AXI を使ってプロセッサと連携する回路の設計例について説明するコースも、いよいよ最終回となりました。今回は、前回作成したインタフェース変換回路を使い、専用計算回路 (コプロセッサ) の一例としてステンシル計算コプロセッサを作成し、C 言語によるソフトウェア実装と性能を比較してみます。
なお、第4回~第5回で使用する回路の SystemVerilog 記述は、GitHub からダウンロードできるようにしています。今回は、主に stencil/hdl/stencil_opt.sv を取り上げます。
また、本記事で紹介するステンシル計算コプロセッサは、2014年の情報科学技術フォーラム (FIT2014) のイベントとして開催された、高性能コンピュータシステム設計コンテストに提出した設計の一部を SystemVerilog に移植したものです。
ステンシル計算コプロセッサ
計算の定義
今回は、ハードウェアで計算を高速化する対象として、2次元ステンシル計算を取り上げます。ステンシル計算は、配列の自要素とその周辺要素の値をもとに、自要素の値を更新する、という計算を繰り返すものです。このようなタイプの計算は、流体シミュレーションや画像処理などで典型的にみられます。
今回扱うステンシル計算は、以下の通り定義します。
- 配列は N x N の2次元配列
- 配列の各要素は 32 bit の符号なし整数
- 自要素の新しい値は、自要素とその近傍8要素の値の平均値 (端数切捨て) とする
- 外周要素は0で固定とする
- (4, 4) 要素は
0x0fffffffで固定とする - 配列のいくつかの要素には、初期値として決まった値が書き込まれているとする
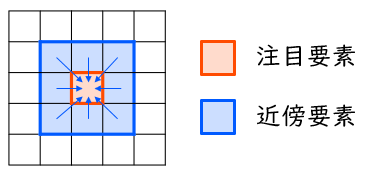
下図に、注目要素とその近傍要素を図示します。平均をとる対象となるのは、注目要素からの X・Y 座標の差がともに ±1 に収まっている要素 (注目要素そのものを含む) です。
C 言語で記述した場合には、例えば以下のソースコードのように表現できます。なお、このコードは、stencil.c の47行目以降にあります。後でプロセッサ (PS) 上のソフトウェア処理の関数として使用します。
void stencil_soft (unsigned int src[][N], unsigned int dst[][N])
{
int x, y;
for (y = 1; y < N - 1; y++) {
for (x = 1; x < N - 1; x++) {
dst[y][x] = (src[y-1][x-1] + src[y-1][x] + src[y-1][x+1] +
src[y ][x-1] + src[y ][x] + src[y ][x+1] +
src[y+1][x-1] + src[y+1][x] + src[y+1][x+1]) / 9;
}
}
dst[4][4] = 0x0fffffff;
}
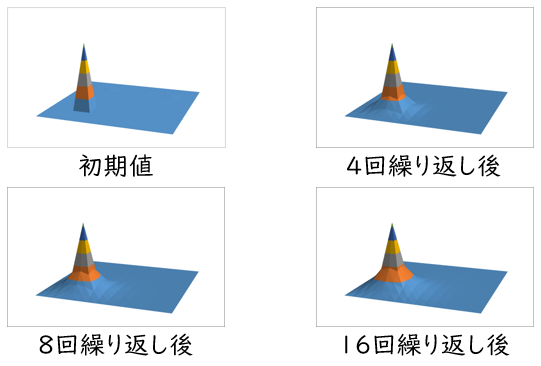
この計算を複数回繰り返した後の、配列の値の変化の様子の例を下図に示します。(4, 4) 要素がホットスポット (固定値) になっているため、その周辺の要素の値も、計算を繰り返すたびにじわじわと大きくなっています。
コプロセッサ本体の設計
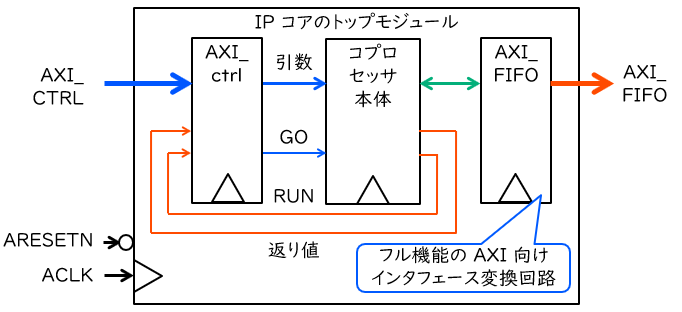
上図に、第4回で示した典型的なコプロセッサ IP コアの構成図を再掲します。 計算を行うときのコプロセッサは、おおむね以下の手順で動作します。
