
こんにちは、フィックスターズの丸岡です。
フィックスターズでは、多種多様なハードウェア向けのソフトウェアの高速化や、その知見を活かしたアルゴリズムの提案、ソフトウェアシステムの開発などに貢献させていただいています。近年では機械学習 (Machine Learning, ML) 分野の急速な発達や DX (Digital Transformation) の推進によって、ML を含んだアプリケーション開発の需要が増えています。ML の中でも特にディープニューラルネットワーク (Deep Neural Network, DNN) の推論処理は計算量が多いため、性能に関する要望を受けることが多いです。
DNN の推論処理の性能を向上させる手法の1つに、「DNN コンパイラを利用する手法」があります。DNN コンパイラは、学習済みの DNN モデルに対してモデル軽量化、グラフ最適化、プログラム最適化などといった様々な変換処理を適用し、入力された DNN モデルの推論処理を対象のハードウェア上で高効率に処理可能な DNN モデルや実行ファイルを生成するコンパイラです。FPGA 上で DNN の推論処理を高速に実行したい場合も、この DNN コンパイラを利用した手法が有用となっています。
本連載では、OSS で開発されている DNN コンパイラ「TVM」を取り上げて、ディープラーニングの推論処理を FPGA 上で高速に実行する技術について紹介します。連載の内容は下記の通りになります。
- ディープラーニングの概要と、FPGA 上での DNN 推論処理の高速化するための手法やツールの紹介
- DNN コンパイラ「TVM」を用いた、DNN 推論処理の FPGA デバイスに対するコンパイル手順の紹介
- 2の手法でコンパイルした DNN 推論処理の FPGA デバイス上での性能評価
背景
ディープラーニングの概要と FPGA を利用した高速化の需要
ディープラーニングとは、多層に積み重ねたニューラルネットワークを学習、推論させることによって実現される計算モデルのことです。
現在、ディープラーニングは画像や音声の認識、自然言語処理、異常検知などといった、現実世界の様々なタスクに用いられています。
一方で、ディープラーニングの推論処理の計算量は膨大であるため、処理時間が長くという課題があります。そのため、計算時間を短縮したい、消費電力の制約が厳しいなどの要求がある場合には、FPGA を利用した推論処理の高速化が有効なユースケースが存在します。
ディープラーニングの概要や FPGA で高速化することのメリットについては過去の ACRi ブログで紹介していますので、詳しく知りたい方はそちらの記事をご覧ください。

DNN コンパイラによる DNN モデルの最適化
DNN コンパイラは、主に学習済みの DNN モデルを入力として、推論処理を対象ハードウェア上で高効率に実行するためのモデル変換やプログラム変換を適用するソフトウェアの総称です。
DNN コンパイラで適用される代表的な変換処理をいくつか紹介します。
DNN モデルの軽量化
下記に代表されるような、学習済みの DNN モデルを軽量化する手法が存在します。
- 量子化 (Quantization) : アクティベーションや重みの値や内部の計算を、より低い精度の浮動小数や整数に変換する手法。
- 枝刈り (Pruning) : 認識に影響度が少ない重みを削除する手法。
DNN コンパイラの一部は、これらのモデル軽量化を自動で適用する機能を備えています。
