本コースの第2回目は、ニューラルネットワークのモデル記述からどのようにハードウェアが生成されるか、NNgen コンパイラの仕組みを紹介します。
NNgen の全体構成
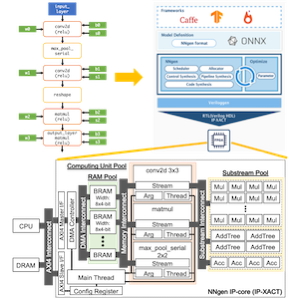
第1回の記事からの再掲ですが、NNgen のコンパイラ構成は下図の通りです。
NNgen でハードウェア化するニューラルネットワークのモデル表現方法は、NNgen のオペレータを組み合わせて、プログラマが計算グラフを定義する方法と、Tensorflow や Pytorch などの一般的な DNN フレームワーク上のモデル定義を、DNN の共通フォーマットの ONNX を介して、NNgen 形式の計算グラフへと変換する方法の2つがあります。
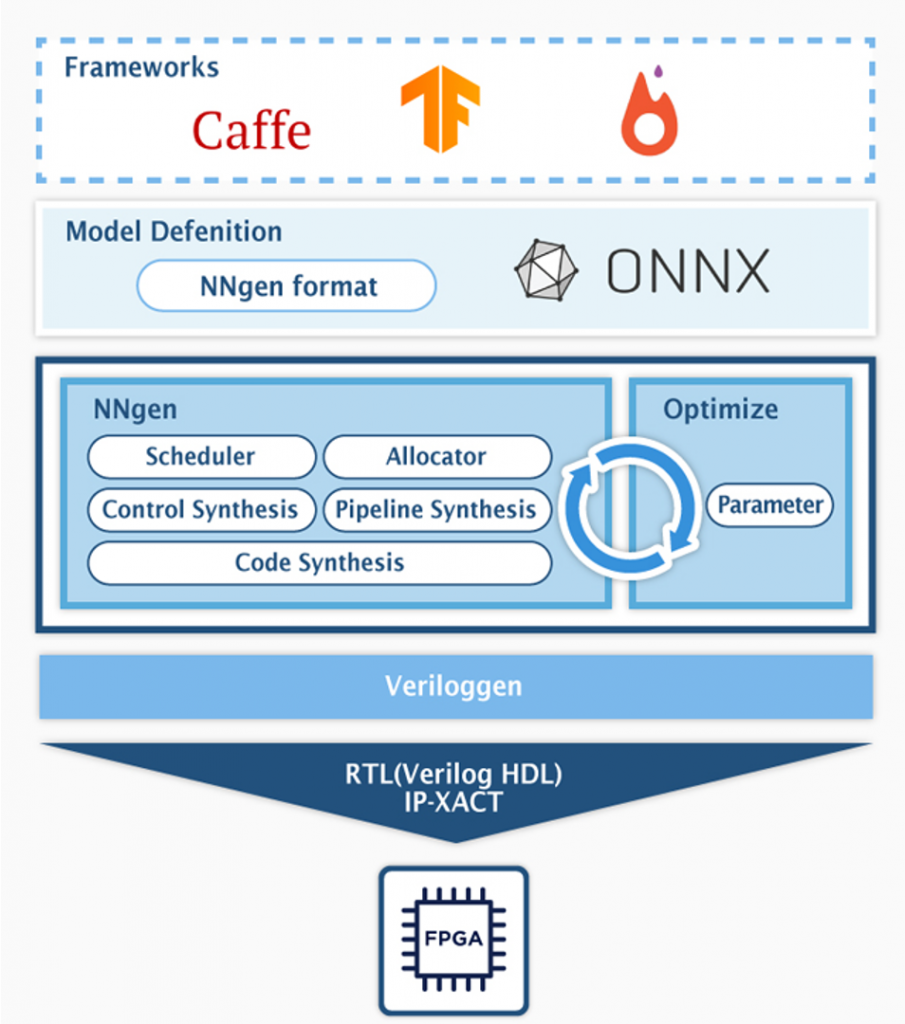
NNgen コンパイラは、NNgen 形式の計算グラフから、演算器やオンチップメモリ等の計算を行う回路と、それらの制御回路を生成し、最終的な生成物であるハードウェア記述と IP コア設定ファイルを出力するのが仕事です。第1回で取り扱った、NNgen のサンプルコード (hello_nngen.py) について、計算グラフの記述からハードウェア記述が生成されるまでを、手順を追って見ていきましょう。
計算グラフ
以下に、サンプルコード中のグラフ定義を抜粋します。
# --------------------
# (1) Represent a DNN model as a dataflow by NNgen operators
# --------------------
# data types
act_dtype = ng.int8
weight_dtype = ng.int8
bias_dtype = ng.int32
scale_dtype = ng.int8
batchsize = 1
# input
input_layer = ng.placeholder(dtype=act_dtype,
shape=(batchsize, 32, 32, 3), # N, H, W, C
name='input_layer')
# layer 0: conv2d (with bias and scale (= batchnorm)), relu, max_pool
w0 = ng.variable(dtype=weight_dtype,
shape=(64, 3, 3, 3), # Och, Ky, Kx, Ich
name='w0')
b0 = ng.variable(dtype=bias_dtype,
shape=(w0.shape[0],), name='b0')
s0 = ng.variable(dtype=scale_dtype,
shape=(w0.shape[0],), name='s0')
a0 = ng.conv2d(input_layer, w0,
strides=(1, 1, 1, 1),
bias=b0,
scale=s0,
act_func=ng.relu,
dtype=act_dtype,
sum_dtype=ng.int32)
a0p = ng.max_pool_serial(a0,
ksize=(1, 2, 2, 1),
strides=(1, 2, 2, 1))
