
前回の記事では Vivado で Aurora 64B/66B コアを生成し、シミュレーションで動かしてみましたが、中身はブラックボックスでした。外からわかるのは、
- シリアルトランシーバから信号が出始めるまでは時間がかかる (約4.5µs)
- リンクが確立されるまではさらに時間がかかる (約19µs)
- データを送受信するパラレルインタフェイスは、シリアルリンクのラインレートのクロックを分周したものになっている
といったことです。もちろん、Aurora 64B/66B コアを使ってデータを転送するアプリケーションの設計にはこれだけわかっていれば充分なのですが、やろうと思えば何でも作り込めるのが FPGA ですし、今回は (ほぼ) ブラックボックスなしに、基本的な機能を提供する IP コアだけでトランシーバを直接触ってみることにします。
今回は通信できるところまではたどり着けませんが、あと2回の残りの連載で、これを元に Xilinx の Aurora 64B/66B コアと通信するところまで解説していきたいと思います。その他のプロトコルの実装にも役立つことと思います。
トランシーバのクロッキングアーキテクチャ
トランシーバコアを直接触る、といっても、プリミティブを直接記述して動かすのは大変なので、Vivado や Quartus に付属する IP コアである程度の形を作ることにしましょう。ここでは、
- Xilinx Ultrascale / Ultrascale+ の GTH, GTY トランシーバ
- Intel Arria 10 GX / Cyclone 10 GX の GX トランシーバ
を扱いますが、基本的にはどちらも同じですし、両社の他のトランシーバにも応用することが可能です。
ところで、前回や前々回の記事をお読みくださった方は、トランシーバを動かすのには、まずクロックの供給が大事、という気持ちを理解していただけていると思います。トランシーバへ供給されるクロックは、周波数の安定性やジッタの少なさが重要なので、トランシーバの近くに設けられた専用の PLL (Phase Locked Loop) から供給されます。まずは、実際の FPGA でこれらはどのように配置されているか、というところから見ていきましょう。
Xilinx GTH, GTY トランシーバ
Xilinx の最近の FPGA ではいずれもトランシーバは4チャネルひと組で、これをトランシーバクワッド (Transceiver Quad) と呼んでいます。トランシーバチャネルはチャネルごとに備えられた Channel PLL、またはクワッドで共通の Quad PLL によって駆動されます。
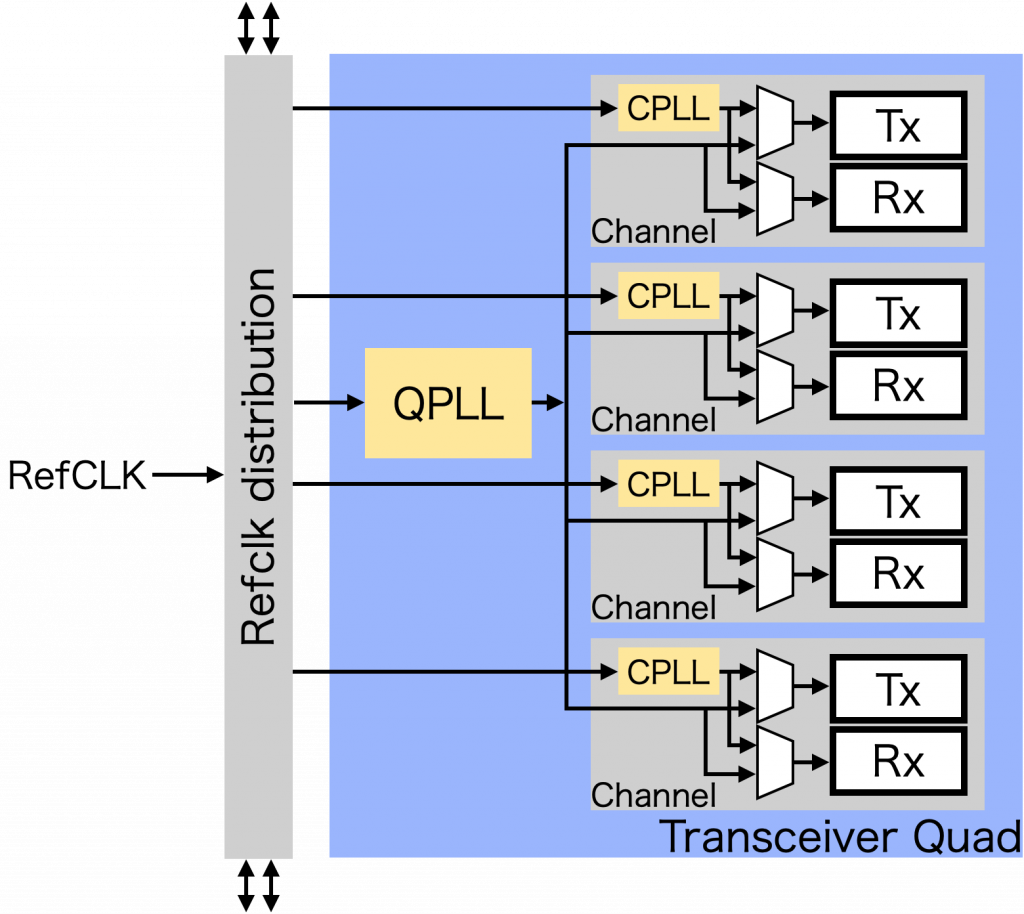
(説明のために簡略化しています)
