
みなさんこんにちは。この記事は「TVMを使ってディープラーニングを手軽に FPGA で高速化」の第2回目です。
今回は TVM Vitis-AI Integration を利用して、DNN モデルを Ultra96V2 向けにコンパイルし、実際に実行してみます。
本記事で紹介する手順は TVM Vitis-AI Integration に基づいています。
本記事は以下の環境で実行しています。
- Avnet Ultra96-V2
- PYNQ v2.6
- DPU-PYNQ v1.2.0
- ホストPC
- Ubuntu 18.04
Ultra96 への PYNQ 環境の構築
まずは Ultra96V2 向け PYNQ 環境の SD カードを作成します。
PYNQ 公式サイトからイメージをダウンロードして解凍します。SD カードを PC と接続し、df コマンドでデバイス名を調べてからdd コマンドでイメージファイルを書き込みます。
unzip ultra96v2_v2.6.0.zip
df -h #今回はSDカードが/dev/sdbに認識されている
umount /dev/sdb
sudo dd bs=4M if=ultra96v2_v2.6.0.img of=/dev/sdb
sync以上で SD イメージの作成は完了です。
DPU-PYNQ 環境の構築
SD カードを Ultra96 に差し込み、USB-LAN アダプタまたは Wifi でネットワークに接続し、電源を入れます。
以降は ssh 接続で作業を行うため、Ultra96 の IP アドレスを調べます。筆者は DisplayPort-HDMI アダプタと USB キーボードを Ultra96 に接続して画面出力した状態でifconfigで調べました。
IP アドレスがわかれば、ホスト環境から ssh 接続し、DPU 環境をセットアップします。FPGA ボードへの書き込みおよび DPU の制御には root 権限が必要なので、Ultra96 での作業は全て root ユーザで実行します。
ssh xilinx@192.168.xx.xx #デフォルトパスワードはxilinx
sudo -s #以下rootで実行
git clone --branch v1.2.0 --recursive --shallow-submodules https://github.com/Xilinx/DPU-PYNQ.git
cd DPU-PYNQ/upgrade
make
pip3 install pynq-dpu==1.2.0DPU ビットストリームを FPGA ボードに書き込みます。
python3 -c 'from pynq_dpu import DpuOverlay ; overlay = DpuOverlay("dpu.bit")'正常に書き込めれば、dexplorer -w コマンドで FPGA 上にある DPU の情報を以下のように確認できます。DPU B1600 が1つ搭載されていることが確認できます。
dexplorer -w
[DPU IP Spec]
IP Timestamp : 2020-06-18 12:00:00
DPU Core Count : 1
[DPU Core Configuration List]
DPU Core : #0
DPU Enabled : Yes
DPU Arch : B1600
DPU Target Version : v1.4.1
DPU Freqency : 300 MHz
Ram Usage : Low
DepthwiseConv : Enabled
DepthwiseConv+Relu6 : Enabled
Conv+Leakyrelu : Enabled
Conv+Relu6 : Enabled
Channel Augmentation : Disabled
Average Pool : EnabledUltra96 への TVM ランタイムのインストール
Ultra96 ボード上で TVM でビルドしたモジュールを実行するために、TVM ランタイムのビルド・インストールをします。
- 必要なパッケージのインストール
apt-get install libhdf5-dev
pip3 install pydot==1.4.1 h5py==2.8.0- PyXir のインストール
PyXir のバージョンは、記事執筆時点では v0.2.1 を使用しました。
git clone --recursive https://github.com/Xilinx/pyxir.git
cd pyxir
git checkout refs/tags/v0.2.1
git submodule update --recursive
sudo python3 setup.py install --use_vai_rt_dpuczdx8g- TVM ランタイムのビルド・インストール
Ultra96 側には TVM のランタイムのみをビルドします。
git clone --recursive https://github.com/apache/tvm
cd tvm
mkdir build
cp cmake/config.cmake build
cd build
echo set\(USE_LLVM OFF\) >> config.cmake
echo set\(USE_VITIS_AI ON\) >> config.cmake
cmake ..
make tvm_runtime -j$(nproc)
cd ..
export PYTHONPATH=`pwd`/python/:$PYTHONPATH最後に TVM ランタイムのインストールが成功したかどうかを以下のコマンドで確認することができます。
python3 -c 'import pyxir; import tvm'ホスト環境での TVM のセットアップ
TVM が提供する Dockerfile を使用してホスト側の環境構築を行います。作成されるイメージは dockerhub にある最新の Vitis-AI をベースとしています。 (記事執筆時点v1.3)
git clone --recursive https://github.com/apache/tvm.git
./tvm/docker/build.sh demo_vitis_ai bash
./tvm/docker/bash.sh tvm.demo_vitis_ai以降は Docker コンテナ内で作業を進めます。筆者は VSCode の Remote Development を使用してコンテナにアタッチして作業を進めました。PyXir は Vitis-AI が提供する conda 環境 vitis-ai-tensorflow を内部で必要とするため、conda 環境をアクティベートします。
$VAI_ROOT/conda/etc/profile.d/conda.sh
conda activate vitis-ai-tensorflow次に、PyXir を docker 環境にインストールします。ここで、PyXir に含まれる Ultra96 のDPU 情報 (dcf) ファイルは今回使用する DPU-PYNQ 環境と異なるため、dcf ファイルを書き換えてからインストールします。dcf ファイルに含まれる DPU コンフィグレーション情報をもとに実行モジュールがコンパイルされるため、FPGA ビットストリームに含まれる DPU の設定を適切に設定する必要があります。Vitis-AI が提供する dlet を用いて Vivado で作成された DPU ハードウェアハンドオフファイル (hwh) から dcf を作成します。
git clone --recursive https://github.com/Xilinx/pyxir
cd pyxir
git checkout refs/tags/v0.2.1
git submodule update --recursive
cd ..
