
みなさんこんにちは。この記事は ACRi ブログの Deep Learning コースの第7回目です。
この記事からは、前回までに作成したネットワークモデルに対して実際に並列性の抽出を行い、処理速度が向上していくことを確認していきます。まずは現在実装しているモデルのアーキテクチャについて確認し、どのような並列化が可能か検討していきます。
並列化手法の検討
現状の推論モジュールのブロック図は下図のようになっています。maxpool2d, relu については紙面の都合で省略しています。
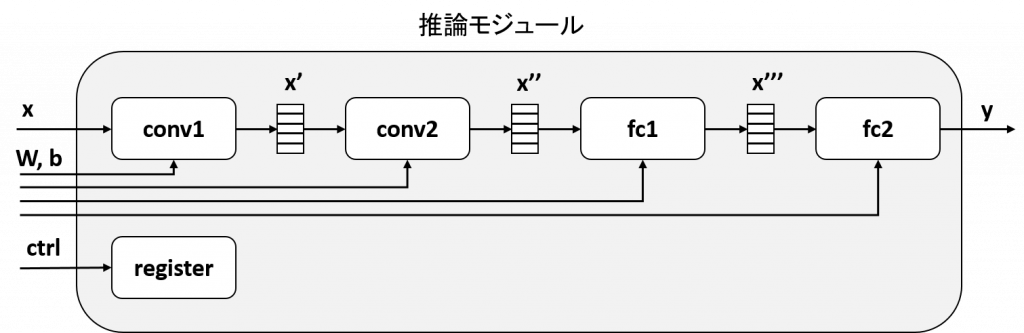
このモジュールでは、conv1, conv2, fc1, fc2 は全て異なるモジュールとして実装されています。各層の間には FPGA 内部の SRAM によるバッファ (x', x'', x''') が挿入されていて、このバッファが各層の入出力となります。以降、この各層 (conv1, conv2, fc1, fc2) をタスクと呼称します。
逐次的な処理 (ベースライン)
このモジュールで推論処理を3フレーム分行ったときの実行時間を可視化すると、下図のようになります。
各タスクあたりの実行時間は推論モジュールの実際の動作波形を元に作っており、conv2 > conv1 > fc1 > fc2 の関係です。このモジュールでは conv1, conv2, fc1, fc2 は別々のタスクとして実装しているものの、これらのタスクは一つずつしか同時に動くことができません (理由は後述します)。このため、conv1, conv2, fc1, fc2 の各層の実行時間をt0, t1, t2, t3 とすると、この3フレームの画像の処理時間は 3 * (t0 + t1 + t2 + t3) となります。

タスクの並列処理
これらのタスクが同時に実行できるよう修正できたとします。この場合の実行時間は下図のようになり、同時刻において複数のタスクが別々のフレームを処理することができるようになります。

このように複数のタスクが同時に動くように並列性を抽出することを、タスク並列化と呼びます。この処理では conv2 の実行時間が支配的なため、3フレーム分の処理時間は t0 + 3 * t1 + t2 + t3 となります。
理想的なタスクの並列処理
最後に理想的にタスク並列化が行えるパターンについて考察します。前述した通り、ただタスク並列性を抽出するだけでは最も遅いタスクがボトルネックとなり、全体の処理速度はそのタスクの性能に律速されます。このため、最も効率的にタスク並列を行えるのは、全タスクの実行時間が揃っている場合となります。

この場合、処理時間としてはt0 + 3 * t1 + t2 + t3 のままですが、t0 = t1 = t2 = t3 となるよう各タスクの実行時間が調整されているため性能が向上します。この高速化を実現する手法として、このコースではループ並列化, データ並列化の2つを取り上げます。この2つの並列性の抽出法は次回以降の記事での紹介とします。
タスク並列化
この記事では、まずはタスク並列化を行うことを目標とします。
今回作成したモジュールのタスクは複数存在しているので、これらは既に並列処理できそうですが、実際の波形ではそうなっていません。なぜこれが並列化できていないかというと、タスク間のインターフェースであるバッファ (x', x'', x''') が複数のタスクから同時に使用できないためです。タスク並列化を行うには、タスク間のインターフェースが2つ以上のタスクから同時に読み書きできる必要があります。
今回のモジュールでは、タスク間のバッファ x' を ping-pong バッファとすることで、タスクレベルの並列化を実現します。ping-pong バッファは、2枚のバッファを用意し片方を書き込み用、片方を読み込み用とするバッファです。ping-pong バッファを使用したブロック図は次のようになります。
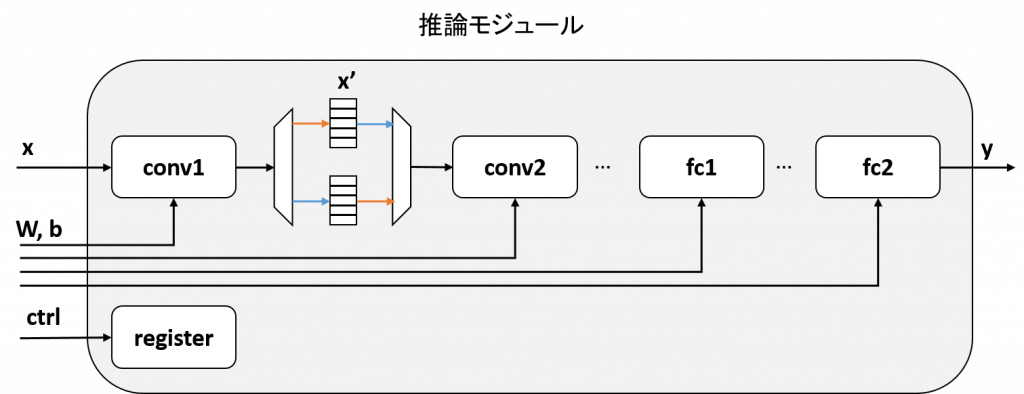
このように回路を構成すると、conv1 からの出力を格納するバッファと conv2 が入力を読み出すバッファが別となるため、conv1, conv2 が同時に動作可能となります。図では省略していますが、conv2 <-> fc1, fc1 <-> fc2 についても同様にダブルバッファを行うことで、全ての層が同時に動くことができます。
これを RTL で実現すると 2つのバッファを用意したり切り替え機構を実装したりと手間なのですが、Vivado HLS / Vitis ではこの並列化をいくつかのプラグマを追加するだけで実現可能です。
