
第4回目のこの記事では、ART 法の並列計算をマルチ FPGA に展開するために、第2回目の記事で紹介した宇宙物理アプリケーションの支配的な処理である ART 法の FPGA アクセラレータに、前回の記事で紹介した OpenCL プログラミングを用いた並列 FPGA 処理システムである CIRCUS をどのように適用するかを紹介します。
ART 法アクセラレータをマルチ FPGA 上に実装
概要
第2回目の記事のおさらいですが、ART 法の実装は複数の PE を Channel で接続した構成をしています。各 PE が Channel を介してレイデータを相互に通信し、レイデータを受信した PE で ART 法の演算カーネル (第1回の記事参照) を実行し、レイの進行方向に位置する次の問題空間を担当する PE に演算カーネルの結果を反映したレイデータを送信することによって、 ART 法のレイトレーシングアルゴリズムが実現されます。そして大事なのは、全ての PE はクロック単位で同時並列的にパイプライン動作するので、1 FPGA に実装される ART 法アクセラレータは、時間並列性 (パイプライン並列) および空間並列性を活用し、ART 法の実効性能を最大化できることでした。
今日の本題である ART 法アクセラレータをマルチ FPGA 上に実装するとは、PE 間のチャネル接続をこれまでに開発した FPGA 間通信技術である CIRCUS を用いて異なる FPGA 間に拡張することです。つまり、複数の FPGA を組み合わせることで巨大な PE クラスタを構築している、ということです。以下に 2 FPGA 上に実装された ART 法アクセラレータの概要図を示します。
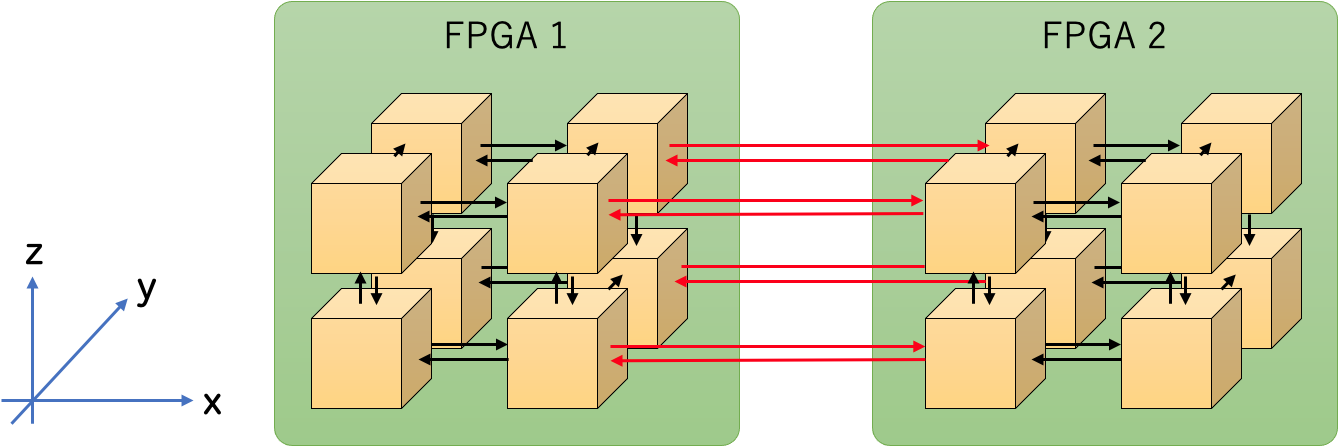
論文の執筆時は X および Y 次元方向のみ CIRCUS 通信に対応する実装でしたが、現在、Z 次元にも並列化可能なように開発中です。また、これまでの研究で動作実績のあった 512 bit 幅の CIRCUS Channel で通信を記述しています。レイデータは 312 bit の大きさを持つ構造体ですが、それに 200 bit のゼロパディングを挿入することで 512 bit の大きさの構造体を定義し、それを通信しています。この論文ではマルチ FPGA による並列計算が可能なことを示すことが目的の一つであったため、通信の動作安定性を重視した設計・実装を採用しましたが、今後は通信の最適化を実施する予定です。
擬似コード
通信に用いる Channel (CIRCUS Channel) の要求 (名前・データ型・数量など) はアプリケーション毎に異なります。したがって CIRCUS フレームワークでは、アプリケーションに必要な通信構造を XML ファイルに定義し、コードジェネレータがそのファイルからCIRCUS カーネルを生成し、アプリケーションの OpenCL コードから、自動生成された CIRCUS カーネルを #include して、1 つの FPGA 回路を作成するのでした。
CIRCUS を適用した PE の中身を見ていきましょう。以下に (x, y, z) = (0, 0, 0) に位置する PE の擬似コードを示します。x– (x_neg) の方向へのアクセスは CIRCUS 経由で行い、それ以外の次元は内部 Channel へのアクセスとなっていることが分かると思います。
#pragma OPENCL EXTENSION cl_intel_channels : enable
// CIRCUS カーネルをインクルード
#include <circus.h>
channel rt_ch[6][NPE_X][NPE_Y][NPE_Z];
// CIRCUS Channel
channel extout_x_neg_x0_y0_z0;
channel extin_x_neg_x0_y0_z0;
// PE が保持するメッシュ空間
#define PE_MESH_SIZE (16 * 16 * 16)
// 1 つの面に 1 入力 / 1 入力 あるので、12 本のチャネルが必要