- プロセッサは引数および動作開始の指令を AXI-lite のインタフェース回路 (AXI_ctrl) に書き込む。
- インタフェース回路は、引数や指令をコプロセッサに入力する。
- コプロセッサは動作中のフラグを ‘1’ にし、動作を開始する。
- コプロセッサは、どこからどの順番でデータを読み出すかを決定し、インタフェース変換回路 (AXI_FIFO) に読み出しリクエストを送る。
- インタフェース変換回路は AXI を通じてメモリにリクエストを送り、読み出されたデータを受け取る。
- コプロセッサは、読み出されたデータを加工して書き込みデータを生成するとともに、どこにどの順番でデータを書き込むかを決定する。
- コプロセッサは、インタフェース変換回路に書き込みリクエストを送る。
- インタフェース変換回路は AXI を通じてメモリにリクエストを送り、データを書き込む。
- 4~8 の手順を、処理が終了するまで同時並行的に繰り返す。
- コプロセッサでの処理が終了したら、コプロセッサは返り値を出力するとともに、動作中のフラグを ‘0’ にする。
- インタフェース回路を通じてプロセッサがそれらを読み取ると、計算が完了する。
これより、コプロセッサで行うべき仕事は、(1) コプロセッサ全体の動作制御、(2) データの読み出しアドレスの決定、(3) 読み出したデータをどう処理してから書き込むのか (演算パイプライン)、そして (4) データの書き込みアドレスの決定の4つに大別されることとなります。これらを順番に見ていきます。
コプロセッサ全体の動作制御
今回、引数と返り値、および動作制御に用いる信号は、下表に示す通り定義します。アドレスの列は、AXI-Lite でプロセッサからアクセスするとき、それがベースアドレス (基準) から何バイト目に位置するかを示します。R/W はプロセッサから書き込まれる (W) のか読み出される (R) のかを示します。なお、今回は返り値を使用しません。
| 種別 | 名前 | アドレス | R/W | 概要 |
|---|---|---|---|---|
| 制御 | GO | 0x0 | W | GO と DONE がともに ‘1’ のとき動作開始 |
| 引数 | SIZE | 0x4 | W | 配列サイズ N に相当 |
| 引数 | SRC | 0x8 | W | 入力配列へのポインタ |
| 引数 | DST | 0xc | W | 出力配列へのポインタ |
| 制御 | DONE | 0x0 | R | DONE が ‘1’ なら動作前、または動作終了 |
これらは AXI-Lite のインタフェース回路を通じて読み書きができるよう、AXI_ctrl.sv を適切に修正しておきます。詳しくは、第2回を参照してください。
コプロセッサは、GO と DONE がともに ‘1’ となったときに動作を開始します。したがって、記述の各所に、このとき引数の取り込みとレジスタの初期化を行うための記述が加わります。
例えば、stencil_opt.sv の 48~51 行目は、このあと説明する読み出しアドレスの決定部分の一部です。
if (DONE) begin
read_proceed = GO;
n_read_addr = SRC;
n_read_y = 16'd0;
end else begin
49行目の read_proceed は、読み出しアドレスの決定に関するレジスタを更新するかどうかを決める信号になっています。そのため、DONE と GO がともに ‘1’ になると、読み出しアドレス (read_addr) には最初に読み出すべき入力配列の先頭アドレスが入り、Y 座標のカウンタ (read_y) は0にリセットされます。
