
本コースでは、複数の FPGA を用いた計算機システムの構成と、私達が研究開発が行っているカスタム・コンピューティング・システムについて紹介していきます。
第4回では、FPGA を搭載したヘテロジニアスシステム上で、ソフトウェアのみで自由にデータ転送を行える機能、「ソフトウェアブリッジドデータ転送」機能を紹介します。
ソフトウェアブリッジドデータ転送 (SBDT データ転送)
紹介するソフトウェアブリッジドデータ転送 (SBDT データ転送) の目的は、FPGA 搭載ヘテロジニアスシステム上で安価かつ柔軟にデータを転送することです。
RDMA 機能を搭載するネットーワーク機器や FPGA 上にルーターなどのハードウェア (HW) モジュールを用意することで、同等の機能を実現することは可能です。しかし、システムの規模が大きくなれば、これらを用意する追加の投資は無視できません。なお、筆者の知る限り、現時点では、別のノード上の FPGA ボードに直接データを転送する機能を持つネットーワーク機器や機能は商用では提供されていません。
そこで、我々は追加のネットーワーク機器や HW モジュール を用意することなく FPGA メモリから別ノードのホスト CPU や FPGA メモリへのデータ転送を実現する手法を考案しました。
SBDT データ転送の概要
SBDT データ転送機能が想定するヘテロジニアスシステムは、以下の図の様に CPU のみの rNode と、CPU/FPGA を搭載した FPGA Node から成ります。データの経路は、ノード間の通信に InfiniBand を、ノード内の通信に PCIe Gen3 x16 を利用しています。
FPGA 搭載ヘテロジニアスシステムで柔軟なデータ転送が行える
具体的な通信方法として、FPGA メモリとホスト CPU 間のデータ転送に一般的な DMA 転送を、ノード間のホスト CPU 同士のデータ転送に InfiniBand verbs を用いた RDMA 転送を利用します。また、ユーザレベル API として、SBDT データ転送を実行するための C/C++ 関数を用意しました。
実装と評価に利用したノードの機器の詳細は、以下の表の通りです。
| OS | CentOS 7.6.1810 |
| CPU | Cavium ThunderX2 CN9975 (28core @2.4GHz) x2 |
| Memory | 64GB x 2 = 128GB |
| InfiniBand HCA | Mellanox ConnectX-5 (MCX555A-ECAT) |
| libibverbs version | 41mlnx1 |
| InfiniBand driver | Mellanox OFED.4.2.1.2.0.1.gf8de107.rhel7u4 |
| OS | CentOS 7.6.1810 |
| CPU | Intel Xeon Gold 5122 (8core @3.60GHz) x2 |
| Memory | 48GB x 2 = 96GB |
| InfiniBand HCA | Mellanox ConnectX-5 (MCX555A-ECAT[1]) |
| libibverbs version | 41mlnx1 |
| InfiniBand driver | Mellanox OFED.4.2.1.2.0.1.gf8de107.rhel7u4 |
| FPGA | Intel PAC with Arria10 |
| FPGA | Intel Arria 10 GX (11AX115N2F40E2LG) |
| Logic elements | 1150k |
| ALM | 427,200 |
| Register | 1,708,800 |
| Emb. Mem. (M20K) | 53Mb |
| FP32 DSPs | 1,518 |
| Memory | Two channel of 4GB DDR4-2133 |
| Interface | PCIe Gen3 x8, QSFP28 |
ノード内通信 (DMA 転送) の実装と予備評価