#modify ultra96 hardware file for DPU-PYNQ v2.6
wget https://www.xilinx.com/bin/public/openDownload?filename=pynqdpu.dpu.ultra96.hwh -O ultra96.hwh
dlet -f ultra96.hwh #dpu-06-22-2021-18-45.dcfのようなファイルが作成されます
mv `ls -t *.dcf | head -n1` Ultra96.dcf
echo -e "{\n\t\"target\" : \"dpuv2\",\n\t\"dcf\" : \"Ultra96.dcf\",\n\t\"cpu_arch\" : \"arm64\"\n}" > ultra96.json
mv Ultra96.dcf ./pyxir/python/pyxir/contrib/target/components/DPUCZDX8G/
mv ultra96.json ./pyxir/python/pyxir/contrib/target/components/DPUCZDX8G/
cd pyxir
python3 setup.py install最後に TVM をビルドしてインストールします。
cd tvm
mkdir build
cp cmake/config.cmake build
cd build
echo set\(USE_LLVM ON\) >> config.cmake
echo set\(USE_VITIS_AI ON\) >> config.cmake
cmake ..
make -j$(nproc)
cd ..
export PYTHONPATH=`pwd`/python:$PYTHONPATH
cd tvm/python
pip3 install -e . --userVitis-AI チュートリアルの動作
ここでは、Xilinx の PyXir リポジトリで公開されている resnet18 のサンプルを実行します。このサンプルでは MXNet の resnet18 モデルを TVM Vitis-AI オンザフライ量子化により量子化し、PyXir と TVM を用いて DPU 向けの実行モジュールをビルドします。
docker 環境における Ultra96 向け実行モジュールのビルド
resnet18 のサンプルに含まれるedge_resnet_18_host.pyを実行します。
サンプルコードはZCU104ボードをターゲットにしていますので、131行目をtarget = 'DPUCZDX8G-ultra96'に書き換えます。
また、157行目のmod = partition_for_vitis_ai(mod, params, dpu=target)の後にprint(mod)を挿入し、TVM におけるネットワークの内部表現である relayIR を表示してみます。
最後に、今回の記事では TVM の RPC を用いたリモート実行を行うのでグラフとパラメータを保存する処理を追記します。
graph, params = lib_edge_dpu.get_graph_json(), lib_edge_dpu.get_params()
with open('mod.json', 'w') as graph_file:
graph_file.write(graph)
with open('mod.params', 'wb') as params_file:
params_file.write(tvm.runtime.save_param_dict(params))edge_resnet_18_host.pyを実行することで表示される relayIR は以下の通りです。
def @main(%data: Tensor[(1, 3, 224, 224), float32]) -> Tensor[(1, 1000), float32] {
%0 = layout_transform(%data, src_layout="NCHW", dst_layout="NHWC") /* ty=Tensor[(1, 224, 224, 3), float32] */;
%1 = @vitis_ai_0(%0) /* ty=Tensor[(1, 1, 1, 512), float32] */;
%2 = layout_transform(%1, src_layout="NHWC", dst_layout="NCHW") /* ty=Tensor[(1, 512, 1, 1), float32] */;
%3 = nn.batch_flatten(%2) /* ty=Tensor[(1, 512), float32] */;
%4 = nn.dense(%3, meta[relay.Constant][0] /* ty=Tensor[(1000, 512), float32] */, units=1000) /* ty=Tensor[(1, 1000), float32] */;
add(%4, meta[relay.Constant][1] /* ty=Tensor[(1000), float32] */) /* ty=Tensor[(1, 1000), float32] */
}
def @vitis_ai_0(%vitis_ai_0_i0: Tensor[(1, 224, 224, 3), float32], global_symbol="vitis_ai_0", Primitive=1, Compiler="vitis_ai", Inline=1) -> Tensor[(1, 1, 1, 512), float32] {
%5 = nn.conv2d(%vitis_ai_0_i0, meta[relay.Constant][2] /* ty=Tensor[(7, 7, 3, 64), float32] */, strides=[2, 2], padding=[3, 3, 3, 3], channels=64, kernel_size=[7, 7], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 112, 112, 64), float32] */;
%6 = nn.batch_norm(%5, meta[relay.Constant][3] /* ty=Tensor[(64), float32] */, meta[relay.Constant][4] /* ty=Tensor[(64), float32] */, meta[relay.Constant][5] /* ty=Tensor[(64), float32] */, meta[relay.Constant][6] /* ty=Tensor[(64), float32] */, axis=3) /* ty=(Tensor[(1, 112, 112, 64), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%7 = %6.0;
%8 = nn.relu(%7) /* ty=Tensor[(1, 112, 112, 64), float32] */;
%9 = nn.max_pool2d(%8, pool_size=[3, 3], strides=[2, 2], padding=[1, 1, 1, 1], layout="NHWC") /* ty=Tensor[(1, 56, 56, 64), float32] */;
%10 = nn.conv2d(%9, meta[relay.Constant][7] /* ty=Tensor[(3, 3, 64, 64), float32] */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 56, 56, 64), float32] */;
%11 = nn.batch_norm(%10, meta[relay.Constant][8] /* ty=Tensor[(64), float32] */, meta[relay.Constant][9] /* ty=Tensor[(64), float32] */, meta[relay.Constant][10] /* ty=Tensor[(64), float32] */, meta[relay.Constant][11] /* ty=Tensor[(64), float32] */, axis=3) /* ty=(Tensor[(1, 56, 56, 64), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%12 = %11.0;