Channel PLL (CPLL) はリングオシレータ型の PLL で 2.0-6.25GHz、Quad PLL (QPLL) は LC タンク型の PLL で 8.0-16.375GHz のクロックを生成可能で、どちらもラインレートはこの2倍のレートを分周して生成されます。ただしこの周波数帯域は、もっとも高いスピードグレードの場合で、「ふつうの」グレードの FPGA で 10Gbps を出すなら QPLL が唯一の選択肢です。また、QPLL のほうが特性的にも優れているので、チャネルごとにラインレートが異なるような構成になる場合を除き、QPLL を利用したほうがよいでしょう。
QPLL や CPLL を駆動する参照 (reference) クロックは FPGA の外部から供給されますが、これは隣接するクワッドと共有できる構造になっており、必ずしも全部のクワッドにクロック入力が接続されている必要はありません。
Intel GX トランシーバ
Intel の Cyclone / Arria FPGA の GX トランシーバでは、3〜6 チャネルがひと組で、これをトランシーババンク (Transceiver Bank) といいます。Cyclone 10 GX ではバンクあたり 4 チャネルまたは 6 チャネルで、Arria 10 GX ではバンクあたりのチャネルは 3 または 6 です。各バンクには、最低3チャネルに1つ、Advanced Transmit PLL (ATX PLL) と Fractional PLL (fPLL) の2つの PLL が用意されています。つまり、3チャネルのバンクでは ATX PLL と fPLL は1組、4チャネルまたは6チャネルのバンクでは2組、というわけです。
ATX PLL は LC タンク型、fPLL はリングオシレータ型、というのは Xilinx に似ていますが、両方ともバンクで共有です。チャネルごとの PLL も用意されているのですが、原則としてこちらは CDR (クロックデータリカバリ) 用で、チャネルによっては送信にも使える、といった具合ですので、今回は説明を省略します。
fPLL は 6.25GHz までで、データレートがクロックの 2 倍を基準とするのは Xilinx と同じです。12.5Gbps を超える場合は ATX PLL を使うことになりますし、それ以下のデータレートでも ATX PLL を使った方が安定性の面で有利です。隣接するバンクでクロックの入力を共有できるのも、Xilinx FPGA と同じです。
トランシーバに関連する IP コア
トランシーバに限らず、FPGA に備えられている各種の専用回路を直接使うには、「プリミティブ」と呼ばれるブラックボックスのモジュールを直接呼び出してやればよいのですが、これには使わない機能を抑制したりするための記述も必要で、とても大変です。そこで多くの場合には、ごく基本的な機能だけを提供する IP コアを利用するのが現実的です。当然、これらの IP コアはプリミティブの周辺回路を含みますが、それらは必要最低限といえるものですので、LUT や FF が無駄になるかも、という心配はご無用です。
