本コースの第3回目と第4回目では、NNgen とニューラルネットワーク・フレームワーク Pytorch を用いて、学習済みのモデルを SoC 型の FPGA の Ultra96-V2 上で動かしてみます。
今回の第4回は、PYNQ と Jupyter を用いて、Ultra96 上で、第3回で開発した VGG-11 専用回路を実際の FPGA システム上で動かします。
Ultra96 向け PYNQ の構築
まず、Ultra96 向けの PYNQ のリポジトリの Releaseにある、ビルド済みの SD カードのイメージファイルをダウンロードします。Ultra96-V1 用と V2 用の異なる SD カードのイメージが提供されていますので、ボードのバージョンに応じて正しいイメージファイルをダウンロードしてください。
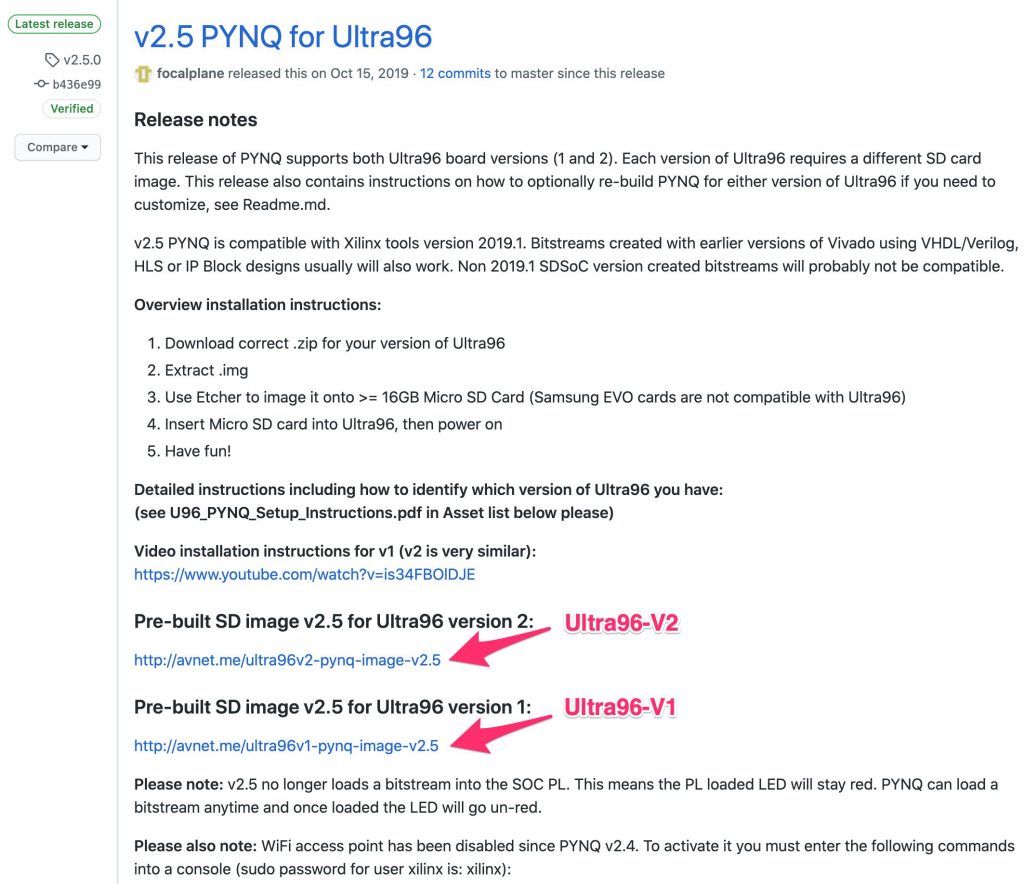
ダウンロードの後、同じページに記載されている手順に従って、ダウンロードしたイメージファイルを SD カードに展開します。以下に手順を引用します。
Overview installation instructions:
1. Download correct .zip for your version of Ultra96
2. Extract .img
3. Use Etcher to image it onto >= 16GB Micro SD Card (Samsung EVO cards are not compatible with Ultra96)
4. Insert Micro SD card into Ultra96, then power on
5. Have fun!CMA 領域の最大サイズの変更
PYNQ では、CPU と FPGA 回路が共有するメモリ領域を CMA (Continuous Memory Allocator) という仕組みを用いて確保しています。ここでは、このメモリ領域のことを CMA 領域と呼ぶことにします。
今回のニューラルネットワークアクセラレータの場合では、入力データや重みパラメータ等を CMA 領域に、CPU 上のソフトウェアから予めロードした後、FPGA 上のハードウェアアクセラレータの実行を開始することで、アクセラレータが自律的に必要なデータを DMA で読み書きし、計算を行っています。
確保可能な CMA 領域の大きさ (最大サイズ) は、ブート関連ファイルのビルドスクリプト で指定することができます。
上記のビルド済みの PYNQ イメージでは、CMA 領域の最大サイズは 128MB となっています。しかし、今回開発した VGG-11 専用アクセラレータは、それ以上のメモリ領域を必要とするため、ブート関連ファイルの再ビルドが必要となります。
自前で再ビルドするのが面倒な場合には、再ビルド済みの CMA 領域サイズを増やしたブートファイルをアップロードしておきますので、ご利用ください。
Boot files for PYNQ on Ultra96-V2
ブート関連ファイルの再ビルド方法
自分で PYNQ のブート関連ファイルの更新を行う場合は、以下の手順で進めます。
まず、予め Vivado SDK と Petalinux をインストールしておきます。今回は2019.1を用いています。
