
本コースでは、複数の FPGA を用いた計算機システムの構成と、私達が研究開発が行っているカスタム・コンピューティング・システムについて紹介していきます。
第3回では、FPGA を搭載したヘテロジニアスシステムの分類を行い、システムの構成には何が必要かを考えていきます。
FPGA を搭載したヘテロジニアスシステムの分類と特徴
前回は、いろいろな FPGA 接続ネットワークについて紹介しました。今回は、CPU 側を含めたヘテロジニアスシステムとしての観点で、これらのシステムを見て行きます。
CPU と FPGA を搭載するヘテロジニアスシステムのネットワーク構成は、CPU と FPGA のネットワークが専用か共有かどうかと、そのネットワークがスイッチか直結なのかで以下の 6 パターンが便宜上考えられます。
この中で、CPU 専用直結ネットワークと CPU / FPGA 共有直結ネットワークも存在しないと思われるため、今後の議論から外します。また、CPU 専用スイッチネットワークは、 Ethernet か InfiniBand がディファクトスタンダードです。
| FPGA 側ネットワーク | CPU 側ネットワーク | CPU / FPGA 共有ネットワーク | |
| スイッチ | FPGA 専用スイッチネットワーク | CPU 専用スイッチネットワーク | CPU / FPGA 共有スイッチネットワーク |
| 直結 | FPGA 専用直結ネットワーク | CPU 専用直結ネットワーク | CPU / FPGA 共有直結ネットワーク |
ヘテロジニアスシステムとしての構成は、FPGA 側と CPU 側のネットワークの有無も含めて、以下の 6 つの構成が考えられます。
- CPU 専用スイッチネットワーク + FPGA 専用スイッチネットワーク
- CPU 専用スイッチネットワーク + FPGA 専用直結ネットワーク:Cygnus, Noctua, Novo-G#, Catapult v1
- FPGA 専用スイッチネットワークのみ
- FPGA 専用直結ネットワークのみ
- CPU 専用スイッチネットワークのみ
- CPU / FPGA 共有スイッチネットワーク:Catapult v2, v3
この中で前回ご紹介した 4 つのシステムが該当する 2, 6 に加え、最も単純な構成である 5 について見ていきたいと思います。
CPU 専用スイッチネットワーク + FPGA 専用直結ネットワーク
この方式は、CPU 側も FPGA 側も別々のネットワークを持っています。Cygnus, Noctua, Novo-G#, Catapult v1 が、この方式に該当します。FPGA 側のネットワークは直結網であるため、短距離のレイテンシが非常に低く、高いバンド幅が得られます。このため、ネットワーク性能を最大限に利用できます。
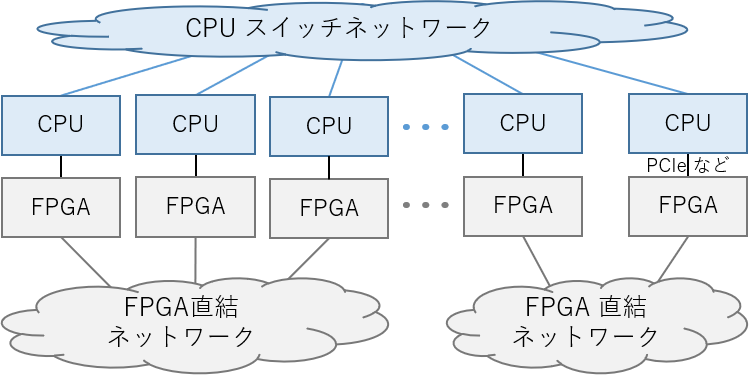
CPU と FPGA が別々のネットワークを利用する形式
この構成は、対象アプリケーションの通信パターンが事前に分かる場合に非常に有効です。しかし、直結できる FPGA の台数に制限があるため、上限以上の FPGA を利用する場合には CPU 側のネットワークを介する必要があります。上記の 4 システムの論文から、上限は多くとも 100 台程度と考えられます。
運用上の利点として、1つのネットワークが故障しても別のネットワークの障害とならないため、対障害性も前者の構成に比べて高いと考えられます。
CPU 専用スイッチネットワークのみ
この方式は、CPU 側にのみネットワークを持ち、FPGA 側にはネットワークはありません。Amazon F1 インスタンスが、この形式に該当すると思われます。
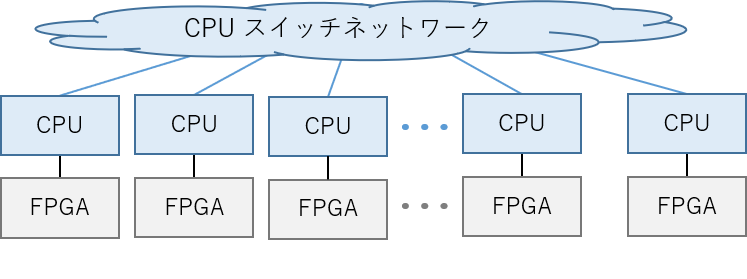
FPGA も CPU 側のスイッチネットワークを利用する形式
FPGA が別の FPGA や CPU に通信する場合は、CPU 側のスイッチネットワークを介する必要があり、レイテンシが大きい点が問題になります。GPU の場合は、特定のネットワークカードなどを用いて直接通信が可能ですが、FPGA ではその様な機器はまだ登場していません。
運用上の利点として、既存のネットワークシステムやソフトウェアを流用できるため、開発コストや柔軟性は高いと考えられます。
CPU / FPGA 共有スイッチネットワーク
この形式は、CPU と FPGA が単一のネットワークを共有します。Catapult v2, v3が、この形式に該当します。どちらもノードの構成は 3. に該当しますが、Ethernet プロトコルを用いて CPU とも通信が可能なため、こちらに分類しています。
