
ORB-SLAM とは
ホームサービスロボットや自動運転車が、家や工場内を自律移動する技術が活発に研究、開発されています。自律移動するには、家具や壁の配置を認識(地図作成)し、自分がどこにいるかを把握(自己位置推定)しなければなりません。これを同時に行うのが SLAM (Simultaneous Localization and Mapping) です。 SLAM には使用するセンサなどによっていくつか種類があります。主に LiDAR やステレオカメラ、単眼カメラなどが使われますが、 ORB-SLAM [1] は単眼カメラで実行する事が可能で、安価にシステムを構築できます。
ORB-SLAM ではカメラで撮影した1フレームの画像から、物体の端などのコーナー部分を特徴点として検出します。時間(フレーム)が進むにつれ2次元の画像中をどのように移動するか追跡し、その移動方向、移動距離から3次元空間での座標を計算します(地図作成)。そこから逆算して、3次元空間に配置された特徴点中のどこに自分がいるかを計算します(自己位置推定)。こちらのビデオが分かりやすいでしょう。

直進している場合は画面を放射状に移動する。
(画像はKITTIデータセット[2])

(画像はKITTIデータセット[2])
ORB-SLAM は C++ で書かれたオープンソースのソフトウェアで、 Github で公開されています。今回は ORB-SLAM を高位合成により FPGA 実装した事例を紹介します[3][4]。
開発環境
FPGA 開発環境は SDSoC を使用しました。 SDSoC は Xilinx の高位合成開発環境で、 C/C++ でプログラムを書くことができ、 CPU 上で動作するソフトウェアと FPGA 上で動作する回路を同時に開発することができます。ソフトウェア処理の重い部分を関数単位で指定して、 FPGA 回路に実装できます。動作確認には同じく Xilinx の ZCU102 を使用しました。
FPGA 化対象
ORB-SLAM は大きく TRACKING、LOCAL MAPPING、LOOP CLOSING の3つに分かれます。カメラで取得した画像は TRACKING の先頭部分である特徴点抽出処理 (ExtractORB) に入力され、右回りに処理が進みます。 TRACKING は画像が入力される度に動作しますが、 LOCAL MAPPING、LOOP CLOSING は動作頻度が落ちます。高頻度で動作して高負荷な処理を FPGA 化した方がメリットを享受できますので、TRACKING を対象としました。
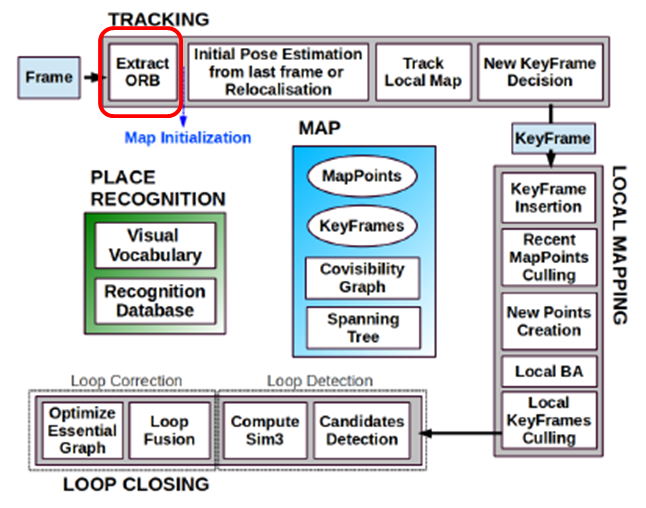
