前回からの続き
第3回では、非同期型の FIFO について2つの設計例を示しましたが、いずれも特定の条件下では有効に機能するが、万能ではない結果となってしまいました。今回はこれに対し改善を試みます。
アドレス交換法3
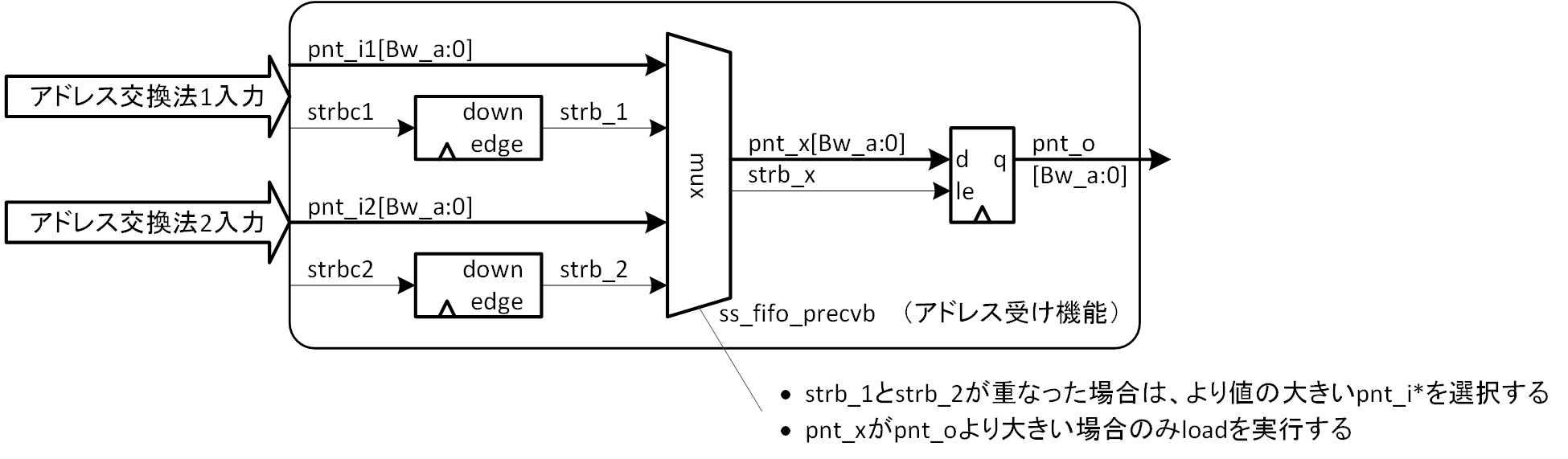
非常に安直な考え方ですが、前回説明のアドレス交換法1と2の両方の良いとこ取りという意味で、ハイブリッド型を考えてみます。アドレス交換法1と2とで異なるタイミングにて、一方のクロック系から他方のクロック系にアドレスを渡しあうわけですが、アドレス交換法1と2のタイミングは互いに阻害し合うものではありませんし、同時に起きうるものですし、もし2つのタイミングがぶつかるときには、都合の良いほうを選択すればよいだけです。そのアイデアを図4-1に示します。アドレスの受け機能部分をハイブリッド化する (アドレス交換法1と2の両方の機能を同居させる) だけです。図中では、ss_fifo_precvb としてモジュール化しています。
ss_fifo_precvb の記述例を、list4-1 (ss_fifo_precvb.v) に示します。
module ss_fifo_precvb (
pnt_o , // o pointer out
pnt_ia , // i pointer in a
strbca , // i strobe count in a
pnt_ib , // i pointer in b
strbcb , // i strobe count in b
clk , // i clock
rst ); // i sync reset ( h active )
parameter Bw_a = 10 ;
input [Bw_a:00] pnt_ia ; // i pointer in a
input strbca ; // i strobe count in a
input [Bw_a:00] pnt_ib ; // i pointer in b
input strbcb ; // i strobe count in b
input clk ; // i clock
input rst ; // i sync reset ( h active )
output [Bw_a:00] pnt_o ; // o pointer out
// wires & regs
reg [02:01] strbcar; // strobe count in a shift reg
reg [02:01] strbcbr; // strobe count in b shift reg
wire p_stba = ( strbcar==2'b10 ) ; // pointer strobe
wire p_stbb = ( strbcbr==2'b10 ) ; // pointer strobe
wire [Bw_a:00] p_dfao = pnt_ia - pnt_o ; // pnt_ia - pnt_o
wire [Bw_a:00] p_dfbo = pnt_ib - pnt_o ; // pnt_ib - pnt_o
wire [Bw_a:00] p_dfab = pnt_ia - pnt_ib ; // pnt_ia - pnt_ib
reg [Bw_a:00] pnt_o ; // o pointer out
// termc shift reg
always @( posedge clk ) begin
strbcar <= {strbcar[01],strbca} ;
strbcbr <= {strbcbr[01],strbcb} ;
end
// pnt_i strobe
always @( posedge clk ) begin
if ( rst ) pnt_o <= {(Bw_a+1){1'b0}} ;
else begin
casex ( {p_stba,p_stbb,p_dfab[Bw_a],p_dfao[Bw_a],p_dfbo[Bw_a]} )
5'b10_x0x : pnt_o <= pnt_ia ;
5'b01_xx0 : pnt_o <= pnt_ib ;
