はじめに
皆さん、こんにちは。本コースを担当する東京大学の高前田です。
私たちの研究室、CASYS (Laboratory for Computer Architecture and Systems) では、コンピュータアーキテクチャ (コンピュータの構造や設計技術、コンピュータそのものの在り方) を中心に、FPGA や専用ハードウェアによるカスタムコンピューティング、機械学習処理などの計算対象アルゴリズムとハードウェアの協調設計、ハードウェア設計を支援する高位合成コンパイラなど、高効率で楽しい次世代コンピュータに関する研究を進めています。
自己紹介として、これまでの研究を少し紹介します。専用ハードウェア・チップについては、活性値や重みを対数 (log) で表現する対数量子化とビットシリアル演算を組み合わせた、ディープニューラルネットワーク(ディープラーニング)アクセラレータの QUEST や、組合せ最適化問題を高速に解くアクセラレータチップの STATICA などの開発に携わってきました。
ハードウェアそのものに関する研究だけではなく、ハードウェア・回路の特性を活かす、アルゴリズムとアーキテクチャの協調設計に関する研究を進めています。例えば、量子化ニューラルネットワークの量子化誤差に着目した精度向上手法の QER (Quantization Error based Regularization)、二値化ニューラルネットワークの認識精度を高めるための誤差拡散法に基づく二値化ニューラルネットワーク Dither NN や、部分順序情報を残す差分二値化による活性化関数 Delta を提案しました。最近は、ベイジアンニューラルネットワークのアルゴリズムとハードウェアアーキテクチャ、決定木・決定森のハードウェア指向アルゴリズムの研究にも取り組んでいます。
さて、前置きが長くなりましたが、本コースでは、ニューラルネットワークのモデルに特化した専用ハードウェアアクセラレータを生成する、ドメイン特化高位合成コンパイラ NNgen を用いて、FPGA 上にニューラルネットワーク処理システムを実装する方法を紹介します。また、NNgen の内部構造の解説を通じて、ドメイン特化型の高位合成ツールの作り方についても紹介できればと思います。
FPGA を用いたニューラルネットワーク処理
ニューラルネットワークの推論の計算を高速処理する方法としては、GPU を用いる他に、TPU などの専用アクセラレータチップ (俗に言うAIチップ) の利用や、CPU が持つ SIMD 演算器を活用、そして FPGA の利用など、様々な方法があり、性能、電力効率、プログラマビリティ、コストなどの観点で得失が異なります。専用アクセラレータを用いることで、高い電力効率 (消費電力あたりの速度) を達成することができますが、用途次第では、GPU や CPU を用いることでも十分な電力性能や速度を達成できることもあります。
FPGA を用いてニューラルネットワークの処理システムを実装する利点の1つは、様々な制御回路を混載するシステムを1チップで実現できる点です。FPGA は、CPU や GPU 等と比較して、多くの I/O ピンが利用可能であるため、周辺デバイスの入出力を低遅延に制御する用途に適しています。その制御において、ニューラルネットワーク等の機械学習技術を用いる場合に、FPGA 上に1チップでシステムを構築することで、入力信号に基づく認識・判断・制御を低遅延で行うことが容易になります。
NNgen とは
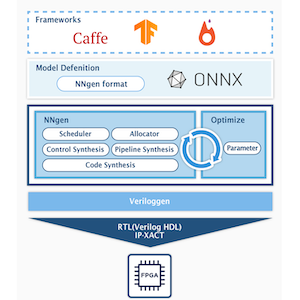
NNgen の構造を図に示します。NNgen は、ニューラルネットワークの畳み込み (Convolution) やプーリング (Pooling)、全結合 (Full-Connection) などといった、ニューラルネットワークの基本要素で構成される計算グラフ (モデル) から、そのグラフに特化した専用の処理ハードウェア回路を生成する、Python で実装されたドメイン特化型の高位合成コンパイラです。

NNgen では、ニューラルネットワークのモデルの表現方法は2つあります。1つは、各種ニューラルネットワークの演算に対応する NNgen のオペレータを組み合わせて、プログラマが明示的に計算グラフを構築するというものです。
