
自作回路を PYNQ から使うための設計・開発法に関するコースの最終回になります。今回の設計も、対象のアプリケーションがステンシル計算であること、IP コアがフル機能の AXI をもつ場合を取り上げることは変わりません。異なるのは、IP コアを Vitis HLS (2019.2 以前の Vivado では Vivado HLS とよばれていました) による高位合成で作成する点です。
本コースで使用したハードウェア記述 (一部ソフトウェアも含む) は、GitHub リポジトリ上で公開しています。今回のハードウェア (PL) 部分は高位合成で作成しますので、ソースコードは C 言語で記述されたものになります。
HLS 版ステンシル計算コプロセッサ
入出力インタフェースに関するディレクティブ
高位合成 (High Level Synthesis) は、C 言語などのプログラミング言語の記述を RTL (Register Transfer Level) の回路記述へと変換する技術です。Xilinx 社の FPGA 向けには、同社が開発している HLS ツールである Vitis HLS が利用できます。当然ながら、同社のハードウェア開発環境である Vivado やソフトウェア開発環境である Vitis とも連携がしやすくなっています。
特に便利なのは、高位合成によって作成された回路を Vivado の IP コアとしてエクスポートする機能を持っていることです。これにより、エクスポートされた IP コアを Vivado でリポジトリに追加するだけで、回路をブロック図に追加できます。
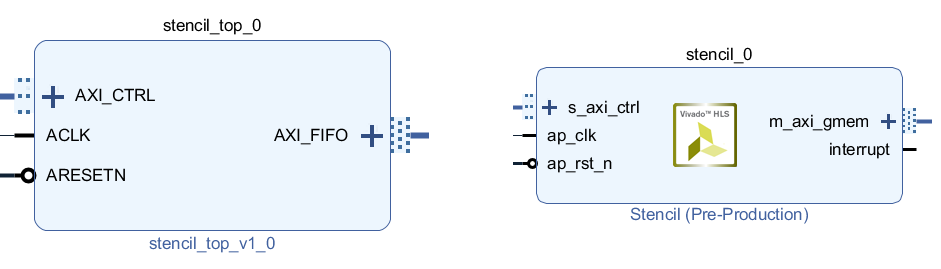
前回使用した (RTL で設計された) ステンシル計算コプロセッサの IP コアと、今回作成する HLS 版ステンシル計算コプロセッサの IP コアとを並べたものを、下図に示します。プロセッサとの連携を考えれば、HLS で作成された回路にもやはり AXI や AXI-Lite のインタフェースを持たせるのが便利です。そうすれば、IP コアを RTL で設計したときと同じ要領で扱えます。
(注: HLS 版では、割込み要求をプロセッサに通知するための出力が追加されているので、左右のブロックの入出力は厳密には一致していません)
高位合成で作成される回路の入出力インタフェースをどうすべきかは、C 言語で記述できる範囲を超えています。そこで、プラグマ (pragma) という仕組みを使って、Vitis HLS に回路をどう合成するかの指令 (ディレクティブ) を与えます。具体的には、#pragma HLS から始まる行を C 言語のソース中に挿入すると、Vitis HLS はソースを RTL 記述へと「コンパイル」する前にその内容を読み取り、必要な対応をしてくれます。#include や #define も # から始まりますが、これらと同じ枠組みです (# から始まる行をプリプロセッサ指令といいます)。
回路の入出力インタフェースを定めるには、関数やその引数に対して INTERFACE ディレクティブを追加します。以下に、N x N サイズ (N は定数) の入出力配列 src, dst に対して1回分のステンシル計算を行う関数 stencil に対して、AXI や AXI-Lite を使うように INTERFACE ディレクティブを加えた場合の記述例を示します。
void stencil (unsigned int src[N][N], unsigned int dst[N][N])
{
