概要
全5回のこの連載では、ザイリンクスでお客様の技術支援を行っている数名のエンジニアが、高位合成を活用したアクセラレータ開発に関して、その考え方やフローを、事例を交えながら解説します。
初回のこの記事では、ACRi ルーム と PYNQ で、高位合成を使った FPGA 開発フローを「超」お手軽に体験してみましょう。C と Python しか出てきませんので FPGA 初心者の方もご安心ください。
ACRi ルーム
ACRi ルームは、ACRi が運営する FPGA 利用環境です。大学/企業/個人を問わず、FPGA に関わる研究、教育、技術習得、検証評価など、様々な目的で利用できます。ACRi ルームが画期的なのは、大規模で高性能な FPGA を含む計算資源が「無償」で提供されている点です。高価な FPGA を購入しなくても (もしくは購入する前に)、FPGA を使用した研究や、評価、開発ができます。詳しくは ACRi ルームのサイトをご覧ください。ぜひご登録を!

ACRi ルームでは、FPGA を搭載し FPGA 開発に必要なツールがあらかじめインストールされたサーバーが複数台提供されています。利用者はこのサーバーを事前に予約した上でリモートで接続して FPGA 開発環境を利用できます。
この中にザイリンクス Alveo カードが利用できるサーバーがあります。Alveo カードはザイリンクス製品の中でもハイエンドなシリーズの FPGA を搭載した FPGA アクセラレータカードです。Alveo カードが利用できるサーバーについて簡単に説明します。
Alveo サーバー概要
Alveo サーバーでは Vitis を使った FPGA アクセラレータの開発と、Alveo カードの利用ができます。サーバーごとに Alveo カードをひとつ搭載し、サーバーを予約した時間枠内で CPU、メモリ、Alveo カードを占有して使用することができます。各サーバーのスペックを次の表に示します。
| ホスト名 | CPU | スレッド | メモリ | OS | Alveo カード |
|---|---|---|---|---|---|
| as001 | Core i9-9900 | 8 | 60GB | Ubuntu 18.04 | U200 |
| as002 | Core i9-9900 | 8 | 60GB | Ubuntu 18.04 | U250 |
| as003 | Core i9-9900 | 8 | 60GB | Ubuntu 18.04 | U280-ES1 |
| as004 | Core i9-9900 | 8 | 60GB | Ubuntu 18.04 | U50 |
| as005 | Core i7 11700K | 8 | 60GB | Ubuntu 18.04 | VCK5000 |
PYNQ で Alveo 体験
ACRi ルームで高性能な FPGA を無償で使えるとはいえ、なんだか難しそうですし、最初はどこから手を付けて良いか分からないかもしれません。FPGA を動かすには、古めかしい記法で FF ひとつひとつを意識して記述していくハードウェア記述言語を使用する必要がありそうで、これが大きなハードルに感じるかもしれません。
そのような方でも簡単に FPGA に入門してもらえるよう、ザイリンクスでは高位合成ツールを (一部のデバイス向けを除き) 無償で提供しています。高位合成については今後の記事でより詳しく解説していきますが、これを利用すると C や C++ といった一般に馴染みやすいソフトウェア向けの言語を使って、簡単なコードでハードウェアを記述できるようになります。簡単に記述できる上、ツールをうまく使いこなせば高性能なアクセラレータの開発もできてしまいます。