%13 = nn.relu(%12) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%14 = nn.conv2d(%13, meta[relay.Constant][12] /* ty=Tensor[(3, 3, 64, 64), float32] */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 56, 56, 64), float32] */;
%15 = nn.batch_norm(%14, meta[relay.Constant][13] /* ty=Tensor[(64), float32] */, meta[relay.Constant][14] /* ty=Tensor[(64), float32] */, meta[relay.Constant][15] /* ty=Tensor[(64), float32] */, meta[relay.Constant][16] /* ty=Tensor[(64), float32] */, axis=3) /* ty=(Tensor[(1, 56, 56, 64), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%16 = %15.0;
%17 = add(%9, %16) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%18 = nn.relu(%17) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%19 = nn.conv2d(%18, meta[relay.Constant][17] /* ty=Tensor[(3, 3, 64, 64), float32] */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 56, 56, 64), float32] */;
%20 = nn.batch_norm(%19, meta[relay.Constant][18] /* ty=Tensor[(64), float32] */, meta[relay.Constant][19] /* ty=Tensor[(64), float32] */, meta[relay.Constant][20] /* ty=Tensor[(64), float32] */, meta[relay.Constant][21] /* ty=Tensor[(64), float32] */, axis=3) /* ty=(Tensor[(1, 56, 56, 64), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%21 = %20.0;
%22 = nn.relu(%21) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%23 = nn.conv2d(%22, meta[relay.Constant][22] /* ty=Tensor[(3, 3, 64, 64), float32] */, padding=[1, 1, 1, 1], channels=64, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 56, 56, 64), float32] */;
%24 = nn.batch_norm(%23, meta[relay.Constant][23] /* ty=Tensor[(64), float32] */, meta[relay.Constant][24] /* ty=Tensor[(64), float32] */, meta[relay.Constant][25] /* ty=Tensor[(64), float32] */, meta[relay.Constant][26] /* ty=Tensor[(64), float32] */, axis=3) /* ty=(Tensor[(1, 56, 56, 64), float32], Tensor[(64), float32], Tensor[(64), float32]) */;
%25 = %24.0;
%26 = add(%18, %25) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%27 = nn.relu(%26) /* ty=Tensor[(1, 56, 56, 64), float32] */;
%28 = nn.conv2d(%27, meta[relay.Constant][27] /* ty=Tensor[(1, 1, 64, 128), float32] */, strides=[2, 2], padding=[0, 0, 0, 0], channels=128, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 28, 28, 128), float32] */;
%29 = nn.batch_norm(%28, meta[relay.Constant][28] /* ty=Tensor[(128), float32] */, meta[relay.Constant][29] /* ty=Tensor[(128), float32] */, meta[relay.Constant][30] /* ty=Tensor[(128), float32] */, meta[relay.Constant][31] /* ty=Tensor[(128), float32] */, axis=3) /* ty=(Tensor[(1, 28, 28, 128), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%30 = nn.conv2d(%27, meta[relay.Constant][32] /* ty=Tensor[(3, 3, 64, 128), float32] */, strides=[2, 2], padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 28, 28, 128), float32] */;
%31 = nn.batch_norm(%30, meta[relay.Constant][33] /* ty=Tensor[(128), float32] */, meta[relay.Constant][34] /* ty=Tensor[(128), float32] */, meta[relay.Constant][35] /* ty=Tensor[(128), float32] */, meta[relay.Constant][36] /* ty=Tensor[(128), float32] */, axis=3) /* ty=(Tensor[(1, 28, 28, 128), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%32 = %31.0;
%33 = nn.relu(%32) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%34 = nn.conv2d(%33, meta[relay.Constant][37] /* ty=Tensor[(3, 3, 128, 128), float32] */, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 28, 28, 128), float32] */;