#pragma HLS INTERFACE s_axilite port=return bundle=ctrl
#pragma HLS INTERFACE s_axilite port=src bundle=ctrl
#pragma HLS INTERFACE m_axi port=src offset=slave bundle=gmem depth=262144
#pragma HLS INTERFACE s_axilite port=dst bundle=ctrl
#pragma HLS INTERFACE m_axi port=dst offset=slave bundle=gmem depth=262144プラグマが5つ並んでいます。このうち s_axilite を含む3行は、それぞれ回路の制御 (return、7行目)、配列 src のアドレス (8行目)、dst のアドレス (10行目) を AXI-Lite によってやりとりすることを意味しています。残りの2行では、配列 src のデータ (9行目)、dst のデータ (11行目) を PS のメモリから読み書きするのに、フル機能の AXI (m_axi) を使うことを宣言しています。
なお、前者には bundle=ctrl、後者には bundle=gmem と記述されていますが、これはインタフェースをそれぞれ1つ (ctrl, gmem) にまとめるための指示です。これがないと、インタフェースが別々に生成されてしまいます。offset=slave は、配列のアドレスを AXI-Lite で受け取るため、つまり8~9行目、10~11行目をそれぞれ結びつけるための指示です。depth=262144 の数字部分には、送受信される配列の要素数の最大値を指定します。depth の値にかかわらず正しい回路は生成できるのですが、後述する協調シミュレーションを正しく行うためには、適切な depth が設定されている必要があります。
C 言語によるコプロセッサの設計
関数や引数にディレクティブを与えることで、生成される回路の外見 (入力と出力) を定めることができました。中身、つまり入力と出力との関係についても簡単に説明します。
実際のところ、単に C 言語で書いたプログラムをそのまま高位合成しても、まともな性能は期待できません。データの流れ (データパス) をしっかり設計して、それに沿った C 言語のコードを書く必要があります。あくまでも記述しているのはハードウェアであって、ハードウェアは本質的にデータ主導で動くもの、ということを頭に置いておくのが大切です。このあたりの詳しいことは、「高位合成で加速するアクセラレータ開発」のコースでも説明されています。
ステンシル計算においてデータの流れをどう構築するかは、すでに「AXI でプロセッサとつながる IP コアを作る (5)」の記事で説明しています。この方針をもとに、レジスタや FIFO のかわりにローカル配列に中間結果を保存する形で、C 言語による記述を行います。
以下に、データパスを意識して書き直したステンシル計算の C 記述の例を示します。
unsigned int in_data, hsum, vsum;
unsigned int hbuf[2], vbuf[2][N];
int x, y;
for (y = 0; y < N; y++) {
for (x = 0; x < N; x++) {
#pragma HLS PIPELINE
in_data = src[y][x];
// 横3要素の和を求める
hsum = hbuf[0] + hbuf[1] + in_data;