コードへの変更
カーネル
今回のタスク並列化には、以下の3種のプラグマの追加が必要です。
#pragma HLS dataflow#pragma HLS stable#pragma HLS interface ap_ctrl_chain
各プラグマの役割を説明する前に、まずは新たに追加した inference_dataflow 関数のソースコードを示します。第5回の記事で示した inference_top 関数と重複する箇所は一部省略しています。
60 void inference_dataflow(const float x[kMaxSize],
61 const float weight0[kMaxSize], const float bias0[kMaxSize],
62 const float weight1[kMaxSize], const float bias1[kMaxSize],
63 const float weight2[kMaxSize], const float bias2[kMaxSize],
64 const float weight3[kMaxSize], const float bias3[kMaxSize],
65 float y[kMaxSize]) {
66 #pragma HLS dataflow
67 #pragma HLS interface m_axi port=x offset=slave bundle=gmem0
...
76 #pragma HLS interface m_axi port=y offset=slave bundle=gmem9
77 #pragma HLS interface s_axilite port=x bundle=control
...
86 #pragma HLS interface s_axilite port=y bundle=control
87 #pragma HLS interface s_axilite port=return bundle=control
88 #pragma HLS interface ap_ctrl_chain port=return bundle=control
89
90 #pragma HLS stable variable=x
91 #pragma HLS stable variable=weight0
92 #pragma HLS stable variable=bias0
93 #pragma HLS stable variable=weight1
94 #pragma HLS stable variable=bias1
95 #pragma HLS stable variable=weight2
96 #pragma HLS stable variable=bias2
97 #pragma HLS stable variable=weight3
98 #pragma HLS stable variable=bias3
99 #pragma HLS stable variable=y
100
101 dnnk::inference(x,
102 weight0, bias0,
103 weight1, bias1,
104 weight2, bias2,
105 weight3, bias3,
106 y);
107 }66行目に追加された #pragma HLS dataflow というプラグマは、この inference_dataflow 内部関数間のインターフェースを ping-pong バッファとし、タスク並列化を有効にします。101行目で呼び出される dnnk::inference 関数は以下のような関数で、20行目の #pragma HLS inline プラグマにより inference_dataflow 関数内にインライン展開されます。このため、conv2d, relu 等の関数がタスク並列化の対象となり、そのインターフェース (x1, x2, ...) が ping-pong バッファになります。
14 static void inference(const float* x,
15 const float* weight0, const float* bias0,
16 const float* weight1, const float* bias1,
17 const float* weight2, const float* bias2,
18 const float* weight3, const float* bias3,
19 float* y) {
20 #pragma HLS inline
...
