
本連載も第3回目となり折り返し地点に差し掛かってきました。前回の記事では、ART 法のハードウェアアクセラレータは、複数の FPGA に跨がった巨大な演算クラスタを構築できるような設計コンセプトで実装されていることを説明しました。今回の記事では、計算科学研究センター (以下、当センター) にて研究開発された、複数の FPGA を利用した並列計算の実現の根幹を成す FPGA 間通信技術について紹介していきます。この研究成果は論文として出版されており、この通信技術について詳細に知りたい方は、そちらもお読み頂けると理解が一層深まると思います。
CIRCUS:OpenCL から制御可能な FPGA 間通信フレームワーク
設計コンセプト:通信と演算の融合
CIRCUS とは、OpenCL 高位合成処理系から FPGA 間通信を可能にするフレームワークであり、Communication Integrated Reconfigurable CompUting System のアクロニムです。CIRCUS では、パイプライン通信を前提に通信システムを構築しており、HPC アプリケーションを複数ノードに跨がって並列化する際に利用される通信ライブラリである MPI とはアプローチが全く異なるのが特徴です。パイプラインは FPGA における基本的な処理構造であり、OpenCL コンパイラは、コード中にあるループ (for ループや while ループなど) からパイプラインを構築します。したがって、演算パイプラインと 通信パイプラインを接続し、すべてをパイプラインにして利用することが最適であると当センターでは判断しています。
パイプライン通信を導入する利点は、通信と演算をクロックサイクルレベルの粒度でオーバーラップできることであり、これは GPU といった他のアクセラレータには ない FPGA ならではの強みです。例えば、MPI を利用して通信と演算のオーバーラップさせる場合は、演算を止めないために、MPI Isend や MPI Irecv といった non-blocking な通信 API を使用しなければならなかったり、通信に用いるデータの寿命や通信とデータの依存関係を考慮にいれてプログラムを記述しなければならなかったりと、プログラマがアプリケーションの中で通信と演算のオーバーラップさせるコードを明示的に記述する必要があります。
