
みなさん、こんにちは。ACRi ブログ第2期の8番目のコースを担当する宮島と申します。私たち、理化学研究所 計算科学研究センター (R-CCS) プロセッサ研究チームでは、次世代の計算機システムに FPGA を利用できないかと考え、研究開発を行っています。
本コースでは、複数の FPGA を用いた計算機システムの構成と、私達が研究開発が行っているカスタム・コンピューティング・システムについて紹介していきます。第1回の記事では、FPGA を計算機システムに用いる理由とコンセプトを紹介します。
FPGA を用いた計算機システムが注目される背景
みなさんは FPGA をどの様な目的やシーンで利用していますか?たとえば、無数のインターフェイスを制御する I/O 制御部や、深層学習の推論に代表されるエッジコンピューティング、ASIC のプロトタイピングなどでしょうか。
また、なぜ FPGA を利用しているのでしょうか?たぶん、既存 CPU では計算時間や消費電力など所要の目的を達成できなかったり、非効率になるためかと思います。
私達は FPGA を用いて次世代の計算機システムを構築できないかと考えており、その背景には大きく以下の項目が挙げられます。
- ノイマン型コンピュータのボトルネックの顕在化
- 領域特化アーキテクチャへの注目
- FPGA の高性能化と周辺技術の成熟
ノイマン型コンピュータのボトルネックの顕在化

出典:Wikichip Skylake
CPU や GPU に代表される現代の計算機は、 四則演算などの実際の計算を行う ALU (Arithmetic and Logic Unit) の他に、非常に沢山の回路が搭載されています。例えば、アウト・オブ・オーダー実行を行うための機能 (OoO 機構) やキャッシュ・ヒット率を向上させるための分岐予測テーブルなどです。
上の図は、Intel 社の Skylake 世代の CPU ダイの写真です。実際の計算を行う Execution Units は全体の1/4以下で、L1, L2 キャッシュや OoO 機構が3/4以上を占めていることがわかります。これらの回路は複雑で面積が大きいだけでなく、消費電力が大きいことが知られています。
近年のメニーコア CPU や GPU は、簡素な OoO 機構のみを搭載する様な軽量な計算コアをたくさん搭載することで、性能向上と消費電力の削減を実現してきました。例えば、PEZY 社の PEZY-SC シリーズは、非常に軽量な計算コアを2048個搭載したチップで、4.1 TFLOPS (倍精度) の計算性能と14.69 GFLOPS/watt の計算効率を達成しました。
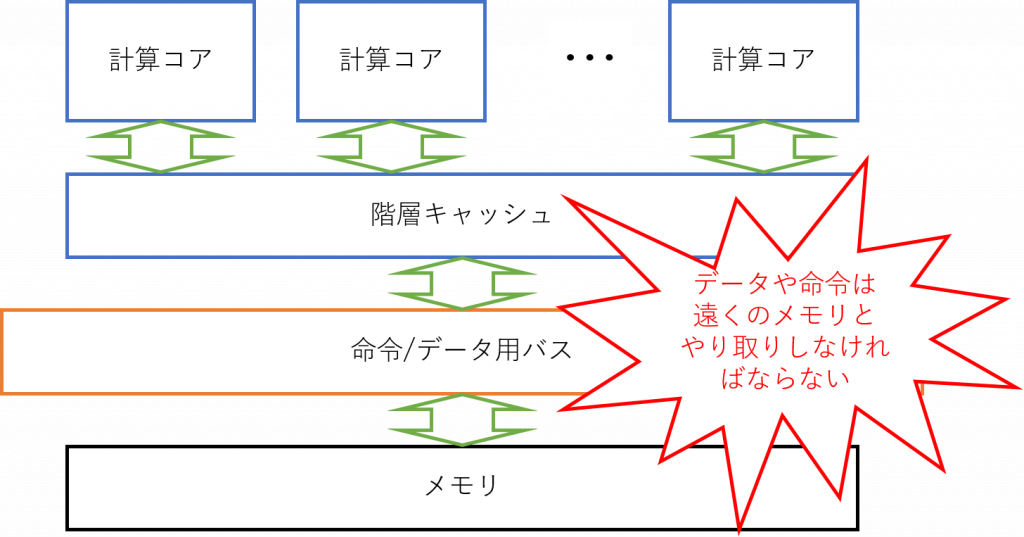