もう1つは、Pytorch や Tensorflow といった一般的なニューラルネットワーク・フレームワークで構築された学習済みのモデルを、ONNX (Open Neural Network eXchange) と呼ばれるニューラルネットワークの共通フォーマットに変換し、その ONNX ファイルから NNgen 形式へと変換するというものです。
どちらの場合でも、NNgen は、計算グラフを解析し、必要なオペレータに対応する専用演算器アレーを持つハードウェアの Verilog HDL 記述と IP-XACT ファイルを生成します。
環境構築と NNgen のインストール
それでは、早速 NNgen を使ってみましょう。まず、NNgen を実行する環境の構築を行います。
想定する環境は以下の通りです。
- Ubuntu 18.04.4 LTS
- macOS 10.15.6 でも大丈夫です。
- Python 3.7.7
- 任意のPythonバージョンをインストールするにはpyenvが便利です。
- Ubuntu 18.04 デフォルトの3.6系でも大丈夫です。
Icarus Verilog および Verilator のインストール
NNgen のインストールをする前に、Verilog シミュレータの Icarus Verilog と Verilator をインストールしましょう。
Ubuntu 18.04 の場合は、
sudo apt install iverilog verilatorでインストールできます。
もし、macOS 上で brew を使っている場合には、
brew install icarus-verilog verilatorでインストールできます。
Python の仮想環境の作成
既存の Python の環境を壊さないようにするために、以下の手順で、ターミナル上で Python の仮想環境を作成します。
mkdir nngen_test
cd nngen_test
python3 -m venv python3_nngen
source python3_nngen/bin/activateこれで、ターミナルの表示が以下の様に変わっていれば、仮想環境の構築は成功です。

このターミナルのセッションでは、すべての Python 関連のコマンドは、今インストールした仮想環境に切り替わっています。もし、システムのデフォルトの Python 環境に戻る場合には、ターミナルのセッションを閉じるか、
deactivateと実行することで、仮想環境から抜けることができます。再度、仮想環境に戻る場合には、
cd nngen_test
source python3_nngen/bin/activateとしましょう。
Jupyter のインストール
この後のサンプルの実行に Jupyter Notebook を使うので、インストールしましょう。
Python の仮想環境上で、次のコマンドを実行します。
pip3 install jupyterJupyter へパスを通すために、一旦仮想環境から抜けて、再度入り直します。
deactivate
source python3_nngen/bin/activateNNgen のインストール
仮想環境上に、NNgen をインストールします。ここでは develop 版をインストールします。
仮想環境にいることを再度確認してください。もし万が一、仮想環境にいない状態で、以下のコマンドを実行すると、システムのデフォルトの環境に NNgen 等がインストールされてしまいますので、注意して下さい。
以下のコマンドで NNgen をダウンロードし、インストールします。NNgen のインストール時に、依存関係のある関連パッケージも自動的にインストールされます。
git clone https://github.com/NNgen/nngen.git
cd nngen
python3 setup.py installなお、本記事を執筆している段階での最新の安定版は v1.3.0 です。安定版を使う場合に、pip3 コマンドを使い、
pip3 install nngenとするだけでインストールすることができます。
以上で、NNgen を使う準備が整いました。
Hello, NNgen!