# ...
# output
output_layer = ng.matmul(a2, w3,
bias=b3,
scale=s3,
transposed_b=True,
name='output_layer',
dtype=act_dtype,
sum_dtype=ng.int32)計算グラフの構造は以下の図の通りです。NNgen では現状、再帰型ニューラルネットワーク (RNN) には対応していないため、有向非巡回グラフ (DAG) になります。
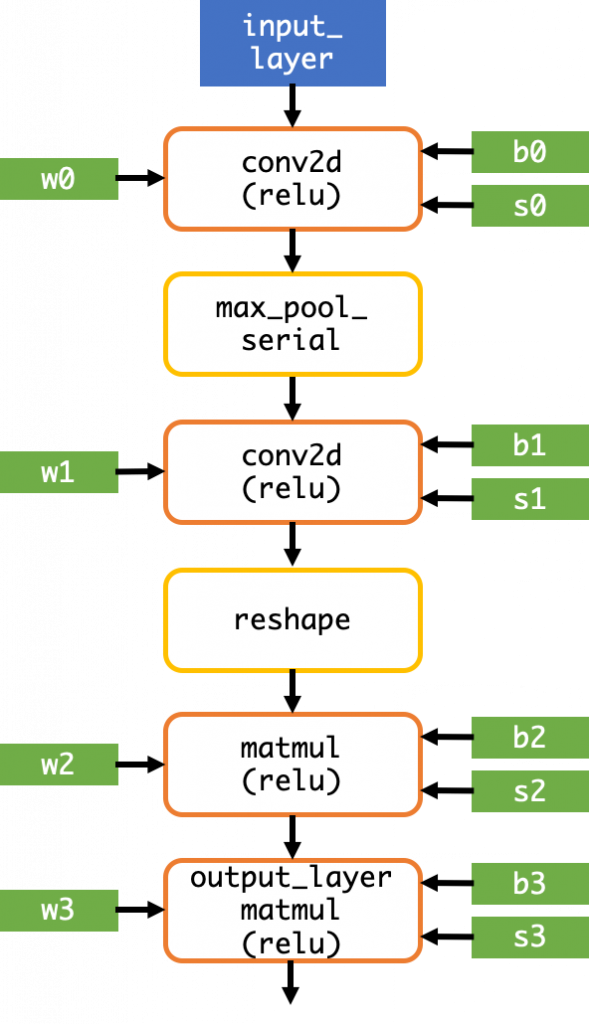
この計算グラフから、どのようにハードウェアが生成されるかを見ていきましょう。
NNgen が生成するハードウェア構造
NNgen が最終的に生成する回路構造は、下図の点線で囲まれた部分のようになります。conv2d や matmul、max_pool といった計算オペレータに対応する回路と、各オペレータ回路を構成する演算器群 (Substream Pool) とメモリ群 (RAM Pool)、それらを接続するカスタムのチップ内ネットワーク (Substream Interconnect, Memory Interconnect) 、全体を制御する制御回路 (Main Thread) 、NNgen ハードウェアの外部とデータ転送を行う DMA コントローラなどで構成されます。
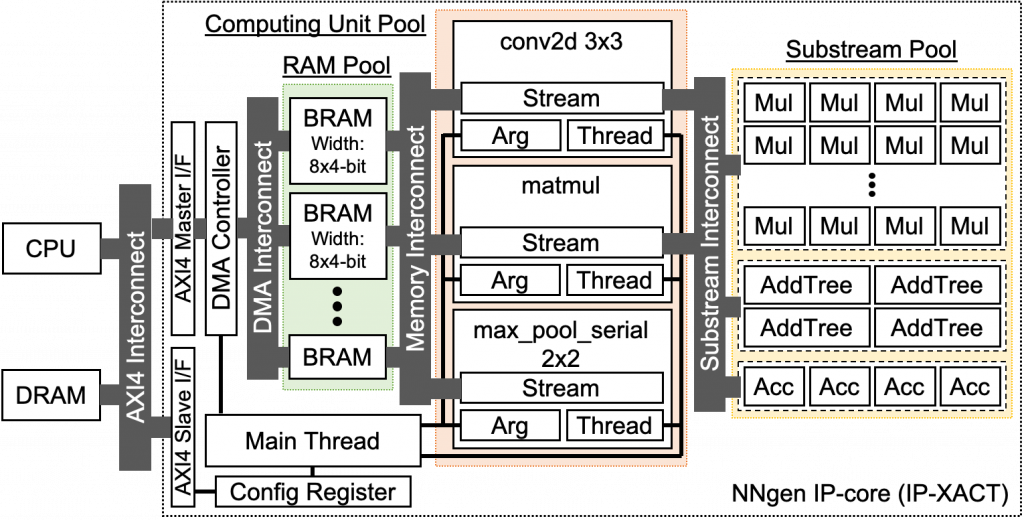
重要な点として、計算グラフ中で同一種類のオペレータが複数回用いられている場合であっても、そのオペレータの回路は1つしか生成されない点です。今回取り扱うサンプルコードでは、conv2d および matmul はそれぞれ2回ずつ用いられていますが、それぞれの回路は1つずつしか生成されていません。計算グラフを解析し、最大公約数的なハードウェアを生成するのが NNgen の特徴と言えます。
また、各オペレータで用いる演算器は、演算器プール (Substream Pool) にまとめて生成され、各オペレータはチップ内ネットワーク (Substream Interconnect) を介して、プール化された演算器を共有します。例えば、conv2d や matmul のどちらも積和演算を行いますが、それぞれ個別に積和演算器が生成されるのではなく、同一の演算器群を共有します。オペレータ回路および演算器を共有することで、ニューラルネットワークのレイヤー数が増えても、回路規模の増加を抑えることができます。
計算グラフの解析
以下のように、計算グラフを to_ipxact または to_verilog という関数を用いて、IP-XACT 形式の IP コアや Verilog HDL のソースコードテキストへと変換します。出力層のオブジェクトを引数として渡します。この例では、”output_layer” を出力層として渡しています。
targ = ng.to_ipxact([output_layer], 'hello_nngen', silent=silent,
config={'maxi_datawidth': axi_datawidth})ここで、NNgen コンパイラの内部を覗いてみましょう。”nngen/verilog.py” に定義されている、to_ipxact 関数
から辿ります。
def to_ipxact(objs, name, ipname=None, config=None, silent=False):
if ipname is None:
ipname = name
config = load_default_config(config)
m = _to_veriloggen_module(objs, name, config,
silent=silent, where_from='to_ipxact', output=ipname)
clk_name = config['clock_name']
rst_name = config['reset_name']
rst_polarity = ('ACTIVE_LOW'
if 'low' in config['reset_polarity'] else
'ACTIVE_HIGH')
irq_name = config['interrupt_name']