それに比べて、FPGA では通信と一体となった演算パイプラインを得ることは比較的容易と言えます。下の OpenCL カーネルコードを Intel FPGA SDK for OpenCL のオフラインコンパイラでコンパイルした際に構築されるパイプライン構造を見てみましょう。
#pragma OPENCL EXTENSION cl_intel_channels : enable
channel int ch;
__kernel void send(__global int* restrict data, int n) {
for (int i = 0; i < n; i++) {
int v = data[i];
write_channel_intel(ch, v);
}
}
__kernel void recv(__global int* restrict data, int n) {
for (int i = 0; i < n; i++) {
int v = read_channel_intel(ch);
v = v + 1;
data[i] = v;
}
}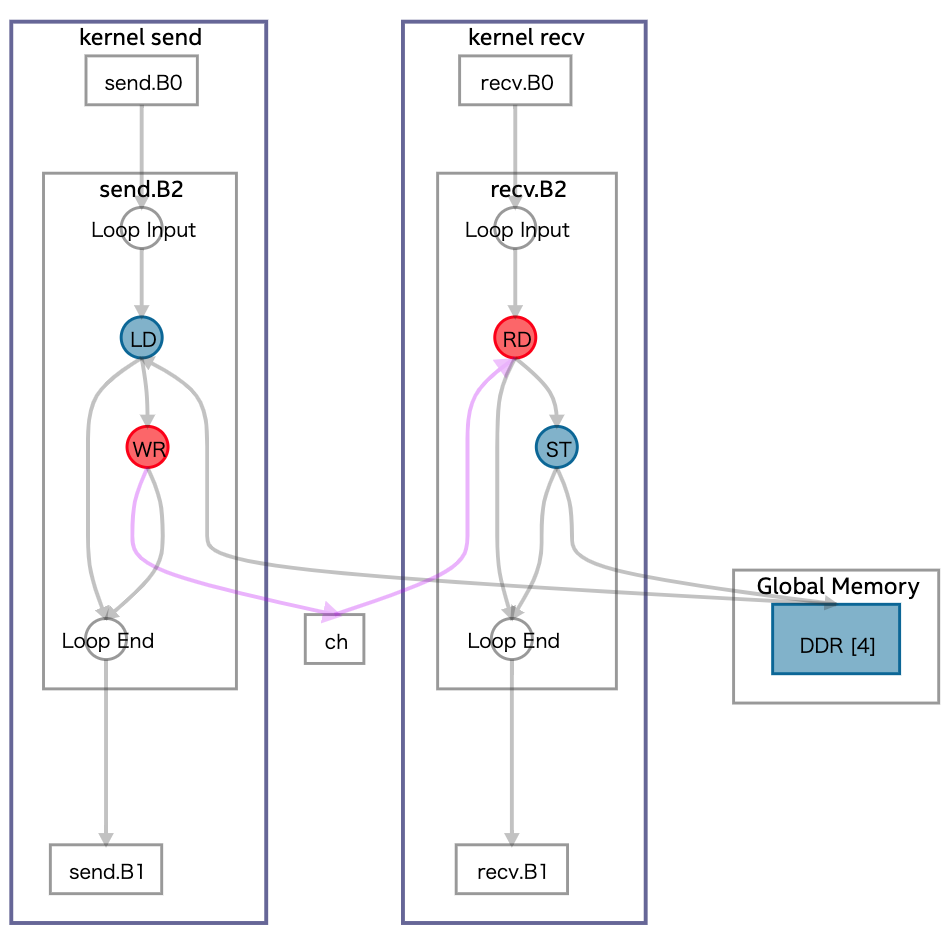
上の図はオフラインコンパイラが生成するコンパイルレポートに含まれる Graph Viewer を用いて生成したものです。このコードには、メモリから値を読み出す send カーネルと、その値に 1 を加えメモリに書き込む recv カーネルがあり、その 2 つのカーネルが Channel で接続されています (Channel については前回の記事を参照)。ここで LD、ST、RD、WR はそれぞれメモリからの読み出し、メモリへの書き込み、Channel からの読み出し、Channel への書き込みを表します。それぞれのループは異なるカーネルとして実装されているため非同期に動作しますが、Channel によるデータの依存関係があるため、全体として大きな 1 つのパイプラインを構築できます。
