
前回は Vitis 開発環境が従来の課題をどのように解決するかについて解説しました。さらに ACRi ルーム (FPGA 利用環境) を使って実際にツールとハードウェアを動かしてみました。
今回は高いスループット、超低遅延と低消費電力を同時に実現する Vitis AI について解説します。さらに FPGA を使用して画像認識をおこなうまでのフローを ACRi ルームの FPGA 環境を使用してひととおり体験しましょう。
Vitis AI とは
Vitis AI 開発環境は、エッジデバイスと Alveo アクセラレータカードの両方を含むザイリンクス社のハードウェアプラットフォーム向け AI 推論開発向け開発キットです。最適化された IP コア、開発ツール、ソフトウェアライブラリ、ネットワークモデル、サンプルデザインが含まれています。
ベースとなる FPGA や ACAP (Adaptive Compute Acceleration Platform ; 新世代のプログラマブルロジックデバイス) を抽象化することにより、FPGA の設計経験がないユーザーでもこれらの優れたハードウェアプラットフォームが持つポテンシャルを十分に引き出し、高いスループット、低消費電力、低レイテンシーな深層学習推論アプリケーションを容易に開発することが可能です。
応用事例
FPGA の特性を生かした事例として太陽電池駆動の AI 内蔵カメラについて第一回のブログで触れました。
ほかの事例として、GPU を使用して検証した自動駐車システムを FPGA に置き換えて5個のカメラと12個の超音波レーダーのデータをまとめるセンサーフュージョン機能と独自開発の深層学習推論の機能を一体化することで世界初とする量産対応自動運転コンピュートユニットを発表したプラットフォームベンダーも現れました。
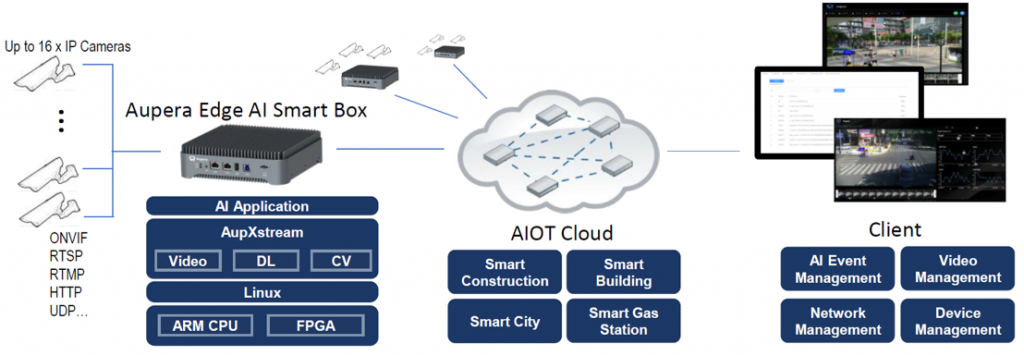
FPGA を搭載したエッジ AI スマートボックスはスループット、精度、コストパフォーマンス、厳しい環境での信頼性の高さが評価され、ホテルやオフィスビルでの顔認証、屋外の工事現場でのヘルメットやベストの安全装備装着確認などで幅広く商用運用されています。 (ウェビナー (英語) による解説はこちら)
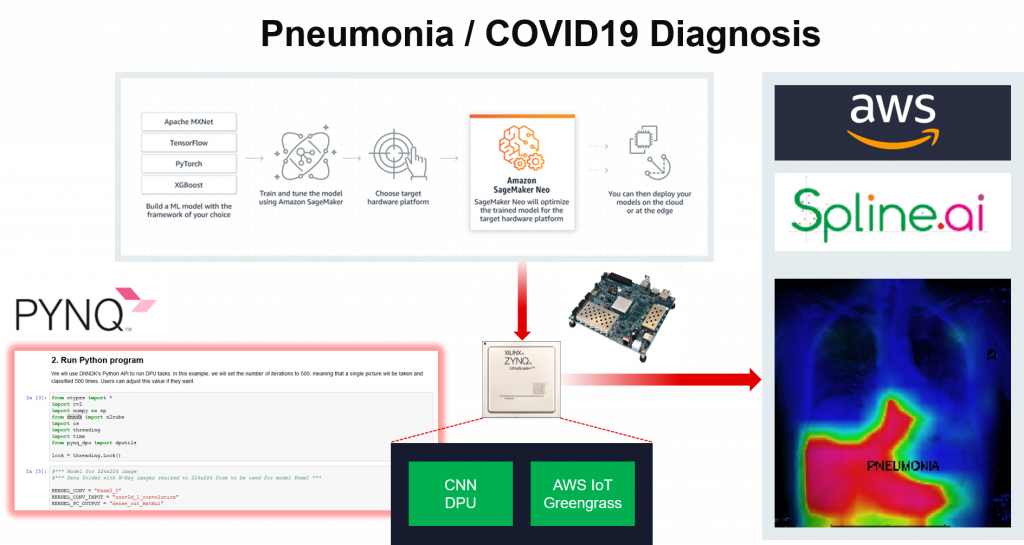