今回は PYNQ を使って、高位合成を利用したアクセラレータ開発を、少しのキーボード入力とマウス操作だけで「超」お手軽に体験する方法をご紹介します。ここでは ACRi ルームにアカウントを申請し、予約したサーバーにログインしたところから解説します。ぜひ一緒に体験してみましょう。
PYNQ に関してはわさらぼの三好さんが詳しく解説されています。こちらもご覧ください。
現在 ACRi ルームで PYNQ が利用できるのは次のサーバーです。以下の説明では as001 を使います。
- as001 (U200)
- as002 (U250)
- as004 (U50)
- as005 (VCK5000)
さて、as001 にログインしたところです。ふつうの Ubuntu の画面ですね。
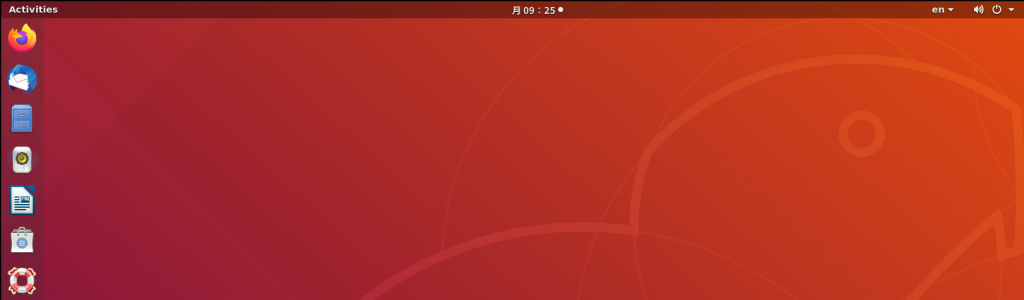
左上の「Activities」の文字をクリックして、「Terminal」アプリを検索し、起動してください。
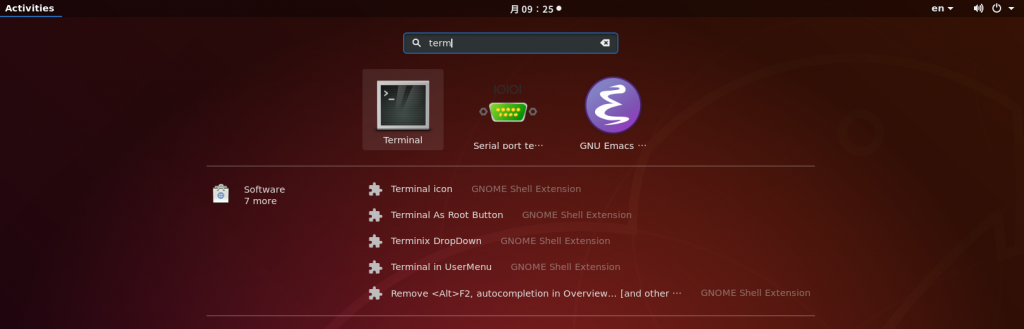
ターミナルに次のコマンドを入力してください。今回はキーボード入力はこれだけです。
$ /opt/pynq-notebooks/start.sh次のように Jupyter Lab が起動します。あらかじめダウンロードされた Alveo 向けの Jupyter ノートブックをいくつか試すことができます。
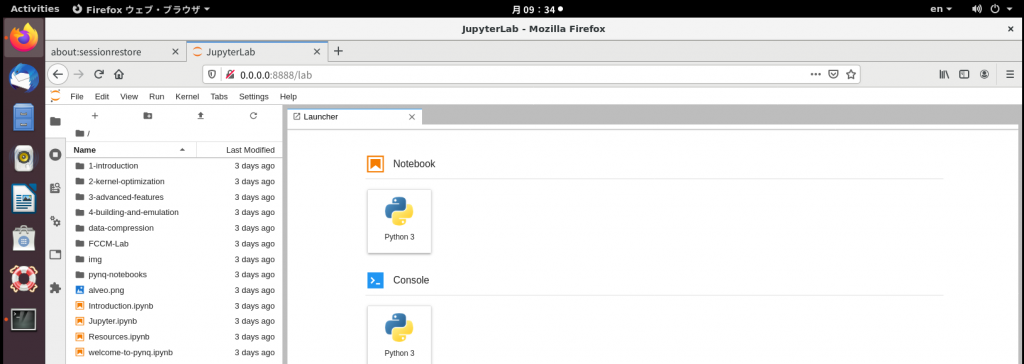
ここでは C 記述のアクセラレータをビルドして FPGA 上で動かしてみましょう。「4_building_and_emulation」ディレクトリの下にある、「1-building-with-vitis」ノートブックを開いてください。
次の図はノートブックを開いたところです。あとはマウスを使ってブロックをひとつずつ実行していけば FPGA 実行まで行うことができます。
このノートブックでは、ベクトルの足し算を行う簡単な例を使って、Vitis による FPGA アクセラレータ開発フローを学べます。Vitis はザイリンクスが無償で提供する FPGA アクセラレータ向け開発環境です。次の記事で Vitis がどのようなツールか解説しました。


以下がベクトル加算アクセラレータを C で記述したコードです。このコードが高位合成によりハードウェアに変換され、FPGA 上で実行されます。
void vadd(int* in_a, int* in_b, int* out_c, int count) {
#pragma HLS INTERFACE m_axi port=in_a offset=slave
#pragma HLS INTERFACE s_axilite port=in_a bundle=control
#pragma HLS INTERFACE m_axi port=in_b offset=slave
#pragma HLS INTERFACE s_axilite port=in_b bundle=control
#pragma HLS INTERFACE m_axi port=out_c offset=slave
#pragma HLS INTERFACE s_axilite port=out_c bundle=control
#pragma HLS INTERFACE s_axilite port=count bundle=control
#pragma HLS INTERFACE s_axilite port=return bundle=control
for (int i = 0; i < count; ++i) {
*out_c++ = *in_a++ + *in_b++;
}
}#pragmaから始まる行は、ソフトウェア記述をどのようにハードウェアに変換するかをツールに指示するためのものです。今回はこの詳細には触れません。