ノード内の FPGA メモリと CPU メモリの通信に用いられる DMA 転送機能は、 C 言語で実装された DMA 用 API (含 制御用ソフトウェア) と、 FPGA に実装された Tx/Rx 用の 2 つの DMA コントローラ (DMAC) モジュールで実現されます。
DMA のユーザレベル API の名称は afuShellDMATransfer で、 DMAC は Intel PAC に付属のサンプル streaming dma afu に機能を追加したものです。DMAC には Intel が提供している IP コア modular scatter-gather DMA (mSGDMA) を利用しています。
表 4 に Tx/Rx 用の 2 つの DMA コントローラ (DMAC) を合計したリソース使用量を示します。Intel PAC with Arria10 の全リソースの 1% 以下と、非常に小さいです。
| ALMs | Rigisters | BRAM [Kbits] | DSPs |
| 2905 | 3055 | 135040 | 27 |
実装
Tx と Rx の DMAC の性能を最大限に発揮するために、 POSIX スレッドが各 DMAC の制御のために割り当てました。また、ノードの構成の図に示すような、送受信用の 8 エントリのリングバッファ (Tx Buffer, Rx Buffer) を用意しています。
2 つのリングバッファは、hugepage 機能と Intel Open Programmable Acceleration Engine (OPAE) の fpgaPrepareBuffer() を用いて、 Kernel 空間上で連続したメモリアドレスとして確保することで、 CPU メモリから FPGA メモリへのデータ転送の高速化を実現しています。また、リングバッファは CPU と FPGA 上の DMAC からアクセス可能なためゼロコピーが可能です。ゼロコピーは可能ですが、使いやすさの向上を目的として、ユーザデータを一旦リングバッファにコピーする形式を採用しました。
具体的には、CPU メモリから FPGA メモリへのデータ転送は次の様にして実現されます。
- ユーザ空間に存在する読み出し先アドレスのデータは、リングバッファのサイズに分割され、順にリングバッファの各エントリにコピーされる
- Tx DMAC が、各エントリのデータを PCIe バスと 512bit の Avalon-MM ポートを介して読み出す
- 読み出されたデータは、 Tx DMAC の書き出し側にある 512bit の Avalon-ST ポートに送られる
- Tx DMAC の Avalon-ST ポートと Rx DMAC の Avalon-ST ポートは、計算コアを介して接続されており、 Tx DMAC から送られたデータは Rx DMAC へと流れる
- Rx DMAC は、流れて来たデータを Avalon-MM ポートを介して指定された FPGA メモリ上のアドレスへと書き出す
- 全てのデータが Rx DMAC の Avalon-MM ポートを通過した時に、 Rx DMAC は完了信号として割り込みを発生させる
バッファサイズは可変です。しかし、サイズが小さすぎる場合は、ユーザデータをコピーしたり DMAC へディスクリプタを書き込むなどの制御処理の回数が増えるため CPU 側の負荷が増加すると考えられます。
評価
FPGA メモリの理論転送帯域は、 PAC が搭載しているメモリの帯域 (DDR4-2133) ではなく、FPGA に実装された計算コアの動作周波数に 512bit を掛けたものとなります。本実装では、計算コアは 200 [MHz] で動作しているため、FPGA メモリの論理転送帯域は 200 [MHz] * (512 [bit] / 8 [bit/byte]) = 12800 [MB/s] となります。
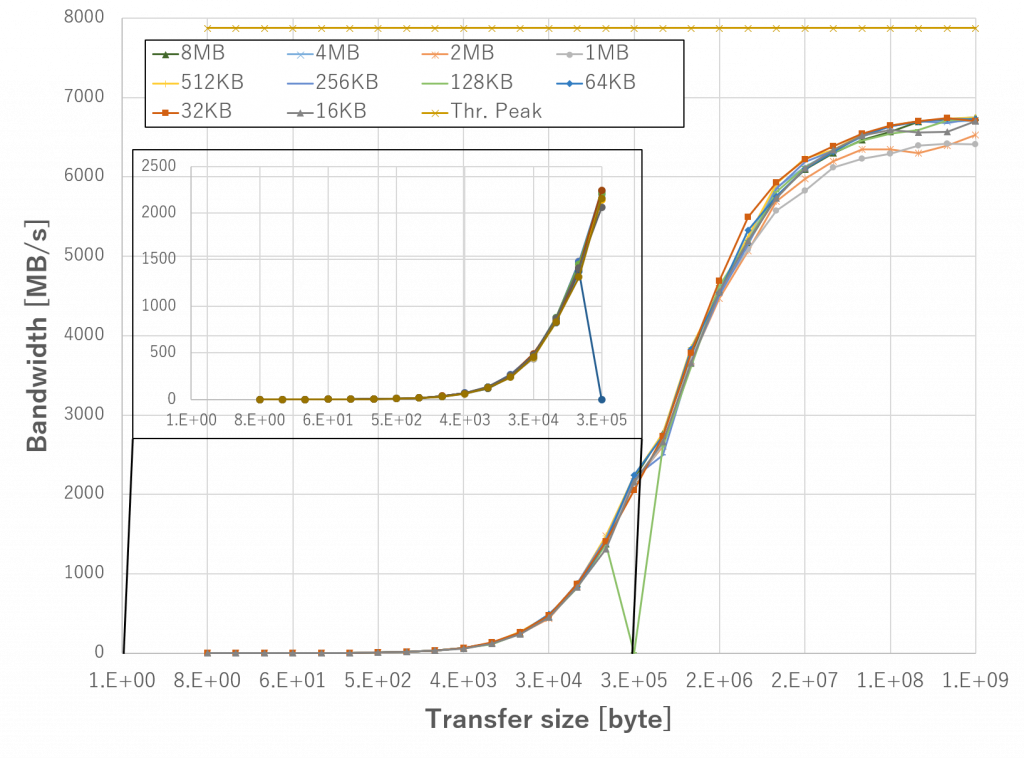
上図は、 Tx/Rx バッファのサイズを 16KB から 8MB まで変更した際の CPU メモリから FPGA メモリへの実効データ転送帯域の値を示したものです。また、図中の左上に転送サイズが 2 bytes から 256 Kbyte の時の値を拡大して示します。