次に、PYNQ と Ultra96 ボードファイルのリポジトリを clone します。このとき、NFS 等で他のマシンと共有しているファイルシステム上では、ルート権限がファイルの書き込みができず、正しくビルドができないことがあるため、ルート権限で書き込みができる場所に展開することをおすすめします。
mkdir build_pynq_ultra96v2
cd build_pynq_ultra96v2
git clone https://github.com/Xilinx/PYNQ.git
git clone https://github.com/Avnet/Ultra96-PYNQ.gitimage_v2.5 というタグがついたブランチに切り替えます。
cd PYNQ
git checkout image_v2.5
cd ../
cd Ultra96-PYNQ
git checkout image_v2.5“PYNQ/sdbuild/sdbuild/setup_host.sh” を実行し、ビルド環境を構築します。
source /opt/Xilinx/SDK/2019.1/settings64.sh
source /opt/Xilinx/petalinux/2019.1/settings.sh
cd PYNQ/sdbuild
bash scripts/setup_host.sh“PYNQ/sdbuild/boot/meta-pynq/recipes-kernel/linux/linux-xlnx/pynq.cfg” の “CONFIG_CMA_SIZE_MBYTES=128” の行を編集します。ここでは、512MB に変更しています。
CONFIG_CMA_SIZE_MBYTES=512ビルド環境構築ができたら、”PYNQ/sdbuild/sdbuild” で、”make boot_files” を実行しブート関連ファイルのみを再ビルドします。その際、”BOARDDIR” で先ほど clone した Ultra96-PYNQ のリポジトリの場所を指定します。
source /opt/Xilinx/SDK/2019.1/settings64.sh
source /opt/Xilinx/petalinux/2019.1/settings.sh
export PATH=/opt/qemu/bin:/opt/crosstool-ng/bin:$PATH
cd PYNQ/sdbuild
make boot_files BOARDDIR=/home/yourname/build_pynq_ultra96v2/Ultra96-PYNQ再ビルドに成功すると、”PYNQ/sdbuild/output/boot/Ultra96/” に “BOOT.BIN” と “image.ub” が生成されているはずです。これらのファイルを先ほどイメージを展開した SD カードの第1パーティションにコピーします。
PYNQ/Ultra96 の起動
ここまでの手順で、Ultra96 上で PYNQ を起動する準備が整いました。
PYNQ イメージと先ほど再ビルドしたブートファイルを書き込んだ SD カードを Ultra96 に差し込み、ネットワークに接続し、電源を入れます。ここでは、下図のように、USB-LAN アダプタを用いて有線 LAN で Ultra96 をネットワークに接続します。

Jupyter Notebook で Ultra96 にアクセスする
まず、Ultra96 の IP アドレスを何かしらの方法で調べましょう。多くの場合、DHCP により IP アドレスが自動的に割り当てられていると思いますので、DHCP サーバーのログなどを参考に、IP アドレスを特定します。
