
みなさんはじめまして。ACRi ブログ第1期の6番目のコースを担当する小林です。
このコースでは、スーパーコンピュータ (以下、ブログの文字数節約のために一般的に使われている略称「スパコン」を使います) にも FPGA がなぜ使われ始めたのか、FPGA をスパコンに使うことによって何ができるようになるのか、どのような技術的な面白さがあるのか、を紹介していきます。
第1回の記事ではいまどきのスパコン事情を紹介します。
そもそもスパコンとは?
「スーパーコンピュータ」という言葉は、2011年に世界最速となった「京」(2019年8月に運用終了) がマスメディアに取り上げられたことで世の中にだいぶ広まりました。それでは、スパコンは普段手にしているラップトップ、デスクトップパソコンと何が違うのでしょうか?
一言で言えば、「演算能力・メモリ性能・メモリ容量・ネットワーク性能・ディスク容量といった、コンピュータの基本的な構成要素がすべて桁違いに大きかったり高速だったりする『スーパーな』コンピュータ」である。
情報処理 Vol.60 No.12 Dec. 2019 特集 「京」の後の時代を支えるスパコン (参考資料[1]) p.1176より引用
そして資料 [1] では、“一般的なコンピュータと比べて「スーパー」な物差しは様々なだが、最も重要な物差しは「浮動小数点演算性能」である”と述べています。この浮動小数点演算の性能は、Floating-point Operations Per Second (FLOPS) と呼ばれる単位で表されます。これは1秒間に何回の浮動小数点演算を処理したかを示す指標です。例えば、1秒間に浮動小数点演算 (例: 足し算) を1回だけ処理できれば 1FLOPS になります。
一般的なコンピュータとスパコンの FLOPS はどのくらい違うのでしょうか。次の図に示すとおり、一般的なコンピュータに搭載されている CPU の FLOPS 値は高々十数 GFLOPS です。対して、「京」では 10PFLOPS です。ここで G は「ギガ」、P は「ペタ」のことであり、それぞれ 109、1015 を示します。文字通り「桁違いの」性能差があるということですね。

それでは、なぜ浮動小数点演算の性能が重要なのでしょうか。それは、様々な分野で高精細シミュレーションが日常的に行われており、それには極めて高い FLOPS 値が求められているからです [1]。
気象予報を例にあげると、3次元空間の空気の流れは Navier-Stokes 方程式と呼ばれる偏微分方程式で表されますが、これを解析的に解くことは困難です。そこで、空間を細かい「網の目」(メッシュ) に区切り (豆腐をさいの目切りにするイメージです)、区切られた各点における気圧や温度等の物理的な変数を数値化し、これを数値積分によって解くことで気圧の変化や雲の元となる水分子の密度を詳細にシミュレーションします。
しかし、それには膨大な量の計算が必要であり、かつ、高精度にシミュレーションするために浮動小数点の演算が用いられます。そして、これを現実的な時間 で処理する (明日の天気の予報をするためには少なくとも今日中に計算が終わってくれないと困りますよね) ためにスパコンが必要となるわけです。また、 このような浮動小数点演算を用いる既存のアプリケーションに加えて、ここ数年で人工知能に関する研究にもスパコンが多用されるようになっていて、人類の文明を飛躍させるためのスパコンの役割はますます広がっていると言えます。
スパコンの性能を向上させる「演算の加速装置」
演算の加速装置 (演算加速装置) とは、言葉の通りですが演算処理を加速させるハードウェアです。アクセラレータと呼ばれます。特にスパコンの電力あたりの性能を非常に高めたい場合に、CPU とアクセラレータを併用するスパコンが注目を集めています。例えば、2019年11月時点のスパコンの性能ランキング TOP500 の上位の10システムにおける6システムがアクセラレータを利用しています。
CPU はシステムの根幹の部分なのでどのような処理も実行できますが、CPU にとって不得手となる処理も存在します。そのような処理をアクセラレータに肩代わりさせることでアプリケーション全体の処理性能の向上を狙います。要するに、CPU にとっての助っ人プレイヤーがアクセラレータの立ち位置です。
