
みなさんこんにちは。この記事は ACRi ブログの Deep Learning コースの第8回目です。
この記事では、前回タスク並列化を施した推論カーネルに対し、ループ並列化を行い層間の実行時間のバランスをとっていきます。
また、現在のカーネルでは外部メモリアクセスが非効率的なため、内部の計算でなくメモリアクセスがボトルネックとなっています。この状態ではループ並列化を行っても結局メモリアクセスがボトルネックとなってしまうため、まずは簡単な修正をカーネルに施しメモリアクセスを効率化します。
現在のカーネルのボトルネック
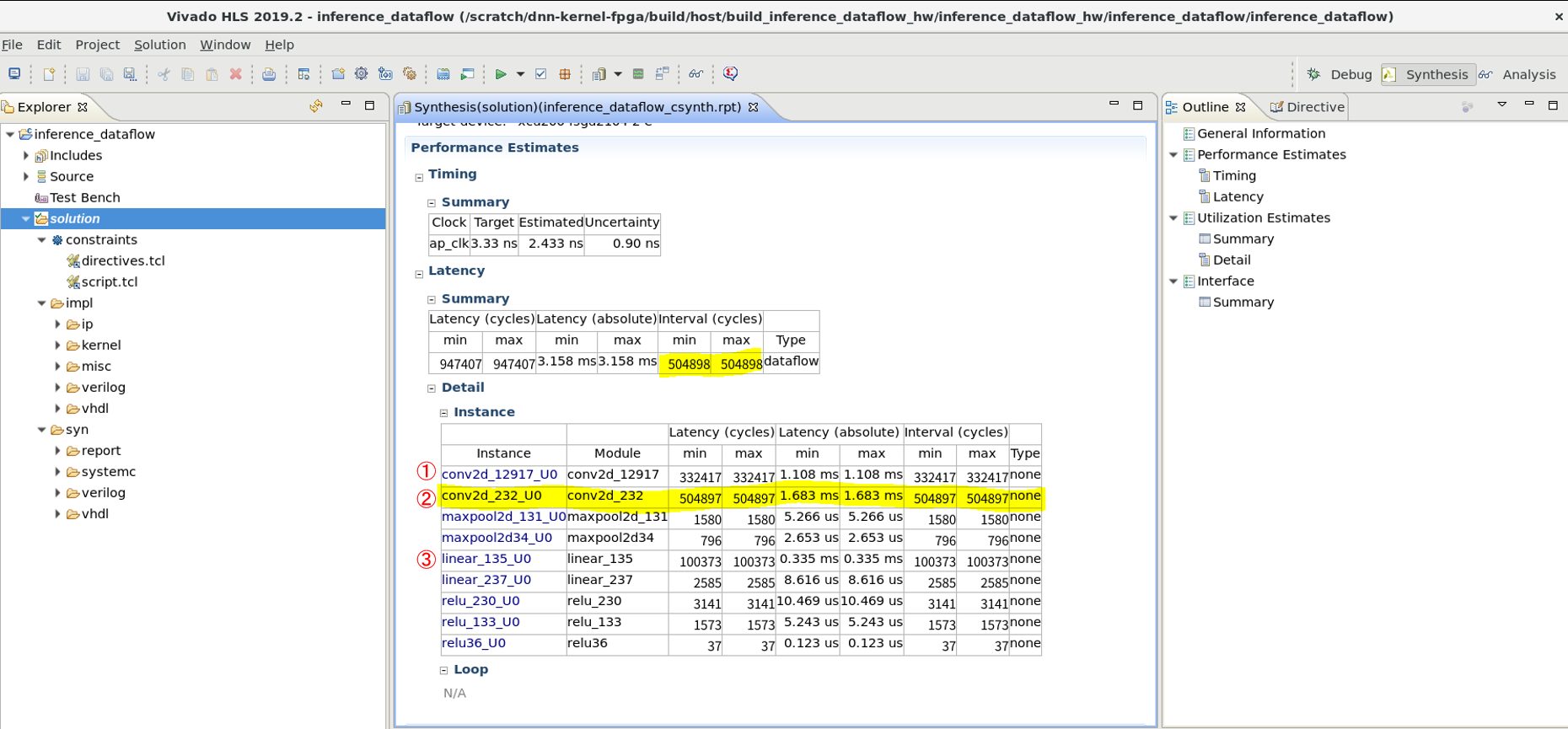
前回の記事で添付したカーネルの実行時間レポート、実機のタイムラインを以下に再掲します。
実行時間レポート:
実機タイムライン:
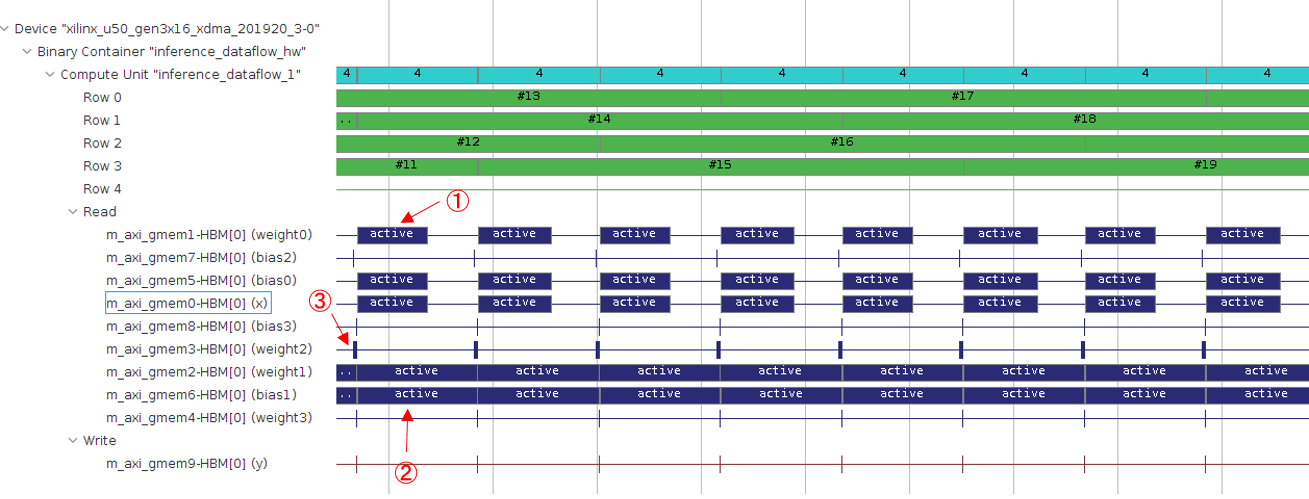
ここで、各図中の①, ②, ③ がそれぞれ最初の畳み込み層 (conv1)、2つ目の畳み込み層 (conv2)、最初の全結合層 (fc1) に対応します。実行時間レポートでは conv2, conv1, fc1 の実行時間の比は 5:3:1 となっています。一方、実機のタイムラインでは、conv2:conv1 の比は 5:3 程度であるものの、fc1 層はそれらに比べると非常に短い実行時間になっています。また、推論処理全体の実行時間も 12.65 [ms/image] のため、レポートで記載されたスループット (504098 cycles / 300MHz = 1.68 [ms/image]) よりも大幅に長くなっています。
なぜこのように HLS レポート <-> 実機の性能 に差が出ているかというと、HLS のレポートでは外部メモリが要求されたタイミングに即座にデータを供給可能という前提でレポート作成を行っているためです。実機では、外部メモリアクセスがそこまで速くないため、実機でのみ性能が大幅に悪化します。