医療分野ではクラウドでディープラーニングの学習を実行し、エッジに推論プロセッサを搭載した FPGA を使用することにより X 線写真から一般的な肺炎と新型肺炎の判別を10 usec 以下で行うシステムを構築しました。これにより、判定精度および速度の向上と医療従事者の負担軽減を同時に実現しています。(ウェビナー (英語) による解説はこちら)
特長
これまで述べてきた FPGA の特徴は Vitis AI ディープラーニングのアプリケーションに当てはまります。すなわち
(1) 遅延時間とスループットの両立
(2) 消費電力の低減
(3) エッジとクラウドの双方に実装が容易
(4) 最新技術に短期間で対応できる
(5) 周辺機能の一体化によるシステムレベルの性能向上、消費電力低減、小型化、信頼性向上、コスト低減
“Today’s AI productization challenges demand domain specific architectures” で触れられているように、AI 実装の効率化にはおもに3つの側面があります。
1) データの流れ (Data path)
2) データのビット幅 (Precision)
3) メモリの階層構成 (Memory Hierarchy)
2) データのビット幅については以前触れた INT4 データへの流れのほかに1ビット化などさまざまな研究が日々なされています。上記の英文記事にあるとおり現時点のディープラーニングソリューションはハードウェアの持っているリソースを十分活用し切れておらず、改善する余地が多分にあると考えられています。用途に最適化したハードウェア、ソフトウェアを持つ DSA (Domain Specific Architecture) が待ち望まれるところですが、ディープラーニングの実現理論も日々進化しています。最新技術に短期間で対応できる FPGA はこのような目的に適しています。さらに次回解説する新しい世代の ACAP はロジックのプログラマビリティを保ったまま信号処理能力を増強しています。
構成要素
Vitis AI は以下の要素から構成されています。

ハードウェア
Deep Learning Processing Unit (DPU)
DPU はディープニューラルネットワーク向けに最適化されたプログラム可能なエンジンです。既にハードウェアに実装されたパラメーター指定可能な IP コアであり、デバイス上に実装するための配置、配線工程が不要のため、プロセッサ向けのソフトウェア開発と同じ感覚で開発が進められます。DPU には、Vitis AI 用の命令セットが含まれているため、多くのディープラーニングネットワークを効率的に実装できます。