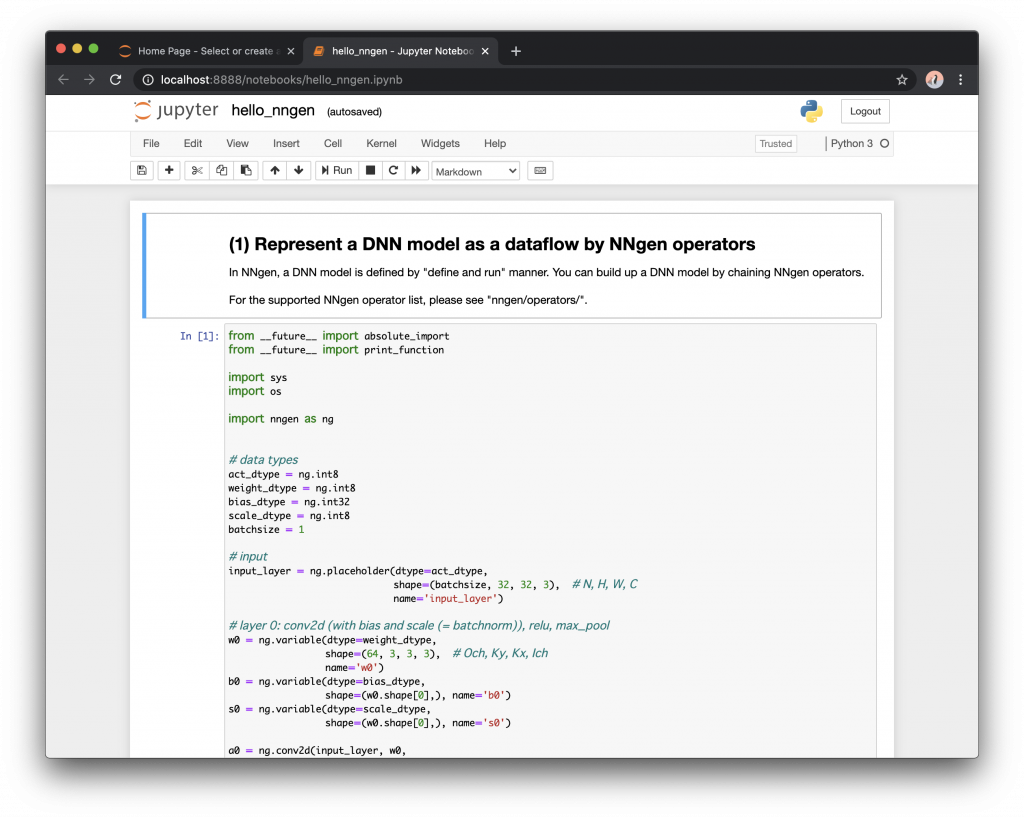
サンプルファイルを開く
先ほどの NNgen インストール時にダウンロードした NNgen ディレクトリにある、”hello_nngen.ipynb” を Jupyter Notebook で開きましょう。
nngen ディレクトリにいる状態で、
jupyter notebookと先ほどインストールした Jupyter を起動し、ブラウザ上で “hello_nngen.ipynb” を選択して、開きましょう。
以下の図のように、入力済みの Notebook が表示されるはずです。
Jupyter Notebook を使わない方は、同様の内容が記入されている “hello_nngen.py” をテキストエディタで開きましょう。
以下の手順に従って、Jupyter 上 (またはターミナル上) で順番に実行しましょう。
計算グラフの構築
今開いたサンプルは、畳み込み層2層、最大値プーリング1層、全結合層が2層で構成される、簡単なニューラルネットワークです。
まず、データ型を決めます。ここでは、入力値 (act_dtype)、重み (weight_dtype)、スケーリング係数 (scale_dtype) には8ビット整数、バイアス項には32ビット整数を用いることにします。また、バッチサイズは1とします。スケーリング係数とバイアス項は、学習済みのバッチ正規化の演算に対応します。
# data types
act_dtype = ng.int8
weight_dtype = ng.int8
bias_dtype = ng.int32
scale_dtype = ng.int8
batchsize = 1入力画像を与えるデータ置き場の placeholder を定義します。縦横 32×32 ピクセル、RGB の3チャネル画像を入力とします。
なお、NNgen のデータレイアウトは、Inner-most がチャネルの NHWC となっています。
# input
input_layer = ng.placeholder(dtype=act_dtype,
shape=(batchsize, 32, 32, 3), # N, H, W, C
name='input_layer')次に畳み込み層や全結合層を定義していきます。1層目の畳み込み、活性化関数 ReLU、最大値プーリングの箇所は次の通りです。
一般的なニューラルネットワーク・フレームワークを用いた記述と似ていることがわかります。
# layer 0: conv2d (with bias and scale (= batchnorm)), relu, max_pool
w0 = ng.variable(dtype=weight_dtype,
shape=(64, 3, 3, 3), # Och, Ky, Kx, Ich
name='w0')
b0 = ng.variable(dtype=bias_dtype,
shape=(w0.shape[0],), name='b0')
s0 = ng.variable(dtype=scale_dtype,
shape=(w0.shape[0],), name='s0')