5'b11_00x : pnt_o <= pnt_ia ;
5'b11_1x0 : pnt_o <= pnt_ib ;
default : ;
endcase
end
end
endmodule
書き込みアドレスを読み出しクロックに系に渡す場合であれば、pnt_b1 は書き込みアドレス交換法1による値、pnt_b2 は書き込みアドレス交換法2による値になり、いずれかストローブが発生した方を選択してレジスタにロードします。
ここで1点注意点があります。アドレス交換法1でもアドレス交換法2でも、一方から他方のクロック系へアドレスを渡すタイミングは、遅れる傾向にあります。この遅れが小さいほど、wr_rdy、rd_rdy はより良い情報になります。ですので、以下の2条件を付けて情報の質を向上させることにします。
- 例1と例2によるアドレスストローブタイミングが重なった場合には、より大きな (より新しい) アドレスを選択する。
- アドレスをレジスタにロードする際、現状保持している値より大きな (新しい) アドレスのみをロードする。
2番目の条件は、strb_1 と strb_2 からロードされるそれぞれのアドレスは、値としてもタイミングとしても異なりますので、レジスタの値が逆行しないことを保証するために付けた条件です。逆行が発生すると、wr_rdy、rd_rdy が一時的に偽の値になるからです。逆行が発生しないことを証明できれば要らない条件ですが、値、タイミングあるいはアドレス桁の間引きなど条件が多いので、保険として加えています。
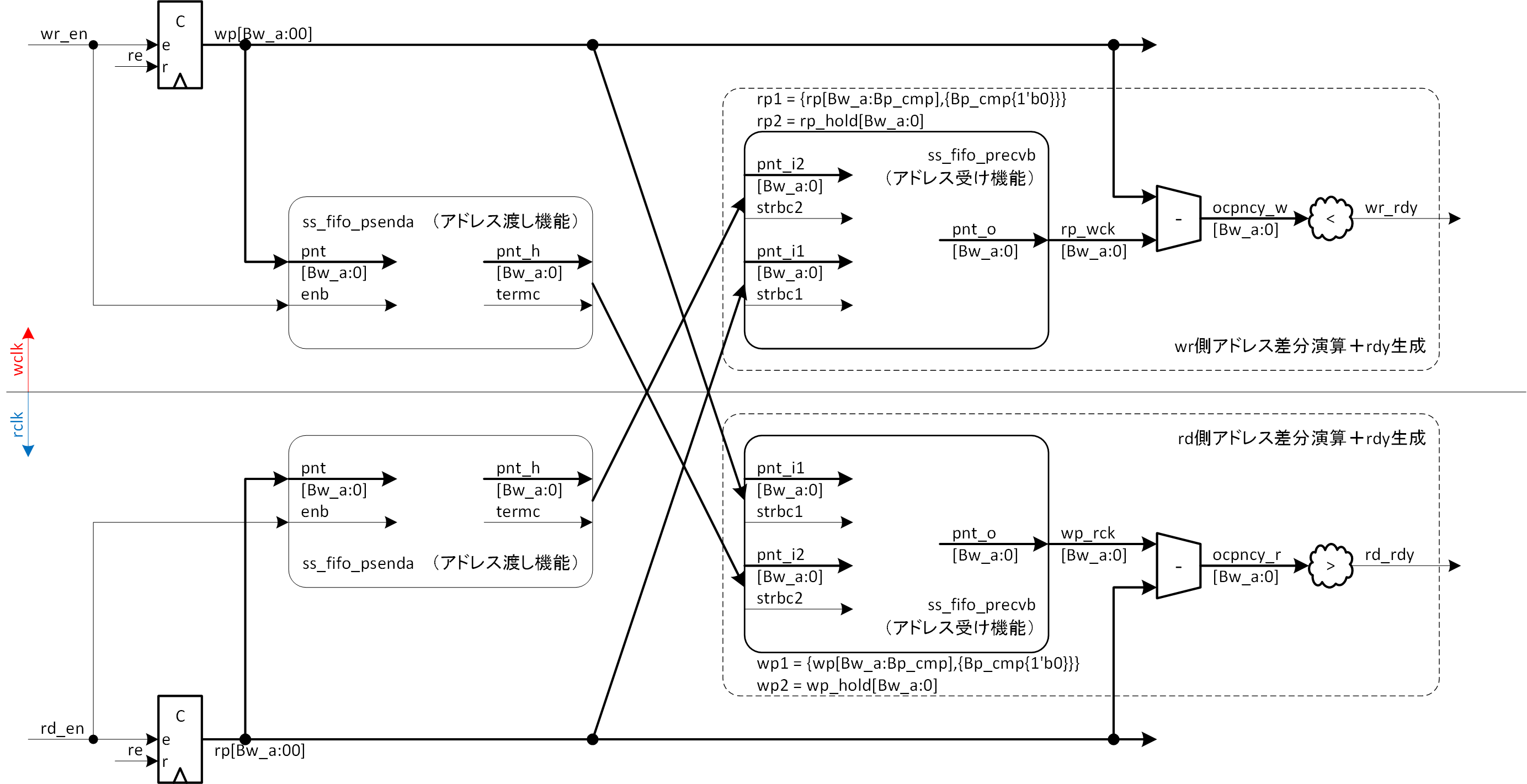
図4-2に、この例による FIFO の全体をブロック図で示します。BRAM 周辺の省略は前例と同じです。モジュール化されたものを対称に配置し、アドレス交換法1と2を合体しただけですので、特に説明の必要はないでしょう。FIFO 階層の記述例を、ss_fifo_asyncc.v として list4-2に示します。。
module ss_fifo_asyncc (
rd_rdy , // o fifo read ready
rd_en , // i read enable in
rd_do , // o read data out
rclk , // i read clock
wr_rdy , // o fifo write ready
wr_di , // i write data in
wr_en , // i write enable in
wclk , // i write clock
rst ); // i sync reset ( h active )
parameter Bw_d = 8 ;
parameter Bw_a = 10 ;
parameter Bp_cmp = 2 ; // compare bit point for ready
parameter Depth = 2**Bw_a ; // fifo depth
parameter Thrs_w = Depth/4*3 ; // for write ready
parameter Thrs_r = 1 ; // for read ready
output wr_rdy ; // o fifo write ready
input [Bw_d-1:00] wr_di ; // i write data in
input wr_en ; // i write enable in
input wclk ; // i write clock
input rst ; // i sync reset ( h active )
output rd_rdy ; // o fifo read ready
input rd_en ; // i read enable in
output [Bw_d-1:00] rd_do ; // o read data out
input rclk ; // i read clock
// wires & regs
reg [Bw_a:00] wp ; // wr pointer
reg [Bw_a:00] rp ; // rd pointer
