
みなさんこんにちは。この記事は ACRi ブログの Deep Learning コースの第6回目です。
この記事では、前回の記事で作った推論関数を Alveo U200 ボード上で動作させていきます。このデザインは ACRi ルーム の Alveo U200 搭載サーバー上で動作を確認済みです。
また、このブログに記載しているコードは https://github.com/fixstars/dnn-kernel-fpga で公開しています。コードの権利、ライセンスに関してはライセンスファイルを参照するようにして下さい。興味がある方はコードをダウンロード後、README に従って試してみてください。
実機で動作させるまでのフロー
これまでの開発では、Vivado HLS を用いて推論機能の IP を作成してきました。これはあくまで IP であるため、実際に FPGA 上で推論処理を動かすにはこの IP を Vivado 上に配置してビットストリームを作成する必要があります。ただし、このビットストリームは PCIe 等のホスト用インターフェースなども含んでいる必要があり、それを Vivado で一つずつ配置していくのは非常に手間がかかります。
Vitis を用いると、この IP の配置をツールで自動化できるため、今回は Vitis を使用します。他にもVitis を採用するメリットには、以下の記事で既に非常に分かりやすい解説があるため、興味があればこちらもご参照ください。

Alveo のようなアクセラレーションカード上で処理を行うには、FPGA 上の機能を実行するためのホストアプリケーション・実際のハードウェアイメージの両方を開発する必要があります。
下図は Vitis の UG1393 内の図であり、Vitis におけるビルド手順を示しています。図の左側のフローがホストアプリケーションのビルドフローで、これは OpenCL API を使用して書かれたホストアプリケーションを通常のg++ でビルドしています。
図の右側が FPGA Binary (xclbin) のビルドフローで、こちらもコンパイル・リンクという2つのフローに分かれています。
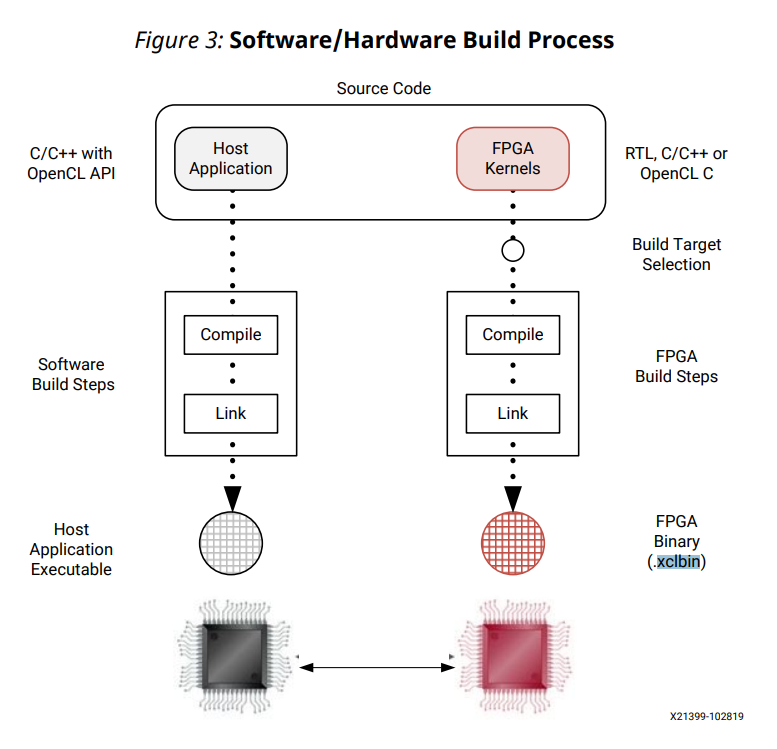
Vitis では、以下のように FPGA カーネルに対するコンパイル・リンク処理を定義しています。
- コンパイル: FPGA カーネルに対して高位合成をかけるまで (Vivado HLS による高位合成と同じ)
- リンク: 高位合成をかけたカーネルを Vivado 上で配置、ビットストリーム作成
このリンクという手順が便利で、ターゲットとなる FPGA ボードや内部 IP の構成 (まとめてターゲットプラットフォームと呼称) を指定すれば、その構成上にツールが自動的にコンパイル後の IP を配置してくれます。
またリンク処理時には、PCIe IP 等の必須の IP に加え、プロファイルやデバッグ機構までオプションで追加することができます。特にプロファイル機構を自分で埋め込むのはホストアプリケーションの修正 + FPGA バイナリの修正と非常に手間がかかるため、Vitis を用いると自動化できて非常に簡単です。
FPGA Binary (xclbin) の作成
まずは FPGA 用のバイナリ (xclbin) を作成していきます。
コンパイル手順
コンパイルは非常に簡単で、今回は以下のようなコマンドを実行しています。
$ v++ -c inference_hls.cc -o inference_top_hw.xo --target hw --kernel inference_top --platform </path/to/XXX.xpfm> --profile_kernel data:all:all:all --profile_kernel stall:all:all:all基本的には gcc でコンパイルを行う際のコマンドを v++ という高位合成コンパイラ向けに移植した形となります。v++ ならではのオプションとしては、以下のものがあります。
- target: 実行モード。ハードウェア (hw), ソフトウェアエミュレーション (sw_emu), ハードウェアエミュレーション (hw_emu) から選択可能