実装した DMA 転送機能はバッファサイズが 8MB で転送データのサイズが 1GB の時に、最大値である 6745.2 MB/s を達成しており、PCIe Gen3 x8 (7877 MB/s) の理論ピーク性能の 85.6% となります。バッファサイズが 256KB 以下の場合は性能が低下することもわかりました。転送サイズが 1KB の際に、バッファサイズが 64KB の方が 8MB よりも 13%ほど高い帯域を記録しています。
全体としては、バッファサイズは性能に大きな影響を与えないが、多くの転送データのサイズで 8MB の時に最大値となることがわかりました。
ノード間通信 (InfiniBand verbs による RDMA転送) の実装と予備評価
InfiniBand は HPC 分野における低レイテンシかつ高速なノード間データ転送を実現する相互接続網であり、 InfiniBand verbs (IBv) は InfiniBand を利用するためのネイティブ API です。RDMA 転送には IBv の RDMA Read と RDMA Write オペレーションを用いました。
少し細かい話ですが、IBv はユーザがネットーワーク機器の内部状態を遷移させる必要があり、扱いが簡単ではありません。今回の場合、IBv でデータ転送を行うには、 ibv_reg_mr 関数を用いて転送するデータを protection domain 内の memory region に登録する手続きが必要となります。また、データ転送以外の手続きとして、転送経路確立のために queue pair のやり取りが、転送の終了確認のために completion queue の監視がそれぞれ必要となります。memory region への登録にかかる時間は、データサイズに比例して大きくなることが知られています。
予備評価として、 IBv ライブラリに付属の ib_read_bw と ib_write_bw コマンドを利用して、 RDMA Read/Writeの実効データ転送帯域の評価を行いました。上図に RDMA Read と Write の実効データ転送帯域と転送サイズの関係を示します。どちらも転送サイズが 8KB 以上で最大値を達成しており、最大データ転送帯域は RDMA Read が 9162.1 MB/s (73.3 %)、 RDMA Write が 11927.3 MB/s (95.2 %) でした。
SBDT 通信 : ノード内通信とノード間通信のオーバーラップし、パイプライン動作させる
実装
SBDT 通信は、サーバ・クライアント型のデータ通信モデルを利用しています。FPGA Node がサーバとなり、クライアントからのデータの読み書きのリクエストを待ちます。rNode はクライアントで、データの読み書きの処理をサーバにリクエストします。
遠隔でのデータ転送を実現するために、 以下に示すサーバ側の API が FPGA nodeのホスト CPU 側で要求の待受を行い、リスト 2 に示すクライアント側の API が rNode から所定のデータ転送を要求します。DMA API である afuShellDMATransfer() と同様に、 FPGA メモリを読み書きする場合は、読み出し・書き込み先アドレスに物理アドレスを指定する必要があります。
// クライアント側の API
remote fpga result remoteAfuShellDMATransfer(
uint64 t src, // Destination address of data
uint64 t dst, // Source address of data
uint64 t tf len, // Data transfer size [byte]
afu shell dma transfer type t tf type, // transfer type
remote fpga dma handle t dma tx h, // DMA handler
remote fpga dma handle t dma rx h // DMA handler
);// サーバ側の API
void srv afuShellDMATransfer(