a0 = ng.conv2d(input_layer, w0,
strides=(1, 1, 1, 1),
bias=b0,
scale=s0,
act_func=ng.relu,
dtype=act_dtype,
sum_dtype=ng.int32)
a0p = ng.max_pool_serial(a0,
ksize=(1, 2, 2, 1),
strides=(1, 2, 2, 1))学習済みパラメータの設定
計算グラフが定義できたら、次に各レイヤーに学習済みのパラメータ (重み) を設定します。ただしこの例では、学習済みのパラメータの代わりに、ランダムな浮動小数の値を設定し、後に NNgen の量子化機能を用いて整数化しています。
1層目のパラメータを設定する箇所は以下の通りです。
# --------------------
# (2) Assign weights to the NNgen operators
# --------------------
# In this example, random floating-point values are assigned.
# In a real case, you should assign actual weight values
# obtianed by a training on DNN framework.
# If you don't you NNgen's quantizer, you can assign integer weights to each tensor.
import numpy as np
w0_value = np.random.normal(size=w0.length).reshape(w0.shape)
w0_value = np.clip(w0_value, -3.0, 3.0)
w0.set_value(w0_value)
b0_value = np.random.normal(size=b0.length).reshape(b0.shape)
b0_value = np.clip(b0_value, -3.0, 3.0)
b0.set_value(b0_value)
s0_value = np.ones(s0.shape)
s0.set_value(s0_value)量子化: 浮動小数のパラメータを整数に変換する
NNgen で生成されるアクセラレータは、現時点では浮動小数点演算をサポートしておらず、整数 (または固定小数) のみが利用できます。
多くの FPGA では浮動小数点演算の実装には、整数演算よりも多くの回路資源を消費してしまうため、回路の観点では低ビット幅の整数を用いることが好ましいです。
このサンプルでは、先ほど設定した浮動小数のランダムなパラメータを、NNgen の量子化機能を用いて整数に変換しています。
整数に量子化する際には、各レイヤーの計算結果が桁あふれしないように、右シフトにより適切に値を切り捨てる処理が必要になります。右シフト量を決定するためには、入力データがどのような傾向にあるかの情報が必要となります。ここでは、一般的な画像認識データセットの ImageNet の平均・分散を想定して、量子化を行います。
