
みなさん、こんにちは。いよいよこのコースも最終回となりました。今回は、第3回で考えた例題回路の非同期式回路を実際に FPGA 上に実装します。
また、正しく動作する実装を得るために、Vivado の静的タイミング解析機能 (以後、STA エンジンと言うこともあります) をどのように非同期式回路に適用するか、という点について考えていきたいと思います。
FPGA への実装 (2)
例題回路の復習
まず、例題回路の復習です。回路の構成は下記のようになっていました。
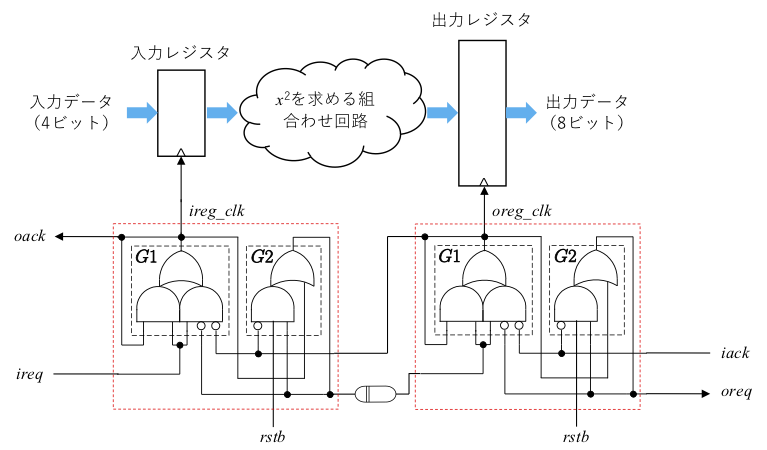
第3回では、RTL シミュレーションを行うために、仮の遅延値を Verilog 記述に設定していましたが、今回は実際に回路を合成するので、Verilog 記述から遅延値は削除します。また、マッチドディレイに対しては、前回検討した遅延素子を用います。さらに、ハンドシェイクコントローラですが、G1とG2の部分が論理最適化されてしまうとゲートの遅延を想定して設計してあった組合わせループが正しく機能しなくなります (下手をすると発振回路のようになってしまいます)。そこで、G1とG2の出力線が最適化されて消されてしまわないように、DONT_TOUCH 属性をそれらの wire 宣言に設定します。その他、2乗を計算する部分もモジュール化しておきます。全体の Verilog 記述は以下のようになります。
module delay(in, out);
input in;
output out;
wire w1;
(* dont_touch = "true" *) (* RLOC = "X1Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst1(.O(w1), .I0(in));
(* dont_touch = "true" *) (* RLOC = "X2Y0" *) LUT1 #( .INIT(2'b10) ) buf_inst3(.O(out), .I0(w1));
endmodule // delay
module hs_cont(ireq, oack,
oreq, iack,
clk, rstb);
input ireq;
output oack;
output oreq;
input iack;
output clk;
input rstb;
(* dont_touch = "true" *) wire G1_out;
(* dont_touch = "true" *) wire G2_out;
assign G1_out = (ireq & G1_out) | (ireq & ~G2_out & ~iack);
assign G2_out = (G2_out & ~iack & rstb) | G1_out;
assign oack = G1_out;
assign clk = G1_out;
assign oreq = G2_out;
endmodule // hs_cont
module controller(ireq, oack,
oreq, iack,
ireg_clk, oreg_clk,
rstb);
input ireq;
output oack;
output oreq;
input iack;
output ireg_clk;
output oreg_clk;
input rstb;
wire in_req1, in_req2;
wire in_ack;
hs_cont U_ireg_cont(.ireq(ireq), .oack(oack),
.oreq(in_req1), .iack(in_ack),
.clk(ireg_clk), .rstb(rstb));
hs_cont U_oreg_cont(.ireq(in_req2), .oack(in_ack),
.oreq(oreq), .iack(iack),
.clk(oreg_clk), .rstb(rstb));
delay U_delay(.in(in_req1), .out(in_req2));
endmodule // controller
module multi(in, out);
input [3:0] in;
output [7:0] out;
assign out = in * in;
endmodule // multi
module main(data_i, data_o,
ireq, oack,
oreq, iack,
rstb);
input [3:0] data_i;
output [7:0] data_o;
input ireq;
output oack;
output oreq;
input iack;
input rstb;
reg [3:0] ireg;
reg [7:0] oreg;
wire [7:0] mul_out;
wire ireg_clk;
wire oreg_clk;
controller U_cont(.ireq(ireq), .oack(oack),
.oreq(oreq), .iack(iack),
.ireg_clk(ireg_clk), .oreg_clk(oreg_clk),
.rstb(rstb));
always @(posedge ireg_clk, negedge rstb) begin
if (rstb == 1'b0)
ireg <= 0;
else
ireg <= data_i;
end
always @(posedge oreg_clk, negedge rstb) begin
if (rstb == 1'b0)
oreg <= 0;
else
oreg <= mul_out;
end
multi U_multi(.in(ireg), .out(mul_out));
assign data_o = oreg;
endmodule // main
例題回路の実装と論理シミュレーション
前回と同様に、Vivadoを起動し、新しいプロジェクトを作ります。プロジェクトディレクトリを main_impl, プロジェクト名を main としておきます。また、Add Sources で上記の Verilog 記述を design sources として登録しておきます。さらに、Settings で Synthesis -> Synth Design -> flatten_hierarchy を none と変更します。これも前回と同様です。それでは、IMPLEMENTATION から Run Implementation を実行してみましょう。
実装が問題なく行えたら、次に論理シミュレーションを実行してみます。第3回で掲載した async_test_main.v を Add Sources から Add or create simulation sources を選んで、追加します。SIMULATION -> Run Simulation -> Run Post-Implementation Timing Simulation を実行すると次のような結果が得られます。波形ウィンドウには、mul_out と遅延素子の入出力である in_req1, in_req2を追加しています。
