
みなさん、こんにちは。このコースでは、ある簡単な例題を非同期式回路として FPGA 上に実装し、ツールを適切に使うことで、正しく動作するものを作る、ということ目指しています。前回は、FPGA 上に実装する例題回路について、詳しく説明しました。また、同期式回路として設計した例題回路についても考えました。
前回述べたように、同期式版例題回路は直ちに FPGA 実装可能ですが、非同期式回路版については、FPGA 実装に当たっていくつか検討する事項があります。今回は、そのうちの一つである、遅延素子の実装について、実際にツールを使いながら解説していきたいと思います。なお、このコースではザイリンクスのツールである Vivado を使っています。使用している Vivado のバージョンは v2019.1 (64-bit) であり、OS は CentOS Linux release 7.5.1804です。
FPGAへの実装 (1)
以下は、このコースで考えている、非同期式版の例題回路です。
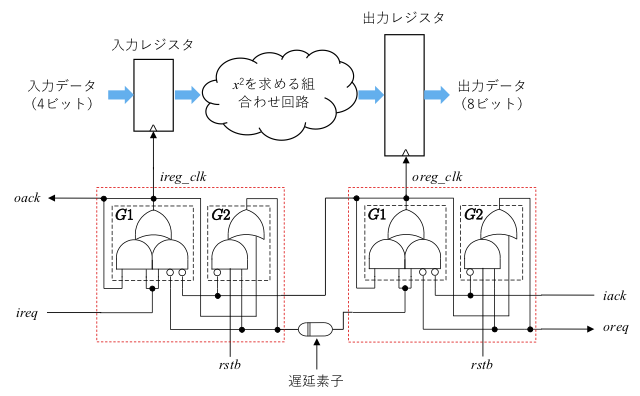
二つのハンドシェークコントローラ (赤点線で囲まれたブロック) の間に入っているのが遅延素子です。これは、前段のハンドシェイクコントローラが出力する要求信号を遅延させるものです。
前段のハンドシェイクコントローラが要求信号を出すタイミングと、入力レジスタに対するクロック信号(ireg_clk)により入力データ xが出力ポートに現れるのはほぼ同時です。このデータは、データパス上の組合わせ回路を通り、x2 の値となって出力レジスタに到達するわけですが、そのデータが確定した後、速やかに oreg_clk を出力する必要があります。このタイミングを生成するのが遅延素子です。すなわち、この遅延素子の遅延値としては、データパス回路の遅延値とほぼ同じものを設定することになります。この遅延素子 (あるいは遅延値) はデータパス回路の遅延に合わせる、という意味でマッチドディレイ (matched delay) とも呼ばれます。
以下では、所望の遅延値を持つ遅延素子をどうやって FPGA 上に実装するかについて、具体的に考えていきます。
実験用回路
遅延素子の実装実験を行うには、例題回路はやや複雑ですので、以下のように単純化した回路を考え、これを実験用回路と呼ぶことにします。
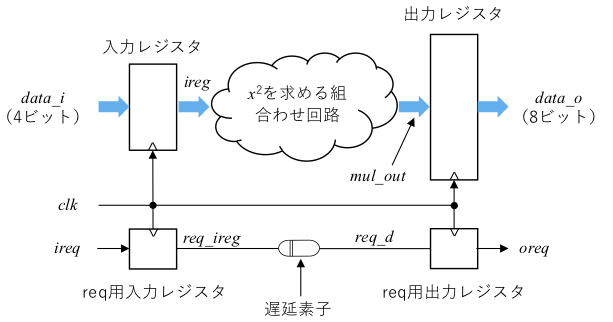
出力レジスタや req 用出力レジスタは今回の実験では不要ですが、内部のレジスタ間での組合わせ回路や遅延素子の遅延値を観測したいため、使用しています。
この回路の verilog 記述は以下のようになります。
module main(data_i, data_o,
ireq, oreq,
clk, rstb);
input [3:0] data_i;
output [7:0] data_o;
input ireq;
output oreq;
input clk;
input rstb;
reg [3:0] ireg;
reg [7:0] oreg;