データの読み出しアドレスの決定
下図に、入力配列からのデータの読み出しの順序を示します。できる限りの高速化を達成するために、今回は単純に2次元配列全体を左上から順番に読み出すこととします。
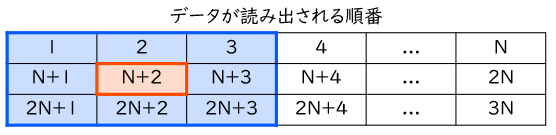
この場合、例えば (1, 1) 要素の値を求めたい場合には、青枠で示す9つのデータが必要になります。最初に必要なデータは1番目に読み出せますが、最後に必要なデータは 2N + 3 番目まで待たないと読み出されません。それまでの間、必要な情報は回路内部へと保存しておくことになります。
この読み出しアドレスの決定に関する記述は、36~72 行目にあります。その主要部分は、先ほどの続きの 52~59 行目です。
end else begin
read_proceed = READ_REQ & ~ READ_BUSY;
n_read_addr = READ_ADDR + N * 4;
n_read_y = read_y + 1'b1;
if (read_y == N - 1'b1) begin
read_last = 1'b1;
end
end
ここでは、各行のデータ (N 要素) を順番に読み出す制御をしています。1つ前の読み出しリクエストが受理されると、read_proceed が ‘1’ になります。このとき、読み出しアドレスを1行分 (N 要素分) 加算するとともに、Y 座標のカウンタをインクリメントします。もし Y 座標が最下段である N – 1 に達していれば、read_last を ‘1’ にします。これにより、READ_REQ が ‘0’ となり、読み出しリクエストの生成は停止します。
演算パイプライン
さて、先に述べた通り、各要素の新しい値を計算するには、途中経過をしばらく保存しておく必要があります。ここでも FIFO が役に立ちます。長さ N の FIFO を使えば、入力した値を最大 N サイクル (厳密には N 個のデータが読み出されるまで。以下同じ) 遅れで出力できます。
例えば (1, 1) 要素の計算を行う場合には、例えば以下の手順によって行えます。
- 1, 2, 3 番目に読み出されたデータを足し合わせ、その結果を記憶しておく
- N + 1, N + 2, N + 3 番目に読み出されたデータの和も同様に求め、記憶していた結果とその和を加算し、その結果を記憶しておく
- 2N + 1, 2N + 2, 2N + 3 番目に読み出されたデータの和とも同様に加算する
- これで総和が得られるので、総和を9で割ることで平均を求め、書き込みデータとする
以上の計算を実現する回路をブロック図で表現すると、下図に示すものになります。
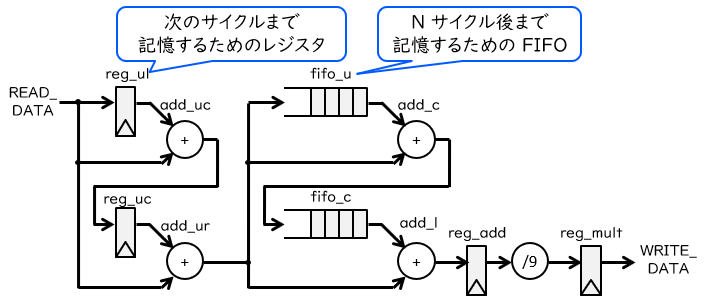
左側の2つのレジスタと加算器で、連続する3要素の加算を行います。その結果は中央の FIFO によりそれぞれ N サイクルの間保存され、N サイクル、2N サイクル後の連続3要素の和と足し合わされます。最後に、右側で9による除算を行い、それを書き込みデータとしています。
これらに関する記述は112行目以降に書かれており、記述全体の約6割を占めています。FIFO の読み書きや出力のタイミングをチェックするためにいくつかのカウンタ (add_x, add_y など) が用意されていますが、それ以外は基本的に上図に忠実に記述されています。