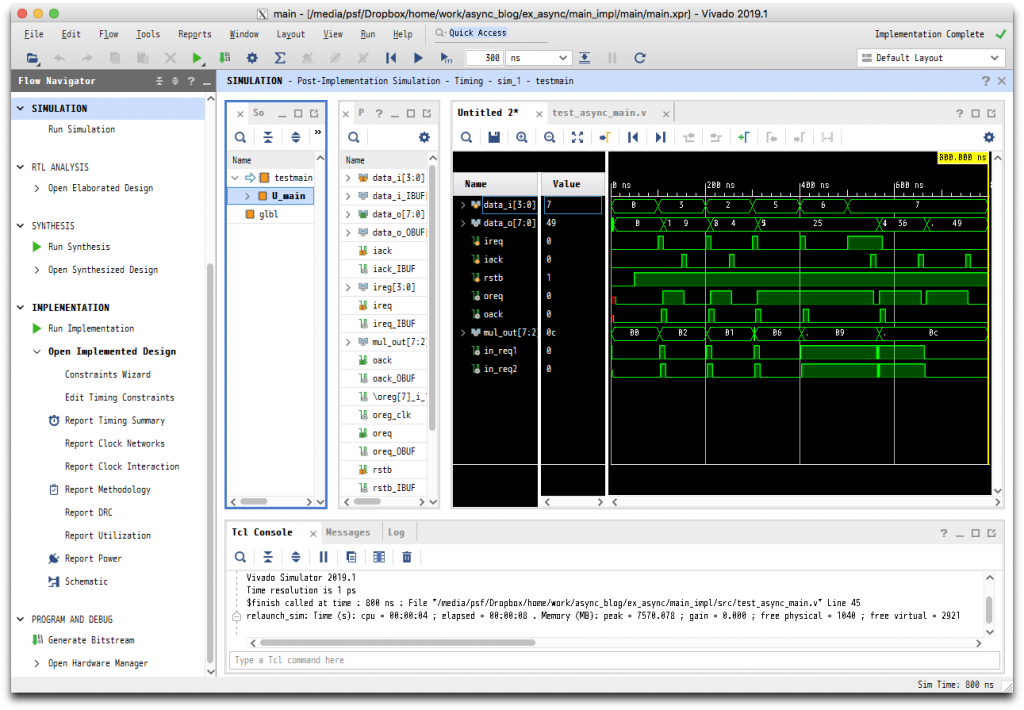
第3回の RTL シミュレーションと同じ結果が得られています。特に、in_req2 の各立ち上がりにおいて mul_out の確定タイミングを見てみると、いずれも in_req2 の立ち上がりが若干遅くなっており、マッチドディレイとして正しく動作しているように見えます。実際、出力レジスタには正しい x2の値が格納されています。ただし、前回の終わりでも述べましたが、他の x の値に対しても正しく動作する保証はないわけで、次の静的タイミング解析が必要になります。
同期式回路の静的タイミング解析
まず、比較のために、同期式回路に対する静的タイミング解析を見てみます。そのために、第3回で考えた、例題回路の同期式版を実装してみます。通常通り、新規プロジェクト作成を行い、sync_cont.v, sync_main.v を design sources として登録した後、Run Implementation を実行します。最初は、制約は与えません。次に、test_main_sync.v を simulation sourcesとして登録し、SIMULATION -> Run Simulation -> Run Post-Implementation Timing Simulation を実行すると所望の動作が行われていることがわかります。
次にタイミング解析を行うために、タイミング制約を設定します。このために、次のような内容のファイル timing.xdc を作り、それを Vivado に Add Sources -> Add or create constrainsから登録します。なお、これはタイミング制約違反を解説するために、クロック周期を1.5ns (クロック周波数666MHz) と非常に短く設定したものです。
create_clock -name CLK -period 1.5 [get_ports clk]その後、いつものように Run Implementation を実行すると、プロジェクトマネジャの中央下のパネルに Timing というタブが現れ、ここに Setup や Hold に関する slack が表示されます。
セットアップ時間解析
まず、セットアップ時間解析に関する情報を詳しく見るために、Tcl Console において次のTcl コマンドを実行します。
report_timing -setup -through [get_pins oreg_reg*/D] -no_report_unconstrained -file setup.rptこれも解説の都合上、データパス回路を通るパス (出力レジスタ oreg_reg の入力ピン Dに至るパス) を選択的に選んでいます。これにより、setup.rpt というファイルが作られ、セットアップ時間解析に関するパスや遅延の情報がレポートされます。以下は、その一部を示したものです。
Location Delay type Incr(ns) Path(ns) Netlist Resource(s)
------------------------------------------------------------------- -------------------
(clock CLK rise edge) 0.000 0.000 r
U7 0.000 0.000 r clk (IN)
net (fo=0) 0.000 0.000 clk
U7 IBUF (Prop_ibuf_I_O) 1.058 1.058 r clk_IBUF_inst/O
net (fo=1, routed) 2.171 3.229 clk_IBUF
BUFGCTRL_X0Y0 BUFG (Prop_bufg_I_O) 0.101 3.330 r clk_IBUF_BUFG_inst/O
net (fo=14, routed) 1.817 5.147 clk_IBUF_BUFG
SLICE_X0Y23 FDRE r ireg_reg[2]/C
------------------------------------------------------------------- -------------------
SLICE_X0Y23 FDRE (Prop_fdre_C_Q) 0.478 5.625 r ireg_reg[2]/Q
net (fo=5, routed) 0.821 6.446 ireg[2]
SLICE_X0Y22 LUT3 (Prop_lut3_I2_O) 0.301 6.747 r oreg[3]_i_1/O
net (fo=1, routed) 0.000 6.747 oreg[3]_i_1_n_0
SLICE_X0Y22 FDRE r oreg_reg[3]/D
------------------------------------------------------------------- -------------------
(clock CLK rise edge) 1.500 1.500 r
U7 0.000 1.500 r clk (IN)
net (fo=0) 0.000 1.500 clk
U7 IBUF (Prop_ibuf_I_O) 0.924 2.424 r clk_IBUF_inst/O
net (fo=1, routed) 1.972 4.396 clk_IBUF
BUFGCTRL_X0Y0 BUFG (Prop_bufg_I_O) 0.091 4.487 r clk_IBUF_BUFG_inst/O
net (fo=14, routed) 1.642 6.129 clk_IBUF_BUFG
SLICE_X0Y22 FDRE r oreg_reg[3]/C
clock pessimism 0.497 6.626
clock uncertainty -0.035 6.591
SLICE_X0Y22 FDRE (Setup_fdre_C_D) 0.077 6.668 oreg_reg[3]
-------------------------------------------------------------------
required time 6.668
arrival time -6.747
-------------------------------------------------------------------
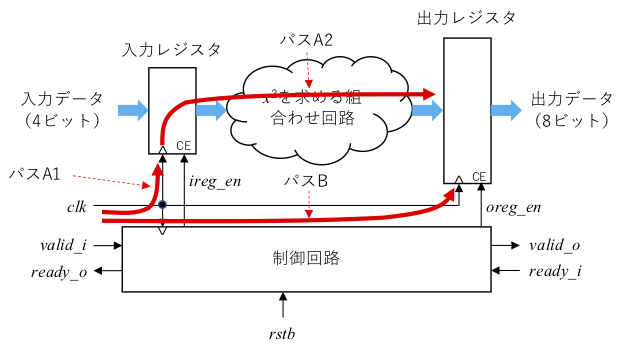
slack -0.079 これを同期式回路のブロック図(下図)といっしょに見ていきましょう。
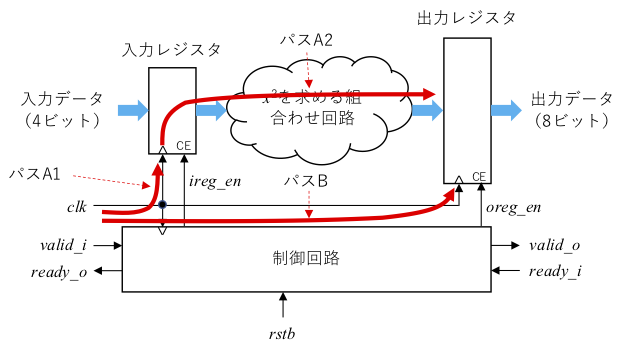