この特徴を下の図に示すように複数の FPGA に跨がって実現するのが CIRCUS のコンセプトです。CIRCUS では、図に示すようなパイプライン通信を実現する機構を OpenCL 環境に組み込むことによって、異なる FPGA 間での Channel 通信を可能にし、通信と演算が融合したパイプラインが構築されます。
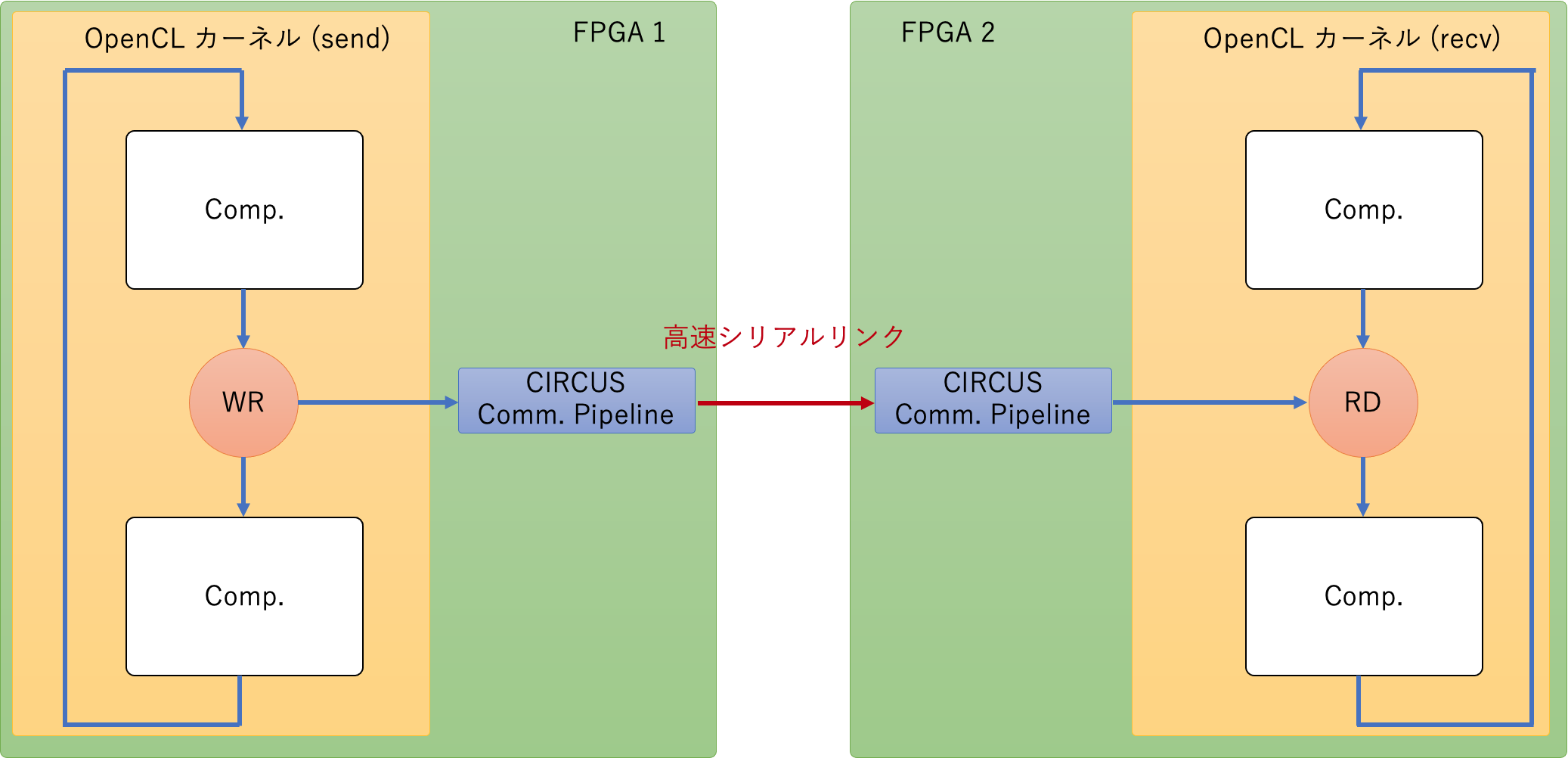
パイプライン通信を実現する機構
概要
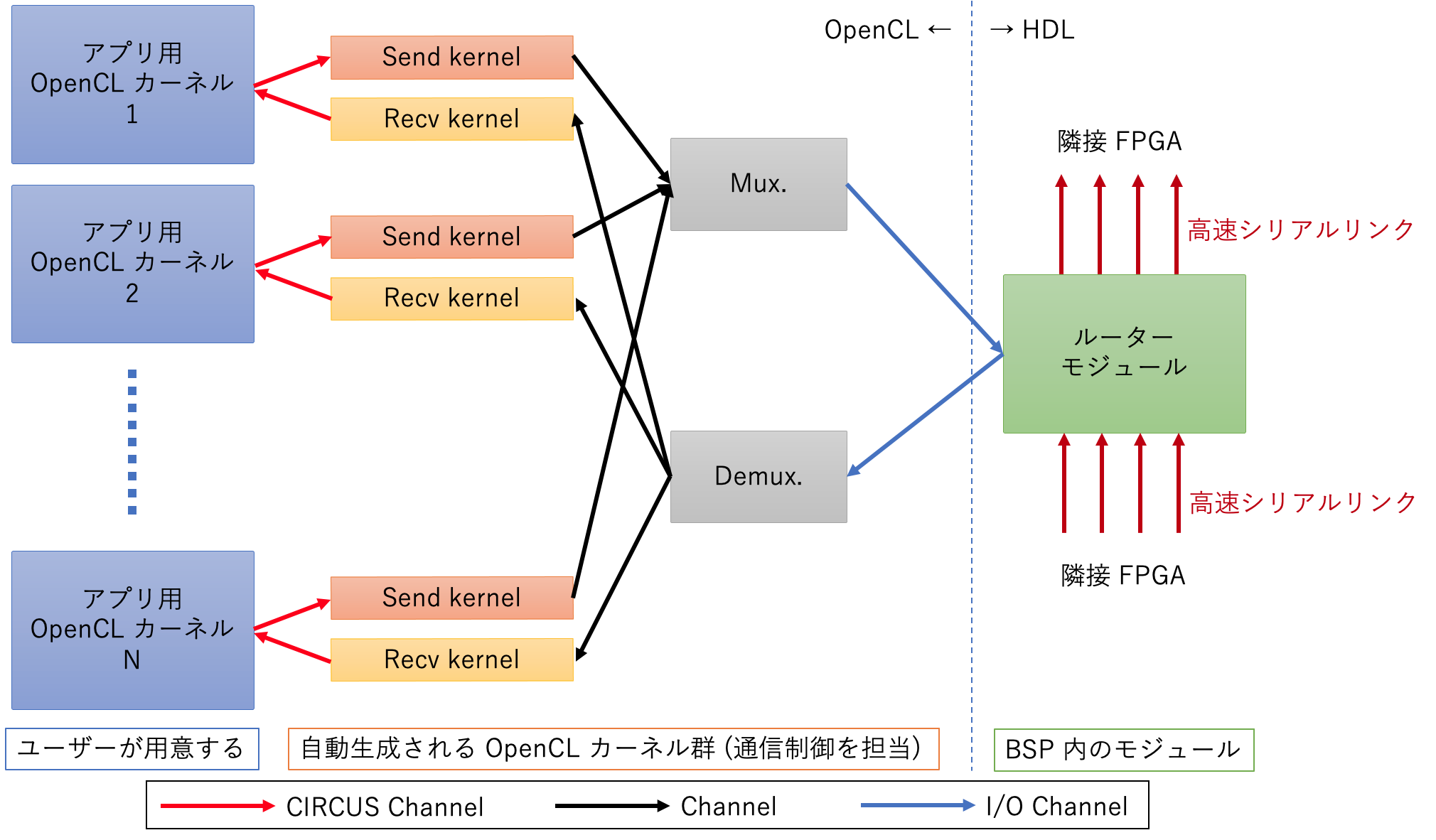
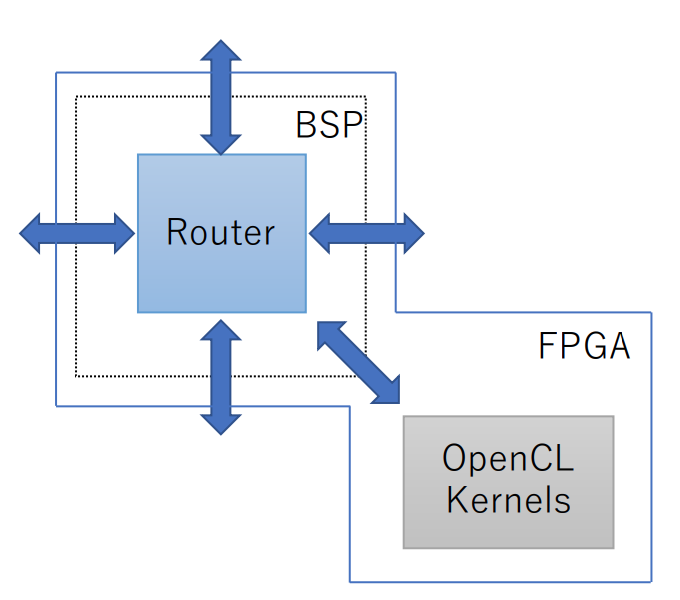
図に示すように、CIRCUS の通信機構は、通信制御を担当する OpenCL カーネルと Verilog HDL で実装されたルーターモジュールから構成され、それらのコンポーネント間は Channel もしくは I/O Channel で接続されます (I/O Channel は OpenCL カーネルから HDL で実装されたモジュールにアクセスするための独自拡張で、この記事で解説されています)。また、ルーターモジュールはさらに低レイヤーの通信 IP に接続され、高速シリアル通信を通じて他の FPGA と接続されています。個々の要素の詳細については後述します。
CIRCUS を使う簡単なコード例を下に示します。このコードには 2 つの CIRCUS Channel (“simple out” と “simple in”) が存在しますが、これらのカーネルは別々の FPGA で動作しているものとします。カーネルが別々の FPGA 上で動作しているため、通常の OpenCL コードであれば Chnenel を通じて、ある FPGA から 別の FPGA に通信することはできません。CIRCUS は、この 2 つの Channel をネットワークを通じて仮想的に接続する機能を実現します。