hbuf[0] = hbuf[1];
hbuf[1] = in_data;
// 縦3要素分について,求めた和の合計を求める
vsum = vbuf[0][x] + vbuf[1][x] + hsum;
vbuf[0][x] = vbuf[1][x];
vbuf[1][x] = hsum;
// 外周でなければ,9で割ってから書き込み
if (x == 5 && y == 5) {
dst[y-1][x-1] = 0x0fffffff; // (4, 4) はホットスポット
} else if (x >= 2 && y >= 2) {
dst[y-1][x-1] = vsum / 9;
}
}
}
}データの読み出し・書き込みは、左上の要素から右下の要素へと、各要素につき1度だけ行います。これにより回路内部では、
- 直近2要素のデータと、
- 列方向に隣接する3要素を足し合わせた和を直近2行分
記憶しておく必要がありました。そのために、それぞれ配列 hbuf と vbuf を定義しています。9要素分のデータの足し合わせが終わったら、それを9で割った値を出力配列へと書き込んでいます (外周および (4, 4) の要素を除く)。
18行目に #pragma HLS が再び現れていますが、これは対応する for 文をパイプライン方式で並行実行することを指示する1文です。
ここで行われている最適化は、おおむね「高位合成で加速するアクセラレータ開発 (2)」の「鉄則5」で挙げられている例と同様です。ただ、上記の記事とは異なり、専用のライブラリは使用しない書き方をしています。また、高位合成に向けた最適化の例として、Xilinx のユーザガイド UG1270 の4~5章で挙げられている例も参考になります。上記の C 言語による記述も、このガイドの手法を簡略化することで作成しました。
Vitis HLS による IP コアの作成
それでは、Vitis HLS を使って、作成した C 言語の関数をハードウェアに変換してみましょう。Vitis HLS を起動して、File → New Project で新規のプロジェクトを作成します。まず、プロジェクト名とプロジェクト保存先を指定します。プロジェクト保存先として指定したディレクトリ上に、プロジェクト名と同じ名前のフォルダが作成されます。プロジェクトのファイル一式はそのフォルダに保存されます (Vivado と同じ要領です)。以下、プロジェクト名は HLS_project に指定したものとして説明します。
次に、ソースファイルを指定します。ここでは、GitHub リポジトリの stencil_hls/C_source ディレクトリ上にある、stencil.c を Design Files として、stencil_test.c を Testbench Files として、それぞれ追加します。
最後に、プロジェクト上に作成されるソリューションの設定画面が表示されます。ここでは使用するパーツを Boards → PYNQ-Z1 に変更します。複数のソリューションを使うと、異なる設定で高位合成を行って結果を比較するなどの機能が使えますが、今回は単一のソリューションで作業を進めます。
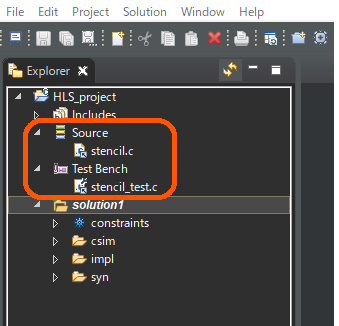
以上の設定でプロジェクトを作成すると、Vitis HLS の画面左上の Explorer タブに、下図に示す画面が表示されます。Sources の中に stencil.c が、Test Bench の中に stencil_test.c があることを確認します。