reg req_ireg;
reg req_oreg;
wire [7:0] mul_out;
wire req_d;
always @(posedge clk, negedge rstb)
if (rstb == 1'b0) begin
ireg <= 0;
oreg <= 0;
req_ireg <= 0;
req_oreg <= 0;
end
else begin
ireg <= data_i;
req_ireg <= ireq;
oreg <= mul_out;
req_oreg <= req_d;
end
delay U_delay(.in(req_ireg), .out(req_d));
multi U_multi(.in(ireg), .out(mul_out));
assign data_o = oreg;
assign oreq = req_oreg;
endmodule // main
module multi(in, out);
input [3:0] in;
output [7:0] out;
assign out = in * in;
endmodule // multi遅延素子の部分は module delay ですが、ここでは単純な方法として、FPGA の LUT で単なるバッファを構成し、それを何段か繋げる方法で作っていきます。こんな感じです。
module delay(in, out);
input in;
output out;
wire w1;
wire w2;
wire w3;
LUT1 #( .INIT(2'b10) ) buf_inst1(.O(w1), .I0(in));
LUT1 #( .INIT(2'b10) ) buf_inst2(.O(w2), .I0(w1));
LUT1 #( .INIT(2'b10) ) buf_inst3(.O(out), .I0(w2));
endmodule // delayここで、LUT1 は Xilinx FPGA の1入力 LUT モジュールであり、.INIT に与える値によりその機能を表します。これは、真理値表と等価で、入力が0の場合の出力を LSB が、入力が1の場合の出力を MSB が示すので、この1入力 LUT はバッファとなります。
さて、これを3段直列に接続したわけですが、このままでは Vivado の論理最適化機能により、論理的に不要と見なされ、削除されてしまいます。これは、下記のように DONT_TOUCH 属性を各インスタンスに設定してやることで防げます。
module delay(in, out);
input in;
output out;
wire w1;
wire w2;
(* dont_touch = "true" *) LUT1 #( .INIT(2'b10) ) buf_inst1(.O(w1), .I0(in));
(* dont_touch = "true" *) LUT1 #( .INIT(2'b10) ) buf_inst2(.O(w2), .I0(w1));