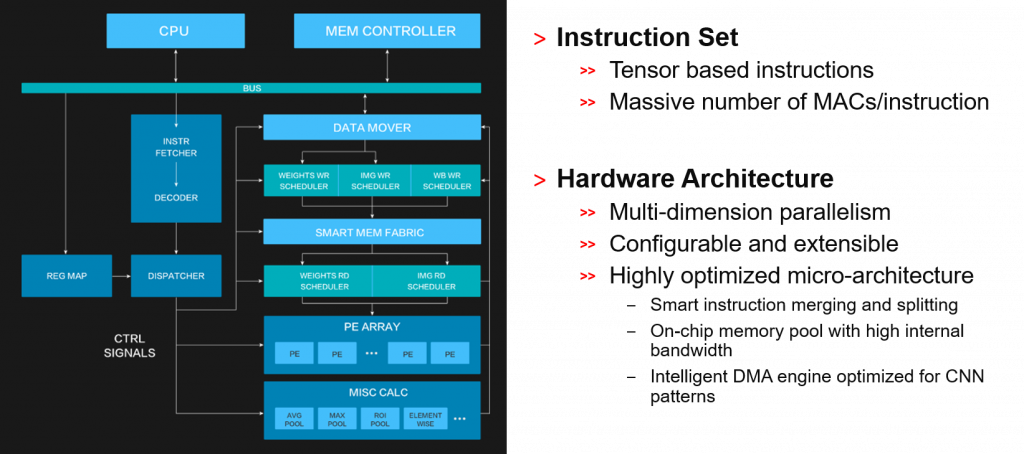
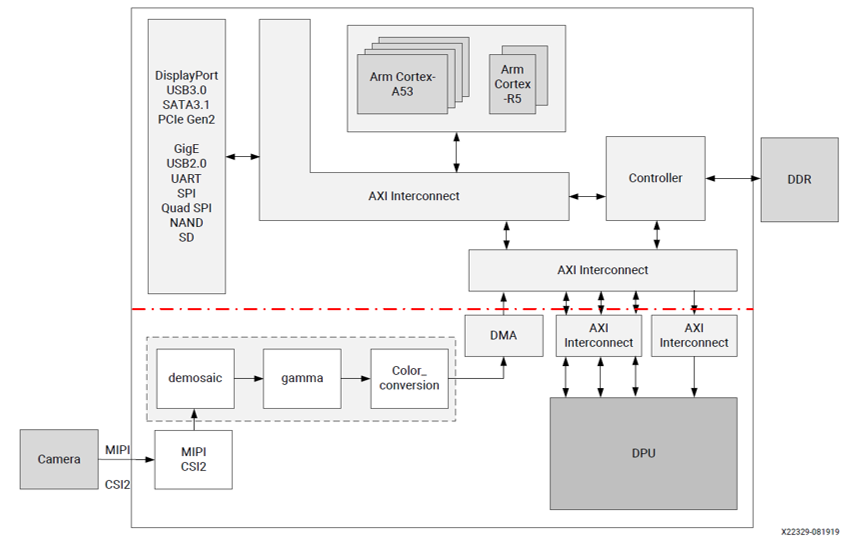
モデル、ライブラリ
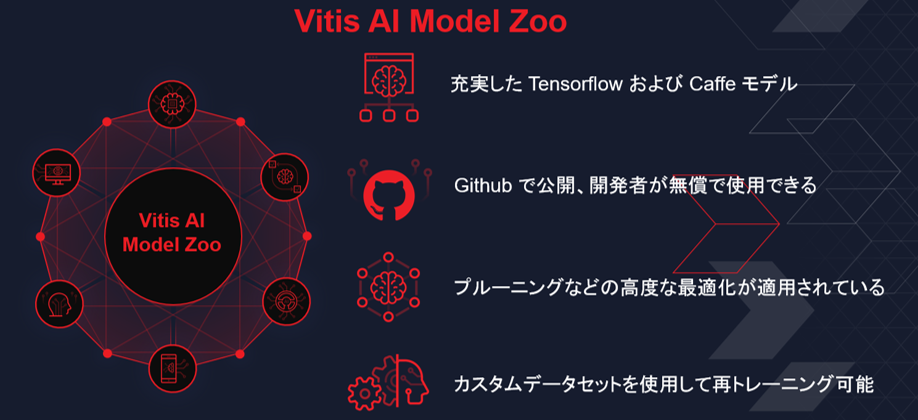
AI Model Zoo
AI Model Zoo には、ザイリンクス プラットフォームで深層学習推論をすばやく運用するための、最適化済み深層学習モデルが含まれています。これらのモデルは、ADAS、自動運転、ビデオ監視、ロボット工学、データセンターなど、さまざまなアプリケーションに対応します。これらの学習済みモデルを利用することで、深層学習推論の高速化が可能になります。詳細は、https://github.com/Xilinx/Vitis-AI/tree/master/AI-Model-Zoo を参照してください。
AI ライブラリ
Vitis AI ライブラリは、DPU を使用して効率的な AI 推論を実現するために構築された高レベルのライブラリと API で構成されています。統合 API を備えた Vitis AI ランタイム (後述) をベースに構築されています。Vitis AI ライブラリは、効率的かつ高品質のニューラルネットワークをカプセル化することで、統合された使いやすいインターフェイスを提供します。これにより、深層学習や FPGA について深い知識がなくても深層学習ニューラルネットワークを容易に使用することが可能です。
開発ツール
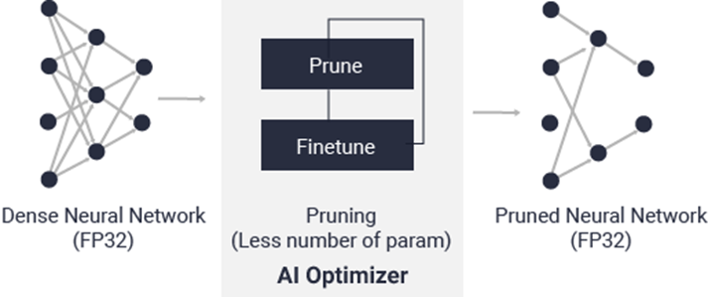
AI オプティマイザー
世界最先端のモデル圧縮技術により、精度への影響を最小限に抑えながら、複雑なモデルを 1/5 から最大 1/50 までに圧縮できます。これにより、演算処理量、消費電力を大幅に削減すると同時にスループットの向上とレイテンシーの低減を実現します。AI オプティマイザーはオプションとなっており、別途ライセンスが必要です。

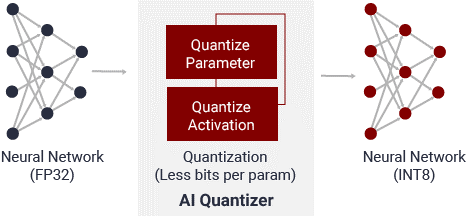
AI クオンタイザー