主流は GPU (Graphics Processing Unit)
今日までに、世界中で様々なアクセラレータが開発・活用されてきましたが、アクセラレータとして最もメジャーなのは Graphics Processing Unit (GPU) です。
グラフィクス処理用プロセッサとして開発された GPU は、ピクセル値などの大量のデータ列とパラメータに対する積和演算などに特化した設計をとっています。そして、数千個という規模の演算コアを搭載しているため、大量のデータに対して同一の演算を行う並列性の高い処理においては、同世代の CPU の 5 から10 倍の性能を示します。また、電力あたりの性能も高くなります。
こうした GPU の特徴は、大量のデータに対して並列性・規則性の高い処理を要求する科学技術計算と相性が良く、そして科学技術計算には積和演算が多用される (例: 行列積) ので、GPU がアクセラレータとして用いられるというわけです。

ここがダメだよ GPU
GPU にも弱点があります。主に以下の3点が GPU の苦手とする局面です。
if 文のような条件分岐
GPU で動作するプログラムはスレッドという処理単位で実行されます。そして、GPU のスレッドはそれぞれがバラバラに動いているのではなく、32 個のスレッド (32という数字はいわゆるマジックナンバー) ごとの塊 (Warp) にまとめられ、Warp の全スレッドは「常に」足並みを揃えて動作しています。
ここで、if 文のような条件分岐に遭遇したとき、Warp 内のスレッド達の「意見」がそろうか、そろわないかで動作が異なってきます。意見がそろわないと GPU の性能が低下してしまします。
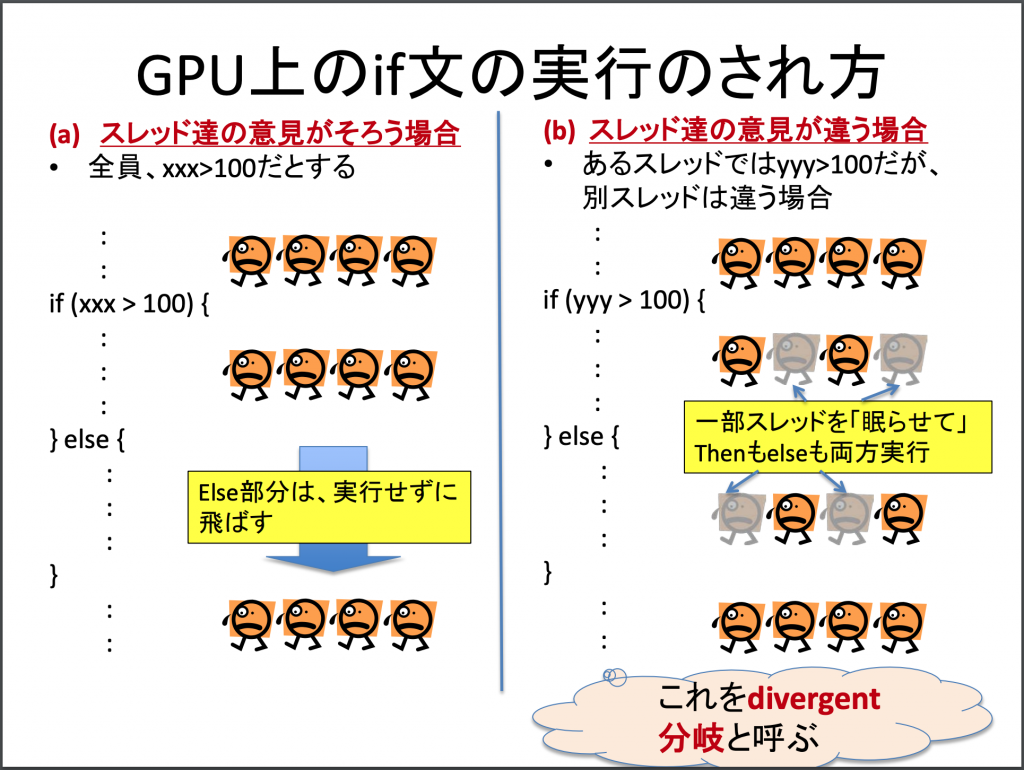
アプリケーション中に十分な並列性がない
先述しましたが、多数の演算コアを大量のデータに対して並列に稼働させることで性能を稼ぐハードウェアが GPU です。つまり逆に言うと、アプリケーションに十分な並列性がない場合、多数の演算コアを利用できずに演算性能を稼ぐことができません。このような場合、GPU に処理を肩代わりさせるより CPU にそのまま処理させた方が良かったというオチがありがちです。
GPU は多数の演算コアを一つのパッケージに押し込むために、一つ一つのコアの作りは CPU に比べて簡素化されており、そのためコア当たりの演算性能は CPU のコアの方が高くなります。
アプリケーションに通信処理が頻出する
GPU はスタンドアロンで動作できないので、CPU の助けが往々にして必要となります。その最たる例が通信処理です。通信が発生すると、処理の制御を CPU に戻す必要があるのでオーバーヘッドがかかります。オーバーヘッドとは処理の実行に影響しない処理、いわゆる「手間」のことです。そして通信そのものもオーバーヘッドとなります。なぜなら通信は CPU のみの処理では存在しなかったからです (GPU を併用することにより生じるオーバーヘッド) 。したがって、通信処理が頻出してオーバーヘッドが大きいアプリケーションは GPU にとって不得手となります。
と、ここまで GPU の弱点を説明してきました。これらの問題に対処するためには FPGA が有望なのではないか、とスパコン分野の研究者は注目しているわけです。次回の記事では、 これらの問題を解決するための FPGA の特徴を説明していきます。
まとめ
本コースの第1回目では、いまどきのスパコン事情についてご紹介しました。FPGA についての記事なのに、GPU について色々書いてしまいましたが、スパコンに FPGA を活用する背景として GPU のことを語らない訳にはいかなかったので、ご容赦ください。その代わりといいますか、次回からは FPGA がしっかり出てきます。ご期待ください。
参考資料
[1] 情報処理 Vol.60 No.12 Dec. 2019 特集 「京」の後の時代を支えるスパコン pp. 1174-1211
[2] 東京工業大学学術国際情報センター: “GPUプログラミング・応用編”
筑波大学 計算科学研究センター 小林諒平