コアの個数を増やすと計算コアとメモリを接続するバスが性能向上のボトルネックとなる
しかし、コアが増えるにつれ、フォン・ノイマン・ボトルネックと呼ばれる計算性能を律速する根本的な要因が顕在化しています。フォン・ノイマン・ボトルネックとは、メモリからデータを持ってきて ALU で計算を行う際にデータが通過するバスの性能が、性能律速の要因となることです。非常に単純に言い換えると、メインメモリのバンド幅やレイテンシが全体の性能を律速する、ということになります。
これらの問題点は、ノイマン型計算機に起因するものです。半導体設計技術 (Intel 社の Foveros や TSMC 社の CoWoS など) やマイクロアーキテクチャ設計技術 (階層キャッシュやマルチコア化など)、アルゴリズム設計技術 (キャッシュのブロッキングやコアレスド・アクセス化など) などの広い領域で、この問題を回避する手法が取られています。
加えて、経済的に搭載可能なトランジスタの数は、今後それほど向上しないと見込まれています。そのため、一定量のトランジスタをいかに有効に実際の計算に利用できるかが重要になってきています。
これらの問題を根本的に解決するために、非ノイマン型計算機が利用できるのではないかと我々は考えています。
領域特化アーキテクチャへの注目
近年、深層学習向け専用チップを始めとする領域特化アーキテクチャの実利用が始まっています。
領域特化アーキテクチャ (Domain Specific Architecture) は、従来の汎用 CPU や GPU とは違い、特定の問題領域のみに特化した計算機です。特定の問題領域に特化することで必要のない回路を省き、省電力化や高性能化を目指すものと言えます。
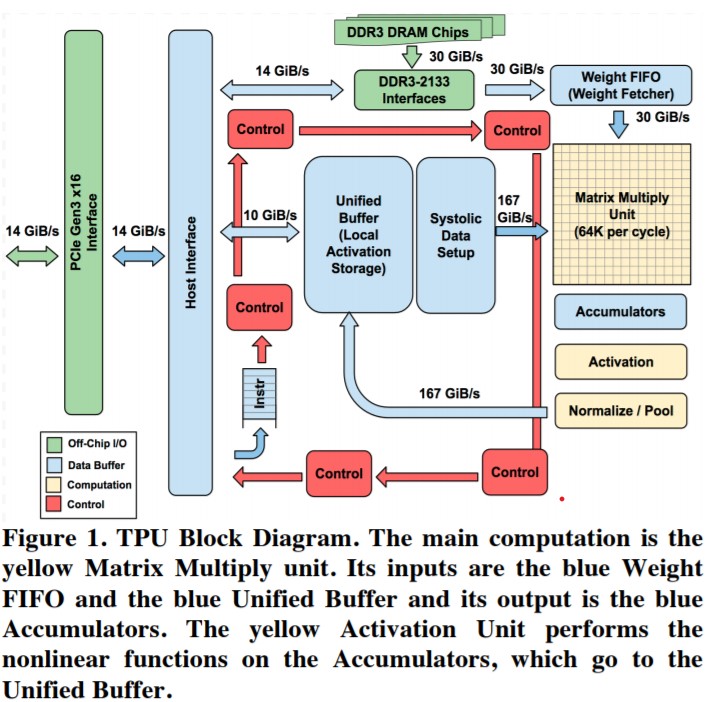
出典:ACM SIGARCH CAN
例えば、Google 社の TPU (Tensor Processing Unit) や PFN 社の MN-Coreは、深層学習に必須の小さな密行列を計算するための特殊な ALU が搭載されています。また、深層学習での計算に特化することで、OoO 機構やキャッシュなどを搭載しないという選択肢を取っています。実際、MN-Core は電力あたりの性能を競うランキング “Green500” で2020年6月に1位となっています。
深層学習だけではなく、以前より領域特化の計算機は研究開発が行われてきました。代表的なものに、天文学分野のN体問題に特化した GRAPE シリーズや、生化学分野の分子動力学法に特化した D.E. Shaw Research 社の Antonなどがあります。