%35 = nn.batch_norm(%34, meta[relay.Constant][38] /* ty=Tensor[(128), float32] */, meta[relay.Constant][39] /* ty=Tensor[(128), float32] */, meta[relay.Constant][40] /* ty=Tensor[(128), float32] */, meta[relay.Constant][41] /* ty=Tensor[(128), float32] */, axis=3) /* ty=(Tensor[(1, 28, 28, 128), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%36 = %29.0;
%37 = %35.0;
%38 = add(%36, %37) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%39 = nn.relu(%38) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%40 = nn.conv2d(%39, meta[relay.Constant][42] /* ty=Tensor[(3, 3, 128, 128), float32] */, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 28, 28, 128), float32] */;
%41 = nn.batch_norm(%40, meta[relay.Constant][43] /* ty=Tensor[(128), float32] */, meta[relay.Constant][44] /* ty=Tensor[(128), float32] */, meta[relay.Constant][45] /* ty=Tensor[(128), float32] */, meta[relay.Constant][46] /* ty=Tensor[(128), float32] */, axis=3) /* ty=(Tensor[(1, 28, 28, 128), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%42 = %41.0;
%43 = nn.relu(%42) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%44 = nn.conv2d(%43, meta[relay.Constant][47] /* ty=Tensor[(3, 3, 128, 128), float32] */, padding=[1, 1, 1, 1], channels=128, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 28, 28, 128), float32] */;
%45 = nn.batch_norm(%44, meta[relay.Constant][48] /* ty=Tensor[(128), float32] */, meta[relay.Constant][49] /* ty=Tensor[(128), float32] */, meta[relay.Constant][50] /* ty=Tensor[(128), float32] */, meta[relay.Constant][51] /* ty=Tensor[(128), float32] */, axis=3) /* ty=(Tensor[(1, 28, 28, 128), float32], Tensor[(128), float32], Tensor[(128), float32]) */;
%46 = %45.0;
%47 = add(%39, %46) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%48 = nn.relu(%47) /* ty=Tensor[(1, 28, 28, 128), float32] */;
%49 = nn.conv2d(%48, meta[relay.Constant][52] /* ty=Tensor[(1, 1, 128, 256), float32] */, strides=[2, 2], padding=[0, 0, 0, 0], channels=256, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 14, 14, 256), float32] */;
%50 = nn.batch_norm(%49, meta[relay.Constant][53] /* ty=Tensor[(256), float32] */, meta[relay.Constant][54] /* ty=Tensor[(256), float32] */, meta[relay.Constant][55] /* ty=Tensor[(256), float32] */, meta[relay.Constant][56] /* ty=Tensor[(256), float32] */, axis=3) /* ty=(Tensor[(1, 14, 14, 256), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%51 = nn.conv2d(%48, meta[relay.Constant][57] /* ty=Tensor[(3, 3, 128, 256), float32] */, strides=[2, 2], padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 14, 14, 256), float32] */;
%52 = nn.batch_norm(%51, meta[relay.Constant][58] /* ty=Tensor[(256), float32] */, meta[relay.Constant][59] /* ty=Tensor[(256), float32] */, meta[relay.Constant][60] /* ty=Tensor[(256), float32] */, meta[relay.Constant][61] /* ty=Tensor[(256), float32] */, axis=3) /* ty=(Tensor[(1, 14, 14, 256), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%53 = %52.0;
%54 = nn.relu(%53) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%55 = nn.conv2d(%54, meta[relay.Constant][62] /* ty=Tensor[(3, 3, 256, 256), float32] */, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 14, 14, 256), float32] */;
%56 = nn.batch_norm(%55, meta[relay.Constant][63] /* ty=Tensor[(256), float32] */, meta[relay.Constant][64] /* ty=Tensor[(256), float32] */, meta[relay.Constant][65] /* ty=Tensor[(256), float32] */, meta[relay.Constant][66] /* ty=Tensor[(256), float32] */, axis=3) /* ty=(Tensor[(1, 14, 14, 256), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%57 = %50.0;
%58 = %56.0;
%59 = add(%57, %58) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%60 = nn.relu(%59) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%61 = nn.conv2d(%60, meta[relay.Constant][67] /* ty=Tensor[(3, 3, 256, 256), float32] */, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 14, 14, 256), float32] */;
