
このブログも今回で最終回となります。このブログの第2回から第4回まで、係数行列が16×16の比較的小規模な連立一次方程式を扱ってきました。これを小規模な FPGA である Ultra96-V2 で上で高速化してみます。また、大規模な係数行列への対応も検討してみます。今回使ったプログラムも github 上の solver/cg/ocl_unroll, solver/cg/ocl_r16_spmv, solver/cg/ocl_large においてありますので参考にして下さい。
小規模な問題の高速化
ループアンローリングと配列の分割
Vitis では、ループアンローリングによってループを展開し、演算を並列に実行できます。ただし、条件が整えば、ですが。
たとえば CG 法にも出てくる axpy は配列 x の各要素をスカラ変数 a 倍したものと配列 y の各要素とを加算した結果の配列 r を求める処理です。これは並列化が容易な例といえます。
for (i=0; i<N; i++) {
r[i] = a * x[i] + y[i];
}この axpy をアンロール段数 (unroll factor) 4でアンロールすると以下のようになります。ここでは説明を簡単にするため、ループの繰り返し回数 N は4で割り切れるものとします。
for (i=0; i<N/4; i+=4) {
r[i] = a * x[i] + y[i];
r[i+1] = a * x[i+1] + y[i+1];
r[i+2] = a * x[i+2] + y[i+2];
r[i+3] = a * x[i+3] + y[i+3];
}Vitis では、以下のように UNROLL 指示文というものを挿入すると、上記の4段でアンロールされたループを記述するのと同じことになります。UNROLL 指示文を使う場合は、N が4で割り切れない場合についてもそれを補うコードを Vitis が自動的に生成してくれます。
for (i=0; i<N; i++) {
#pragma HLS UNROLL factor=4
r[i] = a * x[i] + y[i];
}さて、このアンローリングにはどのような効果があるのでしょうか。
4段でアンロールされた axpy なら、4つの乗算器と加算器が FPGA 上に配置されます。可能であれば、それらの演算器が並列に実行できるような回路が合成されます。
このとき、配列 x, y, r の4個の要素も同時に読み書きできるように ARRAY_PARTITION という別の指示文が必要になります。
#pragma HLS ARRAY_PARTITION variable=x cyclic factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=y cyclic factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=r cyclic factor=4 dim=1図1に16要素の配列の axpy を4段ループアンローリングし、ARRAY_PARTITION によって配列を分割した例を示します。
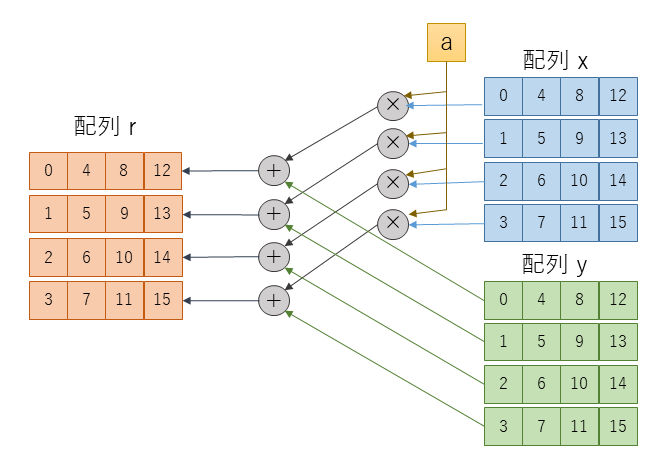