念のため C 言語としての検証をしてから、高位合成に進みます。まず、メニューの Project → Run C Simulation で一連のコードが C 言語として正しく実行できるかを確認します。問題がなさそうなら、メニューの Solution → Run C Synthesis で高位合成を行います。高位合成に成功すると、合成結果の概要が表示されます。
合成結果の詳細なレポートを確認しておきます。プロジェクトの Solution1/syn/report ディレクトリの中に stencil_csynth.rpt というファイルが作成されていますので、これを Explorer タブ内でダブルクリックすると、詳細な合成結果レポートが表示されます。合成結果レポートの一例を下図に示します。
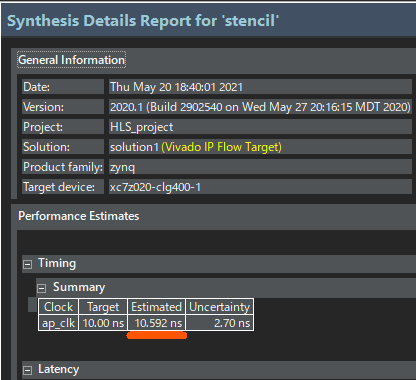
……おっと、クロック周期の見積もり (図中の Estimated) が目標 (Target) を超えてしまっていますね。この回路は 100 MHz (周期 10 ns) では動作しない可能性があります。とはいえ、あくまでもこれは Vitis HLS による見積もりですので、実際に回路を Vivado で合成してみると、タイミング制約を満たす (MET する) 場合も多いです。ひとまず、そうなることを信じて先に進みましょう。
その下にはレイテンシ (関数の実行にかかるクロックサイクル数) の見積もりも表示されます。手元の環境では 262,165 サイクルと表示されました。今は配列の要素数を 512 x 512 = 262,144 としていますから、1要素をおおむね1サイクルで処理する回路になっているようです。
レポートを下までスクロールすると、入出力ポートの一覧、つまりどのようなインタフェースが入出力として生成されたかを確認できます。その一部を下図に示します。
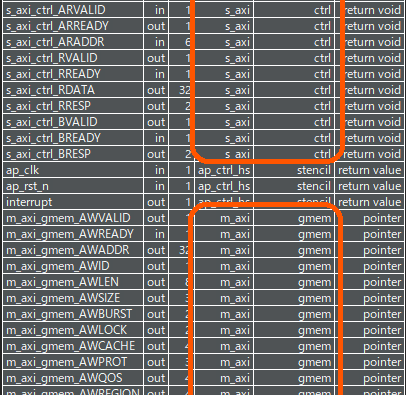
ここでは、ctrl というサボーディネイト (リクエストを受ける) 側の AXI インタフェースと、gmem というマネージャ (リクエストを発行する) 側の AXI インタフェースが作成されていることが確認できます。先ほどディレクティブで指定した通りですね。
こうしたレポートを確認して (時にはさらに詳細な解析を行って)、想定した回路が得られていそうであることが確認できたら、C 言語のテストベンチと高位合成で得られた回路とを組み合わせた協調シミュレーション (C/RTL Cosimulation) を行います。協調シミュレーションに関する詳細はここでは割愛しますが、今回のステンシル計算コプロセッサに対して協調シミュレーションを行う際には、配列サイズや繰り返し回数は適度に小さくしておくことをおすすめします。協調シミュレーションは回路の論理シミュレーションを伴うため、それなりの時間とメモリ容量を必要とするからです。
最後に、作成された回路を Vivado で使える形にエクスポートします。メニューの Solution → Export RTL を選択すると、下図に示すダイアログが表示されます。
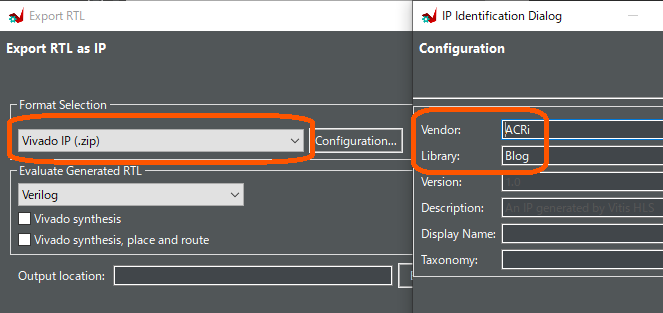
Format Selection が Vivado IP (.zip) になっていることを確認します。その横の Configuration ボタンを押すと、別のダイアログが出現し、そこで IP コアのベンダー名などを設定できます。今回は、第2回のときと同様に、ベンダー名を ACRi、ライブラリ名を Blog としておきましょう。コア名は C 言語の関数名と同じ名前に設定されます。したがって、生成される IP コアの正式名称は、ACRi:Blog:stencil:1.0 となります。