34
35 // 1st layer
36 conv2d(x, weight0, bias0, kWidths[0], kHeights[0], kChannels[0], kChannels[1], 3, x1);
37 relu(x1, kWidths[0] * kHeights[0] * kChannels[1], x2);
38 maxpool2d(x2, kWidths[0], kHeights[0], kChannels[1], 2, x3);
39
...
48
49 // 4th layer
50 linear(x8, weight3, bias3, kChannels[3], kChannels[4], y);
51 }inference_dataflow 関数の90行目からの #pragma HLS stable は、x, weight0, y 等の入出力に対して、inference_dataflow 関数の開始時/終了時に自動的に行われる同期を削除します。この同期を削除しないと、例えば “前フレームの y 出力の完了 -> 次フレームの x 入力の準備完了” の2つの処理の間に依存が発生してしまい、複数タスクが動かなくなってしまいます。Vivado HLS の公式ドキュメント (UG902) の stable 配列の項に詳細な説明があるので、こちらもご参照ください。
最後に、inference_dataflow 関数の88行目の #pragma HLS interface ap_ctrl_chain port=return というプラグマは、この inference_dataflow 関数を用いて複数フレーム同時に処理できるよう、外部へのレジスタインターフェースに変更を行います。このプラグマがないと、せっかく ping-pong バッファを実装してもホスト側が 1枚ずつしか実行しようとしないため、性能が向上しません。
高位合成結果の確認
タスク並列化がうまくいっているかの確認は、高位合成結果の確認時点で行えます。
これは前回の記事で説明したように、Vitis 上では .xo ファイルを作る作業に該当します。
以下が高位合成結果の HLS レポートで、Latency -> Summary の欄に、関数全体のレイテンシと実行間隔 (Interval) が記載されています。ここで、全体のレイテンシとしては相変わらず全タスクの処理時間の総和となっていますが、実行間隔の値は2回目の畳み込み層 (conv2d_232_U0) の実行サイクル数と一致しています。このモジュールのスループットは2回目の畳み込み層の実行間隔の逆数になります。
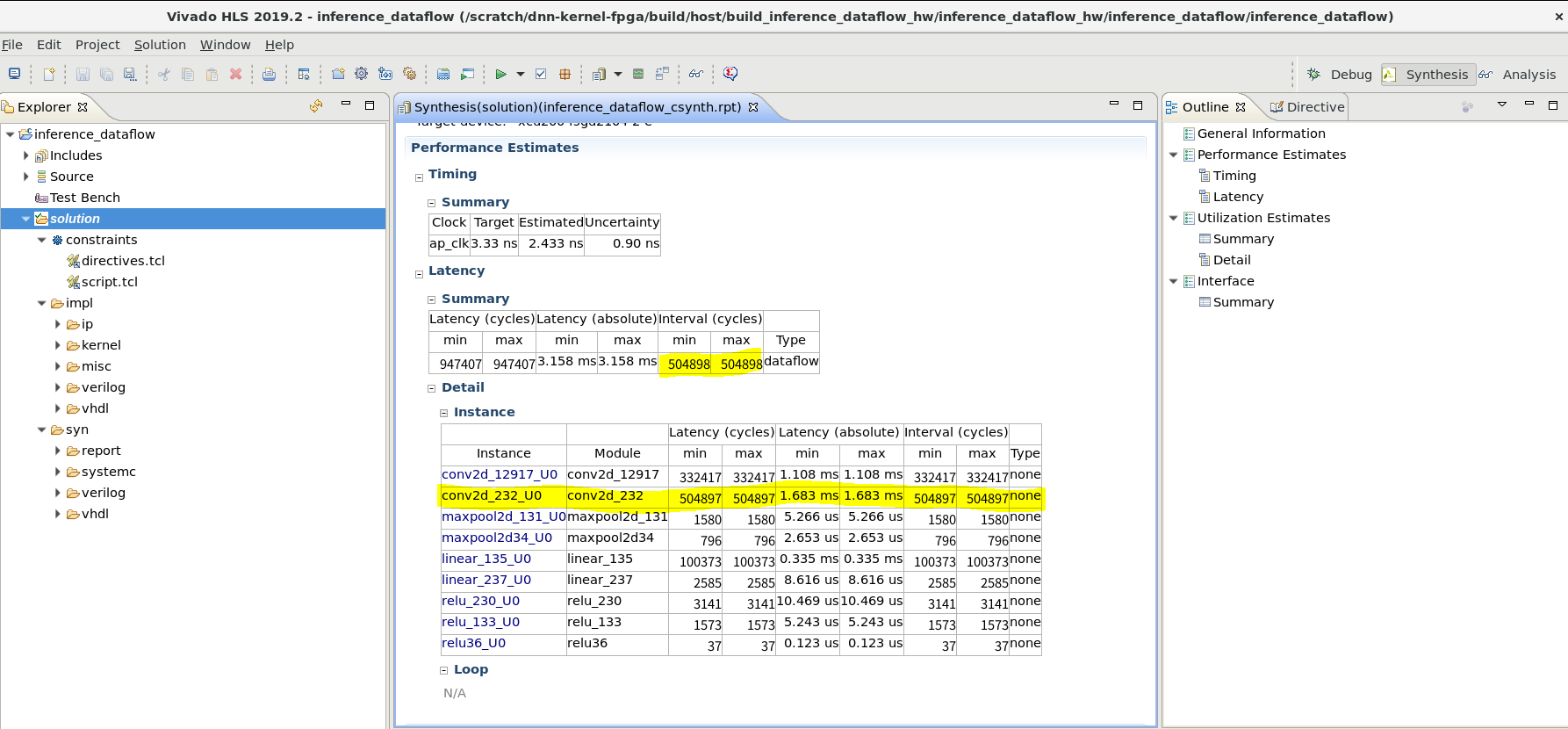
この記事の冒頭で説明したように、このタスク並列化後の回路ではconv2d_232_U0 の処理時間がボトルネックとなります。タスク並列化による速度向上率としては、947407 / 504898 = 1.88 倍 になります。
ホストアプリケーション
ここまでの修正によりハードウェア側はタスク並列化が可能な構成となっているのですが、実際はホストアプリケーションにも少し修正が必要となります。修正の内容を説明する前に、まずは前回の記事で省略した OpenCL についての説明を行います。
