術的な面白さがあるのか等について紹介していきます。
第3回のこの記事では、FPGA を導入したスパコンについて紹介していきます。
その名は「Cygnus」
Cygnus は、本記事の執筆時点において国内で唯一、FPGA を本格的に使用するスパコンです。お気づきかもしれませんが、ブログコースのアイキャッチ画像が Cygnus の筐体を写したものでした。それでは、Cygnus について詳しく紹介していきます。ちなみに、Cygnus の紹介ムービーが YouTube にアップロードされていますので、興味のある方は是非ご覧ください。
どこで運用されているのか
Cygnus は、日本電気株式会社 (NEC) により、筑波大学計算科学研究センター (茨城県つくば市) に2019年3月末に導入されました。計算科学研究センター (CCS) では、長年に渡りスパコンの研究開発を続けており、Cygnus は CCS 独自開発の第10世代スパコンです。CCS 歴代のスパコンに興味がある方はこちらを参照してください。

設計コンセプト
前回の記事では、スパコンのアクセラレータとして用いられる GPU の問題点をカバーし得る FPGA の特性について書きました。そのため「じゃあ、アクセラレータを全て FPGA にすれば良いではないか」と思うかもしれません。が、話はそう単純ではありません。
まず、FPGA の演算性能 (FLOPS) およびメモリバンド幅の絶対性能は GPU に及びません。例えば、Intel Stratix 10 FPGAの単精度の FLOPS 値は最大 10TFLOPS (まずそんな性能は出ませんが) と言われていますが、PCIe 接続の NVIDIA Tesla V100 GPU の単精度の FLOPS 値は最大 14TFLOPSです。特にメモリバンド幅では、例えば Intel Stratix10 を搭載した 520N FPGA カードのピークメモリバンド幅は 76.8 GB/s ですが、PCIe 接続の NVIDIA Tesla V100 GPU では 900 GB/s です。すなわちメモリバンド幅に関しては11.7倍もの差があります。これは、FPGA の外部メモリが DDR4 であるのに対して、GPU ではより進んだ DRAM 技術である HBM2 を採用していることに起因しています。しかし最近では、HBM2 を採用した FPGA ボードがリリースされてきていますので、この性能差は改善されるのではないかと筆者は期待しています。
次に、高位合成が普及し始めて FPGA の開発環境が改善されたと言っても、効率的な開発をサポートするための数値計算ライブラリ・機械学習ライブラリやプロファイラを含んだデバッグツールを提供している CUDA 環境と比べると、まだまだ発展途上と言わざるを得ません。また、プログラミング言語、例えば OpenCL で FPGA を利用する場合でも、FPGA の性能を最大限に引き出すためには、FPGA のアーキテクチャに適したコード (字面は OpenCL だけど、ほとんどレジスタ転送レベルのようなコード) を記述する必要があるため、開発コストは決して低い訳ではありません。
下に、CPU、GPU、FPGA の特性をまとめた表を示します。CPU は、FLOPS 値に関しては GPU に比べていまひとつですが、HPC 向けインターコネクト (例: InfiniBand) を用いた高速通信をサポートしています。また、プログラミングのし易さについては、GPU および FPGA よりも優れているのは言わずもがなです。GPU と FPGA の演算、通信、プログラミングのし易さについては、これまでの記事で述べてきた各デバイスの特性を表に当てはめてみました。