ただし、9による除算のみ、定数 0x38e38e39 による乗算と33ビットの右シフトに置き換えています。除算は組合せ回路で実現すると遅延が大きくなってしまい、実用的ではありません。一方で、乗算は除算よりも遅延は少なく済みますし、加えて FPGA では内部の信号処理 (DSP; Digital Signal Processing) ユニットを用いることで高速に演算できます。
データの書き込みアドレスの決定
最後に、これらの書き込み先アドレスを決定します。今回の仕様では、外周要素は0で固定になっています。外周要素に書き込むときに、計算した値のかわりに0を書き込むことは1つの解決法ですが、そもそも外周要素には書き込みを行わないのがスマートでしょう。
外周要素への書き込みを排除する場合、(1, 1) 要素を起点として、N – 2 要素書き込んで1行下に進む、を N – 2 行目まで繰り返すこととなります。これに対応する記述は 74~110 行目にあたります。また、そのうち主要部分は 86~97 行目です。
if (DONE) begin
write_proceed = GO;
n_write_addr = DST + 3'd4 + N * 4;
n_write_y = 16'd1;
end else begin
write_proceed = WRITE_REQ & ~ WRITE_BUSY;
n_write_addr = WRITE_ADDR + N * 4;
n_write_y = write_y + 1'b1;
if (write_y == N - 2'd2) begin
write_last = 1'b1;
end
end
基本的な考え方は読み出しの場合と同じです。ただし、書き込みアドレス (write_addr) の起点が (1, 1) 要素になっている (88行目)、Y 座標のカウンタが N – 2 に達したら書き込みリクエストを終了する (95行目) という点に違いが見られます。
シミュレーションによる動作検証
まずは、例によって作成したコプロセッサの動作をシミュレーションにより検証してみましょう……と、言いたいところですが、フル機能の AXI を含む回路を検証しようと思うと、テストベンチ内に AXI の信号を受け取る側、すなわちメモリ側の記述が必要です。このような機能を提供する擬似的な回路の機能モデルのことを BFM (Bus Functional Model) といいます。Xilinx はその1つとして AXI Verification という IP コアを用意しています。
ただ今回は簡易的な検証ということで、FPGA の部屋の marsee 氏によって開発されたオープンソースの BFM を使用することにします。これらのソース一式 (2個のファイル) を適当なテキストエディタに貼り付けて保存し、testbench ディレクトリに置きます。そして、hdl ディレクトリの全ファイルを Design Source(s) として、testbench ディレクトリの全ファイルを Simulation Source(s) として、それぞれプロジェクトに追加してから、シミュレーションを行います。
いくつかのシミュレーション結果を示します。まずは、コプロセッサの起動部分にかかるタイミングチャートを下図に示します。
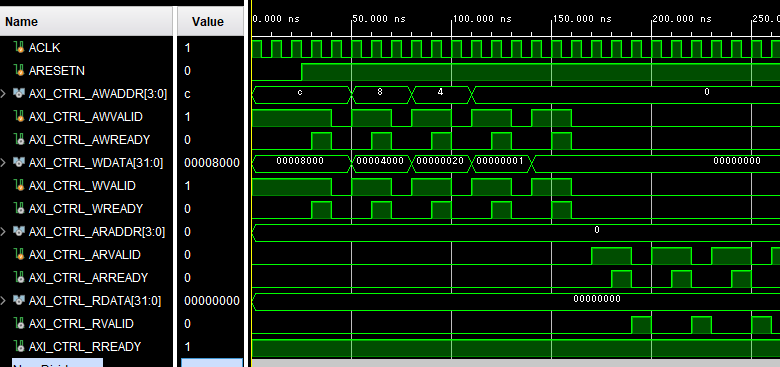
ここでは、引数および制御信号 GO への書き込みを、テストベンチ中に記載しています。AXI_ctrl を通じて、アドレス 0xc, 0x8, 0x4, 0x0 にそれぞれ 0x8000, 0x4000, 0x20, 0x1 を書き込んでいますので、引数 SIZE, SRC, DST はそれぞれ 0x20 (32), 0x4000, 0x8000 となります。あまり大きいサイズの配列だとシミュレーション時間もメモリへの負担もかかりますので、ここでは N = 32 としています。