wire [Bw_a:00] wp_ha = {wp[Bw_a:Bp_cmp],{Bp_cmp{1'b0}}} ; // wr pointer hold type a
wire [Bw_a:00] rp_ha = {rp[Bw_a:Bp_cmp],{Bp_cmp{1'b0}}} ; // rd pointer hold type a
wire wp_sta = wp[Bp_cmp-1] ; // wr pointer strobe source type a
wire rp_sta = rp[Bp_cmp-1] ; // rd pointer strobe source type a
wire [Bw_a:00] wp_hb ; // wr pointer hold type b
wire [Bw_a:00] rp_hb ; // rd pointer hold type b
wire wp_stb ; // wr pointer strobe source type b
wire rp_stb ; // rd pointer strobe source type b
wire [Bw_a:00] wp_rck ; // wr pointer rclk
wire [Bw_a:00] rp_wck ; // rd pointer wclk
wire [Bw_a:00] ocpncyw; // pointer difference for wr
wire [Bw_a:00] ocpncyr; // pointer difference for rd
reg [Bw_d-1:00] m_ary [0:Depth-1] ; // memory array
reg [Bw_d-1:00] rdo_r ;
assign rd_do = rdo_r ;
// write pointer
always @( posedge wclk ) begin
if ( rst ) wp <= {(Bw_a+1){1'b0}} ;
else if ( wr_en ) wp <= wp + 1'b1 ;
end
// write pointer send type b
ss_fifo_psenda
#(.Bw_a (Bw_a ))
usw (
.pnt_h (wp_hb ), // o pointer hold out
.termc (wp_stb ), // o term count out
.pnt (wp ), // i pointer in
.enb (wr_en ), // i enable in
.clk (wclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer receive
ss_fifo_precvb
#(.Bw_a (Bw_a ))
urw (
.pnt_o (rp_wck ), // o pointer out
.pnt_ia (rp_ha ), // i pointer in a
.strbca (rp_sta ), // i strobe count in a
.pnt_ib (rp_hb ), // i pointer in b
.strbcb (rp_stb ), // i strobe count in b
.clk (wclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer
always @( posedge rclk ) begin
if ( rst ) rp <= {(Bw_a+1){1'b0}} ;
else if ( rd_en ) rp <= rp + 1'b1 ;
end
// read pointer send type b
ss_fifo_psenda
#(.Bw_a (Bw_a ))
usr (
.pnt_h (rp_hb ), // o pointer hold out
.termc (rp_stb ), // o term count out
.pnt (rp ), // i pointer in
.enb (rd_en ), // i enable in
.clk (rclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// read pointer receive