OpenCL では、コマンドキューと呼ばれるオブジェクトを用いてホストからターゲットとなるデバイスに対してリクエストを送ることができます。リクエストの例としては、例えば以下のようなものがあります。
- ホスト上のメモリ <-> デバイス上のメモリ のデータコピー
- カーネル (今回の例だと
inference関数) の実行 - コマンドキュー内のリクエストの完了待ち
今回使用しているホストアプリケーション (host/run_inference.cc) からカーネル実行部を抜粋すると、以下のようになっています。
148 for (std::size_t i = 0; i < buf_x.size(); i++) {
149 kernel.setArg(0, buf_x[i]);
150 kernel.setArg(9, buf_y[i]);
151
152 queue.enqueueTask(kernel);
153 }
154 queue.finish();152行目、154行目がキューに対するリクエストで、ここではテスト対象となる画像 (buf_x[i]) を処理するリクエスト queue.enqueueTask(kernel) を連続してキューに積み、最後に queue.finish() によりキュー内の全処理が完了するまで待機しています。buf_x[i], buf_y[i] はデバイス側のメモリで、buf_x[i] へのホストからの画像データのコピーはこの処理より前に済ませてあります。
OpenCL のコマンドキューはデフォルトではインオーダなキューであり、キューに積まれたリクエストの処理順が積まれた順と同じであることが保証されます。このインオーダな処理順が問題で、”前フレームの全ての層の処理の完了後に初めて次フレームの最初の層の処理が可能となる” という依存が発生してしまいます。このため、現在のコードでは複数フレーム分の処理を同時に行うことができません。
この問題の解決策として一番簡単なのは、コマンドキューをアウトオブオーダ とすることです。アウトオブオーダなキューでは発行したリクエスト間の実行順に依存が発生しないため、上述したような依存が発生せずタスク並列化による高速化が可能となります。キューをアウトオブオーダとするには、以下のようにキューの定義にフラグを付与することで設定が可能です。
cl::CommandQueue queue(context, device, CL_QUEUE_PROFILING_ENABLE | CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE);アウトオブオーダなキューを使用する場合は、cl::Event というオブジェクトを用いてリクエスト間の依存を自分で定義することができます。OpenCL C++ Bindings のページより enqueueTask 関数の定義を見ると、次のように末尾にevents, event というイベントオブジェクトが設定可能です。