メモリアクセスの最適化
メモリアクセスが非効率であることが分かったのでこれを最適化します。現在のカーネルでは、畳み込み層で積和演算を行うたびに係数データを外部 DRAM からフェッチしています。この構成だと非常に細かい粒度で DRAM へのアクセスが発生してしまうため、DRAM への負荷が非常に高くなってしまいます。
Xilinx の FPGA 内部のメモリ階層は下図のようになっており、分散 RAM (Distributed RAM), BRAM (Block RAM), URAM (Ultra RAM) の 3種は FPGA 内に実装されています。

これら FPGA 内部のメモリは DRAM より非常に高速な動作が可能であり、毎サイクル安定してデータを読み書きできます。このため、今回は画像や重みサイズなどのデータ全てを FPGA 内部に予めコピーし、各層からは FPGA 内部のメモリからデータを読み出すように修正します。今回は画像や重みサイズが十分小さいので、Vivado HLS のデフォルト (BRAM または分散 RAM) をそのまま使います。
作成する回路のブロック図を図示すると、下のようになります。
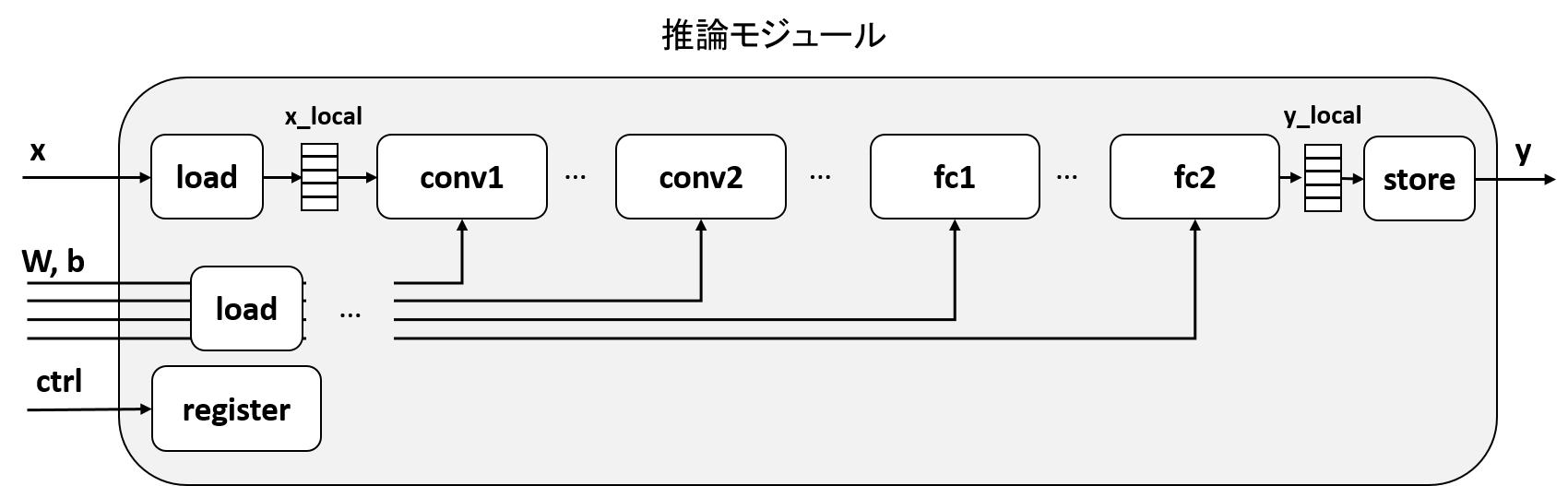
x の DRAM 入力からのデータを、x_local というローカルメモリ上に一時ストアする役割を持つ load 回路を新たに追加します。weight, bias 等についても同様です。出力に関しても、fc2層からのデータを y_local というローカルメモリにバッファリングし、その結果をyポートから出力します。
この図では簡単のためローカルバッファをシングルバッファとしています。前回説明したようにタスク並列化を行う場合は、このバッファは ping-pong バッファとする必要があります。
この回路を Vivado HLS 上で実現するには、load, store 関数及びローカルバッファをコード上に定義します。実際はこのload, store 関数は自前で定義する必要がなく、 C の標準ライブラリ上の memcpy を使えば自動で効率的な回路を生成してくれるため、これを使用します。
コードは以下のようになります。
111 void inference_with_local_buffer(const float x[kMaxSize],
112 const float weight0[kMaxSize], const float bias0[kMaxSize],
113 const float weight1[kMaxSize], const float bias1[kMaxSize],
114 const float weight2[kMaxSize], const float bias2[kMaxSize],
115 const float weight3[kMaxSize], const float bias3[kMaxSize],
116 float y[kMaxSize]) {
117 #pragma HLS dataflow
118 #pragma HLS interface m_axi port=x offset=slave bundle=gmem0
...
151
152 const std::size_t x_size = 1 * 28 * 28;
153 const std::size_t w0_size = 4 * 1 * 3 * 3, b0_size = 4;
...
157 const std::size_t y_size = 10;
158
159 float x_local[x_size];
160 float w0_local[w0_size], b0_local[b0_size];
...