FPGA に実装できる回路規模にも上限がありますので、TRACKING 全体を FPGA 化することは出来ません。したがって、CPU で動作させたときの処理時間を処理ごとに計測しました。当然ながら処理時間の長い部分を FPGA 化すべきで、先頭部分の特徴点抽出処理が TRACKING の3割程度を占めていたため、これを FPGA 化対象としました。
FPGA(ハードウェア)指向の設計変更
なぜ設計変更が必要か
C++ で書かれたソフトウェアがあり、 C/C++ などの高級言語で FPGA 回路を書くことができる高位合成の開発環境があれば、ソフトウェアをそのまま FPGA 回路にすることができるように思えます。しかし実際はそれほど単純ではありません。 CPU と FPGA の動作原理の違いから、回路を合成できないこともありますし、合成できたとしても CPU より処理が遅くなってしまうこともあり得ます。
FPGA で処理を高速化するには、合成される回路を意識して、パイプライン化や並列化、メモリアクセスを効率的に行うことなど CPU で動かすソフトウェアとは異なる観点での設計が重要となります。動作原理の違いを考慮しなければ高速化は望めないでしょう。
この章では以下の流れで、全体の設計からコードレベルまで、設計変更について説明します。
- FPGA化部分全体のデータフロー設計について
- ある処理を例としたアルゴリズムの変更について
- 高位合成におけるC/C++言語仕様の制限について
1. 全体のデータフロー
特徴点抽出処理のデータフローは下図のようになっています。カメラから取得されたフレーム画像は、 1 倍、 1/1.2 倍、 1/1.2^2 倍、、、 と 1/1.2 倍ずつ縮小した 8 段階の画像を作成します。以降の各処理では、内部で 8 回ループしながら 8 枚の画像に対して同様に処理します。これによって、対象物との距離が変わり見た目の大きさが変化しても同一物と認識できるようになります。最後の特徴量計算ではぼかした画像を使用するため、8段階に縮小した画像に Gaussian Blur フィルタをかけた画像を作成して保持しておきます。

このデータフローをそのまま FPGA 化するには、メモリ使用量について以下 2 つの問題があります。
- Gaussian Blurでぼかした画像は最後の特徴量計算に使用するため、画像 8 枚分のメモリが必要となる。
- Oct-Tree 処理では画像データは使用せず次の角度計算では使用するため、 Oct-Tree処理を実行する間保持しておく、画像8枚分のメモリが必要となる。
FPGA 内でもデータを格納するメモリを確保することは可能ではありますが、ソフトウェアで使用するメモリ量とは比較にならない程少ないです。また、 FPGA での処理はパイプライン化して高速化しますが、これはベルトコンベアに画像データを 1 ピクセルずつ流していくようなイメージで、メモリに全てのデータを格納しておいてランダムアクセスしながら処理することは FPGA では非効率となりますので、そもそもその様な事はしません。その為、この部分は設計変更する必要があります。