- kernel: 高位合成をかける最上位関数の指定
- platform: プラットフォームファイルを指定。例えば ACRi ルームのサーバー上で U200 を指定するには
/opt/xilinx/platforms/xilinx_u200_xdma_201830_2/xilinx_u200_xdma_201830_2.xpfm。 - profile_kernel: オプション引数。ここでは、データ転送・ストール情報のプロファイルを全てのポート上で有効にしている
出力される xo オブジェクトは、高位合成後の RTL 等を含むファイルになります。
リンク手順
リンクも gcc ライクに書けて、以下のようなコマンドで実行できます。リンクではビットストリームの作成までが行われるため、 Alveo ボード向けのデザインだと少なくとも1時間以上かかり、今回のデザインでは2時間かかりました。
$ v++ -l inference_top_hw.xo -o inference_top_hw.xclbin --target hw --platform </path/to/XXX.xpfm> --config link.iniターゲット、プラットフォームはコンパイル時と同じ値を設定する必要があります。link.ini は設定用ファイルで、今回は次のようなファイルを使用しています。
# Debug
dk=chipscope:inference_top_1:M_AXI_GMEM0
dk=chipscope:inference_top_1:M_AXI_GMEM1
...
dk=chipscope:inference_top_1:M_AXI_GMEM9
dk=chipscope:inference_top_1:S_AXI_CONTROL
dk=protocol:inference_top_1:M_AXI_GMEM0
dk=protocol:inference_top_1:M_AXI_GMEM1
...
dk=protocol:inference_top_1:M_AXI_GMEM9
dk=protocol:inference_top_1:S_AXI_CONTROL
# Profile
profile_kernel=stall:all:all:all
profile_kernel=data:inference_top:inference_top_1:x:all
profile_kernel=data:inference_top:inference_top_1:weight0:all
...
profile_kernel=data:inference_top:inference_top_1:y:all
[connectivity]
nk=inference_top:1:inference_top_1 sp=inference_top_1.x:DDR[0] sp=inference_top_1.weight0:DDR[0] sp=inference_top_1.bias0:DDR[0] sp=inference_top_1.weight1:DDR[0] sp=inference_top_1.bias1:DDR[0] sp=inference_top_1.weight2:DDR[0] sp=inference_top_1.bias2:DDR[0] sp=inference_top_1.weight3:DDR[0] sp=inference_top_1.bias3:DDR[0] sp=inference_top_1.y:DDR[0]一番重要なのは[connectivity] 以下の欄です。先頭の文ではnk=<top_func>:<N>:<instance_name0>.<instance_name1>... の構文で、<top_func> という名前の IP を <N> 個配置し、それぞれに<instance_name0> から順にインスタンス名を割り当てることを定義します。sp=<instance_name>.<port_name>:<platform_port> の文では、各インスタンスのポート <port_name> を プラットフォーム上のポートに割り当てることを指示しています。この例では全て DDR[0] に割り振っていますが、受け側のメモリ帯域が不足する場合などは別のポートに割り当てる必要があります。U200 だとあまり変更する必要はありませんが、ポート辺りの帯域が狭くなりやすいエッジデバイス (zynq等) では変更が必要となることが多いです。