AI クオンタイザーは、32 ビット浮動小数点の重みやアクティベーションを INT8 などの固定小数点に量子化変換することで、予測精度を損なうことなく計算の複雑度を大幅に軽減するツールです。固定小数点のネットワークモデルは必要なメモリ帯域幅が小さいため、浮動小数点モデルよりも高速で電力効率に優れています。
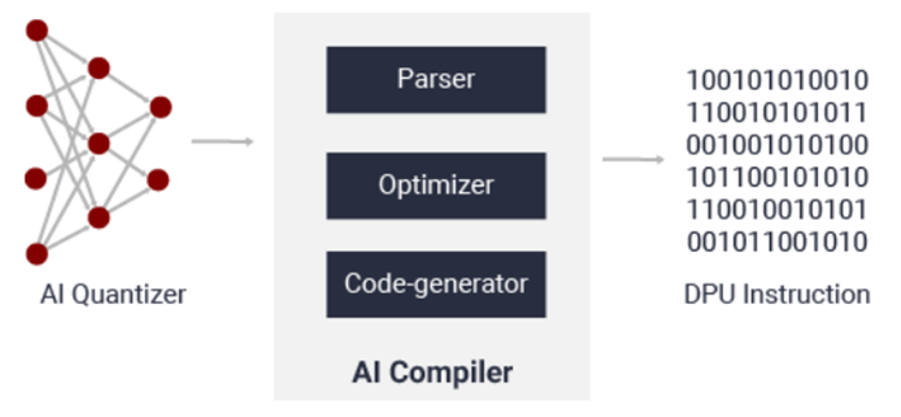
AI コンパイラ
AI コンパイラは、AI モデルを DPU で実行可能な効率の高い命令セットとデータフローにマップします。また、レイヤーの融合や命令スケジューリングなどの高度な最適化を実行し、オンチップメモリを可能な限り再利用します。
AI プロファイラー
Vitis AI プロファイラーは、AI アプリケーションのプロファイリングと視覚化を可能にします。ボトルネックの認識や多様なデバイス間における演算リソースの割り当てに役立ちます。コードの変更や再コンパイルの必要はありません。関数呼び出しや実行時間、CPU、DPU、メモリなどの使用率も取得できます。
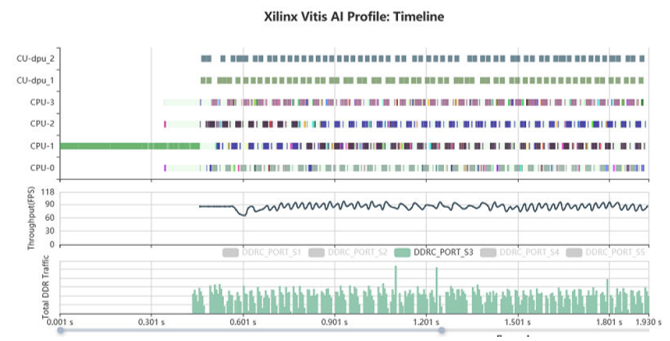
ランタイムソフトウェア
Vitis AI ランタイムにより、アプリケーションはクラウドとエッジの両方に対応する高レベルの統合されたランタイム API を使用できます。これにより、クラウドとエッジ間の運用がシームレスかつ効率的になります。Vitis AI ランタイム API の機能は次のとおりです。
• アクセラレータへジョブを非同期送信
• アクセラレータからジョブを非同期取得
• C++ および Python で実装
• マルチスレッド および マルチプロセスの実行に対応
Vitis AI 関連の詳細は下記の資料を参考にして下さい。
– Vitis AI ユーザー ガイド (UG1414) v1.1/v1.2/オンライン
– AI オプティマイザーユーザーガイド (UG1333) v1.1/v1.2/オンライン
– Vitis AI ライブラリ ユーザーガイド (UG1354) v1.1/v1.2/オンライン
(v1.2 日本語版 pdf および オンラインマニュアルは9月リリース予定)
– Zynq DPU (PG338) v3.1/v3.2/オンライン
(v3.2 日本語版 pdf および オンラインマニュアルは9月リリース予定)
ACRi ルームを使って試してみよう!