これらのモデル軽量化を適用することによって、計算量やメモリ使用量が削減され、推論処理の高速化が実現できる場合があります。
ただし、これらの手法の適用には認識精度の劣化を伴う場合があるため、注意が必要です。
推論処理のプログラム最適化
推論の認識結果を保ったまま、推論処理内の演算処理の簡略化やプログラム最適化を適用します。
DNN コンパイラで適用されることが多いコンパイラ最適化手法として、下記のものが挙げられます。
- 学習パラメータなど、推論フェーズに移行するに伴って定数化するデータに対する定数畳み込み (Constant Folding)
- 複数の DNN の演算の融合 (Operator Fusion)
- アクティベーションや学習パラメータに対するメモリレイアウトの変換
- ループ最適化やキャッシュブロッキングなどの古典的なコンパイラ最適化
- 対象ハードウェア上で利用可能な専用高速命令への変換
これらの手法を適用することによって、推論処理における計算量や必要メモリ量を削減したり、対象ハードウェア上における計算効率を向上させることが出来ます。
DNN コンパイラの中には、DNN で利用される演算やテンソル型に対応した中間表現を備えているものも多くあり、この中間表現から抽出出来る高抽象度な解析情報を利用することによって、従来の最適化コンパイラと比較してより高度な最適化を実現しています。
Xilinx 製 FPGA における、ディープラーニングの開発環境
Vitis AI
Vitis AI は、Xilinx 社が提供している、Xilinx 製 FPGA 上で DNN の推論処理を実現するための開発プラットフォームです。Vitis AI には、下記のツールが含まれています。
- AI Model Zoo : 学習済みのモデルと、それらを Xilinx 製 FPGA デバイス上で実行可能になるようにコンパイルしたモデルファイルの Model Zoo。
- AI Optimizer : 学習済みモデルに対してチャネル単位の枝刈りを適用するツール。
- AI Quantizer : 学習済みのDNNモデルに対して量子化を適用するツール。推論処理を後述の DPU IP 上で実行するためには、本ツールによってアクティベーションと重みを8ビット整数に量子化することが必須となっています。
- AI Compiler : 学習済みの DNN モデルを、Xilinx 製 FPGA デバイス上で実行可能なファイルに変換するコンパイラ。
- AI Library : Vitis AI コンパイラによってコンパイルされたモデルを実行出来る API や、画像の前後処理のライブラリ。これらを利用することで FPGA デバイス上でディープラーニングを利用した認識アプリケーションが簡単に開発出来ます。
これらのツールを利用することによって、既に提供されている学習済み&コンパイル済みモデルや、開発者が自分で学習したモデルを、FPGA 上で高速処理させることが可能となっています。DNN の推論処理を Zynq や Alveo 上で実行したい場合には、まずはこの Vitis AI を利用して実装するのが手軽でオススメです。

(引用: Vitis AI)
Xilinx DPU IP
