
このコースでは、スーパーコンピュータ (以下、ブログの文字数節約のために一般的に使われている略称「スパコン」を使います) にも FPGA が何故使われ始めたのか、FPGA をスパコンに使うことによって何ができるようになるのか、どのような技術的な面白さがあるのか等について紹介していきます。
このコースもいよいよ最終回となりました。最後は Cygnus を使い倒すにあたって、前回の記事で紹介した以外にも解決しなければならない課題を紹介していきたいと思います。
なお、先に謝っておきますが、これから紹介する内容は、現在着手中でまだ論文として公開されていないもので、あまり具体的には書けません。ですので、この記事 (できればこれまでの記事も) を見て、興味を持って頂けた方は、今後の我々の出版された論文を是非お読み下さい。
もっと Cygnus を使い倒そう!
どうやってプログラミングするの?
前回の記事では、GPU と FPGA とを相補的に利用するための GPU-FPGA 間のデータ転送技術について紹介しました。そして、GPU と FPGA をソフトウェア的に連携させるためには、ハードウェア及び周辺システムの開発だけでなく、GPU および FPGA を同一プログラムから呼び出し、開発した DMA 転送技術を活用しながら協調計算を行うためのプログラム環境が必要です。
そのため、我々は GPU と FPGA のコンパイル環境や開発言語の組み合わせを調査し、GPU-FPGA 協調計算を行うための基本モデルを提案しています。下にそのコンパイルフローを示します。
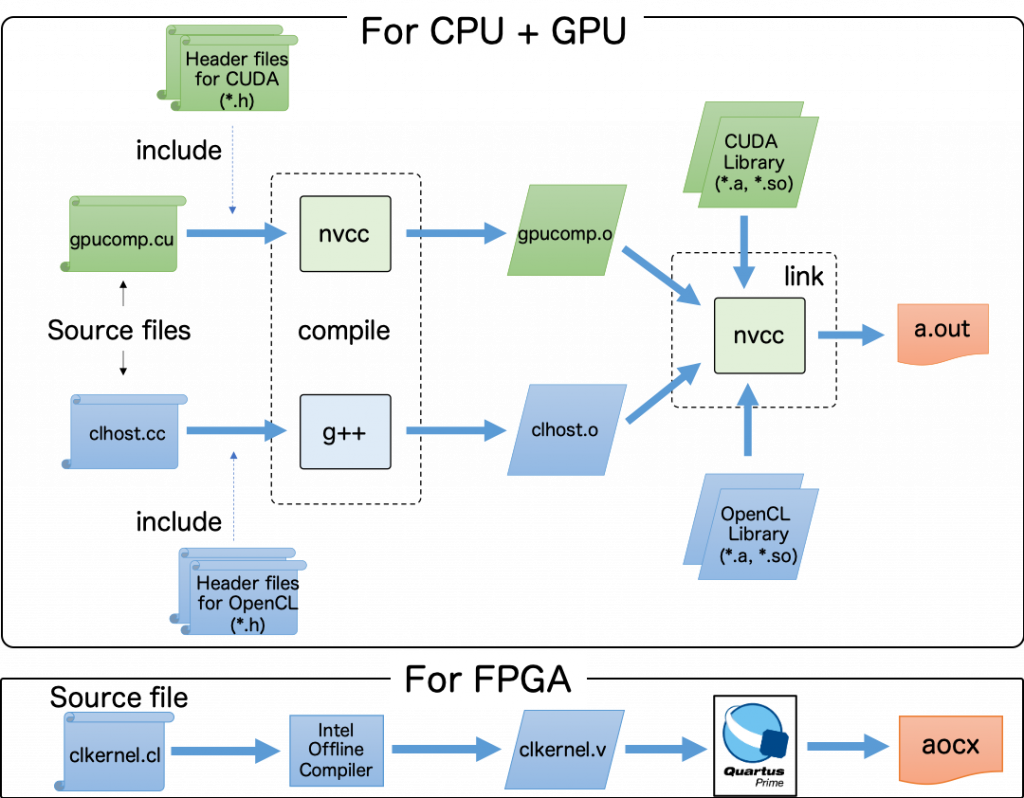
GPU プログラムは CUDA、FPGA プログラムは OpenCL で記述されます。図に示すように、CUDA コードと OpenCL ホストコードは、nvcc と g++ を用いて分割コンパイルされ、生成されたオブジェクトファイルは、nvcc でリンクされることによって、実行ファイル (図の a.out) が生成されます。そして、OpenCL カーネルコードはホストコードとは別にコンパイルされ,FPGA にオフロードされる演算を実行する回路情報を含む aocx が生成されます。この aocx ファイルは、ホストアプリケーションの実行時に OpenCL API を用いることで FPGA にダウンロードされ、その際に回路のコンフィグレーションが行われます。
ここで「OpenCL はヘテロジニアスな環境でもちゃんとアプリが動くことを前提としたプラットフォームなのだから、全部 OpenCL でやればいいじゃない」と思われる方もいると思います。我々が CUDA を対象にしている最大の理由は、HPC における実アプリケーションのほとんどが CUDA で記述されているためです。そして、NVIDIA GPU アーキテクチャに追従した CUDA を利用した方が、GPU の性能を最大限に引き出しやすいと個人的に思っています。このため、CUDA + OpenCL のマルチリンガルプログラミングを採用しました。