それが終わったら、アドレス 0x0、すなわち DONE に対して繰り返し読み出しを行います。もし 1 が読み出せれば、DONE が ‘1’ になった、計算は終了したことを意味します。
この後、もう1度 GO を ‘1’ にして、2回目も同じように計算ができることを確認します。信号に初期化漏れがあるなどすると、2回目だけうまく動かなかったりしますので、注意が必要です。再び DONE が ‘1’ になったら、その時点でシミュレーションを終了します。
次に、コプロセッサ起動直後における AXI_FIFO 関連の信号のタイミングチャートを下図に示します。
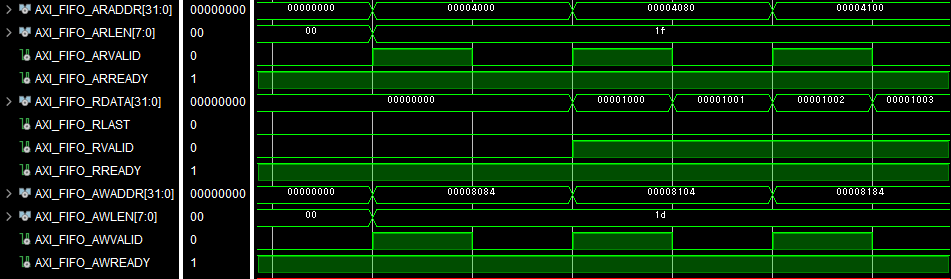
AR チャネルに注目すると、読み出しでは入力配列の (0, 0) 要素であるアドレス 0x4000 から、32要素 (AWLEN = 0x1f) の読み出しリクエストを順番に発行しています。一方、AW チャネルに注目すると、書き込みでは出力配列の (1, 1) 要素であるアドレス 0x8084 から、30要素 (AWLEN = 0x1d) の書き込みリクエストが発行されています。
このタイミングチャートからはまた、読み出されたデータが R チャネルに順番に流れてきていることも確認できます。なお、書き込みデータは早くても (2, 2) 要素が届いてから出ないと計算できませんので、これらが現れるのはもう少し後になります。
最後に、シミュレーション終了にかかるタイミングチャートを下図に示します。
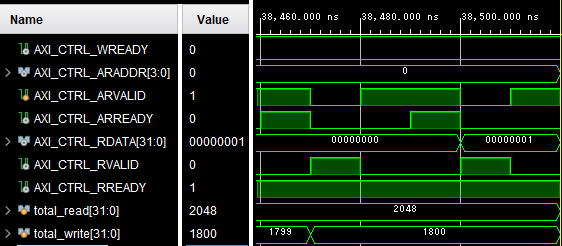
2度の計算を終え、DONE が再び ‘1’ を出力すると、AXI_ctrl の R チャネルに1が読み出されます。それを検知してシミュレーションが終了しています。テストベンチではこの間に AXI_FIFO で読み書きされたデータの要素数をそれぞれ total_read、total_write でカウントしています。
終了時点でのこれらの値 (10進数表記に変更しています) を確認すると、読み出しが 2,048 個で、書き込みが 1,800 個です。想定される読み書きの回数は、読み出しが 322 (全要素数) x 2 (計算回数) = 2,048、書き込みが 302 (外周以外の要素数) x 2 (計算回数) = 1,800 ですので、確かに一致しています。
Vivado/Vitis でのシステム構築と評価
IP コアの作成から論理合成まで
コプロセッサが無事正しく動作していそうなことが確認できたので、いつものように IP パッケージャで IP コア化し、IP インテグレータを用いてシステムへと組み込んでいきます。IP パッケージャの使い方は、「IP の世界からこんにちは」の第2回、IP インテグレータの基本的な使い方は、同コースの第4回を参照してください。
ここでは、IP コア一式のディレクトリを GitHub からダウンロードしたものとします。 PYNQ-Z1 または Arty Z7-20 を対象にプロジェクトを作成し、IP Repository として stencil ディレクトリを指定します。
IP カタログに stencil_top_v1_0 が正しく登録されていることを確認したら、Create Block Design でブロック図を新規作成し、Zynq の PS 部 (ZYNQ7 Processing System) を追加し、Run Block Automation を行い、その後で HP ポートを1つ有効化します (ここまでは第3回と同様の手順です)。
