
このコースでは、スーパーコンピュータ (以下、ブログの文字数節約のために一般的に使われている略称「スパコン」を使います) にも FPGA が何故使われ始めたのか、FPGA をスパコンに使うことによって何ができるようになるのか、どのような技術的な面白さがあるのか等について紹介していきます。
第2回目のこの記事では、いよいよスパコンに FPGA がなぜ必要なのかを紹介していきます。
スパコン分野の研究者が注目する FPGA の3大要素
前回の記事で、スパコンのアクセラレータとして用いられる GPU の問題点に対処するために、FPGA が有望なのではないか、とスパコン分野の研究者は注目していると書きました。それは、FPGA が次の3つの要素を兼ね備えているからです。
何にでも変身できる
他の記事で既に紹介されていますが、FPGA は Field Programmable Gate Array の略称であり、任意の論理回路を電気的にプログラムすることができる集積回路です。そのため、あるときは自分のオリジナルのプロセッサだったり、またあるときは特定の処理専用のハードウェアだったりと、ユーザが設計したハードウェアロジックに「変身」します。どのように変身しているか詳しく知りたい方は [1] を手に取ってみることをオススメします。
何にでも変身できるため、GPU の不得手な処理にフォーカスしたハードウェアロジックを FPGA に実装して、性能低下を回避するという使い方もできます。例えば、前回の記事で紹介した GPU の弱点の1の条件分岐を、FPGA なら次の図のように実行できるハードウェアを実現できます。
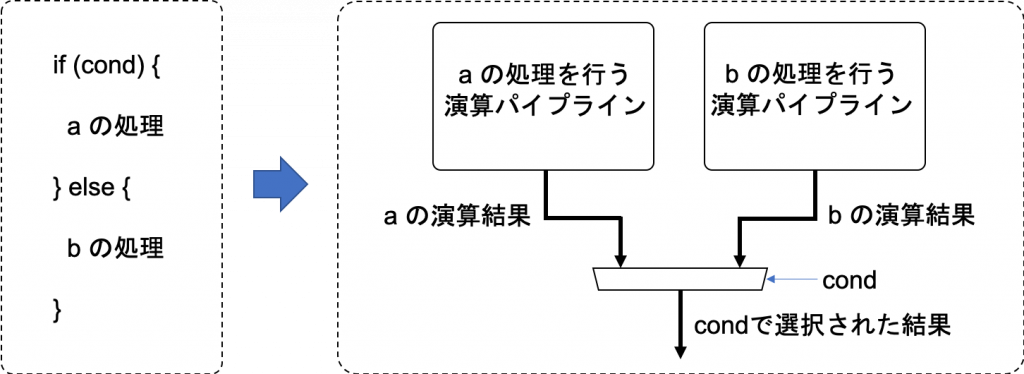
また、何にでも変身できるという性質を持つ FPGA は、近年の高性能計算の分野で重要となっている「コ・デザイン」と呼ばれるコンセプトを究極的に実現しうるデバイスであると言えます。コ・デザインとは、アプリケーションとシステムの両サイドの研究者が協力し、解くべき問題の特性・規模・システムの制約といった条件を総合的に考えて最適なアプリケーション実装とシステム構築を行うコンセプトです [2]。
例えば、宇宙物理学のアプリケーションでは、解くべき問題によっては32ビットの単精度は必要なく、20ビット程度で十分という場合があります (宇宙物理学の研究者と共同研究の打ち合わせをした際に教えて頂きました) 。そのような場合に、FPGA であればその演算精度にカスタマイズしたハードウェアを作り込むことができます。このように、アプリケーションに特化した演算パイプラインと、その演算パイプラインを十分に稼働させるデータ供給機構を実現できる点は FPGA の魅力の1つと言えるでしょう。
ハードウェア記述言語を知らなくても使える
私が学生だった2010年頃は、FPGA を使うにはハードウェア記述言語 (HDL: Hardware Description Language) を習得する必要がありました。HDL は論理回路を設計するための専用言語であり、VHDL や Verilog HDL が代表的です。この HDL ベースの開発でツラい点の一つは、設計者が1ビット・1サイクルの粒度で、解きたいアプリケーションを処理する回路を組み立てる必要があり、コードが非常に煩雑になりがちな所です。