第2回に説明したように、例として使っている CG 法のプログラムでは配列の記憶領域を FPGA 内部の BRAM に確保しています。各配列にはそれぞれ1ポートの BRAM が割り当てられます。つまり、各配列で同時に読み書きできるのは1要素になります。しかし、ループアンローリングで複数の演算器が並列に実行可能となっているのにあわせて、配列の複数の要素を同時に読み書きできるようにする必要があります。
そこで、図1のように各配列を4つのブロックに分割し、最初のブロックに 0, 4, 8, 12 番目の要素、次のブロックに 1, 5, 9, 13 番目の要素といったように配列の要素を割り当てていきます。各ブロックには1つづつポートが割り当てられています。このようにすると、0, 1, 2, 3 の4つの要素はそれぞれ別のブロックに割り当てられていますので、同時に読み書き可能です。
指示文 ARRAY_PARTITION によって、このように配列の分割方法を指示することができます。いろいろな分割方法が指定できますので、詳しくは UG1399 Vitis HLS User Guide などを参照して下さい。
なお、指示文 ARRAY_PARTITION は、配列の宣言や関数の仮引数の直後などに記述しなくてはならないようです。関数から関数へと配列が渡される場合も、それぞれの仮引数名で指定しなくてはなりません。恥ずかしながら、仮引数の ARRAY_PARTITION を指定し忘れたことがあったのですが、関数のインライン展開のおかげか Vitis の処理系が推測してくれたこともあります。とはいえ、あまり、そのような推測には頼りきらない方が良いとは思います。
ループアンローリングと配列の分割の効果
では、axpy 以外のループも含めたループアンローリングと配列の分割を組み合わせた効果を見ていきましょう。CG 法のプログラムは、第2,3,4回でも使った係数行列が16×16の連立一次方程式を解くものです。github 上の solver/cg/ocl_unroll にソースコードをおいていますので参考にして下さい。Vitis 2020.1 で回路を合成することを前提に、ホストコードとカーネルコードは同一のディレクトリ上にまとめています。
疎行列の圧縮方式は ELL にしています。連続する2つの axpy をループ融合して axpy2 としていますが、それ以外のループ融合は適用しないコードにしています。ELL やループ融合については、このブログの3回目でも説明しましたので、そちらもご参照下さい。
ループアンローリングや配列の分割については以下のように設定しました。
- dot, spmv_ell, axpy, axpy2 などの関数内のループにアンローリングを適用します。
- アンローリング段数は 4, 8, 16 とします。
- アンローリング段数にあわせて、配列を分割します。
たとえば、関数 spmv_ell では以下のように、i, j の2重ループの外側のループをアンローリングし、それにあわせて疎行列の配列 ell_col, ell_val は1次元目を分割しています。
template<typename T>
void