最後に OK ボタンを押すと、エクスポートが実行されます。エクスポートされた IP コアのファイル一式は、プロジェクトの Solution1/impl/ip ディレクトリに置かれます。また、このディレクトリの中身を zip 形式で圧縮したものが、Solution1/impl/export.zip として保存されます。
オーバーレイの作成
ここからは Vivado 上での作業です。今回は、作成した IP コアのディレクトリをユーザリポジトリに登録してから作業します。プロジェクトが作成できたら、IP リポジトリの設定を開き、先ほどのディレクトリ (プロジェクトの Solution1/impl/ip) を追加します。IP リポジトリの追加についての詳細は、「IP の世界からこんにちは (3)」を参照してください。
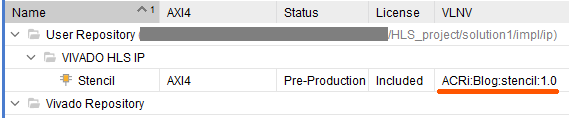
登録後に「Project Manager → IP Catalog」で IP カタログを開くと、ユーザーリポジトリに VIVADO HLS IP というカテゴリが追加され、その中に先ほど作成した IP コアの存在を確認できます。このときの様子を下図に示します。正式名称 (VLNV) が指定した通り ACRi:Blog:stencil:1.0 となっていることも確認できます。
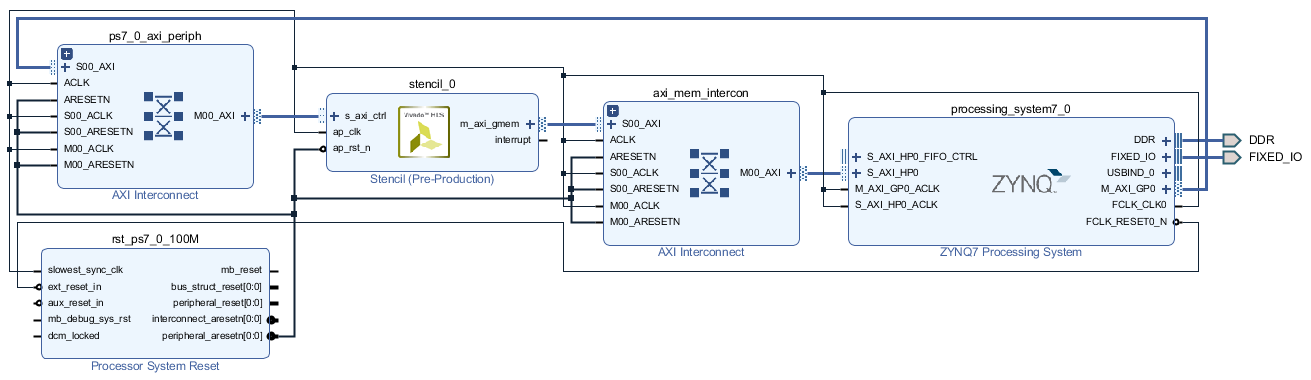
ブロック図の作成、あるいはそれ以降の Vivado での作業の要領は、「AXI でプロセッサとつながる IP コアを作る (5)」と同様です。PS 部の追加、Block Automation、PS の HP ポートの有効化、ステンシル計算コプロセッサの追加、Connection Automation の順で進めます。完成したブロック図の例を下図に示します。
※ 手元の環境では、このブロック図をもとに Vivado で論理合成したところ、無事タイミング制約を満足 (MET) しました。
最終的に .bit ファイルが作成できたら、.bit ファイルと .hwh ファイルを抽出してからファイル名を修正し、PYNQ の所定の場所にアップロードします。
PYNQ 上での動作確認と評価
レジスタマップを用いる場合
ようやく本題にたどり着きました。ここからは PYNQ 上でのプログラミングについて説明します。プログラムのメイン部分はほぼ第4回と同様ですが、コプロセッサを起動するメソッドの定義に少し変更が必要となります。
Vitis HLS で IP コアを作成した場合、PYNQ では register_map という (RegisterMap クラスの) インスタンスを通じて、メモリマップされたレジスタにアクセスできます。Vitis HLS で作成された IP コアのメモリマップに関する情報は .hwh ファイルの中に書かれているのですが、PYNQ のライブラリはそれを自動的に読み取って、各レジスタに名前でアクセスできる手段を提供してくれているのです。
実際に IP コアの register_map を表示させてみれば、IP コアが備えるメモリマップされたレジスタの一覧 (レジスタマップ) が確認できます。ステンシル計算コプロセッサの場合の例を下図に示します。
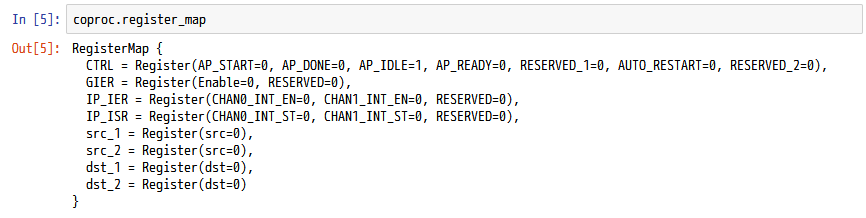