%62 = nn.batch_norm(%61, meta[relay.Constant][68] /* ty=Tensor[(256), float32] */, meta[relay.Constant][69] /* ty=Tensor[(256), float32] */, meta[relay.Constant][70] /* ty=Tensor[(256), float32] */, meta[relay.Constant][71] /* ty=Tensor[(256), float32] */, axis=3) /* ty=(Tensor[(1, 14, 14, 256), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%63 = %62.0;
%64 = nn.relu(%63) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%65 = nn.conv2d(%64, meta[relay.Constant][72] /* ty=Tensor[(3, 3, 256, 256), float32] */, padding=[1, 1, 1, 1], channels=256, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 14, 14, 256), float32] */;
%66 = nn.batch_norm(%65, meta[relay.Constant][73] /* ty=Tensor[(256), float32] */, meta[relay.Constant][74] /* ty=Tensor[(256), float32] */, meta[relay.Constant][75] /* ty=Tensor[(256), float32] */, meta[relay.Constant][76] /* ty=Tensor[(256), float32] */, axis=3) /* ty=(Tensor[(1, 14, 14, 256), float32], Tensor[(256), float32], Tensor[(256), float32]) */;
%67 = %66.0;
%68 = add(%60, %67) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%69 = nn.relu(%68) /* ty=Tensor[(1, 14, 14, 256), float32] */;
%70 = nn.conv2d(%69, meta[relay.Constant][77] /* ty=Tensor[(1, 1, 256, 512), float32] */, strides=[2, 2], padding=[0, 0, 0, 0], channels=512, kernel_size=[1, 1], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 7, 7, 512), float32] */;
%71 = nn.batch_norm(%70, meta[relay.Constant][78] /* ty=Tensor[(512), float32] */, meta[relay.Constant][79] /* ty=Tensor[(512), float32] */, meta[relay.Constant][80] /* ty=Tensor[(512), float32] */, meta[relay.Constant][81] /* ty=Tensor[(512), float32] */, axis=3) /* ty=(Tensor[(1, 7, 7, 512), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%72 = nn.conv2d(%69, meta[relay.Constant][82] /* ty=Tensor[(3, 3, 256, 512), float32] */, strides=[2, 2], padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 7, 7, 512), float32] */;
%73 = nn.batch_norm(%72, meta[relay.Constant][83] /* ty=Tensor[(512), float32] */, meta[relay.Constant][84] /* ty=Tensor[(512), float32] */, meta[relay.Constant][85] /* ty=Tensor[(512), float32] */, meta[relay.Constant][86] /* ty=Tensor[(512), float32] */, axis=3) /* ty=(Tensor[(1, 7, 7, 512), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%74 = %73.0;
%75 = nn.relu(%74) /* ty=Tensor[(1, 7, 7, 512), float32] */;
%76 = nn.conv2d(%75, meta[relay.Constant][87] /* ty=Tensor[(3, 3, 512, 512), float32] */, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 7, 7, 512), float32] */;
%77 = nn.batch_norm(%76, meta[relay.Constant][88] /* ty=Tensor[(512), float32] */, meta[relay.Constant][89] /* ty=Tensor[(512), float32] */, meta[relay.Constant][90] /* ty=Tensor[(512), float32] */, meta[relay.Constant][91] /* ty=Tensor[(512), float32] */, axis=3) /* ty=(Tensor[(1, 7, 7, 512), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%78 = %71.0;
%79 = %77.0;
%80 = add(%78, %79) /* ty=Tensor[(1, 7, 7, 512), float32] */;
%81 = nn.relu(%80) /* ty=Tensor[(1, 7, 7, 512), float32] */;
%82 = nn.conv2d(%81, meta[relay.Constant][92] /* ty=Tensor[(3, 3, 512, 512), float32] */, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 7, 7, 512), float32] */;
%83 = nn.batch_norm(%82, meta[relay.Constant][93] /* ty=Tensor[(512), float32] */, meta[relay.Constant][94] /* ty=Tensor[(512), float32] */, meta[relay.Constant][95] /* ty=Tensor[(512), float32] */, meta[relay.Constant][96] /* ty=Tensor[(512), float32] */, axis=3) /* ty=(Tensor[(1, 7, 7, 512), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%84 = %83.0;