164 float y_local[y_size];
165
166 // fetch to local buffer
167 std::memcpy(x_local, x, x_size * sizeof(float));
168 std::memcpy(w0_local, weight0, w0_size * sizeof(float));
...
176
177 // run inference with local buffer
178 dnnk::inference(x_local,
179 w0_local, b0_local,
180 w1_local, b1_local,
181 w2_local, b2_local,
182 w3_local, b3_local,
183 y_local);
184
185 // store to global buffer
186 std::memcpy(y, y_local, y_size * sizeof(float));
187 }167行目で DRAM 上の x を FPGA 内部の x_local にコピーしています。その後は x_local を用いて推論関数 dnnk::inference を実行し、出力された y_local は最後の memcpy で DRAM へと出力されます。
この回路を合成し、実機で実行したログが以下です。元々 12.65 [ms/image] かかっていた実行時間が、 1.61 [ms/image] まで削減されていることが分かります。
$ ./host/run_inference ./host/inference_with_local_buffer_hw.xclbin inference_with_local_buffer 1
Elapsed time: 1.61029 [ms/image]
accuracy: 0.973元々のカーネルで畳み込み層内で行っていた DRAM アクセスがなくなっているため、このカーネルでは畳み込み層も僅かに性能が向上し、全体の処理サイクル数が 504898 -> 481378 cycles まで削減されます。481378 cycles は 300MHz 換算で 1.604 ms で、これは上述した実機の実行時間 (1.61 ms) とほぼ同じです。このように、ローカルバッファをキャッシュに用いた inference_with_local_buffer 関数では、メモリアクセス時間は全体の性能に悪影響を及ぼしていないことが分かります。
ループ並列化による畳み込み層の高速化
ここまでで HLS レポートと実機の実行時間がほぼ一致するようになりましたので、本記事の主題であるループ並列化を以下より行います。
畳み込み関数の最内ループでは、大きく分けて以下の3処理が行われます。
- ピクセル、重みのロード
- ピクセル、重みの乗算
- 乗算結果を総和レジスタに加算
この3つの処理は、以下の畳み込み関数の31行目で全て行われています。
17 for (int32_t ich = 0; ich < in_channels; ++ich) {
18 for (int32_t kh = 0; kh < ksize; ++kh) {
19 for (int32_t kw = 0; kw < ksize; ++kw) {
...
31 sum += x[pix_idx] * weight[weight_idx];
32 }
33 }
34 }大まかに上記カーネルの処理の流れを波形で図示すると下図のようになります。

ここでは、load 処理は1サイクル、fmul 処理は3サイクル、fadd 処理は4サイクルかかる想定で図示を行っています。最初の行がイタレーション (ループの反復数) i, その次の行が次のイタレーションi+1で、最後にi+2の処理波形となります。ループ並列性を抽出しない場合は、このように各イタレーションの処理が全く重ならず、1イタレーションあたり8サイクルの処理時間がかかっています。
例えばload回路はサイクル2~9, 10~17 等で稼働していないため、これを常に稼働させることで更に性能を向上させることができます。load 回路を常に稼働させた際の波形は下図のようになります。

先ほどまでは8サイクル毎に次のイタレーションが開始していましたが、この例では1サイクル毎に次のイタレーションが開始しています。このように、異なるイタレーション間で並列性を抽出することをループ並列化といいます。イタレーションが実行可能な間隔は II (Iteration Interval) と呼ばれ、この例では II=1 のように表記します。
ループ並列性では、並列性の抽出性の仕方は前回のタスク並列性とほぼ同じです。ただし、タスク並列性ではフレーム間の並列性を抽出していたのに対し、ループ並列性では各層内の処理のイタレーション間の並列性を抽出している点が異なります。また、タスク並列性を抽出するには複数フレームの処理が同時に動く必要があるため、予め複数フレーム分の入力データが FPGA 上の DRAM に展開されている必要があるなどの制約がありました。一方、ループ並列性はフレーム内のみで完結しているため、特に制約などはなく並列性を抽出可能です。
ループ並列化を行う方法は非常に簡単で、次のように #pragma HLS pipeline II=1 という表記をループ内に加えるだけです。これを行うと、kw変数のループが 1サイクル毎、つまり毎サイクル処理できるような最適化が施されます。
17 for (int32_t ich = 0; ich < in_channels; ++ich) {
18 for (int32_t kh = 0; kh < ksize; ++kh) {
19 for (int32_t kw = 0; kw < ksize; ++kw) {
...