irq_sensitivity = 'LEVEL_HIGH'
clk_ports = [(clk_name, (rst_name,))]
rst_ports = [(rst_name, rst_polarity)]
irq_ports = [(irq_name, irq_sensitivity)] if config['interrupt_enable'] else []
ipxact.to_ipxact(m, ipname,
clk_ports=clk_ports,
rst_ports=rst_ports,
irq_ports=irq_ports)
return mto_ipxact 関数では、_to_veriloggen_module 関数を呼び出して、Veriloggen 形式のハードウェア記述を生成しています。Veriloggen はマルチパラダイム型高位合成コンパイラであり、内部では Python のオブジェクトとして、ハードウェア記述を表現されています。次に、同じ “nngen/verilog.py” に定義されている _to_veriloggen_module 関数を覗いてみましょう。
def _to_veriloggen_module(objs, name, config=None,
silent=False, where_from=None, output=None):
if not isinstance(objs, (list, tuple)):
objs = [objs]
(objs, num_storages,
num_input_storages, num_output_storages) = analyze(config, objs)
m, clk, rst, maxi, saxi = make_module(config, name, objs,
num_storages, num_input_storages,
num_output_storages)
schedule_table = schedule(config, objs)
header_info = make_header_addr_map(config, saxi)
(ram_dict, substrm_dict, ram_set_cache,
stream_cache, control_cache, main_fsm,
global_map_info, global_mem_map) = allocate(config, m, clk, rst,
maxi, saxi, objs, schedule_table)
reg_map = make_reg_map(config, global_map_info, header_info)
if not silent:
dump_config(config, where_from, output)
dump_schedule_table(schedule_table)
dump_rams(ram_dict)
dump_substreams(substrm_dict)
dump_streams(stream_cache)
dump_controls(control_cache, main_fsm)
dump_register_map(reg_map)
dump_memory_map(global_mem_map)
return manalyze 関数では、引数 objs として渡されているニューラルネットワークの出力層から、入力側へと逆に計算グラフを辿って、計算グラフを構成するすべてのオブジェクトを収集します。
schedule 関数では、計算グラフ中の各オペレータの演算タイミングをスケジューリングします。
allocate 関数では、スケジュール結果に基づいて、演算器、メモリ、制御回路を合成します。では、どのように実際の回路構造を決定するかを知るために、allocate 関数の内部を覗いてみましょう。
演算器、メモリ、制御回路の生成
def allocate(config, m, clk, rst, maxi, saxi, objs, schedule_table):
set_storage_name(objs)
merge_shared_attrs(objs)
max_stream_rams = calc_max_stream_rams(config, schedule_table)