%85 = nn.relu(%84) /* ty=Tensor[(1, 7, 7, 512), float32] */;
%86 = nn.conv2d(%85, meta[relay.Constant][97] /* ty=Tensor[(3, 3, 512, 512), float32] */, padding=[1, 1, 1, 1], channels=512, kernel_size=[3, 3], data_layout="NHWC", kernel_layout="HWIO") /* ty=Tensor[(1, 7, 7, 512), float32] */;
%87 = nn.batch_norm(%86, meta[relay.Constant][98] /* ty=Tensor[(512), float32] */, meta[relay.Constant][99] /* ty=Tensor[(512), float32] */, meta[relay.Constant][100] /* ty=Tensor[(512), float32] */, meta[relay.Constant][101] /* ty=Tensor[(512), float32] */, axis=3) /* ty=(Tensor[(1, 7, 7, 512), float32], Tensor[(512), float32], Tensor[(512), float32]) */;
%88 = %87.0;
%89 = add(%81, %88) /* ty=Tensor[(1, 7, 7, 512), float32] */;
%90 = nn.relu(%89) /* ty=Tensor[(1, 7, 7, 512), float32] */;
nn.global_avg_pool2d(%90, layout="NHWC") /* ty=Tensor[(1, 1, 1, 512), float32] */
}@vitis_ai_0の部分が DPU にオフロードされる部分であり、ネットワークの推論処理の大部分が DPU で実行されるようにネットワークグラフが分割されていることが確認できました。python3 edge_resnet_18_host.pyの実行結果として実行モジュールlib_dpu.so, 分割されたグラフmod.json、パラメータmod.paramsが生成されます。
Ultra96 上での実機実行
resnet18 の動作サンプルには実機実行用のサンプルedge_resnet_18_board.pyが含まれていますが、せっかくなので今回は TVM の RPC (Remote Procedure Call) 機能を使ってリモート実行を試してみましょう。RPC を利用することで、エッジデバイス上での動作確認や性能評価をネットワーク経由で実行することが出来ます。
まず、ホストの docker 環境上でTVM RPC Tracker を起動します。
python3 -m tvm.exec.rpc_tracker --host=0.0.0.0 --port=8889 &
INFO:RPCTracker:bind to 0.0.0.0:8889Ultra96 に ssh 接続して TVM RPC Server を起動します。--trackerには RPC Tracker を動作させているホスト PC の IP アドレスとポート番号を指定します。key は RPC Tracker に登録されているデバイスを識別するためのもので、ここではultra96_testとしました。
python3 -m tvm.exec.rpc_server --tracker=192.168.xx.xx:8889 --key=ultra96_test
INFO:RPCServer:bind to 0.0.0.0:9091RPC サーバのログにWARNING:RPCServer:Cannot connect to tracker ('192.168.xx.xx', 8889), retry in 5 secs...のように表示される場合、RPC トラッカーへの接続ができていません。
ホストの docker 環境で TVM RPC Tracker を起動したものとは別にシェルを開いて、Device Registry を確認します。
以下のように Ultra96 が登録され、RPC の実行キューが実行可能状態であることが確認できます。
python3 -m tvm.exec.query_rpc_tracker --host=0.0.0.0 --port=8889
Tracker address 0.0.0.0:8889
Server List
----------------------------
server-address key
----------------------------
192.168.xx.xx:57966 server:ultra96_test
----------------------------
Queue Status
------------------------------------
key total free pending
------------------------------------
ultra96_test 1 1 0
------------------------------------以下の Python スクリプトを実行して、TVM の RPC 機能によるリモート実行を動作させます。本スクリプト内では、RPC サーバが動作している Ultra96 の IP アドレスとデバイス登録名を元に TVM RPC セッションを作成して、推論処理を実行しています。
import time
import numpy as np
from PIL import Image
from tvm.autotvm.measure import request_remote
from tvm.contrib import graph_runtime
from tvm.contrib.download import download_testdata
host = "0.0.0.0"
port = 8890
key = "ultra96_test"
# Define utility functions
def softmax(x):
x_exp = np.exp(x - np.max(x))
return x_exp / x_exp.sum()
def transform_image(image):
image = np.array(image) - np.array([123., 117., 104.])
image /= np.array([58.395, 57.12, 57.375])
image = image.transpose((2, 0, 1))
image = image[np.newaxis, :]
return image
# Download synset
img_url = 'https://github.com/dmlc/mxnet.js/blob/master/data/cat.png?raw=true'
img_path = download_testdata(img_url, 'cat.png', module='data')
synset_url = ''.join(['https://gist.githubusercontent.com/zhreshold/',
'4d0b62f3d01426887599d4f7ede23ee5/raw/',
'596b27d23537e5a1b5751d2b0481ef172f58b539/',
'imagenet1000_clsid_to_human.txt'])
synset_name = 'imagenet1000_clsid_to_human.txt'
synset_path = download_testdata(synset_url, synset_name, module='data')
with open(synset_path) as f:
synset = eval(f.read())
out_shape = (1, 1000)
# create session
session = request_remote(key, host, port, timeout=1000)