GPU と FPGA が協調して計算していることを確認するために、GPUでベクタ加算、FPGAで加算結果のリダクション演算を同時かつ非同期的に実行するサンプルコードを実装しました。これを上記のコンパイル方法でコンパイルして実行させたところ、意図した通りの結果を示すことが確認されました。
ただし、このような複数のプログラミング言語を用いたマルチリンガルプログラミングは、ユーザーに多大な負担を強います。そのため、今後の研究では GPU と FPGA が搭載された計算機システム上で、両アクセラレータの統合的な制御を可能にするプログラミング環境について検討していきます。
現在、この手法の一つとして、米国 Oak Ridge National Laboratory の Jeff Vetter 博士の研究グループとの共同研究を進め、同グループが開発中の FPGA をターゲットとした OpenACC コンパイラである OpenARC を用い、演算加速コードの評価及び我々の環境への実装を行なっています。
ここでは、OpenACC を FPGA 及び GPU の共通プログラミング言語として位置付け、それぞれのデバイス用に書かれた OpenACC 化されたコード (カーネルコードに相当) を、GPU 用部分と FPGA 用部分に分割します。前者を従来の PGI 製 OpenACC コンパイラで、後者を OpenARC でそれぞれ部分コンパイルし、生成されたオブジェクトを PGI コンパイラのホストコードと連結することで、OpenACC のみで両デバイスの演算加速プログラムを完結する「プログラミング環境の構築」を進めています。
GPU と FPGA の同期は?
Cygnus は GPU と FPGA が協調動作して、アプリケーションを加速させることを狙っています。そのために、解決しなければいけないのは「GPU-FPGA 間の同期をどのように実行するか」です。この問題を図示しました。
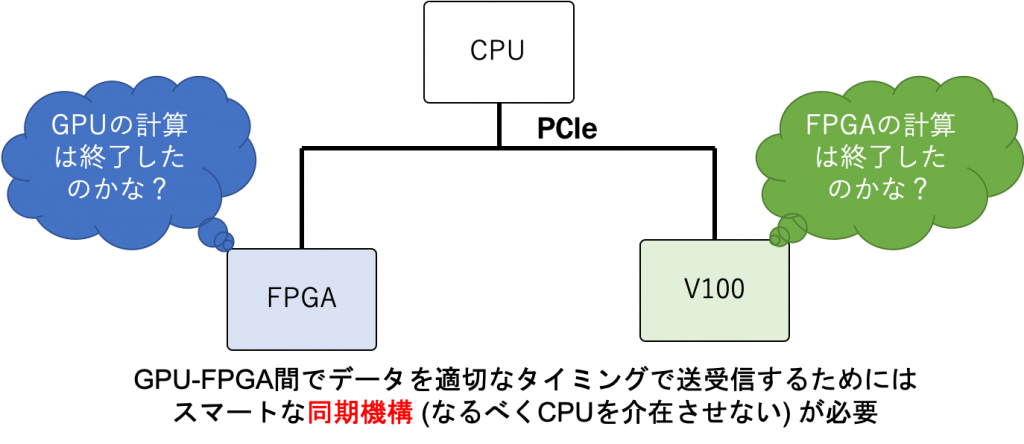
FPGA が、GPU のデバイスメモリにあるデータを DMA で持ってきて演算をスタートさせる場合は、FPGA は GPU の計算が終了したかどうか、すなわち DMA で持ってくるデータは GPU による更新が終わったものかどうかを正確に検知する必要があります。
逆に、GPU が FPGA の計算結果を受け取って演算を進める場合は、GPU は FPGA からデータを受け取ったことを GPU 自身が検知する必要があります。そして、Cygnus は GPU-FPGA 間で演算処理を完結させることを想定しているので、上記の同期処理をなるべく CPU を介在させないで実行することが理想です。
アプリケーションは?