WEB ブラウザで Ultra96 の IP アドレスにアクセスします。デフォルトのパスワードは “xilinx” です。
vgg11 というフォルダを作成しましょう。
そして、作成したフォルダの中に、
- “nngen/pynq” の “nngen_ctrl.py”
- “nngen/examples/torchvision_onnx_vgg11” の “imagenet_class_index.json”
- “nngen/examples/torchvision_onnx_vgg11” の “car.png”
- 第3回で生成した重みファイル “vgg11_imagenet.npy”
- 第3回で生成したハードウェアのファイル “design_1_wrapper.bit” と “design_1.hwh” を、それぞれ “vgg11.bit” と “vgg11.hwh” とリネームしたもの
をコピーします。
これで、Jupyter Notebook で VGG-11 専用アクセラレータを使う準備が整いました。
Jupyter Notebook で VGG-11 専用アクセラレータを使う
それでは、Jupyter Notebook 経由で、VGG-11 専用アクセラレータに画像認識をさせてみましょう。順番に操作していきます。
まず、必要なライブラリをインポートします。
from pynq import Overlay, allocate
import numpy as np
import PIL.Image
import nngen_ctrl as ng先ほどコピーした画像ファイルを開き、表示させます。
pic = PIL.Image.open('car.png').convert('RGB')
pic画像が表示されました。
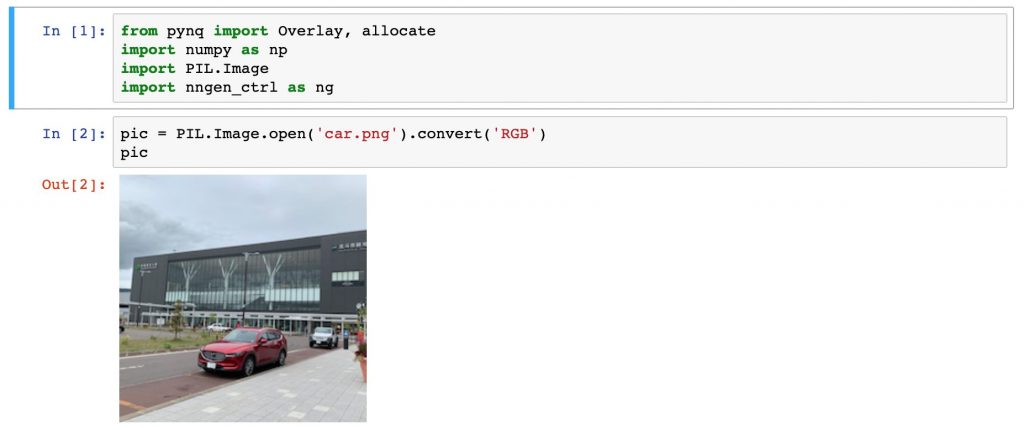
開いた画像に前処理を適用します。そして、学習済みモデルの重みパラメータファイルを読み込みます。
act_shape = (1, 224, 224, 3)
act_scale_factor = 64
imagenet_mean = np.array([0.485, 0.456, 0.406]).astype(np.float32)
imagenet_std = np.array([0.229, 0.224, 0.225]).astype(np.float32)
img = np.array(pic).astype(np.float32)
img = img.reshape([1] + list(img.shape))
img = img / 255
img = (img - imagenet_mean) / imagenet_std
img = img * act_scale_factor
img = np.clip(img, -127.0, 127.0)
img = np.round(img)
img = np.broadcast_to(img, act_shape)
# padding for alignment: (1, 224, 224, 3) -> (1, 224, 224, 4)
input = np.append(img, np.zeros([img.shape[0], img.shape[1], img.shape[2], 1]), axis=3)