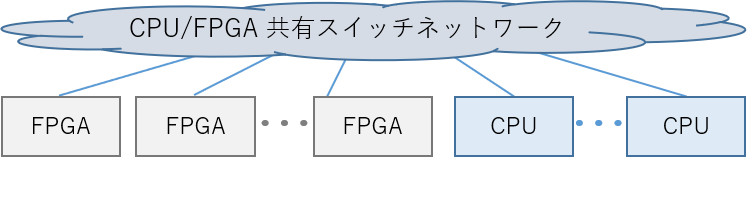
FPGA と CPUが同じスイッチネットワークを共有する形式
スイッチネットワークに Ethernet を採用すれば、CPU も FPGA もお互いに自由かつ動的に通信できる柔軟な構成です。多数の FPGA を利用する大規模なシステムであれば、レイテンシも直結ネットワークよりも優位な場合があります。
また、1つの CPU が複数の FPGA を (スイッチを介して) 利用できるため、FPGA を全く利用しないプログラムと複数利用するプログラムが混在した場合、FPGA リソースを有効に利用できます。
ネットワーク構成と通信性能
ネットワーク構成と通信性能を以下にまとめます。直結ネットワークであれば、1 [us] 以下のレイテンシが実現可能であり、Cygnus では 0.5 [us] を達成しています。Cygnus は、実効バンド幅も理論バンド幅の 90 % 以上を達成しており、非常に高いバンド幅を実現できます。
Ethernet を利用している Catapult v2 では、隣接通信 (a ping-pong通信) のレイテンシ 3[us] 以下と大きいですが、10万台以上の FPGA を接続しても 23.5 [us] 以下を実現できるようです。
| 隣接通信 (a ping-pong通信) [us] | 実効バンド幅 [Gbps] | 1ホップ [ns] | ネットワーク構成 | 特徴 | |
| Cygnus | 0.5 | 98.3 | ~ 250 | CPU 専用スイッチ+ FPGA 専用直結 | 2D Torus |
| Noctua | 0.801 | 31.85 | ??? | CPU 専用スイッチ+ FPGA 専用直結 | トポロジ変更可 |
| Novo-G# | 0.87 (CUBE 通信パターン) | ??? | ??? | CPU 専用スイッチ+ FPGA 専用直結 | プロトコル変更可 (?) |
| Catapult v1 | ~ 1.0 | ??? | ~ 400 | CPU 専用スイッチ+ FPGA 専用直結 | 2D Torus |
| Catapult v2 | 2.88 | ??? | ??? | CPU / FPGA 共有スイッチ | Ethernet |
この様に、プロトコルと接続可能な FPGA の台数はトレードオフの関係にあり、どのくらいの台数をターゲットにするかがポイントになることがわかります。
CPU 側のネットワークの利用
現在の FPGA 搭載ヘテロジニアスシステムでは、どうしても CPU を搭載する必要あります。また、”6. CPU / FPGA 共有スイッチネットワーク” 以外では、CPU を利用した通信が必要となります。CPU 側のネットワークをどの様に利用するかを考えていきます。
我々の考える FPGA を用いたカスタム・コンピューティング・システムの実現には、FPGA 間のデータ通信のみならず、タスクマイグレーションが発生すると考えられます。
例えば、FPGA のコンフィグレーションデータや、計算データに必要な入出力などが挙げられます。これらは、大容量のデータを別ノードの FPGA へ転送する必要がでてくるため、柔軟なデータ転送が行える必要があります。
FPGA 搭載ヘテロジニアスシステムで柔軟なデータ転送が行える
これを実現するために、我々は、ソフトウェアのみで自由にデータ転送を行える機能、「ソフトウェアブリッジドデータ転送」機能を提案しています。
この機能は、FPGA メモリから別ノードのホスト CPU メモリへのデータ転送を実現するものになります。実装には、InfiniBand verbsとDMA転送機能を利用し、それらをパイプライン的に動作させることで、経路全体のボトルネックである PCIe Gen3 x8 の理論ピーク値に対 81.0% の実効性能を達成しました。
まとめ
今回は、FPGA を搭載したヘテロジニアスシステムの分類を行い、システムの構成についてまとめました。具体的には、CPU 専用スイッチネットワーク + FPGA 専用直結ネットワーク、CPU 専用スイッチネットワークのみ、CPU / FPGA 共有スイッチネットワークの3つについて特徴と性能を述べました。
次回は、我々が研究開発中の「ソフトウェアブリッジドデータ転送」機能について紹介していきます。
理化学研究所 計算科学研究センター (R-CCS) プロセッサ研究チーム
特別研究員 宮島敬明
チームリーダー 佐野健太郎