ss_fifo_precvb
#(.Bw_a (Bw_a ))
urr (
.pnt_o (wp_rck ), // o pointer out
.pnt_ia (wp_ha ), // i pointer in a
.strbca (wp_sta ), // i strobe count in a
.pnt_ib (wp_hb ), // i pointer in b
.strbcb (wp_stb ), // i strobe count in b
.clk (rclk ), // i clock
.rst (rst )); // i aync reset ( h active )
// occupancy
assign ocpncyw = wp - rp_wck ;
assign ocpncyr = wp_rck - rp ;
assign wr_rdy = ~ocpncyw[Bw_a] & ( ocpncyw[Bw_a-1:00] <= Thrs_w ) ;
assign rd_rdy = ~ocpncyr[Bw_a] & ( ocpncyr[Bw_a-1:00] >= Thrs_r ) ;
// memory array wr
always @( posedge wclk ) begin
if ( wr_en ) m_ary [wp[Bw_a-1:00]] <= wr_di ;
end
// memory array rd
always @( posedge rclk ) begin
rdo_r <= m_ary [rp[Bw_a-1:00]] ;
end
endmodule
これまで長々と説明をしてきたのですが、FIFO 単体で機能を実現しようと次第に構造が複雑化してしまい、出来上がってみると個人的には美しくない回路になってしまったという印象です。趣味に走ったと言われても仕方ないでしょう。実際のアプリケーションにおいて、1つのシーケンス終わりに端数データが発生するのであれば、アドレス交換法1の設計をベースとした上で、シーケンサ側からシーケンスの終わりでアドレスのロードを指示する、というのが現実的か、と筆者個人としては考えています。例を図4-3に示します。
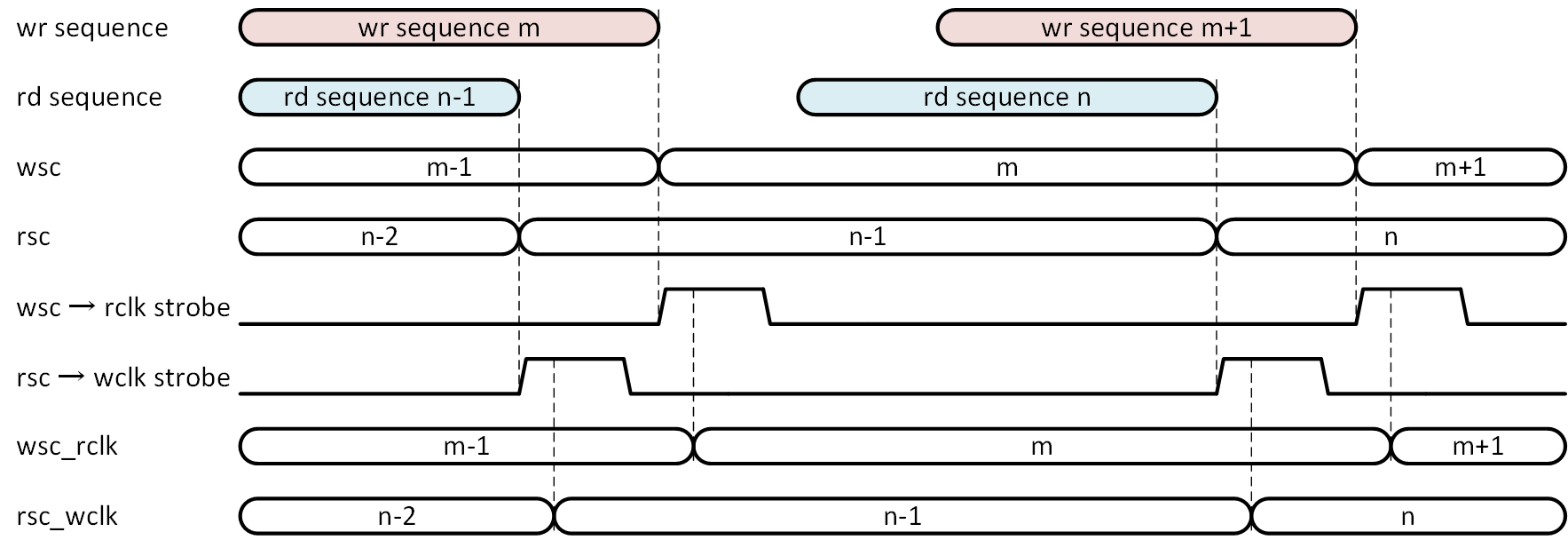
図4-3では、一定のデータワード数を1単位とするシーケンスによって書き込みと読み出しを行う場合を示しています。この場合、1シーケンスのデータワード数は、2のべきである必要はありません。書き込み側と読み出し側で交換するのは、FIFO 内のアドレスではなく、シーケンス数になります。書き込みシーケンスカウントを wsc、読み出しシーケンスカウントを rsc としています。それぞれのシーケンスが終了した時点で、シーケンス数の交換相手となるクロック系に対し十分な長さを持ったストローブ信号を生成し、これとシーケンスカウント数を相手方クロック系に渡します。ちょうど前回示した ss_fifo_precva によって、アドレスでなくシーケンスカウントを渡すイメージです。図中では、それぞれのシーケンス間には休止期間がありますが、シーケンスにある程度の長さがあってシーケンスカウントが相手方クロック系に渡るまで変化しないのであれば ( 静的期間が確保できるのであれば )、連続的なシーケンスでかまいません。制御がシーケンスカウントで行われるのであれば、FIFO の機能とは別に実現できますので、FIFO としては書き込み、読み出しを実現するだけで足ります。書き込み、読み出しのシーケンスが相手方クロック系に比べて十分長いものであれば、かなり安定した制御ができるはずです。制御の粒度を上げることで、クロック周期の差を問題とならない範囲に押し出したイメージです。FIFO だけで問題を解決しようとせず、周辺回路との協調で解決法が単純化し安定になるという一例だと思います。
ここまで設計例を3種類示しましたが、いずれも例であって最適なものとは限りませんので、ご注意をお願いします。さらに前回同様、設計例では BRAM36 内で解決しない要素を含んでいますので、CLB のロジックリソースが使用され、回路規模の増加、動作周波数の低下はありえます。この点もご注意をお願いします。