#define PE_INPUT_X_POS rt_ch[1][1][0][0]
#define PE_INPUT_X_NEG extin_x_neg_x0_y0_z0
#define PE_INPUT_Y_POS rt_ch[3][0][1][0]
#define PE_INPUT_Y_NEG rt_ch[2][0][1][0]
#define PE_INPUT_Z_POS rt_ch[5][0][0][1]
#define PE_INPUT_Z_NEG rt_ch[4][0][0][1]
#define PE_OUTPUT_X_POS rt_ch[0][0][0][0]
#define PE_OUTPUT_X_NEG extout_x_neg_x0_y0_z0
#define PE_OUTPUT_Y_POS rt_ch[2][0][0][0]
#define PE_OUTPUT_Y_NEG rt_ch[3][0][0][0]
#define PE_OUTPUT_Z_POS rt_ch[4][0][0][0]
#define PE_OUTPUT_Z_NEG rt_ch[5][0][0][0]
__kernel void PE_x0_y0_z0(...) {
// メッシュ空間のデータ (光学的厚みと source function) を格納する配列に Block RAM を利用する
__local struct radiation_mesh rmesh[PE_MESH_SIZE];
// メッシュにおける光学的厚み、メッシュの source function を格納
set_radiation_mesh(rmesh);
// 768 x N^2 の全てのレイに対してレイトレーシングを実行 (N = 16)
bool exit = false;
while (!exit) {
bool x_neg;
bool x_pos;
bool y_neg;
bool y_pos;
bool z_neg;
bool z_pos;
// レイの入力判定
INPUT_COND(x_neg);
INPUT_COND(x_pos);
INPUT_COND(y_neg);
INPUT_COND(y_pos);
INPUT_COND(z_neg);
INPUT_COND(z_pos);
// 隣接 PE から入力がある場合、レイデータを受信する
if (x_neg) ray = read_channel_intel(PE_INPUT_X_NEG);
else if (x_pos) ray = read_channel_intel(PE_INPUT_X_POS);
else if (y_neg) ray = read_channel_intel(PE_INPUT_Y_NEG);
else if (y_pos) ray = read_channel_intel(PE_INPUT_Y_POS);
else if (z_neg) ray = read_channel_intel(PE_INPUT_Z_NEG);
else if (z_pos) ray = read_channel_intel(PE_INPUT_Z_POS);
// ART 法の演算カーネルを実行 (輻射強度の計算)
calc_intensity(&ray, rmesh);
bool x_neg_out;
bool x_pos_out;
bool y_neg_out;
bool y_pos_out;
bool z_neg_out;
bool z_pos_out;
// レイの出力判定
OUTPUT_COND(x_neg_out);
OUTPUT_COND(x_pos_out);
OUTPUT_COND(y_neg_out);
OUTPUT_COND(y_pos_out);
OUTPUT_COND(z_neg_out);
OUTPUT_COND(z_pos_out);
// レイの次の計算領域が隣接 PE の保持するメッシュ空間である場合、レイデータを送信する
if (x_neg_out) write_channel_intel(PE_OUTPUT_X_NEG, ray);