Xilinx DPU (Deep-Learning Processing Unit) は、 Convolutional Neural Network (CNN) の推論処理の実行に最適化された、Programmable Logic (PL) 上に実装可能な IP です。DPU には、畳み込み演算を始めとした、CNN の推論処理で頻繁に利用される演算を高速に実行可能な命令が実装されているため、CNN の推論処理を高速に実行することが可能となります。
Vitis AI コンパイラで DNN モデルをコンパイルすると、対象の DNN モデルの推論処理を実行する DPU の命令に変換されます。DPU で対応していない演算は CPU 上で実行されるように変換されます。
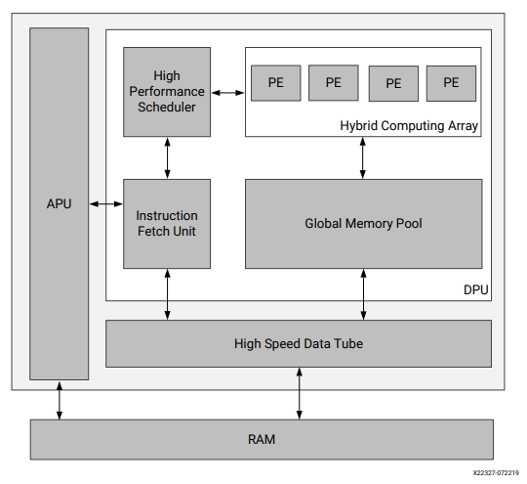
(引用: PG338 Zynq DPU v3.3)
TVM
TVM は OSS で開発されている、DNN のコンパイラスタックです。TVM は各ベンダーの CPU や GPU 向けだけでなく、Apple や Android のモバイルデバイス、WebAssembly などといった、様々なハードウェアやプラットフォーム向けの最適化やコンパイル済みコードの生成が可能となっています。
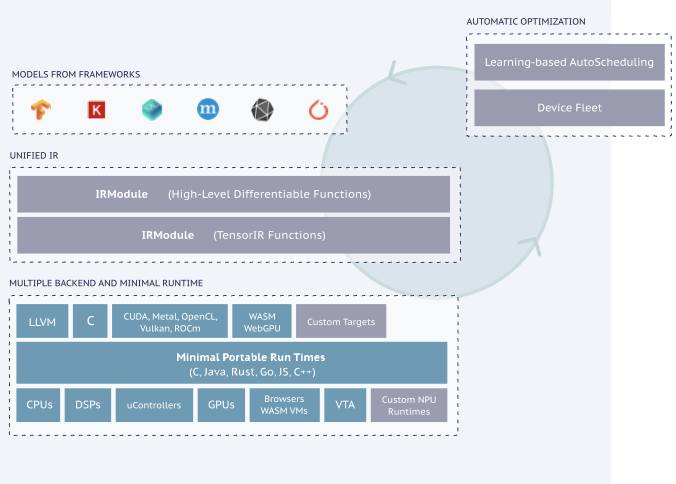
TVM には Bring Your Own Codegen (BYOC) という機能が搭載されています。BYOC とは、TVM に入力された DNN モデルの計算グラフのうちの一部を切り出して、以降のコンパイル処理をサードパーティのコンパイラに移譲出来る機能です。執筆時点での TVM では、下記のサードパーティーコンパイラを利用した BYOC 機能に対応しており、その中に Vitis AI を利用したコード生成フローが存在しています。従って、TVM でもこのコード生成フローを利用することで、DPU IP を利用した推論処理の高速化を適用することが可能となります。
- ARM Compute Libary
- NVIDIA TensorRT
- Xilinx Vitis AI
- Apple BNNS
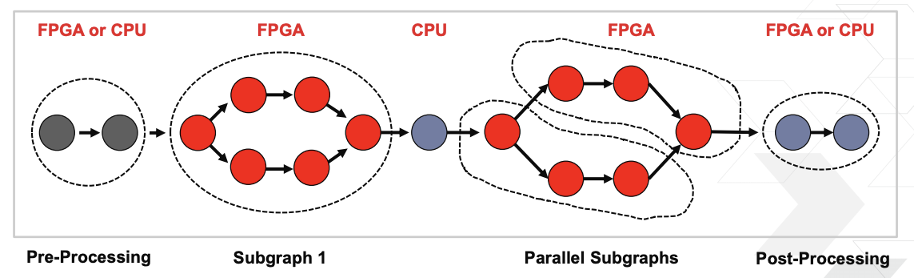
(引用: TVM @ Xilinx, TVM Conference 2019)
Vitis AI を利用する場合と比較して、TVM を利用することによって得られるメリットは下記のようになっています。
- TVM が対応している多種多様なディープラーニングフレームワークのモデルをコンパイル出来る。
- CPU や GPU などの他デバイスと同じランタイムコードで、FPGA 向けの DNN 推論処理を実行出来る。
- DPU 上で実行できない処理部分については、TVM によって高度に高速化された CPU 用コードを実行することが出来る。
- Remote Procedure Call (RPC) を利用して、エッジデバイス上での動作確認や性能評価をネットワーク経由で実行することが出来る。
本連載では、この TVM を利用して、FPGA やそれ以外のエッジデバイス向けの推論処理の高速化と評価を行っていきます。
まとめ
本記事では、「ディープラーニングと DNN コンパイラの概要」、「Xilinx 製 FPGA における、ディープラーニングの開発環境」、そして「TVM」について紹介しました。
次回の記事では、TVM を利用した Ultra96 向けのコンパイルと動作確認、性能評価を行っていきます。
株式会社フィックスターズ ディレクター 丸岡 晃