レポートの3行目から10行目は上図のパス A1に、12行目から16行目はパス A2に、そして19行目から26行目はパス B にそれぞれ対応します。29行目はレジスタに必要となるセットアップ時間です (本来は、required time を求めるのにセットアップ時間は減ずるべきですが、この例では加算されています。これはセットアップ時間がマイナス値ということだと思うのですが、間違いならどなたかご指摘ください)。19行目で1クロック分の幅である1.5ns を加えていることに注意してください。これらの関係は下図のようになります。
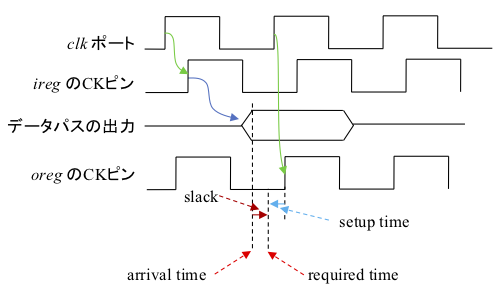
すなわち、
- Required time: (クロック1サイクル分) + (デスティネーションレジスタへのクロックネットワーク遅延) ー (セットアップ時間)
- Arrival time: (ソースレジスタへのクロックネットワーク遅延) + (ソースレジスタからデスティネーションレジスタまでの最大回路遅延)
- Slack: (Required time) ー (Arrival time)
となります。この slack が正となる場合に、セットアップ時間制約を満足することになります。上記のレポートの例では、arrival time の方が6.747ns と required time の6.668ns よりも大きいため、slackは -0.079と負になり、セットアップ時間制約を満足していないことを表しています。これは、クロック周期を大きくすることで解決できます。なお、最悪の場合を考えるということで、組合わせ回路部分についてはその最長パス部分を用いて、上記の計算を行います。また、プロセス条件によっても遅延時間は変わりますが、Vivado では4つのプロセスコーナを試して、もっとも slack が小さくなるものを選ぶようです。
このように、同期式回路ではクロック信号によりすべてのレジスタが同期して動作するため、セットアップ時間解析の required time の計算では、クロック信号の次の立ち上がりが基準点となることに注意してください。
ホールド時間解析
次に、ホールド時間解析を見てみます。Tcl Console において次のTcl コマンドを実行します(Run Implementation を実行し直す必要はありません)。
report_timing -hold -no_report_unconstrained -file hold.rpthold.rpt というファイルが作られ、ホールド時間解析に関するパスや遅延の情報がレポートされます。以下は、その一部を示したものです。
Location Delay type Incr(ns) Path(ns) Netlist Resource(s)
------------------------------------------------------------------- -------------------
(clock CLK rise edge) 0.000 0.000 r
U7 0.000 0.000 r clk (IN)
net (fo=0) 0.000 0.000 clk
U7 IBUF (Prop_ibuf_I_O) 0.286 0.286 r clk_IBUF_inst/O
net (fo=1, routed) 0.663 0.949 clk_IBUF
BUFGCTRL_X0Y0 BUFG (Prop_bufg_I_O) 0.026 0.975 r clk_IBUF_BUFG_inst/O
net (fo=14, routed) 0.611 1.586 clk_IBUF_BUFG
SLICE_X0Y23 FDRE r ireg_reg[0]/C
------------------------------------------------------------------- -------------------
SLICE_X0Y23 FDRE (Prop_fdre_C_Q) 0.164 1.750 r ireg_reg[0]/Q
net (fo=5, routed) 0.131 1.881 ireg[0]
SLICE_X0Y22 FDRE r oreg_reg[0]/D
------------------------------------------------------------------- -------------------
(clock CLK rise edge) 0.000 0.000 r
U7 0.000 0.000 r clk (IN)
net (fo=0) 0.000 0.000 clk
U7 IBUF (Prop_ibuf_I_O) 0.476 0.476 r clk_IBUF_inst/O
net (fo=1, routed) 0.719 1.195 clk_IBUF
BUFGCTRL_X0Y0 BUFG (Prop_bufg_I_O) 0.029 1.224 r clk_IBUF_BUFG_inst/O
net (fo=14, routed) 0.880 2.104 clk_IBUF_BUFG
SLICE_X0Y22 FDRE r oreg_reg[0]/C
clock pessimism -0.503 1.601
SLICE_X0Y22 FDRE (Hold_fdre_C_D) 0.053 1.654 oreg_reg[0]
-------------------------------------------------------------------
required time -1.654
arrival time 1.881
-------------------------------------------------------------------
slack 0.227 この場合に着目されているパスも基本的に上記と同じですが、いくつか違いがあります。まず、ホールド時間解析の最悪の場合は、組合わせ回路部分の遅延がもっとも小さいパスが使われます。12行目から14行目は下図 (上記の図と同じものです) のパス A2 の組合わせ回路部ですが、もっとも遅延の少ない、すなわち配線だけの ireg[0]/Q -> oreg[0]/D というパスが選ばれています。また、プロセスコーナも下記 slack が最も小さくなる場合が選ばれます。例えばレポートの3行目から10行目はパス A1 に対応していますが、遅延値が 1.586ns とセットアップ時間解析と比べて大幅に小さいことがわかります。さらに、デスティネーションレジスタとソースレジスタは同じクロックタイミングにおいて解析されますので、セットアップ解析のように、1クロック分の幅を加えるということはしていません。
これらの関係は下図のようになります。
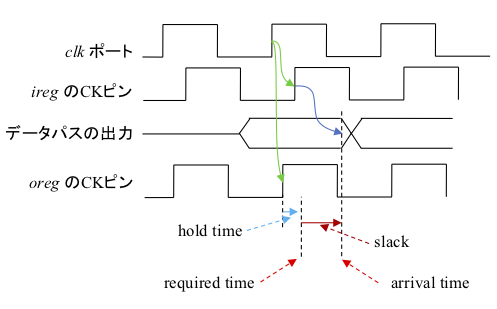