(* dont_touch = "true" *) LUT1 #( .INIT(2'b10) ) buf_inst3(.O(out), .I0(w2));
endmodule // delay 実装の準備
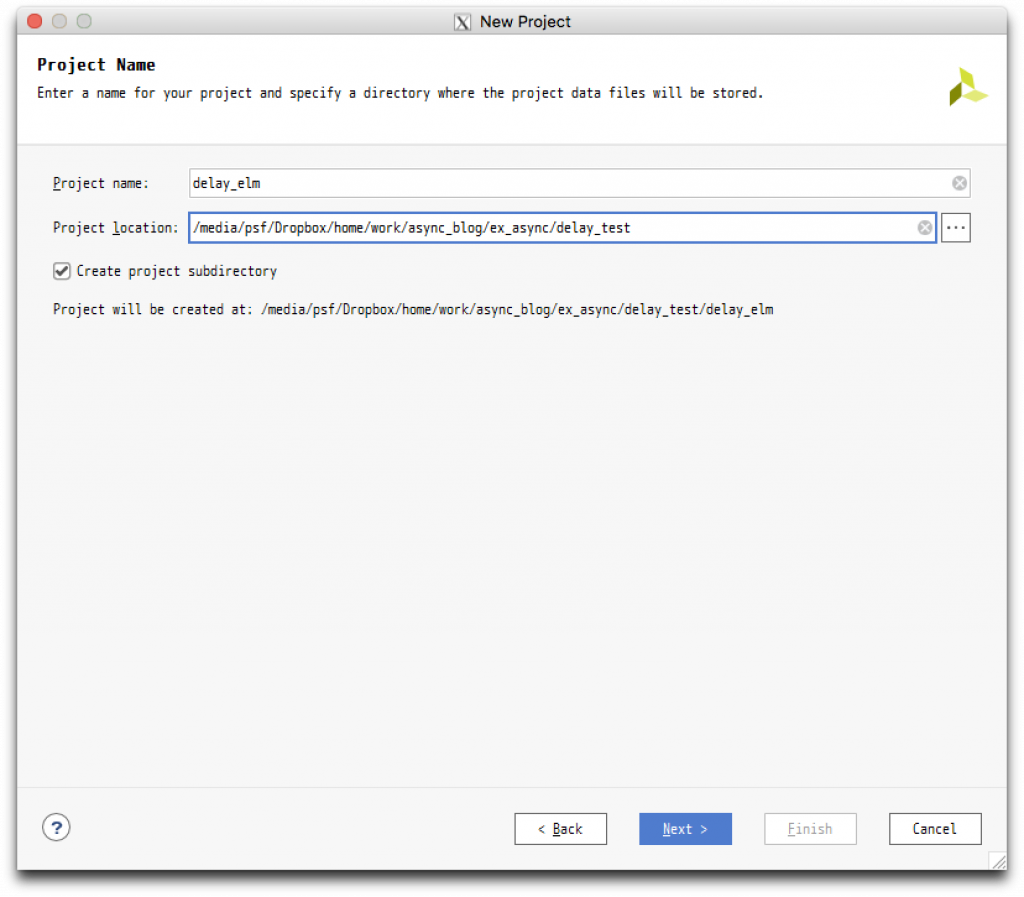
これらを合成・配置配線して、実際にどのような遅延が得られるか調べてみましょう。Vivado を起動して、新しいプロジェクトを作ります。プロジェクトディレクトリをdelay_test、プロジェクト名を delay_elm としておきます。
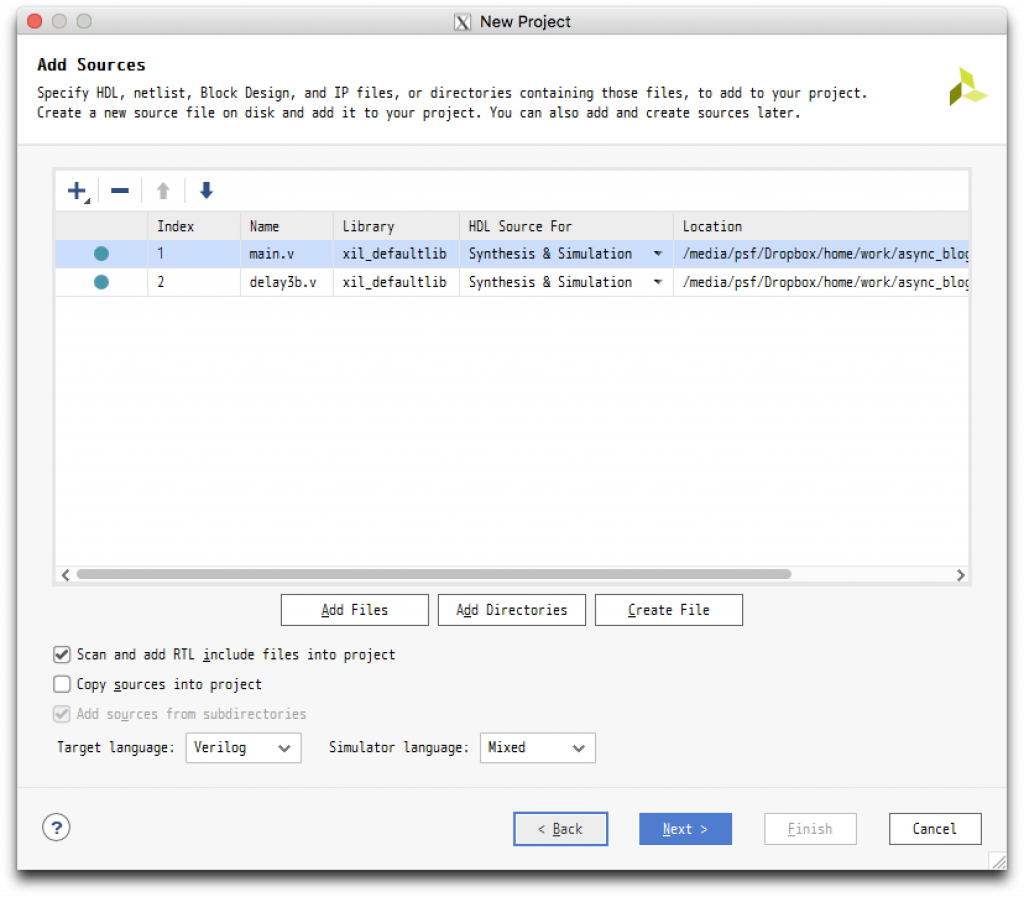
次の Project Type では RTL Project を選び(Do not specify sources at this time のチェックは外しておきます)、Add Sources では Add Files をクリックし、上に示した main.v, delay3b.v を加えます。
Add Constraints では何も入力せず、そのまま Next をクリックします。Default Part では、Parts -> xc7z020clg400-1か Boards -> PYNQ-Z1 を選んでおきます。今回と次回の内容に関しては、多少 FPGA のデバイス依存の事柄を含みます。他のデバイスへの変更は容易ですが、ここで紹介しているコードをそのまま使うのならば、同じデバイスを選んでおくことをお勧めします。最後に、New Project Summary では Finish をクリックします。
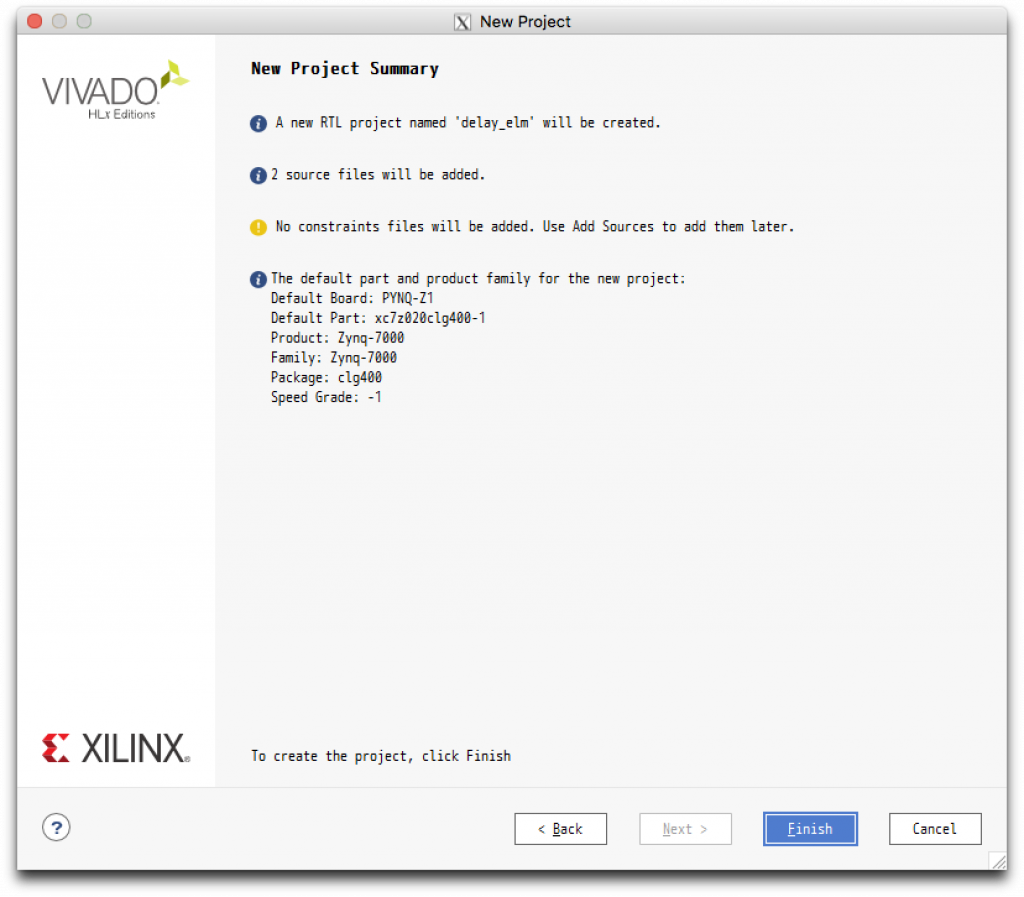
すると次のようなプロジェクトマネジャが表示されます。
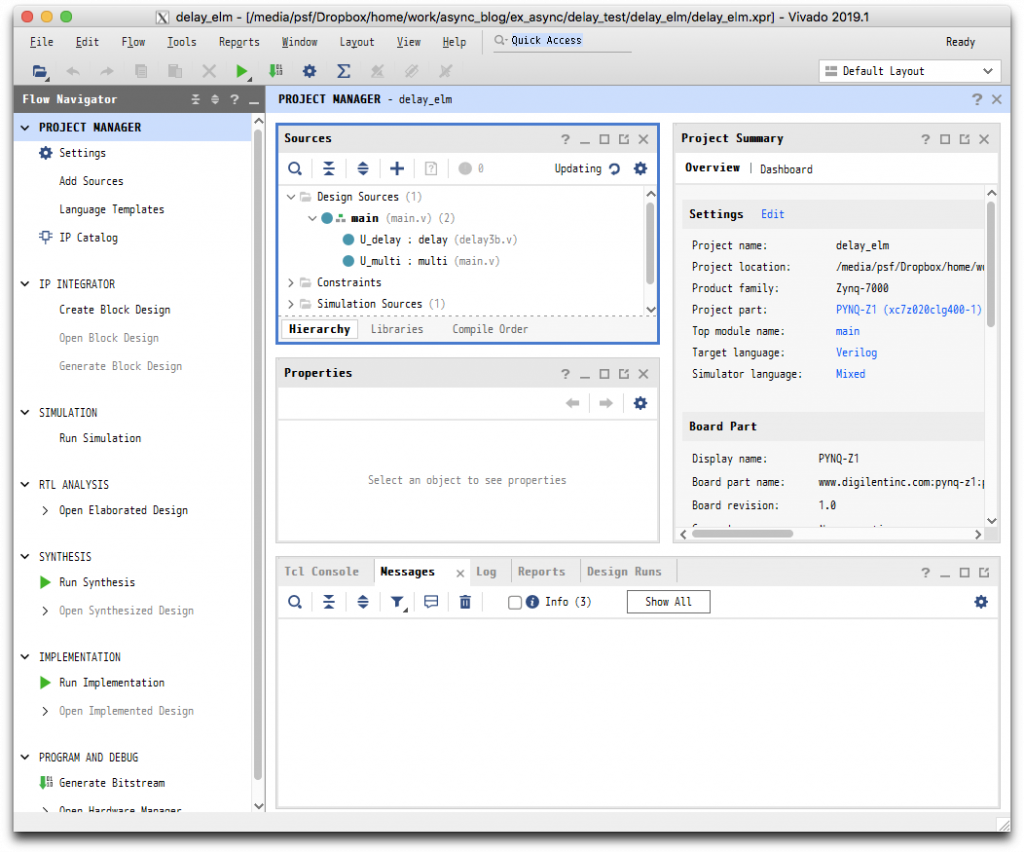
シミュレーションをわかりやすく行うために、ツールの設定を一つだけ変更しておきます。左の Flow Navigator の PROJECT MANAGER のすぐ下の Settings をクリックします。左の Project Settings の Synthesis をクリックし、下の方の Synth Design (Vivado)の flatten_hierarchy の値を rebuilt から none に変更します。これにより、モジュール階層が保たれるので、組合わせ回路の出力が見つけやすくなります。
OK をクリックし、設定変更を終了します。Create New Run と聞かれますが、この設定をこれからも使っていきますので、No と答えておきます。
実装
次に、左の Flow Navigator の下の方、IMPLEMENTATION の Run Implementation をクリックして、合成と配置配線を行います。Warning がいくつか出ますが、制約を与えていないためですので、取り敢えず無視して結構です。もし、Critical Warning が表示されるようなら何か入力ミスがあると思われるので、メッセージを確認してください。