cl_int enqueueTask (const Kernel &kernel, const vector< Event > *events=NULL, Event *event=NULL) const;events 引数にはそのリクエストが依存するイベント (リクエスト) のリストを与え、event 引数はこのタスク処理が完了した時に更新するイベント引数を与えます。enqueueTask以外の関数も同じように末尾にevents, event 引数が存在するため、これを用いてキュー上のリクエストの依存が表現可能となります。
今回は複数フレーム間の処理に依存が発生しないため、イベントオブジェクトは使用しません。ただし、アウトオブオーダキュー自体は FPGA 上に複数のカーネルが存在する場合にしばしば必要となり、その際には正しく依存を定義する必要がある場合があります。より詳細な説明やコード例は、UG1393 の “計算ユニットのスケジューリング” に記載されています。
実行
カーネルを実行する前に、以下のように xrt.ini に追記を行います。これをすると、タスク毎の外部メモリアクセスがタイムライン上に出るので、想定通りに回路が動いているか確認できます。
[Debug]
profile=true
timeline_trace=true
data_tranfer_trace=coarseこのカーネルを実行した際のログは以下のようになります。
$ ./host/run_inference host/inference_dataflow_hw.xclbin inference_dataflow 1
Elapsed time: 12.6491 [ms/image]
accuracy: 0.972前回記事で述べた実行時間は 20.8093 [ms/image] だったので、1.65倍程度の性能向上が達成できています。
次に、実際のタイムラインを元に想定通りのタスク並列化が行えているか確認します。
以下が元の inference_top 関数実行時の実機上のタイムラインです。各レイヤーのメモリアクセス (青色) は、同じ層に対するメモリアクセス以外は重なっておらず、タスク並列化は行われていません。
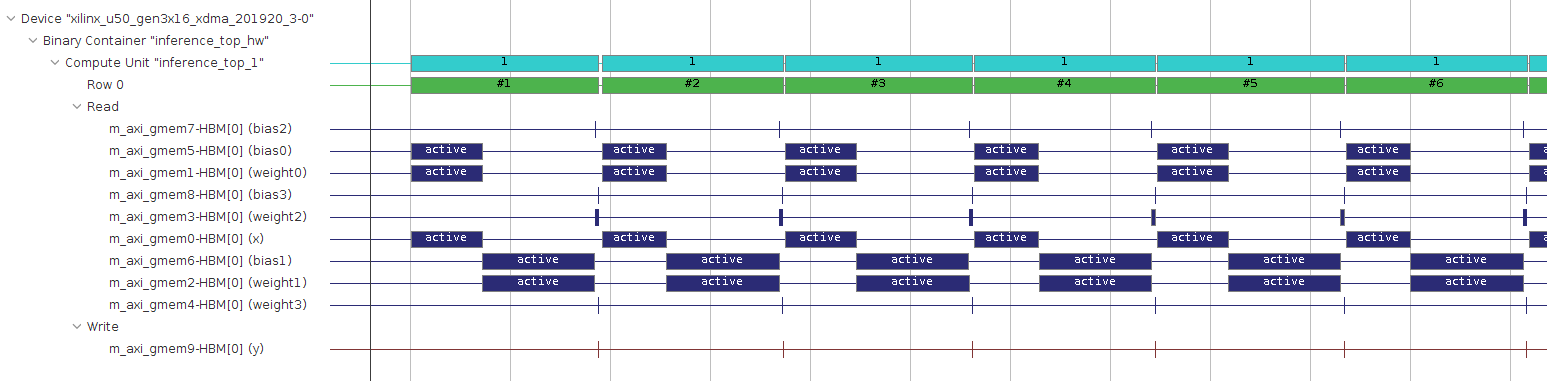
以下が今回作成した inference_dataflow 関数実行時の実機上のタイムラインです。こちらの実装だと、2つめの畳み込み層へのインターフェース (weight1, bias1) の稼働率が100% であり、この畳み込み層がボトルネックとなっていることが分かります。また Row の行を見ると、4フレーム分の処理を同時に行えているようです。

このように、Vitis によりタスク並列化が正しく実装できていることが確認できました。
まとめ
この記事では、タスク並列性を抽出することで推論処理の高速化を行いました。元々 conv2 が実行時間の半分以上を占めていたため速度向上率としては2倍に満たない程度ですが、前述したように各層の実行時間が同じになるようリソースを調整することで、層の数を N とすると最大で N 倍の速度向上率が得られるようになります。
次回の記事では、畳み込み層に対してデータ並列化・ループ並列化を行うことで、各層の処理時間のアンバランスを解消していきます。
株式会社フィックスターズ シニアエンジニア 松田裕貴