すなわち、
- Required time: (デスティネーションレジスタへのクロックネットワーク遅延) +(ホールド時間)
- Arrival time: (ソースレジスタへのクロックネットワーク遅延) + (ソースレジスタからデスティネーションレジスタまでの最小回路遅延)
- Slack: (Arrival time) ー (Required time)
となります。この slack が正となる場合に、ホールド時間制約を満足することになります。上記のレポートの例では、arrival time の方が 1.881ns とrequired time の 1.654ns よりも大きいため、slack は 0.227と正になり、ホールド時間制約を満足していることを表しています。なお、ホールド時間制約は一般的にクロックサイクル時間にはほどんど影響を受けませんので、ホールド時間制約が満足されない場合は、クロック周波数を下げても、違反が解消されることはないと思います。
他にも検査されるタイミング制約はありますが、ここではもっとも重要な2つのタイミング制約について、同期式の場合について紹介しました。同期式の場合、このようにクロック信号ごとに一つの create_clock 制約を与えるだけで、STA エンジンはそのクロックを使っているすべてのレジスタのタイミング解析を行ってくれます。
非同期式回路の静的タイミング解析
非同期式回路の静的タイミング解析も、基本的には同期式回路と同様で、次のようなパスの遅延を比較することで行います。
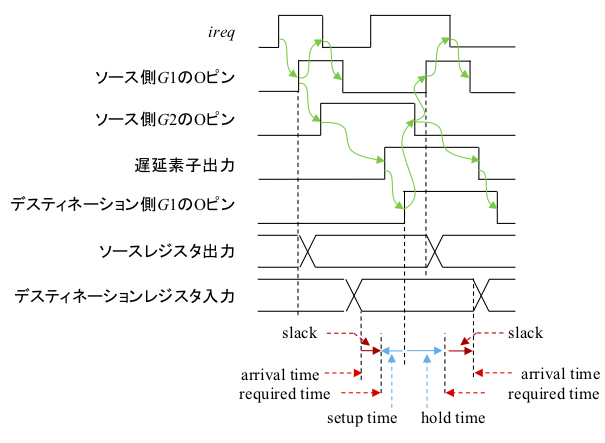
まず、今回冒頭で述べたように、非同期式回路の実装を行います。この際には、timing.xdc のような制約ファイルは与えません。create_clock のようなコマンドは、実装終了後、タイミング解析時に与えます。
セットアップ時間解析
パスの検討
セットアップ時間解析から見ていきます。具体的なパスは、次のようになります。
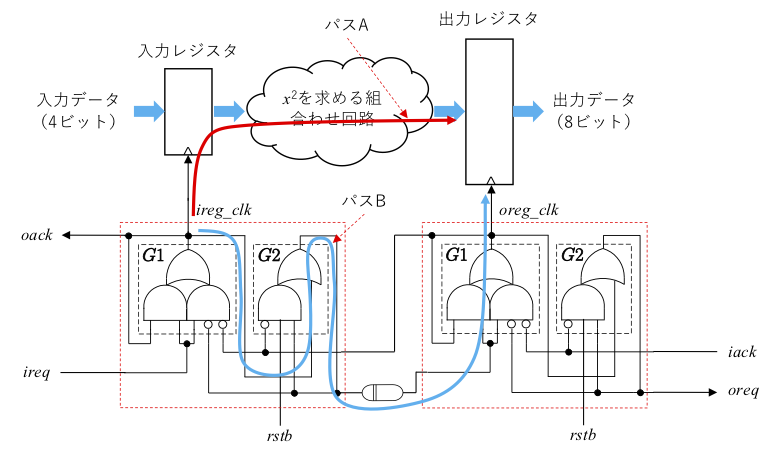
この場合の required time, arrival time は以下の通りです。
- Required time: (ソース側 oreq 出力遅延) + (遅延素子の遅延) + (デスティネーション側 ireq からデスティネーションレジスタクロックピンまでの遅延) ー (セットアップ時間)
- Arrival time: (ソースレジスタクロックピンまでの遅延) + (ソースレジスタからデスティネーションレジスタまでの最大回路遅延)
- Slack: (Required time) ー (Arrival time)
非同期式回路では共通のグローバルクロックは存在しないので、ソースレジスタごとにそれらのパスの共通の起点を create_clock に設定します。上図では、パスの共通の起点は ireg_clk すなわちソース側 G1 の出力ですので、これは次のようになります。これを、Tcl Console において与えます。
create_clock -name STU1 -period 0.001 [get_pins U_cont/U_ireg_cont/G1_out_inferred_i_1/O]name には create_clock を識別できるように適当な名前を、また、クロック周期は使いませんので、period にはエラーとならない範囲で小さい値を与えます。
非同期式回路のセットアップ解析では、もう一つ注意すべき点があります。required time 計算時に、同期式の場合とは異なり、クロック1サイクル分を加えることはしません (そもそもクロック1サイクルという概念がありません)。これは、STA エンジン側からすると、required time と arrival time を同じクロッックタイミングで計算することを意味します。STA エンジンにとっては、required time は次のクロックエッジから計算することがデフォールト設定になっているので、これを指示してやる必要があります。これを行うために、以下のコマンドを使います。
set_multicycle_path 0 -setup -to [all_clocks]本来このコマンドは、同期式回路においては、複数サイクル必要な演算器を使う場合のために設けられているのですが、非同期式回路ではセットアップ時間解析を行うために、マルチサイクル数を0として使います。
あとは、セットアップ時間解析を行うために、同期式の場合と同様に次の Tcl コマンドを実行しますが、実はこれは正しく動作しません。
report_timing -setup -no_report_unconstrained -file setup.rpt組合わせループのカット
一般に STA エンジンは、解析しようとする回路が組合わせループを含む場合に、正しくタイミング解析を行うことができません。上記で、セットアップ時間解析が正しく行われないのはこのためです。ここで言う組合わせループとは、フリップフロップやラッチを含まないループです。同期式回路はあまり組合わせループを含むことはありませんが、非同期式回路は通常、組合わせループを多数含みます。例題回路には以下のような組合わせループが存在します。
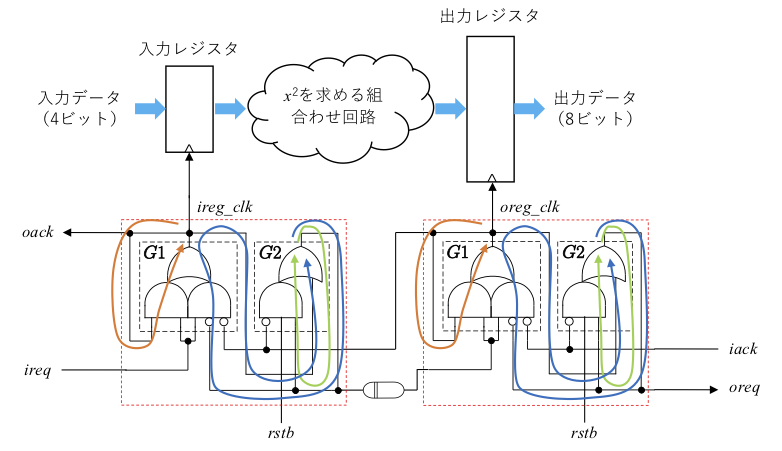
これらはハンドシェィクコントローラ内部のループです。一方、ハンドシェイクコントローラ間の要求信号と応答信号にまたがる次のようなループも存在します。
このループは、紫の部分のように分岐し、合流しています。これらのループは、Vivado の場合、次のコマンドを Tcl Console に入力することでファイルに書き出すことができます。
check_timing -verbose -override_defaults {loops} -file "loops.rpt"STA エンジンに正しく解析を行わせるために、このような組合わせループを切断する必要があります。ただし、切るといっても、回路に変更を加えるのではなく、STA エンジン内に構築されているタイミングパス内のループを切ることになります。これを行う Tcl コマンドは set_disable_timing です。
例えば、上図のソース側ハンドシェイクコントローラ内のオレンジのループは loops.rpt に次のように出力されます。
U_cont/U_ireg_cont/G1_out_inferred_i_1/O
U_cont/U_ireg_cont/G1_out_inferred_i_1/I0