ここで OK をクリックし、実装結果を開いておきます。
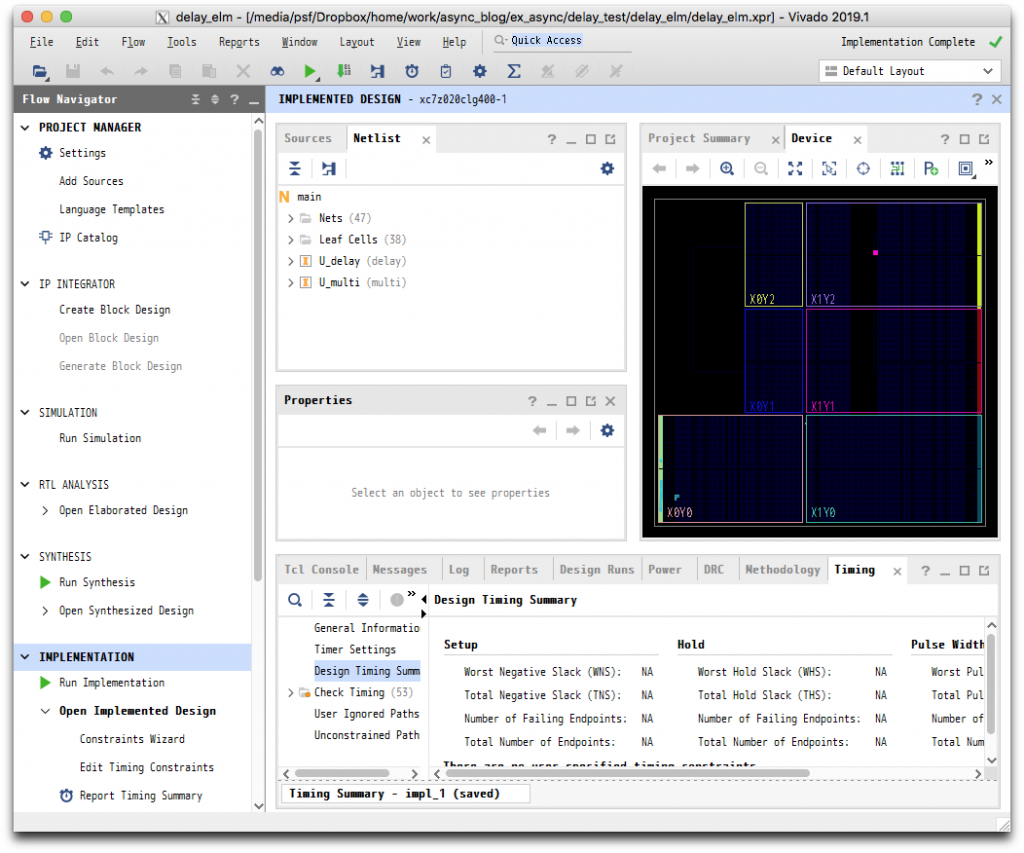
遅延素子の配置状況を確認するために、中央上の Netlist タブに示されている U_delay を開き、Leaf Cells に示される buf_inst1, buf_inst2, buf_inst3 を選択した上で、右上 Device タブの左から7番目 Auto-fit Selection をクリックします。これにより次のように表示されます。
Device タブに表示された白い箱が、LUT1のインスタンスとなります。現状では、どのインスタンスも同じスライスに配置されていることに注意してください。
論理シミュレーション
次に、論理シミュレーションを行い、この遅延素子がどれくらいの遅延を発生しているかを確認してみます。まず、テストベンチとして次のような簡単なものを考えます。
`timescale 1ns/1ps
module testmain;
reg [3:0] data_i;
wire [7:0] data_o;
reg ireq;
wire oreq;
reg clk;
reg rstb;
main U_main(.data_i(data_i), .data_o(data_o),
.ireq(ireq), .oreq(oreq),
.clk(clk), .rstb(rstb));
initial begin
#0 rstb = 0;
data_i = 0;
clk = 0;
ireq = 0;
#100 rstb = 1;
#90 data_i = 7;
ireq = 1;
#10 clk = 1;
end // initial begin
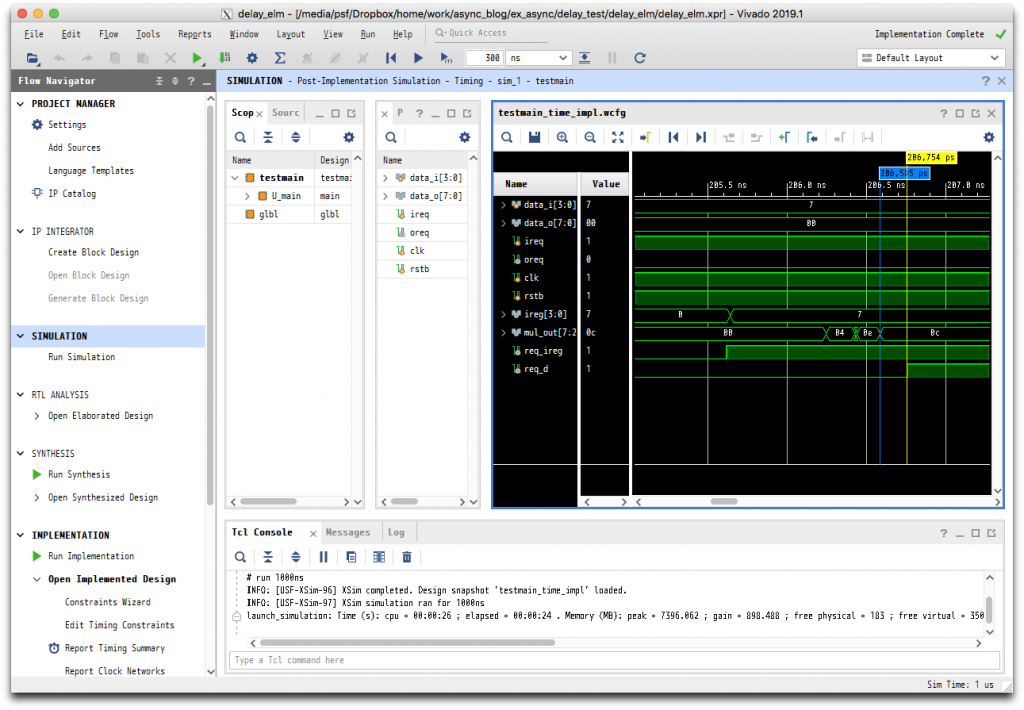
endmodule // testmain入力データとして7を与え、200ns のところで clk を立ち上げるだけです。実験用回路の図を参照していただくとわかると思いますが、この clk により入力レジスタの出力 ireg と req 用レジスタの出力 req_ireg がそれぞれ0 -> 7および0 -> 1と変化し、組合わせ回路の出力 mul_out はやがて49に、遅延素子の出力 req_d はやがて1となります。この mul_out の変化よりも後に req_d の変化が起これば、正しい遅延素子が実現できたことになります。
論理シミュレーションを行うためには、まず Flow navigator の PROJECT MANGER 内の Add Sources をクリックします。表示される Add Sources で Add or create simulation sources を選択し、次のパネルで Add Filesをクリックした上で、test_main.v を加えます。最後に Finish をクリックします。中央の Sources タブの Simulations Sources を開くと、testmainモジュールが追加されていればOKです。