Xilinx FPGA の場合
Xilinx FPGA では、Vivado の IP catalog に、Transceiver Wizard というツールが用意されています。ここでの例は Ultrascale FPGAs Transceiver Wizard ですが、Ultrascale+ でもほとんど同じです。7 series ではちょっと違いますが、基本的なことはやはり同じです。
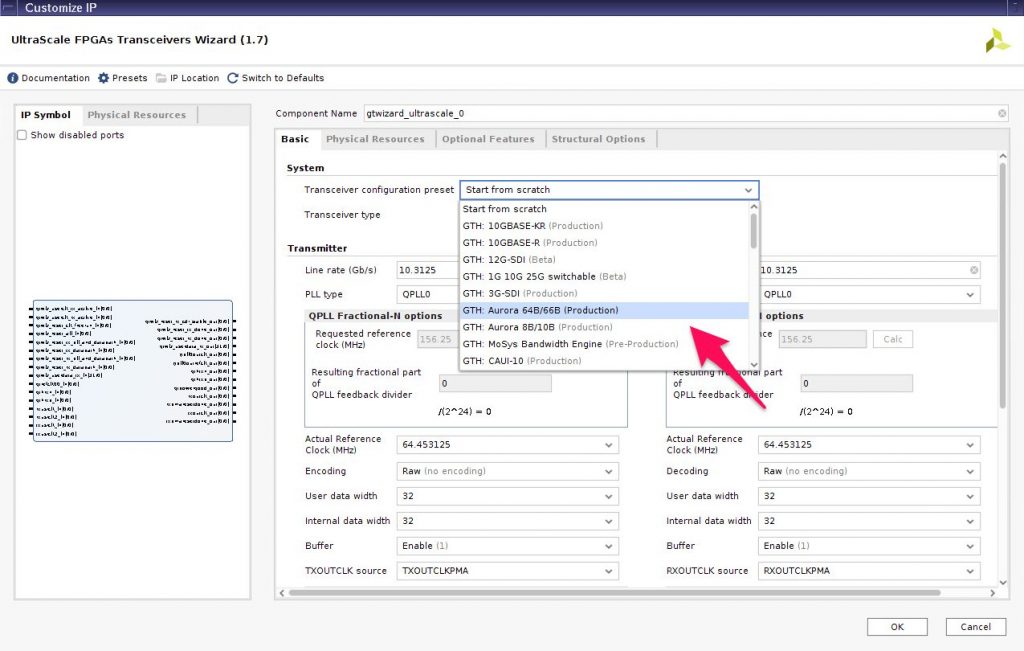
Transceiver Wizard を使うと、トランシーバコアの設定を行うだけでなく、PLL などの周辺回路と、初期化に必要なリセット関係の回路をまとめて生成してくれます。たくさんの設定項目がありますが、上の図に出ているように各種のプロトコルむけのプリセットが用意されており、これを出発点にすると簡単です。たとえば、筆者らのグループで開発した Aurora 64B/66B 互換コアでは以下のように設定しています。
- Transceiver configuration preset: (GTH-)Aurora_64B66B
- Line rate (Gbps): 10.3125
- Actual reference clock (MHz): 156.25
- Encoding: Async. gearbox for 64B/66B
- User data width: 64
プリセット以外は送受信でそれぞれ同じ値を設定しますが、たったこれだけです。ラインレートは使用する値、リファレンスクロックはボードのリファレンスクロックで決まりますし、64B/66B での通信なのでデータインタフェイスは 64bit 幅にするのが自然です。もうひとつ、ギアボックスという項目が残っています。これについては第 1 回目の記事でも簡単に触れましたが、ここでもう一度ご説明することにしましょう。
同期ギアボックスと非同期ギアボックス
PMA と PCS の間のインタフェイスはプロトコルを問わず、8, 10, 16, 20, …, 32 bit といったいくつかの決まったビット幅から選択するようになっており、ラインレートをビット幅で分周したクロック周波数で動作します。これをそれ以外のビット幅に変換したり、異なるクロックに載せ替えたりするのがギアボックスです。
ギアボックスには「同期ギアボックス」と「非同期ギアボックス」の 2 種類があります。同期ギアボックスは PMA に同期して動くので、たとえば PMA-PCS 間が 32bit で、PCS とユーザロジックの間が 64bit、といった具合で、この場合ラインレートが 10.3125Gbps ならばインタフェイスは 10.3125×1000/64 ≒ 161.13 MHz となります。ところで、64B/66B で通信する場合、PCS とユーザロジックの間でやりとりする信号には 64bit のデータブロックに 2bit のヘッダが付加されて合計 66bit です。これを 64bit 幅の同期ギアボックスで送受信するのはちょっとやっかいで、下の図のように 1 ワードごとに 2bit ずつずれていく、ということが起きてしまいます。