U_cont/U_ireg_cont/G1_out_inferred_i_1/Oこれらはピン名のリストになっていますが、その命名規則はインスタンス名とセル名を”/”でつなぎ、最後にセルのピン名をつなげたものになっています。RTL 記述で assign や always から作成されたセルには独自の名前が付加されます。慣れてくると容易に想像がつきますが、正確にはシミュレーションを行う際に用いられる下記の Verilog ファイルを参照してください (なおこれは、プロジェクト名はmain、テストベンチ名はtestmain.v の場合です)。
(プロジェクトディレクトリ)/main.sim/sim.1/impl/timing/xsim/testmain_time_impl.vこのループを切るには、次のようなコマンドを与えます。
set_disable_timing -from I0 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]同様に、両方のコントローラのオレンジ、緑、青のループを切ります。
set_disable_timing -from I0 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]これら6つの set_disable_timing コマンドを与えたのち、再度 check_timing コマンドを実行すると、ハンドシェイクコントローラ間のループが次のように残ります。
U_cont/U_oreg_cont/G1_out_inferred_i_1/O
U_cont/U_ireg_cont/G2_out_inferred_i_1/I1
U_cont/U_ireg_cont/G2_out_inferred_i_1/O
U_cont/U_delay/buf_inst1/I0
U_cont/U_delay/buf_inst1/O
U_cont/U_delay/buf_inst3/I0
U_cont/U_delay/buf_inst3/O
U_cont/U_oreg_cont/G1_out_inferred_i_1/I3
U_cont/U_oreg_cont/G1_out_inferred_i_1/Oこれは赤のループのみであることに注意してください。分岐するようなループは Vivado の場合、そのうちのひとつのみを認識するようです。
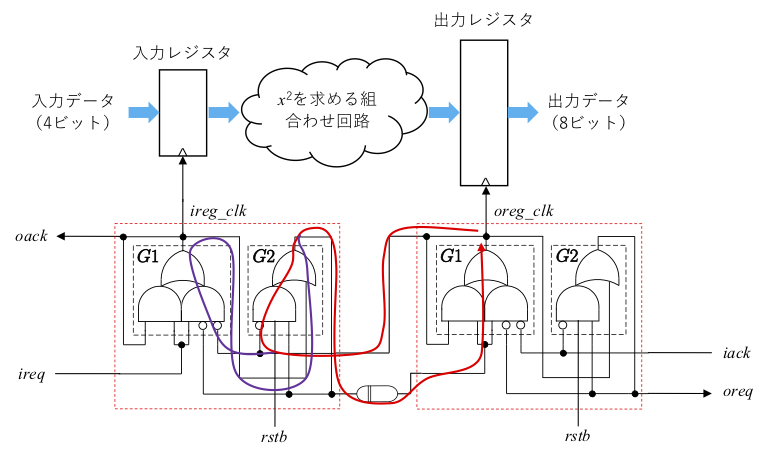
赤の部分も紫の部分も一度に切るには、遅延素子やデスティネーション側の G1 内で切ればいいのですが、そうするとセットアップ解析のためのパス B を切ってしまうことに注意してください。これを防ぐために、赤の部分と紫の部分をソース側のコントローラ内で切ることにします (実は、青のループを切る際にも同様のことを考慮しています)。
まず、赤の部分を切るために、上のループ出力に従って、次のように実行します。
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]この後、再度 check_timing を実行すると、上記のループが消え、紫の部分が次のように出力されます。
U_cont/U_oreg_cont/G1_out_inferred_i_1/O
U_cont/U_ireg_cont/G1_out_inferred_i_1/I1
U_cont/U_ireg_cont/G1_out_inferred_i_1/O
U_cont/U_ireg_cont/G2_out_inferred_i_1/I3
U_cont/U_ireg_cont/G2_out_inferred_i_1/O
U_cont/U_delay/buf_inst1/I0
U_cont/U_delay/buf_inst1/O
U_cont/U_delay/buf_inst3/I0
U_cont/U_delay/buf_inst3/O
U_cont/U_oreg_cont/G1_out_inferred_i_1/I3
U_cont/U_oreg_cont/G1_out_inferred_i_1/Oこれを切るために、同様に次のようなコマンドを与えます。
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]これで、check_timing を実行すると、組合わせループが残っていないことが確認できます。結局、下図のような部分を切ったことになります。
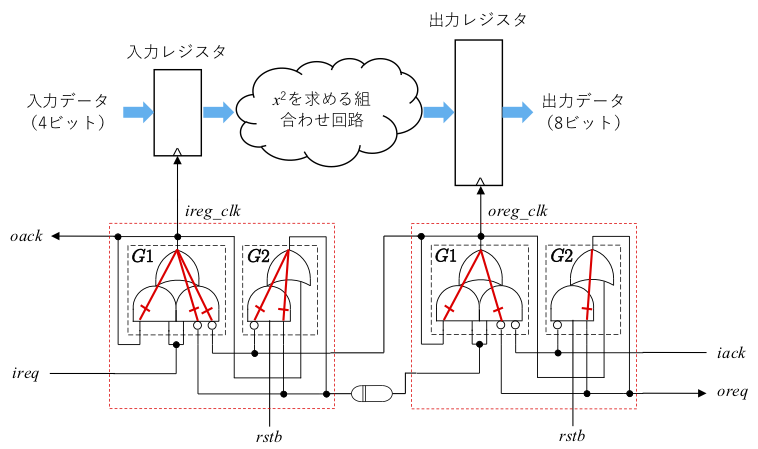
なお、-from の部分に指定するセルの入力ピン番号は、実装を行うごとに変わる可能性があります。check_timing の結果をファイルに格納して、そのファイルを元に、set_disable_timing コマンドを生成するようなスクリプトを作っておくといいかもしれません。あるいは、遅延素子以外の絶対位置を、前回紹介したように BEL, LOC 属性を使って固定しておくと、入力ピン番号が変わることはあまり起こらないかもしれません。
解析結果の確認
以上で準備は完了です。再度、report_timing コマンドを実行すると、今度は次のようなタイミング解析レポートが setup.rpt というファイルに出力されます。以下は、その一部を示したものです。
Location Delay type Incr(ns) Path(ns) Netlist Resource(s)
------------------------------------------------------------------- -------------------
(clock STU1 rise edge) 0.000 0.000 r
SLICE_X0Y12 LUT4 0.000 0.000 r U_cont/U_ireg_cont/G1_out_inferred_i_1/O
net (fo=7, routed) 0.265 0.265 oack_OBUF
SLICE_X0Y12 FDCE r ireg_reg[3]/C
------------------------------------------------------------------- -------------------
SLICE_X0Y12 FDCE (Prop_fdce_C_Q) 0.204 0.469 r ireg_reg[3]/Q
net (fo=4, routed) 0.282 0.751 U_multi/in[3]
SLICE_X1Y12 LUT4 (Prop_lut4_I3_O) 0.056 0.807 r U_multi/out[4]_INST_0/O
net (fo=1, routed) 0.000 0.807 mul_out[4]
SLICE_X1Y12 FDCE r oreg_reg[4]/D
------------------------------------------------------------------- -------------------
(clock STU1 rise edge) 0.001 0.001 r