input = np.reshape(input, [-1]).astype(np.int8)
param = np.load('vgg11_imagenet.npy')ハードウェア情報をFPGA上にロードします。
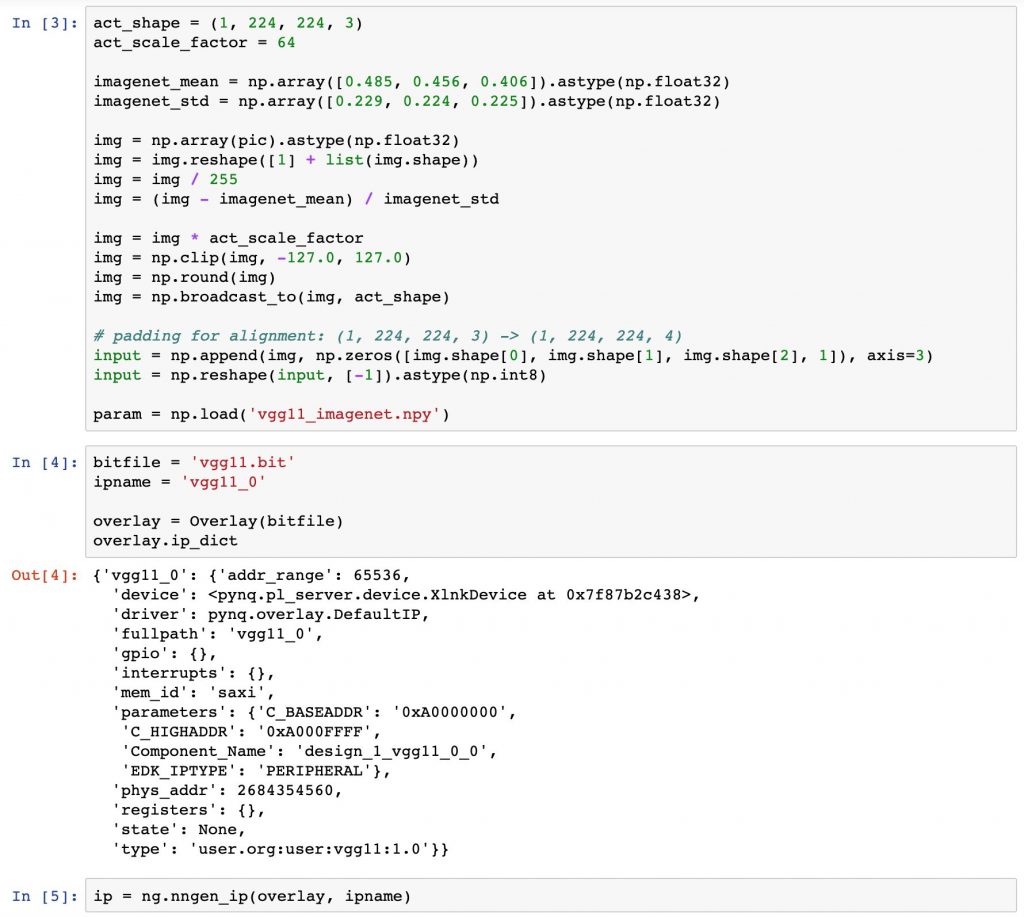
bitfile = 'vgg11.bit'
ipname = 'vgg11_0'
overlay = Overlay(bitfile)
overlay.ip_dictip = ng.nngen_ip(overlay, ipname)“vgg11_0” という IP コアが認識されています。
CPU 上のソフトウェアと FPGA 上の IP コアで共有するメモリ領域を確保します。
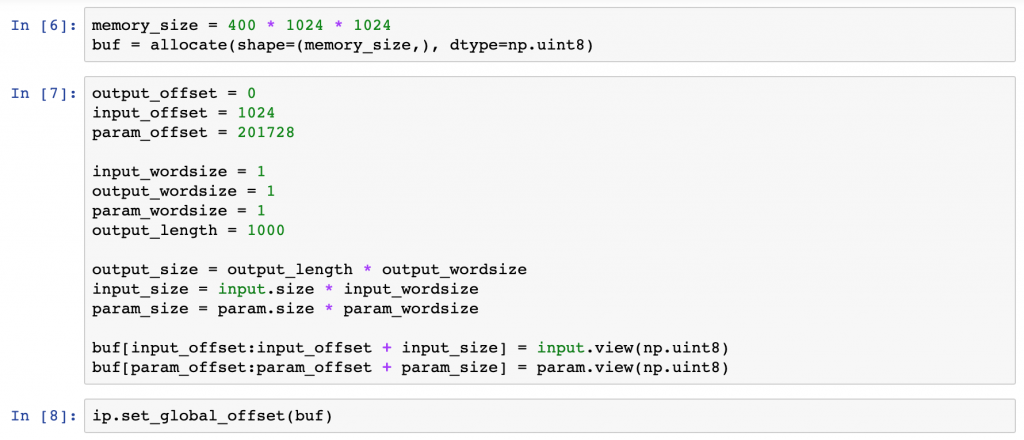
memory_size = 400 * 1024 * 1024
buf = allocate(shape=(memory_size,), dtype=np.uint8)確保した共有メモリ領域に画像データを学習済みモデルの重みパラメータをコピーします。共有メモリ空間のどこに、どのデータを配置すれば良いかは、NNgen で IP コアを生成した際のログファイルに記載されています。
output_offset = 0
input_offset = 1024
param_offset = 201728
input_wordsize = 1
output_wordsize = 1
param_wordsize = 1
output_length = 1000
output_size = output_length * output_wordsize
input_size = input.size * input_wordsize
param_size = param.size * param_wordsize
buf[input_offset:input_offset + input_size] = input.view(np.uint8)
buf[param_offset:param_offset + param_size] = param.view(np.uint8)共有メモリ領域の先頭アドレスを IP コアに教えます。
ip.set_global_offset(buf)アクセラレータを動かす準備が整いました。
遂に VGG-11 専用アクセラレータを動かします。”ip.run()” で実行開始、”ip.wait()” で実行完了を待ち合わせます。
import time
start_time = time.time()
ip.run()
ip.wait()
end_time = time.time()
elapsed_time = end_time - start_time
print(elapsed_time)実行完了しました。約9.7秒かかったようです。
あまり速くありませんね・・・。ニューラルネットワークのモデルとハードウェアの両面で最適化が必要ですね。

認識結果を見てみましょう。
import json
class_index = json.load(open('imagenet_class_index.json', 'r'))
labels = {int(key): value for (key, value) in class_index.items()}