左の Flow Navigator の SIMULATION の Run Simulation をクリックし、Run Post-Implementation Timing Simulation を選んで、シミュレーションを実行します。ここでは、シミュレーションにより遅延を見積りたいので、Timing Simulation を選択することが重要です。
シミュレーションが完了したら、SIMULATION ウィンドウ左側の Scope において U_main を選択し、その右に表示される信号名のうち、ireg, mul_out, req_ireg, req_d の各信号を波形表示ウィンドウにドラッグして、表示される信号線を追加します。SIMULATION ウィンドウの上にあるツールバーの一番右の Relaunch Simulation をクリックすると、再度シミュレーションが実行され、追加された信号線の波形も表示されるようになります。波形表示ウィンドウの Zoom Fit 等を実行したり、マーカを追加して得られたのが下図です。
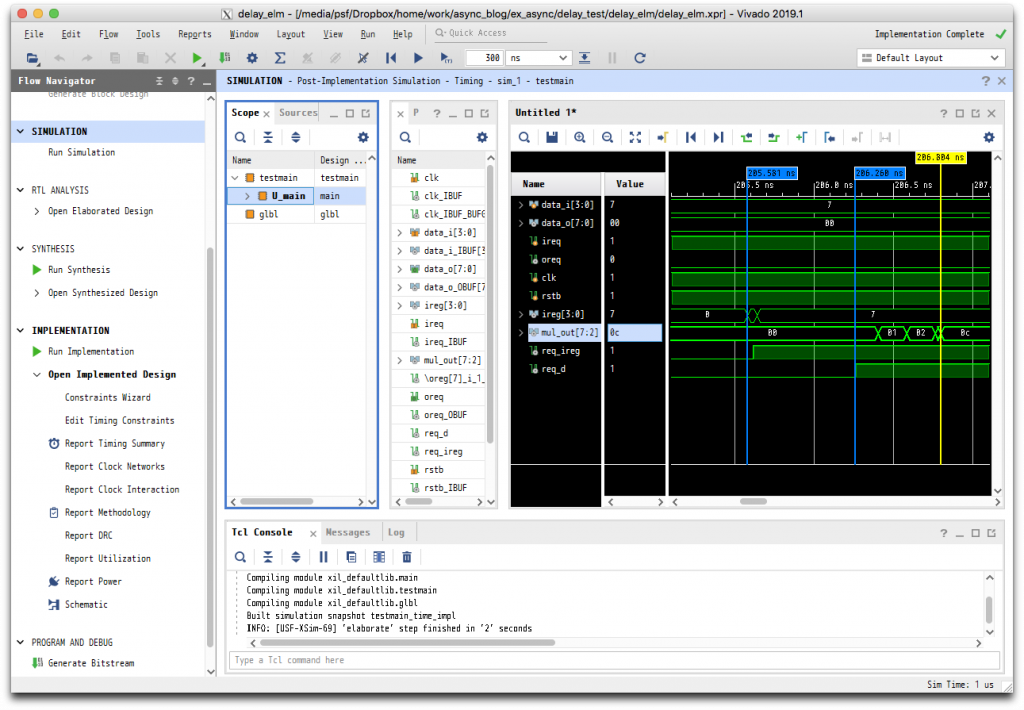
遅延値の測定
これからわかるように、mul_out の安定よりも先に req_d が立ち上がっています。なお、mul_out は[7:2]となっており、2乗の計算結果の下位2ビットが含まれていません。これは、x2 の場合、その下位2ビットは常に2’b0n(ただし、n=x[0])となるため、論理簡単化により mul_out[1]=0, mul_out[0]=x[0]という回路が生成されているからです。この例では、x=7であり、下位2ビットは2’b01となるため、演算結果としては8’b00110001=2’d49、すなわち、mul_out[7:2]=2’h0c となっています。
いずれにしても、遅延素子の遅延値が足りないので、LUT1の数を増やす必要があります。そこで、LUT1 の数を色々と変化させて実装し、その数と遅延値の関係を求めてみます。下図が、LUT1 の数を横軸に、シミュレーションで求めた req_ireg 〜 req_d の遅延値を縦軸にとったグラフです。

このように、LUT1 の数に対して遅延値はうまく変化してくれません。このようになる原因として、LUT1 の数が3までは、それらの LUT1 は同じスライスに配置されたのに対し、LUT1 の数が4以上になると異なるスライスにまたがって配置されるようになったためと考えられます。
このように、特に FPGA ではセルの配置により、その遅延値が大きく変わることがあるので、注意が必要です。なお、LUT1 の数を変える実験中に、x2を求める組合わせ回路部分の配置も若干変わるため、その遅延値も変化するという現象がみられました。このため、遅延素子の遅延を変えるため LUT1 の数を増やしても、組合わせ回路部分の遅延も変わってしまい、なかなか最適な遅延値を決定するのが難しいということが起こり得ます。
セルの配置固定