IP コアの制御に関するレジスタは CTRL にまとめられています。このうち、コアの起動を指示するには AP_START、コアが終了したかを確認するには AP_DONE を使います。配列 src, dst のアドレスに対応するレジスタは2つずつ (src_1, src_2 および dst_1, dst_2) 確認できます。これは、ポインタが64ビット長である環境もあるためです。PYNQ ではポインタは32ビット長ですので、src_1, dst_1 だけを使います。
これらのレジスタマップを使用して記述された、コプロセッサの起動・終了待ちのためのコードを以下に示します。
def stencil_hard1(src, dst, coproc):
coproc.register_map.src_1.src = src.device_address
coproc.register_map.dst_1.dst = dst.device_address
coproc.register_map.CTRL.AP_START = 1
while coproc.register_map.CTRL.AP_DONE == 0:
passやっていることは前回と変わりませんが、少しばかり読みやすくなっており、コードの行数も減っています。AP_START や AP_DONE は読み書きのあと自動的に 0 に戻るように回路が組まれています。そのため、ソフトウェア側で AP_START を 0 に戻したり、AP_DONE が 0 に立下がるのを確認する必要はありません。便利です。
今回も、時間測定のコードを挿入して、実行結果を確認してみます。手元の PYNQ-Z1 で得られた結果を下図に示します。
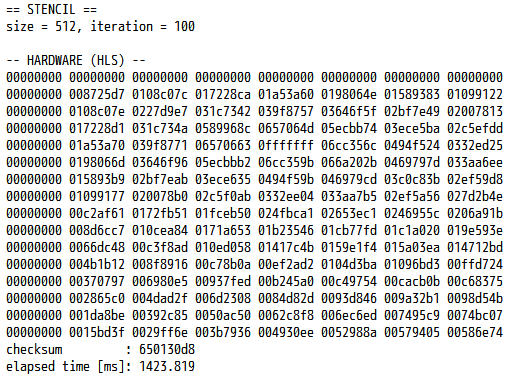
チェックサムは 650130d8 で、これまでの結果と一致しています。気になる実行時間は、およそ 1,423 ミリ秒となりました。前回と比べると、SciPy を用いたソフトウェア実装よりは12.2倍高速である一方、RTL で記述した場合よりは5倍ほど低速という結果になりました。まだ若干高速化の余地はあるのでしょうが、まずまずでしょう。
メモリマップされたレジスタを直接読み書きする場合
もちろん、前回と同じように、read や write を使ってメモリマップされたレジスタを直接読み書きすることもできます。この場合は、自力でのアドレスの確認が必要です。
アドレスの確認にはいくつか方法がありますが、IP コアの作成時に自動生成される C 言語のドライバのソースコードを読む方法がわかりやすいです。ドライバのソースコードは、IP コアのディレクトリ (プロジェクトの Solution1/impl/ip) の下の、drivers/stencil_v1_0/src にあります。その中の xstencil_hw.h の冒頭に、レジスタマップがコメントの形で記載されています。
ステンシル計算コプロセッサのレジスタマップのうち、コプロセッサの制御に必要なものを抜き出してまとめたものを、下表に示します。
| アドレス | ビット | 方向 | 概要 |
|---|---|---|---|
| 0x00 | 0 | R/W | コプロセッサの動作開始 (AP_START) |
| 1 | R | コプロセッサが動作終了したか (AP_DONE) | |
| 7 | R/W | 動作終了後に自動で繰り返すか | |
| 0x10 | 31-0 | R/W | src のアドレス (下位32ビット) |