spmv_ell(int ell_col[N][NZ], T ell_val[N][NZ], T b[N], T ret[N])
{
#pragma HLS ARRAY_PARTITION variable=ell_col cyclic factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=ell_val cyclic factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=b cyclic factor=4 dim=1
#pragma HLS ARRAY_PARTITION variable=ret cyclic factor=4 dim=1
for (int i=0; i<N; i++) {
#pragma HLS UNROLL factor=4
ret[i] = (T)0;
for (int j=0; j<NZ; j++) {
ret[i] += ell_val[i][j] * b[ell_col[i][j]];
}
}
return;
}
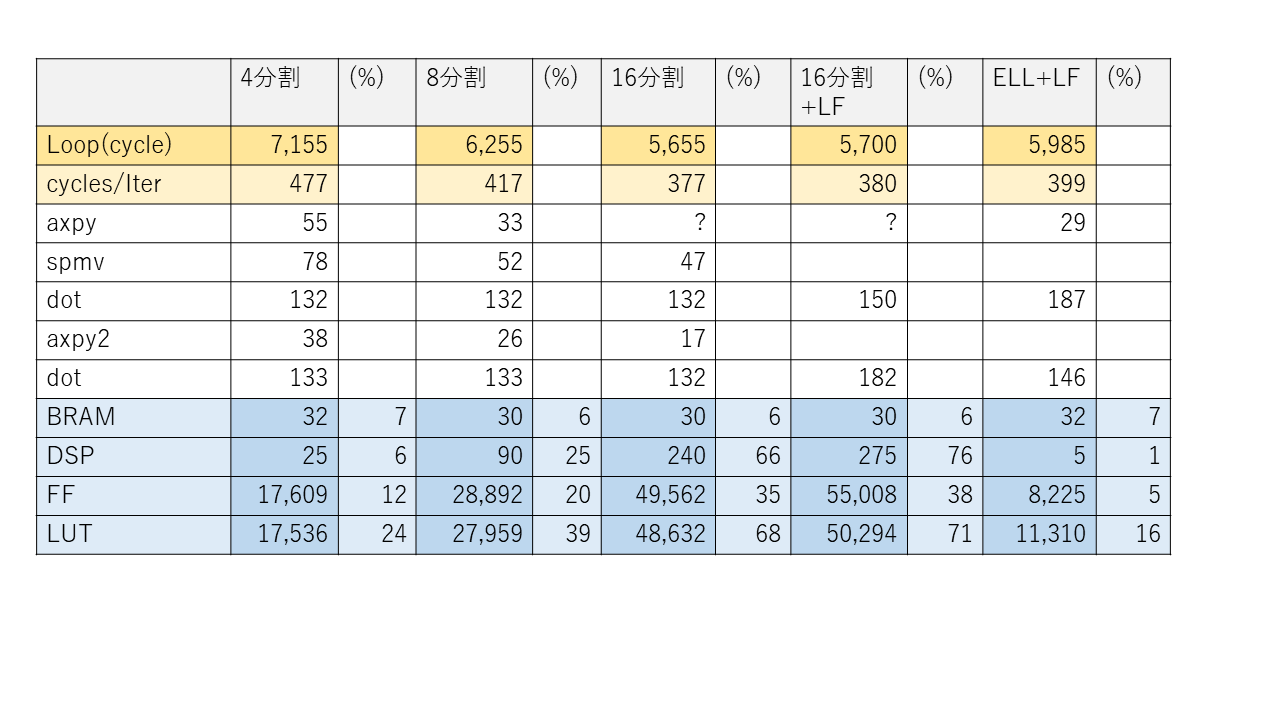
表1に配列の分割数 (ループアンローリングの段数) を4, 8, 16と変えたときの、CG 法のプログラムのカーネルループや各ループの実行サイクル数 (遅延サイクル数) と FPGA の使用資源数の見積もりを示します。FPGA は Ultra96-V2 で動作周波数は 150MHz です。比較のため、このブログの前回、第4回に示したループ融合を適用した場合の遅延サイクル数と使用資源数もこの表の右端に載せました。
FPGA 上の実行時間の大部分を占めるカーネルループの1反復あたりのサイクル数は、表1に示すように、アンローリング段数を増加させると減少していき、アンローリング段数16のときに377サイクルです。一方、表1の右端に示すように、ループアンローリングを適用しなくても、ループ融合を積極的に使えばカーネルループの1反復は399サイクルとなります。
となると、ループアンローリングとループ融合を組み合わせれば良さそうに思えます。そのデータも右から2番目に「分割数16 +LF」として載せています。アンローリング段数16のときカーネルループの1反復は 380 サイクルとなりますので、残念ながら、ループ融合せずにループアンローリングのみ適用した方が高速という結果になってしまいました。
一方、FPGA の資源は配列の分割やループアンローリングによって確実に消費されています。表1には BRAM, DSP, FF, LUT などの資源の使用数と、Ultra96-V2 に搭載されている全資源に対する使用割合 (%) も示していますので、資源の消費度合が確認できます。
このように、16×16の係数行列の例では、ループアンローリングによって高速化は可能ですが、わずかしか高速化されず、一方で必要とされる FPGA の資源は大幅に増加して
しまいます。
疎行列データの埋め込み
ループアンローリングによる高速化とはちょっと方針を変えてみます。このセクションと次のセクションで説明するコードは github 上の solver/cg/r16_spmv においていますので、適宜ご参照下さい。