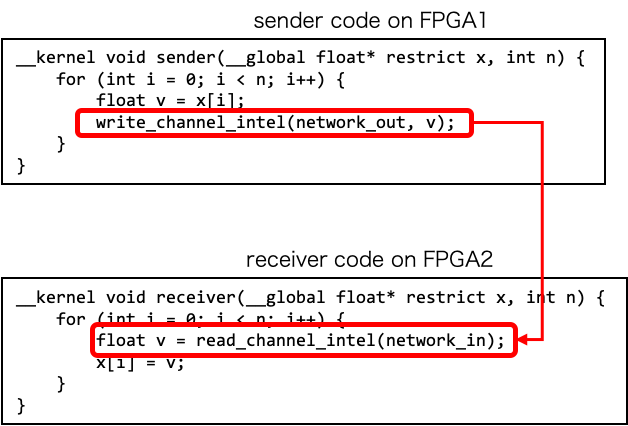
通信制御カーネル
アプリケーションに CIRCUS を適用する場合、CIRCUS Channel の数やデータ型はアプリケーションによって当然異なります。そのため、当センターではこれらの通信に対する要求に対応する OpenCL カーネルコードを、ユーザーが用意した通信定義ファイル (XML ファイル) から自動生成させるコードジェネレータを開発しました。定義ファイルにはアプリケーションが必要とする CIRCUS Channel の定義情報が含まれており、コードジェネレータはそれをもとにして、通信制御を担当する OpenCL カーネル群を自動生成します。また、自動生成したカーネルを制御するためのホストコードも同時に生成します。
以下に、コードジェネレータを使う際の開発フローを図示してみました。入力となっている XML ファイルは上述した CIRCUS を用いた通信コード例を生成するためのものです。図に含まれているファイルの意味は以下の通りです。
- app.xml:CIRCUS Channel の定義ファイル
- app_host.cpp, app_host.h:CIRCUS ランタイム (OpenCL ホストコード)
- app_cl.h:CIRCUS カーネル (OpenCL カーネルコード)
- app.cpp:CIRCUS を使うアプリケーション (OpenCL ホストコード)
- app.cl:CIRCUS を使うアプリケーション (OpenCL カーネルコード)
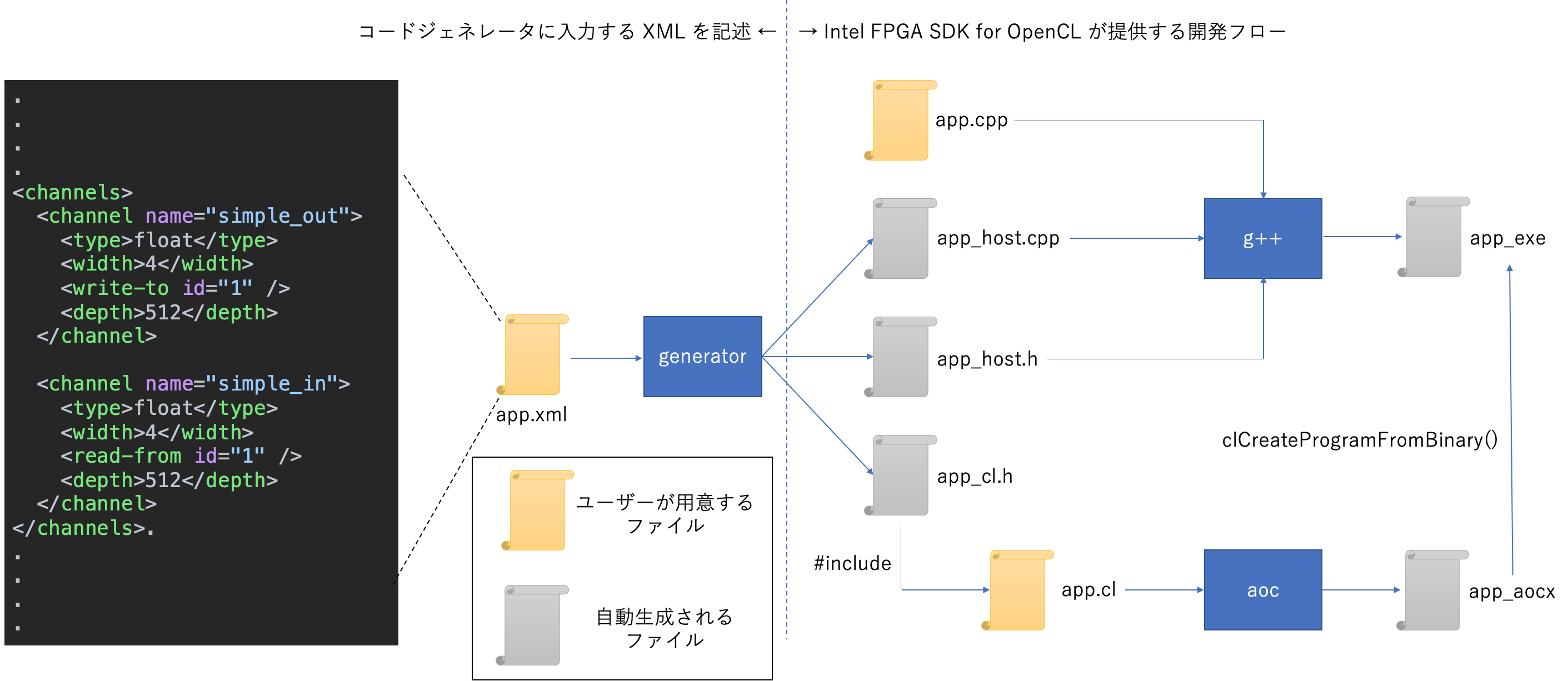