| 0x14 | 31-0 | R/W | src のアドレス (上位32ビット) |
| 0x1C | 31-0 | R/W | dst のアドレス (下位32ビット) |
| 0x20 | 31-0 | R/W | dst のアドレス (上位32ビット) |
アドレス 0x00 番地 (CTRL) は、複数のレジスタを束ねて1つのレジスタとしています。そのため、ある特定のビットだけを操作したい場合は、他のビットの値を誤って上書きしてしまわないよう注意が必要です。
メモリマップされたレジスタを直接操作する形で記述された、コプロセッサの起動・終了待ちのためのコードを以下に示します。
def stencil_hard2(src, dst, coproc):
coproc.write(0x10, src.device_address)
coproc.write(0x1C, dst.device_address)
ctrl = coproc.read(0x00)
coproc.write(0x00, (ctrl & 0x80) | 0x01)
while (coproc.read(0x00) & 0x02) == 0:
passAP_START を操作するときには、7ビット目に存在する繰り返しのフラグを上書きしてしまわないよう、注意が必要です。具体的には、4行目で一度レジスタの値を読み取ってから、5行目で7ビット目の値を保持 (0x80 を AND) しつつ、AP_START にあたる0ビット目を ‘1’ に (0x01 を OR) しています。また、6行目で AP_DONE の値を調べるときには、1ビット目だけを抽出 (0x02 を AND) しています。
こちらのプログラムも、同様に手元の PYNQ-Z1 で動作確認を行ってみました。その結果を下図に示します。
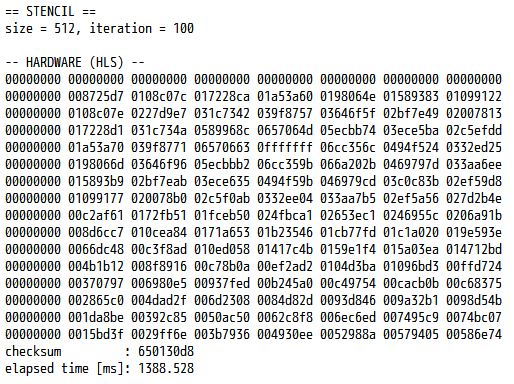
当たり前といえばそうですが、チェックサムは一致しています。実行時間は 2.4 % ほど短縮されて、約 1,389 ミリ秒となりました。先ほど紹介したレジスタマップを使う方法は、お手軽ではあるものの、それなりのオーバーヘッドがあるとみて良さそうです。性能とコードのわかりやすさを両立したいなら、第2回と同じようにドライバクラスを作成した方が良いかもしれません。
まとめ
今回は、高位合成で作成した回路を PYNQ に接続する例を示しました。この場合、Python 側では register_map のインスタンスを使うことでお手軽に回路を制御できる一方、性能面では注意が必要そうだというのが、今回のまとめになります。
このコースでは、回ごとに異なる以下の想定のもと、自作回路を PYNQ から使う方法をそれぞれ確認してきました。
- AXI インタフェースをもたない回路の場合
- 制御用の AXI-Lite インタフェースのみもつ回路の場合
- 2に加えて、データ用に AXI-Stream インタフェースをもつ回路の場合
- 2に加えて、データ用にフル機能の AXI インタフェースをもつ回路の場合
- Vitis HLS による高位合成で作成された回路の場合
各回は同時に PYNQ 上で動作する回路の設計例の紹介にもなるよう、回路そのものの設計にもある程度の分量を割きました。まずはよくあるパターンをしっかり定着させるのが、設計力をつける近道かと思います (芸術の世界では「守破離」と言いますね)。このコースで挙げたいくつかの事例が、読者の皆さんの作りたいものに向けた参考となるよう祈っています。
愛知工業大学 藤枝直輝