CG 法にあらわれる疎行列とベクトルの積 (spmv) では、疎行列のデータ、つまり連立一次方程式の係数行列はプログラムの実行中は変化しません。そこで、この疎行列のデータを spmv に埋め込んでしまうことを考えてみます。
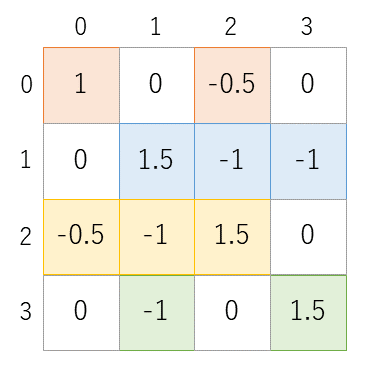
図2はこのブログの第3回でも例として使った疎行列です。この疎行列 A と4要素のベクトル p の積を4要素のベクトル q に代入する処理は、疎行列のデータを埋め込むと以下のように記述できます。
q[0] = p[0] - 0.5*p[2];
q[1] = 1.5*p[1] - p[2] - p[3];
q[2] = -0.5*p[0] - p[1] + 1.5*p[2];
q[3] = -p[1] + 1.5*p[3];これが16×16の行列になったとしても、ちょっと大変ですが、手書きで何とか書き下すことはできそうです。
内積の並列化
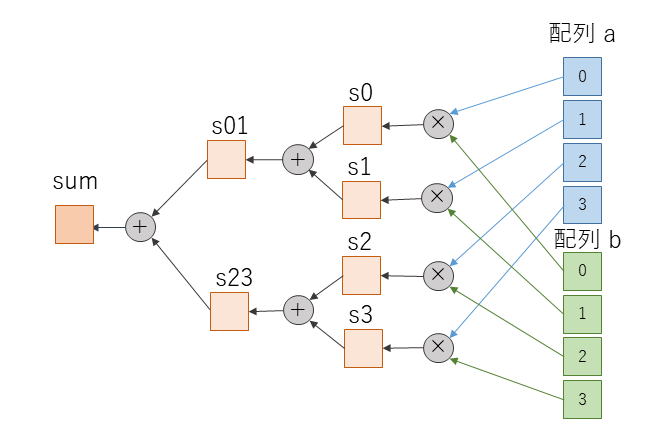
内積には、図3に示すような良く知られた並列化手法があります。図3は4要素の2つの1次元配列を使った内積の並列化の例になります。配列 a, b について 0, 1, 2, 3 番目の要素同士の積を並列に計算し、それぞれ s0, s1, s2, s3 に代入しておきます。さらに s0 と s1, s2 と s3 のそれぞれの和 s01, s23 も並列に計算できます。最後に s01 と s23 の和を計算すると内積が求まります。要素数が増えても同様の並列化が可能です。
今回、16要素の内積について、s0, s1 や s01 のようなスカラ変数を用意し、ループではなく代入文を書き連ねてみました。代入文同士が並列に実行可能かどうかは Vitis の処理系の判断にまかせています。
ところで、このような内積の並列化では、逐次実行と並列実行とで加算の順序が変更されていることに注意が必要です。逐次実行では問題がなかったのに、並列実行では桁落ちが発生して計算結果の精度が低下してしまうことがありますので、逐次実行と並列実行とで結果を比較しておく必要があります。
疎行列データの埋め込みと内積の並列化の効果
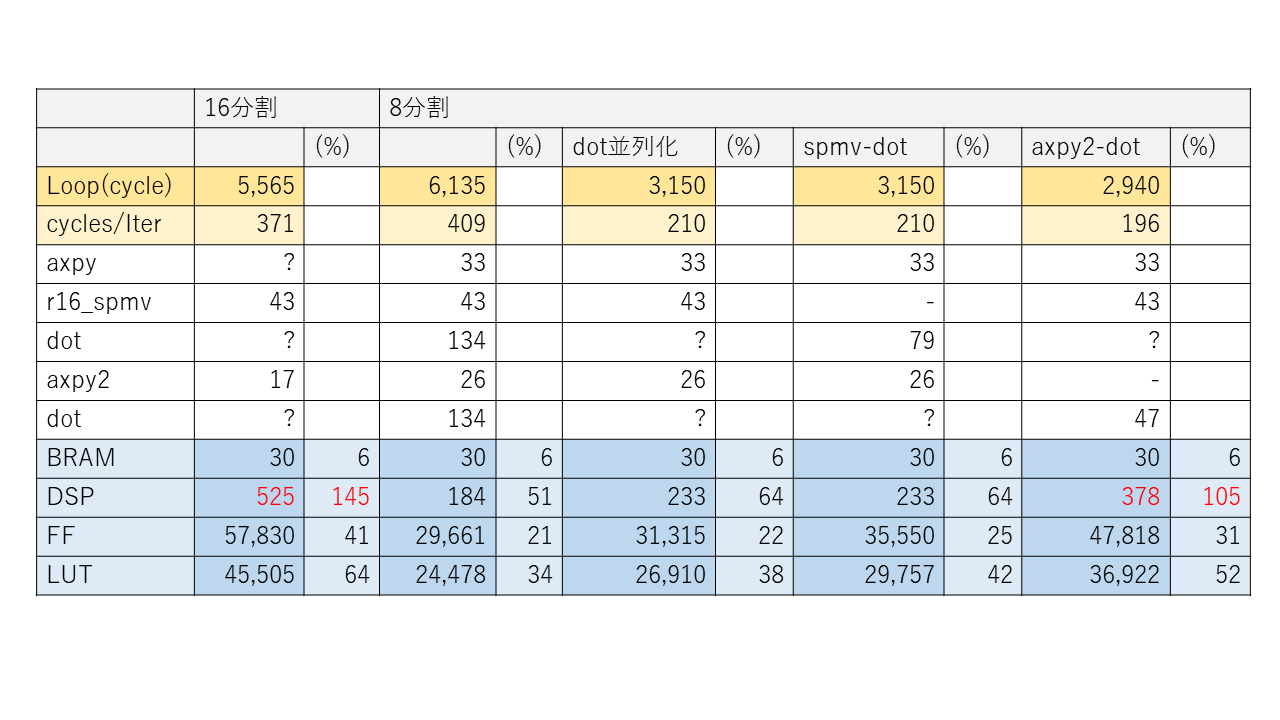
CG 法に spmv への疎行列データの埋め込みと内積の並列化を適用した場合の遅延サイクル数と FPGA の使用資源数の見積もりは表2のとおりになります。これらを適用する場合も、配列を分割して複数の要素に同時にアクセスできなければ効果は出てきません。
使用したコードは github 上の solver/cg/r16_spmv のもので、適用するコード変換や並列化によって呼び出す関数を入れ替えています。使用した FPGA は Ultra96-V2 で動作周波数は 150MHz です。
配列を16分割または8分割とし、spmv への疎行列データの埋め込み (表2では r16_spmv と表記しています) のみ適用したのが表2の左2つの結果です。配列を16分割した場合、かなり高速化されるのですが、残念ながら DSP の使用数が搭載数を大きく上回っています。一方、8分割の場合、使用資源数はそれほど多くないのですが、あまり高速化できていません。