# session = tvm.rpc.connect(host, port, key)
session.upload('lib_dpu.so')
lib = session.load_module('lib_dpu.so')
graph = open('mod.json').read()
params = bytearray(open('mod.params', 'rb').read())
# create context
ctx = session.cpu()
# create runtime
module = graph_runtime.create(graph, lib, ctx)
module.load_params(params)
# set input data
image = Image.open(img_path).resize((224, 224))
image = transform_image(image)
module.set_input('data', image)
# run inference
start = time.time()
module.run()
end = time.time()
# portprocess
res = softmax(module.get_output(0).asnumpy()[0])
top1 = np.argmax(res)
print('========================================')
print('TVM prediction top-1:', top1, synset[top1])
print('========================================')
inference_time = np.round((end - start) * 1000, 2)
print('========================================')
print('Inference time: ' + str(inference_time) + " ms")
print('========================================')入力画像

実行結果
========================================
TVM prediction top-1: 285 Egyptian cat
========================================
========================================
Inference time: 26.61 ms
========================================
無事猫の画像がEgyptian catとして分類されていることが確認できました。
TVM Vitis-AI Integration により TVM を用いて resnet18 を DPU にオフロードして動作することができました。
Vitis-AI チュートリアルの解説
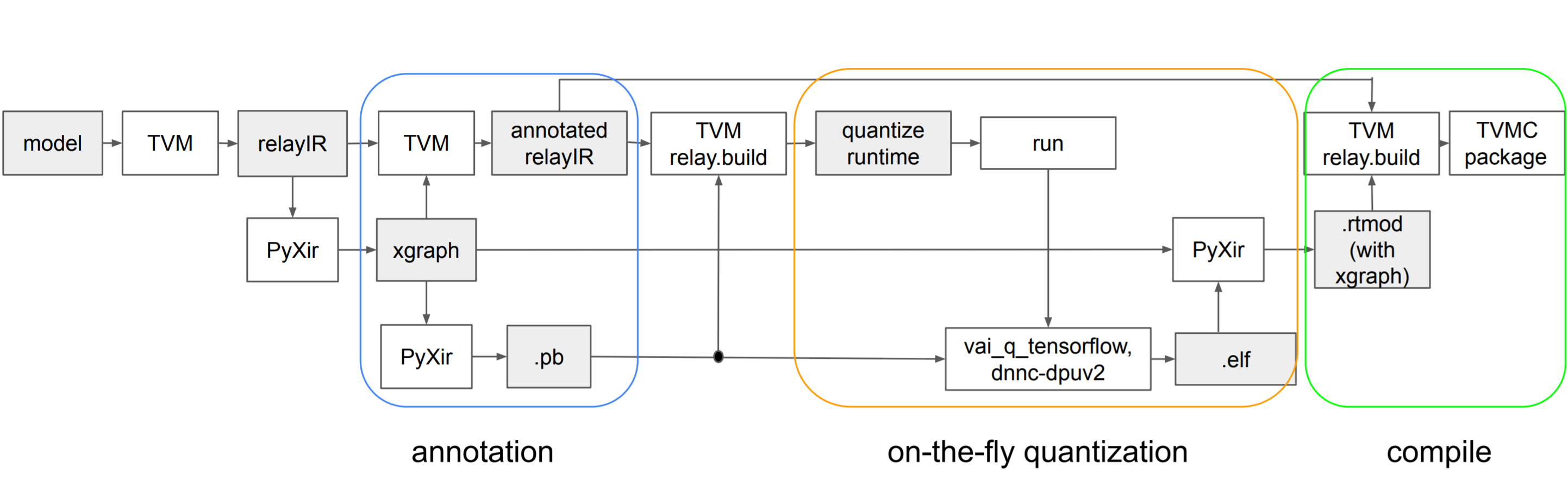
先程動作させた TVM Vitis-AI Integration ではどのように DPU 向けの実行モジュールを生成していたのかを解説します。
コンパイル処理は以下の3つから成り立っています。
- DPU オフロード部分の決定・Vitis-AI Quantizer 向け実行モジュール生成
- Vitis-AI Quantize rによるオンザフライ量子化
- 量子化されたモデルを含めた Ultra96 向けの TVM 実行モジュール生成
DPU オフロード部分の決定・Vitis-AI Quantizer 向け実行モジュール生成
まず最初に、MXNet のモデルを TVM の内部表現である relayIR に変換します。
mod, params = relay.frontend.from_mxnet(block, shape_dict)次に、relayIR に最適化を施し、DPU はNHWC形式の演算のみに対応するため、Conv2D のレイアウトをNHWCに変換します。
mod = relay.transform.InferType()(mod)
mod["main"] = bind_params_by_name(mod["main"], params)
mod = transform.RemoveUnusedFunctions()(mod)
desired_layouts = {'nn.conv2d': ['NHWC', 'default']}
seq = tvm.transform.Sequential([relay.transform.RemoveUnusedFunctions(),
relay.transform.ConvertLayout(desired_layouts),
relay.transform.FoldConstant()])
with tvm.transform.PassContext(opt_level=3):
mod = seq(mod)relayIR で表されるネットワークのグラフのうち、DPU 上で実行できる部分とそうでない部分に分割します。
mod = partition_for_vitis_ai(mod, params, dpu=target)この処理の内部で relayIR は PyXir 内部での内部表現Xgraphに変換され、DPU にオフロードできる relayIR の演算が PyXir によってアノテーションされた後、最大の部分グラフが DPU にオフロードされる部分として決定されます。
PyXir とは Xilinx が開発している DNN 向け中間表現で、TVM や ONNX Runtime といった DNN フレームワークとの統合が行えるように設計されています。コンパイル時には Vitis-AI Quantizer や DNNDK DNNC が内部で実行され、実行時には VART (Vitis-AI Runtime) が呼び出されることで DPU へのコンパイル処理・推論処理の実行が実現されています。
desired_layouts = {'nn.conv2d': ['NCHW', 'default']}
seq = tvm.transform.Sequential([relay.transform.RemoveUnusedFunctions(),
relay.transform.ConvertLayout(desired_layouts),
relay.transform.FoldConstant()])
with tvm.transform.PassContext(opt_level=3):
mod = seq(mod)
export_rt_mod_file = os.path.join(os.getcwd(), 'vitis_ai.rtmod')
build_options = {
'dpu': target,
'export_runtime_module': export_rt_mod_file
}
with tvm.transform.PassContext(opt_level=3, config={'relay.ext.vitis_ai.options': build_options}):
lib = relay.build(mod, tvm_target, params=params)最後に、分割の結果 DPU にオフロードされなかった処理を CPU 向けに最適化し、ホスト環境向けの実行モジュールを生成します。
Vitis-AI Quantizer によるオンザフライ量子化
先程の処理で生成した実行モジュールをホスト環境で実行することで、Vitis-AI Quantizer による量子化が実行されます。
PyXir での内部表現 XGraph を Tensorflow のグラフ定義に変換され、Tensorflow 向けの量子化vai_q_tensorflowが内部で実行されています。量子化後に Vitis-AI DPU Compiler であるDNNCが実行され、vitis_ai.rtmodが DPU ランタイムモジュールとして生成されます。
InferenceSession = graph_executor.GraphModule(lib["default"](tvm.cpu()))
...