// info. of FPGA and data transfer
dev context t∗ dev context,
uint16 t req size // Data transfer size [byte]
);SBDT のナイーブ実装を rNode の CPU メモリ (=src) を FPGA node の FPGA の計算コアを経由して、 rNode の CPU メモリ (=dst) へ戻す場合のデータ転送を例に説明します。以下、この転送経路を round trip と呼称し、下図にデータの流れと処理手順を示します。
- データは rNode から FPGA node の CPU メモリへ IBv RDMA Read を用いてノード間転送され、 CPU メモリ上の受信用中間バッファに書き込まれます
- DMA 転送を行います。書き込まれたデータは、FPGA 上の計算コアを介して、送信用の中間バッファへ送られます
- 送信用中間バッファの内容が IBv RDMA Write を用いて rNode へ書き出され、転送が完了します
実際のデータ転送は、効率的に動作すべく、データがバッファのサイズに分割されて、ノード内通信とノード間通信がオーバーラップかつパイプライン化されています。基本的なアイディアは、ノード間データ転送に afuShellDMATransfer の内部実装で用意された Tx/Rx バッファを直接利用し、バッファサイズ毎に各データ転送をパイプライン的に行うものです。
詳しくは、研究会論文 や HEART2019の論文 を御覧ください。
評価
パイプライン実装版の、SBDTの転送サイズと実効データ転送帯域を関係を測定します。 下図は、rNode の CPU メモリから FPGA メモリへの実効データ転送帯域の測定結果をまとめたものです。Tx/Rx バッファのサイズを 64 KB から 16 MB まで変更した際の性能への影響を評価しました。
本転送経路のボトルネックは、 PCIe Gen x3 (理論ピーク帯域: 7877MB/s) です。バッファサイズが 1MB 以下の場合、転送帯域はピーク帯域に対し大幅に低い値となっています。これは、ノード間データ転送に対し、 DMA 転送が遅いためにパイプラインがストールしてしまったためだと考えています。
予備評価の結果から、転送サイズが 1MB の場合は、 RDMA Read が DMA 転送よりも実効データ転送帯域が高いことが裏付けとなります。バッファサイズが 2MB 以上の場合は、実効データ転送帯域はピーク帯域の 70~80 %を達成しており、バッファサイズが 8MB の場合、最大値を達成しています。これはパイプラインがストールせずに効果的にデータ転送が行われているためだと考えています。
下図に 3 つの経路の実効データ転送帯域をまとめます。
実線で表されたグラフが SBDT の値であり、破線で表されたグラフは比較のためにプロットした DMA 転送の値です。各経路は転送サイズが 512MB の時に転送帯域が最大値となりました。
転送帯域の最大値とピーク性能に対する比率は、 rNode の CPU メモリから FPGA メモリでは 6379.1 MB/s (81.0 %)、 FPGA メモリから rNode の CPUメモリでは 5696.1 MB/s (72.3 %)、 round trip では 4732.0 MB/s (60.1 %) です。なお、CPU メモリから FPGA メモリへの DMA 転送と、rHost のメモリから FPGA メモリへのSBDT 転送を比較すると、後者の方がグラフの立ち上がりが遅いことがわかりました。
まとめ
今回は、FPGA を搭載したヘテロジニアスシステム上で、追加のネットーワーク機器や HW モジュール を用意することなく FPGA メモリから別ノードのホスト CPU や FPGA メモリへのデータ転送を実現する手法「ソフトウェアブリッジドデータ転送」機能を紹介しました。
次回は、我々が研究開発中の AFU シェル についてご紹介したいと思います。
理化学研究所 計算科学研究センター (R-CCS) プロセッサ研究チーム
特別研究員 宮島敬明
チームリーダー 佐野健太郎