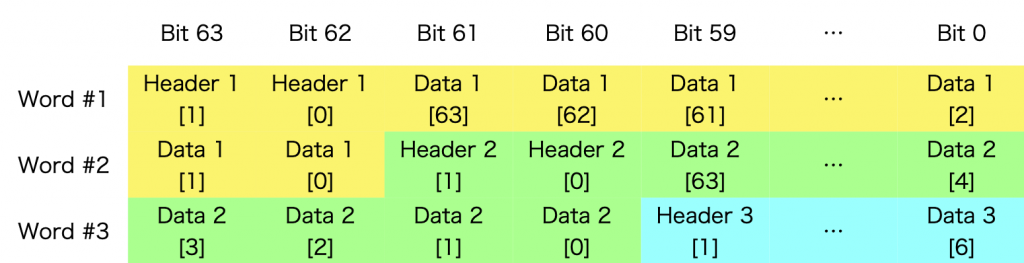
そこで登場するのが非同期ギアボックスです。これは文字通り歯車のように、32bit の PMA-PCS インタフェイスの信号を 66bit で ユーザロジックに接続します。この信号のクロックは 10.3125Gbps ならばその 1/66 の 156.25MHz で、PMA-PCS インタフェイスのクロックの整数倍ではなくなるので「非同期」ギアボックスと呼ばれます。このクロックは、PMA のクロックを分周して作られますので、特に何かクロック関係の回路を追加で設計に含める必要はありません。
ところで、非同期ギアボックスを使えばデータとヘッダ合わせて 66bit でアクセスできるわけですが、トランシーバの電源が入り、リンクが接続された直後はどこがヘッダでどこがデータなのかがわかりません。つまり、ワード境界のアライメントがわからない、ということですが、これを合わせるためにはプロトコルごとに定めた初期化シーケンスの文字列を送信して、それを正しく受信できるように初期化をすることになっています。この際に、64bit 幅とか 66bit 幅のシフト回路をユーザロジック側で持つのは大変なので、ギアボックスでアライメントを調整できる仕組みがあります。
アライメントを調整する操作をビットスリップと呼び、Ultrascale/Ultrascale+ のトランシーバウィザードが生成する IP コアでは rxgearbox_in という信号でこれを制御します。この信号の立ち上がりで 1bit ギアボックスのアライメントがシフトされるようになっており、これは Intel を含め、多くの FPGA のトランシーバで採用されている方式です。実際にどのように使うかは次回の記事で、Xilinx 純正の Aurora 64B/66B コアと接続した事例を取り上げて解説していきます。
Aurora コアの Shared Logic に相当するもの
前回解説したように、Aurora 64B/66B には “Shared Logic” とよばれる部分がありました。ここには PLL や、リセットに関連するロジックが含まれます。Transceiver Wizard では、この部分がもうちょっと細かく分類されており、下の図のようになっています。
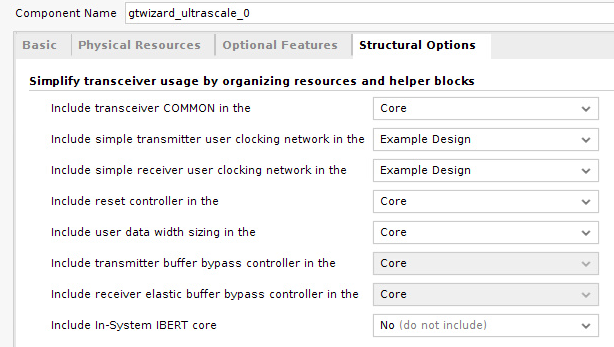
“COMMON” という文字が見えますが、これは GTHE3_COMMON のような FPGA のプリミティブを指しており、具体的には Quad PLL のことだと考えて差し支えありません。そのほかの部分も含め、Aurora のときと同様、単独で使う場合は “in the Core” にすればよいですし、複数のコアを使うときは併用して回路を共有することもできます。