配列を8分割とし、さらに内積 (dot) を並列化すると、遅延サイクル数が大きく減少し、高速化されることがわかります。この並列化された内積と他の関数の処理を融合すると、表2の右2つの結果のようになります。
- spmv-dot: r16_spmv と 並列化された dot を融合します。
- axpy2-dot: axpy2 と 並列化された dot を融合します。
spmv-dot は融合前と遅延サイクル数は変わらず、高速化の効果がないにもかかわらず、FF や LUT といった資源はわずかに増加しています。axpy2-dot は融合によって遅延サイクル数は減少するのですが、使用 DSP 数がやや搭載数を上回っています。
結局、この例では spmv の疎行列データの埋め込みと内積の並列化をそれぞれ個別に行うことで高速化が達成されることがわかりました。
通常の CPU での実行の場合にこのように疎行列のデータをプログラムに埋め込んだり内積を並列化したりするコードを書き下しても、ほとんど効果はないと思います。それに対して FPGA を使う場合には、合成される回路を想定しながら書き下すことになるため、効果が現れているように思われます。
さて、前のセクションの内積の並列化のところで、逐次実行と並列実行の結果の比較が必要だと書きましたが、このセクションの最後に、実際に結果を比較してみます。まずは並列実行の結果です。Vitis 2020.1 で回路を合成し、Ultra96-V2 で実行した結果です。
res:16 = 4.69517
error = 0.52751
0: -0.111131
1: -1.41733
2: -1.61477
3: -0.481627
4: -0.354723
5: -0.242187
6: 0.558789
7: 0.602448
8: -0.279332
9: 3.91903
10: -0.617959
11: -0.0690466
12: 0.0100799
13: 0.452893
14: 0.247869
15: 0.753427
Time: 0.48087これに対し、このブログの第2回でも示した実行結果をもう一度示します。
res:16 = 7.04937e-05
error = 0.000135595
0: 1.00011
1: 1.00024
2: 1.00025
3: 1.00015
4: 1.00014
5: 1.0001
6: 1.00011
7: 1.00005
8: 1.00006
9: 1.00003
10: 1.00005
11: 1.00003
12: 1.00003
13: 1.00002
14: 1.00002
15: 1.00001
Time: 2.74879e-06後者は、Vitis 2020.1 または Vitis 2020.2 で Emulation-SW で得られる結果です。実行時間以外は Vitis 2020.1 で Hardware 実行または Emulation-HW のエミュレーションで得られる結果とも同一です。これと比べると、前者は解が収束へ向かっているようには見えますが、この反復回数で得られている解の精度は良くありません。やはり、内積を並列化する際には、忘れずに実行結果を確認する必要がありそうです。