30 #pragma HLS pipeline II=1
31 sum += x[pix_idx] * weight[weight_idx];
32 }
33 }
34 }このプラグマの追加だけでII=1 を達成できれば良いのですが、上記修正後のカーネルを高位合成しても以下のように目標 (Target) を II=1 としたものの、実際の回路 (Final) は II=4 になったというログが出力されます。
INFO: [v++ 204-61] Pipelining loop 'Loop 1.1'.
INFO: [v++ 204-61] Pipelining result : Target II = 1, Final II = 4, Depth = 12.これは、31行目の sum += ... という処理において、直前のイタレーションの加算結果 sum に、次のイタレーションのsum の計算が依存しているためです。
一方、x[pix_idx] というロード処理や、x[pix_idx] * weight[weight_idx] という乗算処理は前イタレーションの結果に依存しないため、これは先に処理することができます。
#pragma HLS pipeline 適用後の波形は概ね以下のようになっています。

load, fmul は先に実行できるものの、fadd は直前のイタレーションが完了するまで実行できないため、全体の II は fadd のレイテンシである4サイクルに律速されます。
総和レジスタの複製による性能改善
前述したように、イタレーションi+1 の結果がイタレーションi に依存しているためこの畳み込み処理は毎サイクル実行することができません。ここでは、総和レジスタ sum を4つに複製することで、イタレーションi が依存するのはイタレーションi-4 の結果となるように、依存関係を変更します。文字だと分かりにくいので、先に目標とする波形を以下に示します。
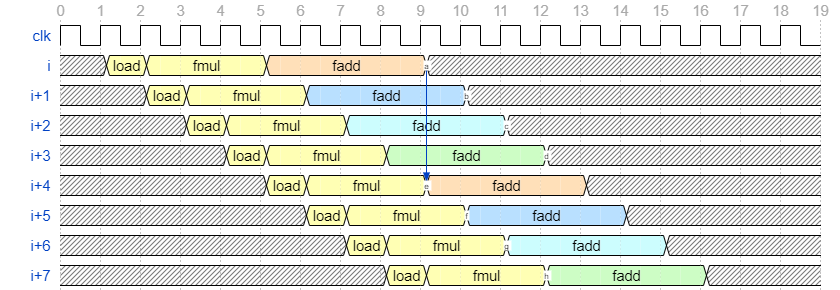
fadd の色 (橙、青、水、緑) が使用する fadd の出力先となるレジスタを表し、サイクル毎に出力先となるレジスタが切り替わっていきます。このようにすると、サイクル5で開始しサイクル8で完了したイタレーションiのfaddの計算結果が、サイクル9で初めてイタレーションi+4 により使用されます。
作成する回路としては上述したものを作れば良いのですが、これを Vivado HLS / Vitis から作成するには少し特殊な書き方が必要です。以下の記載は、shift_register_c という SDAccel 向けのチュートリアルの内容をベースに作成しています。
以下にシフトレジスタを使用した畳み込み関数のコードを記載します。コード全体は https://github.com/fixstars/dnn-kernel-fpga/blob/master/include/dnn-kernel/conv2d.h より確認できます。
82 static void conv2d_pipelined_v2(const float* x, const float* weight, const float* bias, int32_t width, int32_t height,
83 int32_t in_channels, int32_t out_channels, int32_t ksize, float* y) {
84 static const int kShiftRegLength = 4;
85
86 for (int32_t och = 0; och < out_channels; ++och) {
87 for (int32_t h = 0; h < height; ++h) {
88 for (int32_t w = 0; w < width; ++w) {
89 float shift_reg[kShiftRegLength + 1];
90 #pragma HLS array_partition variable=shift_reg complete
91
92 int32_t glob_idx = 0;
93 for (int32_t ich = 0; ich < in_channels; ++ich) {
94 for (int32_t kh = 0; kh < ksize; ++kh) {
95 for (int32_t kw = 0; kw < ksize; ++kw) {
96 #pragma HLS pipeline II=1
...