これらを検討して作成した全体のデータフローが下図となります。
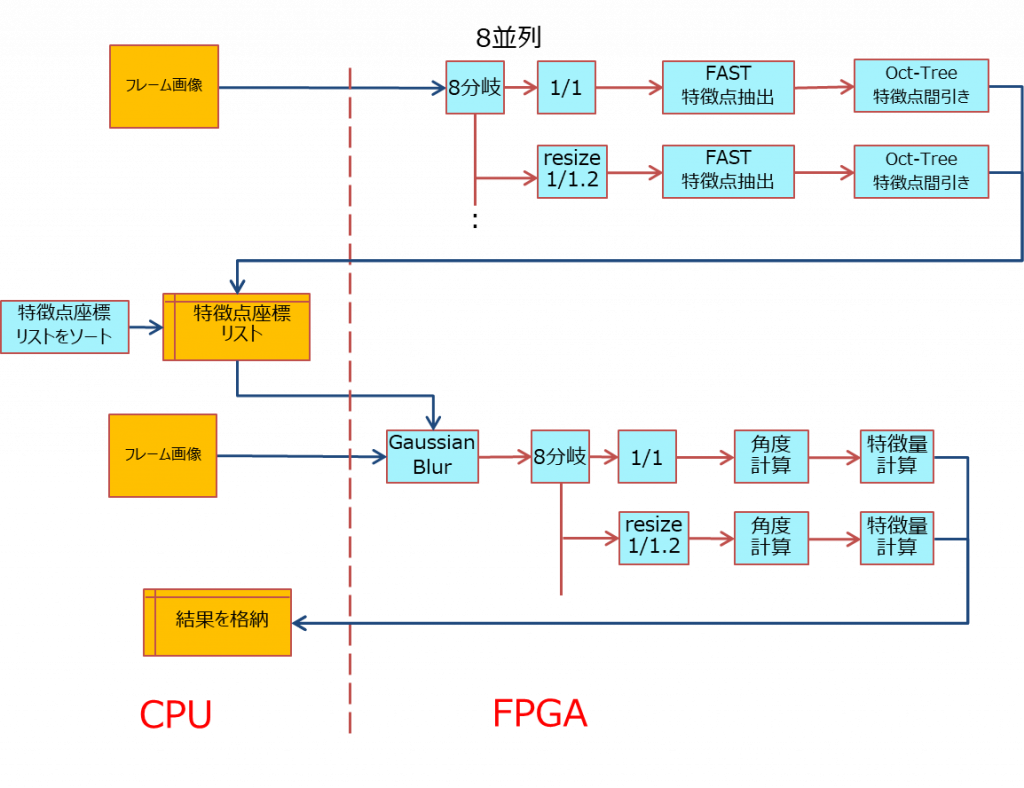
再度画像データを必要とする角度計算以降を後段として、前段と後段に分離しました。特徴点座標リストのソート処理は、前段の最後の処理であること、ソートはランダムアクセスとなり CPU で処理した方が高速と考えられる事から、 CPU で処理することとしました。後段の処理は CPU から再度画像データを転送するようにしたことで、前段では特徴点抽出処理で画像データを捨てても問題なく、保持する必要がなくなりました。前段の処理が終わった後、一旦 CPU に戻り、後段の処理を呼び出す形になります。特徴量計算でぼかした画像を使用しますが、その前の角度計算もぼかした画像を使用しても問題ないので、後段の最初に Gaussian Blur フィルタをかけてしまいます。これによって Gaussian Blur をパイプラインに組み込むことができ、メモリも不要となります。特徴量計算処理の前に縮小画像に対して Gaussian Blur をかけるとすると、 8 個の Gaussian Blur の回路が必要となりますが、縮小処理前にかけてしまうことで回路を 1 つにし、回路リソースを削減出来ています。
8 段階の縮小画像に対して 8 回ループして処理していましたが、画像間で依存関係がなく個別に処理することが可能です。そこで、 8 並列化して同時に処理することにしました。 8 本のベルトコンベアを作ってしまうことで、更に高速化が可能となります。
2. FPGA(ハードウェア)指向アルゴリズムへの変更
個別の処理の内部でも FPGA の動作原理を考慮してアルゴリズムを変更する必要があります。ここでは、Oct-Tree で行う特徴点の間引き処理を例に挙げます。
フレーム画像に細かい構造がたくさん集まる部分がある場合、特徴点が集中して取得されてしまいます。近い距離に多数の特徴点が得られても、地図作成、自己位置推定には効果は小さく、無駄にデータ数を増やしてしまうことになるため、既定の上限数に抑えるように間引き処理を行います。
元のアルゴリズムは以下の通りです。
- フレーム画像を 4 分割する。
- 分割したセル中に複数の特徴点が含まれるものは、更に 4 分割する。
- 分割数が規定の上限に達したとき、分割を止める。
- 複数の特徴点を含むセルでは、最も明確な特徴点を採用し、他は削除して間引く。
これを図にすると以下のようになります。
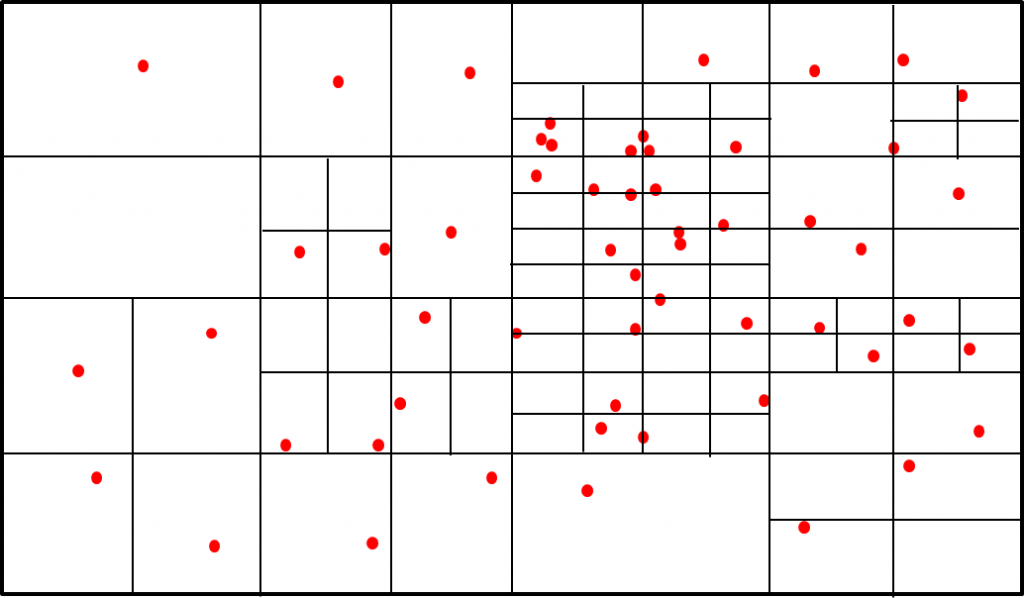
このアルゴリズムでは、分割した後にセル中の特徴点を数え終わらないと、次に分割する対象を決められず、パイプライン化が困難になります。また繰り返し分割するループ数が不定で、これもパイプライン化が困難となる原因になります。