SLICE_X0Y12 LUT4 0.000 0.001 r U_cont/U_ireg_cont/G1_out_inferred_i_1/O
net (fo=7, routed) 0.130 0.131 U_cont/U_ireg_cont/G1_out
SLICE_X0Y12 LUT4 (Prop_lut4_I3_O) 0.045 0.176 r U_cont/U_ireg_cont/G2_out_inferred_i_1/O
net (fo=3, routed) 0.261 0.437 U_cont/U_delay/in
SLICE_X1Y12 LUT1 (Prop_lut1_I0_O) 0.042 0.479 r U_cont/U_delay/buf_inst1/O
net (fo=1, routed) 0.212 0.690 U_cont/U_delay/w1
SLICE_X2Y12 LUT1 (Prop_lut1_I0_O) 0.112 0.802 r U_cont/U_delay/buf_inst3/O
net (fo=1, routed) 0.282 1.084 U_cont/U_oreg_cont/ireq
SLICE_X0Y12 LUT4 (Prop_lut4_I3_O) 0.045 1.129 r U_cont/U_oreg_cont/G1_out_inferred_i_1/O
net (fo=11, routed) 0.380 1.508 oreg_clk
SLICE_X1Y12 FDCE r oreg_reg[4]/C
clock pessimism 0.000 1.508
clock uncertainty -0.035 1.473
SLICE_X1Y12 FDCE (Setup_fdce_C_D) 0.014 1.487 oreg_reg[4]
-------------------------------------------------------------------
required time 1.487
arrival time -0.807
-------------------------------------------------------------------
slack 0.6804行目から12行目までがパス A に、15行目から26行目までがパス B に対応しています。このように、slack が正になったので、セットアップ時間に関しては、適用した遅延素子はどんなデータ入力に対しても正しく動作することがわかりました。
なお、以上のコマンドはTcl Console から入力してもいいのですが、一つのファイル (例えば setup.tcl) にまとめ、Tcl Console では以下のように入力するのが簡単です。
source setup.tclsetup.tcl は次のようになります。
check_timing -verbose -override_defaults {loops} -file "loops_bfr.rpt"
set_disable_timing -from I0 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
check_timing -verbose -override_defaults {loops} -file "loops_aft.rpt"
create_clock -name STU1 -period 0.001 [get_pins U_cont/U_ireg_cont/G1_out_inferred_i_1/O]
set_multicycle_path 0 -setup -to [all_clocks]
report_timing -setup -no_report_unconstrained -file setup.rptホールド時間解析
パスの検討
次にホールド時間解析です。タイミングチャートを再掲します。
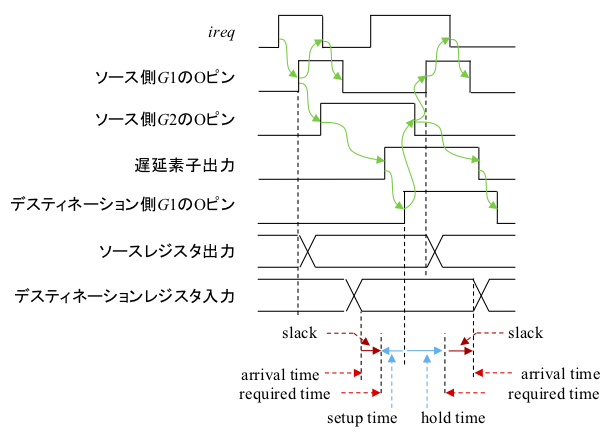
具体的なパスは次のようになります。
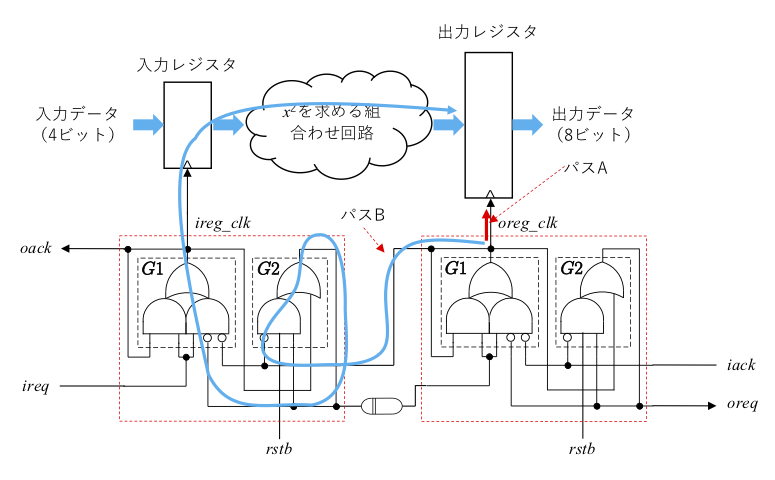
この場合の required time, arrival time は以下の通りです。
- Required time: (デスティネーションレジスタクロックピンまでの遅延) + (ホールド時間)
- Arrival time: (デスティネーション側 oack からソースレジスタクロックピンまでの遅延) + (ソースレジスタからデスティネーションレジスタまでの最小回路遅延)
- Slack: (Arrival time) ー (Required time)
この場合のパスの共通の起点は oreg_clk すなわちデスティネーション側 G1 出力なので、create_clock コマンドは次のようになります。
create_clock -name HLD1 -period 0.001 [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/O]ホールド時間解析の場合、STA エンジンのマルチサイクル数のデフォールト値は0なので、set_multicycle_path コマンドは不要です。
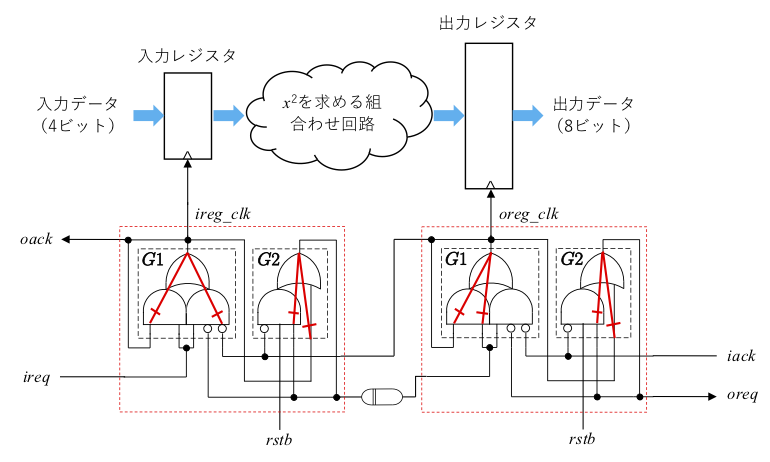
組合わせループのカット
次に、組合わせループのカットですが、上図のパス B を切らないように注意します。
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]これにより、下図の部分をカットしました。
解析結果の確認
以上で準備は完了です。ホールド時間解析に関する詳しい情報を見るために、次のコマンドを実行します。
report_timing -hold -no_report_unconstrained -file hold.rptこれにより、次のタイミング解析レポートが hold.rpt というファイルに出力されます。以下は、その一部を示したものです。
Location Delay type Incr(ns) Path(ns) Netlist Resource(s)
------------------------------------------------------------------- -------------------
(clock HLD1 rise edge) 0.000 0.000 r
SLICE_X0Y12 LUT4 0.000 0.000 r U_cont/U_oreg_cont/G1_out_inferred_i_1/O
net (fo=11, routed) 0.088 0.088 U_cont/U_ireg_cont/iack
SLICE_X0Y12 LUT4 (Prop_lut4_I1_O) 0.045 0.133 f U_cont/U_ireg_cont/G2_out_inferred_i_1/O