つまり、重要となってくるのは、アプリケーションの特性に基づいて,CPU、GPU、FPGA を適材適所的に利用する、ということです。このことを踏まえて、CCSではAccelerator in Switch (AiS) と呼ばれるコンセプトを提唱しています。下の図はそのコンセプトの概要です。
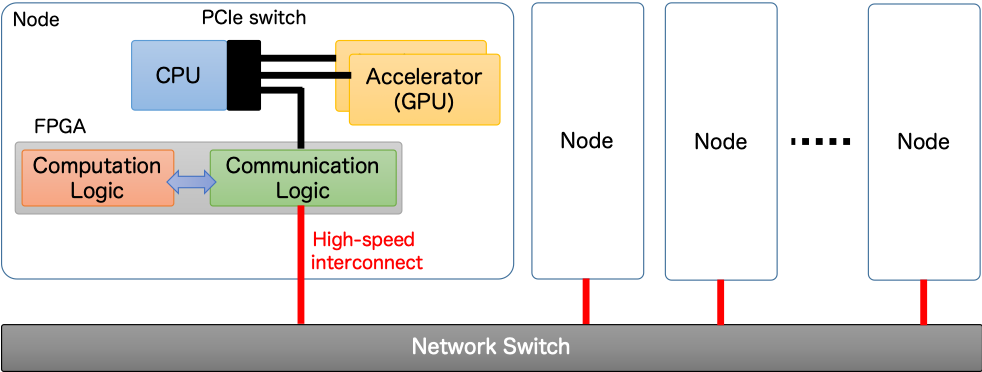
このコンセプトでは、GPU にとって不得手な演算部分のオフロードおよび高速ノード間通信処理に FPGA を適用します。すなわち、GPU と FPGA とを相補的に活用することで、CPU-GPU クラスタ構成である現在の HPC システムの性能を更に向上させることを見据えています。このコンセプトに基づく並列処理モデルを「多重複合演算加速計算 (Multi-hybrid Accelerated Computing)」と呼び、Cygnus はこのコンセプトの実証システムとして開発されました。
ハードウェア構成

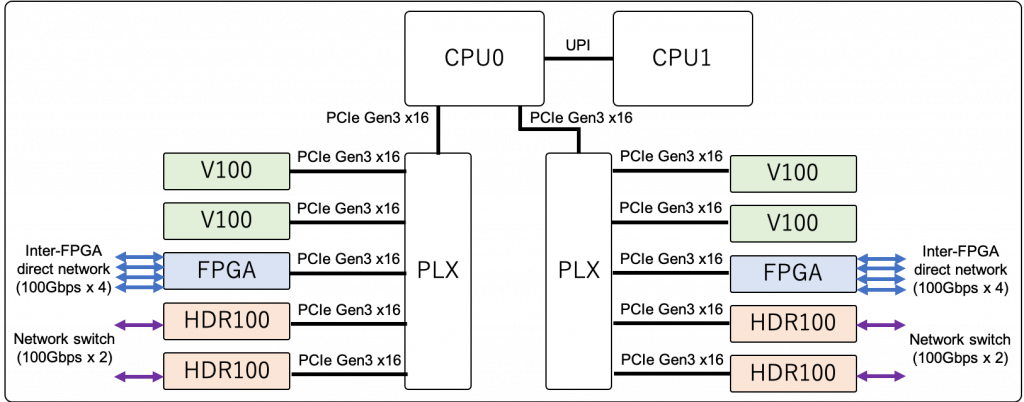
上の表が Cygnus のハードウェア構成です。Cygnus は、GPU 搭載ノードである「Deneb ノード」と、GPU・FPGA 搭載ノードである「Albireo ノード」の2種類の計算ノードからなるクラスタ型スパコンです。どちらのタイプのノードにも米インテル社製の最新 CPU を2基と米エヌビディア社製の最新 GPU を4基搭載し、Albireo ノードには、これらに加えて米インテル社製の最新 FPGA を2基搭載します [1]。
下の図は Albireo ノードのブロックダイアグラムです。GPU・FPGA は PLX と呼ばれる PCIe スイッチを介して接続されています。CPU0 に寄せた構成としているのは、演算のメインに GPU および FPGA を積極的に活用し、両デバイスで動作する計算カーネルの起動およびデバイス間の調停に CPU を用いるという AiS コンセプトを反映しているためです。先述したように、Albireo ノードには FPGA ボード (BittWare 520N) が2基搭載されており、各 FPGA ボードからは4本の 100Gbps の FPGA 間直結リンクが出ています。なお、Deneb ノードのブロックダイアグラムは、Albireo ノードから FPGA を除いたものとなっています。
それでは、Cygnus の理論ピーク性能 (倍精度) はどのくらいでしょうか。まず、ノードあたりの CPU 部、GPU 部のピーク性能を算出してみましょう。
CPU の倍精度の理論ピーク性能は、動作周波数と1クロックあたりの演算数の積で求めることができます。Intel Xeon Gold 6126 の製品仕様から、動作周波数は 2.60GHz (ベース動作周波数) なので、1クロックあたりの演算数が分かれば、CPU の理論ピーク性能を求めることができます。最新の CPU では Fused Multiply Add (FMA) 命令がハードウェアサポートされているので、1クロックで2回の浮動小数点演算 (乗算・加算) を実行できます。また、Intel Xeon Gold 6126 は FMA 演算器が2つあるため、1クロックで 4 = 2 (FMA 命令) × 2 (FMA 演算器の数) 回の浮動小数点演算を実行できます。さらに、Intel AVX-512 命令をサポートしているため、8 (512bit / 64bit) 個の double 型のデータに対して、これらの演算処理を同時に適用させることができます。これらより、1クロックあたりの演算数は