これを改善した、FPGA 指向のアルゴリズムが以下です。
- フレーム画像を既定のサイズのセルに分割する。
- 画面左上のセルから順にスキャンし、各セル中の最も明確な特徴点を一つずつ採用する。
- 全セルをスキャンし終わり、規定数に達していない場合、また左上から次に明確な特徴点を採用する。
- 規定数に達するまで繰り返す。
図にすると以下のようになります。
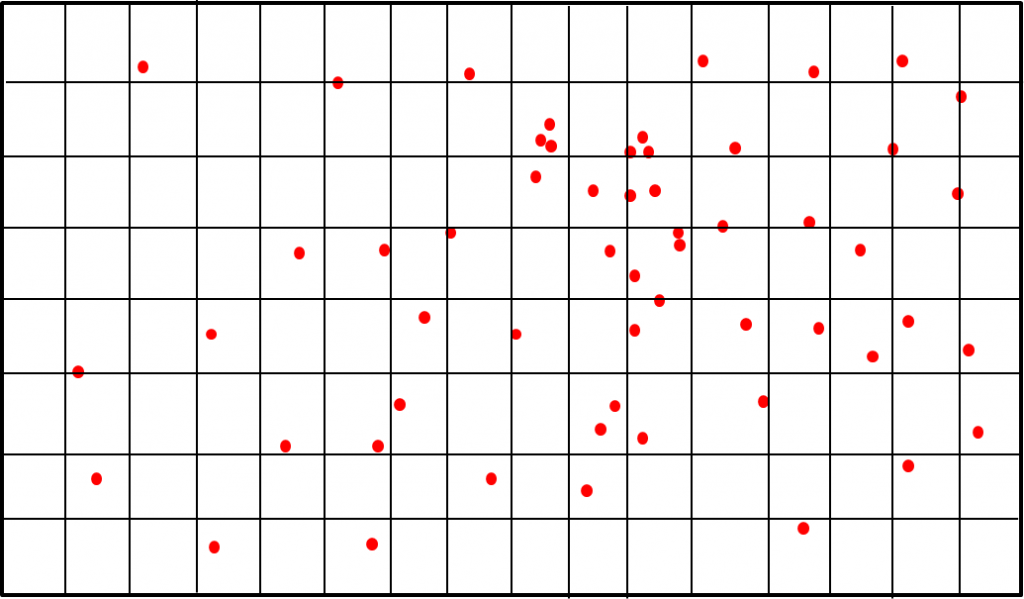
このアルゴリズムでは、セルをスキャンするループ数が固定となります。また、次に処理するセルが明確であるため、パイプライン化することができます。
このようにアルゴリズムを FPGA 指向に変更することで、高速化を目指します。もちろん、変更したアルゴリズムが正しいことを、 FPGA で動作させる前に、 PC 上で検証する必要があります。
3. 高位合成での言語仕様の制限
高位合成では高級言語のすべての機能が使える訳ではありません。ここでは Xilinx の高位合成環境で説明します。FPGA 回路は、パーシャルリコンフィグなどを除いて基本的に時間的に変化しないので、動的にメモリを確保したり、クラスオブジェクトを生成することは出来ません。つまり、 malloc や STL の vector が使えませんし、 new でオブジェクトを動的に生成することも出来ません。したがって配列のサイズは最大値を見積もって固定の配列にするか、ある上限のサイズを超えないようなアルゴリズムに変更しなければなりません。
同様に、処理内容を動的に変更できる関数ポインタも使えません。これもアルゴリズムの変更が必要となるでしょう。
Xilinx 高位合成環境でのコーディングスタイルについては、「 Vivado Design Suite ユーザーガイド 高位合成」の第3章に詳細に書かれています。開発するうえでは必須の知識となりますし、興味のある方は見てみるとよいでしょう。
言語仕様の制限ではありませんが、クラス構造や関数呼び出しの構造は、できる限りシンプルにした方がよいです。ソフトウェアでは、抽象化や流用性のためにクラスや関数を細かく分割します。その結果、ループの中から別の関数を呼び出し、その関数から更に別関数を呼び出し、その中でまたループして別クラスの関数を呼び出し、、、と言うことが通常です。これを高位合成するとどんな回路が合成されるか分かりませんし、パイプライン化も難しくなります。デバッグも非常に困難ですし、原因特定だけでも時間がかかります。流用性などのソフトウェアとしての常識は、ある程度割り切った方がよいでしょう。
性能計測結果
