
前回までは、Vivado や PetaLinux を使用して Vitis Target Platform の作成、そして Acceleration Application の構築までの一連の流れを簡単にご紹介しました。今回は最終回となる、Vitis Library や Vitis AI Solution についてご紹介いたします。
Vitis Library
Vitis には Software の記述を FPGA に置き換えて高速化することが可能な Tool です。ですが、初めての方に FPGA 高速化専用の記述、所謂 HLS C を記述することは非常に大変です。FPGA についての知識、並列演算についてを考えなくとも XILINX 社が Open Source で誰でも使えるように Vitis Library として Github に公開しております。まず初めての方は、これらの Library を使って見ることをお勧めします。
Design Flow
Vitis Library の Design Flow は、通常の Acceleration Application の Flow と同じです。違いは、Acceleration の部分を User が記述するか、Vitis Library の関数を利用するかしないかの違いになります。Vitis Library 自体は HLS C で書かれており、Source Code も Github に公開されております。
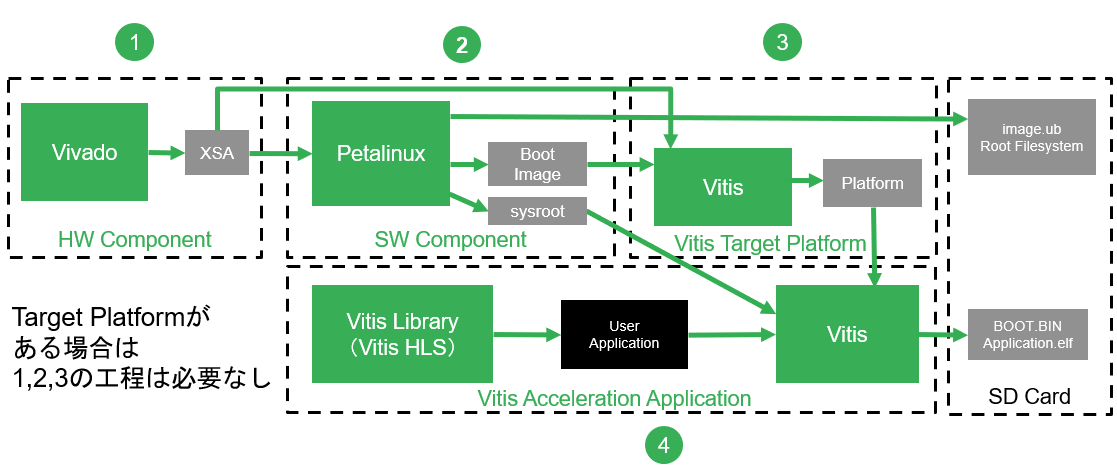
Library の種類
Vitis Library には、FPGA で Acceleration 出来る関数を複数用意しております。Library には DSP や算術演算に始まり、画像処理、機械学習、金融、セキュリティなどがあります。 詳細は、以下の Github をご参照ください。
L3、L2、L1
Vitis Library API (L3)
Host Application から直接呼び出し可能な API として用意されています。Accelerator は 予め Compile して用意した状態なので、User はすぐに Acceleration Application の構築が可能です。
Vitis Library Kernels (L2)
Vitis 上で使えるように Acceleration Application に必要な Interface を備えた形で用意されています。FPGA で Acceleration 出来るようにすでに最適化されており Host Application から OpenCL を使用して呼び出す必要があり、Vitis Tools で Build する必要があります。
Vitis Library Primitives (L1)
algorithm を HLS C で最適化しただけの Source Code になっております。なので、Vitis HLS の Project 形式での提供なので、Vitis Acceleration Application で使用するための Interface が備わっていません。Vitis HLSで Build して、Vivado の IP Integrator などで Interface の接続を行う必要があります。
Vitis AI
最近は AI + FPGA が非常に身近な技術となってきました。XILINX 社では、深層学習の Model を FPGA で処理し高速に推論する方法を Vitis AI として Github で Open Source で公開しております。
Design Flow
Vitis AI の Design Flow ですが、通常の Acceleration Application の Flow とは少々ことなります。Vitis Platform に DPU を搭載することと、Vitis AI という Tool を別途使用する必要があります。