その後、stencil_top_v1_0 をブロック図に追加して、Run Connection Automation を行います。今回は AXI のほかに特別な信号があるわけでもないので、これでブロック図は完成です。完成したブロック図の例を下図に示します。
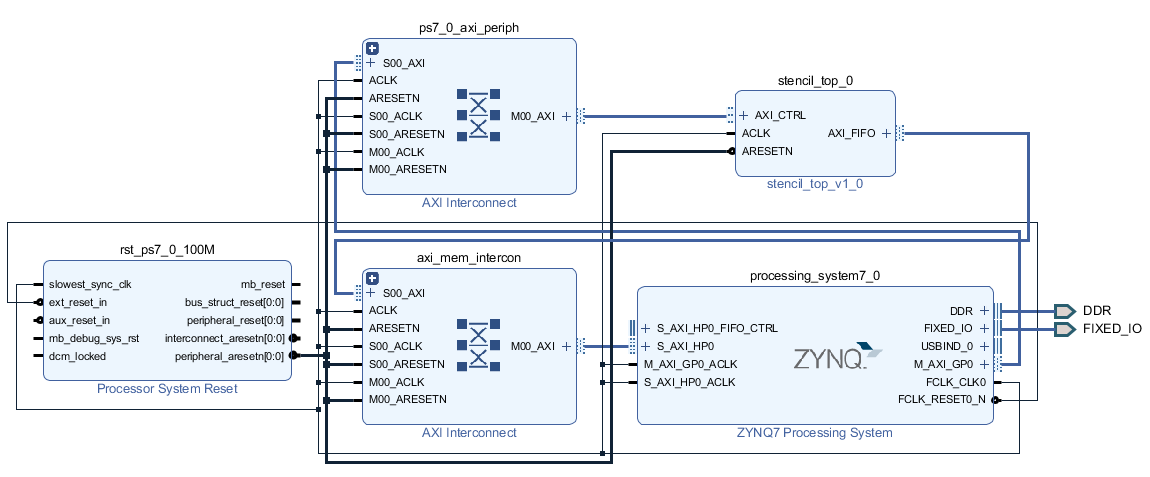
あとはいつも通り、ブロック図からファイルを Generate し、HDL Wrapper を作成し、Generate Bitstream で論理合成以降の一連の処理を行い、ハードウェアを Export します。なお、今回は FPGA (PL) 側に入出力ピンが必要ないため、制約ファイル (XDC) をプロジェクトに追加する必要もありません。
ソフトウェアとの性能比較
ここからは Vitis でのソフトウェア記述に移ります。Vitis の基本的な使用方法は、「IP の世界からこんにちは」の第5回を参照してください。
今回は、同じステンシル計算をソフトウェアとハードウェアの両方にさせることで、結果が一致することの確認と性能比較を行います。ソフトウェア実装については、本記事の冒頭で述べたコードを用います。
コプロセッサを起動し、その終了を待つためのコードは stencil.c 60~69 行目の stencil_hard 関数にまとめられています。
void stencil_hard (unsigned int src[][N], unsigned int dst[][N])
{
STENCIL_SIZE = N;
STENCIL_SRC_PTR = (unsigned int) src;
STENCIL_DST_PTR = (unsigned int) dst;
STENCIL_GO = 1;
while (STENCIL_DONE);
STENCIL_GO = 0;
while (! STENCIL_DONE);
}
あらかじめ、特定のメモリアドレスにアクセスするためのマクロを用意しています。これを使って、引数や GO に値を代入したり、DONE の値を読み取ったりしています。プロセッサの動作周波数は FPGA 側よりもずっと高いですから、GO を ‘1’ とした後、DONE が立下ることを確認 (66行目) した上で GO を ‘0’ に戻しています。その後、DONE が立上ったことを確認 (68行目) し、関数から抜けます。
なお、コプロセッサから直接アクセスされるメモリ領域にプロセッサ側から事前に読み書きを行っている場合、その内容がキャッシュに残っていると、データの不整合を起こす原因になります。今回は配列の初期化をソフトウェアで行っていますので、キャッシュに関するライブラリ関数 (xil_cache.h で定義) を使って、確実に無効化 (フラッシュ) しておく必要があります。該当部分は stencil.c の 119~120 行目です。
start_time = getclock();
Xil_DCacheFlushRange((u32) buf1, sizeof(buf1));
Xil_DCacheFlushRange((u32) buf2, sizeof(buf2));
flush_time = getclock() - start_time;
それでは動作させてみます。Vitis のプロジェクトを作成し、stencil.c を src ディレクトリにインポートしてから、ビルドを行います。そして、Tera Term などであらかじめボードとシリアル通信を行える状態にしておき (ボーレートは 115,200 bps です)、FPGA にビットストリームを書き込み、プログラムを転送します。