Intel FPGA の場合
Intel FPGA では、この記事で扱う Cyclone 10 GX や Arria 10 GX は Quartus Prime Pro で設計することになりますが、Quartus Prime Pro にはトランシーバウィザードのようなコア生成ツールは提供されていません。代わりに、IP catalog から、以下のように PHY (PMA+PCS)、リセットコントローラ、PLL を個別に呼び出すことができます。

3つに分かれてはいますが、通信に関わる基本的な設定は PHY で行い、リセットコントローラは PHY と PLL にリセットやステータスの接続するだけです。PLL は入力 (参照クロック) の周波数と出力周波数を設定すれば、あとは信号の名前を見て上位モジュールで接続するだけで OK です。なお、PLL の出力周波数はラインレート (PHY の設定画面では「データレート」となっています) の半分です。
それでは、本命の PHY の設定を見ていきましょう。基本的には以下の図のようになり、Transceiver configuration rules というのが、Xilinx の Transceiver Wizard に相当します。Intel GX transceiver では、PCS が standard と enhanced の2つ用意されており、基本的には enhanced PCS がより高速なプロトコル向けで、64B/66B で使う場合には enhanced を選択します。
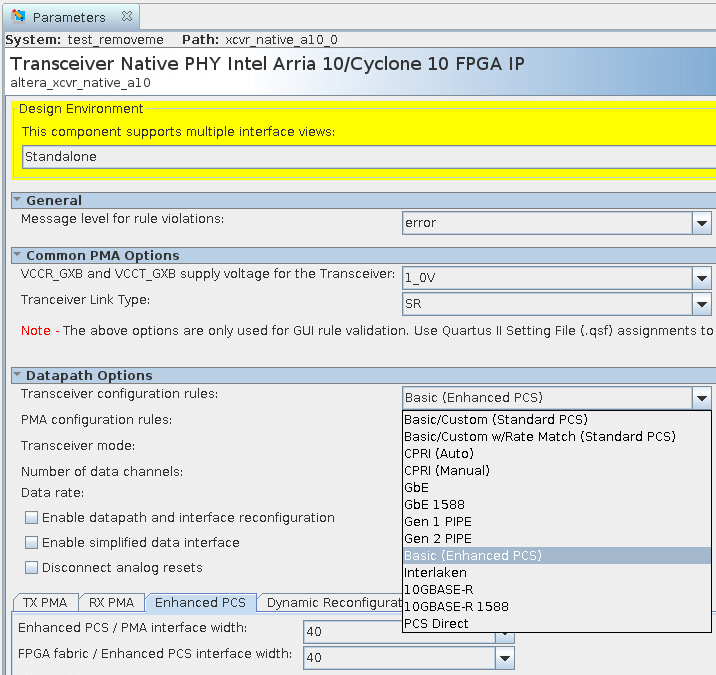
例として、Aurora 64B/66B と接続する場合の設定をあげていくと、概ね以下のようになります。
- TX PMA と RX PMA:
- tx(rx)_pma_div_clkout: div by 33 (PMA クロックはラインレートの半分なので、これでラインレートの 1/66)
- RX PMA にはクロックデータリカバリの参照クロック周波数を設定 (ボードに合わせます)
- Enhanced PCS
- Enhanced PCS/PMA interface width: 64bit
- FPGA fabric/PCS interface width: 66bit
- TX FIFO mode: basic (enable full/empty port)
- RX FIFO mode: basic (enable data_valid/full/empty/rd_en port)
- Gearbox: Enable RX data bitslip / Enable rx_bitslip port