# Debug という行以下を付与すると、デバッグのために System ILA を各ポートに自動的に配置してくれます。System ILA があると、FPGA 上の波形をホスト側で確認できるので、初期のデバッグ時に非常に便利です。
# Profile という行以下は、各ポートに対するプロファイル機構を有効にします。これをつけておくと、実機上でカーネルを動かした際に、各ポートからのメモリへのアクセス時間などを取得できるようになります。
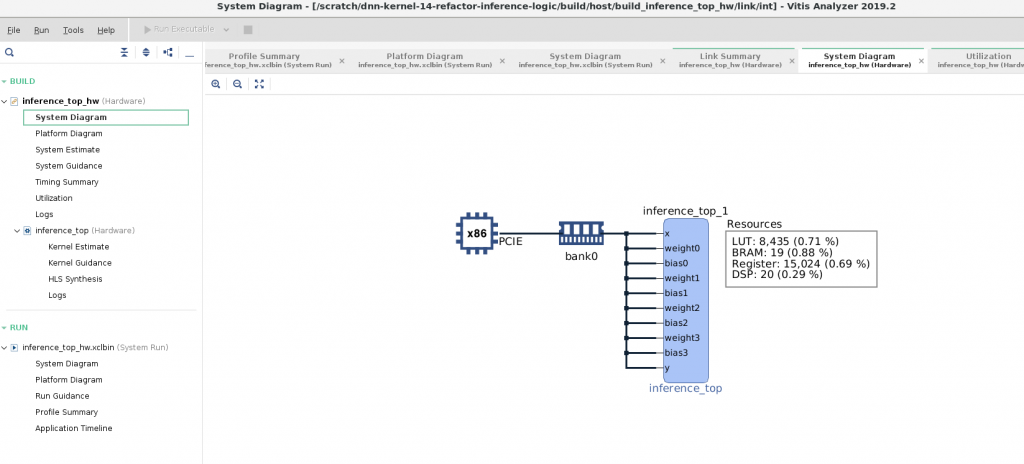
リンク終了時に自動的に出力される inference_top_hw.xclbin.link_summary というファイルを Vitis Analyzer というツールで開くと、Vitis が合成したシステム構成など、様々な情報が可視化できます。下図は System Diagram という図で、プラットフォーム上にどのように IP を配置したか可視化してくれるので、これを見ると想定通りにメモリを割り当てられているか等を確認できます。
ホストアプリケーションの作成
次に、ホストアプリケーションを作成します。
ホストアプリケーションは、OpenCL を用いて作成する必要があります。この記事ではどのように作成していくかは省略しますが、アプリケーションとしては次の処理を行っています。
- OpenCL のセットアップ
- パラメータ (重み・バイアス) を学習済みモデルから読み出し、FPGA ボードの DDR 上に転送
- 入力画像を MNIST データセットから読み出し、 FPGA ボードの DDR 上に転送 (先頭1000枚のみ)
- FPGA 上で 1000枚の画像に対する推論を連続で実行
- 推論結果のラベルを FPGA ボードの DDR 上からホストメモリに転送
- 4 の処理にかかった時間を元に、画像1枚あたりの処理時間を算出
- 正解ラベルと比較、accuracy の出力
この処理は run_inference.cc というファイルに実装しているので、興味がある方はこちらをご参照ください。
動作確認
ホストコードと xclbin の両方が揃ったので、実機上で推論処理を行えます。推論を行う前に、プロファイルのため以下のファイルをxrt.ini という名前でワーキングディレクトリに配置しておきます。
[Debug]
profile=yes
timeline_trace=true推論を実行すると結果は以下のようになります。
$ ./host/run_inference ./host/inference_top_hw.xclbin inference_top
Elapsed time: 20.8093 [ms/image]
accuracy: 0.973フレームあたりの処理時間は約20.8ms で、推論の精度は 97.3% となっています。推論の精度は第2回の記事で 97.26% だったため、今回の結果は十分正しいと言えそうです。
推論の速度としては、実はこのカーネルは Vitis のソフトウェアエミュレーション (C カーネルをそのまま CPU 上で実行した場合) よりも速度が20倍近く遅くなります。全く最適化していない FPGA カーネルでは演算器の数は CPU よりも少ないうえに、動作周波数でも10倍近くの差がつくため、この結果は妥当といえます。
また、上記コマンドを実行すると、ワーキングディレクトリ上にinference_top_hw.xclbin.run_summary というレポートファイルが出力され、これも Vitis Analyzer によりプロファイル結果を確認することができます。
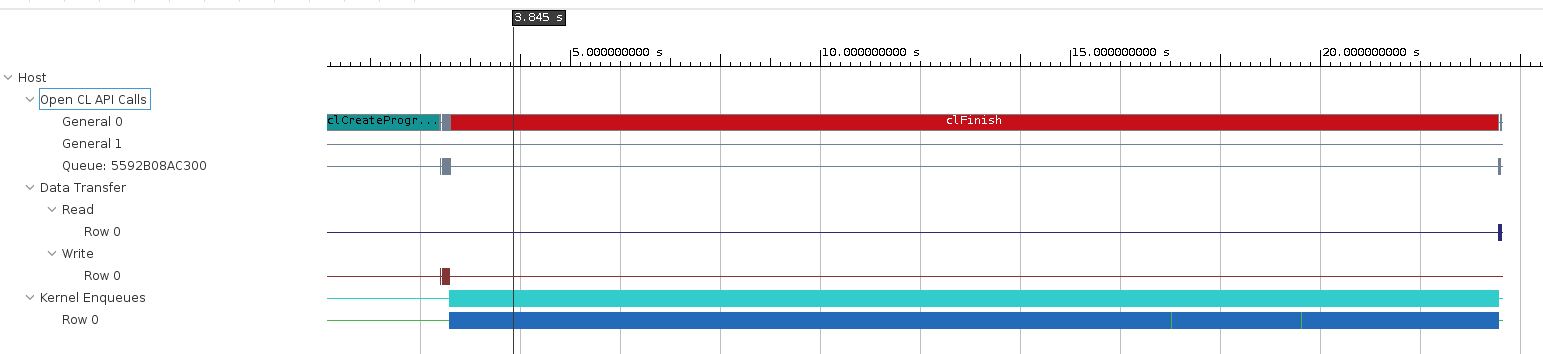