例として、ドット積をとる処理を Verilog HDL でコーディングする例を見ていきましょう。ドット積とは、ベクトルの内積のことであり、行列積をはじめとする科学技術計算に頻出する計算カーネルです。2つのベクトル A = [A0, A1, …, An-1] と B = [B0, B1, …, Bn-1] のドット積は、数式を使って下記のように表すことができます。
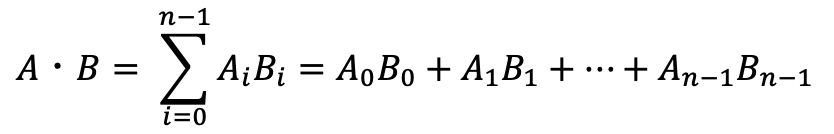
これをVerilog HDLでコーディングすると次のようになります。これだけの処理に69行も書かないといけないので、FPGAに慣れ親しんでいないエンジニアからは敷居が高くてとっつきにくいデバイスだなと思われていました。
module dot_product(
input wire clock,
input wire resetn,
input wire init,
input wire ivalid,
output reg ovalid,
input wire [31:0] a,
input wire [31:0] b,
input wire [31:0] n,
output reg [31:0] sum
);
reg [31:0] a_reg;
reg [31:0] b_reg;
reg ivalid_reg;
always @(posedge clock) a_reg <= a;
always @(posedge clock) b_reg <= b;
always @(posedge clock) begin
if (!resetn) begin
ivalid_reg <= 0;
end else if (init) begin
ivalid_reg <= 0;
end else begin
ivalid_reg <= ivalid;
end
end
reg [63:0] mult_rslt;
reg mult_rslt_valid;
always @(posedge clock) begin
mult_rslt <= a_reg * b_reg;
end
always @(posedge clock) begin
if (!resetn) begin
mult_rslt_valid <= 0;
end else if (init) begin
mult_rslt_valid <= 0;
end else begin
mult_rslt_valid <= ivalid_reg;
end
end
reg [31:0] cnt;
reg [31:0] numdata;
always @(posedge clock) begin
if (!resetn) begin
sum <= 0;
ovalid <= 0;
cnt <= 0;
numdata <= 0;
end else if (init) begin
sum <= 0;
ovalid <= 0;
cnt <= 0;
numdata <= n;
end else if (&{~ovalid, mult_rslt_valid}) begin
sum <= sum + mult_rslt[31:0];
ovalid <= (cnt == numdata - 1);
cnt <= cnt + 1;
end
end