それでは ACRi ルームの環境を使って Vitis AI 開発環境を試して理解を深めましょう。今回は以下の2つのテーマに取り組みます。
(1) デモを使って動作確認
(2) チュートリアルによる設計フローの体験
デモを使って動作確認
Vitis AI の実行方法 (U50 サーバ向け) に解説されている構築済みの環境を使用して Alveo U50 の上で推論を実行し、静止画と動画のセグメンテーションができることを確認してみましょう。
サーバーの予約や環境設定などの手順は ACRi ルームのホームページに説明があります。前回のブログでも解説しました。前回は Vitis の体験のためにプラットフォームとして Alveo U200 が搭載されている as001 のサーバーを使用しました。今回は Alveo U50 が搭載されている as004 のサーバーを使用します。
手順に従って静止画をシングルスレッドでセグメンテーションした結果と動画を8スレッドでリアルタイムにセグメンテーションした結果は以下のような画像になります。動画は 24 fps 程度のスループットで正しくセグメンテーションできているようですね。



チュートリアルによる設計フローの体験
U50 と Alveo AI が正常に動作していることが確認できたので、チュートリアルファイルを使って Vitis AI 開発フローを一通り体験してみましょう。このチュートリアルもデモと同じく Alveo U50 を使用します。
ここからは Using DenseNetX on the Xilinx Alveo U50 Accelerator Card の内容に沿って要点を補足しながら進めます。
概要 (Introduction)
本チュートリアルでは TensorFlow Keras フレームワークを使用し DenseNet という深層学習 CNN (Convolutional Neural Network) を DPUv3E アクセラレータコアを使用して実装、評価する手順を一通り体験します。アプリケーションコードは Python で記述されており、Unified API、VART (Vitis AI Runtime) を介して DPU とやり取りをします。
チュートリアルでは以下のステップを実行します。
1) 深層学習ネットワークの評価のトレーニング
2) Keras のチェックポイント HDF5 フォーマット から TensorFlow Protocol Buffers 互換フォーマットへ変換
3) フォーマットを変換したデータを CPU ソフトウェアにより評価、確認
4) 学習モデルを浮動小数点から8ビット整数に量子化
5) 量子化したモデルを CPU ソフトウェアにより評価、確認
6) 量子化したモデルを U50 にロードした DPUv3E で動作するようコンパイル
7) コンパイルしたモデルを U50 にロードして評価
なお、1) トレーニングは数時間を要するため、今回は予めトレーニング済みのモデルを使用します。
チュートリアルに入る前に使用するテストデータとネットワークモデルについて説明します。
CIFAR-10 データセット
評価データとして CIFAR-10 を使用します。このデータセットは 32 x 32 x 8ビットの小さなカラー静止画で10個の分類で構成されています。32×32 の解像度は実用的と言えないかも知れませんが無償で公開されており、チュートリアルには十分有益な題材と思います。
下記の画像は使用する10,000のテストファイルの一部ですが、解像度が 32×32 だけあって拡大するとぼやけて見えて、逆にこのような画像を Vitis AI で生成したソリューションが正しく判定できるものなのか興味が湧きますね。

DenseNetX CNN
DenseNet という Huang 氏らによって提唱された “Densely Connected Convolutional Networks” をベースに Vitis AI 向けにモディファイした CNN ネットワークを使用します。詳細に知りたいかたは英文の説明、論文、チュートリアルに含まれる DenseNetX.py等を参照してください。
では実際に動かす工程に入りましょう。
Step 0 – チュートリアルファイルのダウンロードと環境の準備 (Downloading the Design and Setting Up the Workspace)
まず、チュートリアルに使用するファイルをダウンロードします。ACRi ルームのサーバからウェブにあるファイルを直接ダウンロードすることができないため、初めに手元の PC へ Vitis AI チュートリアルのダウンロードし、PC から ACRi ルームサーバへ転送します。ブラウザからダウンロードする場合は下記のサイトの緑色の “Code” アイコンから “Download ZIP” を選択してダウンロードします。
執筆時点において Vitis AI の最新版はバージョン1.2となります。バージョン1.1 から多くの機能追加やパフォーマンス向上を実現しています。Vitis AI の実行方法 (U50 サーバ向け) に説明があるとおり ACRi ルームで現在お試しいただける環境が Vitis AI 1.1 のため、今回は 1.1 を使用します。
チュートリアルの zip ファイルをパソコンから Alveo サーバに送信するのに WinSCP を使う場合は前回触れた「WinSCP を使う場合」のページの説明が参考になります。
Alveo サーバにログインして zip ファイルをスクラッチ領域に展開し、リファレンスコードのあるディレクトリへ移動します。
$ cd /scratch
$ unzip ~/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2.zip
$ cd /scratch/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2/filesVitis AI のセットアップおよびチュートリアルの環境設定を行います。
source /opt/vitis_ai/setup.sh