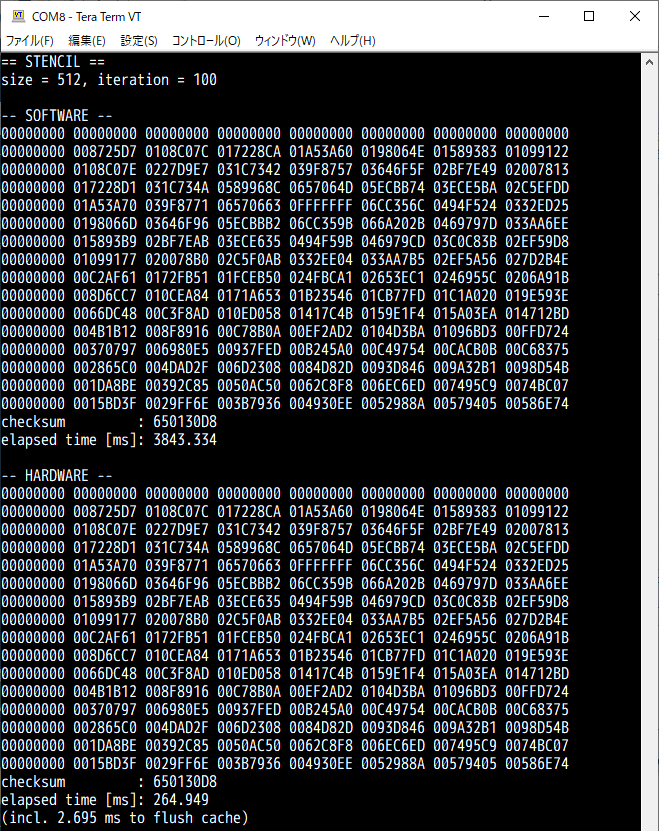
プログラムの実行結果の例を上図に示します。なお、対象ボードは PYNQ-Z1 とし、配列サイズは 512、繰り返し回数は 100 に設定しています。配列の一部の値と、チェックサムの値、そして実行時間が、ソフトウェア実装の場合とハードウェア実装の場合とでそれぞれ表示されます。チェックサムが互いに 650130D8 であることから、配列の値は確かに一致していることが確認できます。
実行時間を見てみると、ソフトウェアの場合が約 3,843 ミリ秒、ハードウェアの場合が約 264.9 ミリ秒となりました。ソフトウェアの方があまり最適化されていないのもありますが、コプロセッサを使うことで、実行時間の14.51倍の短縮を達成することができました。
また、この実行時間のうち約 2.7 ミリ秒はキャッシュを無効化 (フラッシュ) するのに要している時間のようです。これは一見短い時間のようにも見えますが、トータルの実行時間が計算100回の繰り返しの合計であることを鑑みると、計算1回分にほぼ等しい時間です。つまり、仮にハードウェアで1回計算するたびに配列に対して何らかのソフトウェア処理をする、などとしてしまうと、ソフトウェア処理が終わるたびにキャッシュのフラッシュが必要になってしまい、実行時間はほぼ倍になってしまう、ということです。もしもそのようなソフトウェアとの密な結合が必要になるのであれば、第1回で紹介した ACP ポートの使用を検討することになるでしょう。
まとめ
このコースでは、AXI を使ってプロセッサと連携する回路について、実際の設計例を示しながら説明してきました。特に、前回と今回では、フル機能の AXI を用いてソフトウェアの一部を高速化する専用計算 (コプロセッサ) 回路について扱いました。
ところで、今回の約 264.9 ミリ秒という実行時間から、AXI の帯域がどれくらい効率的に使えたかを考えてみます。今回送受信したデータ量は、送信で 5102 (要素数) x 4 (要素/バイト) x 100 (計算回数) ≒ 104.0 MB、受信で 5122 (要素数) x 4 (要素/バイト) x 100 (計算回数) ≒ 104.9 MB です。時間で割って帯域幅を求めると、(104.0 + 104.9) / 0.2649 ≒ 788.6 MB/s となります。
一方、回路が 100 MHz 動作であり、W チャネルと R チャネルは同時動作可能であることから、今回の理想的な帯域幅は 100 (MHz) x 4 x 2 (チャネル数) = 800 MB/s です。したがって、今回のコプロセッサ回路では、AXI の理想の帯域幅に対して 98.6 % の効率を達成できたことになります。
とはいえ、メモリ (DRAM) の帯域幅と比べれば、まだまだ向上の余地はあります。ここから更に改良するためには、Zynq の HP ポートをより活用する (64ビット幅にする、複数ポートを使う)、動作周波数を上げるなどの手段が考えられます。ソースも公開しましたし、ここからは読者への発展課題としたいと思います。
また、本コースで公開した AXI-Lite のインタフェース回路や AXI のインタフェース変換回路は、(無保証であることには留意いただきたいものの) AXI を使った様々な IP コアや、それを組み合わせたシステムを構築する時の便利な部品として利用できるかと思います。自分のやりたいことを形にする近道として、ご活用いただければ幸いです。
愛知⼯業⼤学 藤枝直輝