output = buf[output_offset:output_offset+output_size].view(np.int8)
top10_index = np.argsort(output)[::-1][:10]
for index in top10_index:
print(index, labels[index], 'score:', output[index])第3回で、NNgen での IP コア生成前に、ソフトウェア実行した際の結果と一致しています。処理結果は正しいようです。画像ファイルを変更するなどして、他の振る舞いも試してみると良いでしょう。
751 ['n04037443', 'racer'] score: 97
817 ['n04285008', 'sports_car'] score: 87
573 ['n03444034', 'go-kart'] score: 76
468 ['n02930766', 'cab'] score: 74
511 ['n03100240', 'convertible'] score: 73
656 ['n03770679', 'minivan'] score: 71
436 ['n02814533', 'beach_wagon'] score: 71
627 ['n03670208', 'limousine'] score: 71
705 ['n03895866', 'passenger_car'] score: 71
575 ['n03445924', 'golfcart'] score: 69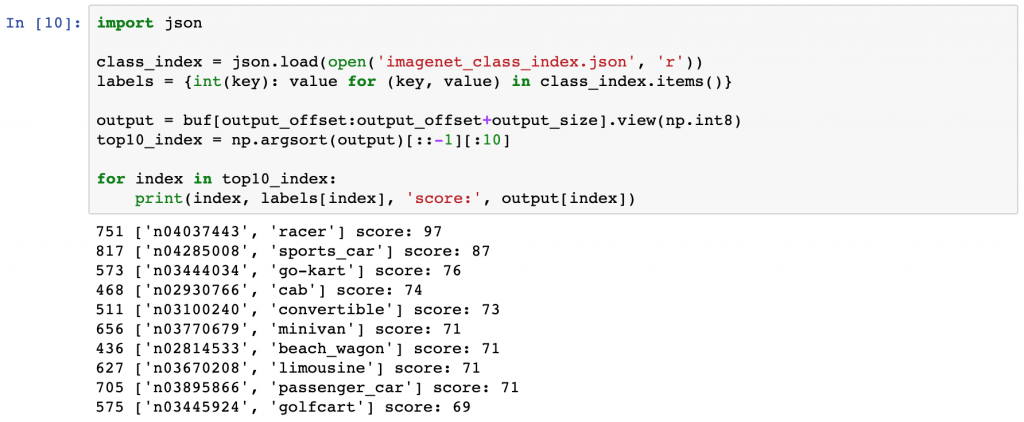
まとめ
第3回と第4回では、NNgen とニューラルネットワーク・フレームワーク Pytorch を用いて、学習済みのモデルを SoC 型の FPGA の Ultra96-V2 上で動かすまでの流れを紹介しました。NNgen を用いることで、ハードウェア記述を一切することなく、FPGA 上で学習済みのニューラルネットワークモデルを動作させることができました。
今回作成した VGG-11 専用アクセラレータは、torchvision で公開されている学習済みモデルをそのままハードウェア化したため、それほど高速ではありませんでした。高速化のためには、モデルの軽量化とハードウェアにおける並列化が必要です。特に、ハードウェアの並列化を行う前に、そもそも計算量が少ない軽量なモデルを作った上で、ハードウェア化することが重要です。
NNgen の活用例としては、経済産業省が主催する第2回AIエッジコンテスト「FPGA を使った自動車走行画像認識」では、Tiny-YOLO v3 に基づく物体認識アクセラレータを NNgen を用いて実装したチーム (筆者ではありません) が第2位に入賞しているようです。
また、GROOVE X 社で開発している家庭用ロボット LOVOT の表現を拡張するための姿勢推定アルゴリズムの処理に、NNgen を用いたニューラルネットワークアクセラレータの利用を試みているようです(コニカミノルタ社のプレスリリース)。
NNgen そのものにも最適化の余地が多く残されております。また、現状対応できていないオペレータも多く存在します。NNgen はオープンソース・ソフトウェアとして開発を進めていますので、皆さんからの気軽な pull request をお待ちしています。
東京大学 大学院情報理工学系研究科 コンピュータ科学専攻 高前田 伸也