# Quantizing the floating-point weights by the NNgen quantizer.
# Alternatively, you can assign integer weights by yourself to each tensor.
imagenet_mean = np.array([0.485, 0.456, 0.406]).astype(np.float32)
imagenet_std = np.array([0.229, 0.224, 0.225]).astype(np.float32)
if act_dtype.width > 8:
act_scale_factor = 128
else:
act_scale_factor = int(round(2 ** (act_dtype.width - 1) * 0.5))
input_scale_factors = {'input_layer': act_scale_factor}
input_means = {'input_layer': imagenet_mean * act_scale_factor}
input_stds = {'input_layer': imagenet_std * act_scale_factor}
ng.quantize([output_layer], input_scale_factors, input_means, input_stds)ハードウェアの並列度の設定
FPGA 上にニューラルネットワーク処理回路を実現する場合に悩ましいのが、どこをどのように並列処理するかです。並列化により、計算時間の短縮は期待できますが、その分のより多くの回路資源を消費してしまいます。NNgen では、プログラマが各層の並列度を自由に設定できるようになっており、設計者の腕の見せ所です (が、自動化できると嬉しいですね・・・)。
この例では、畳み込み層の入力チャネル方向と出力チャネル方向のそれぞれで、デフォルトの2倍に並列度、あわせて4倍の並列度を指定しています。NNgen の畳み込み層の計算は、デフォルトでカーネルサイズ分は並列処理するようになっていますが、それを更にチャネル方向に拡張した形になります。
# --------------------
# (3) Assign hardware attributes
# --------------------
# conv2d, matmul
# par_ich: parallelism in input-channel
# par_och: parallelism in output-channel
# par_col: parallelism in pixel column
# par_row: parallelism in pixel row
par_ich = 2
par_och = 2
a0.attribute(par_ich=par_ich, par_och=par_och)
a1.attribute(par_ich=par_ich, par_och=par_och)
a2.attribute(par_ich=par_ich, par_och=par_och)
output_layer.attribute(par_ich=par_ich, par_och=par_och)ソフトウェア実行による計算グラフの検証
ここまでで、計算グラフ (モデル) の定義、重みパラメータの設定と量子化、並列度の指定が完了しました。ここで一旦、この計算グラフからハードウェアを生成する前に、定義した計算グラフが量子化後に所望の動作をするか確認しましょう。
NNgen 上の計算グラフは、入力データを引数として渡すことで、Python のソフトウェアとして実行することができます。内部は、ハードウェアと同じ整数の演算結果を生成する、各オペレータに対応する関数で構成されています。この実行結果と、元々の浮動小数での計算結果を比較して期待通りの動作をするかどうか、ハードウェア化の前に確認できます。
# --------------------
# (4) Verify the DNN model behavior by executing the NNgen dataflow as a software
# --------------------
# In this example, random integer values are assigned.
# In real case, you should assign actual integer activation values, such as an image.
input_layer_value = np.random.normal(size=input_layer.length).reshape(input_layer.shape)
input_layer_value = input_layer_value * imagenet_std + imagenet_mean
input_layer_value = np.clip(input_layer_value, -3.0, 3.0)
input_layer_value = input_layer_value * act_scale_factor
input_layer_value = np.clip(input_layer_value,
-1 * 2 ** (act_dtype.width - 1) - 1, 2 ** (act_dtype.width - 1))
input_layer_value = np.round(input_layer_value).astype(np.int64)
eval_outs = ng.eval([output_layer], input_layer=input_layer_value)
output_layer_value = eval_outs[0]
print(output_layer_value)今回の実行結果は以下のような値だったようです。
[[ -1 7 0 -14 -5 -2 -9 7 21 12]]ハードウェア記述の生成
ソフトウェアでの検証が終わりましたので、遂にハードウェア記述を生成します。NNgen は、計算グラフからハードウェア構造の Verilog HDL 記述と IP-XACT 形式の設定ファイルを生成します。生成された Verilog HDL のファイルおよび IP-XACT ファイルを、FPGA の CAD ツールにインポートし、適切に他の IP コアと接続することで、システム化できます。
今回は、IP-XACT 形式の IP コアを生成します。
# --------------------
# (5) Convert the NNgen dataflow to a hardware description (Verilog HDL and IP-XACT)
# --------------------
silent = False
axi_datawidth = 32
# to Veriloggen object
# targ = ng.to_veriloggen([output_layer], 'hello_nngen', silent=silent,
# config={'maxi_datawidth': axi_datawidth})
# to IP-XACT (the method returns Veriloggen object, as well as to_veriloggen)
targ = ng.to_ipxact([output_layer], 'hello_nngen', silent=silent,
config={'maxi_datawidth': axi_datawidth})
print('# IP-XACT was generated. Check the current directory.')Verilog シミュレーションおよび実機動作用のパラメータファイルの保存
先ほど各オペレータに設定した重みパラメータは、量子化機能により整数化した後、単一ファイルへと変換する必要があります。
FPGA 上の実機では、指定されたメモリアドレスに単一ファイル化されたパラメータを予め展開することで、生成されたハードウェア内の DMA 回路が自動的にパラメータを読み出し、計算を行います。Verilog シミュレーションの場合も同様に、シミュレーション用のメモリ上に単一ファイル化されたパラメータを展開することで、ハードウェアが同様の振る舞いを行います。