学術分野では、より破壊的な変化を生むことを目的とした組織が立ち上がりました。米国の電気電子学会 (IEEE) の IEEE Rebooting Computing は、新しい計算機について研究開発を行う組織です。この組織の目的は、デバイスからアルゴリズムの領域にまたがって計算機分野に破壊的な変化を生むことで、計算の性能を劇的に向上させることです。
他にも、汎用計算機の書籍として有名な、コンピュータアーキテクチャ 定量的アプローチは第6版から、「第7章 領域特化アーキテクチャ」として領域特化型のアーキテクチャの解説が追加されました。
領域に特化することで性能は向上しますが、汎用性とのトレードオフとなります。また、領域特化とは言え、ASIC の作成には長い時間とお金、ノウハウが必要です。FPGA を利用することで、良いトレードオフのポイントを実現できるのではないかと私たちは考えています。
FPGA の高性能化と周辺技術の成熟

近年の FPGA は、FPGA 自体だけでなく、FPGA ボードも高性能化し、CPU や GPU と同等以上のメモリ帯域や通信性能を実現しつつあります。FPGA 自体は、Intel 社の Stratix10 シリーズや Xilinx 社の Versal シリーズにおいて、1万個を超える DSP や400GB/s超のメモリバンド幅を持つ HBM2 メモリ、汎用の ARM コアなどを搭載しています。
FPGA ボードには、Intel 社の PAC シリーズや Xilinx 社の Alveo シリーズにおいて、100Gbpsネットワークインターフェイスを搭載したものが登場しています。この様に、ボードを自前で設計せずとも、高性能計算機として FPGA を利用可能となってきました。

また、FPGA の高性能化だけでなく、以下に挙げる様な周辺技術の成熟により、実際のシステムとして FPGA を利用する敷居が下がってきたと言えます。
- 高位合成言語に代表されるコンパイラ技術
- ユーザビリティを向上させる動的再構成技術
- クラウド対応やデバイスドライバ、ライブラリの整備
ACRi ブログ「スーパーコンピュータでも使われ始めた FPGA」の第2回では、これらの状況が具体的に説明されています。
この様な状況を踏まえ、FPGAを用いて高性能な計算機システムを構築できるのではないかと私たちは考えています。
FPGA を用いたカスタム・コンピューティング・システム
私たちは、複数の FPGA を相互接続したクラスターを用いて、カスタム・コンピューティング・システムを研究開発中です。詳細は、連載の後半でお話する予定ですので、今回は概要をお話したいと思います。
なぜ FPGA を用いた計算機システムなのか?