これまで示した設計例は、素晴らしいものとはいいがたいのですが、こうして機能の実現を目指し、試行錯誤を繰り返すことの楽しみが伝われば、筆者としてはありがたく思います。
加筆:2021年4月11日
より良い実現法を、文末に加筆しました。そちらも参照してください。
ビルトイン FIFO での非同期型対応
Xilinx が提供するビルトイン FIFO (FIFO36E2) では、非同期型の FIFO は機能として当然対応されています。UG573 では独立クロック FIFO と呼ばれています。CLOCK_DOMAINS 属性で INDEPENDENT を選択すれば実現できることになっています。
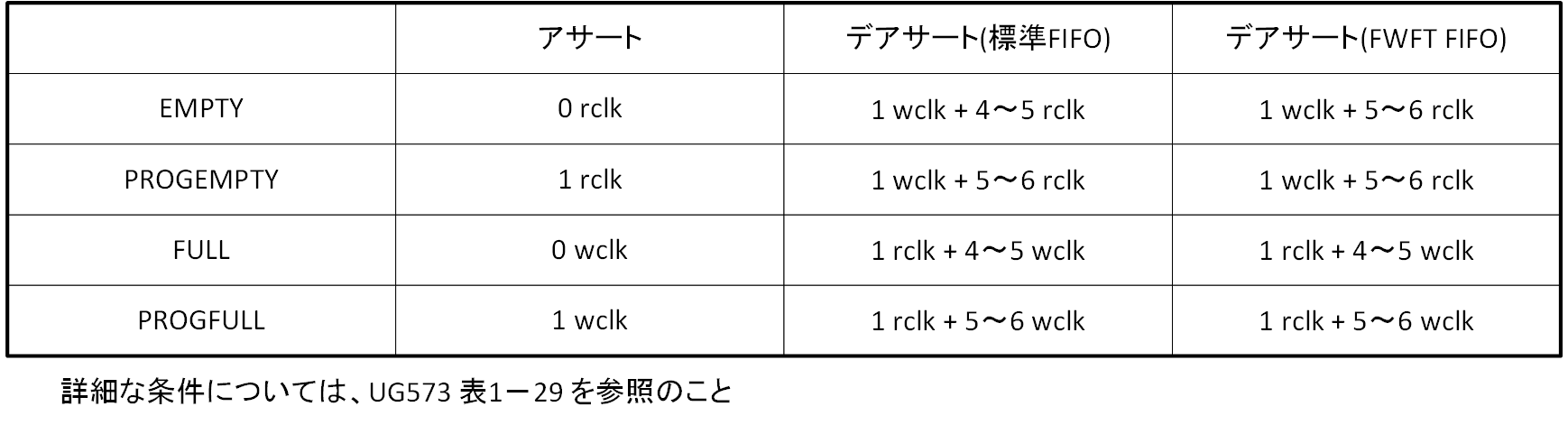
フラグのレイテンシ
同期型との大きな違いは、full/empty フラグのレイテンシです。表4-1にその値を UG573 から転記します。注目すべきは、アサートの反応がとても良いことで、制御を破綻させる可能性のあるアサ-トは、限りなく早くという Xilinx の親心といえるでしょう。デアサートについては、それなりというところでしょう。回路構成の詳細は不明ですが、筆者の考え方とは異なる細工がされているものと思われます。
ビルトイン FIFO における非同期動作については、UG573 から情報を得るようお願いします。
直列カスケード接続
FIFO36E2 を使用して深さの大きな FIFO を構成する際に、面白い方法が用意されていますので紹介しようと思います。深さの大きな FIFO が必要であれば、図4-4のように考えるのが常套ではないかと思います。少なくとも筆者はそう考えてしまうでしょう。考え方は単純で、BRAM そのものを拡張してメモリの深さを拡張し、それに合わせてアドレスカウンタも拡張する、という方法です。
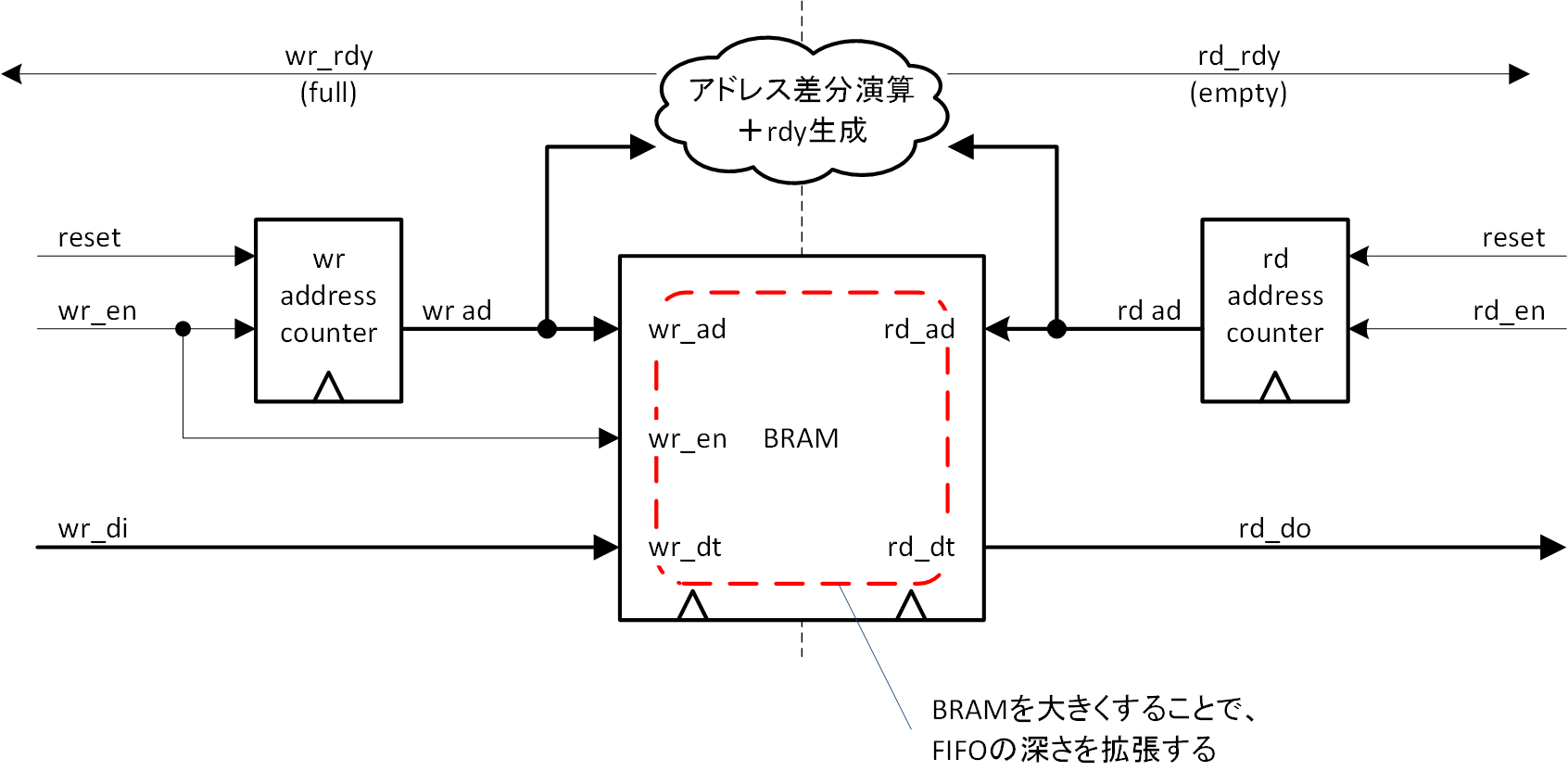
メモリ深さの拡張は、第1回に説明した RAMB36E2 のカスケード法が適用できます。この場合、FIFO36E2 に用意されているアドレスカウンタは自身の BRAM の面倒を見る大きさですので、拡張されたBRAMのアドレス桁としては不足することから、外部にリソースを頼らなければならなくなります。また、BRAM として拡張されたということは、BRAM が並列になっていますので、書き込み側から見た場合のファンアウトは大きくなっていることも意識する必要があります。
Xilinx は FIFO の深さの拡張法として「直列カスケード接続」という興味深く、よくできた方法を提供しています。図3-9に簡単なブロック図を示します。ポート名はこれまでの説明に準ずるため、筆者の命名によるものになっています。
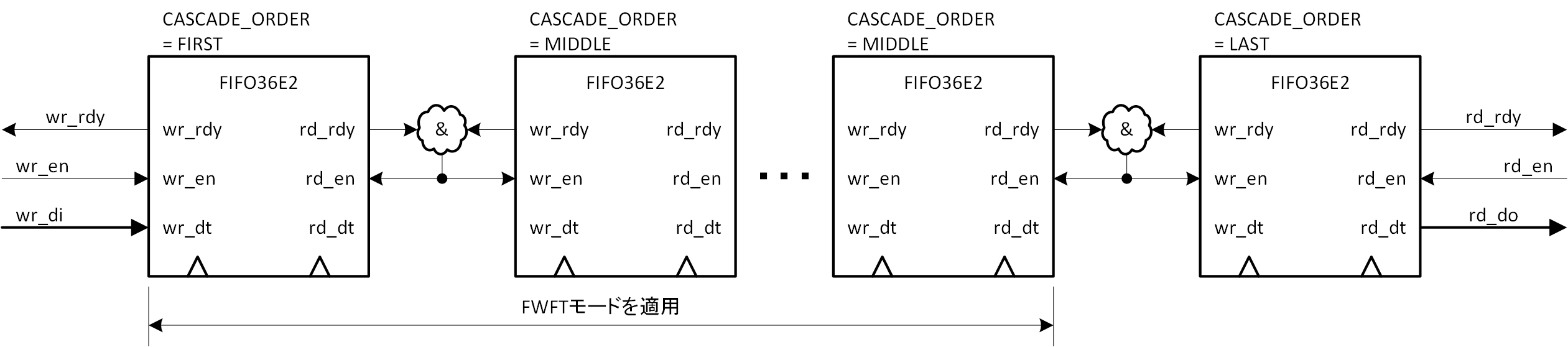
FIFO36E2 には ”CASCADE_ORDER” という属性があり、直列カスケード接続する場合、初段 FIFO は ”FIRST”、最終段は ”LAST”、それ以外の間に入る FIFO には ”MIDDLE” という属性が指定されます。
UG573 では使い方の注意点は示されていますが、仕組みの詳細は示されていませんので筆者の推定を交えながらの説明になってしまうことをお許しいただければ、FIFO36E2 を図4-9の通り直列に接続し、入力されたデータは後段の FIFO に空きがあるかぎり、次々に LAST FIFO に向かって順送りされる、という仕掛けになっているようです。この時に有効なのが、第2回で説明した FWFT (First-Word Fall-Through) モードで、FIRST ~ MIDDLE の FIFO に適用されます。最初に書き込まれたデータは FWFT によって FIRST FIFO 出力に筒抜けになり、これが繰り返されることで、少なくとも LAST FIFO 入力までは到達します。LAST FIFO は FTFW モードでも標準モードでもかまわないことになっています。LAST FIFO が FTFW モードであれば、最初の書き込みデータは一気にLAST FIFO 出力に現れますし、標準モードであればそのデータはメモリ経由で LAST FIFO 出力に現れます。これが最初の書き込みデータが LAST FIFO 出力に到達する仕組みです。