2 (FMA 命令) × 2 (FMA 演算器の数) × 8 (Intel AVX-512 命令で同時処理できるデータ数) × 12 (コア数) = 384
となります。 したがって、Intel Xeon Gold 6126 の理論ピーク性能は 2.60 GHz × 384 = 998.4 GFLOPS となり、1ノードに CPU は2基搭載されているので、ノードあたりの CPU 部の理論ピーク性能は、2 TFLOPS ≅ 998.4 GFLOPS × 2 CPU となります。
一方、GPU の倍精度理論ピーク性能は 7 TFLOPS ≅ 1.53GHz (ターボクロック) × 2 (FMA 命令) × 2560 (倍精度 CUDA コア数) なので、ノードあたりの CPU 部の理論ピーク性能は 28 = 7 TFLOPS × 4 GPU となります。
したがって、1ノードあたりのピーク性能は CPU 部と GPU 部との理論ピーク性能の和である 30 TFLOPS となり、Cygnus のノード数は81であることから、Cygnus の理論ピーク性能は 2.43 PFLOPS = 30 TFLOPS × 81 (ノード数) となります。
この理論ピーク性能は、記事を執筆している時点で国内最速の産業技術総合研究所のスパコン「ABCI」のおよそ10分の1であり、TOP500ランキングの上位に食い込めるものではありません。Cygnus は性能で勝負するというよりも、「将来の計算機の設計思想に挑戦する」ことに重きをおいたスパコンなのです。
ネットワーク構成
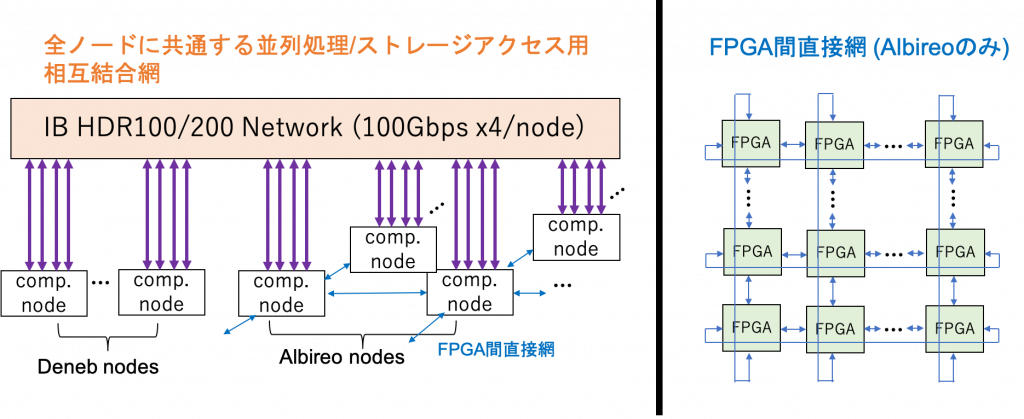
Cygnus は、全ノードを InfiniBand で接続するネットワークと FPGA 間を2次元トーラス状に直接接続したネットワークの2種類のネットワークを持っています。
左の方の全ノード共通の並列処理ネットワークが InfiniBand による通常のネットワーク (ノード・スイッチ間は HDR100、スイッチ・スイッチ間は HDR200 で接続) で、MPI のような通信ライブラリを用いた並列処理が可能です。CPU および GPU の通信に用いますが、FPGA からの CPU を介した通信も可能です。また、このネットワークはフルバイセクションバンド幅を持ちます。
フルバイセクションバンド幅を持つネットワークについて、Google 先生に聞くと以下のページを目にすると思います。
フルバイセクションバンド幅の構成とはクラスタ内の任意の半数のノードが同時に残り半分のノードにデータを送信してもネットワーク内での競合が発生しないネットワーク構成を意味します。
http://understeer.hatenablog.com/entry/2012/03/06/121726
まさにこの通りですが、「では、どのようなネットワーク構成だと競合が発生するのだろう?」と疑問に思うかもしれません。下の図に示した計算ノードの16台が4×4の2次元メッシュ状に接続されたネットワーク構成を例に簡単に説明します。