大規模な問題への対応
FPGA の外部メモリの利用
Alveo U50 は Alveo シリーズの中では FPGA の資源数が少なく小規模なモデルとされていますが、Ultra96-V2 よりは多くの資源が利用できます。では、U50 で問題サイズの大きくして CG 法のプログラムを実行してみましょう。
このブログの第2回でも少し触れているのですが Matrix Market という行列のリポジトリサイトがあり、さまざまな行列のデータがダウンロードできます。今回は、このサイトの 494_bus.mtx と s3dkq4m2.mtx という2つの行列を使ってみます。実際に試される場合は、このサイトで行列名を検索してご自分でダウンロードして下さい(s3dkq4m2.mtx を使用される場合、冒頭のコメント行のうち最初の行を除いて削除して下さい。CG 法のプログラムで使っている Matrix Market 形式のデータの読み込みルーチンが未対応のためです。すみません)。
github 上の CG 法のプログラム solver/cg/ocl_large では、Matrix Market 形式の疎行列データのサイズに関する方法を sparse_defs.hpp に記述しておくことで、その疎行列のサイズにあわせた回路を合成できるようにしています。例えば、疎行列データが 494_bus.mtx なら sparse_defs.hpp に以下のような定数を定義しています。
const int N=494; // 行数または列数
const int SNV=1080; // 対称行列の対角要素を含めた下三角(上三角)行列の非零要素数
const int NV=2*SNV-N; // 非零要素数
const int NZ=10; // 各行の非零要素数の最大値
const int NITER=N; // デフォルトの反復回数github 上の CG 法のプログラムでは solver/cg/ocl_large/cg_float_app/src に上記の定数を定義した 494_bus_sparse_defs_int.hpp というファイルを用意しています。これを sparse_defs.hpp というファイル名に変更して使えば 494_bus 用の回路が合成できます。また、s3dkq4m2 用にも同様のファイル s3dkq4m2_sparse_defs_int.hpp を用意しています。
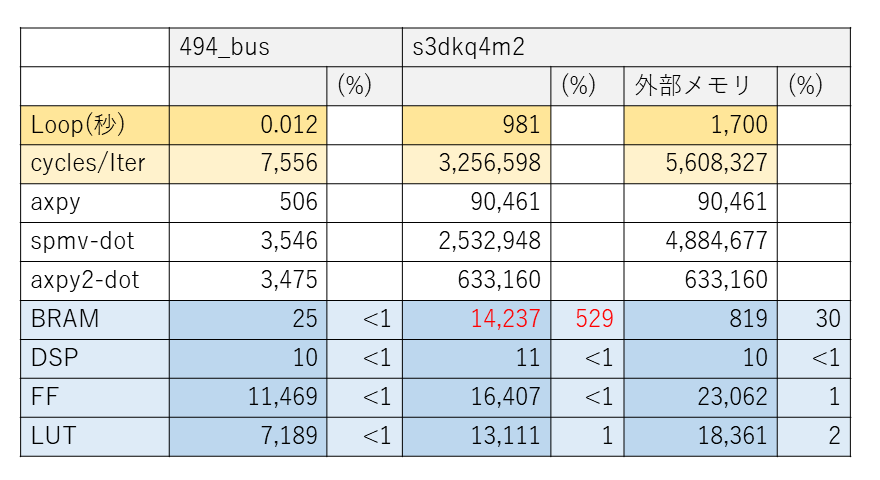
実際にこれら2つの疎行列用の回路を U50 で 300MHz をターゲットとして合成すると遅延サイクル数と FPGA の資源使用数は表3 のようになります。カーネルループの実行時間見積もりはサイクル数だと大きな値になるため秒を単位として表しています。