FIRST ~ MIDDLE の FIFO は自身が EMPTY である限り、FTFW モードでメモリを介さず後段に順送りされますが、!EMPTY (rd_rdy) となった (メモリ上に読むべきデータがある) 場合は、後段 FIFO の !FULL (wr_rdy) との & によって、自身の FIFO を読み出し後段 FIFO に書き込むというシェイクハンドを行います。ここは正に筆者の推定ですので、ご注意をお願いしたいと思います。多分、合っていると思うのですが 。以上が、最初の書き込み以降のデータが LAST FIFO 出力に到達する仕組みになります。
書き込みと読み出しのクロックが異なる場合に、各 FIFO36E2 に供給するクロックをどうするかですが、FIRST FIFO の書き込みには書き込み側クロックを、LAST FIFO の読み出しには読み出し側クロックを適用するのは、自明であると思います。それ以外のクロックには、書き込みクロックと読み出しクロックの高速な方を適用するようにUG573は指定しています。データを直列 FIFO 内を後段に向けて順送りする際、より高速に伝達されることを狙っているようです。
なお、これまでの説明は原理に着目したもので、FIFO が持っているレイテンシを考慮していませんので、注意してください。
こうして、FIRST FIFO に書き込まれたデータは次々に後ろ詰めされる形で蓄えられますので、カスケード FIFO の読み出し側としては、LAST FIFO の EMPTY を気にするだけで読み出しが可能になります。また、直列に接続するFIFOの数が、2のべき数である必要はないところもありがたいところです。 データの後ろ詰めという一見面倒そうなシステム機能が、単純な繰り返しによって自動的に得られることになります。構成要素がそれぞれ自発的に動くことで、大きなシステムが機能を果たすというのは、実に美しいと言えます。こうした発想は、何らかの形で別の設計に役立つ予感がします。すばらしいのは、FIFO 間のシェイクハンド機能も FIFO36E2 に含まれていて、FIFO 間の接続を行うだけで実現でき、余分なロジックリソースを必要とせず、FIFO 間の接続を除けば遅延量が保証されているということでしょう。本当によくできていますね。
おわりに
いくつかの設計例で、非同期型 FIFO の難しさと設計の楽しさを説明しました。また、ビルトイン FIFO の構成法から「盗むべき」発想も示唆してみました。第2回~第4回を通じて「 FIFO はたいして難しいものではない」ということが伝われば幸いです。考え方を応用し、面白いものを作ってみてください。
繰り返しになりますが、設計例はいずれも、どちらかといえば考え方を示したものですので、あらゆるケースでの動作を保証するものではありません。くれぐれもご注意ください。
エンジニア 鈴木昌治
参考文献
UG573 ( v1.11 ) 2020年8月18日「 UltraScale アーキテクチャ メモリリソース ユーザー ガイド」
加筆:2021年4月11日
加筆にあたり
長々と筆者の趣味のような設計事例にお付き合いいただき、ありがとうございます。 非同期 FIFO の設計事例として、非常に煩雑な設計を提示しましたが、より簡易な構成法を思いついてしまい、調べてみるとどうやらその方法が定番のようなのです。筆者の不勉強ゆえに、初心者の方々に非同期 FIFO の実現は面倒だと思われたままにしておくわけにもいかないので、恥を忍んで加筆させていただきます。
アドレスカウンタがバイナリカウンタの場合
以前の設計が複雑になった根底には、多ビットのデータ(メモリアドレス)を非同期クロック間で授受しないと、wr_rdy、rd_rdy を生成できないという点にあります。この非同期クロック間でのアドレスの授受は、必要機能を満たすために避けられないことですが、そのアドレスがバイナリ表現であったため、非同期クロック間で正しく伝達するには工夫が必要となったわけです。そして、その工夫が設計の複雑化そのものであったと言えます。