InferenceSession.run()量子化されたモデルを含めた Ultra96 向けのTVM実行モジュール生成
1つめの処理で分割された relayIR と2つめの処理で生成された DPU ランタイムモジュールを用いて Ultra96 向けの TVM 実行モジュールを生成します。Ultra96 上の CPU で実行される処理も実行モジュールには含めるため、クロスコンパイラを指定してコンパイル処理を行います。
tvm_target = tvm.target.arm_cpu('ultra96')
lib_kwargs = {
'fcompile': contrib.cc.create_shared,
'cc': "/usr/aarch64-linux-gnu/bin/ld"
}
build_options = {
'load_runtime_module': export_rt_mod_file
}
with tvm.transform.PassContext(opt_level=3, config={'relay.ext.vitis_ai.options': build_options}):
lib_edge_dpu = relay.build(mod, tvm_target, params=params)
lib_edge_dpu.export_library('lib_dpu.so', **lib_kwargs)TVM Vitis-AI Integration における TVM と PyXir を用いた DPU 向けの実行モジュールのコンパイルフローを図示すると、以下のように表すことができます。
物体検出ネットワークの性能評価
物体検出ネットワークについて、TVM Vitis-AI Integration を用いて Ultra96 向けにコンパイルし性能評価を行いました。同じネットワークを Raspberry Pi4 と Jetson Nano 向けにも TVM を用いてコンパイルし、実行時間を比較しました。
実行時間には画像の前処理は含まれておらず、後処理については含まれています。Ultra96 の実行時間については、カッコ内はモデルの実行時間のうち、DPU にオフロードされた部分の実行時間を表しています。
| Network | Input Size | Ultra96 [ms] | Raspberry Pi4 int8 [ms] | Jetson Nano fp16 [ms] |
|---|---|---|---|---|
| ssd_mobilenet_v1_coco | 300×300 | 34.32 (23.12) | 112.63 | 26.37 |
| ssd_mobilenet_v2_coco | 300×300 | 55.92 (44.79) | 218.52 | 34.67 |
| ssdlite_mobilenet_v2_coco | 300×300 | 35.60 (26.02) | 95.10 | 30.12 |
| ssd_mobilenet_v3_small_coco | 320×320 | 86.12 (2.40) | 35.68 | 21.86 |
| ssd_mobilenet_v3_large_coco | 320×320 | 244.75 (2.48) | 80.21 | 33.41 |
Ultra96 での実行時間は全体的に Raspberry Pi4 よりも高速ですが、Jetson Nano よりは遅い実行結果となりました。
今回使用した DPU-PYNQ イメージには DPU B1600 が搭載されていますが、FPGA のリソース使用率に余裕があるため、より並列度の高い B2304 を使用するとより高速化されることが見込まれます。
また、ssd_mobilenet_v3については Ultra96 での実行時間は Raspberry Pi4 よりも大きくなっています。
CPU での処理は、Ultra96 では Cortex-A53 上で fp32 精度で、Raspberry Pi4 では Cortex-A72 上で int8 精度で実行されます。 Ultra96 では、グラフ分割の結果、推論処理のうち DPU にオフロードされた部分はごくわずかで、ほとんどが CPU で実行されるようになっています。 Raspberry Pi4 がより性能の優れた CPU を搭載していることと、int8 精度での推論処理が fp32 精度よりも軽いことから、Ultra96 よりも高速に推論処理が実行されていると考えられます。
まとめ
本記事では TVM Vitis-AI Integration を用いて Ultra96V2 向けの実行モジュールを生成し,TVM の RPC リモート実行機能を用いて resnset18 による推論処理を実行しました。さらに物体検出ネットワークの性能評価を行いました。
次回は Xilinx の Kria KV260 上で TVM Vitis-AI Integration を実行します。
株式会社フィックスターズ エンジニア 新田泰大