我々は、複数の物理モデルや複数の同時発生する物理現象を含むシミュレーションであるマルチフィジックスアプリケーションを加速させるために、GPU と FPGA のカップリングが重要であると考えています。マルチフィジックスの概念を下に示します。
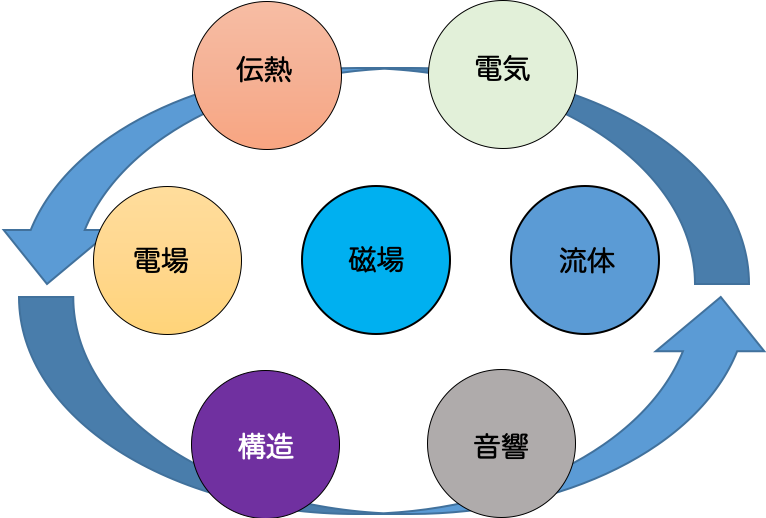
マルチフィジックスの特性上、シミュレーション内に様々な特性の演算が出現するため、GPU だけでは演算加速が困難な場合があります。そのため、GPU だけでは対応しきれない特性の演算の加速に FPGA を利用することで,アプリケーション全体の性能向上を狙います。

現在、我々はマルチフィジックスの例である宇宙輻射輸送シミュレーションコード Accelerated Radiative transfer on Grids using Oct-Tree (ARGOT) を対象に研究に取り組んでいます。ARGOT コードは、筑波大学 計算科学研究センターで開発されている宇宙輻射輸送を解くプログラムであり、初期宇宙における天体形成をシミュレーションします。
ARGOT コードの最大の特徴は、「点光源からの輻射輸送を計算する ARGOT 法」と「空間に広がる光源からの輻射輸送を計算する Authentic Radiative Transfer (ART) 法」との2つのアルゴリズムを組み合わせて輻射輸送問題を解く点です。図に示すように、我々は主要演算部分である ARGOT 法と ART 法を、それぞれ GPU と FPGA に適材適所的に機能分散して ARGOT コードを最適化します。
まとめ
今回の記事では、Cygnus を本格的に利用するためには、どのような問題を解決しなければならないかについて説明しました。これで本コースの連載は終了です。
HPC の分野で FPGA をちゃんと使うためには、色々と考えなければならないことが多いですが、その分やりがいも感じられると筆者は思います。もし、Cygnus や 我々の研究内容についてより詳しく知りたい方は、計算科学研究センターの広報に随時お問い合わせ下さい。
ここまでお読み下さった方々に厚く御礼を申し上げます。ありがとうございました。
筑波大学 計算科学研究センター 小林諒平