# --------------------
# (6) Save the quantized weights
# --------------------
# convert weight values to a memory image:
# on a real FPGA platform, this image will be used as a part of the model definition.
param_filename = 'hello_nngen.npy'
chunk_size = 64
param_data = ng.export_ndarray([output_layer], chunk_size)
np.save(param_filename, param_data)Verilog シミュレータを用いた動作確認
最後に、Verilog シミュレータを用いて、今回構築した計算グラフに対応するハードウェア・アクセラレータの動作を確認しましょう。
NNgen の内部でも用いている、マルチパラダイム型高位合成コンパイラ Veriloggen を用いて、テストベンチを作ります。実は、先ほど IP-XACT ファイルを生成した際に、Veriloggen におけるハードウェア構造表現のオブジェクトも生成されています。そのハードウェア構造を対象にシミュレーションします。この例では、Verilog シミュレータに Verilator を用いています。
# --------------------
# (7) Simulate the generated hardware by Veriloggen and Verilog simulator
# --------------------
# If you don't check the RTL behavior, exit here.
# print('# Skipping RTL simulation. If you simulate the RTL behavior, comment out the next line.')
# sys.exit()
import math
from veriloggen import *
import veriloggen.thread as vthread
import veriloggen.types.axi as axi
outputfile = 'hello_nngen.out'
filename = 'hello_nngen.v'
# simtype = 'iverilog'
simtype = 'verilator'
param_bytes = len(param_data)
variable_addr = int(
math.ceil((input_layer.addr + input_layer.memory_size) / chunk_size)) * chunk_size
check_addr = int(math.ceil((variable_addr + param_bytes) / chunk_size)) * chunk_size
tmp_addr = int(math.ceil((check_addr + output_layer.memory_size) / chunk_size)) * chunk_size
memimg_datawidth = 32
mem = np.zeros([1024 * 1024 * 256 // memimg_datawidth], dtype=np.int64)
mem = mem + [100]
# placeholder
axi.set_memory(mem, input_layer_value, memimg_datawidth,
act_dtype.width, input_layer.addr,
max(int(math.ceil(axi_datawidth / act_dtype.width)), par_ich))
# parameters (variable and constant)
axi.set_memory(mem, param_data, memimg_datawidth,
8, variable_addr)
# verification data
axi.set_memory(mem, output_layer_value, memimg_datawidth,
act_dtype.width, check_addr,
max(int(math.ceil(axi_datawidth / act_dtype.width)), par_och))
# test controller
m = Module('test')
params = m.copy_params(targ)
ports = m.copy_sim_ports(targ)
clk = ports['CLK']
resetn = ports['RESETN']