app.xml はアプリケーション固有の CIRCUS 通信構造を定義するファイルです。まず “channel” タグで、CIRCUS Channel を定義します。“name” 属性は CIRCUS Channel の名称を指定し、“type” タグは CIRCUS Channel の OpenCL における型を指定します。“read-from” または “write-to” では通信先の Channel の ID を指定しており、これは MPI 通信における tag に相当するものです。そして “depth” タグによって CIRCUS Channel のバッファのサイズを指定し、“width” タグによって CIRCUS Channel のデータ幅をビット単位で指定します。
上述したように、CIRCUS Channel の数やデータ型はアプリケーションによって当然異なり得るため、それに柔軟に対応するためにこのアプローチを採用しました。そして、これによるもう 1 つの利点は、アプリケーションがいくつのカーネルを持っていても、また各カーネルが何個 CIRCUS Channel を利用するとしても、OpenCL カーネルと ルーターモジュール 間を接続する I/O Channel の構造は変化しないため、アプリケーションが変化しても Verilog HDL で記述されたルーターモジュールは同じものを利用できることです (つまり BSP の変更は必要ないということです。BSP についても I/O Channel と同様にこの記事で解説されています)。つまり、CIRCUS はアプリケーションに依存して変化する部分を OpenCL で記述し、性能が重要なルーターモジュールを Verilog HDL で記述して組み合わせることによって、開発コストと性能のバランスを保つアプローチとなっています。
ルーターモジュール
CIRCUS では Intel が提供する SerialLite III 通信 IP コアを用いて FPGA 間を接続しています。この IP コアは高速シリアルトランシーバを内包したハードウェアモジュールであり、データリンク層までの通信をサポートしています (高速シリアルトランシーバについてはこちらの記事が参考になります)。