ここではレポートの多くは取り上げませんが、実行のタイムラインは下のようになりました。最初に OpenCL の初期化があり、ホスト -> デバイスへの Write Transfer でパラメータ・入力画像が送信され、その後長時間推論カーネルが動き、最後に デバイス -> ホストへの Read Transfer で全ての推論結果がホストにコピーされます。
まとめ
計6回分の記事と長くなりましたが、ようやく FPGA 上でディープラーニングが動くようになりました。ここまでの記事で行った手順は以下です。
- 学習済みモデルの作成 (第2回)
- C++ で各モデルの処理を記載する (第3回, 第4回, 第5回)
- Vivado HLS / Vitis で高位合成 (本記事)
- Vitis を用いてターゲットプラットフォームにリンク (本記事)
従来の開発手法だと、3の工程で C++ コードを元に RTL コードを作成 + テストしたり、4の工程で一つ一つ Vivado 上に作成した回路や PCIe 等の周辺 IP の配置など、非常に時間がかかります。Vitis を用いれば柔軟性は落ちるものの 3, 4 の工程が数回程度のコマンドを実行するだけで処理できるので、開発は非常に簡単になっています。
また、ディープラーニングは畳み込み層や全結合層など、シンプルな層の積み重ねでネットワークが構成されることも説明しました。今回は MNIST 用の非常にシンプルなネットワークを対象としましたが、より実用的なネットワークを対象としても登場する層はそこまで変化しません。このため、今回と同じように各層を実装していけば FPGA 上でより複雑なネットワークを動作させることも可能です。
このコースのここまでの内容だと、ただ C で書いたコードをそのまま FPGA 上で動かしているだけなので、あまり FPGA ならではといった内容は含まれていません。次回以降の記事では、 FPGA でディープラーニングを効率的に処理するための最適化手法を紹介していきます。
次回以降の内容
次回以降の記事では効率的にディープラーニングを FPGA 上で行うことを目指して、以下のような手法を紹介し、またいくつかをこのモデルに適用していきます。
- FPGA アーキテクチャに適した高速化: 並列性の抽出
- ループ並列性
- データ並列性
- タスク並列性
- 全体的なアーキテクチャの再検討
- 演算処理の削減
- 量子化
- 枝刈り
1, 2 は FPGA 開発で一般的なチューニングで、3 はディープラーニングならではのチューニングとなります。
2 は曖昧な表記のため補足すると、例えば今回作成した回路では各畳み込み層・全結合層などを別々のモジュールとして実装しています。一方で、Xilinx 社の xDNN 等の IP では、一つの巨大な計算エンジンのみを持ち、その計算エンジンを用いて各層の演算を一つずつ適用するようなアーキテクチャとしています。前者の実装だと、うまく層間の演算量が揃っていないと全ての層の演算器をフルに使いきれないというデメリットがあります。後者の実装だと層間の演算バランスを考えなくてよいため演算器の性能はフルに使いやすいですが、層毎に特徴量の入出力をメモリ上で読み書きする必要があるため、メモリアクセスが増えるデメリットがあります。この辺りの比較は、https://japan.xilinx.com/support/documentation/white_papers/j_wp514-emerging-dnn.pdfにまとまっているので興味がある方は見てみると良いと思います。
このコースの記事は残り4回です。最初の3回で1の並列性の抽出法をいくつか紹介し、最後に実際の FPGA 向けのフレームワーク・ライブラリを例にして2, 3 の内容を紹介していきます。
特に並列性の抽出は FPGA 上で効率的に処理を行う際に、ターゲットとするアプリケーションによらず必須のテクニックとなります。次回の記事ではこのモデルに対して実際にタスクレベルの並列化を行い、速度が向上していくことを見ていきます。この高速化は FPGA 開発で特に楽しい部分でもあるので、ぜひ継続して見て頂ければと思います。
株式会社フィックスターズ シニアエンジニア 松田裕貴