s3dkq4m2 の場合、残念ながら FPGA 内の BRAM にデータがおさまりません。そこで、ホストから送られてくる疎行列の配列 ell_val と ell_col を BRAM にコピーせず、FPGA に接続されているメモリに置いたままアクセスすることにして回路を合成してみます。見積もり結果は表3の右端のようになり、実行時間は長くなってしまいますが、回路は FPGA 内におさまり、実行自体は可能です。
ではどの程度のサイズまでなら BRAM にコピーできるのか計算してみます。行数 N, 各行の非零要素数の最大値 NZ は以下のような値です。
- 494_bus: N=494, NZ=10
- s3dkq4m2: N=90,449, NZ=54
疎行列の圧縮形式が ELL の場合、疎行列の非零要素の値を保持する float 型の配列 ell_val と非零要素の行列上の位置を保持する int 型の配列 ell_col はどちらもサイズ N×NZ の2次元配列になります。これら2つの配列のサイズを合計すると以下のようになります。
- 494_bus: 39,520 バイト
- s3dkq4m2: 39,073,968 バイト
一方、U50 のデータシート で確認すると、BRAM は 47.3Mb つまり 1.25MB 程度になります。s3dkq4m2 の場合の疎行列の配列は 39MB 程度になりますので、BRAM の容量を大幅に超えてしまっていることがわかります。計算上は、NZ=10 なら N=15,000 くらいまでは BRAM 上に疎行列のデータを確保できそうです。
Vitis_Library の利用
大規模なデータを扱う場合、Vitis_Library の利用も考えられます。このライブラリは blas, database, sparse など用途や分野ごとにまとめられています。blas の中に dot や axpy がありますし、sparse には疎行列ベクトル積もあるようです。これらのライブラリの実装には hls::stream というメモリと FPGA との間に FIFO をおいて効率的にデータをアクセスする C++ のクラスも使用されています。これらのライブラリを組み合わせて、CG 法で大規模な係数行列を扱うことも可能かと思います。
まとめ
このブログでは5回にわたって CG 法を例として、C++ で記述されたプログラムを FPGA で動かすための回路の合成手順、高速化のためのプログラムの書き換えなどを説明してきました。
ACRi ルームで利用可能な Alveo U50 の例を中心に説明しましたが、前回の第4回で、U50 と同じプログラムを Ultra96-V2, ZCU102, ZC706 などで動かす手順についても説明しました。第2回で説明したように、ホストプログラムで OpenCL の API を呼び出すことで、同一の C/C++ のプログラムを各種の FPGA で稼働させることができます。
第3回で説明したループ融合や、今回の第5回で説明したループアンローリング、配列の分割によって FPGA 上のカーネルの処理が高速化できることも確認できたかと思います。
説明がくどすぎたり、逆に省略しすぎたりして理解しにくい点もあったかと思いますが、その点はご容赦下さい。ご自身のアプリを FPGA で高速化しようとされている方にとって、このブログの情報が少しでもお役に立てれば幸いです。
広島市立大学 窪田昌史