FIFO におけるアドレス ( wr も rd も ) は、順次インクリメントするカウンタによって生成され、連続した値です。このカウンタ値がバイナリ表現である場合には、複数のビットが同時に変化することになります。例えば8ビットカウンタの場合、8’hffから8’h00に変化する際には、8ビットすべてが同時に変化します。しかし同時にとはいっても、厳密に同時ではなく若干の時間差を伴いますので、その過渡期に非同期クロックで値を受け取ると、変化前の値を採るビットと変化後の値を採るビットが現れ、結果的に「値が化ける」という現象が発生します。ビット単位でみても、値の変化点にて非同期クロックで値を受け取った場合は、メタステーブルが発生しますので、最終的に L/H のどちらに落ち着くかはわかりません。非同期クロック間での多ビットデータ授受の問題はここにあり、2段ほどのレジスタを介して渡せばよいという、1ビットデータの手法が使えません。 簡単な例を図4a-1に、3ビットの例で示します。
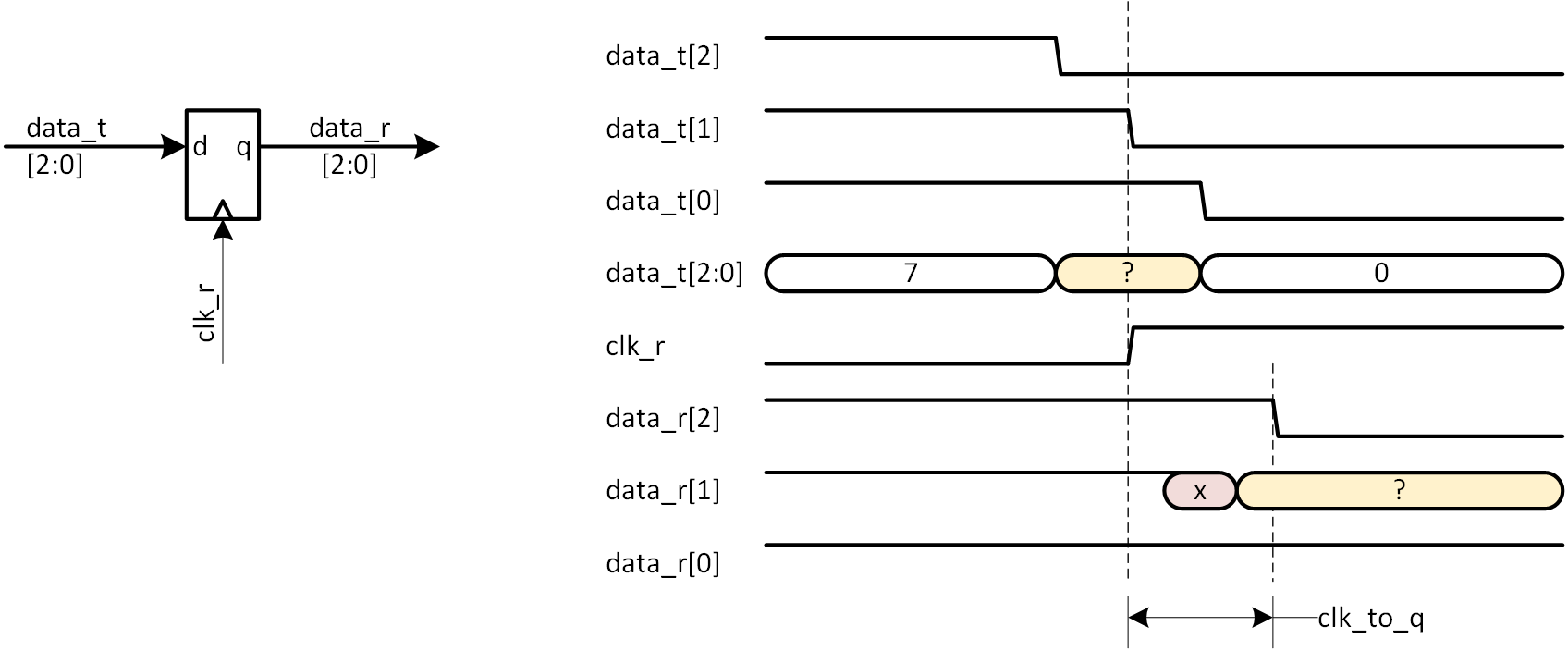
図4a-1 3ビットバイナリカウンタ値を非同期クロックドメインに渡す
左側には回路モデルを示し、右側にはタイミングチャートです。data_t[2:0] は送り側データ、data_r[2:0] は受け側データのレジスタ出力で、clk_r はデータ受け側クロックです。data_t[2:0] が3’h7から3’h0に遷移するケースですが、ビットごとに時間差を伴って受け側レジスタに到着しています。data_t[2] が最も早く、data_t[0] が最も遅く、data_t[1] は clk_r の立ち上がり近辺で到着します。data_t[2]、data_t[0] は clk_r に対し、setup/hold 時間を満たせたと仮定すれば、data_r[2]=1’b0、data_r[0]=1’b1 となると考えられますが、data_t[1] は setup/hold 時間を満たせたとは考えにくく、data_r[1] はメタステーブル状態に一定時間陥り ( 図中で x と示した期間 )、その後 L/Hいずれかの状態に落ち着きます。どちらに落ち着くかはわかりませんので?で示しました。従って、data_r[2:0] としては、3’h1か3’h3のいずれかに静定するのではないかと考えられますが、本当は3’h0になって欲しかったはずです。これが「値が化ける」という現象で、少なくとも1クロックサイクルは、レジスタ上にこの怪しいデータが保持され、有効データのようにふるまいます。
1ビットデータの受け渡し
1ビットデータを非同期クロック間で受け渡す際に、2段のフリップフロップを介して渡すことが定石としてあります。良い機会ですので、1ビットデータはなぜそれで良いのかを説明しておきましょう。
1ビットデータであれば、あるサイクルで値の過渡期に受け側クロックの立ち上がりエッジが来たとしても、次のクロックサイクルでの値が不確定ではありますが、さらに次のクロックサイクルでは正しい値が伝達されます。要するに、値の変化が1サイクル遅れるだけなのです。その様子を図4a-2に示します。

図4a-2 1ビットデータを非同期クロックドメインに渡す
やはり左側には回路モデルで、右側には、タイミングチャートを示します。データは1ビットデータで、clk に対し非同期に入力されるものとし、図中ではデータの変化点がクロックエッジに重なって1→0に遷移してしまった場合を示しています。クロックサイクル1では1段目のレジスタ出力data_1 にはメタステーブルが現れ ( x で示した部分 )、その後1に静定してしまいますが、クロックサイクル2では安定してdata_0=0を受け取り、data1=0となります。メタステーブル期間がクロックサイクルに対し十分短い前提であれば、data_1 の値はクロックエッジでは十分安定していますので、2段目のレジスタ data_2 は安定して値を取り込むことができます。本来期待したのは、クロックサイクル2で data_2=0 となることでしたが、それはクロックサイクル3に持ち越されています。1ビットデータであれば2段のレジスタで非同期クロックにデータ受け渡しができる、というのはこのような仕掛けによります。