この問題を解決する方法としてよく取られるのが、セルの配置をコントロールし、ある程度固定してしまうという方法です。まず、LUT1 の数を1として実装します。配置結果は下図のようになりました。
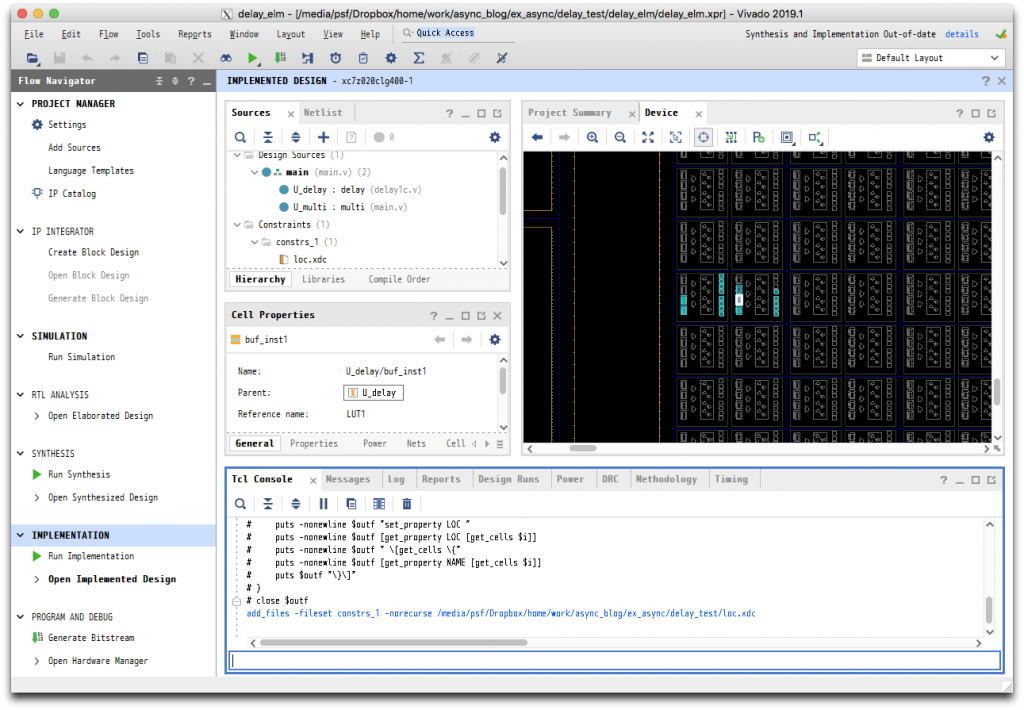
ツールは、レジスタ・組合わせ回路等を適切に配置してくれていると思います。そこで、遅延素子以外の配置を固定することにします。これには、現在の配置情報をファイルに書き出し、それを制約ファイルとして使うことで実現できます。次の TCL ファイル見てください。
set outf [open loc.xdc w]
set MY_CELLS [get_cells * -hier -filter "primitive_group == lut || primitive_group == flop_latch"]
foreach i $MY_CELLS {
puts -nonewline $outf "set_property BEL "
puts -nonewline $outf [get_property bel [get_cells $i]]
puts -nonewline $outf " \[get_cells \{"
puts -nonewline $outf [get_property NAME [get_cells $i]]
puts $outf "\}\]"
puts -nonewline $outf "set_property LOC "
puts -nonewline $outf [get_property LOC [get_cells $i]]
puts -nonewline $outf " \[get_cells \{"
puts -nonewline $outf [get_property NAME [get_cells $i]]
puts $outf "\}\]"
}
close $outfこれは、LUT, FLOP, LATCH のセルを階層を辿って MY_CELLS にリストアップし、その BEL 属性と LOC 属性を指定するコマンドを loc.xdc というファイルに書き出すものです。この TCL ファイルを例えば loc_source.tcl というファイルに格納しておき、プロジェクトマネジャの Tcl Console において、
source loc_source.tclを実行することで、loc.xdc というファイルが得られます。テキストエディタでこのファイルを開いてみると、LUT や FF セルの配置情報が書き出されていることがわかります。例えば、req_ireg や req_oreg を含む行は次のようになっています。
set_property BEL SLICEL.CFF [get_cells {req_ireg_reg}]
set_property LOC SLICE_X1Y11 [get_cells {req_ireg_reg}]
set_property BEL SLICEL.BFF [get_cells {req_oreg_reg}]