109 float mul = x[pix_idx] * weight[weight_idx];
110
111 // local sum
112 for (int i = 0; i < kShiftRegLength; ++i) {
113 if (i == 0) {
114 if (glob_idx < kShiftRegLength) {
// 外部でゼロ初期化するとシフトレジスタに推論されなくなるため、ループ内でゼロ初期化相当の処理
115 shift_reg[kShiftRegLength] = mul;
116 } else {
// 初期化時以外
117 shift_reg[kShiftRegLength] = shift_reg[0] + mul;
118 }
119 }
120
121 shift_reg[i] = shift_reg[i + 1];
122 }
123
124 ++glob_idx;
125 }
126 }
127 }
128
129 // global sum
130 float sum = 0.f;
131 for (int i = 0; i < kShiftRegLength; ++i) {
132 #pragma HLS pipeline II=1
133 sum += shift_reg[i];
134 }
135
136 // add bias
137 sum += bias[och];
138
139 y[(och * height + h) * width + w] = sum;
140 }
141 }
142 }
143 }差分としては、大きく分けて次の3箇所があります。
- シフトレジスタの定義 (L89-L90)
- ローカルな総和: 複製した総和レジスタ上での総和処理 (L111-L122)
- グローバルな総和: 複製した総和レジスタ間の総和処理 (L130-L134)
1 のシフトレジスタの定義では、4+1個の総和レジスタを FPGA 上のレジスタとして定義しています。+1 個は単なるテンポラリのレジスタで、C 言語の文法上で加算結果を一時的に格納するためだけに使用され、高位合成時には削除されます。90 行目で #pragma HLS array_partition という新しいプラグマが追加されていますが、これはデフォルトで BRAM として推論されるシフトレジスタを、レジスタ (complete) として定義するためのプラグマです。このプラグマ自体は他にも色々なことができるのですが、詳細は次回のデータ並列化時に触れる予定です。
2 のローカルな総和では、4 個の総和レジスタに対して乗算結果 (mul) を累積していきます。ここで、glob_idx が ich, kh, kw の3ループをまとめたインデックスです。普通に shift_reg[glob_idx % 4] += mul とすれば今回行う出力レジスタの複製はできそうですが、これだと高位合成結果が II=4 のまま変化しません。そのため、ここでは公式のサンプルでも用いられるシフト処理 (shift_reg[i] = shift_reg[i + 1]) を用いて II=1 を達成しています。毎回加算が行われるのは shift_reg[0] と mul の2レジスタなのですが、shift_reg[0] に入っている総和レジスタの番号 (0~3) がサイクル毎に変化します。
3 のグローバルな総和では、4 個の総和レジスタ間での総和処理を行います。ここでも同様に#pragma HLS pipeline を指定していますが、ここはfadd のレイテンシによりII=1 にはなりません。
このように修正すると、kw ループの II を1にすることができ、最も効率よくループ並列化を行えます。一方でグローバルな総和のループが別途追加されるため、この修正での速度向上率は4倍に達しません。
性能評価
合成結果の確認
以下の3つの構成に関して、性能を比較します。
- メモリアクセスの最適化後(ループ並列なし)