net (fo=3, routed) 0.151 0.283 U_cont/U_ireg_cont/G2_out
SLICE_X0Y12 LUT4 (Prop_lut4_I2_O) 0.045 0.328 r U_cont/U_ireg_cont/G1_out_inferred_i_1/O
net (fo=7, routed) 0.232 0.561 oack_OBUF
SLICE_X0Y12 FDCE r ireg_reg[3]/C
------------------------------------------------------------------- -------------------
SLICE_X0Y12 FDCE (Prop_fdce_C_Q) 0.164 0.725 r ireg_reg[3]/Q
net (fo=4, routed) 0.093 0.818 U_multi/in[3]
SLICE_X1Y12 LUT2 (Prop_lut2_I1_O) 0.051 0.869 r U_multi/out[7]_INST_0/O
net (fo=1, routed) 0.000 0.869 mul_out[7]
SLICE_X1Y12 FDCE r oreg_reg[7]/D
------------------------------------------------------------------- -------------------
(clock HLD1 rise edge) 0.000 0.000 r
SLICE_X0Y12 LUT4 0.000 0.000 r U_cont/U_oreg_cont/G1_out_inferred_i_1/O
net (fo=11, routed) 0.434 0.434 oreg_clk
SLICE_X1Y12 FDCE r oreg_reg[7]/C
clock pessimism 0.000 0.434
SLICE_X1Y12 FDCE (Hold_fdce_C_D) 0.107 0.541 oreg_reg[7]
-------------------------------------------------------------------
required time -0.541
arrival time 0.869
-------------------------------------------------------------------
slack 0.328 今度も slack が正となったので、ホールド時間解析もパスしたことになります。以上で、適用した遅延素子が正しく動作することが確認されました。
ホールド時間解析に用いたコマンドをまとめると次のようになります。
check_timing -verbose -override_defaults {loops} -file "loops_bfr.rpt"
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I3 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
check_timing -verbose -override_defaults {loops} -file "loops_aft.rpt"
create_clock -name HLD1 -period 0.001 [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/O]
report_timing -hold -no_report_unconstrained -file hold.rptCreate_clock により切断されるタイミングパスの対処
最後に、もう一つ、有益かもしれないテクニックを紹介しておきます (2018年の非同期式回路に関する国際会議 ASYNC2018 で紹介された方法です)。
例えばセットアップ時間解析で、複数のソースレジスタの解析を一度に行いたい場合も多いかもしれません。今回の例では該当しませんが、例えば oreg の後にまた組合わせ回路があり、それを oreg2 が受けるようになっているような場合です。この場合、oreg をソースレジスタとした解析も同時に行おうとすると、create_clock の定義は次のようになります。
create_clock -name STU1 -period 0.001 [get_pins U_cont/U_ireg_cont/G1_out_inferred_i_1/O]
create_clock -name STU2 -period 0.001 [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/O]しかし、この二つ目の create_clock は ireg をソースレジスタとする解析を妨害してしまいます。例題回路における setup.tcl に、この二つ目の create_clock を単に追加して、解析を行うと、ireg_clk から始まらなければならないパス B が、oreg_clk から始まってしまいます (下記15行目)。
Location Delay type Incr(ns) Path(ns) Netlist Resource(s)
------------------------------------------------------------------- -------------------
(clock STU1 rise edge) 0.000 0.000 r
SLICE_X0Y12 LUT4 0.000 0.000 r U_cont/U_ireg_cont/G1_out_inferred_i_1/O
net (fo=7, routed) 0.565 0.565 oack_OBUF
SLICE_X0Y12 FDCE r ireg_reg[3]/C
------------------------------------------------------------------- -------------------
SLICE_X0Y12 FDCE (Prop_fdce_C_Q) 0.518 1.083 r ireg_reg[3]/Q
net (fo=4, routed) 0.678 1.761 U_multi/in[3]
SLICE_X1Y12 LUT4 (Prop_lut4_I3_O) 0.124 1.885 r U_multi/out[4]_INST_0/O
net (fo=1, routed) 0.000 1.885 mul_out[4]
SLICE_X1Y12 FDCE r oreg_reg[4]/D
------------------------------------------------------------------- -------------------