rst = m.Wire('RST')
rst.assign(Not(resetn))
# AXI memory model
if outputfile is None:
outputfile = os.path.splitext(os.path.basename(__file__))[0] + '.out'
memimg_name = 'memimg_' + outputfile
memory = axi.AxiMemoryModel(m, 'memory', clk, rst,
datawidth=axi_datawidth,
memimg=mem, memimg_name=memimg_name,
memimg_datawidth=memimg_datawidth)
memory.connect(ports, 'maxi')
# AXI-Slave controller
_saxi = vthread.AXIMLite(m, '_saxi', clk, rst, noio=True)
_saxi.connect(ports, 'saxi')
# timer
time_counter = m.Reg('time_counter', 32, initval=0)
seq = Seq(m, 'seq', clk, rst)
seq(
time_counter.inc()
)
def ctrl():
for i in range(100):
pass
ng.sim.set_global_addrs(_saxi, tmp_addr)
start_time = time_counter.value
ng.sim.start(_saxi)
print('# start')
ng.sim.wait(_saxi)
end_time = time_counter.value
print('# end')
print('# execution cycles: %d' % (end_time - start_time))
# verify
ok = True
for bat in range(output_layer.shape[0]):
for x in range(output_layer.shape[1]):
orig = memory.read_word(bat * output_layer.aligned_shape[1] + x,
output_layer.addr, act_dtype.width)
check = memory.read_word(bat * output_layer.aligned_shape[1] + x,
check_addr, act_dtype.width)
if vthread.verilog.NotEql(orig, check):
print('NG (', bat, x,
') orig: ', orig, ' check: ', check)
ok = False
else:
print('OK (', bat, x,
') orig: ', orig, ' check: ', check)
if ok:
print('# verify: PASSED')
else:
print('# verify: FAILED')
vthread.finish()
th = vthread.Thread(m, 'th_ctrl', clk, rst, ctrl)
fsm = th.start()
uut = m.Instance(targ, 'uut',
params=m.connect_params(targ),
ports=m.connect_ports(targ))
# simulation.setup_waveform(m, uut)
simulation.setup_clock(m, clk, hperiod=5)
init = simulation.setup_reset(m, resetn, m.make_reset(), period=100, polarity='low')
init.add(
Delay(10000000),
Systask('finish'),
)
# output source code
if filename is not None:
m.to_verilog(filename)
# run simulation
sim = simulation.Simulator(m, sim=simtype)
rslt = sim.run(outputfile=outputfile)
print(rslt)今回の最終的なシミュレーション結果は以下の通りでした。先ほどのソフトウェアによる検証結果と一致しています。
# start
# end
# execution cycles: 1906729
OK ( 0 0 ) orig: -1 check: -1
OK ( 0 1 ) orig: 7 check: 7
OK ( 0 2 ) orig: 0 check: 0