set_property LOC SLICE_X1Y11 [get_cells {req_oreg_reg}]LOC 属性の SLICE_ の後の部分 (XaYbの形式) はスライスの絶対位置を表しており、BEL 属性はスライスの中の位置やセルのタイプを表しています。最初の set_property は、req_ireg や req_oreg のセルにそのような属性を与えるコマンドであり、このファイルを制約ファイルとして与えることで、配置時にセルの位置が指定されることになります。
このファイルには、遅延素子の配置も表示されていますが、遅延素子は後述するように相対位置指定するので、コメントアウトしておきます。
# set_property BEL SLICEL.B6LUT [get_cells {U_delay/buf_inst1}]
# set_property LOC SLICE_X1Y11 [get_cells {U_delay/buf_inst1}]loc.xdcをテキストエディタで開き、’U_delay’を含む行の頭に’# ‘を付加すればOKです。
このファイルを制約ファイルとして Vivado に登録するため、プロジェクトマネジャで、File Navigator の直下のPROJECT MANAGER の2番目、Add Sources をクリックし、Add Sources パネルから Add or create design constraints を選択して、次のパネルで loc.xdc を追加して、Finish をクリックします。中央上の Sources タブから Constraints を開いて、constrs_1 の下に loc.xdc が表示されていることを確認します。
最後に、遅延素子の LUT1 の配置を指定します。上記のように絶対位置でセルの指定をしても、もちろんいいのですが、LUT1 の数を変えるごとに絶対値を指定するのはやや面倒です。そこで、下記のように Verilog ソースにおいて相対位置を指定します (配置の状況を把握しやすいように LUT1 の数を5に増やしてあります)。
module delay(in, out);
input in;
output out;
wire w1;
wire w2;
wire w3;
wire w4;
(* dont_touch = "true" *) (* RLOC = "X1Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst1(.O(w1), .I0(in));
(* dont_touch = "true" *) (* RLOC = "X2Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst2(.O(w2), .I0(w1));
(* dont_touch = "true" *) (* RLOC = "X3Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst3(.O(w3), .I0(w2));