(clock STU2 rise edge) 0.001 0.001 r
SLICE_X0Y12 LUT4 0.000 0.001 r U_cont/U_oreg_cont/G1_out_inferred_i_1/O
net (fo=11, routed) 0.823 0.824 oreg_clk
SLICE_X1Y12 FDCE r oreg_reg[4]/C
clock pessimism 0.000 0.824
clock uncertainty -0.035 0.788
SLICE_X1Y12 FDCE (Setup_fdce_C_D) 0.031 0.819 oreg_reg[4]
-------------------------------------------------------------------
required time 0.819
arrival time -1.885
-------------------------------------------------------------------
slack -1.066 これは、追加した create_clock である STU2 も元の STU1 と同期しているクロックと思われてしまい、ireg をソースレジスタとした解析に使われてしまうからです。これを防ぐために、これら二つのクロックが非同期であることを次のようにツールに指示します。
set_clock_groups -asynchronous -group STU1 -group STU2これにより、STU2 はパス B に使われることはなくなりますが、今度はパス B が STU2 の create_clock により切断されてしまい、セットアップ解析においてパスが見つからない、と表示されてしまいます。通常、create_clock は STA エンジンのタイミングアークを切断する効果を持ちます。そこで、提案されたのが、この STU2 を飛び越えるテクニックです。これは、create_generated_clock を用いて、次のように記述します。
create_generated_clock -name STU1_G -divide_by 1 -source [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/I3] [get_pin\
s U_cont/U_oreg_cont/G1_out_inferred_i_1/O] -master STU1 -add
set_clock_groups -asynchronous -group {STU1 STU1_G} -group STU2STU1 をマスタに指定して、STU2 が指定しているポイントを出力として持つセル (この場合、U_oreg_cont/G1_out_inferred_i_1) に create_generated_clock を被せる形とします。set_clock_groups も関連して修正します。これらを加えることにより、STU2 が存在しても、ireg をソースとするセットアップ時間解析は正しく行えるようになります。
コマンド全体を以下に示しておきます。
check_timing -verbose -override_defaults {loops} -file "loops_bfr.rpt"
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I1 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I0 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G2_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_ireg_cont/G1_out_inferred_i_1]
set_disable_timing -from I2 -to O [get_cells U_cont/U_oreg_cont/G1_out_inferred_i_1]
check_timing -verbose -override_defaults {loops} -file "loops_aft.rpt"
create_clock -name STU1 -period 0.001 [get_pins U_cont/U_ireg_cont/G1_out_inferred_i_1/O]
create_clock -name STU2 -period 0.001 [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/O]
create_generated_clock -name STU1_G -divide_by 1 -source [get_pins U_cont/U_oreg_cont/G1_out_inferred_i_1/I3] [get_pin\
s U_cont/U_oreg_cont/G1_out_inferred_i_1/O] -master STU1 -add
set_clock_groups -asynchronous -group {STU1 STU1_G} -group STU2
set_multicycle_path 0 -setup -to [all_clocks]
report_timing -setup -no_report_unconstrained -file setup.rptまとめ
前回と今回で述べた、非同期式回路を FPGA に実装する上で、重要なポイントをまとめておきます。
- 必要なセルや信号線を保存するために DONT_TOUCH 属性を使う。
- 実装ごとの遅延時間変化を少なくするために、セルの配置を固定する。
- 遅延素子の実装には、セルの相対位置指定を行う。
- 静的タイミング検証を行う上では、
- 各ソースレジスタに対して、ひとつの create_clock の設定
- タイミングアークにおける組合わせループのカット
- create_clock によって切断されるタイミングパスの対処
このほかにも、幅の短いパルスを作ると消えてしまうとか、ハンドシェイクのオーバーヘッドを削減するにはどうしたら良いか、など様々な検討課題が、非同期式回路設計にはあります。しかし、同期式回路におけるクロック関連問題に対する一つの選択肢、あるいは、GALS のような同期式設計との共存、などの方向を期待したいところです。
最終回は長くなってしまいましたが、最後までお読み頂き、誠にありがとうございました。このコースでは、取り敢えず FPGA 上でちゃんと動く非同期式回路を作ってみる、ということを目指して、細かなことにこだわらず、大まかな話をしたつもりです。非同期式回路に少しでも興味のある方にとって、取っ掛かりとなるような記事となることを願っています。
国立情報学研究所 米田友洋