ただし、この IP コアがデータリンク層で利用しているプロトコルは Intel がサポートする直結通信プロトコルであるため、隣接 FPGA 間でしか通信することができず、Ethernet のようにスイッチを介して任意の宛先にデータを転送することは不可能です。この問題に対して当センターでは、ハードウェアルーター機構を開発し、それを BSP に組み込むことによって解決しています。下の図はそれと OpenCL カーネルとの接続関係を示しており、青矢印はそれぞれ 384 MHz で駆動する 256 bits 幅の全二重の通信バスです (0.384 × 256 = 98.3 Gbps)。
ルーターは 5 入力ポート、5 出力ポート、クロスバー、ルーティングテーブルから構築されており、Verilog HDL で実装されています。ルーターの概要図は以下に示す通りです。
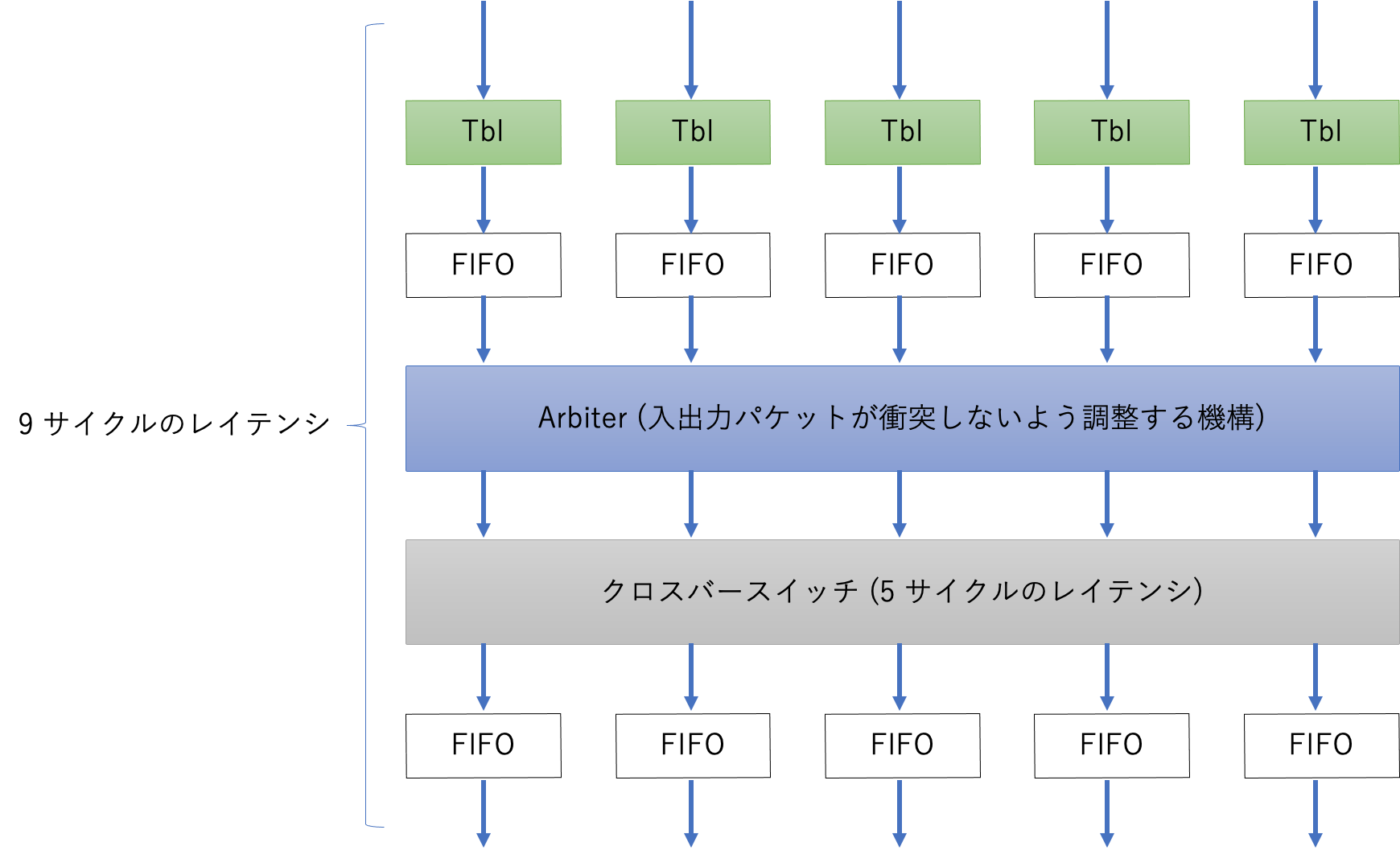
図の “Tbl” はルーティングテーブルを参照するモジュールを意味し、“Arbiter” はルーターの入出力を調停し、パケットが衝突しないように調整を行います。ルーターの動作周波数は通信層の物理層 (SerialLite III) の動作周波数にリンクしており、通信バスと同じく 384 MHz で動作します。RTL シミュレータである ModelSim を用いてルーターモジュールのレイテンシを測定したところ、入力から出力までの全体のレイテンシは 9 クロックサイクル (∼24 ns) で、クロスバー本体のレイテンシは 5 クロックサイクル (∼13 ns) でした。
CIRCUS における通信パケットは FPGA ノード ID と CIRCUS Channel ID の 2 つの宛先情報を持ち、この 2 つの情報を組み合わせて通信の宛先を決定しています。パケットには 6 bit 幅の宛先フィールドをヘッダーの中に持っており、このフィールドで 宛先 FPGA ノード ID を指定しています。パケットがルーターに到着すると、ルーターはパケットに含まれるヘッダの中の宛先を元にルーティングテーブルを参照し、どのポートにパケットを送り出すかを決定します。