(* dont_touch = "true" *) (* RLOC = "X4Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst4(.O(w4), .I0(w3));
(* dont_touch = "true" *) (* RLOC = "X5Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst5(.O(out), .I0(w4));
endmodule // delayRLOC 属性としてスライスの相対座標を与えています。これを用いて実装した結果、下図のように配置されました。
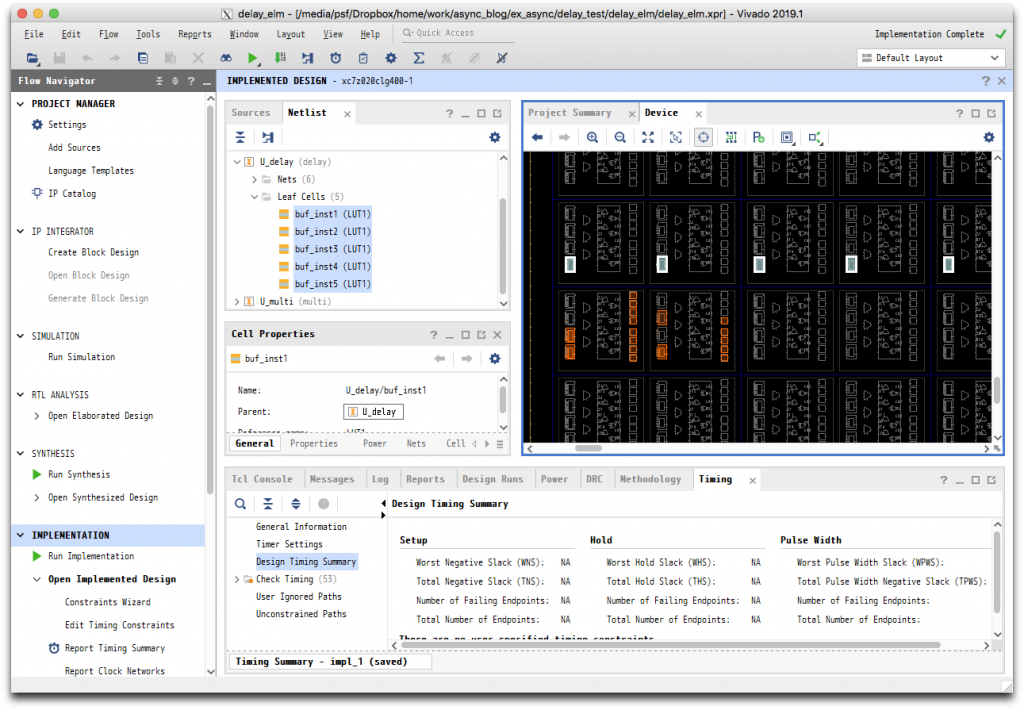
赤く示されているセルが loc.xdc で絶対位置を指定したセルで、遅延素子は白く示された5つのセルです。このように指定した相対位置で配置されていることがわかります。これらのセル指定を用いて、再度 LUT1 の数を変えて実装し、シミュレーションにより遅延値を測定してみます。結果は次のようになりました。
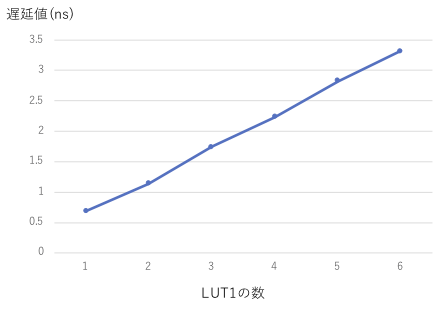
このように、遅延値はほぼ LUT1 の数に比例するようになりました。また、組合わせ回路部分も、位置が固定されているので、その遅延値は変化しませんでした。この方法を用いれば、最適な遅延値を比較的容易に求めることができることになります。
この方法を用いて、遅延素子の出力である req_d の立ち上がりが、組合わせ回路の出力である mul_out の確定よりもやや遅くなるものを選ぶと、結局 LUT1 は2個でいいことがわかりました。この場合のシミュレーション結果を以下に示します。
まとめ
今回は、遅延素子の実装方法とその遅延値の調整方法について考えてみました。セルの配置を制約しないと遅延値の調整が難しいこと、そして絶対位置や相対位置を指定して配置位置を固定することで、遅延値の調整が容易になる、ということを紹介しました。
この話の中では、シミュレーションにより遅延素子の遅延と組合わせ回路の遅延を比較しましたが、厳密にはこれでは不十分です。なぜなら、組合わせ回路部分の遅延値は、入力データにより変化するからです。上記の例では x=7 について正しく動作する遅延素子を求めましたが、他の x の値に対しては遅延値が不足するかもしれません。これを厳密に行うには、組合わせ回路部分のクリティカルパスを見つける必要があるのですが、手作業で行うのは大変です。
幸いなことに、大抵のツールにはクリティカルパスを解析し、いろいろなパスの遅延を比較する機能が用意されています。この機能を静的タイミング解析 (Static Timing Analysis: STA) と呼びますが、同期式回路のクロック信号を前提として動作しますので、非同期式回路においてこれを使いこなすには、いくつかのテクニックを必要とします。
次回の最終回では、そのような STA のためのテクニックを紹介し、前回取り上げた例題回路に Vivado の STA 機能を適用してみます。
国立情報学研究所 米田友洋