上記の「FPGA を用いた計算機システムに注目した背景」で挙げた3つの項目から、FPGA を用いて以下の様な計算機システムが実現可能ではないかと考えています。
ノイマン型コンピュータの問題を回避できる
古くから研究が行われているデータ・フローマシンなどは、非ノイマン型コンピュータであり、ノイマン型コンピュータが有する問題がありません。もちろん、非ノイマン型コンピュータにもそれ特有の問題があります。
FPGA は、データフローを空間方向に展開する様な、非ノイマン型コンピュータとして利用することができます。全ての計算を非ノイマン型コンピュータで実現することは難しいですが、ARM などを搭載した FPGA であれば、利用範囲はより広いと考えられます。
特定の領域にカスタマイズ可能である
再構成可能な FPGA は、特定の領域にカスタマイズして利用する用途で既に多くの実績があります。さらに、ネットワーク・インターフェイスのカスタマイズも可能なため、他の計算機に対し大きなアドバンテージがあります。また、周辺技術の成熟で実装や運用のしきい値は大幅に低下しています。
大規模な計算が可能である
大規模な計算が可能かどうかは未知数な部分もありますが、高性能な FPGA ボードを強力なネットワークで相互接続することは可能です。複数の FPGA を接続したシステムは、以前から研究が行われています。
また、Ethernet や InfiniBand などのディファクト・スタンダードな技術を利用することで、最新技術のキャッチアップも容易になると考えられます。
FPGA を用いたカスタム・コンピューティング・システムのコンセプト
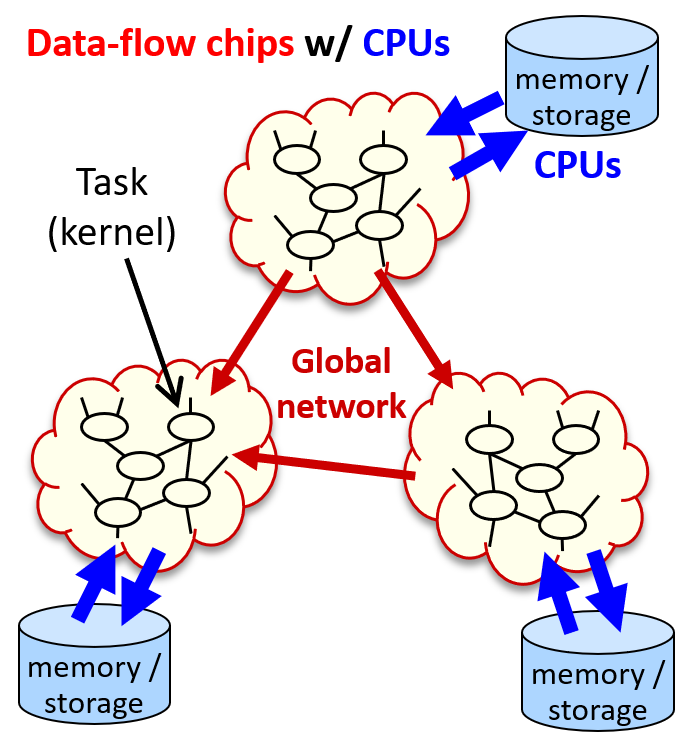
カスタム・コンピューティング・システムのコンセプトは上の図の様なものになります。データフロー・マシンをベースにした各計算ノードは、互いに高速なネットワークで相互接続され、全体として大規模な計算機システムとして動作します。
計算ノードとネットワーク・インターフェイスに FPGA を利用することで、ノイマン型コンピュータの問題を回避しつつ、特定の領域にカスタマイズ可能なシステムを実現します。また、既存の CPU を併用することで、データフロー・マシンだけでは実現が難しい問題にも対処したいと考えています。
FPGA を用いたカスタム・コンピューティング・システムの実現には、いくつか解決すべきポイントがあります。例えば、FPGA と CPU の相互接続の方法やデータフロー・マシンの実現方法、エコシステムの構築などが挙げられます。
FPGA を用いたカスタム・コンピューティング・システムは、複数の FPGA を利用したマルチ FPGA システムとも考えられます。マルチ FPGA システムには、先行研究がいくつか存在します。例えば、筑波大学 計算科学研究センターの Cygnus やドイツの Paderborn 大学の Noctua などです。
次回は、これらのマルチ FPGA システムの紹介を行い、解決すべきポイントを具体化していきます。
まとめ
今回は、私たちが研究開発中の FPGA を用いたカスタム・コンピューティング・システムの研究背景とコンセントを紹介しました。従来型のノイマン型コンピュータでは性能向上が難しくなってきたため、FPGA を用いて計算やネットワークがカスタマイズ可能な計算システムを構築したいと考えています。
次回は、他の複数 FPGA を利用したシステムの紹介を行い、カスタム・コンピューティング・システムを実現する上で解決すべきポイントを解説します。
理化学研究所 計算科学研究センター (R-CCS) プロセッサ研究チーム
特別研究員 宮島敬明
チームリーダー 佐野健太郎