ギアボックス、という文字は特に出てこないのですが、TX と RX の FIFO がそれに相当し、PCS-PMA 側のインタフェイスを 64bit、PCS-ユーザロジックのインタフェイスを 66bit にすることで非同期ギアボックスになります。ただ、何もしないと前述のビットスリップの制御信号の入力がありませんので、そこは注意が必要です。
送受信それぞれの PMA から33分周されたクロックを取り出すことができますので、これで FIFO のユーザロジック側を動かせば OK です。PMA 側のクロックを分周して作られていますので、この33分周のクロックで動かしていれば基本的に、FIFO があふれたり、空になってしまう心配はありません。
まとめ
今回はなんとなく、淡々と Xilinx / Intel のトランシーバのインタフェイスを紹介しただけになってしまった感じもありますが、これは次回以降への壮大な伏線… ということでお許しいただければ幸いです。今回の記事でご理解いただきたい一番のポイントは、両社ともトランシーバと FPGA 上のユーザロジックのインタフェイスは基本的には同じ、というところです。下の図は第 1 回の記事に掲載したものですが、どちらのトランシーバも次の図のような構造です。
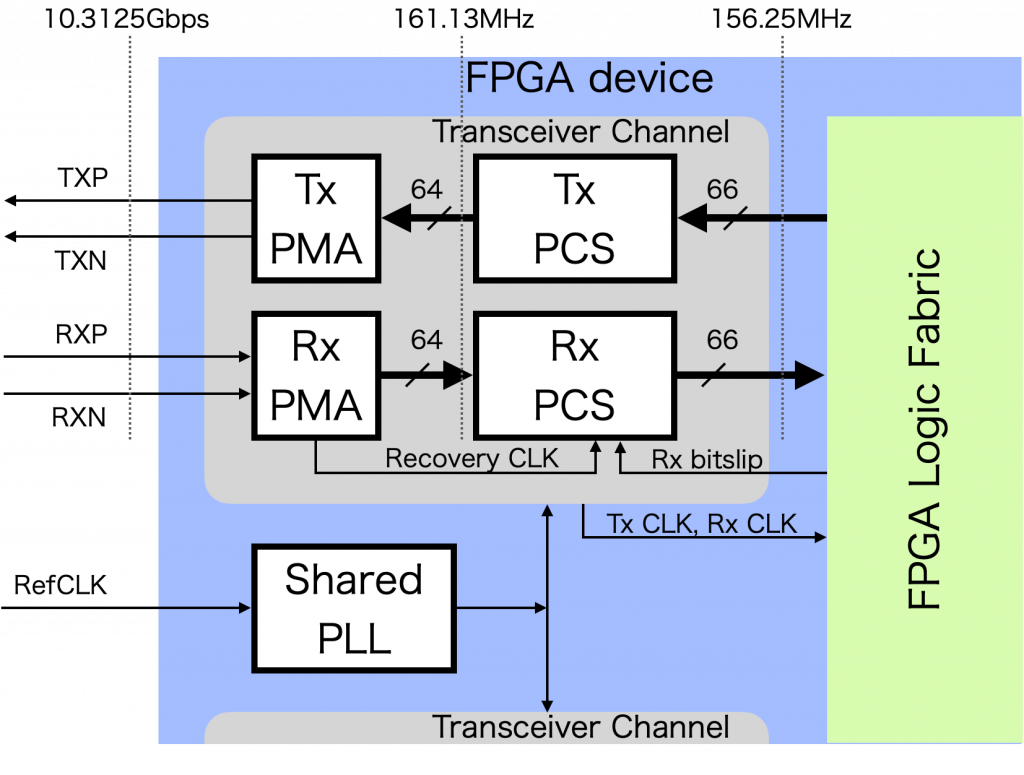
ポイントは、Xilinx / Intel を問わず、高速シリアルトランシーバのインタフェイスは、信号の名前をはじめとする細かい点を除けば、
- ユーザロジックとトランシーバのインタフェイスになるのはギアボックス
- ギアボックスの入出力に使うクロックは基本的に PMA から供給されるが、受信はクロックデータリカバリによるクロックが元になるので、送受信のクロックは別
- 非同期ギアボックスを使うと、たとえば 66bit など、PMA-PCS インタフェイスと整数比にならないビット幅のインタフェイスでアクセス可能
- ギアボックスのワードアライメントは、リンクの初期化時にビットスリップ操作によって確定
といったように、ほぼ共通なことです。つまり、いずれかの FPGA の高速シリアルトランシーバのインタフェイスを理解すれば、他のベンダや、他のデバイスファミリのトランシーバもそれほど手強い存在ではありませんし、ギアボックスの操作を理解してしまえばいろいろなプロトコルの実装につなげていくことが可能です。
今回は実際に回路を動かす話題はありませんでしたが、次回以降はいよいよ Xilinx 純正の Aurora 64B/66B インタフェイスと自前の回路を接続して動作させる話に進みます。
ドキュメントがほとんどない状態での手前味噌で大変恐縮ですが、私たちの研究グループで開発している Aurora 64B/66B 互換コアである Kyokko (極光: 日本語で「オーロラ」です) のソースコードは https://lut.eee.u-ryukyu.ac.jp/svn/kyokko/trunk/ から入手できます。次回以降の記事と合わせてご覧いただければと思います。
琉球大学 長名保範