source 0_setenv.shStep 1 – トレーニング (Training)
トレーニングの工程は数時間かかるため今回は実行せず、かわりに Keras 学習済みモデルを準備します。次に files フォルダの下に移ります。
cd build/keras_model
unzip ../../pretrained/k_model.zip
cd ../..Step 2 – Keras HDF5 チェックポイントから TensorFlow Frozen Graph への変換 (Convert the Keras HDF5 Checkpoint to a TensorFlow Frozen Graph)
Vitis AI が Keras のチェックポイント HDF5 フォーマットをそのまま読み込むことに対応していないため、HDF5 を TensorFlow Frozen Graph Protocol Buffers 互換フォーマットへ変換します。
source 2_keras2tf.shStep 3 – Frozen Graph の評価 (Evaluate the Frozen Graph)
この時点では浮動小数点データ形式である Frozen Graph を CPU ソフトウェアにより評価、確認します。チュートリアルファイルのダウンロードと同様の手順で前述した CIFAR-10 データセットを手元の PC へダウンロードし、PC から ACRi ルームサーバへ転送を行います。
ダウンロード:https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
mkdir -p ~/.keras/datasets
mv cifar-10-python.tar.gz ~/.keras/datasets/cifar-10-batches-py.tar.gz
source 3_eval_frozen.sh実行結果から、約93.4%の正解率であることが確認できました。
(vitis-ai-tensorflow) tu_yhorie_xilinx@as004:/scratch/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2/files$ source 3_eval_frozen.sh
-----------------------------------------
EVALUATING THE FROZEN GRAPH..
-----------------------------------------
100% (66 of 66) |########################| Elapsed Time: 0:00:33 Time: 0:00:33
------------------------------------
TensorFlow version : 1.15.2
3.6.10 |Anaconda, Inc.| (default, Mar 25 2020, 23:51:54)
[GCC 7.3.0]
------------------------------------
Command line options:
--graph : ./build/freeze/frozen_graph.pb
--input_node : input_1
--output_node: dense/BiasAdd
--batchsize : 150
------------------------------------
Correct: 9251 Wrong: 649 Accuracy: 0.9344444444444444
-----------------------------------------
EVALUATION COMPLETED
-----------------------------------------Step 4 – Frozen Graph の量子化 (Quantize the Frozen Graph)
Step 2 で使用した浮動小数点データ形式の Frozen Graph を DPU で実行可能な 8ビットint 形式に変換 (量子化) します。量子化の処理は精度を確保するためのキャリブレーション処理を含んでいます。calib_iter (キャリブレーションの繰り返し回数) = 10 と設定してあり、実行完了までには約5分かかります。
source 4_quant.sh量子化の処理はスクリプトに含まれている vai_q_tensorflow コマンドが実行します。量子化が正常に完了すると deploy_model.pb (量子化が完了した DPU 用のファイル) および quantize_eval_model.pb (量子化結果を CPU で評価するファイル) の2つのファイルが ./files/build/quantize フォルダに生成されます。
Step 5 – 量子化されたモデルの評価 (Evaluate the Quantized Model)
Frozen Graph を32ビット浮動小数点から8ビット int 形式に変換 (量子化) した結果を確認するため、8ビット int 形式に量子化したデータ quantize_eval_model.pb を使用して CPU ソフトウェアにより評価、確認します。実行完了までには約7分かかります。
source 5_eval_quant.sh実行結果を見ると、約92.8%の正解率であることが確認できました。量子化前は93.4%でしたので、データサイズや演算量を大幅に削減しても正解率にはほとんど影響が無いと判断できます。
(vitis-ai-tensorflow) tu_yhorie_xilinx@as004:/scratch/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2/files$ source 5_eval_quant.sh
-----------------------------------------
EVALUATING THE QUANTIZED GRAPH..