OK ( 0 3 ) orig: -14 check: -14
OK ( 0 4 ) orig: -5 check: -5
OK ( 0 5 ) orig: -2 check: -2
OK ( 0 6 ) orig: -9 check: -9
OK ( 0 7 ) orig: 7 check: 7
OK ( 0 8 ) orig: 21 check: 21
OK ( 0 9 ) orig: 12 check: 12
# verify: PASSED
- hello_nngen.out/out.v:1092: Verilog $finish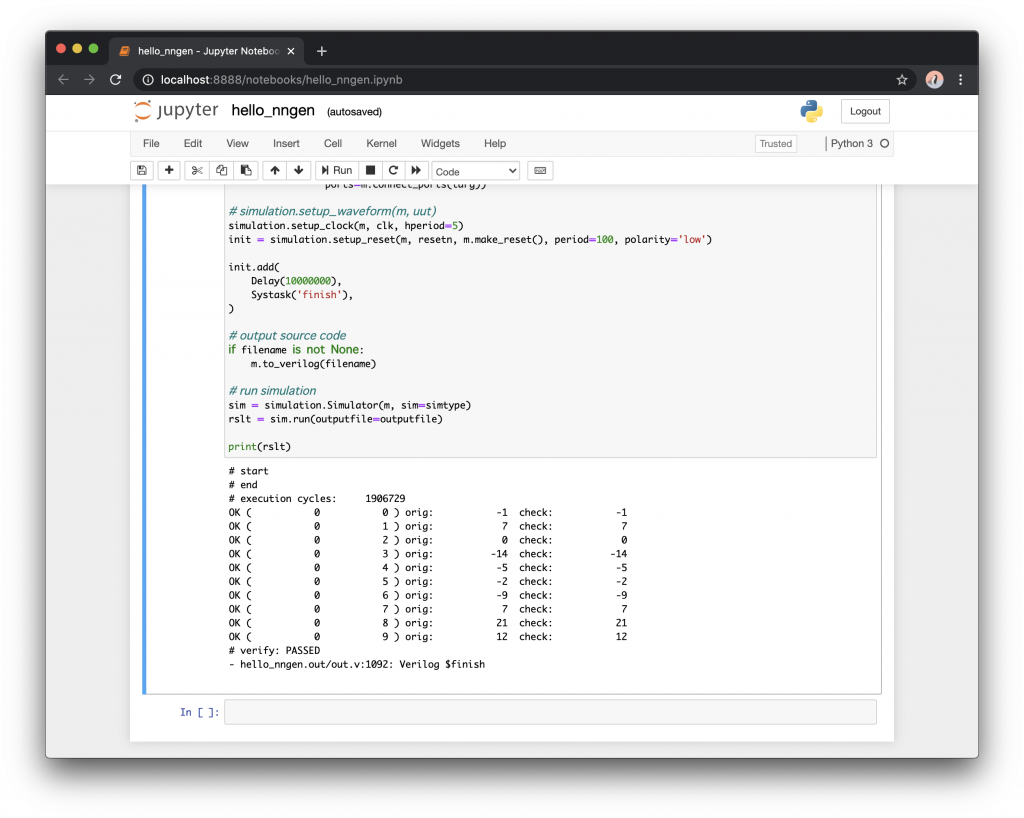
せっかくですので、生成された Verilog HDL のファイルも見てみましょう。hello_nngen_v1_0/hdl/hello_nngen.v を開きましょう。
module hello_nngen
(
input CLK,
input RESETN,
output reg [32-1:0] maxi_awaddr,
output reg [8-1:0] maxi_awlen,
output [3-1:0] maxi_awsize,
output [2-1:0] maxi_awburst,
output [1-1:0] maxi_awlock,
output [4-1:0] maxi_awcache,
output [3-1:0] maxi_awprot,
output [4-1:0] maxi_awqos,
output [2-1:0] maxi_awuser,
output reg maxi_awvalid,
input maxi_awready,
output reg [32-1:0] maxi_wdata,
output reg [4-1:0] maxi_wstrb,
output reg maxi_wlast,
output reg maxi_wvalid,
input maxi_wready,
input [2-1:0] maxi_bresp,
input maxi_bvalid,
output maxi_bready,
output reg [32-1:0] maxi_araddr,
output reg [8-1:0] maxi_arlen,
output [3-1:0] maxi_arsize,
output [2-1:0] maxi_arburst,
output [1-1:0] maxi_arlock,
output [4-1:0] maxi_arcache,
output [3-1:0] maxi_arprot,
output [4-1:0] maxi_arqos,
output [2-1:0] maxi_aruser,
output reg maxi_arvalid,
input maxi_arready,
input [32-1:0] maxi_rdata,
input [2-1:0] maxi_rresp,
input maxi_rlast,
input maxi_rvalid,
output maxi_rready,
input [32-1:0] saxi_awaddr,
input [4-1:0] saxi_awcache,
input [3-1:0] saxi_awprot,
input saxi_awvalid,
output saxi_awready,
input [32-1:0] saxi_wdata,
input [4-1:0] saxi_wstrb,
input saxi_wvalid,
output saxi_wready,
output [2-1:0] saxi_bresp,
output reg saxi_bvalid,
input saxi_bready,
input [32-1:0] saxi_araddr,
input [4-1:0] saxi_arcache,
input [3-1:0] saxi_arprot,
input saxi_arvalid,
output saxi_arready,
output reg [32-1:0] saxi_rdata,
output [2-1:0] saxi_rresp,
output reg saxi_rvalid,
input saxi_rready
);
// ...何やら巨大な Verilog HDL のファイルが生成されています。これが、定義した計算グラフに特化したニューラルネットワークアクセラレータのハードウェア記述です。メモリや乗算器などのインスタンスが多数定義されていることがわかります。
まとめ
いかがでしたでしょうか?今回は、NNgen のインストールと、シンプルな畳み込みニューラルネットワークのハードウェアを生成し、Verilog シミュレータでその動作を確認しました。
次回、NNgen が生成するハードウェア・アーキテクチャの構成を説明します。
東京大学 高前田