上記の設計に従ってプログラムを変更し、 PC 上でソフトウェアとして動作確認した後、高位合成して ZCU102 評価ボードで動作させました。速度性能測定結果は以下の通りです。内訳の前段と後段の合計が処理全体となっていませんが、ソート処理などの他の処理も全体に含まれているためです。
| FPGA [ms] | CPU [ms] | 倍率 | ||
| 処理全体 | 31.8 | 631.0 | 19.9 | |
| 内訳 | 前段 | 9.6 | 310.9 | 32.5 |
| 後段 | 19.7 | 317.6 | 16.1 | |
FPGA 対象部分の処理時間と、その内訳である前段、後段の個別の処理時間を計測しました。また、比較のために同じソースコードを FPGA 化せずにソフトウェアとして CPU で動作させたときの処理時間も、合わせて計測しました。この時の CPU は ZCU102 に搭載されている MPSoC の CPU で、 ARM 1.5GHz です。
CPU で動作させたとき 631.0ms かかっていた処理が 31.8ms となり、約 20 倍高速化できました。内訳を見ると前段が 32.5 倍、後段は 16.1 倍の高速化になっています。後段は前段より FPGA での効率的な処理にまだ改善の余地がありそうです。
FPGA リソース消費量は以下の通りです。
| Resource | Utilization | Available | Utilization % |
| LUT | 157983 | 274080 | 57.64 |
| LUTRAM | 9289 | 144000 | 6.45 |
| FF | 186451 | 548160 | 34.01 |
| BRAM | 813.5 | 912 | 89.20 |
| DSP | 176 | 2520 | 6.98 |
| BUFG | 3 | 404 | 0.74 |
| MMCM | 1 | 4 | 25.00 |
BRAM が約 90% 消費しています。パイプライン化しましたが、後段の処理で大きなバッファを持つ必要があり、大きなメモリを消費してしまいました。この辺も改善の余地があります。
ソースコードの実装量としては、コメント行を除いて約 3100 行です。ソフトウェアとしては大きな規模ではありませんが、 FPGA としては多くのリソースを消費しています。 LUT も半分以上を消費していますので、更に大きく FPGA 回路を増やすことは難しいでしょう。ソフトウェアでは数万、数十万行の規模に及ぶことはよくありますが、高負荷な処理が全体に散らばっている場合、その一部しか FPGA 化することは出来ません。高負荷処理がコード行数にして数千行程度の範囲に集中している状況において、大きな FPGA 化の効果が得られると言えます。
まとめ