endmoduleですが、この10年で C や C++ といったプログラミング言語から FPGA に実装する回路を生成する技術である「高位合成」がだいぶ進歩したおかげで、その敷居も徐々に下がりつつあります。例えば、Intel が提供する OpenCL ベースの FPGA 開発環境である Intel FPGA SDK for OpenCL では、ユーザーはホスト PC で動作するホストコードと FPGA で動作するカーネルコードの2種類を記述するだけで、ハードウェア記述言語を知らなくても FPGA を利用できます。次の図はそのプログラミングモデルを示していて、ホストコードは主に OpenCL API (Application Programming Interface) を用いての FPGA のコンフィグレーション、メモリ管理、カーネル実行管理などの FPGA デバイスの制御を担当し、カーネルコードは FPGA にオフロードされる演算を担当します。
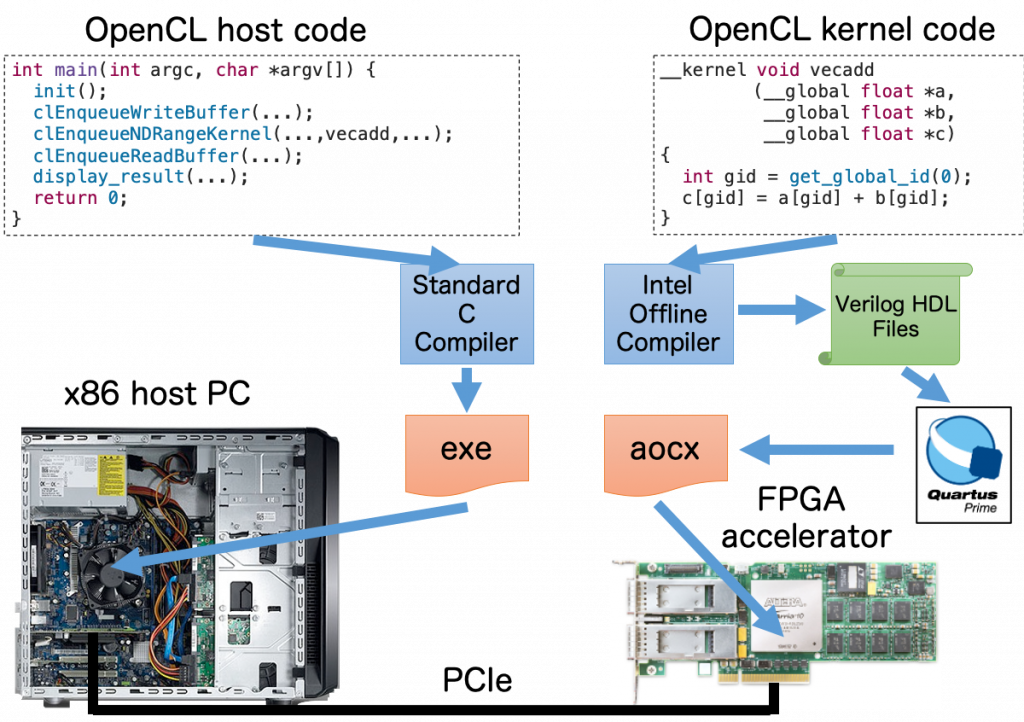
そして、OpenCL で先ほどのドット積をとる処理をコーディングすると次のようになります。Verilog HDL で69行も書かないといけなかった処理が、OpenCL では12行ですみました。
__kernel void dot_product(__global uint *restrict a,
__global uint *restrict b,
const uint n,
__global uint *restrict sum
)
{
uint temp = 0;
for (uint i = 0; i < n; i++) {
temp += a[i] * b[i];
}
*sum = temp;
}
ちなみに、Verilog HDL で記述されたコードは、演算に必要なデータが既に外部メモリからロードされていることを前提としたコードです。OpenCL のコードと完全に対応させるには、外部メモリを操作するコードを追加で書く必要があります。そのため、コード行数が更に増加します。それをしなくても、既に 5.75 倍の記述量の差があるため、HDL ベースの実装がいかに大変か分かると思います。高位合成を利用できるというのは、FPGA に慣れ親しんでいない多くのスパコン分野の研究者にとって、FPGA を利用する上での前提条件と言えるでしょう。
高速通信機構を搭載している
高性能計算やデータセンターに用いられるハイエンド FPGA には、高速通信を実現するための回路ブロックが潤沢に搭載されています。
例えば、Intel 製のハイエンド FPGA である Stratix 10 を搭載している Bittware 520N では、100Gbps の通信リンクを4本 (合計400Gbps) 備えています。どのくらいの規模感なのかを、我々が利用しているインターネットの帯域と比較して考えてみましょう。私の自宅では、インターネットの帯域はおおよそ100Mbpsなので、Bittware 520N のサポートする帯域は、これの4,000倍になります。凄まじいですね。そして、FPGA にこの通信機構を制御するハードウェアを実装すれば、GPU みたいに CPU に制御を移すことなく、FPGA が自律的に高速通信を実行できます。これも、スパコン分野の研究者が注目する FPGA の魅力の1つです。
まとめ
本コースの2回目では、スパコンに FPGA を導入する意義を紹介しました。次回は、スパコン分野の研究者が注目する FPGA の3大要素を踏まえて、どのようなスパコンが導入されたのかを紹介していきます。どうぞお楽しみに。
参考資料
[1] FPGAの原理と構成, オーム社
[2] 筑波大学計算科学研究センター長挨拶, https://www.ccs.tsukuba.ac.jp/ccs_introduction/message/
筑波大学 計算科学研究センター 小林諒平