ram_dict = make_rams(config, m, clk, rst, maxi, schedule_table, max_stream_rams)
ram_set_cache = make_ram_sets(config, schedule_table, ram_dict, max_stream_rams)
control_param_dict = make_control_params(config, schedule_table)
substrm_dict = make_substreams(config, m, clk, rst, maxi, schedule_table)
stream_cache = make_streams(config, schedule_table, ram_dict, substrm_dict)
(global_addr_map, local_addr_map,
global_map_info, global_mem_map) = make_addr_map(config, objs, saxi)
if config['use_map_ram']:
global_map_ram, local_map_ram = make_addr_map_rams(config, m, clk, rst, maxi,
global_addr_map, local_addr_map)
else:
global_map_ram = None
local_map_ram = None
control_cache, main_fsm = make_controls(
config, m, clk, rst, maxi, saxi,
schedule_table, control_param_dict,
global_addr_map, local_addr_map,
global_map_ram, local_map_ram)
disable_unused_ram_ports(ram_dict)
return (ram_dict, substrm_dict, ram_set_cache, stream_cache, control_cache,
main_fsm, global_map_info, global_mem_map)まず、calc_max_stream_rams 関数で、スケジューリング結果に基づいて、生成すべきオンチップメモリの大きさと数を求めます。その結果に基づいて、make_rams 関数でメモリ回路を生成します。
make_control_params 関数では、各演算の制御パラメータ (積和演算の回数やストライド幅など) を決定します。各オペレータ回路は、複数のオペレータの間で再利用されますが、オペレータ毎に異なる振る舞いをさせる必要があります。この段階で、各オペレータの制御パラメータを求めます。
make_substreams 関数では、共有演算器 (演算器プール (Substream Pool)) を生成します。この段階で、積和演算器や加算ツリー等が生成されます。
make_streams 関数では、事前に生成したメモリや共有演算器を組み合わせて、実際に畳み込み計算等を行う、オペレータ回路全体を生成します。内部では、各オペレータ回路で占有される、比較的小規模な演算器や、共有演算器および共有メモリを接続する、チップ内ネットワークを生成しています。
その後、make_addr_map 関数で、NNgen ハードウェアの外部から制御するための AXIS レジスタを生成します。そして、make_controls 関数で、各オペレータのタイミングを管理する状態遷移機械 (FSM) を生成し、ハードウェア全体の構成要素が揃いました。
生成されたハードウェア構造は Veriloggen 形式で表現されているので、この後、実際のハードウェア記述 (Verilog HDL) のソースコードを生成しています。
まとめ
今回は、NNgen が生成するハードウェア構造と、計算グラフからハードウェアが生成されるまでの NNgen コンパイラの仕組みを解説しました。
次回は、具体的なニューラルネットワークを動かしてみましょう。
東京大学 大学院情報理工学系研究科 コンピュータ科学専攻 高前田 伸也