-----------------------------------------
100% (100 of 100) |######################| Elapsed Time: 0:06:53 Time: 0:06:53
------------------------------------
TensorFlow version : 1.15.2
3.6.10 |Anaconda, Inc.| (default, Mar 25 2020, 23:51:54)
[GCC 7.3.0]
------------------------------------
Command line options:
--graph : ./build/quantize/quantize_eval_model.pb
--input_node : input_1
--output_node: dense/BiasAdd
--batchsize : 100
------------------------------------
Correct: 9278 Wrong: 722 Accuracy: 0.9278
-----------------------------------------
EVALUATION COMPLETEDStep 6 – コンパイル (Compile the Quantized Model)
量子化された .pb ファイルをコンパイルして DPU で実行可能な ELF 形式の実行ファイルを生成します。実際のコンパイル処理はスクリプトに含まれている vai_c_tensorflow コマンドが実行します。
source 6_compile.shコンパイルが正常に完了すると .xmodel と meta.json の2つのファイルが ./files/build/compile フォルダに生成されます。
Step 7 – Alveo U50 で推論を実行 (Run the Application on the Board)
Alveo U50 上に DPU を置いて実行する準備が整いました。いよいよ実行してみましょう。
source 7_make_target.sh
cd build/target/
/usr/bin/python3 app_mt.py
/usr/bin/python3 app_mt.py -t 4補注) 英文の説明にある source ./alveo_hbm_setup.sh はACRi ルームの環境として予め設定してありますので ACRi ルーム U50 の使用環境では実行する必要がありません。
スループットはシングルスレッドの場合 315.48 fps、4スレッドの場合 678.32 fps、正解率はともに91.52%であることが確認できました。
(vitis-ai-tensorflow) tu_yhorie_xilinx@as004:/scratch/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2/files/build/target$ /usr/bin/python3 app_mt.py
-----------------------------------------
Running on Alveo U50
-----------------------------------------
Command line options:
--image_dir : images
--threads : 1
--model : model_dir
-----------------------------------------
Thread 0 : processed 10000 images
FPS=315.48, total frames = 10000 , time=31.6980 seconds
output buffer length: 10000
Correct: 9152 Wrong: 848 Accuracy: 0.9152(vitis-ai-tensorflow) tu_yhorie_xilinx@as004:/scratch/Vitis-AI-Tutorials-3c9a2a0c09e960722bfa4c62cec1914952f18ce2/files/build/target$ /usr/bin/python3 app_mt.py -t 4
-----------------------------------------
Running on Alveo U50
-----------------------------------------
Command line options:
--image_dir : images
--threads : 4
--model : model_dir
-----------------------------------------
Thread 1 : processed 2500 images
Thread 0 : processed 2500 images
Thread 3 : processed 2500 images
Thread 2 : processed 2500 images
FPS=678.32, total frames = 10000 , time=14.7424 seconds
output buffer length: 10000
Correct: 9152 Wrong: 848 Accuracy: 0.9152このチュートリアルでは使用していないオプティマイザツールを適用することでスループットの大幅な向上、レイテンシィや消費電力の低減が可能です。
まとめ
今回は高いスループット、超低遅延と低消費電力を同時に実現する Vitis AI について解説しました。さらに FPGA を使用して画像認識をおこなうまでのフローを ACRi ルームの環境を使用してひととおり体験しました。
5回シリーズ最終回となる次回は FPGA を取り巻く市場の動向、最新テクノロジーおよび将来の展開について興味深いさまざまな応用事例を交えて解説します。
ザイリンクス株式会社
堀江義弘