for 文の中の記述がややこしいですが、次のように書き直すことができます。配列を要素ごとに足し合わせて別の配列に代入しているだけですね。
for (int i = 0; i < count; ++i) {
out_c[i] = in_a[i] + in_b[i];
}次にこのコードをコンパイルします。Vitis におけるコンパイルとは、高位合成によりソフトウェア記述をハードウェア記述に変換し、再利用可能な形でパッケージ化することを意味します。Vitis の v++ コマンドを使用して次のように実行すると、およそ1分ほどでパッケージ化された vadd.xo が生成されます。
$ v++ -c vadd.c -t hw --kernel vadd -f $platform -o vadd.xo次にパッケージ化した xo をプラットフォームとリンクします。このコマンドの裏で Vivado プロジェクトが作成され、論理合成や配置配線、ビットストリーム生成などが実行されます。これによりビットストリームやアクセラレータに関するメタ情報を含んだ xclbin ファイルが、およそ1時間ほどで生成されます。
$ v++ -l -t hw -o vadd.xclbin -f $platform vadd.xo生成された xclbin ファイルを使って、アクセラレータを動かしてみましょう。アクセラレータを動かすためのホストプログラムは次のようなコードです。本来であれば OpenCL Runtime API を使ってもっと複雑な記述が必要ですが、PYNQ の API を使って非常に分かりやすい記述になっています。
import pynq
import numpy as np
ol = pynq.Overlay('vadd.xclbin') ... (1)
vadd = ol.vadd_1
in1 = pynq.allocate((1024,), 'u4') ... (2)
in2 = pynq.allocate((1024,), 'u4') ... (2)
out = pynq.allocate((1024,), 'u4') ... (2)
in1[:] = np.random.randint(low=0, high=100, size=(1024,), dtype='u4')
in2[:] = 200
in1.sync_to_device() ... (3)
in2.sync_to_device() ... (3)
vadd.call(in1, in2, out, 1024) ... (4)
out.sync_from_device() ... (5)
np.array_equal(in1 + in2, out)この短いコードでアクセラレータを動かすために必要なことがすべて表現されています。上から順に説明すると、次のことを行っています。
- xclbin ファイルを読み込んで FPGA をコンフィグする
- ホストと FPGA の両方のメモリにデータ領域を確保する
- ホストのメモリから FPGA のメモリにデータを転送する (sync_to_device)
- アクセラレータを実行する
- FPGA のメモリからホストのメモリにデータを転送する (sync_from_device)
最後にホスト上で計算した結果と答え合わせをしています。実行結果として True が出力されれば成功です。
まとめ
今回は ACRi ルームの Alveo サーバーを利用して、高位合成を使った FPGA アクセラレータ開発フローを体験して、簡単なソフトウェア記述で FPGA の開発ができることを見てみました。次回以降の記事では、高位合成を使ったハードウェア設計について詳しく解説する予定です。
ザイリンクス株式会社 安藤潤