ORB-SLAM の FPGA 化について説明しました。オープンソースソフトウェアを元に、 FPGA 向けに設計を見直し、高位合成で FPGA 実装したところ、 CPU での処理と比べて約 20 倍、部分的には 30 倍以上高速化した結果を得られました。合成レポートなどから詳細に解析して非効率な部分を探し、更なる高速化を目指したいと思います。
高位合成によってソフトウェア技術者が FPGA を扱いやすくなったとは言え、「FPGA 指向の設計変更」の節で述べたように、 FPGA の原理を理解しておく必要があり、まだ敷居は高いかも知れません。しかしその見返りは大きく、 CPU では得られない高速化を実現できる可能性があります。 CPU と FPGA がワンチップに収まっている製品もありますので、高負荷処理を行うデバイスの小型化、省電力化も見込めるでしょう。
高負荷な処理、例えば画像処理やディープラーニングがありますが、処理の高速化にはよく GPU が使われています。もちろん GPU を使うのが最適な状況もあるでしょう。その場合は GPU を使うべきであると思いますが、 FPGA の方が得意な状況もあります。 FPGA を扱えると言うことは、より最適なソリューションを提供できる引き出しが一つ増えることになります。ソフトウェア技術者にも、ぜひ FPGA にチャレンジしていただきたいと思います。
この5回の連載ブログで、ホームサービスロボットとFPGAがオーバーラップする領域について記述させて頂きました。当チームでは引き続きホームサービスロボットの高度知能化をけん引する組込指向の脳型計算機を目指した研究開発を進めていきます。もちろん、そこではFPGAが大きな役割を担います。
九州工業大学大学院生命体工学研究科
准教授 田向 権 (Hakaru Tamukoh)、Hibikino-Musashi@Home
参考文献
[1] Raúl Mur-Artal, J. M. M. Montiel, Juan D. Tardós, “ORB-SLAM: A Versatile and Accurate Monocular SLAM System”, IEEE Transactions on Robotics, Vol. 31, Issue 5, pp. 1147-1163, 2015.
[2] KITTI Vision Benchmark Suite : http://www.cvlibs.net/datasets/kitti/
[3] 岩渕 甲誠,松本 茂樹,松尾 幸治,石田 裕太郎,廣瀬 尚三,長瀬 雅之,田向 権, “高位合成によるORB-SLAMのFPGA実装の最適化,” 第20回計測自動制御学会システムインテグレーション部門講演会,1A5-03,2019.
[4] 岩渕 甲誠,松本 茂樹,松尾 幸治,石田 裕太郎,廣瀬 尚三,長瀬 雅之,田向 権, “高位合成によるORB-SLAMのFPGA実装と評価,” ロボティクス・メカトロニクス講演会2019 in Hiroshima,1AI-F06,2019.