宛先 FPGA ノード ID に該当する FPGA にパケットが到着すると、I/O Channel を介して Demux. カーネルにパケットが転送され、そのカーネル内で CIRCUS Channel ID がチェックされます。そして、チェックされた CIRCUS Channel ID に対応する Recv kernel にパケットを転送し、そこでパケットからペイロードデータを取り出して、アプリ用のカーネルに転送することによって、ある FPGA で動作する OpenCL カーネルから、任意の FPGA で動作する OpenCL カーネルへのパイプライン通信が実現される、ということです。ちなみに、Send Kernel は宛先情報を含むパケットの生成を担当し、Mux. は複数の入力をまとめて 1 つのストリームにする OpenCL カーネルです。OpenCL カーネルから BSP 内に実装されたハードウェアルーターへのデータの渡し方やデータの受け取り方については、上述した I/O Channel をベースとしたアプローチを採用しており、この記事で解説していますので、ここでは割愛します。
実証実験
CIRCUS の胆は演算パイプラインと通信パイプラインの融合であり、それが想定通りに構築できることを示す実証実験を行いました。この実験結果は論文にも記載されており、ここではその概要を紹介します。
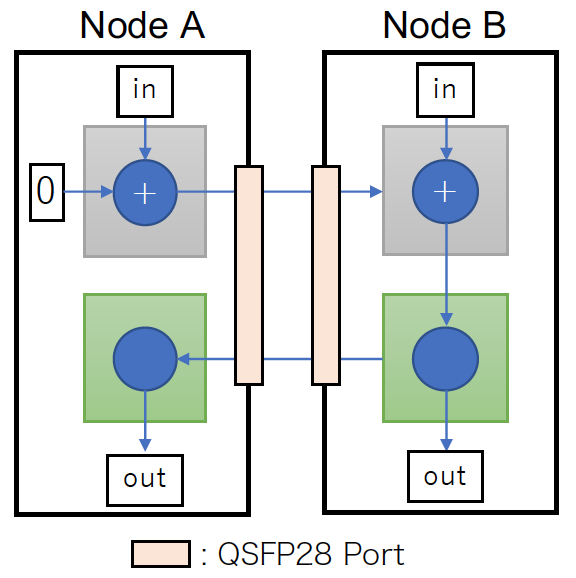
論文より引用
上の図は実証実験に用いたベンチマーク全体の構成を示しています。このベンチマークは MPI Allreduce 通信を 32-bit 整数 (uint type in OpenCL)、MPI SUM で実行した時の動作を模したものです (右側のノードが root ノードのように振る舞う)。
Node A の入力データを Node B に送り、Node B では「自分の入力データ+ Node A から来たデータ」の演算を行い、そしてその結果を Node A に送り返します。図の灰色や緑色の箱は OpenCL カーネルを表しています。