グレイコードカウンタの採用
FIFO におけるメモリアドレスを非同期側に渡す話に戻ります。「1ビットの変化であればレジスタ2段を介して渡せる」という条件に着目して発想されるのが、グレイコードカウンタです。
グレイコードを採用してカウンタでインクリメントを続ける限りは、カウンタ値の変化するビットは必ず1ビットだけ、という特質を持っていますので、変化するビットだけに着目すれば「1ビットの変化」のケースと同じに考えられますし、変化しないビットは考える必要もありません。結果として、レジスタ2段を介して非同期クロックに渡しても、「値が化ける」現象は発生しないことになります。グレイコード自体は、バイナリと状態の表現が違うだけですから、不連続な値を扱う場合には多ビットの同時変化はあり得ますが、連続した値を採るカウンタであれば、「1ビットの変化」を手に入れることができます。 同じような1ビットしか変化しないカウンタとしては、ジョンソンカウンタがありますが、ジョンソンカウンタは N ビットを使用して 2N 状態しか表現できません。グレイコードカウンタは、バイナリカウンタと同じ2の N 乗の状態を持ちますので、バイナリカウンタと相性が良いと言えます。最終的な目標は、wr アドレスと rd アドレスの差分を採ってwr_rdy、rd_rdy を生成することにあり、差分演算はバイナリ表現で行われますので、相互に変換できることが望ましく、その意味でもグレイコードカウンタは有用と言えます。
グレイコードカウンタについて
グレイコードカウンタそのものについては、インクリメントの度に1ビットしか変化しない、という性質を利用しているだけなので、ここでは解説を控えます。グレイコードカウンタのインクリメントの様子を図4a-3に示します。参考までに、バイナリカウンタも合わせて示します。c_bin がバイナリ、c_gry がグレイコードです。

図4a-3 グレイコードカウンタの動作
グレイコードカウンタの構成法についてはいろいろあるようですが、ここではバイナリカウンタを併用する構成とします。先に述べた通り、wr アドレスと rd アドレスの差分を採る必要があるので、バイナリ表現でのアドレスも必要となるからです。図4a-4にその構成を示します。バイナリカウンタをインクリメンタとレジスタに分け (図中の点線で囲った部分)、インクリメンタ出力 (バイナリ) をグレイコードに変換してレジスタに入力することで、バイナリカウンタとグレイコードカウンタの位相を合わせています。
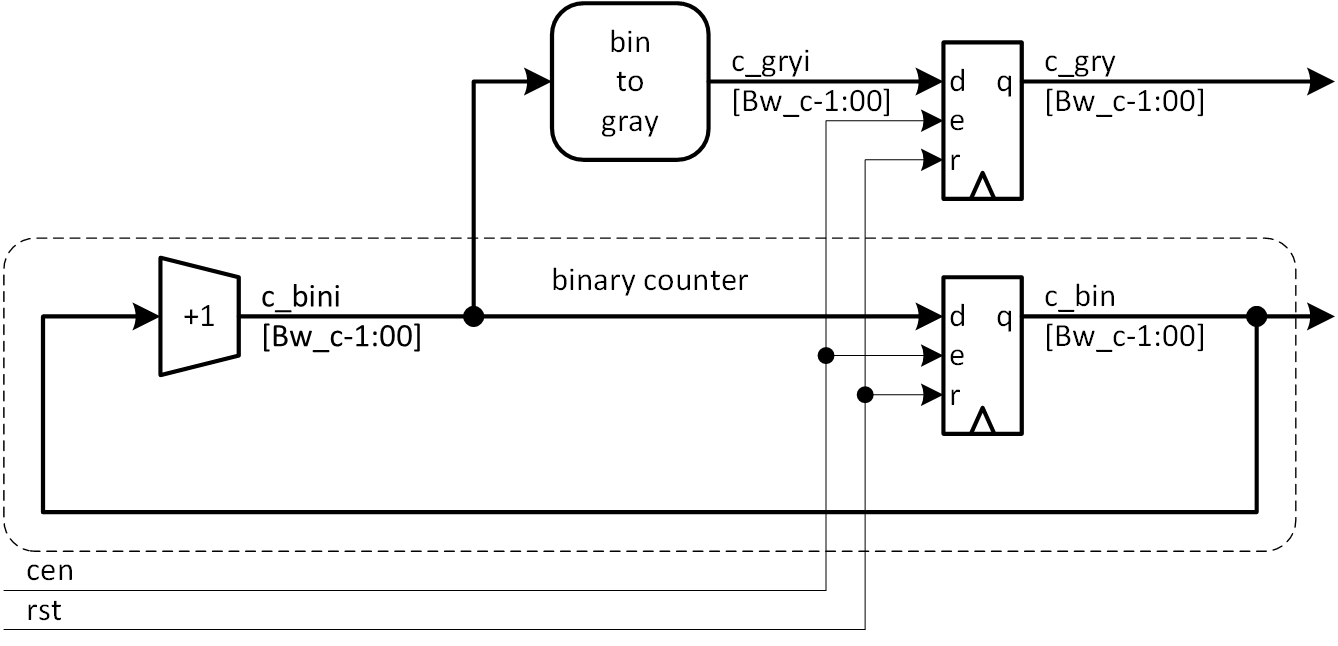
図4a-4 バイナリ/グレイコードカウンタ構成例
バイナリ→グレイコードの変換は単純で、図4a-5左に示す通りです。5ビットの例です。ビット幅に依存することなく、一定のロジックの深さになります。後程必要になるので、グレイコード→バイナリの変換も図4a-5右に示します。こちらはビット幅に比例してロジックが深くなります。
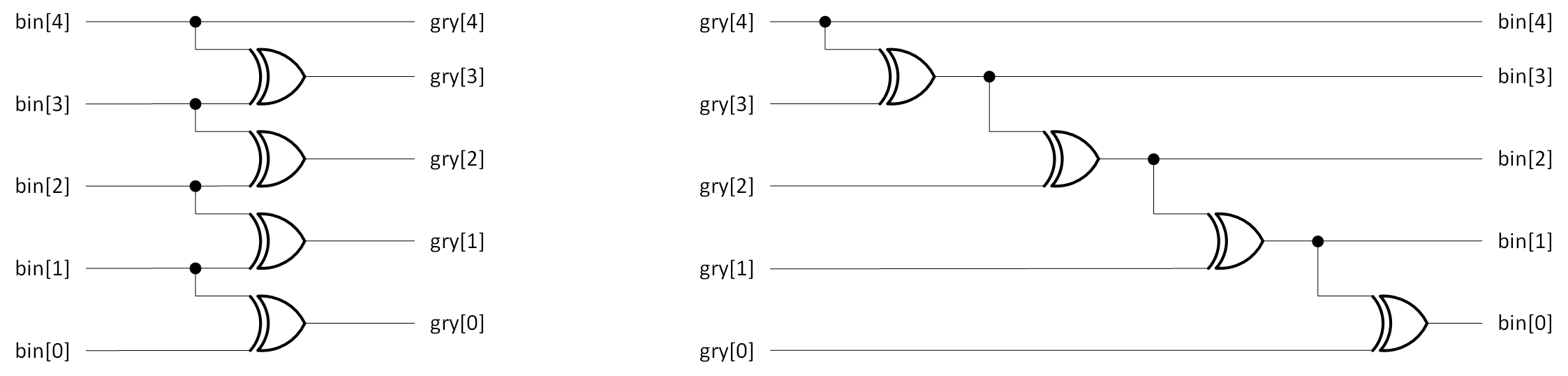
図4a-5 バイナリ⇔グレイコード変換
FIFO の構成
アドレスの非同期クロック系への授受にグレイコードカウンタを用いて、FIFO を構成します。図4a-6にブロック図を示します。既に、バイナリ→グレイコード変換、グレイコード→バイナリ変換、グレイコードカウンタについては構成を示していますので、ブロック図は簡素なものになります。FIFO そのものの構成については、既に長々と説明をしていますので、もう説明の必要はないものと思います。ポイントはアドレスの非同期クロック間の交換においてのみ、グレイコードを使用する点で、それ以外は基本的な FIFO の構成であるということです。
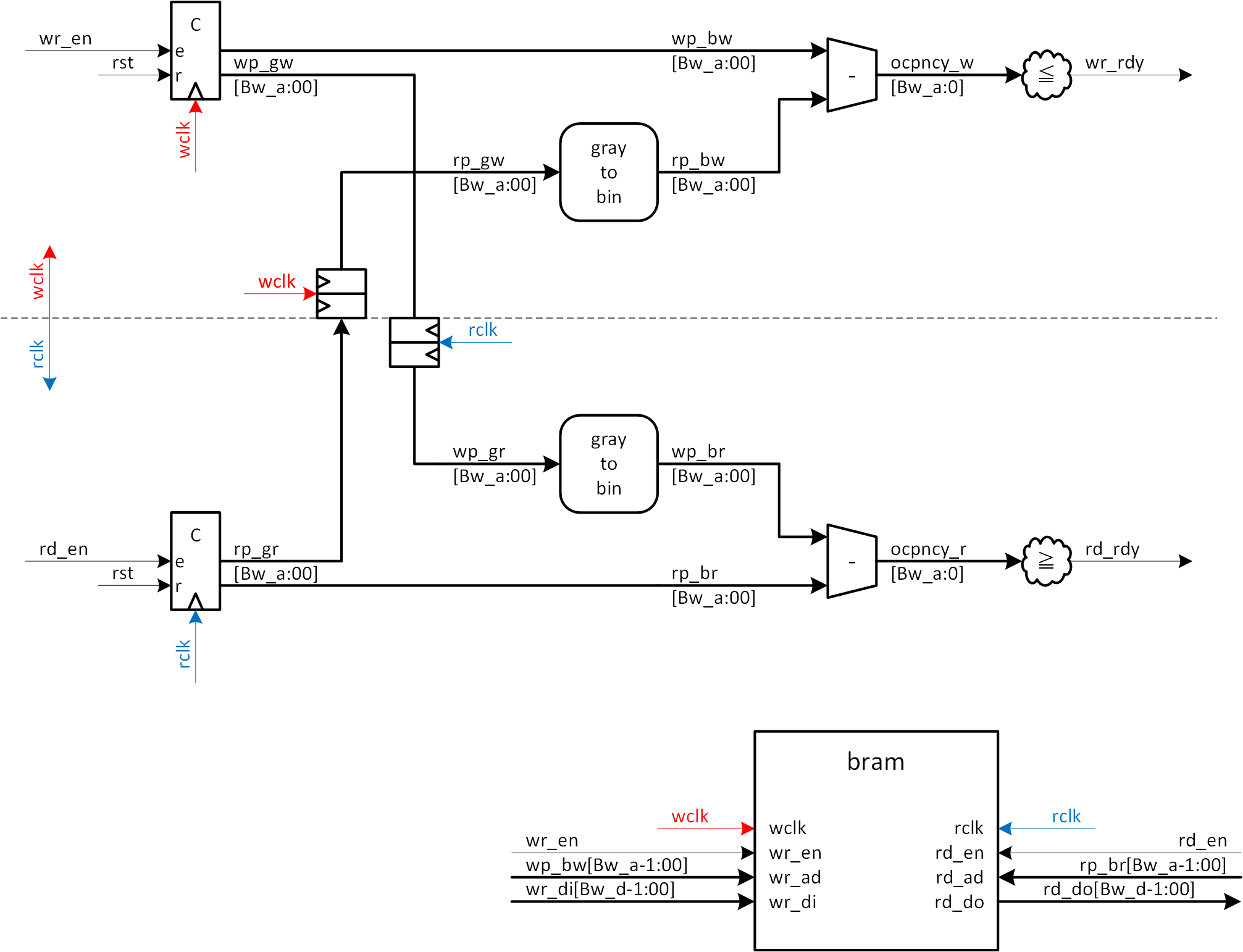
図4a-6 グレイコードカウンタを併用した非同期 FIFO 構成例
随分と簡素なものになりました。簡素になった分、説明もかなり短くなっています。うまく作るというのは、こういうことなんですね。かなり単純化されましたので、RTL ソースは割愛します。皆さんで書いてみてはいかがでしょうか。