- 1 に
#pragma HLS pipeline II=1のみを付与 - シフトレジスタを用いた高速化後
結果をまとめると以下の表のようになります。
| 構成 | 畳み込み層 II | 2層目の畳み込みの反復回数 (II) | 推論処理全体の反復間隔 (II) |
|---|---|---|---|
| ループ並列なし | 8 | 481377 | 481378 |
pipeline のみ | 4 | 257153 | 257154 |
| シフトレジスタ適用後 | 1 | 127009 | 172482 |
2層目の畳み込み層に注目すると、ループ並列なし -> pipeline のみの変化で概ね1.87倍、pipeline のみ -> シフトレジスタ適用により2.02倍程度の性能向上が得られています。ここで、本来はII=4 -> II=1 となっているため4倍くらい性能が向上して欲しいところですが、実際は上述したグローバルな総和処理が大きな時間を占めるため、そこまでの速度向上が得られません。
以下にシフトレジスタ適用後の構成の HLS レポートを示します。
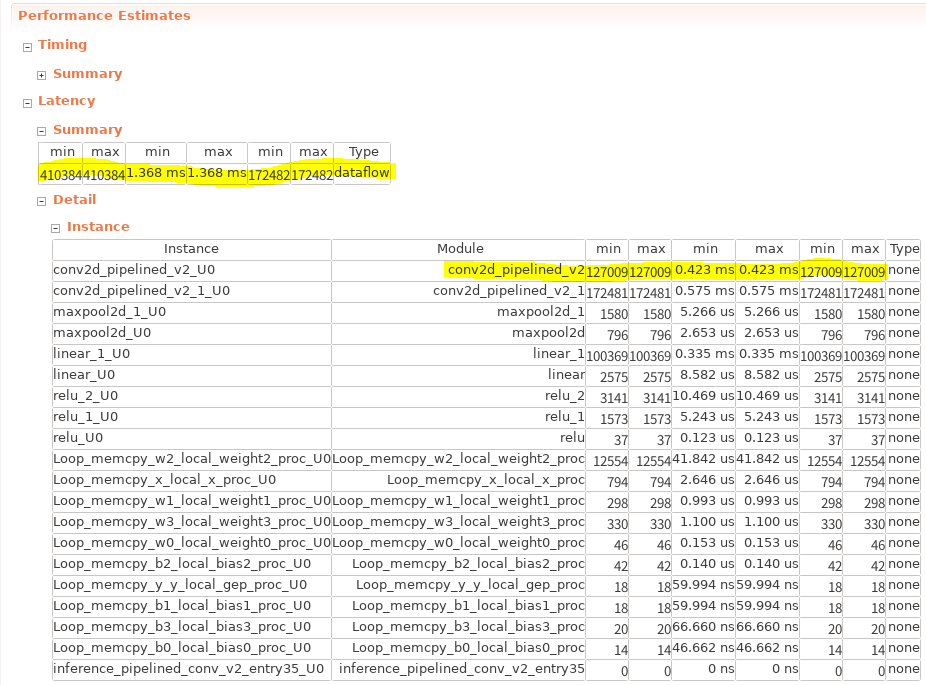
これまでの推論処理では2層目の畳み込み層 (conv2d_pipelined_v2) がボトルネックでしたが、ここでは1層目の畳み込み層 (conv2d_pipelined_v2_1) がボトルネックになっています。これは1つ目の畳み込み層が1ch, 3×3 の畳み込みのため、そもそも画素あたり高々9回分の演算しか行われていなかったためです。この場合は II=1 でローカルな総和を行えることによる性能向上を、グローバルな総和ループの追加による性能低下が上回り、逆に性能が低下しています。一方で、この入力チャネル数やカーネルサイズが大きくなればなるほどローカルな総和処理の性能向上が目立ってくるため、大規模なネットワークではこの最適化はより効果的となります。
実機での処理結果
実行ログは以下のようになり、処理時間は0.6ms 付近まで縮まりました。
$ ./host/run_inference ./host/inference_pipelined_conv_v2_hw.xclbin inference_pipelined_conv_v2 1
Elapsed time: 0.607567 [ms/image]
accuracy: 0.976ループ並列性を抽出することにより、並列化を行う前よりも順当に性能が向上しています。
まとめ
ここまでのチューニングによる高速化率は以下のようになります。
| 名称 | 実行時間 (ms/image) | 直前の実装からの速度向上率 | ベースラインからの向上率 |
|---|---|---|---|
| ベースライン | 20.81 | 1.00 | 1.00 |
| タスク並列化 | 12.65 | 1.65 | 1.65 |
| ローカルバッファによる外部メモリアクセス削減 | 1.61 | 7.86 | 12.93 |
| ループ並列化 (畳み込み層のみ) | 0.61 | 2.64 | 34.11 |
元の実装が速度のことを全く考えていなかったのはありますが、少しのプラグマ追加とコード修正により、ベースラインから34倍まで速度向上が得られています。
現状特に効果的だったのは、この記事の冒頭で行ったメモリアクセスのチューニングです。FPGA は豊富な内部 RAM 帯域が強みの一つなので、今回のように外部メモリへのアクセスを隠蔽することで大きな性能向上を得られることが多いです。
次回の記事ではこのカーネルに対してデータ並列化を施し、更なる高速化を行っていきます。
このブログに記載しているコードは https://github.com/fixstars/dnn-kernel-fpga で公開しています。コードの権利、ライセンスに関してはライセンスファイルを参照して下さい。
株式会社フィックスターズ シニアエンジニア 松田裕貴