このベンチマークにおけるデータの流れを Signal Tap (組み込みロジック・アナライザツール) でキャプチャしてみました。その様子を以下に示します。
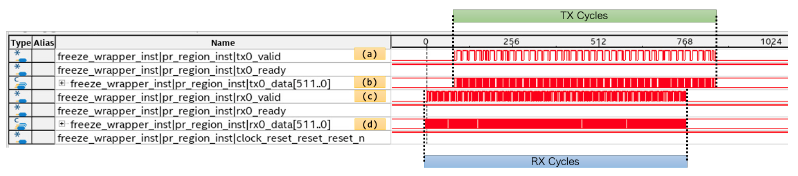
論文より引用
上の図は、ベンチマークを実行した際の OpenCL カーネルと BSP 間にある I/O Channel のデータの流れを Node B でキャプチャしたものです。(a) は送信データの valid 信号、(b) は送信データの中身、(c) は受信データの valid 信号、(d) は受信データの中身を表しています。横軸の単位は OpenCL Kernel のクロックサイクルです。0 点は Signal Tap が記録を開始した時間を示し、図の右側にいくほど未来のデータを意味します。そして、受信している時間と送信している時間が、それぞれ RX Cycles と TX Cycles と表記された箱で示されています。この結果から、受信している時間と送信している時間がオーバーラップしていることがわかると思います。これは即ち、通信と演算を融合したパイプラインが想定通りに構築できることを裏付けています。
まとめ
本記事は、当センターが開発した OpenCL プログラミングを用いた並列 FPGA 処理システムである CIRCUS を紹介しました。CIRCUS の胆は演算パイプラインと通信パイプラインの融合であり、それが確かに実現されていることがお分かり頂けたかと思います。CIRCUS の通信性能がどの程度なのか、関連研究との立ち位置はどうなのか、という疑問については本記事ではお答えしていませんが、それらにつきましては是非論文をお読み頂けると幸いです。
次回はいよいよ ART 法アクセラレータに CIRCUS を適用し、ART 法の並列計算をマルチ FPGA に展開していきます。どうぞお楽しみに。
筑波大学 計算科学研究センター 小林諒平