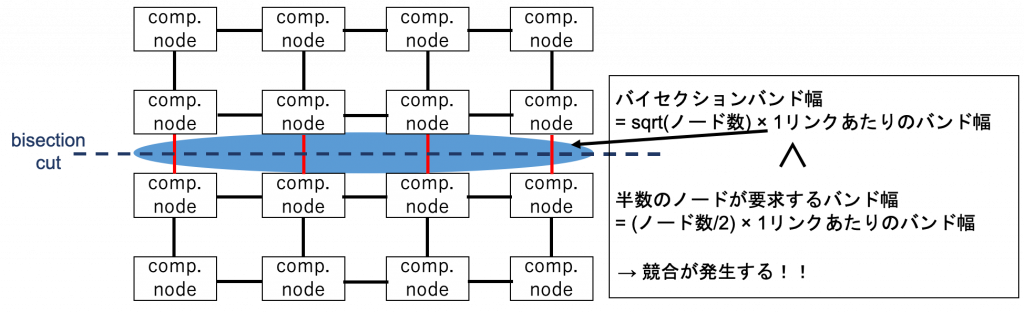
バイセクションバンド幅とは、ネットワークを均等に2分割したときの両者間のバンド幅です。図に示すような、N正方型の2次元メッシュネットワーク構成では、バイセクションバンド幅は sqrt(ノード数) × 1リンクあたりのバンド幅となります。一方、半数のノード数が要求するバンド幅は (ノード数/2) × 1リンクあたりのバンド幅です。そのため 4×4 の2次元メッシュネットワークでは、半数のノードが要求するバンド幅がバイセクションバンド幅を上回り、ネットワーク内で競合が発生します。すなわち、フルバイセクションバンド幅を持つネットワークとは、このような競合が起きないように構築されたネットワークということです。
右の方の FPGA 間の直接網は、Albireo ノードの64台の FPGA (2FPGA /ノード) をスイッチなしで 8×8 の2次元トーラス状に直接接続したネットワークです。バイセクションバンド幅は、sqrt (FPGAの数) × 1リンクのバンド幅 × 2 リンク (トーラスネットワークのため) ですが、フルバイセクションバンド幅を持つネットワークではありません。ですが、スイッチなしの直接接続のため、Ethernet プロトコルをサポートする必要がありません。また、ある FPGA から任意の FPGA にデータを転送するために、通信パケットをルーティングするハードウェアを FPGA に実装する必要はありますが、ルーティングハードウェアにある特定の演算を付加するというような FPGA ならではの最適化を施すことも可能です。このため、研究する上で非常に面白いネットワーク構成だと筆者は考えています。
おまけ: FPGA を導入した”国外”のスパコン
実は、Cygnus に先駆けて FPGA を本格使用しているスパコンが国外に存在します。2018年、ドイツのパーダーボルン大学に Cray 社が導入した Noctua です。
このスパコンの非常に興味深い点は、FPGA 間を光スイッチで接続していることです。光スイッチは、電気信号に変換することなく、光信号のまま特定の信号を分岐したり行き先を切り替えたりできます。これは、スイッチ内の鏡の向きを調整し、光を実際に反射させることで実現されます。光スイッチを用いるメリットとしては、光通信であるため通信性能が非常に高いところです。逆にデメリットは、スイッチの再設定には鏡の向きを調整しなければいけないためミリ秒オーダーのレイテンシがかかります (1台につき1,000万円以上するので非常に高価な点もデメリットです) 。
Noctua についてもっと詳しく知りたい方は、こちらに Noctua の情報が掲載されていますのでチェックしてみてください。また、SC18@ダラスでパーダーボルン大学の Christian 先生が Noctua について紹介している動画が YouTube にアップロードされていますので、そちらもご覧ください。
まとめ
本コースの第3回では、FPGA を導入した国内外のスパコンについて紹介しました。次回は、Cygnus を対象にどのような研究開発が行われているかについて紹介していきます。どうぞお楽しみに。
参考資料
[1] プレスリリース:新型スーパーコンピュータ「Cygnus」の運用を開始, https://www.ccs.tsukuba.ac.jp/press_cygnus_20190326/
筑波大学 計算科学研究センター 小林諒平