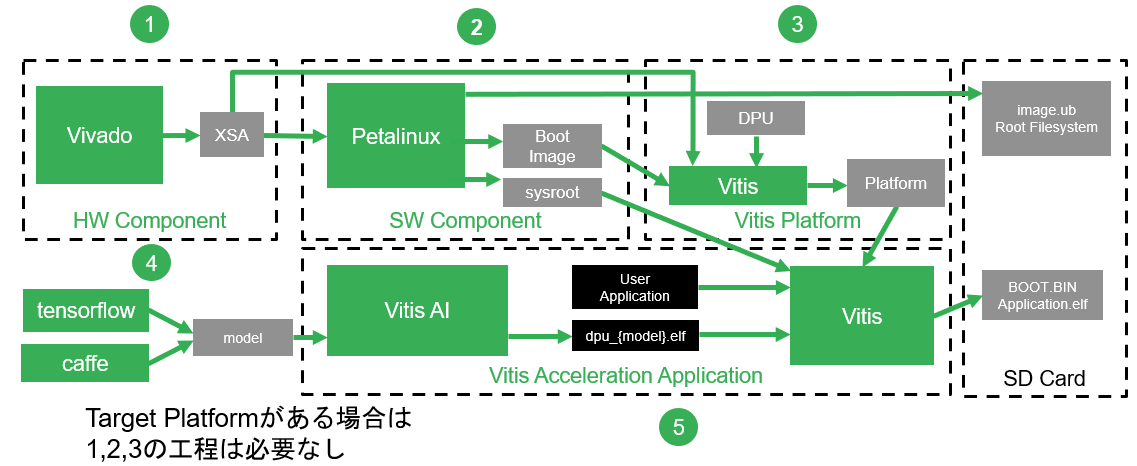
Vitis AI Tool Stack
Vitis AI の Tool Stack は、以下のような構成になっています。
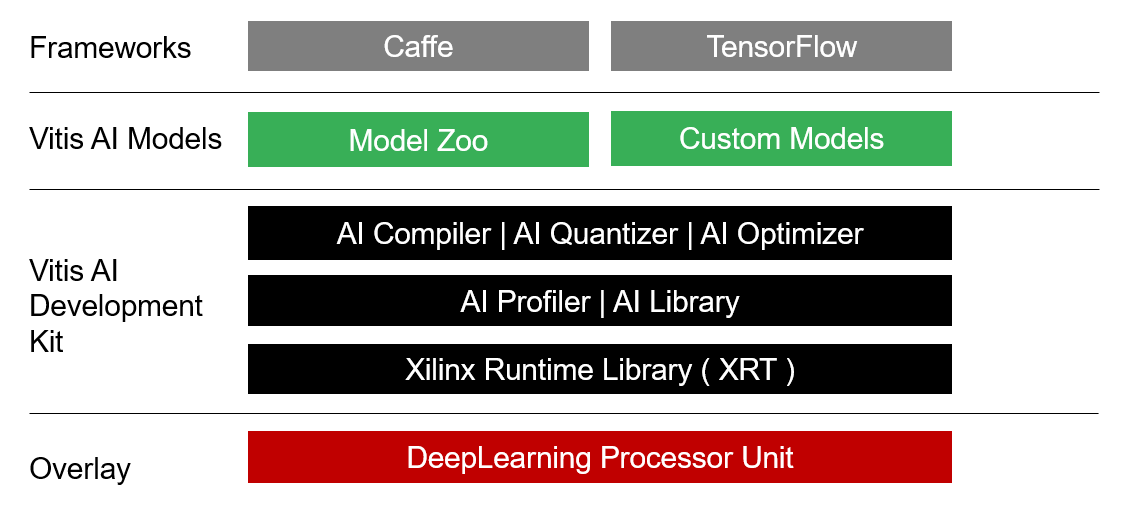
また、Tool 自体は Docker で提供されるため、PC 環境さえあれば環境構築は非常に簡単です。Docker については、Tool Docker と Runtime Docker を用意しており、Tool Docker は、Vitis AI Tool Flow のために使用し、Runtime Docker は ARM Linux の Cross Compile 環境として使用します。詳細は以下の Github をご参照ください。
DPU
DPU は、DeepLearning Processor Unit の略で、FPGA に実装可能な専用の Neural Network の演算専用 Processor となります。DPU は、AI Compiler で Compile した Binary を処理します。DPU の Binary は、Edge 側の場合、Zynq ARM 上の Linux から命令が送られます。命令は専用の Runtime を使用します。
AI Quantizer
通常、深層学習で用意する Neural Network は、Float 型 (浮動小数点32bit) です。この Tool は、Float 型の Neural NetworkをInteger 型 (固定小数点8bit) に変換 (量子化) します。これは、DPU の内部の演算器に対応させるためです。変換されたモデルは、以下のファイル名で出力されます。
- Caffe:deploy.prototxt/deploy.caffemodel
- TensorFlow:deploy_model.pb
AI Compiler
AI Quantizer で Integer 型 に変換した Neural Network は、AI Compiler を使用して DPU 専用の Instruction に変換します。出力形式は .elf になります。ARM CPU の Application 作成時に、この .elf と Link して ARM CPU と DPU の Hybrid Binary として生成します。
Model Zoo
XILINX 社では、Vitis AI に最適化した深層学習モデルを用意しています。Pruning 有り無し両方のモデルを提供しております。機械学習を取り入れた Application (例えば Face Detection など) を作りたいけど機械学習が初めての方に最適です。詳細は以下の Github をご参照ください。
Tool Flow
Vitis AI の Tool Flow は以下の4つの Step で実行します。
- Quantize the neural network model.
AI Quantizer を使用して、NN を圧縮します。 - Compile the neural network model.
AI Compiler を使用して、DPU 用の命令に Compile します。 - Program with Vitis AI programming interface.
Runtime を使用して Application を構築します。 - Run and evaluate the deployed DPU application.
実機上で動作および評価します。
また、Vitis AI では Tutorial を用意しているので、まずは Tutorial を試してみることをお勧めします。
以上が、Vitis Library および Vitis AI についての簡単な説明になります。これらの Solution を有効活用し、Application の高速化に役立てていただければ幸いです。
AVNET K.K. 仲見 倫