else if (x_pos_out) write_channel_intel(PE_OUTPUT_X_POS, ray);
else if (y_neg_out) write_channel_intel(PE_OUTPUT_Y_NEG, ray);
else if (y_pos_out) write_channel_intel(PE_OUTPUT_Y_POS, ray);
else if (z_neg_out) write_channel_intel(PE_OUTPUT_Z_NEG, ray);
else if (z_pos_out) write_channel_intel(PE_OUTPUT_Z_POS, ray);
// レイトレーシングの終了判定
CHECK_TERMINATION(exit);
}
}この擬似コードを見ると、第2回目の記事で紹介した擬似コードにほんの少しの修正を加えているだけであることが分かると思います。4 行目で自動生成された CIRCUS カーネルを #include し、9 および 10 行目で CIRCUS Channel をファイルスコープ変数として宣言、そしてそれらを示すマクロを定義しているのが違いとなります。ART 法アクセラレータの開発当初からマルチ FPGA に展開することを見据え、その実現に適したアーキテクチャを採用していたため、このような最小限の変更でマルチ FPGA 化を実現できました。
制限事項
論文執筆時の ART アクセラレータは開発中であったため、いくつかの制限事項があります。
- 各 PE が持つ計算用メモリ (BRAM) に収まる問題しか扱えない
- レイとメッシュが交わる距離が短い場合、計算が停止する可能性がある
- X および Y 次元の方向しか CIRCUS を用いた領域分割ができない
以前の実装である Arria 10 を用いた ART on FPGA の実装では、計算の進捗にあわせて BRAM と DDR メモリの間でデータを入れ替えることで、BRAM サイズに収まらない大きな問題を扱うことができました。しかし今回の実装では、CIRCUS を用いた並列計算の実現を優先したため、BRAM と DDR メモリを組み合わせる機能が実装できていません。計算データは開始時に DDR メモリから BRAM にロードし、完了後に DDR メモリに書き戻すのみです。
次は 2 番目の制限事項についてです。ART 法は直行格子上で平行光を扱うため、隣り合う並行レイ同士は、レイとメッシュが交わる距離は同じであり (第1回の記事参照)、進行する次元 (X, Y or Z) も同じです。ところが、レイとメッシュが交わる距離が短い場合、演算誤差によって、あるレイは X 次元方向に進むが、あるレイは Y 次元に進むという可能性があります。この条件が満たされると、FPGA 内の計算が破綻し、カーネルの実行が完了しなくなってしまいます。そのため、今回の実装では、そのような条件が発生しないパラメータを設定して実験を行っています。
3 番目の制限事項 CIRCUS に関するものですが、それに加えて以下に示すような CIRCUSの通信機能に由来する制限が存在します。
- フロー制御が未実装
- エラー処理 (再送・訂正) が未実装
フロー制御がないことは並列計算を行う上で大きな障壁となります。これまでに行ってきた実験の範囲では、用いる FPGA の数が少ないため、通信路内部にあるバッファが溢れず問題なく通信できています。しかし、多数の FPGA を用いる場合、FPGA ごとの計算進捗の差が大きくなりバッファが溢れ通信が破綻する可能性があります。これらの実装も我々が向き合わなければならない課題です。
まとめ
この記事では、ART 法アクセラレータに CIRCUS を適用し、ART 法の並列計算をマルチ FPGA に展開していきました。次回の記事では、ART 法の FPGA アクセラレータの性能が FPGA の台数に応じてどのようにスケーリングしていくかを評価していきます。いよいよ最終回ですので、最後までお読み頂けると幸いです。どうぞお楽しみに。
筑波大学 計算科学研究センター 小林諒平